 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning emergent PDEs in a learned emergent space
Dec 23, 2020
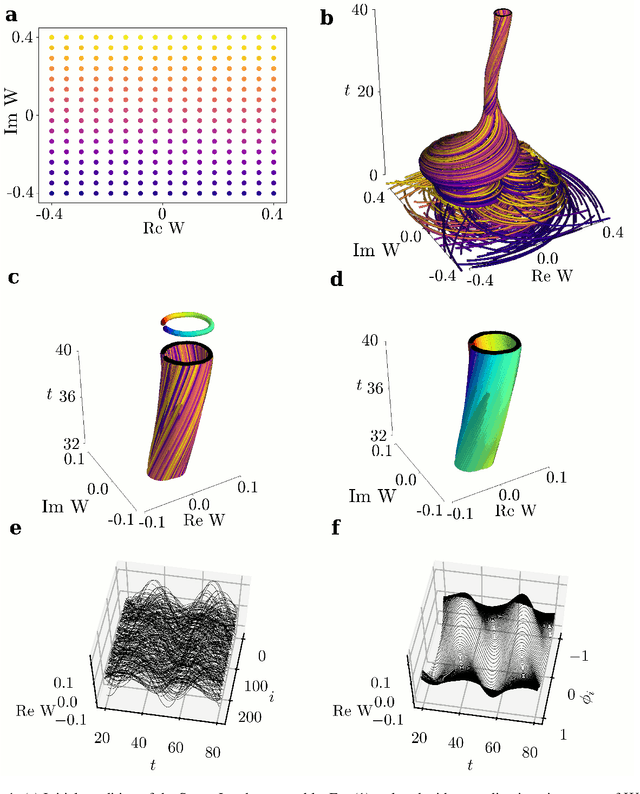
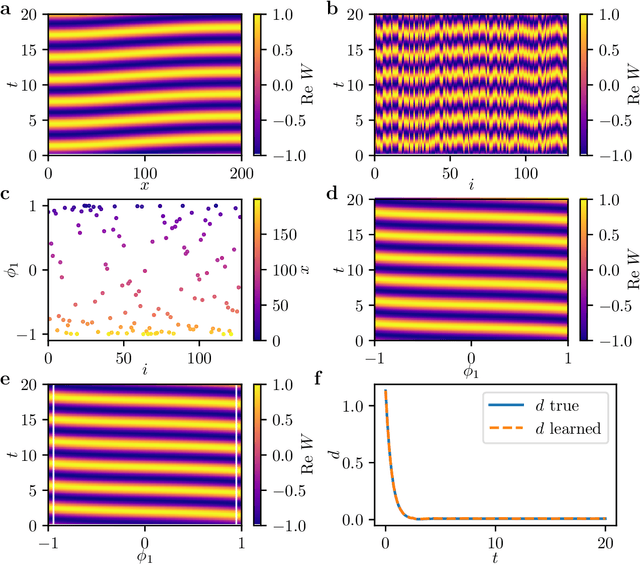
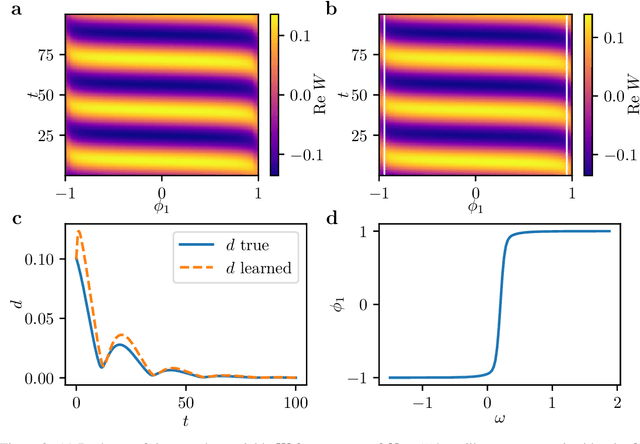
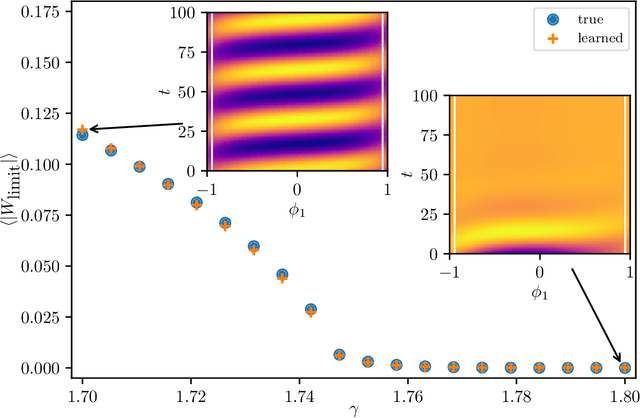
We extract data-driven, intrinsic spatial coordinates from observations of the dynamics of large systems of coupled heterogeneous agents. These coordinates then serve as an emergent space in which to learn predictive models in the form of partial differential equations (PDEs) for the collective description of the coupled-agent system. They play the role of the independent spatial variables in this PDE (as opposed to the dependent, possibly also data-driven, state variables). This leads to an alternative description of the dynamics, local in these emergent coordinates, thus facilitating an alternative modeling path for complex coupled-agent systems. We illustrate this approach on a system where each agent is a limit cycle oscillator (a so-called Stuart-Landau oscillator); the agents are heterogeneous (they each have a different intrinsic frequency $\omega$) and are coupled through the ensemble average of their respective variables. After fast initial transients, we show that the collective dynamics on a slow manifold can be approximated through a learned model based on local "spatial" partial derivatives in the emergent coordinates. The model is then used for prediction in time, as well as to capture collective bifurcations when system parameters vary. The proposed approach thus integrates the automatic, data-driven extraction of emergent space coordinates parametrizing the agent dynamics, with machine-learning assisted identification of an "emergent PDE" description of the dynamics in this parametrization.
Drift anticipation with forgetting to improve evolving fuzzy system
Jan 07, 2021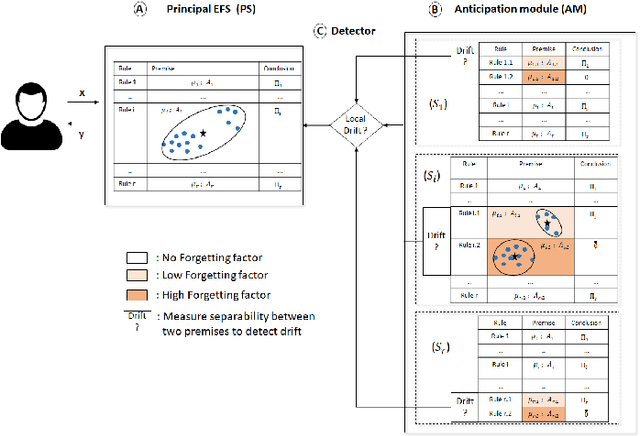
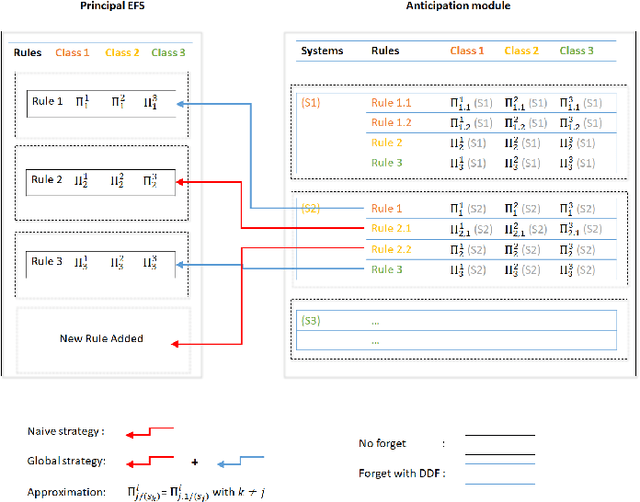
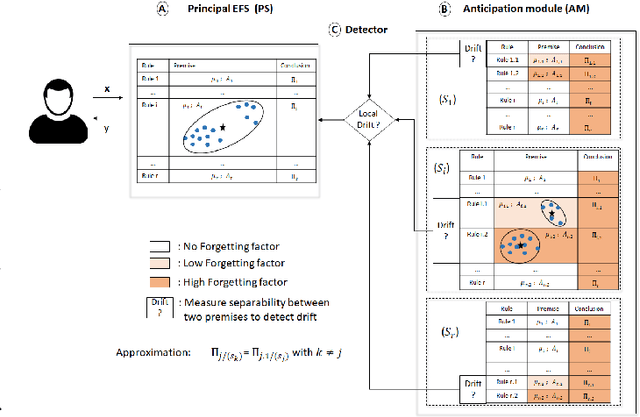
