 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Enhancing Balanced Graph Edge Partition with Effective Local Search
Dec 17, 2020
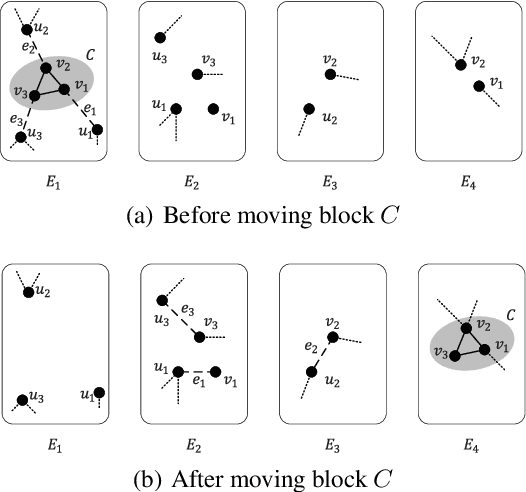
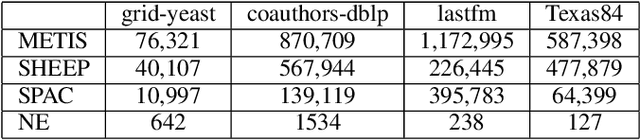
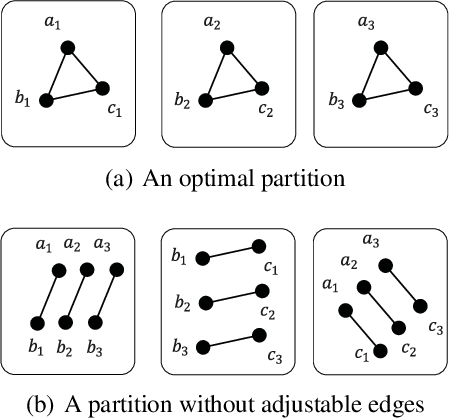
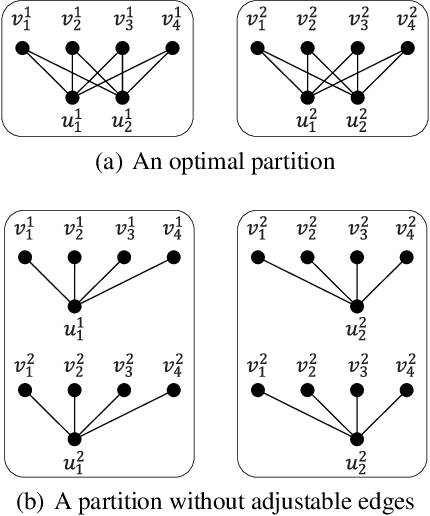
Graph partition is a key component to achieve workload balance and reduce job completion time in parallel graph processing systems. Among the various partition strategies, edge partition has demonstrated more promising performance in power-law graphs than vertex partition and thereby has been more widely adopted as the default partition strategy by existing graph systems. The graph edge partition problem, which is to split the edge set into multiple balanced parts to minimize the total number of copied vertices, has been widely studied from the view of optimization and algorithms. In this paper, we study local search algorithms for this problem to further improve the partition results from existing methods. More specifically, we propose two novel concepts, namely adjustable edges and blocks. Based on these, we develop a greedy heuristic as well as an improved search algorithm utilizing the property of the max-flow model. To evaluate the performance of our algorithms, we first provide adequate theoretical analysis in terms of the approximation quality. We significantly improve the previously known approximation ratio for this problem. Then we conduct extensive experiments on a large number of benchmark datasets and state-of-the-art edge partition strategies. The results show that our proposed local search framework can further improve the quality of graph partition by a wide margin.
