 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Federated Learning over Noisy Channels: Convergence Analysis and Design Examples
Jan 06, 2021
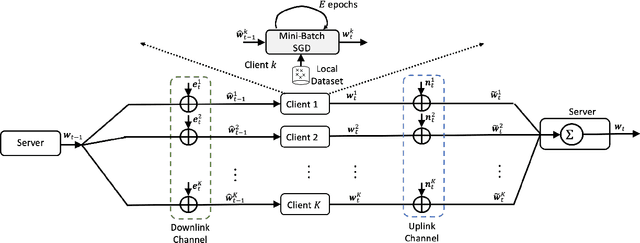


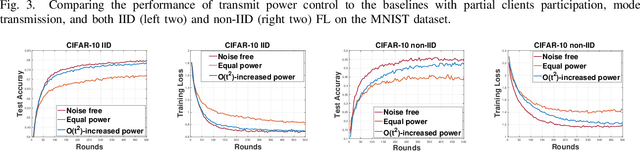
Does Federated Learning (FL) work when both uplink and downlink communications have errors? How much communication noise can FL handle and what is its impact to the learning performance? This work is devoted to answering these practically important questions by explicitly incorporating both uplink and downlink noisy channels in the FL pipeline. We present several novel convergence analyses of FL over simultaneous uplink and downlink noisy communication channels, which encompass full and partial clients participation, direct model and model differential transmissions, and non-independent and identically distributed (IID) local datasets. These analyses characterize the sufficient conditions for FL over noisy channels to have the same convergence behavior as the ideal case of no communication error. More specifically, in order to maintain the O(1/T) convergence rate of FedAvg with perfect communications, the uplink and downlink signal-to-noise ratio (SNR) for direct model transmissions should be controlled such that they scale as O(t^2) where t is the index of communication rounds, but can stay constant for model differential transmissions. The key insight of these theoretical results is a "flying under the radar" principle - stochastic gradient descent (SGD) is an inherent noisy process and uplink/downlink communication noises can be tolerated as long as they do not dominate the time-varying SGD noise. We exemplify these theoretical findings with two widely adopted communication techniques - transmit power control and diversity combining - and further validating their performance advantages over the standard methods via extensive numerical experiments using several real-world FL tasks.
A Non-Parametric Subspace Analysis Approach with Application to Anomaly Detection Ensembles
Jan 13, 2021
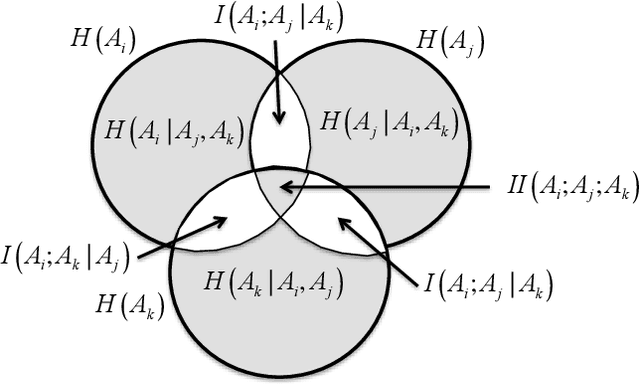

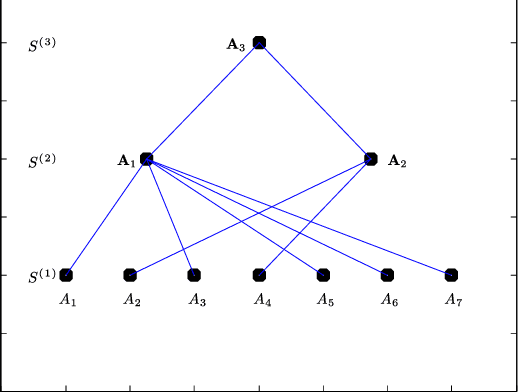
Identifying anomalies in multi-dimensional datasets is an important task in many real-world applications. A special case arises when anomalies are occluded in a small set of attributes, typically referred to as a subspace, and not necessarily over the entire data space. In this paper, we propose a new subspace analysis approach named Agglomerative Attribute Grouping (AAG) that aims to address this challenge by searching for subspaces that are comprised of highly correlative attributes. Such correlations among attributes represent a systematic interaction among the attributes that can better reflect the behavior of normal observations and hence can be used to improve the identification of two particularly interesting types of abnormal data samples: anomalies that are occluded in relatively small subsets of the attributes and anomalies that represent a new data class. AAG relies on a novel multi-attribute measure, which is derived from information theory measures of partitions, for evaluating the "information distance" between groups of data attributes. To determine the set of subspaces to use, AAG applies a variation of the well-known agglomerative clustering algorithm with the proposed multi-attribute measure as the underlying distance function. Finally, the set of subspaces is used in an ensemble for anomaly detection. Extensive evaluation demonstrates that, in the vast majority of cases, the proposed AAG method (i) outperforms classical and state-of-the-art subspace analysis methods when used in anomaly detection ensembles, and (ii) generates fewer subspaces with a fewer number of attributes each (on average), thus resulting in a faster training time for the anomaly detection ensemble. Furthermore, in contrast to existing methods, the proposed AAG method does not require any tuning of parameters.
