 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unifying Homophily and Heterophily Network Transformation via Motifs
Dec 21, 2020
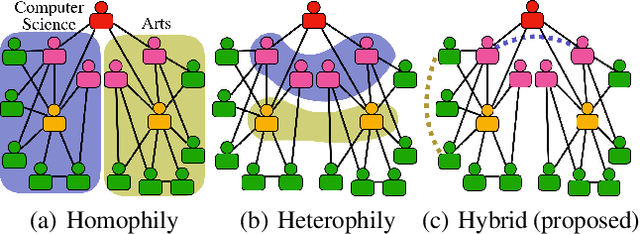

Higher-order proximity (HOP) is fundamental for most network embedding methods due to its significant effects on the quality of node embedding and performance on downstream network analysis tasks. Most existing HOP definitions are based on either homophily to place close and highly interconnected nodes tightly in embedding space or heterophily to place distant but structurally similar nodes together after embedding. In real-world networks, both can co-exist, and thus considering only one could limit the prediction performance and interpretability. However, there is no general and universal solution that takes both into consideration. In this paper, we propose such a simple yet powerful framework called homophily and heterophliy preserving network transformation (H2NT) to capture HOP that flexibly unifies homophily and heterophily. Specifically, H2NT utilises motif representations to transform a network into a new network with a hybrid assumption via micro-level and macro-level walk paths. H2NT can be used as an enhancer to be integrated with any existing network embedding methods without requiring any changes to latter methods. Because H2NT can sparsify networks with motif structures, it can also improve the computational efficiency of existing network embedding methods when integrated. We conduct experiments on node classification, structural role classification and motif prediction to show the superior prediction performance and computational efficiency over state-of-the-art methods. In particular, DeepWalk-based H2 NT achieves 24% improvement in terms of precision on motif prediction, while reducing 46% computational time compared to the original DeepWalk.
Anytime MiniBatch: Exploiting Stragglers in Online Distributed Optimization
Jun 10, 2020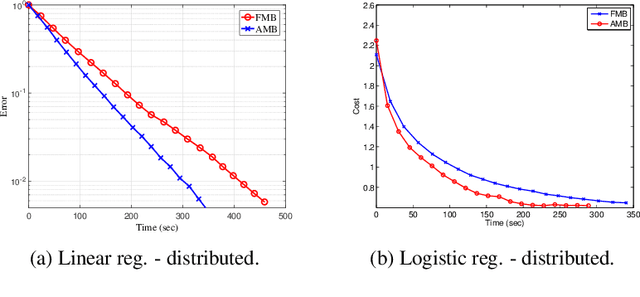
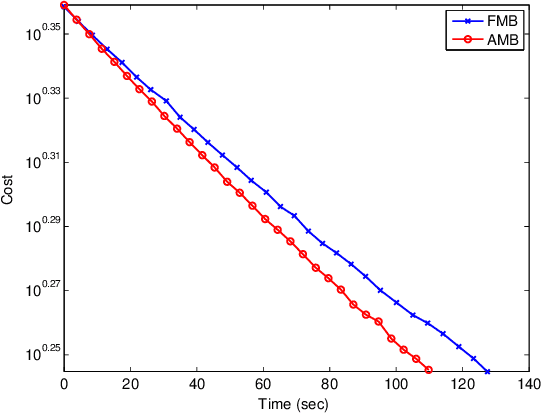
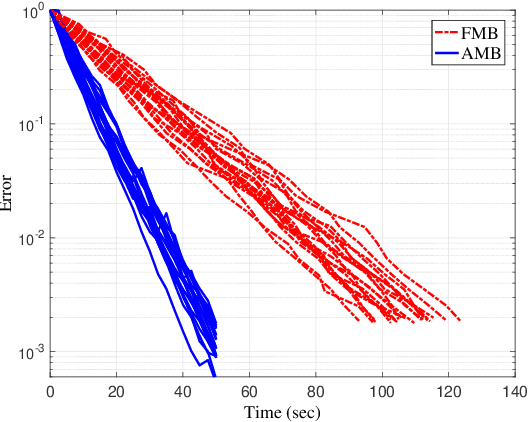
Distributed optimization is vital in solving large-scale machine learning problems. A widely-shared feature of distributed optimization techniques is the requirement that all nodes complete their assigned tasks in each computational epoch before the system can proceed to the next epoch. In such settings, slow nodes, called stragglers, can greatly slow progress. To mitigate the impact of stragglers, we propose an online distributed optimization method called Anytime Minibatch. In this approach, all nodes are given a fixed time to compute the gradients of as many data samples as possible. The result is a variable per-node minibatch size. Workers then get a fixed communication time to average their minibatch gradients via several rounds of consensus, which are then used to update primal variables via dual averaging. Anytime Minibatch prevents stragglers from holding up the system without wasting the work that stragglers can complete. We present a convergence analysis and analyze the wall time performance. Our numerical results show that our approach is up to 1.5 times faster in Amazon EC2 and it is up to five times faster when there is greater variability in compute node performance.