GPU Accelerated Convex Approximations for Fast Multi-Agent Trajectory Optimization
Nov 09, 2020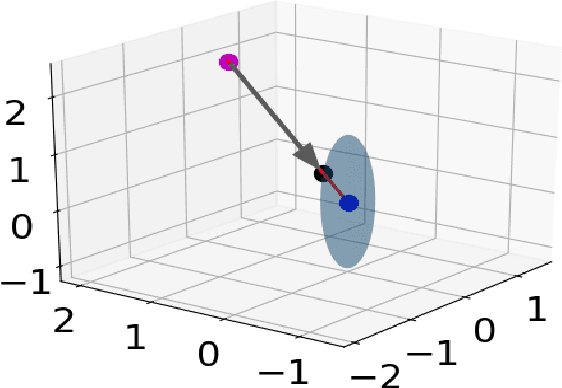
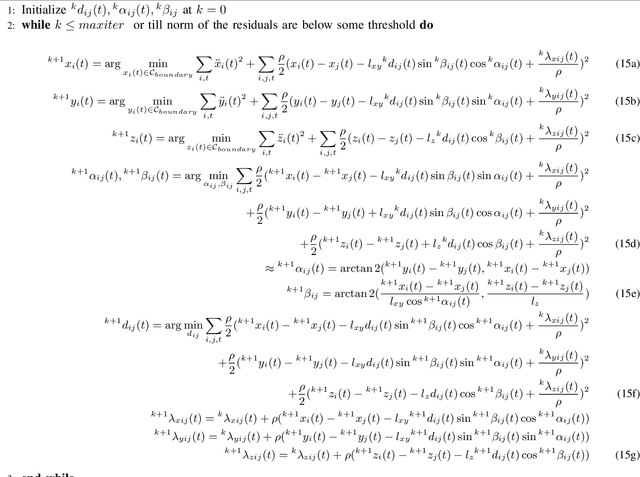
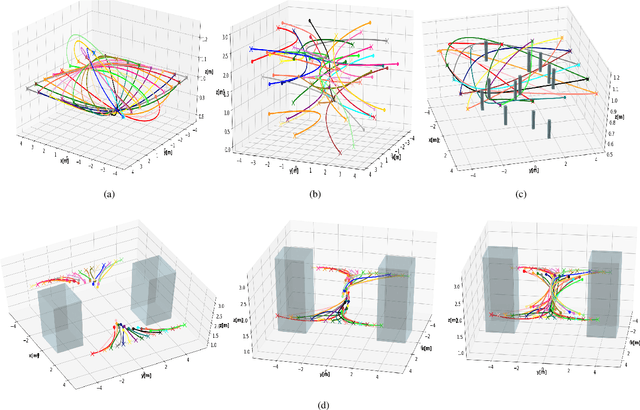
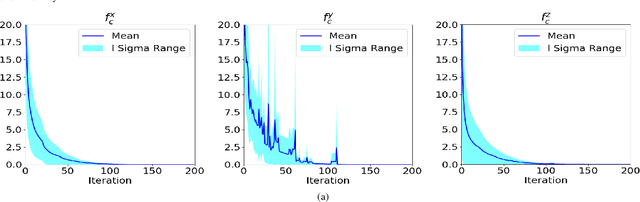
In this paper, we present a computationally efficient trajectory optimizer that can exploit GPUs to jointly compute trajectories of tens of agents in under a second. At the heart of our optimizer is a novel reformulation of the non-convex collision avoidance constraints that reduces the core computation in each iteration to that of solving a large scale, convex, unconstrained Quadratic Program (QP). We also show that the matrix factorization/inverse computation associated with the QP needs to be done only once and can be done offline for a given number of agents. This further simplifies the solution process, effectively reducing it to a problem of evaluating a few matrix-vector products. Moreover, for a large number of agents, this computation can be trivially accelerated on GPUs using existing off-the-shelf libraries. We validate our optimizer's performance on challenging benchmarks and show substantial improvement over state of the art in computation time and trajectory quality.