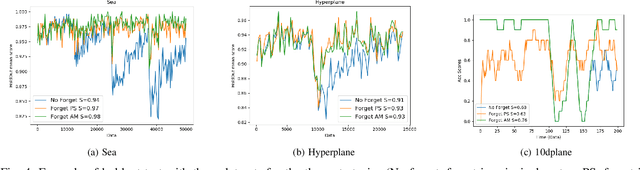
Working with a non-stationary stream of data requires for the analysis system to evolve its model (the parameters as well as the structure) over time. In particular, concept drifts can occur, which makes it necessary to forget knowledge that has become obsolete. However, the forgetting is subjected to the stability-plasticity dilemma, that is, increasing forgetting improve reactivity of adapting to the new data while reducing the robustness of the system. Based on a set of inference rules, Evolving Fuzzy Systems-EFS-have proven to be effective in solving the data stream learning problem. However tackling the stability-plasticity dilemma is still an open question. This paper proposes a coherent method to integrate forgetting in Evolving Fuzzy System, based on the recently introduced notion of concept drift anticipation. The forgetting is applied with two methods: an exponential forgetting of the premise part and a deferred directional forgetting of the conclusion part of EFS to preserve the coherence between both parts. The originality of the approach consists in applying the forgetting only in the anticipation module and in keeping the EFS (called principal system) learned without any forgetting. Then, when a drift is detected in the stream, a selection mechanism is proposed to replace the obsolete parameters of the principal system with more suitable parameters of the anticipation module. An evaluation of the proposed methods is carried out on benchmark online datasets, with a comparison with state-of-the-art online classifiers (Learn++.NSE, PENsemble, pclass) as well as with the original system using different forgetting strategies.
Fighting Copycat Agents in Behavioral Cloning from Observation Histories
Oct 28, 2020



