 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Scalable Graph Neural Networks for Heterogeneous Graphs
Nov 19, 2020
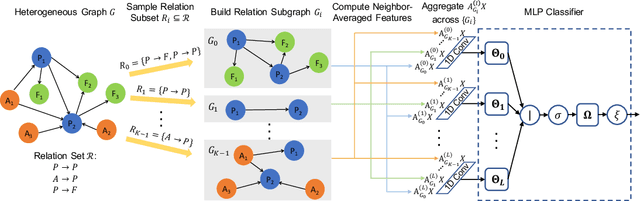


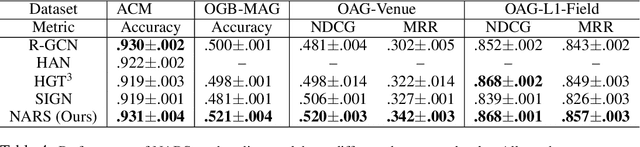
Graph neural networks (GNNs) are a popular class of parametric model for learning over graph-structured data. Recent work has argued that GNNs primarily use the graph for feature smoothing, and have shown competitive results on benchmark tasks by simply operating on graph-smoothed node features, rather than using end-to-end learned feature hierarchies that are challenging to scale to large graphs. In this work, we ask whether these results can be extended to heterogeneous graphs, which encode multiple types of relationship between different entities. We propose Neighbor Averaging over Relation Subgraphs (NARS), which trains a classifier on neighbor-averaged features for randomly-sampled subgraphs of the "metagraph" of relations. We describe optimizations to allow these sets of node features to be computed in a memory-efficient way, both at training and inference time. NARS achieves a new state of the art accuracy on several benchmark datasets, outperforming more expensive GNN-based methods
An exact kernel framework for spatio-temporal dynamics
Nov 13, 2020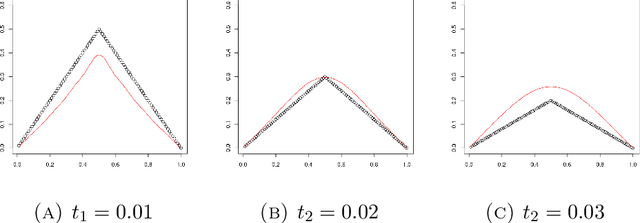
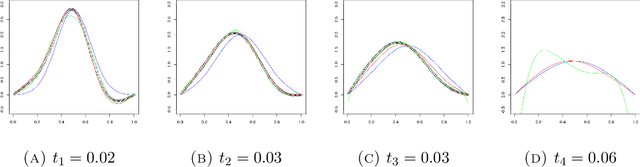
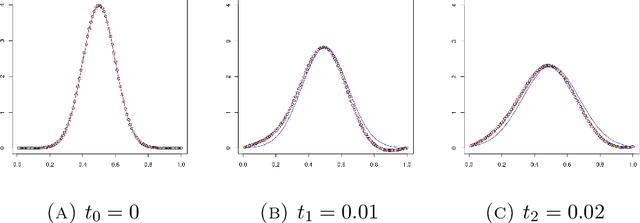
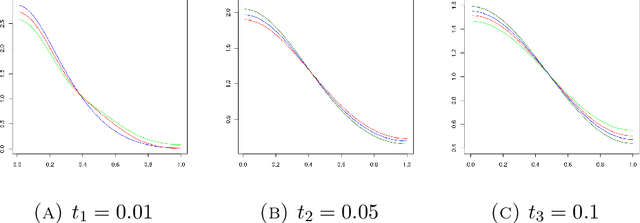
A kernel-based framework for spatio-temporal data analysis is introduced that applies in situations when the underlying system dynamics are governed by a dynamic equation. The key ingredient is a representer theorem that involves time-dependent kernels. Such kernels occur commonly in the expansion of solutions of partial differential equations. The representer theorem is applied to find among all solutions of a dynamic equation the one that minimizes the error with given spatio-temporal samples. This is motivated by the fact that very often a differential equation is given a priori (e.g.~by the laws of physics) and a practitioner seeks the best solution that is compatible with her noisy measurements. Our guiding example is the Fokker-Planck equation, which describes the evolution of density in stochastic diffusion processes. A regression and density estimation framework is introduced for spatio-temporal modeling under Fokker-Planck dynamics with initial and boundary conditions.
