 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Spatio-Temporal Graph Scattering Transform
Dec 10, 2020
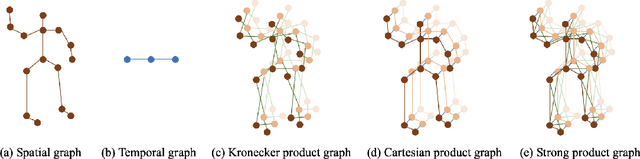
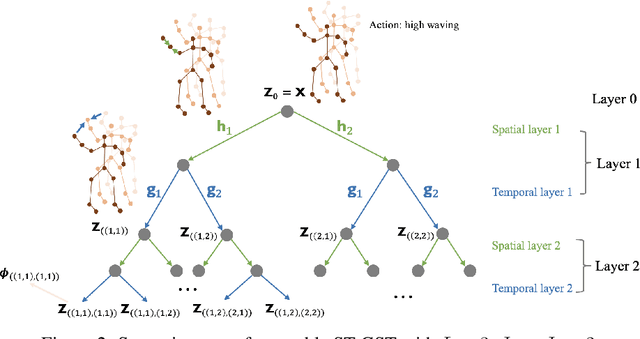

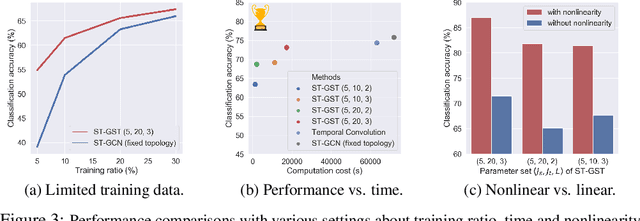
Although spatio-temporal graph neural networks have achieved great empirical success in handling multiple correlated time series, they may be impractical in some real-world scenarios due to a lack of sufficient high-quality training data. Furthermore, spatio-temporal graph neural networks lack theoretical interpretation. To address these issues, we put forth a novel mathematically designed framework to analyze spatio-temporal data. Our proposed spatio-temporal graph scattering transform (ST-GST) extends traditional scattering transforms to the spatio-temporal domain. It performs iterative applications of spatio-temporal graph wavelets and nonlinear activation functions, which can be viewed as a forward pass of spatio-temporal graph convolutional networks without training. Since all the filter coefficients in ST-GST are mathematically designed, it is promising for the real-world scenarios with limited