Image Classification via Quantum Machine Learning
Nov 03, 2020

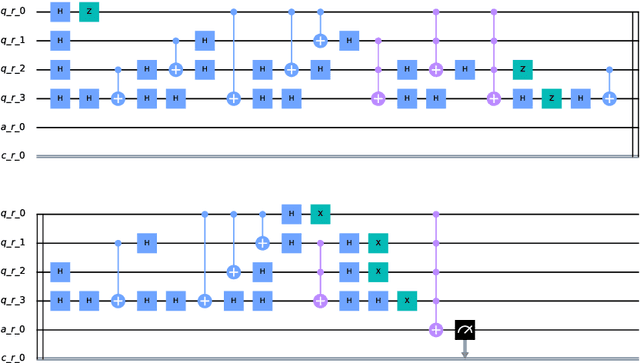
Quantum Computing and especially Quantum Machine Learning, in a short period of time, has gained a lot of interest through research groups around the world. This can be seen in the increasing number of proposed models for pattern classification applying quantum principles to a certain degree. Despise the increasing volume of models, there is a void in testing these models on real datasets and not only on synthetic ones. The objective of this work is to classify patterns with binary attributes using a quantum classifier. Specially, we show results of a complete quantum classifier applied to image datasets. The experiments show favorable output while dealing with balanced classification problems as well as with imbalanced classes where the minority class is the most relevant. This is promising in medical areas, where usually the important class is also the minority class.
Fast and automated biomarker detection in breath samples with machine learning
May 24, 2020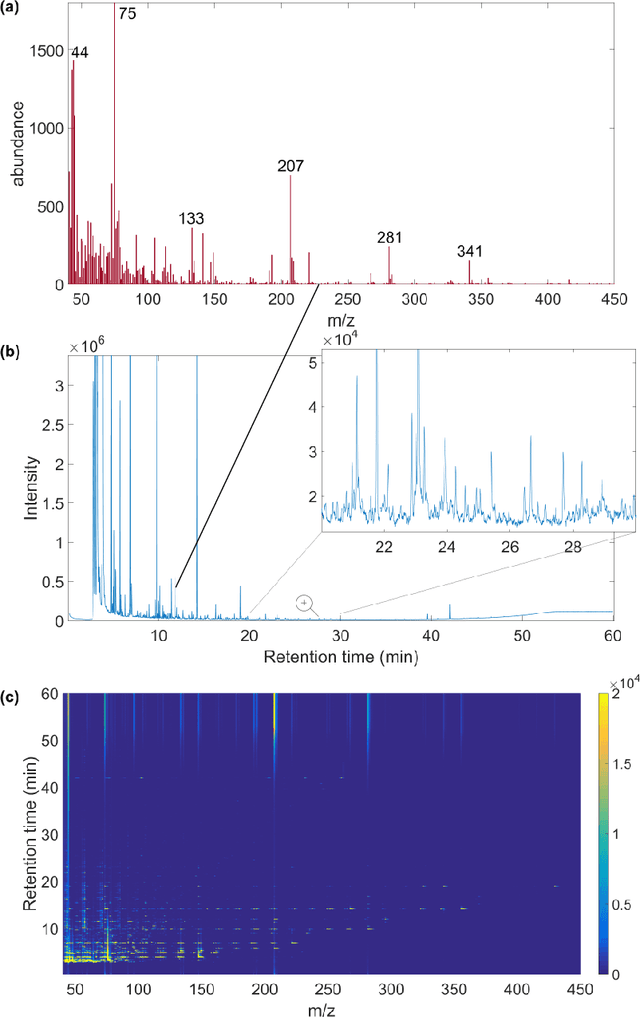

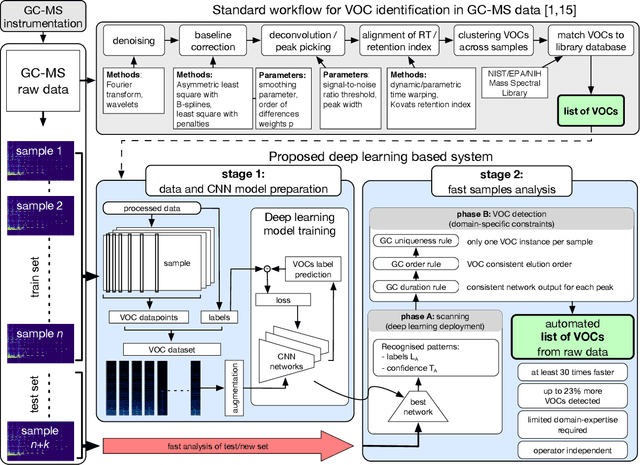
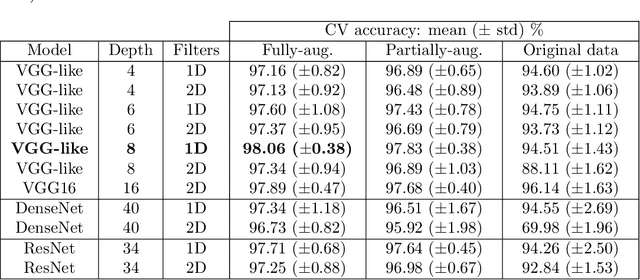
Volatile organic compounds (VOCs) in human breath can reveal a large spectrum of health conditions and can be used for fast, accurate and non-invasive diagnostics. Gas chromatography-mass spectrometry (GC-MS) is used to measure VOCs, but its application is limited by expert-driven data analysis that is time-consuming, subjective and may introduce errors. We propose a system to perform GC-MS data analysis that exploits deep learning pattern recognition ability to learn and automatically detect VOCs directly from raw data, thus bypassing expert-led processing. The new proposed approach showed to outperform the expert-led analysis by detecting a significantly higher number of VOCs in just a fraction of time while maintaining high specificity. These results suggest that the proposed method can help the large-scale deployment of breath-based diagnosis by reducing time and cost, and increasing accuracy and consistency.
Trustworthy AI Inference Systems: An Industry Research View
Aug 10, 2020In this work, we provide an industry research view for approaching the design, deployment, and operation of trustworthy Artificial Intelligence (AI) inference systems. Such systems provide customers with timely, informed, and customized inferences to aid their decision, while at the same time utilizing appropriate security protection mechanisms for AI models. Additionally, such systems should also use Privacy-Enhancing Technologies (PETs) to protect customers' data at any time. To approach the subject, we start by introducing trends in AI inference systems. We continue by elaborating on the relationship between Intellectual Property (IP) and private data protection in such systems. Regarding the protection mechanisms, we survey the security and privacy building blocks instrumental in designing, building, deploying, and operating private AI inference systems. For example, we highlight opportunities and challenges in AI systems using trusted execution environments combined with more recent advances in cryptographic techniques to protect data in use. Finally, we outline areas of further development that require the global collective attention of industry, academia, and government researchers to sustain the operation of trustworthy AI inference systems.