* International Conference on Learning Representations (ICLR), May 2019, New Orleans, LA, USA
Narrative Maps: An Algorithmic Approach to Represent and Extract Information Narratives
Sep 09, 2020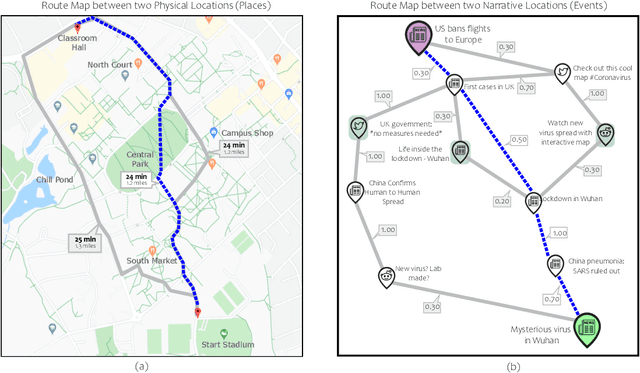
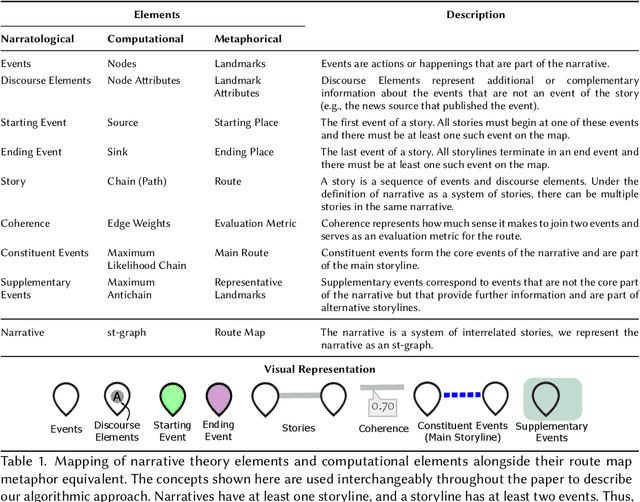
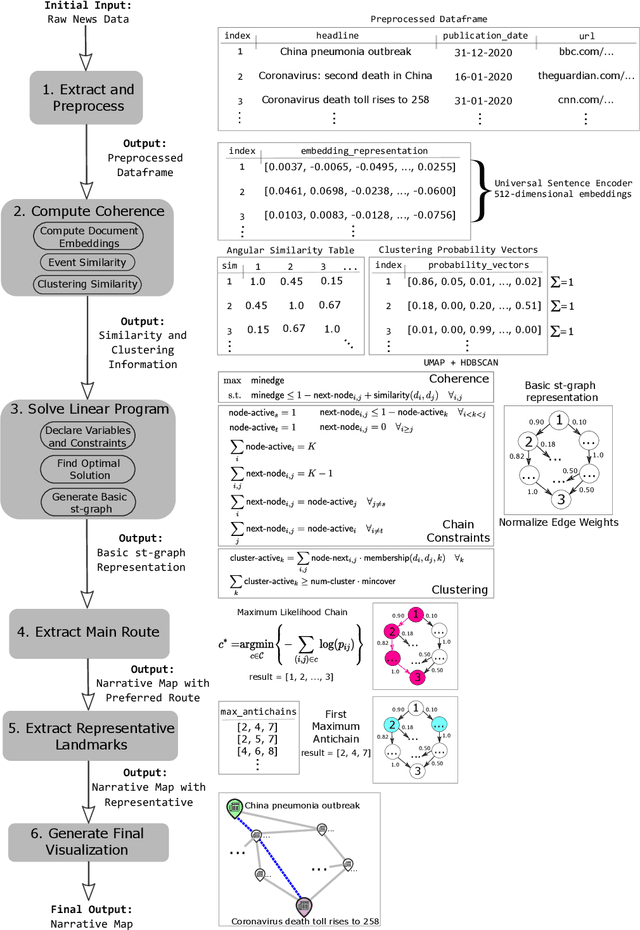
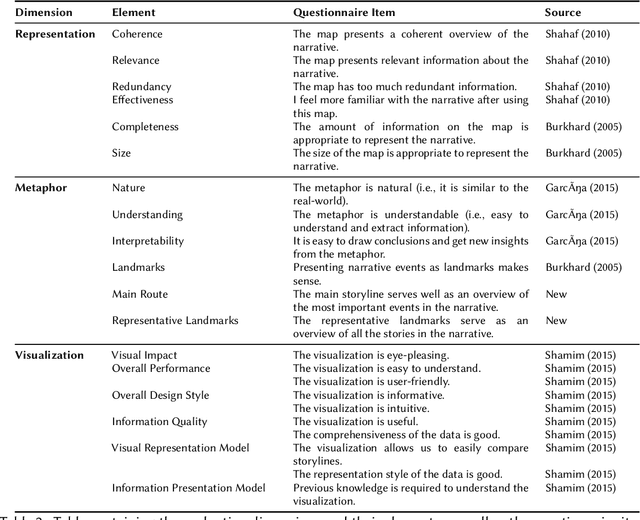
Narratives are fundamental to our perception of the world and are pervasive in all activities that involve the representation of events in time. Yet, modern online information systems do not incorporate narratives in their representation of events occurring over time. This article aims to bridge this gap, combining the theory of narrative representations with the data from modern online systems. We make three key contributions: a theory-driven computational representation of narratives, a novel extraction algorithm to obtain these representations from data, and an evaluation of our approach. In particular, given the effectiveness of visual metaphors, we employ a route map metaphor to design a narrative map representation. The narrative map representation illustrates the events and stories in the narrative as a series of landmarks and routes on the map. Each element of our representation is backed by a corresponding element from formal narrative theory, thus providing a solid theoretical background to our method. Our approach extracts the underlying graph structure of the narrative map using a novel optimization technique focused on maximizing coherence while respecting structural and coverage