 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Model-based Reinforcement Learning from Signal Temporal Logic Specifications
Nov 10, 2020
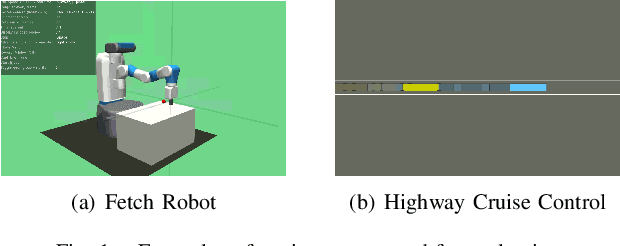
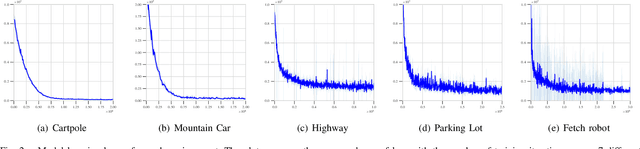

Techniques based on Reinforcement Learning (RL) are increasingly being used to design control policies for robotic systems. RL fundamentally relies on state-based reward functions to encode desired behavior of the robot and bad reward functions are prone to exploitation by the learning agent, leading to behavior that is undesirable in the best case and critically dangerous in the worst. On the other hand, designing good reward functions for complex tasks is a challenging problem. In this paper, we propose expressing desired high-level robot behavior using a formal specification language known as Signal Temporal Logic (STL) as an alternative to reward/cost functions. We use STL specifications in conjunction with model-based learning to design model predictive controllers that try to optimize the satisfaction of the STL specification over a finite time horizon. The proposed algorithm is empirically evaluated on simulations of robotic system such as a pick-and-place robotic arm, and adaptive cruise control for autonomous vehicles.
Machine learning spatio-temporal epidemiological model to evaluate Germany-county-level COVID-19 risk
Nov 30, 2020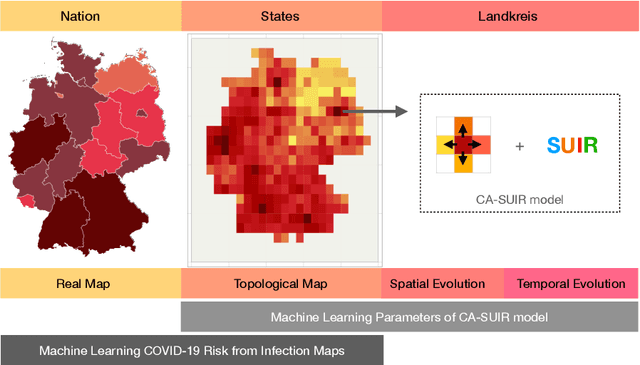
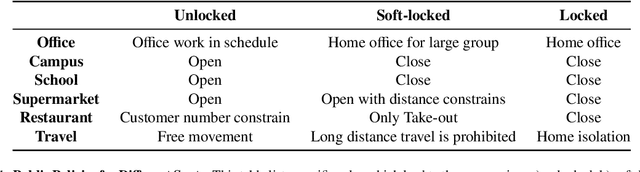
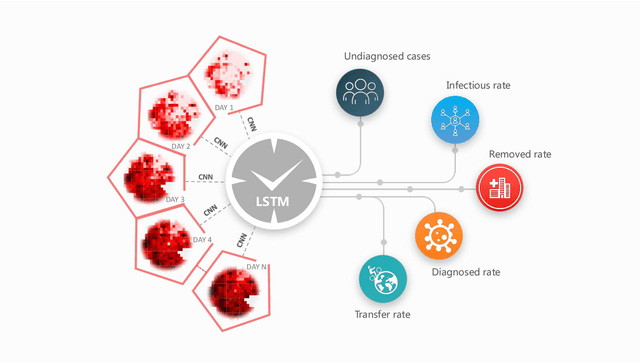
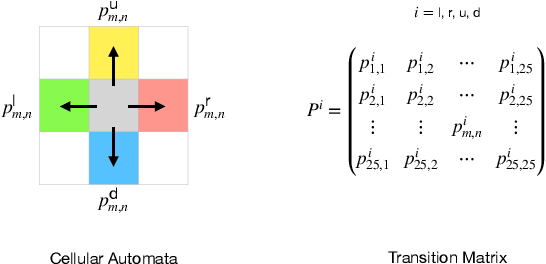
As the COVID-19 pandemic continues to ravage the world, it is of critical significance to provide a timely risk prediction of the COVID-19 in multi-level. To implement it and evaluate the public health policies, we develop a framework with machine learning assisted to extract epidemic dynamics from the infection data, in which contains a county-level spatiotemporal epidemiological model that combines a spatial Cellular Automaton (CA) with a temporal Susceptible-Undiagnosed-Infected-Removed (SUIR) model. Compared with the existing time risk prediction models, the proposed CA-SUIR model shows the