 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AERIAL-CORE: AI-Powered Aerial Robots for Inspection and Maintenance of Electrical Power Infrastructures
Jan 04, 2024
Large-scale infrastructures are prone to deterioration due to age, environmental influences, and heavy usage. Ensuring their safety through regular inspections and maintenance is crucial to prevent incidents that can significantly affect public safety and the environment. This is especially pertinent in the context of electrical power networks, which, while essential for energy provision, can also be sources of forest fires. Intelligent drones have the potential to revolutionize inspection and maintenance, eliminating the risks for human operators, increasing productivity, reducing inspection time, and improving data collection quality. However, most of the current methods and technologies in aerial robotics have been trialed primarily in indoor testbeds or outdoor settings under strictly controlled conditions, always within the line of sight of human operators. Additionally, these methods and technologies have typically been evaluated in isolation, lacking comprehensive integration. This paper introduces the first autonomous system that combines various innovative aerial robots. This system is designed for extended-range inspections beyond the visual line of sight, features aerial manipulators for maintenance tasks, and includes support mechanisms for human operators working at elevated heights. The paper further discusses the successful validation of this system on numerous electrical power lines, with aerial robots executing flights over 10 kilometers away from their ground control stations.
Towards Enhancing the Reproducibility of Deep Learning Bugs: An Empirical Study
Jan 05, 2024Context: Deep learning has achieved remarkable progress in various domains. However, like traditional software systems, deep learning systems contain bugs, which can have severe impacts, as evidenced by crashes involving autonomous vehicles. Despite substantial advancements in deep learning techniques, little research has focused on reproducing deep learning bugs, which hinders resolving them. Existing literature suggests that only 3% of deep learning bugs are reproducible, underscoring the need for further research. Objective: This paper examines the reproducibility of deep learning bugs. We identify edit actions and useful information that could improve deep learning bug reproducibility. Method: First, we construct a dataset of 668 deep learning bugs from Stack Overflow and Defects4ML across 3 frameworks and 22 architectures. Second, we select 102 bugs using stratified sampling and try to determine their reproducibility. While reproducing these bugs, we identify edit actions and useful information necessary for their reproduction. Third, we used the Apriori algorithm to identify useful information and edit actions required to reproduce specific bug types. Finally, we conduct a user study with 22 developers to assess the effectiveness of our findings in real-life settings. Results: We successfully reproduced 85 bugs and identified ten edit actions and five useful information categories that can help us reproduce deep learning bugs. Our findings improved bug reproducibility by 22.92% and reduced reproduction time by 24.35% based on our user study. Conclusions: Our research addresses the critical issue of deep learning bug reproducibility. Practitioners and researchers can leverage our findings to improve deep learning bug reproducibility.
Plug-in Diffusion Model for Sequential Recommendation
Jan 05, 2024Pioneering efforts have verified the effectiveness of the diffusion models in exploring the informative uncertainty for recommendation. Considering the difference between recommendation and image synthesis tasks, existing methods have undertaken tailored refinements to the diffusion and reverse process. However, these approaches typically use the highest-score item in corpus for user interest prediction, leading to the ignorance of the user's generalized preference contained within other items, thereby remaining constrained by the data sparsity issue. To address this issue, this paper presents a novel Plug-in Diffusion Model for Recommendation (PDRec) framework, which employs the diffusion model as a flexible plugin to jointly take full advantage of the diffusion-generating user preferences on all items. Specifically, PDRec first infers the users' dynamic preferences on all items via a time-interval diffusion model and proposes a Historical Behavior Reweighting (HBR) mechanism to identify the high-quality behaviors and suppress noisy behaviors. In addition to the observed items, PDRec proposes a Diffusion-based Positive Augmentation (DPA) strategy to leverage the top-ranked unobserved items as the potential positive samples, bringing in informative and diverse soft signals to alleviate data sparsity. To alleviate the false negative sampling issue, PDRec employs Noise-free Negative Sampling (NNS) to select stable negative samples for ensuring effective model optimization. Extensive experiments and analyses on four datasets have verified the superiority of the proposed PDRec over the state-of-the-art baselines and showcased the universality of PDRec as a flexible plugin for commonly-used sequential encoders in different recommendation scenarios. The code is available in https://github.com/hulkima/PDRec.