constraints. We showcase the effectiveness of our approach by performing a user evaluation to assess the quality of the representation, metaphor, and visualization. Evaluation results indicate that the Narrative Map representation is a powerful method to communicate complex narratives to individuals. Our findings have implications for intelligence analysts, computational journalists, and misinformation researchers.
Resilient Identification of Distribution Network Topology
Nov 16, 2020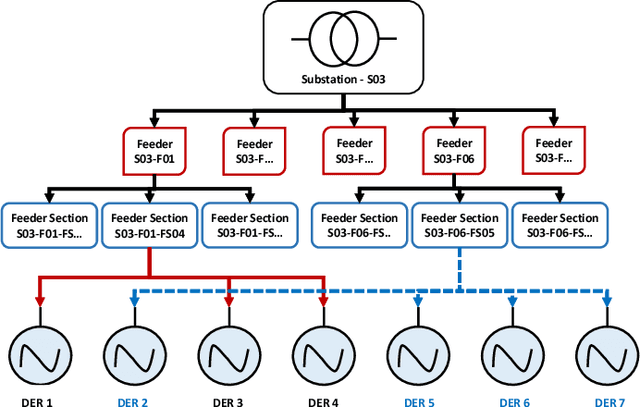
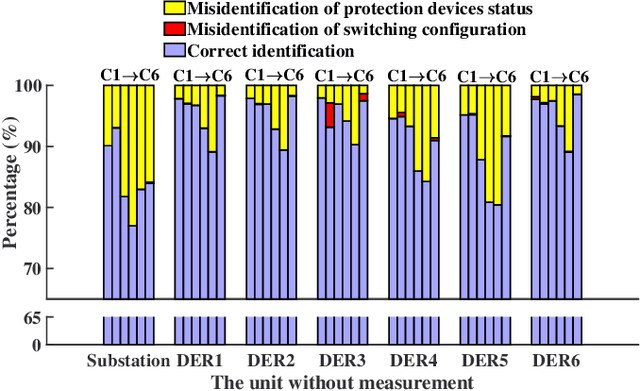
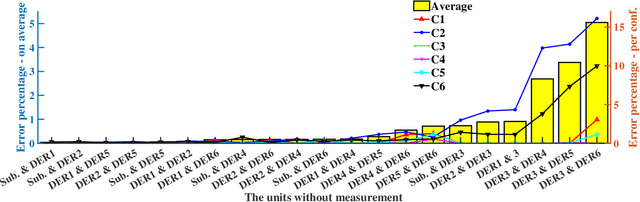
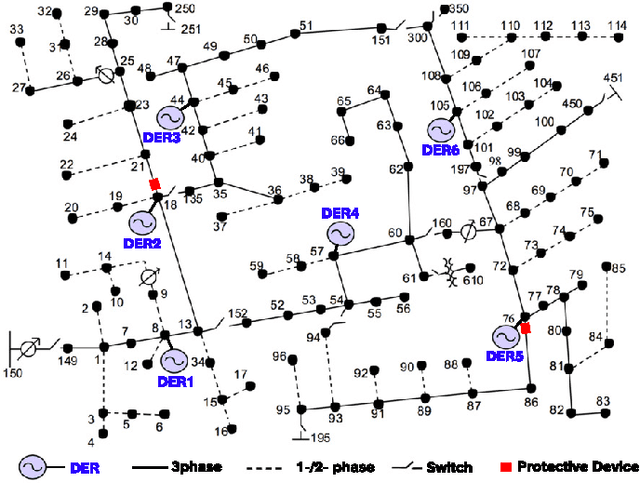
Network topology identification (TI) is an essential function for distributed energy resources management systems (DERMS) to organize and operate widespread distributed energy resources (DERs). In this paper, discriminant analysis (DA) is deployed to develop a network TI function that relies only on the measurements available to DERMS. The propounded method is able to identify the network switching configuration, as well as the status of protective devices. Following, to improve the TI resiliency against the interruption of communication channels, a quadratic programming optimization approach is proposed to recover the missing signals. By deploying the propounded data recovery approach and Bayes' theorem together, a benchmark is developed afterward to identify anomalous measurements. This benchmark can make the TI function resilient against cyber-attacks. Having a low computational burden, this approach is