multi-level risk of the county to the government and coronavirus transmission patterns under different policies. This new toolbox is first utilized to the projection of the multi-level COVID-19 prevalence over 412 Landkreis (counties) in Germany, including t-day-ahead risk forecast and the risk assessment to the travel restriction policy. As a practical illustration, we predict the situation at Christmas where the worst fatalities are 34.5 thousand, effective policies could contain it to below 21 thousand. Such intervenable evaluation system could help decide on economic restarting and public health policies making in pandemic.
TimeSHAP: Explaining Recurrent Models through Sequence Perturbations
Nov 30, 2020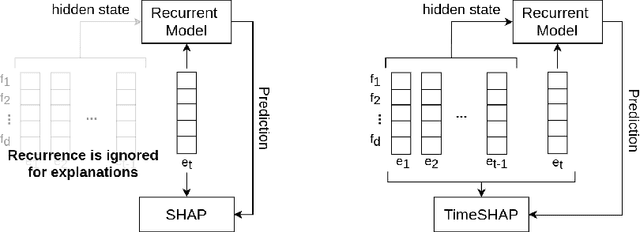
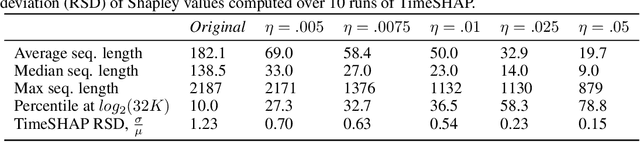
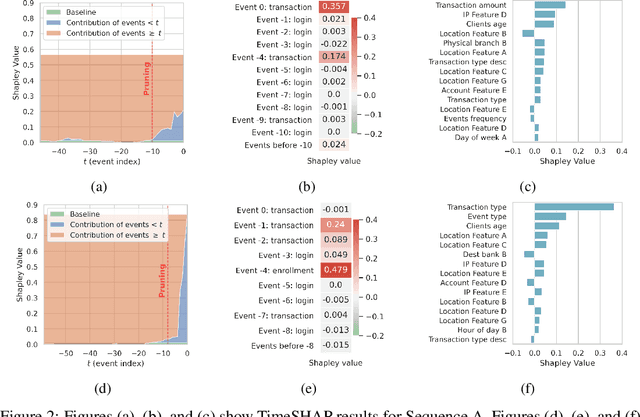
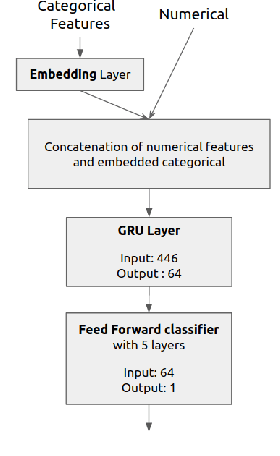
Recurrent neural networks are a standard building block in numerous machine learning domains, from natural language processing to time-series classification. While their application has grown ubiquitous, understanding of their inner workings is still lacking. In practice, the complex decision-making in these models is seen as a black-box, creating a tension between accuracy and interpretability. Moreover, the ability to understand the reasoning process of a model is important in order to debug it and, even more so, to build trust in its decisions. Although considerable research effort has been guided towards explaining black-box models in recent years, recurrent models have received relatively little attention. Any method that aims to explain decisions from a sequence of instances should assess, not only feature importance, but also event importance, an ability that is missing from state-of-the-art explainers. In this work, we contribute to filling these gaps by presenting TimeSHAP, a model-agnostic recurrent explainer that leverages KernelSHAP's sound theoretical footing and strong empirical results. As the input sequence may be arbitrarily long, we further propose a pruning method that is shown to dramatically improve its efficiency in practice.