Deep Learning Based Intelligent Inter-Vehicle Distance Control for 6G Enabled Cooperative Autonomous Driving
Dec 26, 2020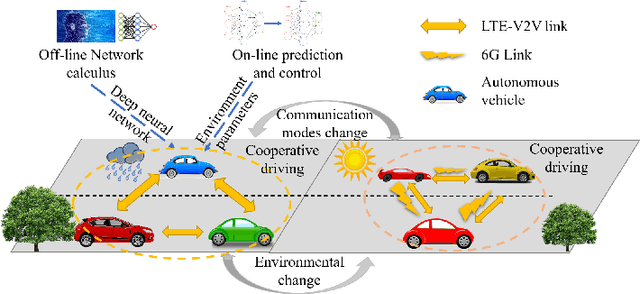
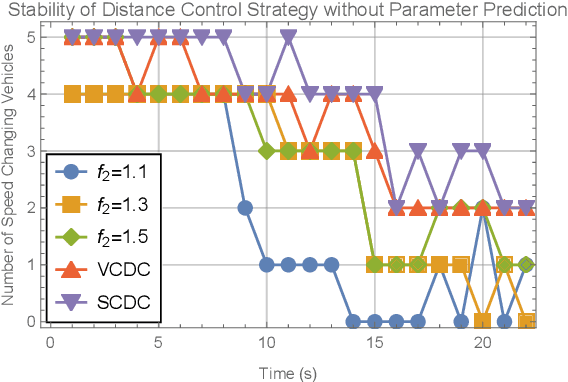
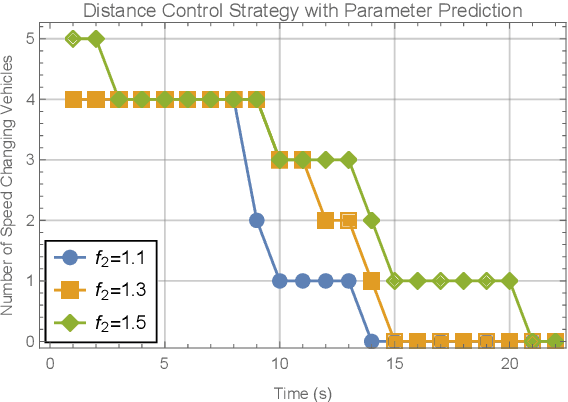
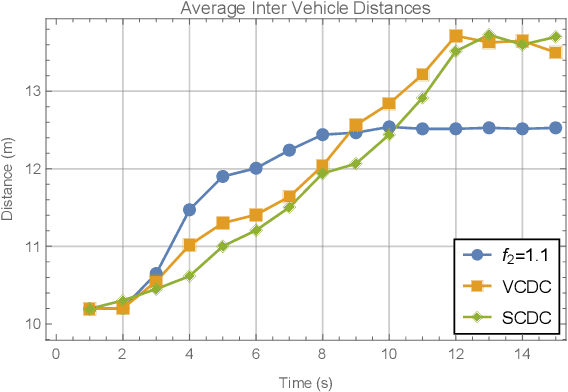
Research on the sixth generation cellular networks (6G) is gaining huge momentum to achieve ubiquitous wireless connectivity. Connected autonomous driving (CAV) is a critical vertical envisioned for 6G, holding great potentials of improving road safety, road and energy efficiency. However the stringent service requirements of CAV applications on reliability, latency and high speed communications will present big challenges to 6G networks. New channel access algorithms and intelligent control schemes for connected vehicles are needed for 6G supported CAV. In this paper, we investigated 6G supported cooperative driving, which is an advanced driving mode through information sharing and driving coordination. Firstly we quantify the delay upper bounds of 6G vehicle to vehicle (V2V) communications with hybrid communication and channel access technologies. A deep learning neural network is developed and trained for fast computation of the delay bounds in real time operations. Then, an intelligent strategy is designed to control the inter-vehicle distance for cooperative autonomous driving. Furthermore, we propose a Markov Chain based algorithm to predict the parameters of the system states, and also a safe distance mapping method to enable smooth vehicular speed changes. The proposed algorithms are implemented in the AirSim autonomous driving platform. Simulation results show that the proposed algorithms are effective and robust with safe and stable cooperative autonomous driving, which greatly improve the road safety, capacity and efficiency.