fast-track and can be applied in real-time applications. Sensitivity analysis is performed to assess the contribution of different measurements and the impact of the system load type and loading level on the performance of the proposed approach.
Conflicting Bundles: Adapting Architectures Towards the Improved Training of Deep Neural Networks
Nov 05, 2020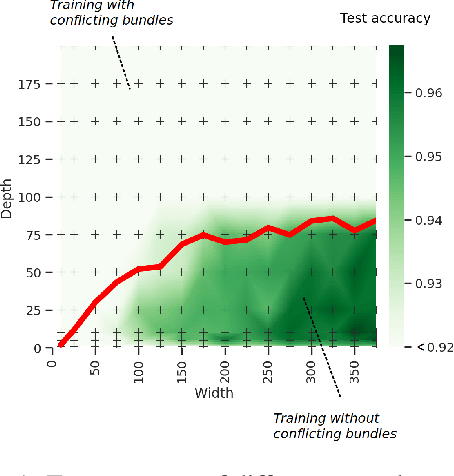
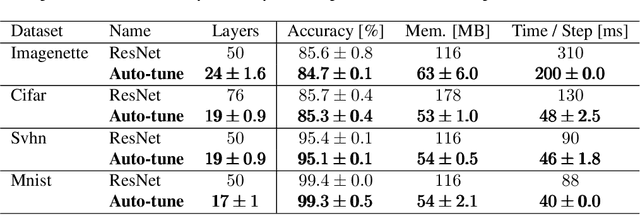
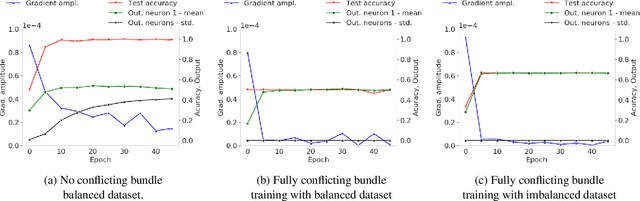
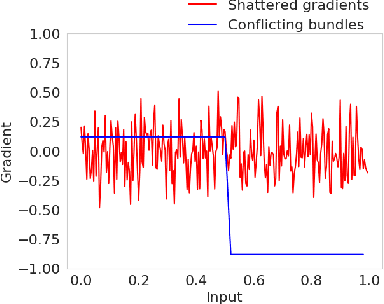
Designing neural network architectures is a challenging task and knowing which specific layers of a model must be adapted to improve the performance is almost a mystery. In this paper, we introduce a novel theory and metric to identify layers that decrease the test accuracy of the trained models, this identification is done as early as at the beginning of training. In the worst-case, such a layer could lead to a network that can not be trained at all. More precisely, we identified those layers that worsen the performance because they produce conflicting training bundles as we show in our novel theoretical analysis, complemented by our extensive empirical studies. Based on these findings, a novel algorithm is introduced to remove performance decreasing layers automatically. Architectures found by this algorithm achieve a competitive accuracy when compared against the state-of-the-art architectures. While keeping such high accuracy, our approach drastically reduces memory consumption and inference time for different computer vision tasks.