Fast Graph Kernel with Optical Random Features
Oct 16, 2020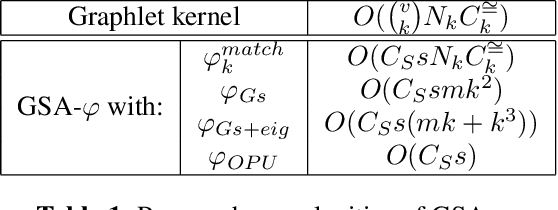
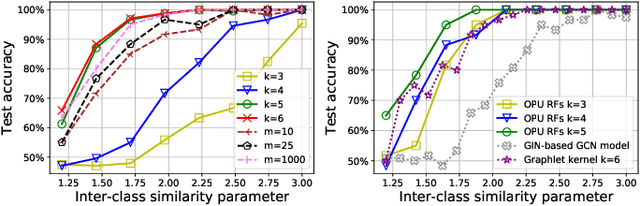
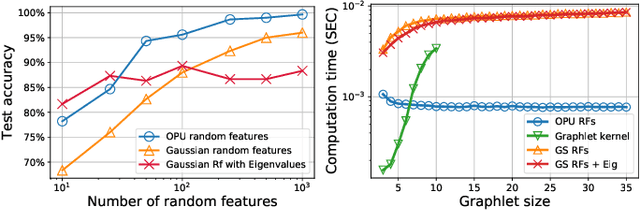
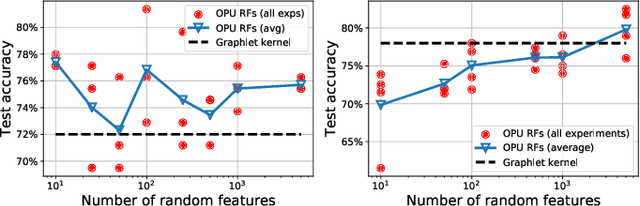
The graphlet kernel is a classical method in graph classification. It however suffers from a high computation cost due to the isomorphism test it includes. As a generic proxy, and in general at the cost of losing some information, this test can be efficiently replaced by a user-defined mapping that computes various graph characteristics. In this paper, we propose to leverage kernel random features within the graphlet framework, and establish a theoretical link with a mean kernel metric. If this method can still be prohibitively costly for usual random features, we then incorporate optical random features that can be computed in constant time. Experiments show that the resulting algorithm is orders of magnitude faster that the graphlet kernel for the same, or better, accuracy.
Animating Pictures with Eulerian Motion Fields
Nov 30, 2020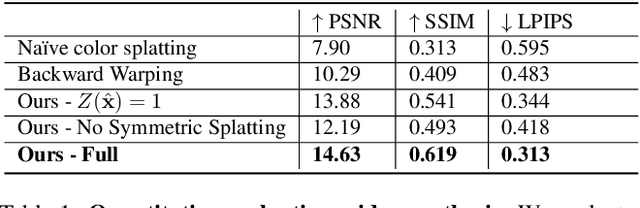
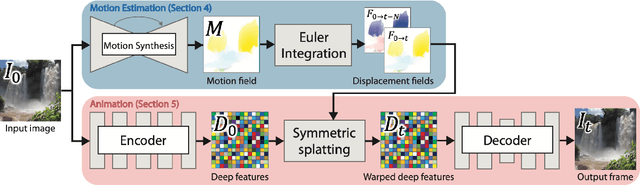

In this paper, we demonstrate a fully automatic method for converting a still image into a realistic animated looping video. We target scenes with continuous fluid motion, such as flowing water and billowing smoke. Our method relies on the observation that this type of natural motion can be convincingly reproduced from a static Eulerian motion description, i.e. a single, temporally constant flow field that defines the immediate motion of a particle at a given 2D location. We use an image-to-image translation network to encode motion priors of natural scenes collected from online videos, so that for a new photo, we can synthesize a corresponding motion field. The image is then animated using the generated motion through a deep warping technique: pixels are encoded as deep features, those features are warped via Eulerian motion, and the resulting warped feature maps are decoded as images. In order to produce continuous, seamlessly looping video textures, we propose a novel video looping technique that flows features both forward and backward in time and then blends the results. We demonstrate the effectiveness and robustness of our method by applying it to a large collection of examples including beaches, waterfalls, and flowing rivers.