Imitation learning trains policies to map from input observations to the actions that an expert would choose. In this setting, distribution shift frequently exacerbates the effect of misattributing expert actions to nuisance correlates among the observed variables. We observe that a common instance of this causal confusion occurs in partially observed settings when expert actions are strongly correlated over time: the imitator learns to cheat by predicting the expert's previous action, rather than the next action. To combat this "copycat problem", we propose an adversarial approach to learn a feature representation that removes excess information about the previous expert action nuisance correlate, while retaining the information necessary to predict the next action. In our experiments, our approach improves performance significantly across a variety of partially observed imitation learning tasks.
Input Convex Neural Networks for Building MPC
Nov 26, 2020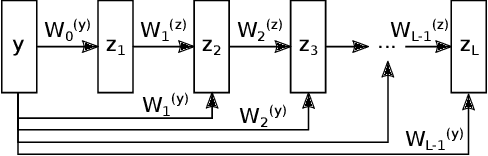
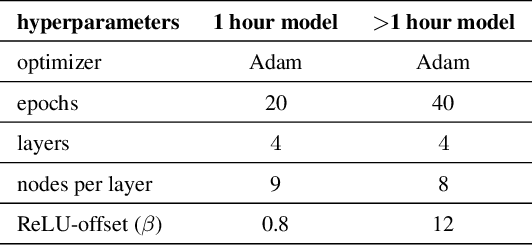
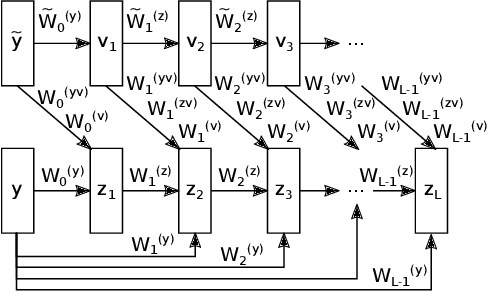
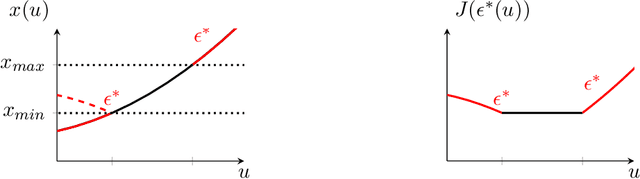
Model Predictive Control in buildings can significantly reduce their energy consumption. The cost and effort necessary for creating and maintaining first principle models for buildings make data-driven modelling an attractive alternative in this domain. In MPC the models form the basis for an optimization problem whose solution provides the control signals to be applied to the system. The fact that this optimization problem has to be solved repeatedly in real-time implies restrictions on the learning architectures that can be used. Here, we adapt Input Convex Neural Networks that are generally only convex for one-step predictions, for use in building MPC. We introduce additional constraints to their structure and weights to achieve a convex input-output relationship for multistep ahead predictions. We assess the consequences of the additional constraints for the model accuracy and test the models in a real-life MPC experiment in an apartment in Switzerland. In two five-day cooling experiments, MPC with Input Convex Neural Networks is able to keep room temperatures within comfort constraints while minimizing cooling energy consumption.