Mixed Membership Models for Time Series
Sep 13, 2013
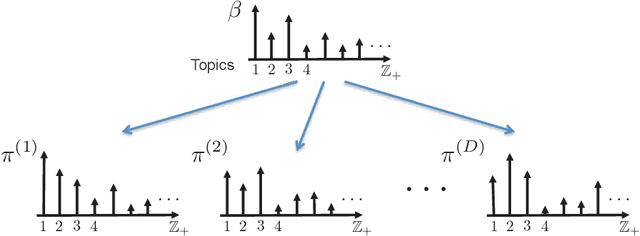
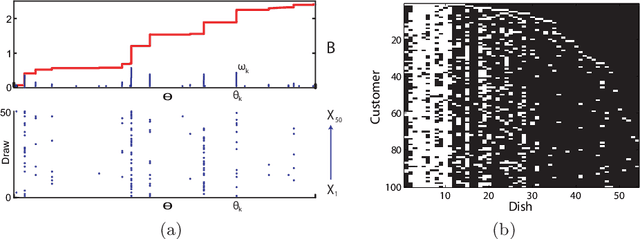
In this article we discuss some of the consequences of the mixed membership perspective on time series analysis. In its most abstract form, a mixed membership model aims to associate an individual entity with some set of attributes based on a collection of observed data. Although much of the literature on mixed membership models considers the setting in which exchangeable collections of data are associated with each member of a set of entities, it is equally natural to consider problems in which an entire time series is viewed as an entity and the goal is to characterize the time series in terms of a set of underlying dynamic attributes or "dynamic regimes". Indeed, this perspective is already present in the classical hidden Markov model, where the dynamic regimes are referred to as "states", and the collection of states realized in a sample path of the underlying process can be viewed as a mixed membership characterization of the observed time series. Our goal here is to review some of the richer modeling possibilities for time series that are provided by recent developments in the mixed membership framework.
vLPD-Net: A Registration-aided Domain Adaptation Network for 3D Point Cloud Based Place Recognition
Dec 09, 2020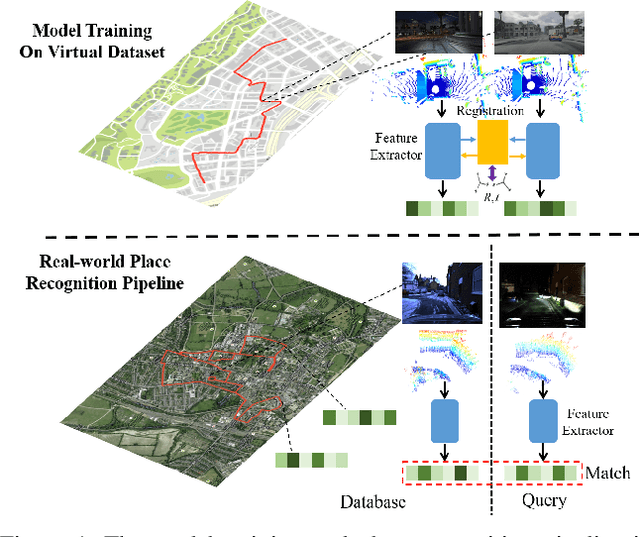

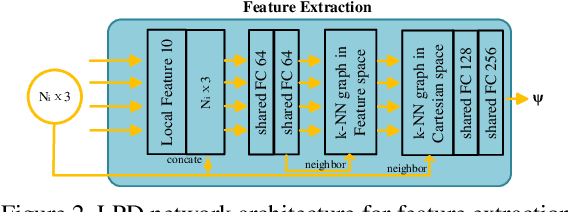
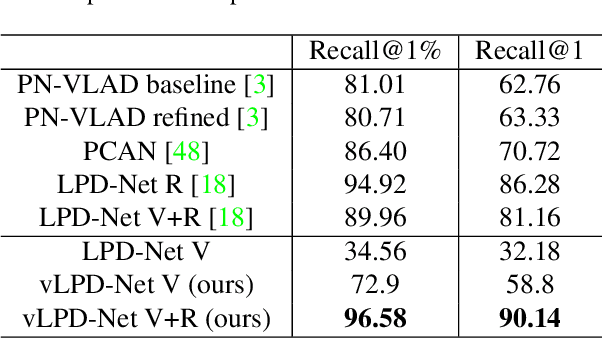
In the field of large-scale SLAM for autonomous driving and mobile robotics, 3D point cloud based place recognition has aroused significant research interest due to its robustness to changing environments with drastic daytime and weather variance. However, it is time-consuming and effort-costly to obtain high-quality point cloud data and groundtruth for registration and place recognition model training in the real world. To this end, a novel registration-aided 3D domain adaptation network for point cloud based place recognition is proposed. A structure-aware registration network is introduced to help learn feature from geometric properties and a matching rate based triplet loss is involved for metric learning. The model is trained through a new virtual LiDAR dataset through GTA-V with diverse weather and daytime conditions and domain adaptation is