Progressive Voice Trigger Detection: Accuracy vs Latency
Oct 29, 2020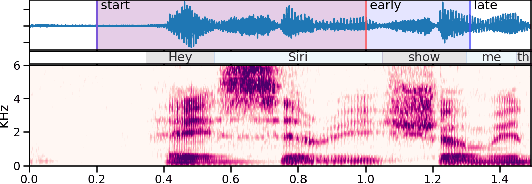
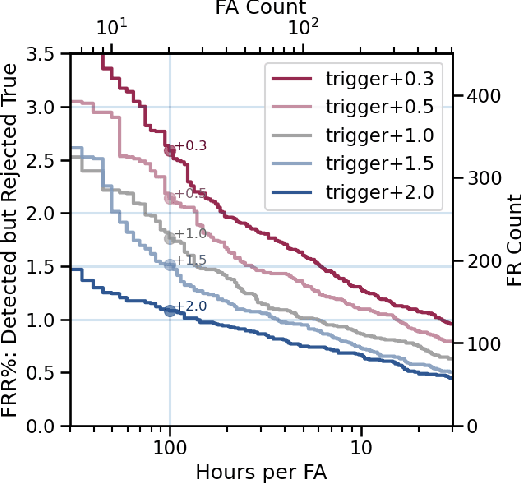
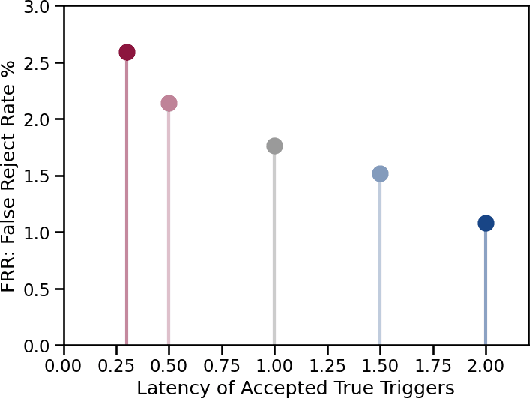
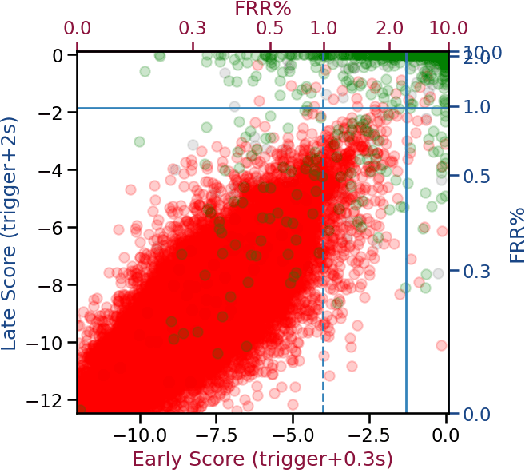
We present an architecture for voice trigger detection for virtual assistants. The main idea in this work is to exploit information in words that immediately follow the trigger phrase. We first demonstrate that by including more audio context after a detected trigger phrase, we can indeed get a more accurate decision. However, waiting to listen to more audio each time incurs a latency increase. Progressive Voice Trigger Detection allows us to trade-off latency and accuracy by accepting clear trigger candidates quickly, but waiting for more context to decide whether to accept more marginal examples. Using a two-stage architecture, we show that by delaying the decision for just 3% of detected true triggers in the test set, we are able to obtain a relative improvement of 66% in false rejection rate, while incurring only a negligible increase in latency.