Incremental Verification of Fixed-Point Implementations of Neural Networks
Dec 21, 2020
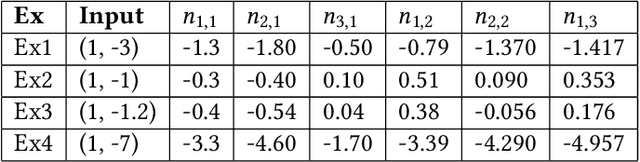
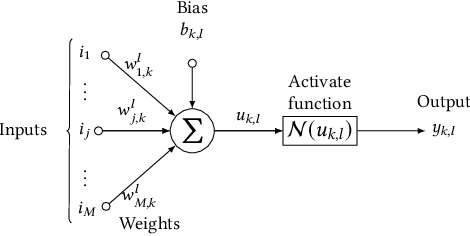
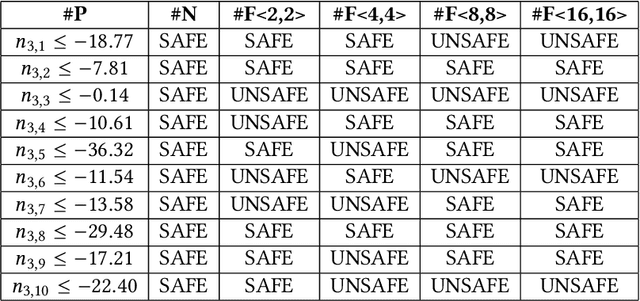
Implementations of artificial neural networks (ANNs) might lead to failures, which are hardly predicted in the design phase since ANNs are highly parallel and their parameters are barely interpretable. Here, we develop and evaluate a novel symbolic verification framework using incremental bounded model checking (BMC), satisfiability modulo theories (SMT), and invariant inference, to obtain adversarial cases and validate coverage methods in a multi-layer perceptron (MLP). We exploit incremental BMC based on interval analysis to compute boundaries from a neuron's input. Then, the latter are propagated to effectively find a neuron's output since it is the input of the next one. This paper describes the first bit-precise symbolic verification framework to reason over actual implementations of ANNs in CUDA, based on invariant inference, therefore providing further guarantees about finite-precision arithmetic and its rounding errors, which are routinely ignored in the existing literature. We have implemented the proposed approach on top of the efficient SMT-based bounded model checker (ESBMC), and its experimental results show that it can successfully verify safety properties, in actual implementations of ANNs, and generate real adversarial cases in MLPs. Our approach was able to verify and produce adversarial examples for 85.8% of 21 test cases considering different input images, and 100% of the properties related to covering methods. Although our verification time is higher than existing approaches, our methodology can consider fixed-point implementation aspects that are disregarded by the state-of-the-art verification methodologies.
Quantum Geometric Machine Learning for Quantum Circuits and Control
Jun 19, 2020
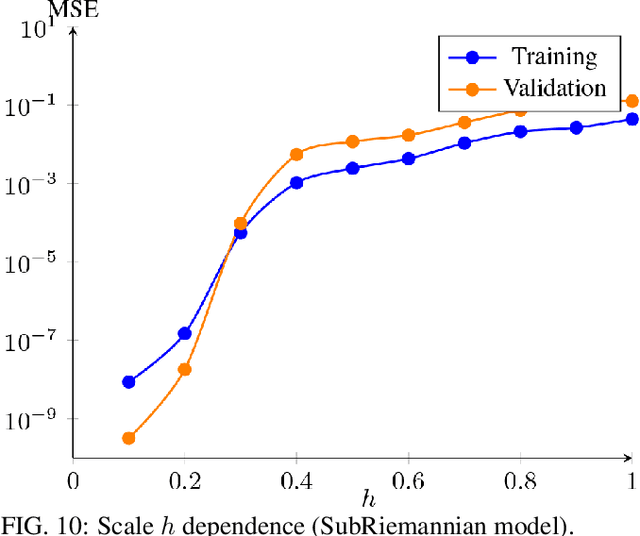
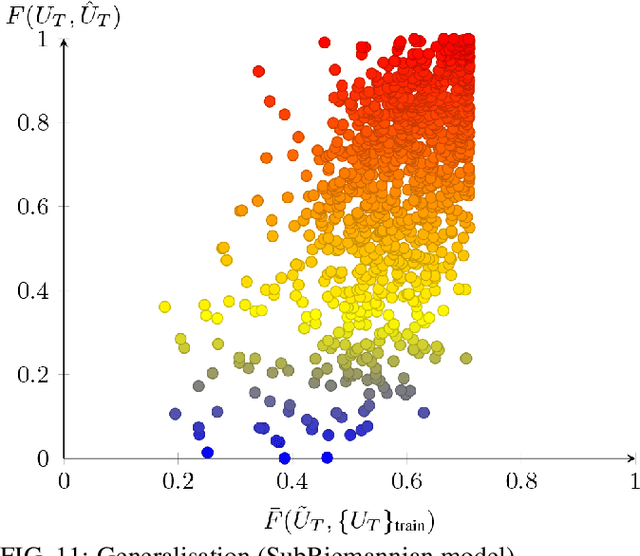
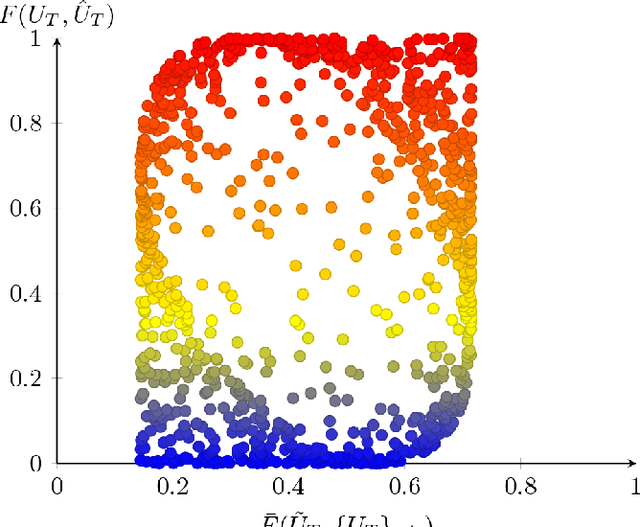
The application of machine learning techniques to solve problems in quantum control together with established geometric methods for solving optimisation problems leads naturally to an exploration of how machine learning approaches can be used to enhance geometric approaches to solving problems in quantum information processing. In this work, we review and extend the