Recovery of Linear Components: Reduced Complexity Autoencoder Designs
Dec 14, 2020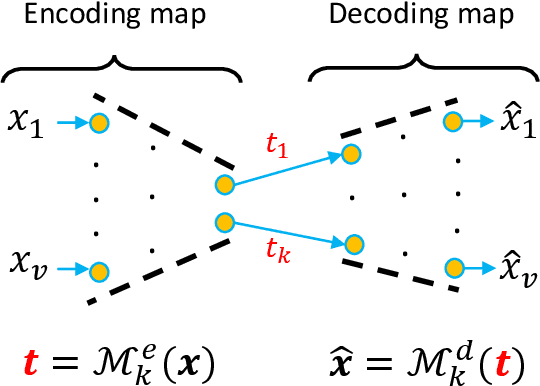
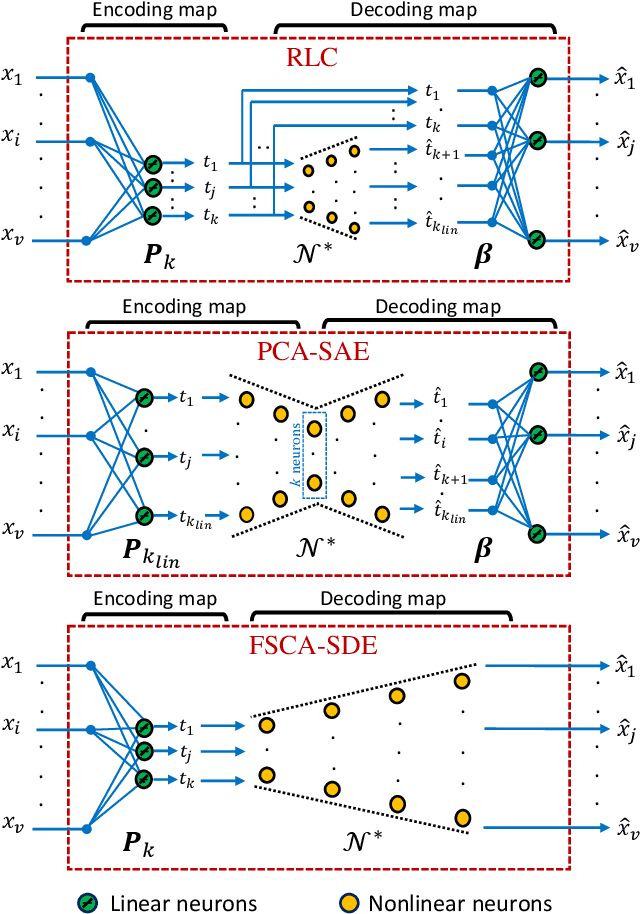
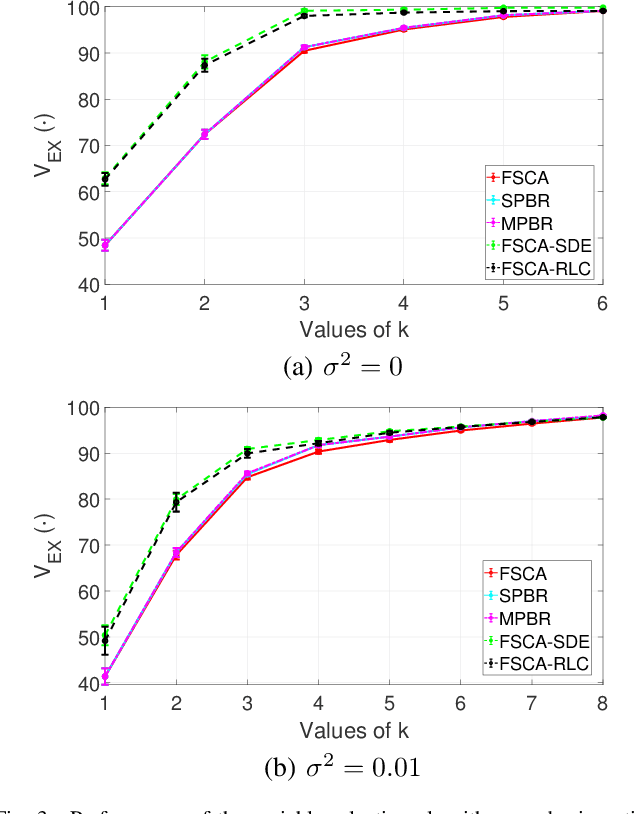
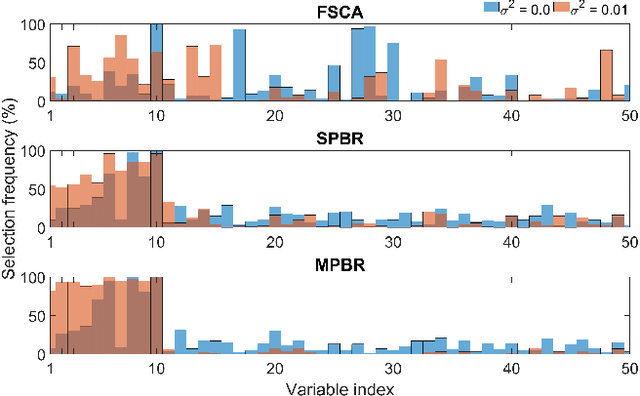
Reducing dimensionality is a key preprocessing step in many data analysis applications to address the negative effects of the curse of dimensionality and collinearity on model performance and computational complexity, to denoise the data or to reduce storage requirements. Moreover, in many applications it is desirable to reduce the input dimensions by choosing a subset of variables that best represents the entire set without any a priori information available. Unsupervised variable selection techniques provide a solution to this second problem. An autoencoder, if properly regularized, can solve both unsupervised dimensionality reduction and variable selection, but the training of large neural networks can be prohibitive in time sensitive applications. We present an approach called Recovery of Linear Components (RLC), which serves as a middle ground between linear and non-linear dimensionality reduction techniques, reducing autoencoder training times while enhancing performance over purely linear techniques. With the aid of synthetic and real world case studies, we show that the RLC, when compared with an autoencoder of similar