Against Adversarial Learning: Naturally Distinguish Known and Unknown in Open Set Domain Adaptation
Nov 04, 2020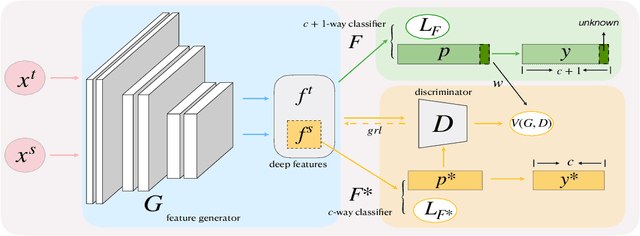
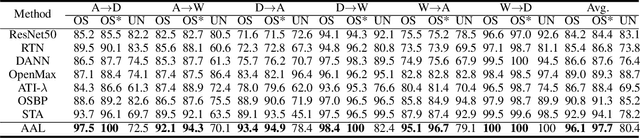
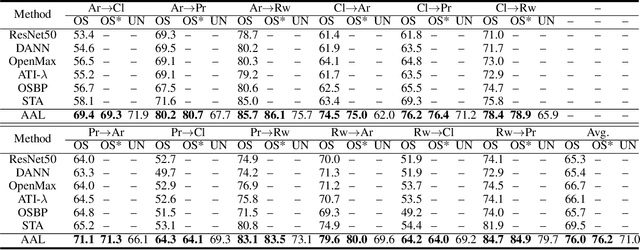
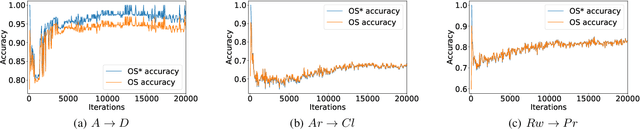
Open set domain adaptation refers to the scenario that the target domain contains categories that do not exist in the source domain. It is a more common situation in the reality compared with the typical closed set domain adaptation where the source domain and the target domain contain the same categories. The main difficulty of open set domain adaptation is that we need to distinguish which target data belongs to the unknown classes when machine learning models only have concepts about what they know. In this paper, we propose an "against adversarial learning" method that can distinguish unknown target data and known data naturally without setting any additional hyper parameters and the target data predicted to the known classes can be classified at the same time. Experimental results show that the proposed method can make significant improvement in performance compared with several state-of-the-art methods.
Analyzing COVID-19 on Online Social Media: Trends, Sentiments and Emotions
Jun 05, 2020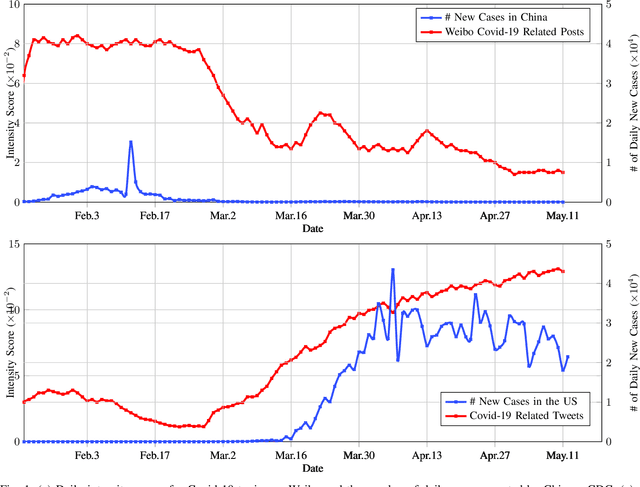
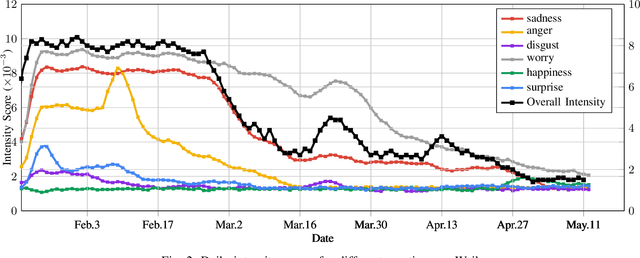
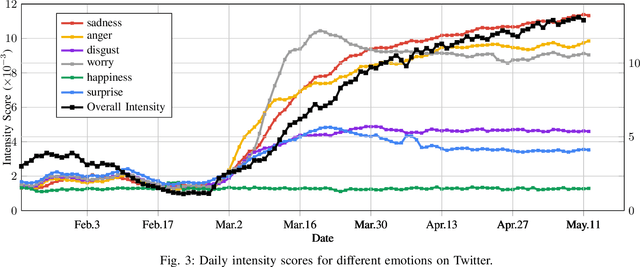
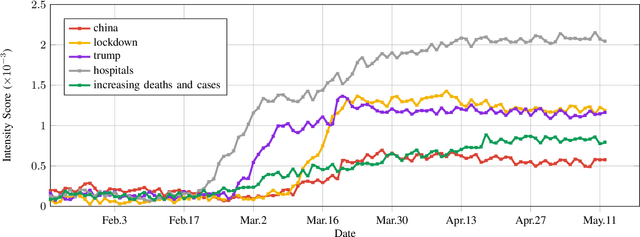