application of deep learning to quantum geometric control problems. Specifically, we demonstrate enhancements in time-optimal control in the context of quantum circuit synthesis problems by applying novel deep learning algorithms in order to approximate geodesics (and thus minimal circuits) along Lie group manifolds relevant to low-dimensional multi-qubit systems, such as SU(2), SU(4) and SU(8). We demonstrate the superior performance of greybox models, which combine traditional blackbox algorithms with prior domain knowledge of quantum mechanics, as means of learning underlying quantum circuit distributions of interest. Our results demonstrate how geometric control techniques can be used to both (a) verify the extent to which geometrically synthesised quantum circuits lie along geodesic, and thus time-optimal, routes and (b) synthesise those circuits. Our results are of interest to researchers in quantum control and quantum information theory seeking to combine machine learning and geometric techniques for time-optimal control problems.
Relative Drone -- Ground Vehicle Localization using LiDAR and Fisheye Cameras through Direct and Indirect Observations
Nov 16, 2020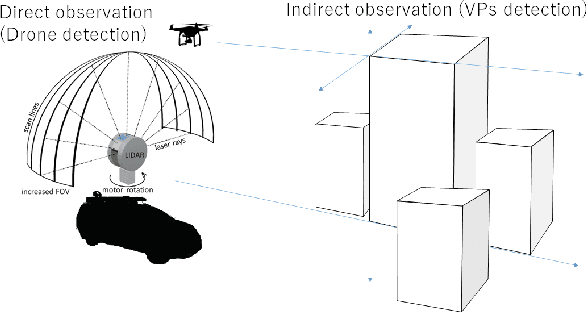
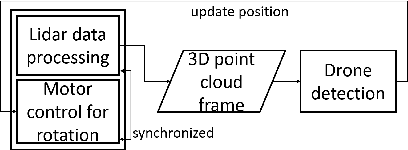
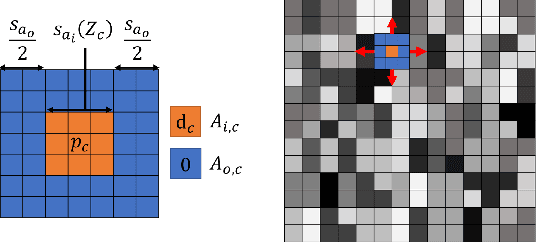
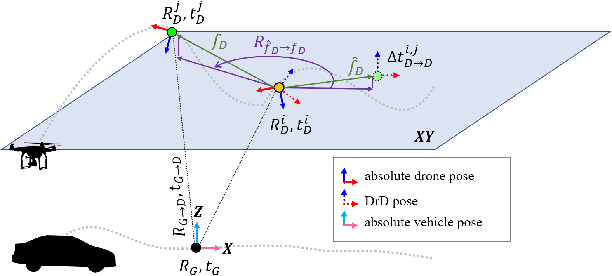
Estimating the pose of an unmanned aerial vehicle (UAV) or drone is a challenging task. It is useful for many applications such as navigation, surveillance, tracking objects on the ground, and 3D reconstruction. In this work, we present a LiDAR-camera-based relative pose estimation method between a drone and a ground vehicle, using a LiDAR sensor and a fisheye camera on the vehicle's roof and another fisheye camera mounted under the drone. The LiDAR sensor directly observes the drone and measures its position, and the two cameras estimate the relative orientation using indirect observation of the surrounding objects. We propose a dynamically adaptive kernel-based method for drone detection and tracking using the LiDAR. We detect vanishing points in both cameras and find their correspondences to estimate the relative orientation. Additionally, we propose a rotation correction technique by relying on the observed motion of the drone through the LiDAR. In our experiments, we were able to achieve very fast initial detection and real-time tracking of the drone. Our method is fully automatic.