complexity, shows higher accuracy, similar robustness to overfitting, and faster training times. Additionally, at the cost of a relatively small increase in computational complexity, RLC is shown to outperform the current state-of-the-art for a semiconductor manufacturing wafer measurement site optimization application.
Early Detection of Thermoacoustic Instabilities in a Cryogenic Rocket Thrust Chamber using Combustion Noise Features and Machine Learning
Nov 25, 2020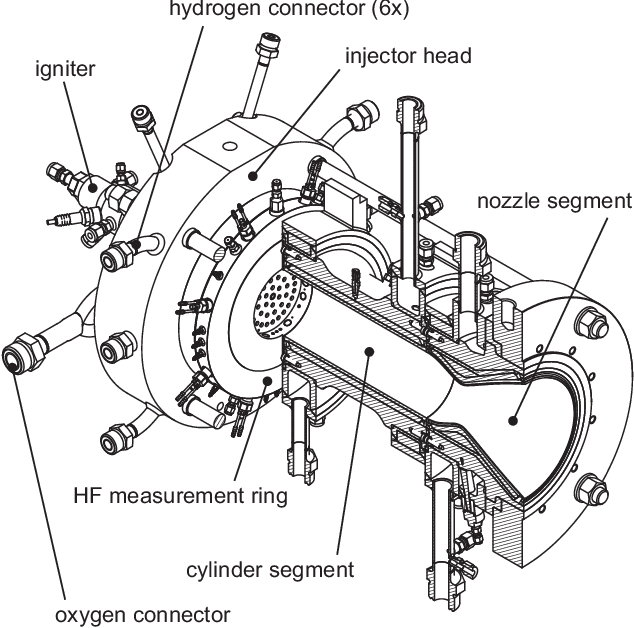
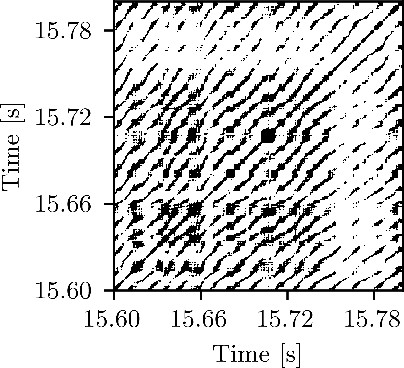
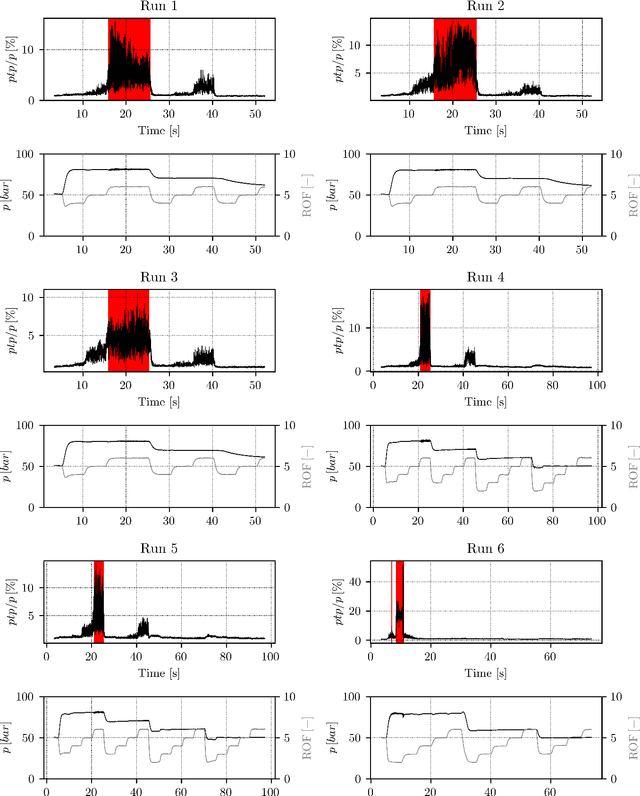
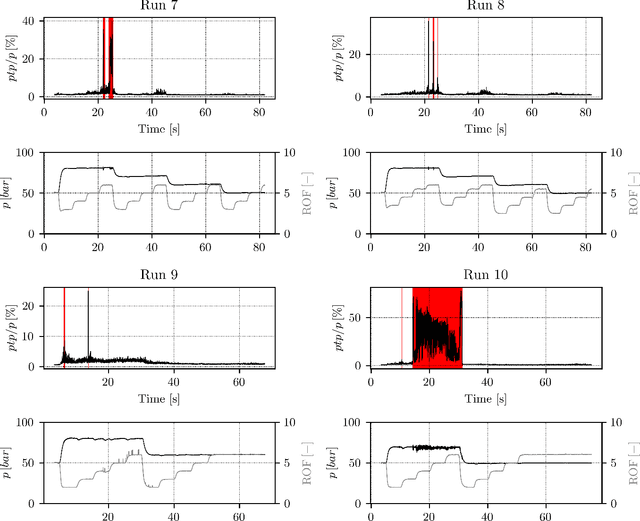
Combustion instabilities are particularly problematic for rocket thrust chambers because of their high energy release rates and their operation close to the structural limits. In the last decades, progress has been made in predicting high amplitude combustion instabilities but still, no reliable prediction ability is given. Reliable early warning signals are the main requirement for active combustion control systems. In this paper, we present a data-driven method for the early detection of thermoacoustic instabilities. Recurrence quantification analysis is used to calculate characteristic combustion features from short-length time series of dynamic pressure sensor data. Features like the recurrence rate are used to train support vector machines to