At the time of writing, the ongoing pandemic of coronavirus disease (COVID-19) has caused severe impacts on society, economy and people's daily lives. People constantly express their opinions on various aspects of the pandemic on social media, making user-generated content an important source for understanding public emotions and concerns. In this paper, we perform a comprehensive analysis on the affective trajectories of the American people and the Chinese people based on Twitter and Weibo posts between January 20th, 2020 and May 11th 2020. Specifically, by identifying people's sentiments, emotions (i.e., anger, disgust, fear, happiness, sadness, surprise) and the emotional triggers (e.g., what a user is angry/sad about) we are able to depict the dynamics of public affect in the time of COVID-19. By contrasting two very different countries, China and the Unites States, we reveal sharp differences in people's views on COVID-19 in different cultures. Our study provides a computational approach to unveiling public emotions and concerns on the pandemic in real-time, which would potentially help policy-makers better understand people's need and thus make optimal policy.
Self-supervised Pre-training Reduces Label Permutation Instability of Speech Separation
Oct 29, 2020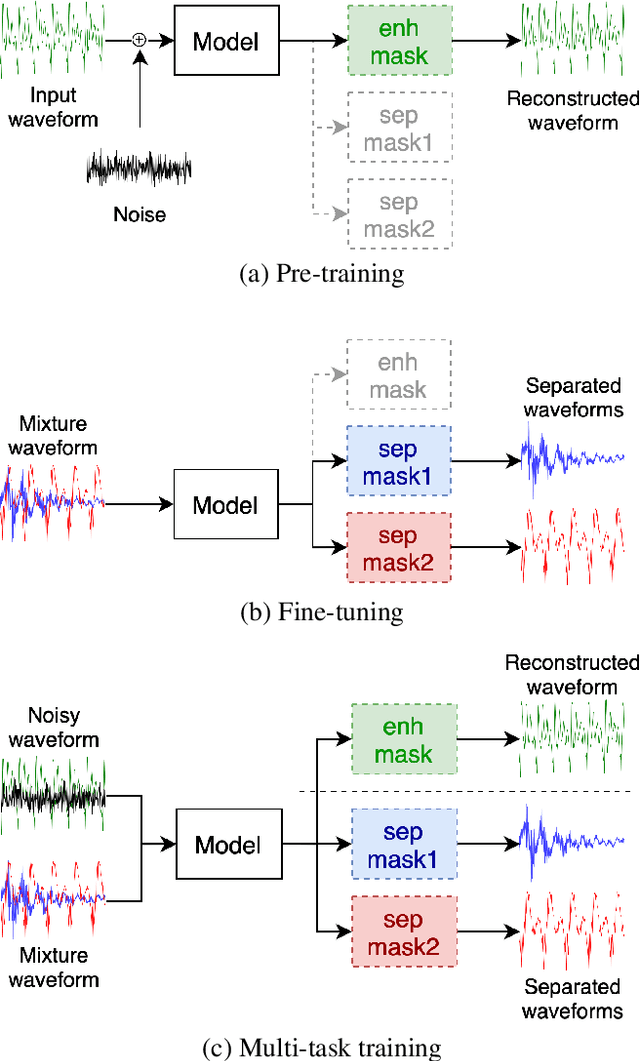
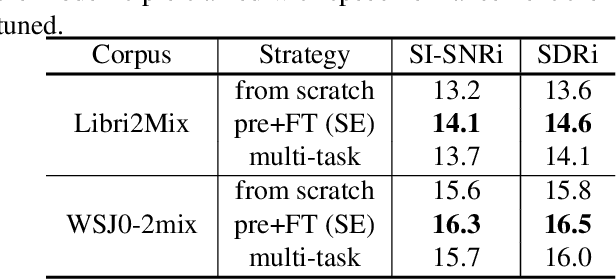
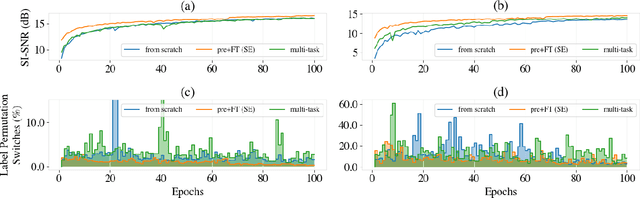
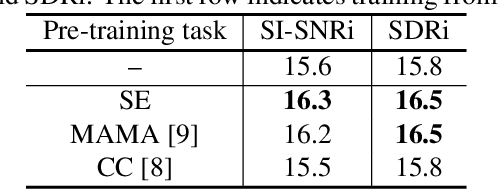
Speech separation has been well-developed while there are still problems waiting to be solved. The main problem we focus on in this paper is the frequent label permutation switching of permutation invariant training (PIT). For N-speaker separation, there would be N! possible label