Prediction of short and long-term droughts using artificial neural networks and hydro-meteorological variables
Jun 03, 2020
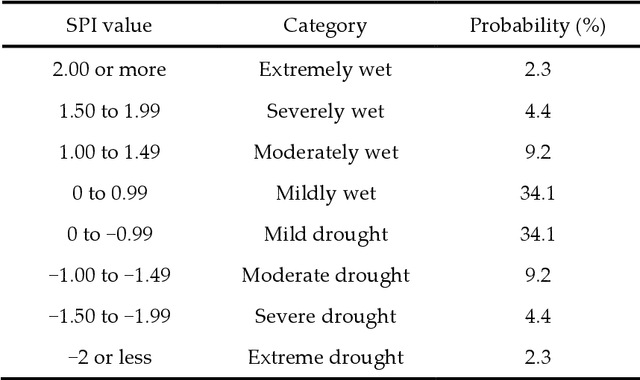
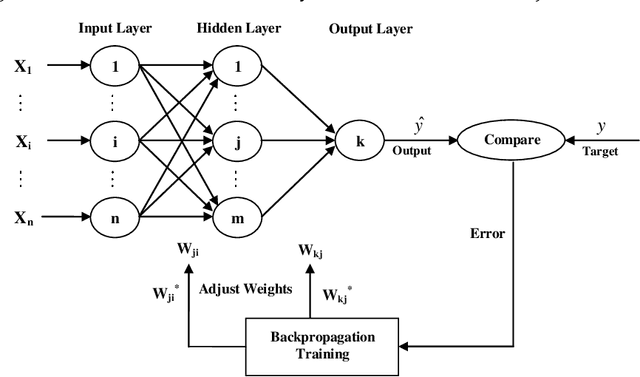
Drought is a natural creeping threat with numerous damaging effects in various aspects of human life. Accurate drought prediction is a promising step in helping policy makers to set drought risk management strategies. To fulfill this purpose, choosing appropriate models plays an important role in predicting approach. In this study, different models of Artificial Neural Network (ANN) are employed to predict short and long-term of droughts by using Standardized Precipitation Index (SPI) at different time scales, including 3, 6, 12, 24 and 48 months in Tabriz city, Iran. To this end, different combination of calculated SPI and time series of various hydro-meteorological variables, such as precipitation, wind velocity, relative humidity and sunshine hours for years 1992 to 2010 are used to train the ANN models. In order to compare the models performances, some well-known measures, namely RMSE, Mean Absolute Error (MAE) and Correlation Coefficient (CC) are utilized in the present study. The results illustrate that the application of all hydro-meteorological variables significantly improves the prediction of SPI at different time scales.
TeslaMirror: Multistimulus Encounter-Type Haptic Display for Shape and Texture Rendering in VR
Jul 05, 2020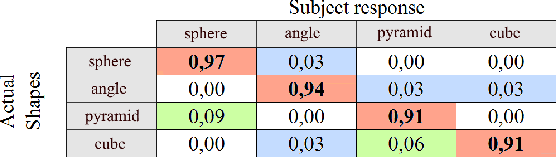


This paper proposes a novel concept of a hybrid tactile display with multistimulus feedback, allowing the real-time experience of the position, shape, and texture of the virtual object. The key technology of the TeslaMirror is that we can deliver the sensation of object parameters (pressure, vibration, and electrotactile feedback) without any wearable haptic devices. We developed the full digital twin of the 6 DOF UR robot in the virtual reality (VR) environment, allowing the adaptive surface simulation and control of the hybrid display in real-time. The preliminary user study was conducted to evaluate the ability of TeslaMirror to reproduce shape sensations with the under-actuated end-effector. The results revealed that potentially this approach can be used in the virtual systems for rendering versatile VR shapes with high fidelity haptic experience.
Incremental Real-Time Multibody VSLAM with Trajectory Optimization Using Stereo Camera