Assessment of Deep Learning Segmentation for Real-Time Free-Breathing Cardiac Magnetic Resonance Imaging
Nov 30, 2023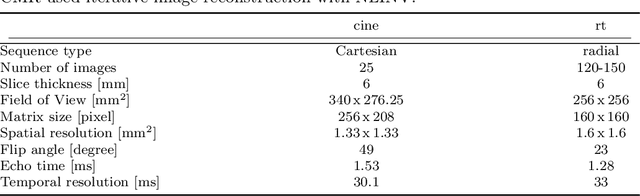

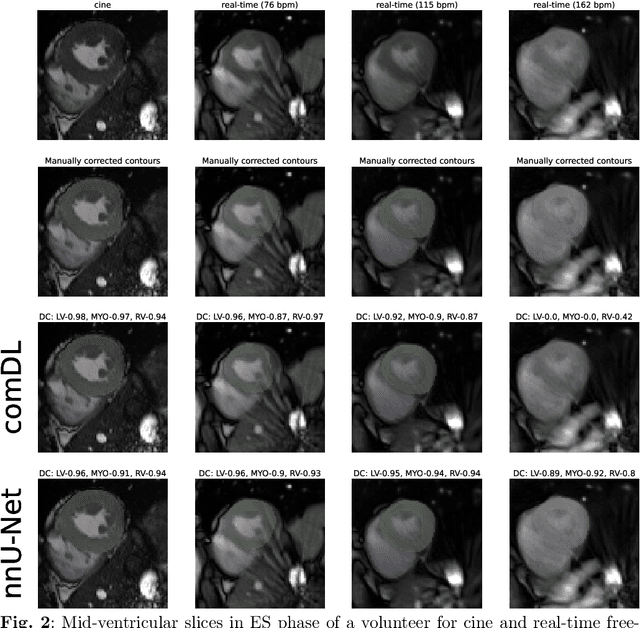

In recent years, a variety of deep learning networks for cardiac MRI (CMR) segmentation have been developed and analyzed. However, nearly all of them are focused on cine CMR under breathold. In this work, accuracy of deep learning methods is assessed for volumetric analysis (via segmentation) of the left ventricle in real-time free-breathing CMR at rest and under exercise stress. Data from healthy volunteers (n=15) for cine and real-time free-breathing CMR were analyzed retrospectively. Segmentations of a commercial software (comDL) and a freely available neural network (nnU-Net), were compared to a reference created via the manual correction of comDL segmentation. Segmentation of left ventricular endocardium (LV), left ventricular myocardium (MYO), and right ventricle (RV) is evaluated for both end-systolic and end-diastolic phases and analyzed with Dice's coefficient (DC). The volumetric analysis includes LV end-diastolic volume (EDV), LV end-systolic volume (ESV), and LV ejection fraction (EF). For cine CMR, nnU-Net and comDL achieve a DC above 0.95 for LV and 0.9 for MYO, and RV. For real-time CMR, the accuracy of nnU-Net exceeds that of comDL overall. For real-time CMR at rest, nnU-Net achieves a DC of 0.94 for LV, 0.89 for MYO, and 0.90 for RV; mean absolute differences between nnU-Net and reference are 2.9mL for EDV, 3.5mL for ESV and 2.6% for EF. For real-time CMR under exercise stress, nnU-Net achieves a DC of 0.92 for LV, 0.85 for MYO, and 0.83 for RV; mean absolute differences between nnU-Net and reference are 11.4mL for EDV, 2.9mL for ESV and 3.6% for EF. Deep learning methods designed or trained for cine CMR segmentation can perform well on real-time CMR. For real-time free-breathing CMR at rest, the performance of deep learning methods is comparable to inter-observer variability in cine CMR and is usable or fully automatic segmentation.
A Soft Continuum Robot with Self-Controllable Variable Curvature
Jan 03, 2024This paper introduces a new type of soft continuum robot, called SCoReS, which is capable of self-controlling continuously its curvature at the segment level; in contrast to previous designs which either require external forces or machine elements, or whose variable curvature capabilities are discrete -- depending on the number of locking mechanisms and segments. The ability to have a variable curvature, whose control is continuous and independent from external factors, makes a soft continuum robot more adaptive in constrained environments, similar to what is observed in nature in the elephant's trunk or ostrich's neck for instance which exhibit multiple curvatures. To this end, our soft continuum robot enables reconfigurable variable curvatures utilizing a variable stiffness growing spine based on micro-particle granular jamming for the first time. We detail the design of the proposed robot, presenting its modeling through beam theory and FEA simulation -- which is validated through experiments. The robot's versatile bending profiles are then explored in experiments and an application to grasp fruits at different configurations is demonstrated.