training data, and also allows for a theoretical analysis, which shows that the proposed ST-GST is stable to small perturbations of input signals and structures. Finally, our experiments show that i) ST-GST outperforms spatio-temporal graph convolutional networks by an increase of 35% in accuracy for MSR Action3D dataset; ii) it is better and computationally more efficient to design the transform based on separable spatio-temporal graphs than the joint ones; and iii) the nonlinearity in ST-GST is critical to empirical performance.
Logic-guided Semantic Representation Learning for Zero-Shot Relation Classification
Oct 30, 2020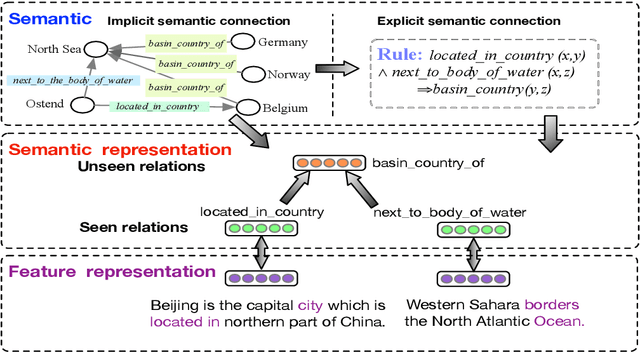
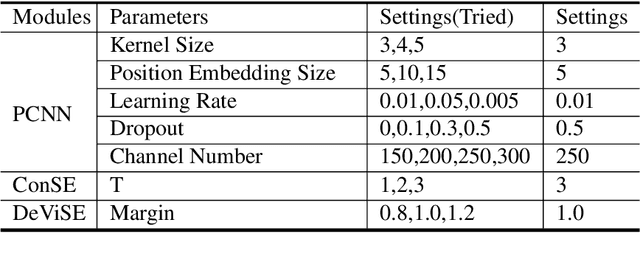
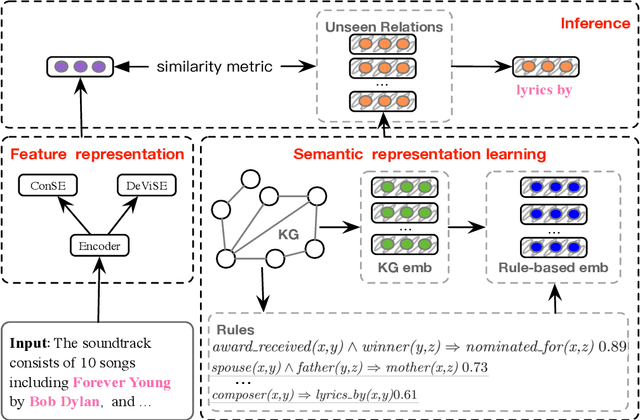
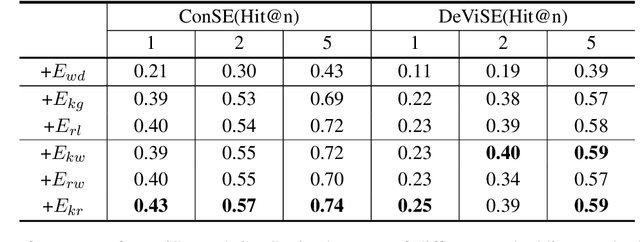
Relation classification aims to extract semantic relations between entity pairs from the sentences. However, most existing methods can only identify seen relation classes that occurred during training. To recognize unseen relations at test time, we explore the problem of zero-shot relation classification. Previous work regards the problem as reading