Aug 02, 2016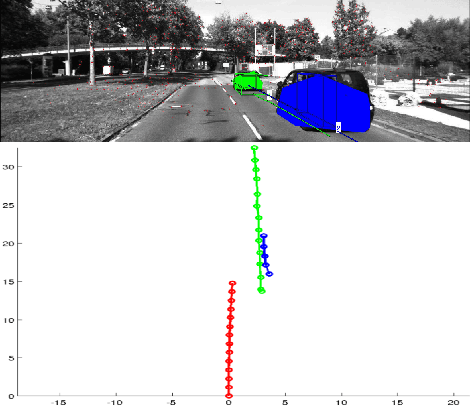
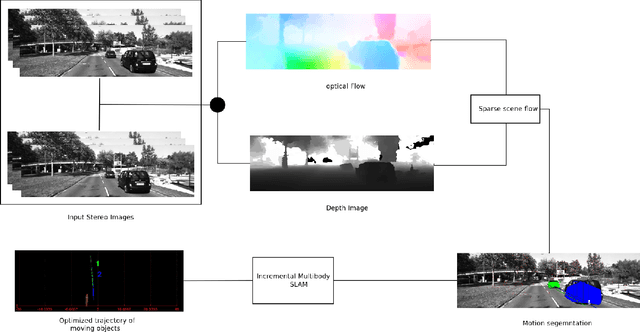
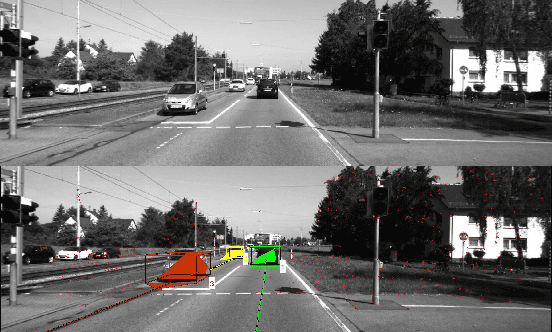
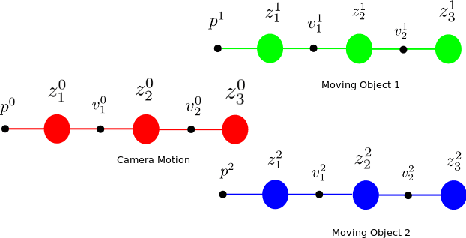
Real time outdoor navigation in highly dynamic environments is an crucial problem. The recent literature on real time static SLAM don't scale up to dynamic outdoor environments. Most of these methods assume moving objects as outliers or discard the information provided by them. We propose an algorithm to jointly infer the camera trajectory and the moving object trajectory simultaneously. In this paper, we perform a sparse scene flow based motion segmentation using a stereo camera. The segmented objects motion models are used for accurate localization of the camera trajectory as well as the moving objects. We exploit the relationship between moving objects for improving the accuracy of the poses. We formulate the poses as a factor graph incorporating all the constraints. We achieve exact incremental solution by solving a full nonlinear optimization problem in real time. The evaluation is performed on the challenging KITTI dataset with multiple moving cars.Our method outperforms the previous baselines in outdoor navigation.
Precomputed Real-Time Texture Synthesis with Markovian Generative Adversarial Networks
Apr 15, 2016
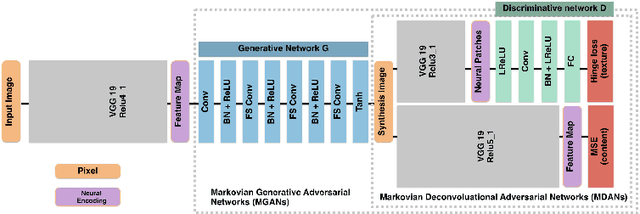


This paper proposes Markovian Generative Adversarial Networks (MGANs), a method for training generative neural networks for efficient texture synthesis. While deep neural network approaches have recently demonstrated remarkable results in terms of synthesis quality, they still come at considerable computational costs (minutes of run-time for low-res images). Our paper addresses this efficiency issue. Instead of a numerical deconvolution in previous work, we precompute a feed-forward, strided convolutional network that captures the feature statistics of Markovian patches and is able to directly generate outputs of arbitrary dimensions. Such network can directly decode brown noise to realistic texture, or photos to artistic paintings. With adversarial training, we obtain quality comparable to recent neural texture synthesis methods. As no optimization is required any longer at generation time, our run-time performance (0.25M pixel images at 25Hz) surpasses previous neural texture synthesizers by a significant margin (at least 500 times faster). We apply this idea to texture synthesis, style transfer, and video stylization.