TransTrack: Multiple-Object Tracking with Transformer
Dec 31, 2020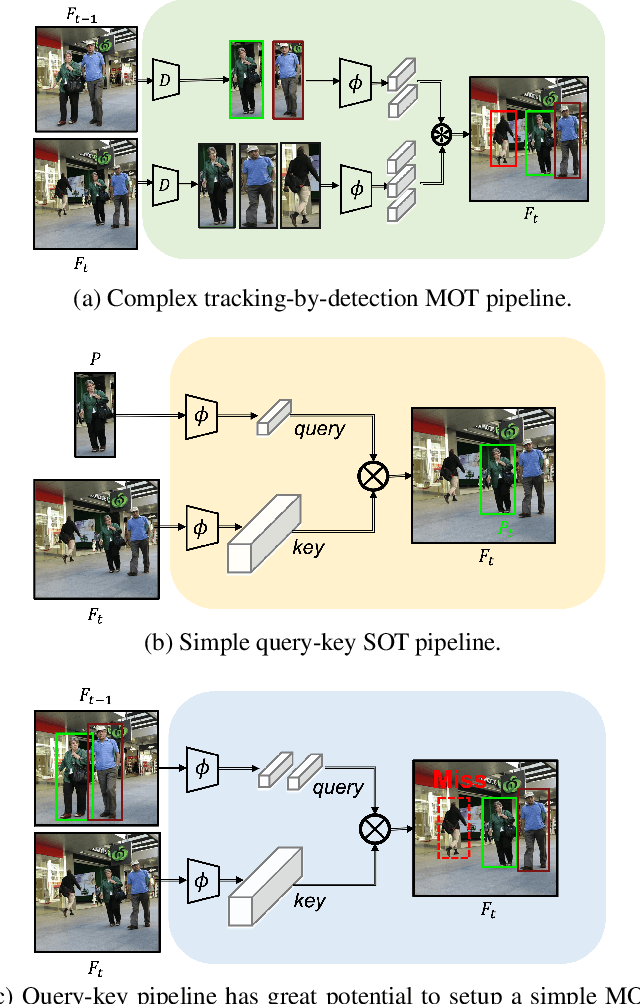

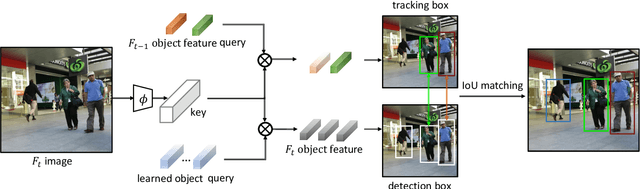
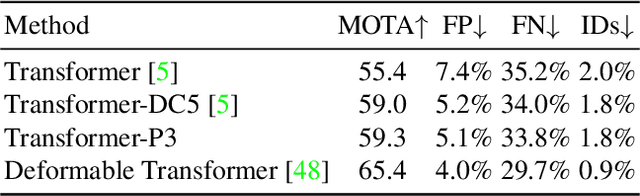
Multiple-object tracking(MOT) is mostly dominated by complex and multi-step tracking-by-detection algorithm, which performs object detection, feature extraction and temporal association, separately. Query-key mechanism in single-object tracking(SOT), which tracks the object of the current frame by object feature of the previous frame, has great potential to set up a simple joint-detection-and-tracking MOT paradigm. Nonetheless, the query-key method is seldom studied due to its inability to detect new-coming objects. In this work, we propose TransTrack, a baseline for MOT with Transformer. It takes advantage of query-key mechanism and introduces a set of learned object queries into the pipeline to enable detecting new-coming objects. TransTrack has three main advantages: (1) It is an online joint-detection-and-tracking pipeline based on query-key mechanism. Complex and multi-step components in the previous methods are simplified. (2) It is a brand new architecture based on Transformer. The learned object query detects objects in the current frame. The object feature query from the previous frame associates those current objects with the previous ones. (3) For the first time, we demonstrate a much simple and effective method based on query-key mechanism and Transformer architecture could achieve competitive 65.8\% MOTA on the MOT17 challenge dataset. We hope TransTrack can provide a new perspective for multiple-object tracking. The code is available at: \url{https://github.com/PeizeSun/TransTrack}.