comprehension or textual entailment, which have to rely on artificial descriptive information to improve the understandability of relation types. Thus, rich semantic knowledge of the relation labels is ignored. In this paper, we propose a novel logic-guided semantic representation learning model for zero-shot relation classification. Our approach builds connections between seen and unseen relations via implicit and explicit semantic representations with knowledge graph embeddings and logic rules. Extensive experimental results demonstrate that our method can generalize to unseen relation types and achieve promising improvements.
Weight and Gradient Centralization in Deep Neural Networks
Oct 02, 2020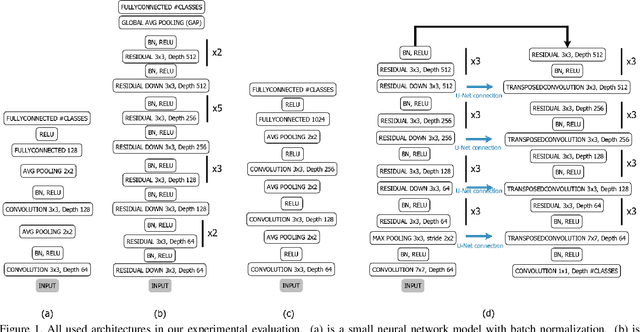
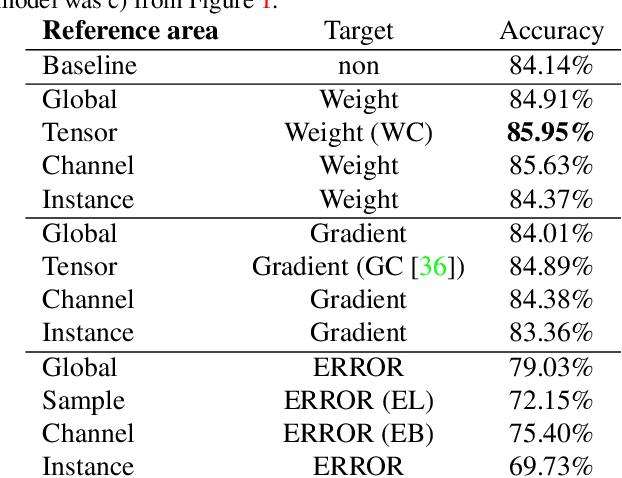
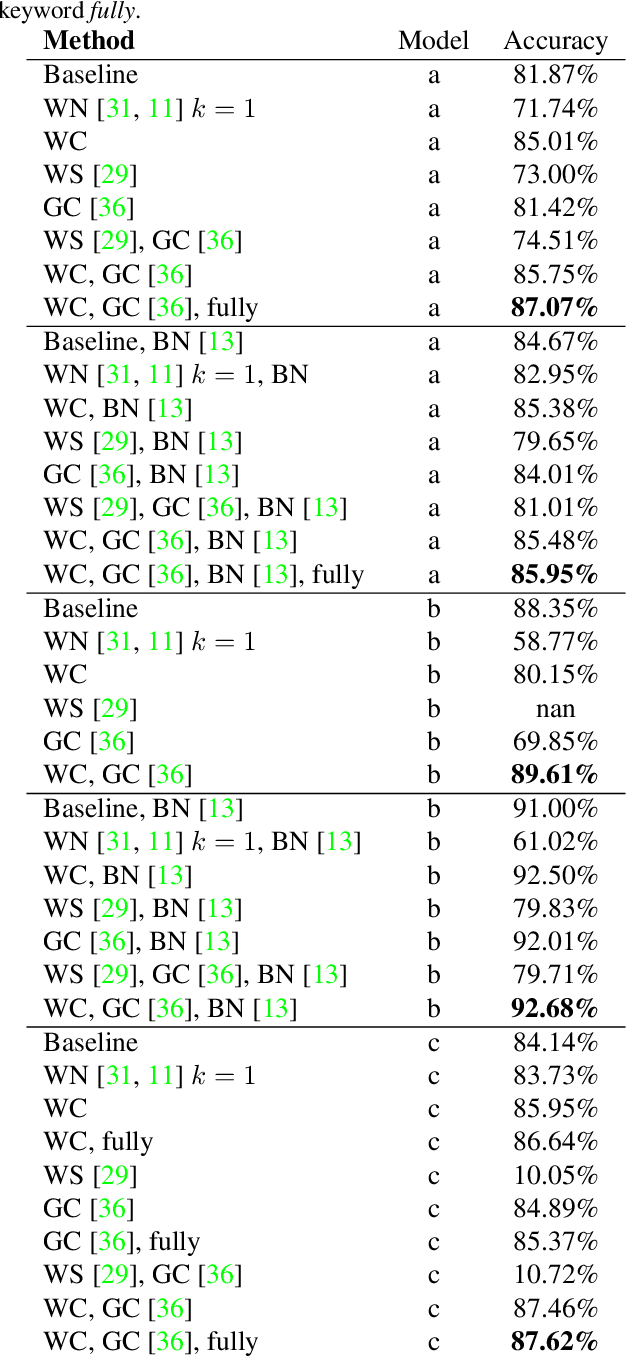
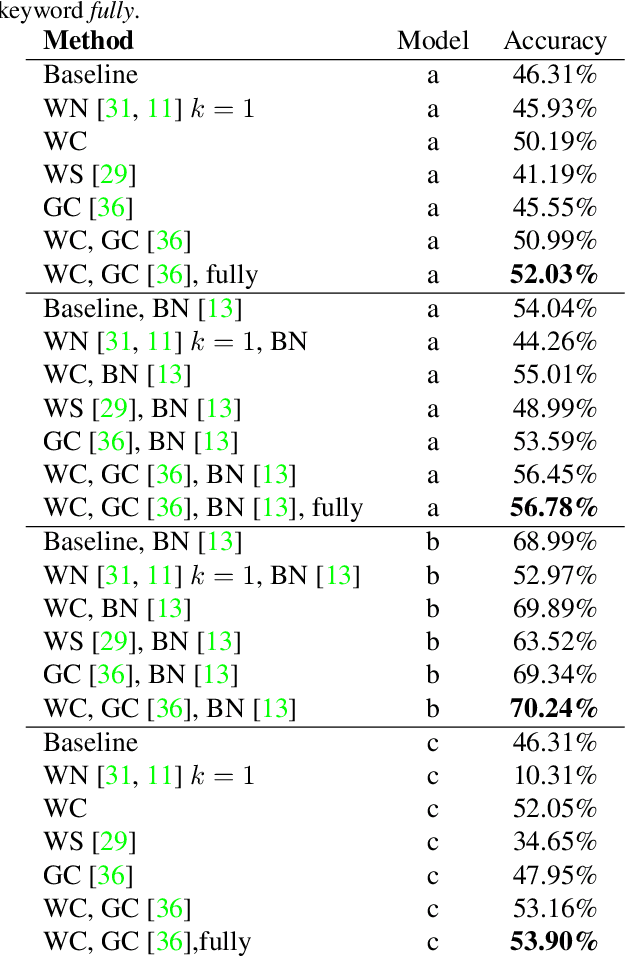
Batch normalization is currently the most widely used variant of internal normalization for deep neural networks. Additional work has shown that the normalization of weights and additional conditioning as well as the normalization of gradients further improve the