Efficient Balanced Treatment Assignments for Experimentation
Oct 21, 2020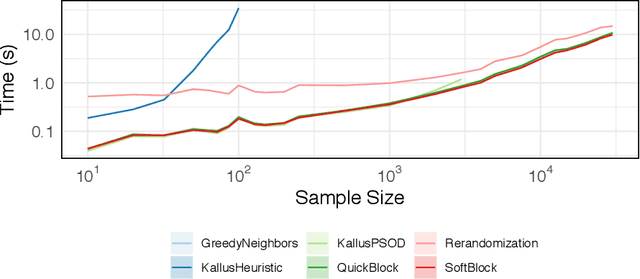
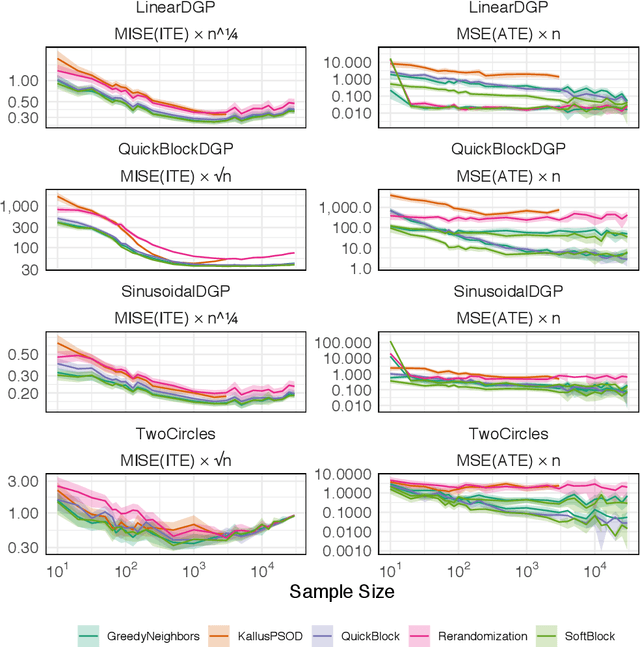
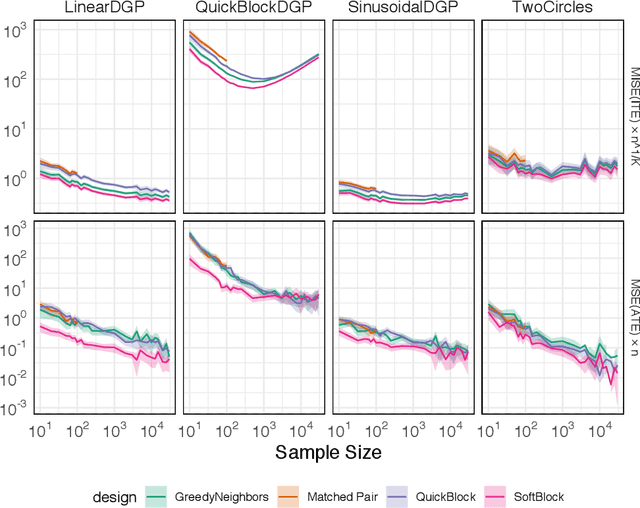
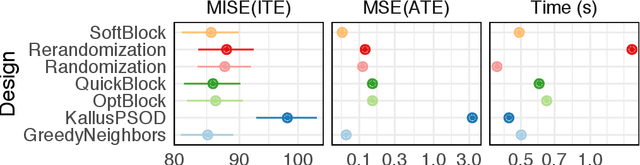
In this work, we reframe the problem of balanced treatment assignment as optimization of a two-sample test between test and control units. Using this lens we provide an assignment algorithm that is optimal with respect to the minimum spanning tree test of Friedman and Rafsky (1979). This assignment to treatment groups may be performed exactly in polynomial time. We provide a probabilistic interpretation of this process in terms of the most probable element of designs drawn from a determinantal point process which admits a probabilistic interpretation of the design. We provide a novel formulation of estimation as transductive inference and show how the tree structures used in design can also be used in an adjustment estimator. We conclude with a simulation study demonstrating the improved efficacy of our method.
Semi-Global Shape-aware Network
Dec 17, 2020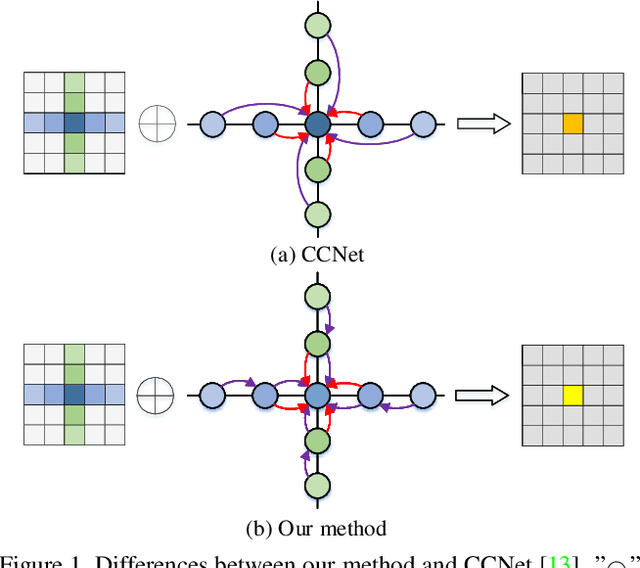

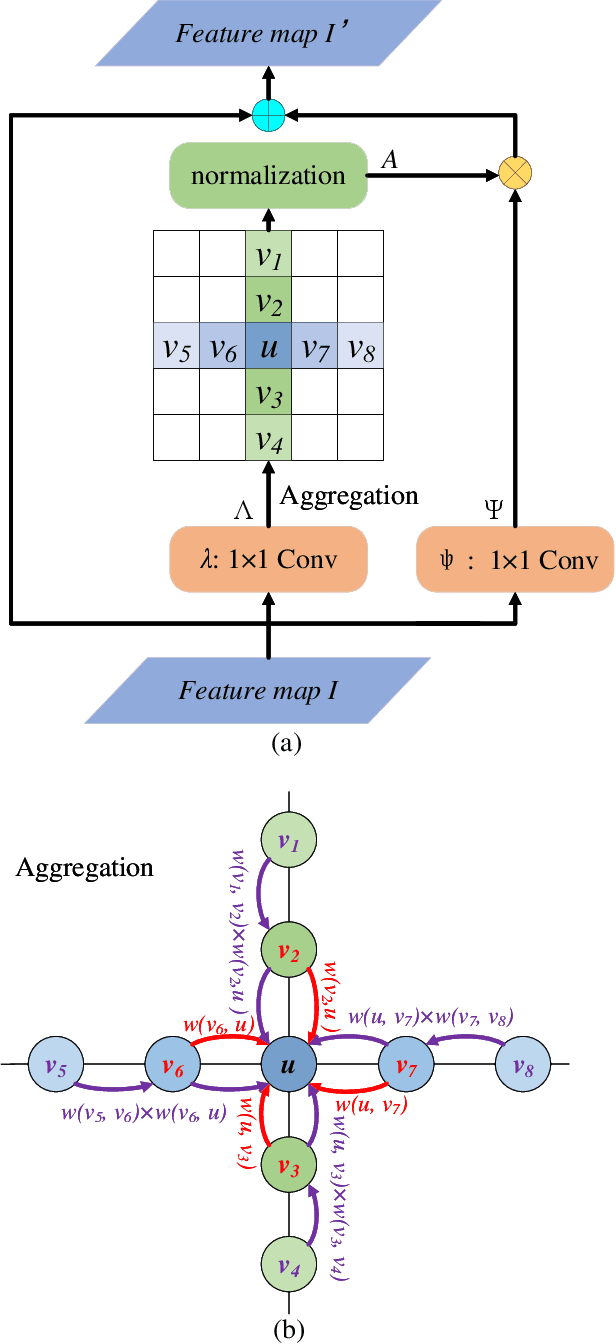
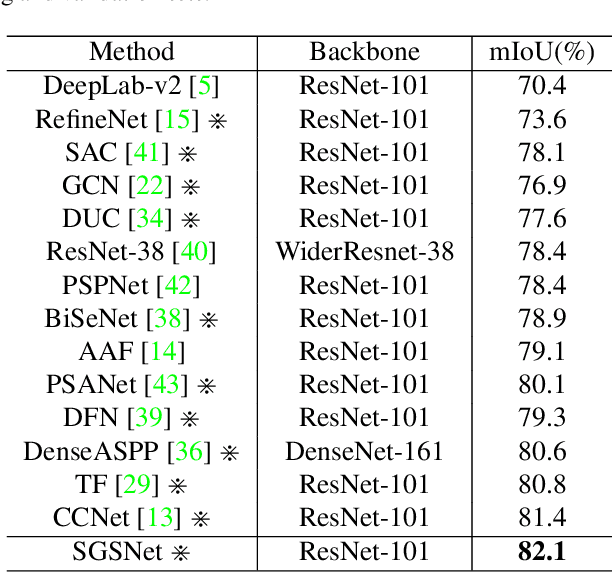
Non-local operations are usually used to capture long-range dependencies via aggregating global context to each position recently. However, most of the methods cannot preserve object shapes since they only focus on feature similarity but ignore proximity between central and other positions for capturing long-range dependencies, while shape-awareness is beneficial to many computer vision tasks. In this paper, we propose a Semi-Global Shape-aware Network (SGSNet) considering both feature similarity and proximity for preserving object shapes when modeling long-range dependencies. A hierarchical way is taken to aggregate global context. In the first level, each position in the whole feature map only aggregates contextual information in vertical and horizontal directions according to both similarity and proximity. And then the result is input into the second level to do the same operations. By this hierarchical way, each central position gains supports from all other positions, and the combination of similarity and proximity makes each position gain supports mostly from the same semantic object. Moreover, we also propose a linear time algorithm for the aggregation of contextual information, where each of rows and columns in the feature map is treated as a binary tree to reduce similarity computation cost. Experiments on semantic segmentation and image retrieval show that adding SGSNet to existing networks gains solid improvements on both accuracy and efficiency.