A Scalable Approach for Privacy-Preserving Collaborative Machine Learning
Nov 03, 2020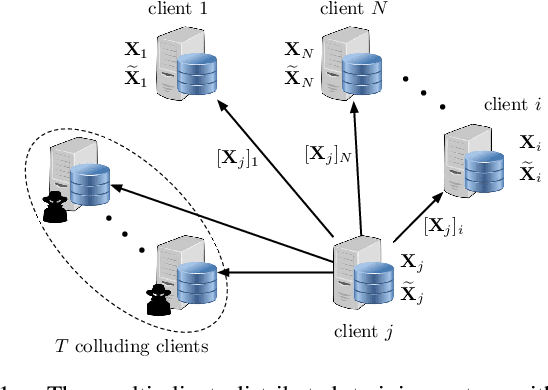

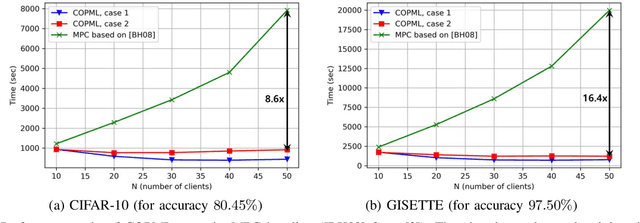
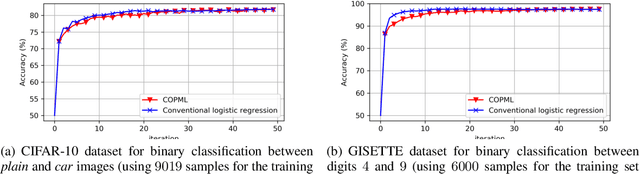
We consider a collaborative learning scenario in which multiple data-owners wish to jointly train a logistic regression model, while keeping their individual datasets private from the other parties. We propose COPML, a fully-decentralized training framework that achieves scalability and privacy-protection simultaneously. The key idea of COPML is to securely encode the individual datasets to distribute the computation load effectively across many parties and to perform the training computations as well as the model updates in a distributed manner on the securely encoded data. We provide the privacy analysis of COPML and prove its convergence. Furthermore, we experimentally demonstrate that COPML can achieve significant speedup in training over the benchmark protocols. Our protocol provides strong statistical privacy guarantees against colluding parties (adversaries) with unbounded computational power, while achieving up to $16\times$ speedup in the training time against the benchmark protocols.