implemented to the real-world domain by aligning the local and global features. Extensive experiments have been conducted to validate the effectiveness of the structure-aware registration network and domain adaptation. Our results outperform state-of-the-art 3D place recognition baselines on the real-world Oxford RobotCar dataset with the visualization of large-scale registration on the virtual dataset.
Next-best-view Regression using a 3D Convolutional Neural Network
Jan 23, 2021
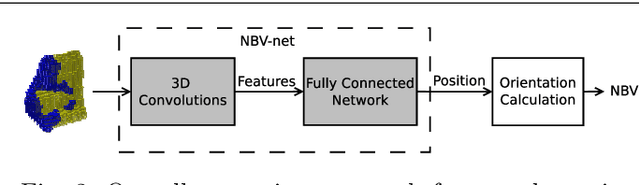
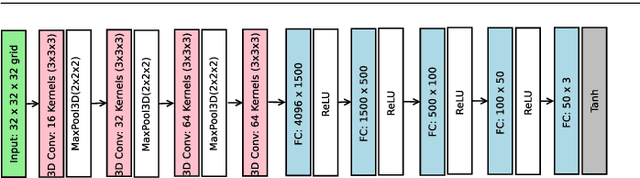
Automated three-dimensional (3D) object reconstruction is the task of building a geometric representation of a physical object by means of sensing its surface. Even though new single view reconstruction techniques can predict the surface, they lead to incomplete models, specially, for non commons objects such as antique objects or art sculptures. Therefore, to achieve the task's goals, it is essential to automatically determine the locations where the sensor will be placed so that the surface will be completely observed. This problem is known as the next-best-view problem. In this paper, we propose a data-driven approach to address the problem. The proposed approach trains a 3D convolutional neural network (3D CNN) with previous reconstructions in order to regress the \btxt{position of the} next-best-view. To the best of our knowledge, this is one of the first works that directly infers the next-best-view in a continuous space using a data-driven approach for the 3D object reconstruction task. We have validated the proposed approach making use of two groups of experiments. In the first group, several variants of the proposed architecture are analyzed. Predicted next-best-views were observed to be closely positioned to the ground truth. In the second group of experiments, the proposed approach is requested to reconstruct several unseen objects, namely, objects not considered by the 3D CNN during training nor validation. Coverage percentages of up to 90 \% were observed. With respect to current state-of-the-art methods, the proposed approach improves the performance of previous next-best-view classification approaches and it is quite fast in running time (3 frames per second), given that it does not compute the expensive ray tracing required by previous information metrics.