Adaptive Workload Allocation for Multi-human Multi-robot Teams for Independent and Homogeneous Tasks
Jul 27, 2020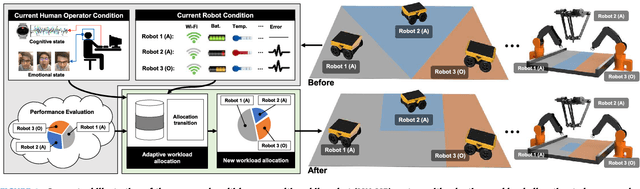
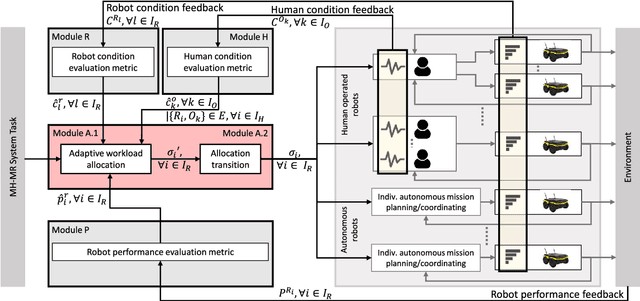
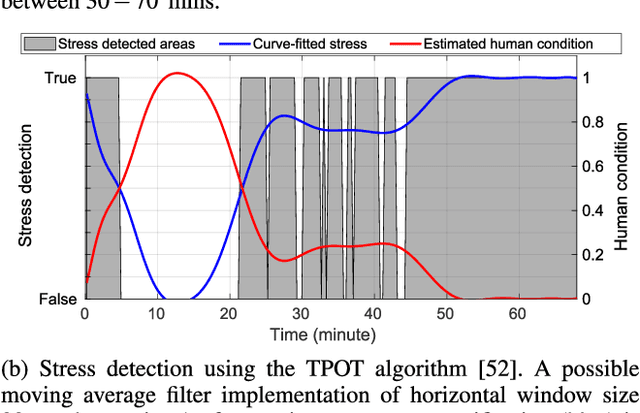
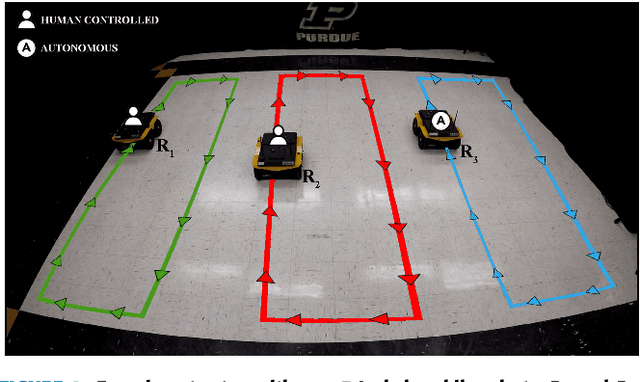
Multi-human multi-robot (MH-MR) systems have the ability to combine the potential advantages of robotic systems with those of having humans in the loop. Robotic systems contribute precision performance and long operation on repetitive tasks without tiring, while humans in the loop improve situational awareness and enhance decision-making abilities. A system's ability to adapt allocated workload to changing conditions and the performance of each individual (human and robot) during the mission is vital to maintaining overall system performance. Previous works from literature including market-based and optimization approaches have attempted to address the task/workload allocation problem with focus on maximizing the system output without regarding individual agent conditions, lacking in real-time processing and have mostly focused exclusively on multi-robot systems. Given the variety of possible combination of teams (autonomous robots and human-operated robots: any number of human operators operating any number of robots at a time) and the operational scale of MH-MR systems, development of a generalized framework of workload allocation has been a particularly challenging task. In this paper, we present such a framework for independent homogeneous missions, capable of adaptively allocating the system workload in relation to health conditions and work performances of human-operated and autonomous robots in real-time. The framework consists of removable modular function blocks ensuring its applicability to different MH-MR scenarios. A new workload transition function block ensures smooth transition without the workload change having adverse effects on individual agents. The effectiveness and scalability of the system's workload adaptability is validated by experiments applying the proposed framework in a MH-MR patrolling scenario with changing human and robot condition, and failing robots.