A novel policy for pre-trained Deep Reinforcement Learning for Speech Emotion Recognition
Jan 04, 2021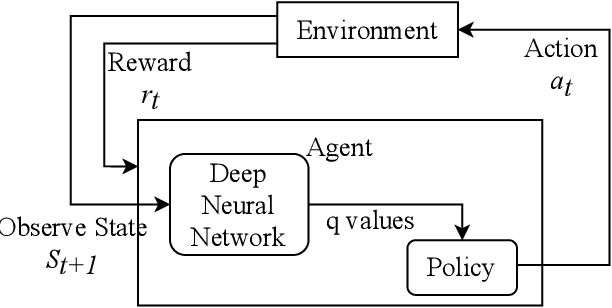


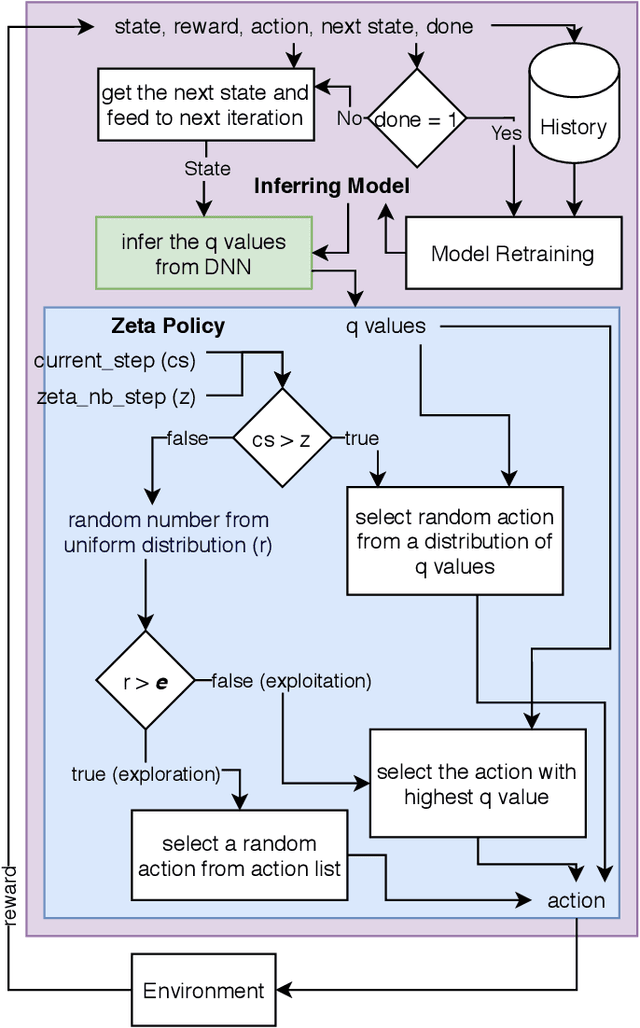
Reinforcement Learning (RL) is a semi-supervised learning paradigm which an agent learns by interacting with an environment. Deep learning in combination with RL provides an efficient method to learn how to interact with the environment is called Deep Reinforcement Learning (deep RL). Deep RL has gained tremendous success in gaming - such as AlphaGo, but its potential have rarely being explored for challenging tasks like Speech Emotion Recognition (SER). The deep RL being used for SER can potentially improve the performance of an automated call centre agent by dynamically learning emotional-aware response to customer queries. While the policy employed by the RL agent plays a major role in action selection, there is no current RL policy tailored for SER. In addition, extended learning period is a general challenge for deep RL which can impact the speed of learning for SER. Therefore, in this paper, we introduce a novel policy - "Zeta policy" which is tailored for SER and apply Pre-training in deep RL to achieve faster learning rate. Pre-training with cross dataset was also studied to discover the feasibility of pre-training the RL Agent with a similar dataset in a scenario of where no real environmental data is not available. IEMOCAP and SAVEE datasets were used for the evaluation with the problem being to recognize four emotions happy, sad, angry and neutral in the utterances provided. Experimental results show that the proposed "Zeta policy" performs better than existing policies. The results also support that pre-training can reduce the training time upon reducing the warm-up period and is robust to cross-corpus scenario.