* Accepted to Machine Vision and Applications
MASSIVE: Tractable and Robust Bayesian Learning of Many-Dimensional Instrumental Variable Models
Dec 18, 2020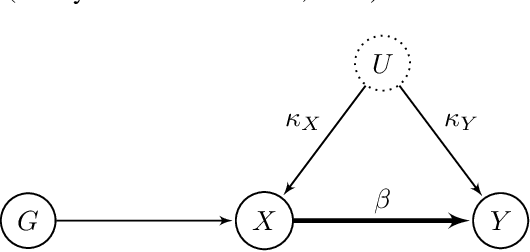
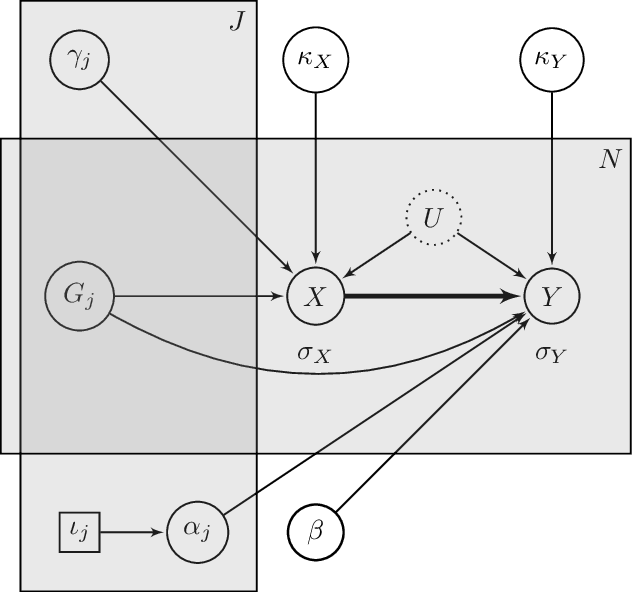
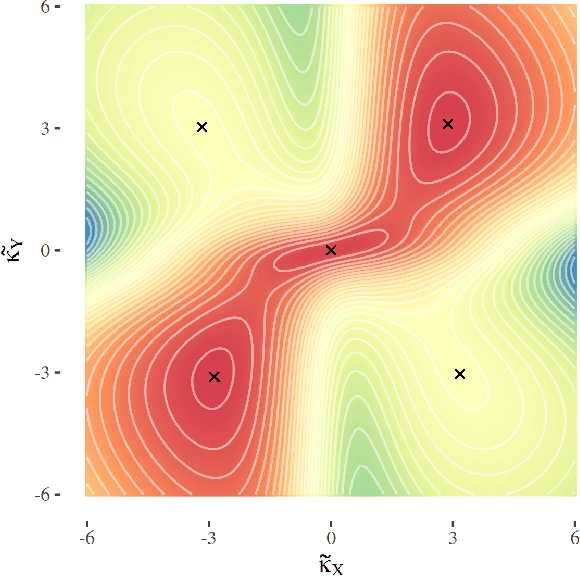
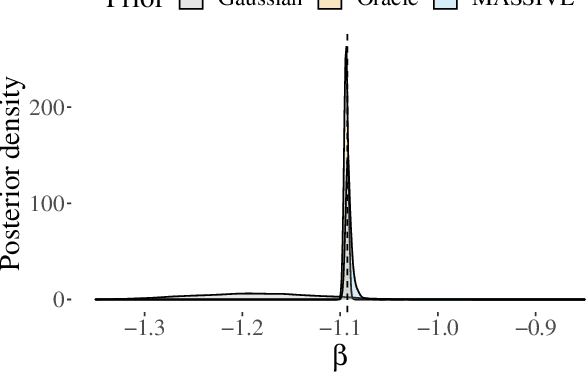
The recent availability of huge, many-dimensional data sets, like those arising from genome-wide association studies (GWAS), provides many opportunities for strengthening causal inference. One popular approach is to utilize these many-dimensional measurements as instrumental variables (instruments) for improving the causal effect estimate between other pairs of variables. Unfortunately, searching for proper instruments in a many-dimensional set of candidates is a daunting task due to the intractable model space and the fact that we cannot directly test which of these candidates are valid, so most existing search methods either rely on overly stringent modeling assumptions or fail to capture the inherent model uncertainty in the selection process. We show that, as long as at least some of the candidates are (close to) valid, without knowing a priori which ones, they collectively still pose enough restrictions on the target interaction to obtain a reliable causal effect estimate. We propose a general and efficient causal inference algorithm that accounts for model uncertainty by performing Bayesian model averaging over the most promising many-dimensional instrumental variable models, while at the same time employing weaker assumptions regarding the data generating process. We showcase the efficiency, robustness and predictive performance of our algorithm through experimental results on both simulated and real-world data.