StyleMelGAN: An Efficient High-Fidelity Adversarial Vocoder with Temporal Adaptive Normalization
Nov 03, 2020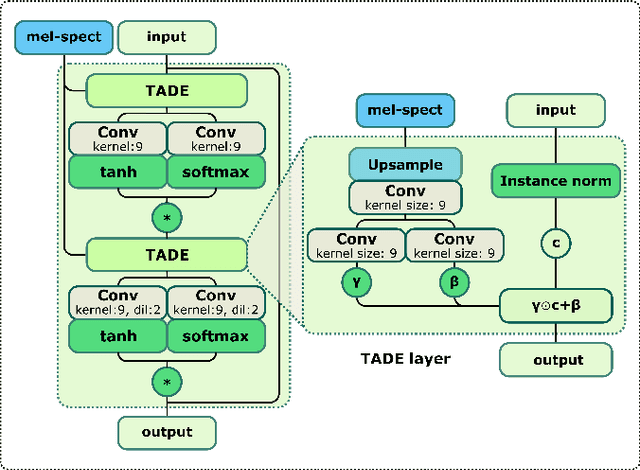
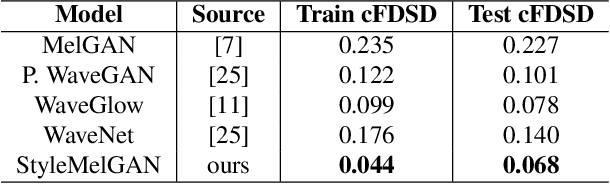
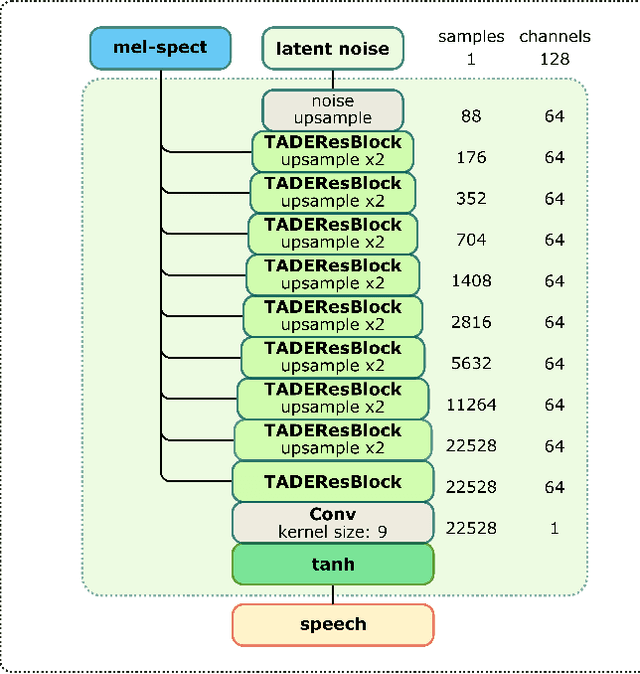

In recent years, neural vocoders have surpassed classical speech generation approaches in naturalness and perceptual quality of the synthesized speech. Computationally heavy models like WaveNet and WaveGlow achieve best results, while lightweight GAN models, e.g. MelGAN and Parallel WaveGAN, remain inferior in terms of perceptual quality. We therefore propose StyleMelGAN, a lightweight neural vocoder allowing synthesis of high-fidelity speech with low computational complexity. StyleMelGAN employs temporal adaptive normalization to style a low-dimensional noise vector with the acoustic features of the target speech. For efficient training, multiple random-window discriminators adversarially evaluate the speech signal analyzed by a filter bank, with regularization provided by a multi-scale spectral reconstruction loss. The highly parallelizable speech generation is several times faster than real-time on CPUs and GPUs. MUSHRA and P.800 listening tests show that StyleMelGAN outperforms prior neural vocoders in copy-synthesis and Text-to-Speech scenarios.