Structured, Complex and Time-complete Temporal Event Forecasting
Dec 02, 2023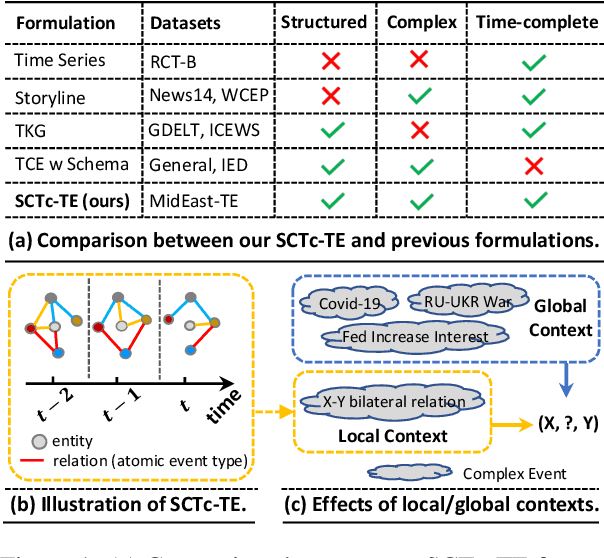
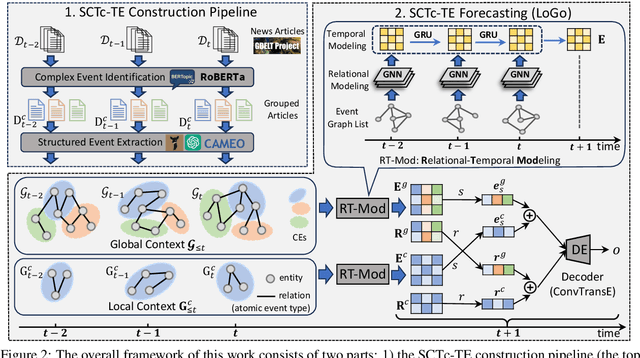
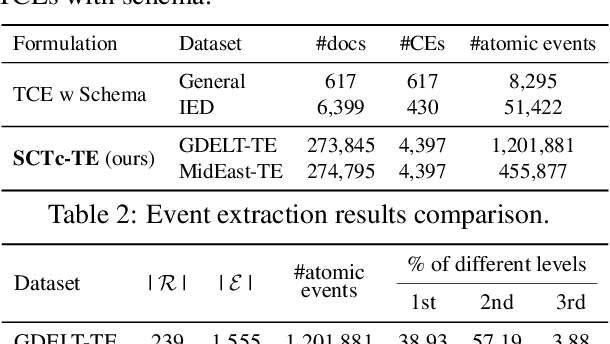
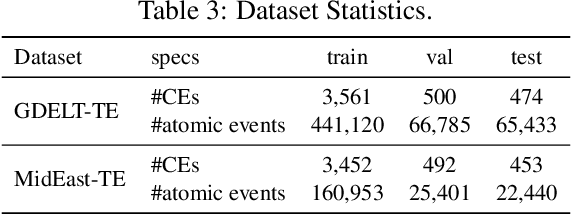
Temporal event forecasting aims to predict what will happen next given the observed events in history. Previous formulations of temporal event are unstructured, atomic, or lacking full temporal information, thus largely restricting the representation quality and forecasting ability of temporal events. To address these limitations, we introduce a novel formulation for Structured, Complex, and Time-complete Temporal Event (SCTc-TE). Based on this new formulation, we develop a simple and fully automated pipeline for constructing such SCTc-TEs from a large amount of news articles. Furthermore, we propose a novel model that leverages both Local and Global contexts for SCTc-TE forecasting, named LoGo. To evaluate our model, we construct two large-scale datasets named MidEast-TE and GDELT-TE. Extensive evaluations demonstrate the advantages of our datasets in multiple aspects, while experimental results justify the effectiveness of our forecasting model LoGo. We release the code and dataset via https://github.com/yecchen/GDELT-ComplexEvent.