detect the onset of an instability a few hundred milliseconds in advance. The performance of the proposed method is investigated on experimental data from a representative LOX/H$_2$ research thrust chamber. In most cases, the method is able to timely predict two types of thermoacoustic instabilities on test data not used for training. The results are compared with state-of-the-art early warning indicators.
Pushing the Limits of AMR Parsing with Self-Learning
Oct 20, 2020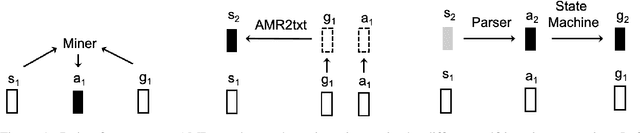

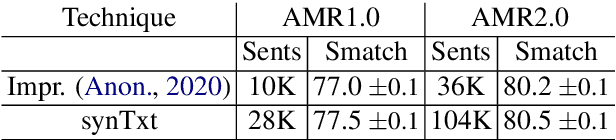
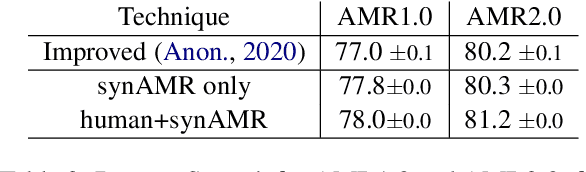
Abstract Meaning Representation (AMR) parsing has experienced a notable growth in performance in the last two years, due both to the impact of transfer learning and the development of novel architectures specific to AMR. At the same time, self-learning techniques have helped push the performance boundaries of other natural language processing applications, such as machine translation or question answering. In this paper, we explore different ways in which trained models can be applied to improve AMR parsing performance, including generation of synthetic text and AMR annotations as well as refinement of actions oracle. We show that, without any additional human annotations, these techniques improve an already performant parser and achieve state-of-the-art results on AMR 1.0 and AMR 2.0.