* 14 pages, 7 figures, Published in the Proceedings of the 36th Conference on Uncertainty in Artificial Intelligence (UAI)
COVID-MTL: Multitask Learning with Shift3D and Random-weighted Loss for Diagnosis and Severity Assessment of COVID-19
Dec 18, 2020
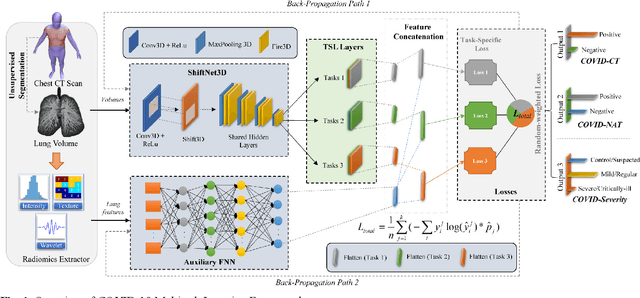
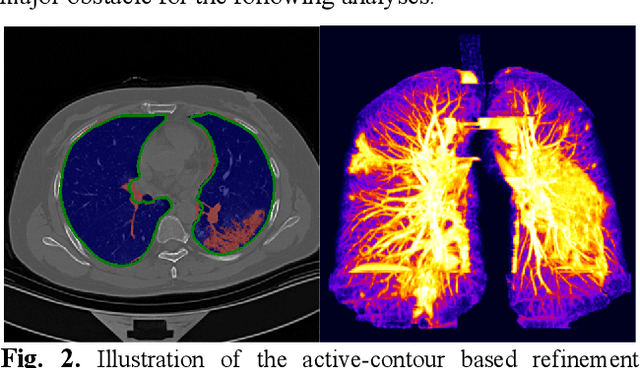
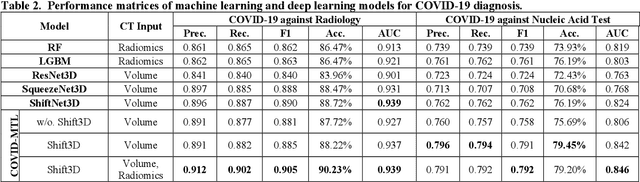
Both radiology and nucleic acid test (NAT) have their pros and cons for assessment of COVID-19. Here we present a 3D CNN-based multitask learning (MTL) framework, termed COVID-MTL, which is capable of simultaneously detecting COVID-19 against both radiology and NAT as well as assessing infection severity. A real-time 3D augmentation algorithm (Shift3D) was proposed to introduce space variances by shifting low-level feature representations of volumetric inputs in three dimensions, which boosted the convergence and accuracy of state-of-the-art 3D CNNs. A random-weighted loss was proposed to assign learning weights to different COVID-19 tasks under Dirichlet distribution, which prevented task dominance and improved joint performance. By only using CT data, COVID-MTL was trained on 930 CT scans and tested on another 399 cases, which yielded AUCs of 0.939 and 0.846, and accuracies of 90.23% and 79.20% for detection of COVID-19 against radiology and NAT, respectively, and outperformed state-of-the-art models. COVID-MTL yielded AUC of 0.800 $\pm$ 0.020 and 0.813 $\pm$ 0.021 (with transfer learning) for classifying control/suspected, mild/regular, and severe/critically-ill cases. To decipher the recognition mechanism, we identified high-throughput lung features, which are significantly related (P < 0.001) to the positivity and severity of COVID-19.