Activity Recognition with Moving Cameras and Few Training Examples: Applications for Detection of Autism-Related Headbanging
Jan 10, 2021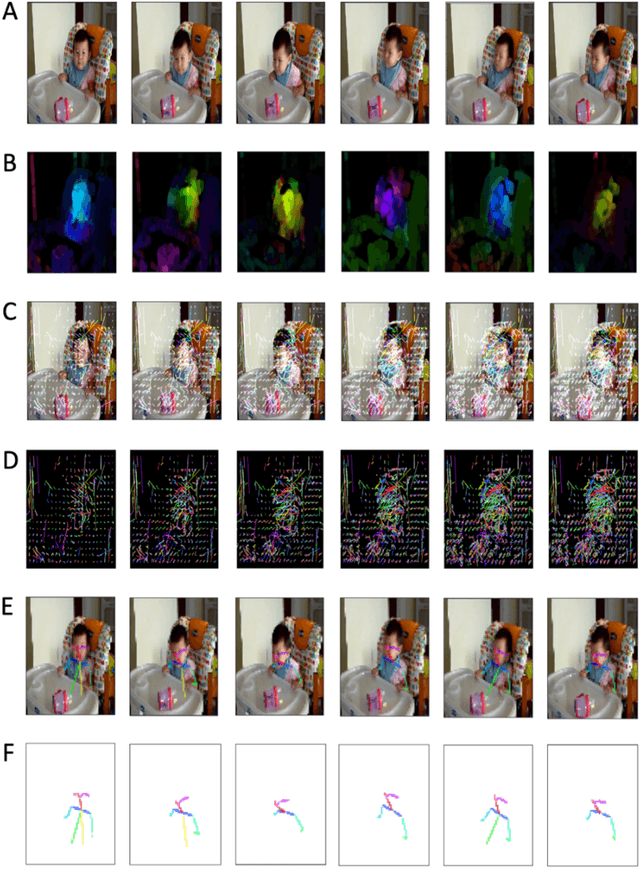

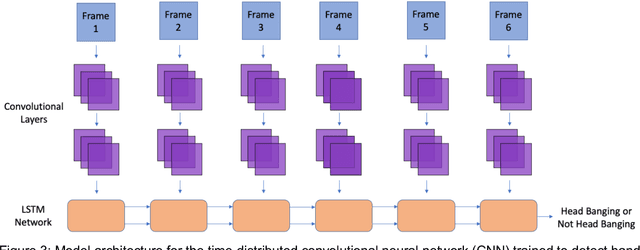
Activity recognition computer vision algorithms can be used to detect the presence of autism-related behaviors, including what are termed "restricted and repetitive behaviors", or stimming, by diagnostic instruments. The limited data that exist in this domain are usually recorded with a handheld camera which can be shaky or even moving, posing a challenge for traditional feature representation approaches for activity detection which mistakenly capture the camera's motion as a feature. To address these issues, we first document the advantages and limitations of current feature representation techniques for activity recognition when applied to head banging detection. We then propose a feature representation consisting exclusively of head pose keypoints. We create a computer vision classifier for detecting head banging in home videos using a time-distributed convolutional neural network (CNN) in which a single CNN extracts features from each frame in the input sequence, and these extracted features are fed as input to a long short-term memory (LSTM) network. On the binary task of predicting head banging and no head banging within videos from the Self Stimulatory Behaviour Dataset (SSBD), we reach a mean F1-score of 90.77% using 3-fold cross validation (with individual fold F1-scores of 83.3%, 89.0%, and 100.0%) when ensuring that no child who appeared in the train set was in the test set for all folds. This work documents a successful technique for training a computer vision classifier which can detect human motion with few training examples and even when the camera recording the source clips is unstable. The general methods described here can be applied by designers and developers of interactive systems towards other human motion and pose classification problems used in mobile and ubiquitous interactive systems.