Adapting to Delays and Data in Adversarial Multi-Armed Bandits
Oct 12, 2020We consider the adversarial multi-armed bandit problem under delayed feedback. We analyze variants of the Exp3 algorithm that tune their step-size using only information (about the losses and delays) available at the time of the decisions, and obtain regret guarantees that adapt to the observed (rather than the worst-case) sequences of delays and/or losses. First, through a remarkably simple proof technique, we show that with proper tuning of the step size, the algorithm achieves an optimal (up to logarithmic factors) regret of order $\sqrt{\log(K)(TK + D)}$ both in expectation and in high probability, where $K$ is the number of arms, $T$ is the time horizon, and $D$ is the cumulative delay. The high-probability version of the bound, which is the first high-probability delay-adaptive bound in the literature, crucially depends on the use of implicit exploration in estimating the losses. Then, following Zimmert and Seldin [2019], we extend these results so that the algorithm can "skip" rounds with large delays, resulting in regret bounds of order $\sqrt{TK\log(K)} + |R| + \sqrt{D_{\bar{R}}\log(K)}$, where $R$ is an arbitrary set of rounds (which are skipped) and $D_{\bar{R}}$ is the cumulative delay of the feedback for other rounds. Finally, we present another, data-adaptive (AdaGrad-style) version of the algorithm for which the regret adapts to the observed (delayed) losses instead of only adapting to the cumulative delay (this algorithm requires an a priori upper bound on the maximum delay, or the advance knowledge of the delay for each decision when it is made). The resulting bound can be orders of magnitude smaller on benign problems, and it can be shown that the delay only affects the regret through the loss of the best arm.
Analysis of the Performance of Algorithm Configurators for Search Heuristics with Global Mutation Operators
Apr 09, 2020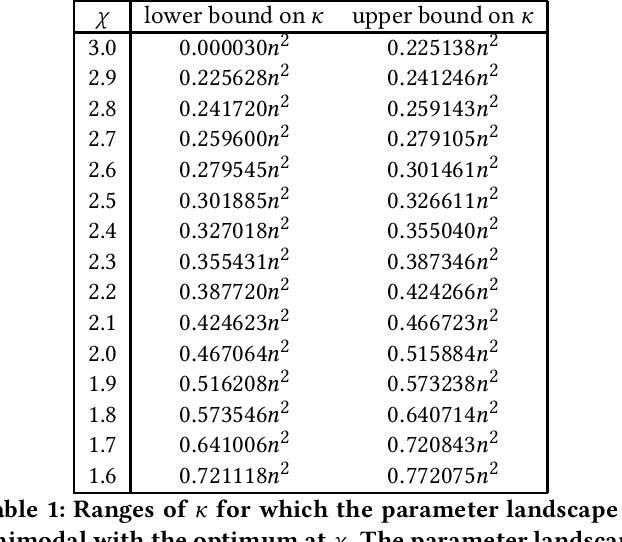

Recently it has been proved that a simple algorithm configurator called ParamRLS can efficiently identify the optimal neighbourhood size to be used by stochastic local search to optimise two standard benchmark problem classes. In this paper we analyse the performance of algorithm configurators for tuning the more sophisticated global mutation operator used in standard evolutionary algorithms, which flips each of the $n$ bits independently with probability $\chi/n$ and the best value for $\chi$ has to be identified. We compare the performance of configurators when the best-found fitness values within the cutoff time $\kappa$ are used to compare configurations against the actual optimisation time for two standard benchmark problem classes, Ridge and LeadingOnes. We rigorously prove that all algorithm configurators that use optimisation time as performance metric require cutoff times that are at least as large as the expected optimisation time to identify the optimal configuration. Matters are considerably different if the fitness metric is used. To show this we prove that the simple ParamRLS-F configurator can identify the optimal mutation rates even when using cutoff times that are considerably smaller than the expected optimisation time of the best parameter value for both problem classes.