Framework for Passenger Seat Availability Using Face Detection in Passenger Bus
Jul 12, 2020



Advancements in Intelligent Transportation System (IES) improve passenger traveling by providing information systems for bus arrival time and counting the number of passengers and buses in cities. Passengers still face bus waiting and seat unavailability issues which have adverse effects on traffic management and controlling authority. We propose a Face Detection based Framework (FDF) to determine passenger seat availability in a camera-equipped bus through face detection which is based on background subtraction to count empty, filled, and total seats. FDF has an integrated smartphone Passenger Application (PA) to identify the nearest bus stop. We evaluate FDF in a live test environment and results show that it gives 90% accuracy. We believe our results have the potential to address traffic management concerns and assist passengers to save their valuable time
Misinformation Has High Perplexity
Jun 10, 2020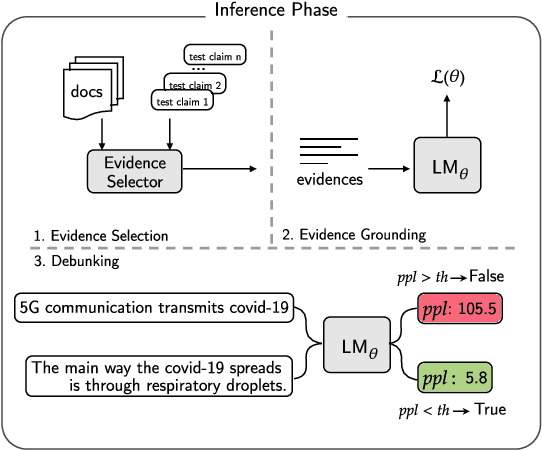


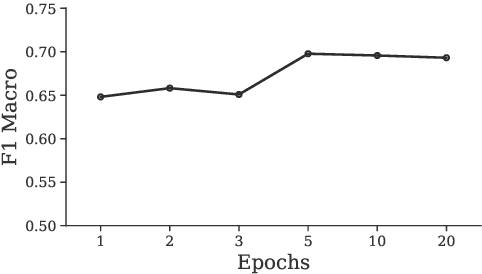
Debunking misinformation is an important and time-critical task as there could be adverse consequences when misinformation is not quashed promptly. However, the usual supervised approach to debunking via misinformation classification requires human-annotated data and is not suited to the fast time-frame of newly emerging events such as the COVID-19 outbreak. In this paper, we postulate that misinformation itself has higher perplexity compared to truthful statements, and propose to leverage the perplexity to debunk false claims in an unsupervised manner. First, we extract reliable evidence from scientific and news sources according to sentence similarity to the claims. Second, we prime a language model with the extracted evidence and finally evaluate the correctness of given claims based on the perplexity scores at debunking time. We construct two new COVID-19-related test sets, one is scientific, and another is political in content, and empirically verify that our system performs favorably compared to existing systems. We are releasing these datasets publicly to encourage more research in debunking misinformation on COVID-19 and other topics.
Incremental Text-to-Speech Synthesis Using Pseudo Lookahead with Large Pretrained Language Model
Dec 23, 2020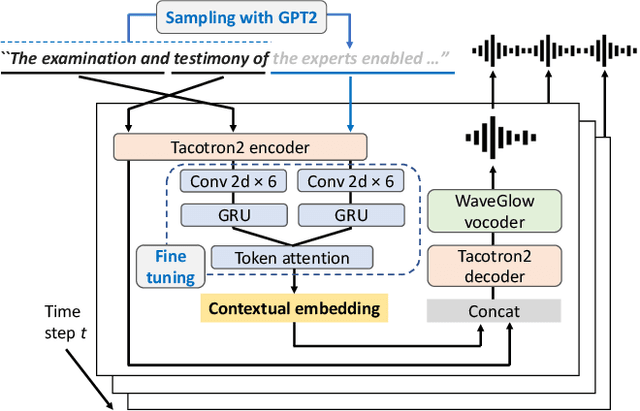
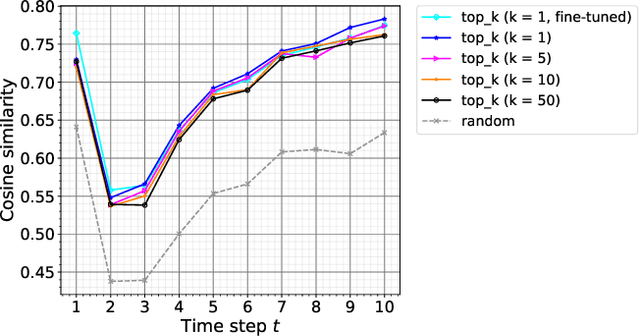
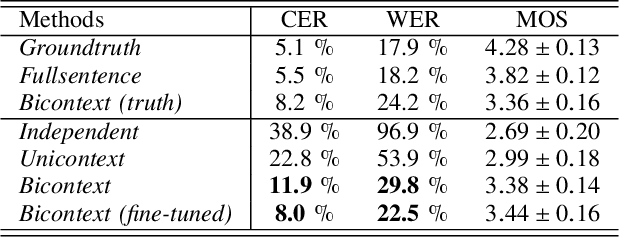