Developing Flying Explorer for Autonomous Digital Modelling in Wild Unknowns
Dec 29, 2023This work presents an innovative solution for robotic odometry, path planning and exploration in wild unknown environments, focusing on digital modelling. The approach uses a minimum cost formulation with pseudo-randomly generated objectives, integrating multi-path planning and evaluation, with emphasis on full coverage of unknown maps based on feasible boundaries of interest. The evaluation carried out on a robotic platform with a lightweight 3D LiDAR sensor model, assesses the consistency and efficiency in exploring completely unknown subterranean-like areas. The algorithm allows for dynamic changes to the desired target and behaviour. At the same time, the paper details the design of AREX, highlighting its robust localisation, mapping and efficient exploration target selection capabilities, with a focus on continuity in exploration direction for increased efficiency and reduced odometry errors. The real-time, high-precision environmental perception module is identified as critical for accurate obstacle avoidance and exploration boundary identification.
Event-Based Contrastive Learning for Medical Time Series
Dec 16, 2023In clinical practice, one often needs to identify whether a patient is at high risk of adverse outcomes after some key medical event; e.g., the short-term risk of death after an admission for heart failure. This task, however, remains challenging due to the complexity, variability, and heterogeneity of longitudinal medical data, especially for individuals suffering from chronic diseases like heart failure. In this paper, we introduce Event-Based Contrastive Learning (EBCL) - a method for learning embeddings of heterogeneous patient data that preserves temporal information before and after key index events. We demonstrate that EBCL produces models that yield better fine-tuning performance on critical downstream tasks including 30-day readmission, 1-year mortality, and 1-week length of stay relative to other representation learning methods that do not exploit temporal information surrounding key medical events.
Traffic Cameras to detect inland waterway barge traffic: An Application of machine learning
Jan 05, 2024Inland waterways are critical for freight movement, but limited means exist for monitoring their performance and usage by freight-carrying vessels, e.g., barges. While methods to track vessels, e.g., tug and tow boats, are publicly available through Automatic Identification Systems (AIS), ways to track freight tonnages and commodity flows carried on barges along these critical marine highways are non-existent, especially in real-time settings. This paper develops a method to detect barge traffic on inland waterways using existing traffic cameras with opportune viewing angles. Deep learning models, specifically, You Only Look Once (YOLO), Single Shot MultiBox Detector (SSD), and EfficientDet are employed. The model detects the presence of vessels and/or barges from video and performs a classification (no vessel or barge, vessel without barge, vessel with barge, and barge). A dataset of 331 annotated images was collected from five existing traffic cameras along the Mississippi and Ohio Rivers for model development. YOLOv8 achieves an F1-score of 96%, outperforming YOLOv5, SSD, and EfficientDet models with 86%, 79%, and 77% respectively. Sensitivity analysis was carried out regarding weather conditions (fog and rain) and location (Mississippi and Ohio rivers). A background subtraction technique was used to normalize video images across the various locations for the location sensitivity analysis. This model can be used to detect the presence of barges along river segments, which can be used for anonymous bulk commodity tracking and monitoring. Such data is valuable for long-range transportation planning efforts carried out by public transportation agencies, in addition to operational and maintenance planning conducted by federal agencies such as the US Army Corp of Engineers.
Tissue Artifact Segmentation and Severity Analysis for Automated Diagnosis Using Whole Slide Images
Jan 05, 2024Traditionally, pathological analysis and diagnosis are performed by manually eyeballing glass slide specimens under a microscope by an expert. The whole slide image is the digital specimen produced from the glass slide. Whole slide image enabled specimens to be observed on a computer screen and led to computational pathology where computer vision and artificial intelligence are utilized for automated analysis and diagnosis. With the current computational advancement, the entire whole slide image can be analyzed autonomously without human supervision. However, the analysis could fail or lead to wrong diagnosis if the whole slide image is affected by tissue artifacts such as tissue fold or air bubbles depending on the severity. Existing artifact detection methods rely on experts for severity assessment to eliminate artifact affected regions from the analysis. This process is time consuming, exhausting and undermines the goal of automated analysis or removal of artifacts without evaluating their severity, which could result in the loss of diagnostically important data. Therefore, it is necessary to detect artifacts and then assess their severity automatically. In this paper, we propose a system that incorporates severity evaluation with artifact detection utilizing convolutional neural networks. The proposed system uses DoubleUNet to segment artifacts and an ensemble network of six fine tuned convolutional neural network models to determine severity. This method outperformed current state of the art in accuracy by 9 percent for artifact segmentation and achieved a strong correlation of 97 percent with the evaluation of pathologists for severity assessment. The robustness of the system was demonstrated using our proposed heterogeneous dataset and practical usability was ensured by integrating it with an automated analysis system.
* 60 pages, 21 figures, 16 tables