CodeVIO: Visual-Inertial Odometry with Learned Optimizable Dense Depth
Dec 18, 2020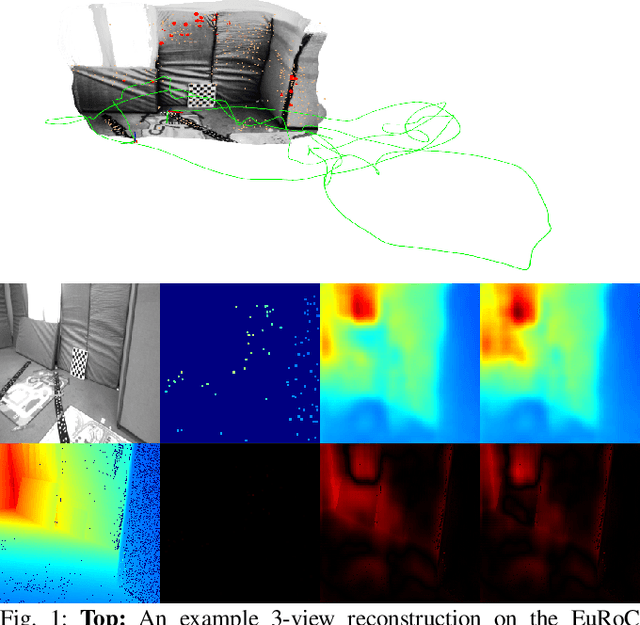
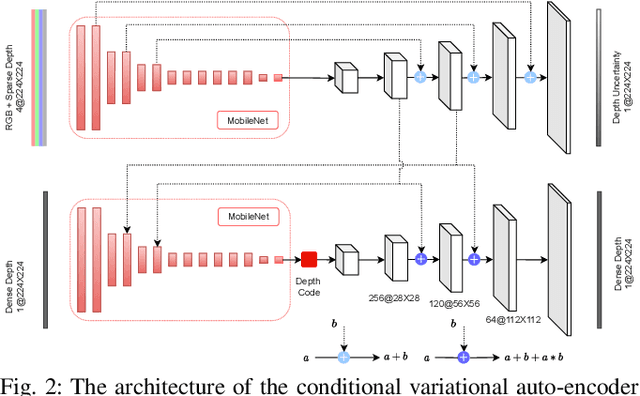
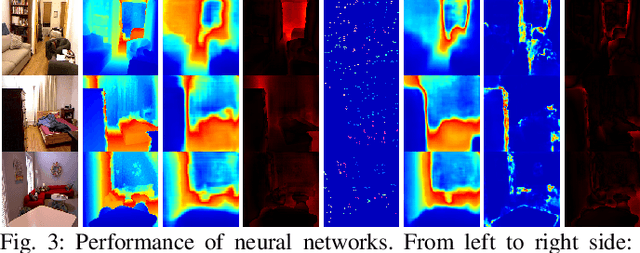
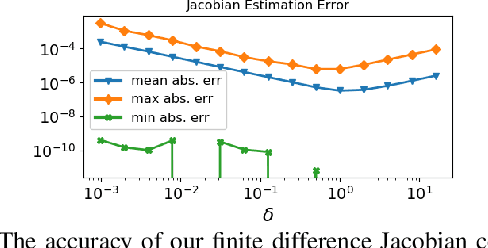
In this work, we present a lightweight, tightly-coupled deep depth network and visual-inertial odometry (VIO) system, which can provide accurate state estimates and dense depth maps of the immediate surroundings. Leveraging the proposed lightweight Conditional Variational Autoencoder (CVAE) for depth inference and encoding, we provide the network with previously marginalized sparse features from VIO to increase the accuracy of initial depth prediction and generalization capability. The compact encoded depth maps are then updated jointly with navigation states in a sliding window estimator in order to provide the dense local scene geometry. We additionally propose a novel method to obtain the CVAE's Jacobian which is shown to be more than an order of magnitude faster than previous works, and we additionally leverage First-Estimate Jacobian (FEJ) to avoid recalculation. As opposed to previous works relying on completely dense residuals, we propose to only provide sparse measurements to update the depth code and show through careful experimentation that our choice of sparse measurements and FEJs can still significantly improve the estimated depth maps. Our full system also exhibits state-of-the-art pose estimation accuracy, and we show that it can run in real-time with single-thread execution while utilizing GPU acceleration only for the network and code Jacobian.