Text-to-speech (TTS) synthesis, a technique for artificially generating human-like utterances from texts, has dramatically evolved with the advances of end-to-end deep neural network-based methods in recent years. The majority of these methods are sentence-level TTS, which can take into account time-series information in the whole sentence. However, it is necessary to establish incremental TTS, which performs synthesis in smaller linguistic units, to realize low-latency synthesis usable for simultaneous speech-to-speech translation systems. In general, incremental TTS is subject to a trade-off between the latency and quality of output speech. It is challenging to produce high-quality speech with a low-latency setup that does not make much use of an unobserved future sentence (hereafter, "lookahead"). This study proposes an incremental TTS method that uses the pseudo lookahead generated with a language model to consider the future contextual information without increasing latency. Our method can be regarded as imitating a human's incremental reading and uses pretrained GPT2, which accounts for the large-scale linguistic knowledge, for the lookahead generation. Evaluation results show that our method 1) achieves higher speech quality without increasing the latency than the method using only observed information and 2) reduces the latency while achieving the equivalent speech quality to waiting for the future context observation.
Numerically Solving Parametric Families of High-Dimensional Kolmogorov Partial Differential Equations via Deep Learning
Nov 09, 2020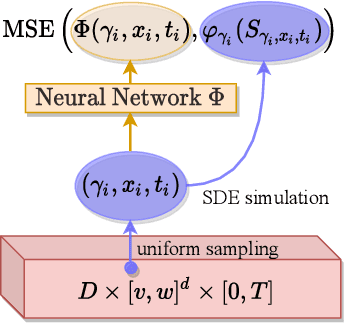
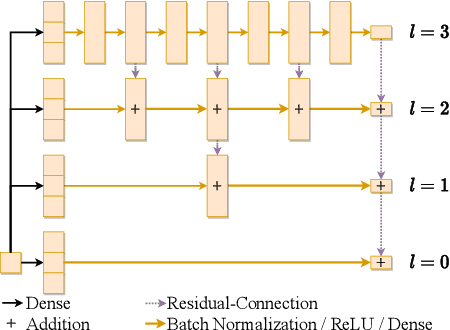
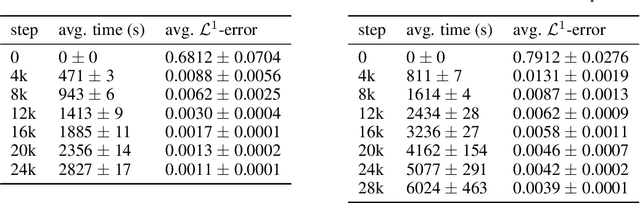
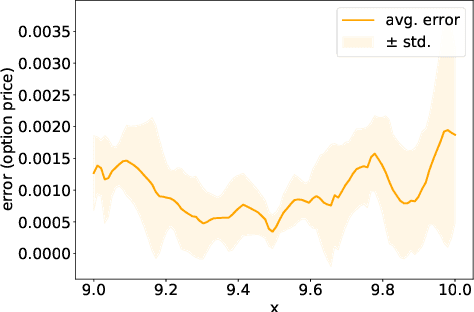
We present a deep learning algorithm for the numerical solution of parametric families of high-dimensional linear Kolmogorov partial differential equations (PDEs). Our method is based on reformulating the numerical approximation of a whole family of Kolmogorov PDEs as a single statistical learning problem using the Feynman-Kac formula. Successful numerical experiments are presented, which empirically confirm the functionality and efficiency of our proposed algorithm in the case of heat equations and Black-Scholes option pricing models parametrized by affine-linear coefficient functions. We show that a single deep neural network trained on simulated data is capable of learning the solution functions of an entire family of PDEs on a full space-time region. Most notably, our numerical observations and theoretical results also demonstrate that the proposed method does not suffer from the curse of dimensionality, distinguishing it from almost all standard numerical methods for PDEs.