permutations. How to stably select correct label permutations is a long-standing problem. In this paper, we utilize self-supervised pre-training to stabilize the label permutations. Among several types of self-supervised tasks, speech enhancement based pre-training tasks show significant effectiveness in our experiments. When using off-the-shelf pre-trained models, training duration could be shortened to one-third to two-thirds. Furthermore, even taking pre-training time into account, the entire training process could still be shorter without a performance drop when using a larger batch size.
Autonomous Control of a Particle Accelerator using Deep Reinforcement Learning
Oct 16, 2020
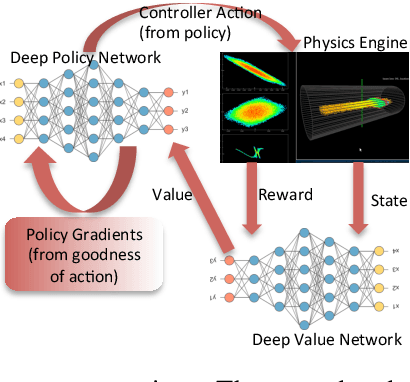
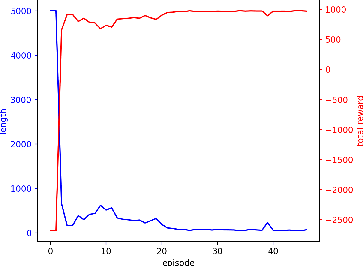
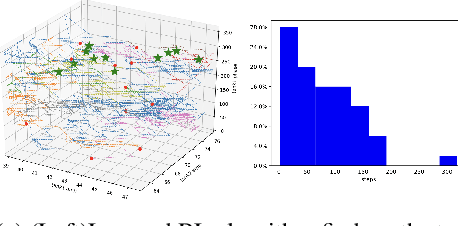
We describe an approach to learning optimal control policies for a large, linear particle accelerator using deep reinforcement learning coupled with a high-fidelity physics engine. The framework consists of an AI controller that uses deep neural nets for state and action-space representation and learns optimal policies using reward signals that are provided by the physics simulator. For this work, we only focus on controlling a small section of the entire accelerator. Nevertheless, initial results indicate that we can achieve better-than-human level performance in terms of particle beam current and distribution. The ultimate goal of this line of work is to substantially reduce the tuning time for such facilities by orders of magnitude, and achieve near-autonomous control.