Measuring Data Collection Quality for Community Healthcare
Nov 13, 2020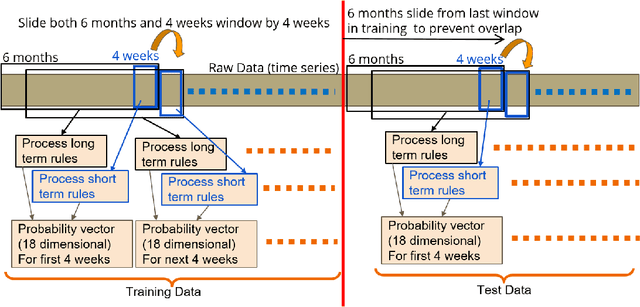
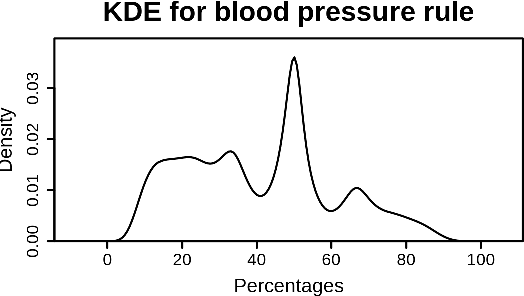
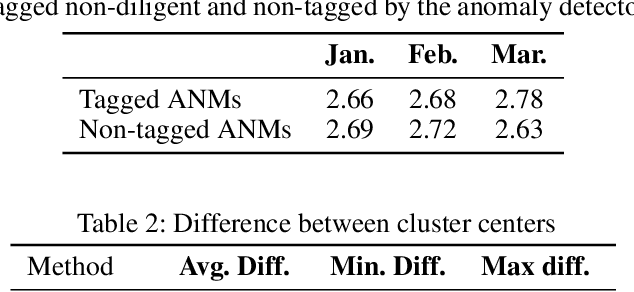
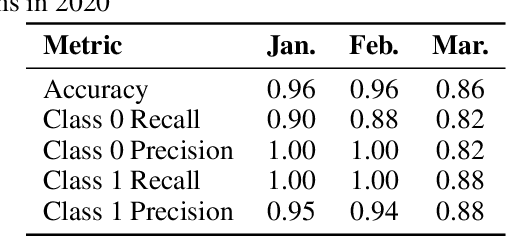
Machine learning has tremendous potential to provide targeted interventions in low-resource communities, however the availability of high-quality public health data is a significant challenge. In this work, we partner with field experts at a non-governmental organization (NGO) in India to define and test a data collection quality score for each health worker who collects data. This challenging unlabeled data problem is handled by building upon domain-expert's guidance to design a useful data representation that is then clustered to infer a data quality score. We also provide a more interpretable version of the score. These scores already provide for a measurement of data collection quality; in addition, we also predict the quality for future time steps and find our results to be very accurate. Our work was successfully field tested and is in the final stages of deployment in Rajasthan, India.