generalization. In this work, we combine several of these methods and thereby increase the generalization of the networks. The advantage of the newer methods compared to the batch normalization is not only increased generalization, but also that these methods only have to be applied during training and, therefore, do not influence the running time during use. Link to CUDA code https://atreus.informatik.uni-tuebingen.de/seafile/d/8e2ab8c3fdd444e1a135/
DMD: A Large-Scale Multi-Modal Driver Monitoring Dataset for Attention and Alertness Analysis
Aug 27, 2020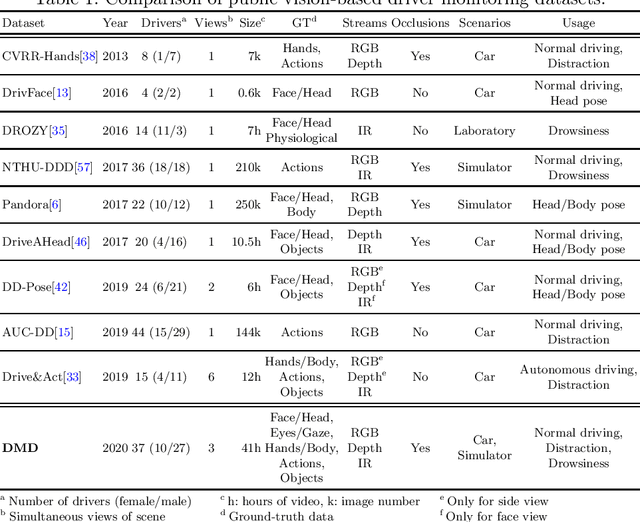
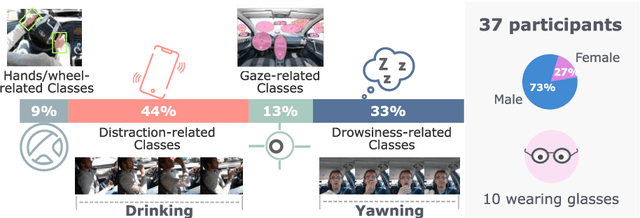
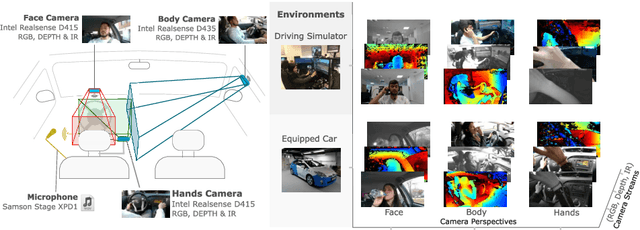

Vision is the richest and most cost-effective technology for Driver Monitoring Systems (DMS), especially after the recent success of Deep Learning (DL) methods. The lack of sufficiently large and comprehensive datasets is currently a bottleneck for the progress of DMS development, crucial for the transition of automated driving from SAE Level-2 to SAE Level-3. In this paper, we introduce the Driver Monitoring Dataset (DMD), an extensive dataset which includes real and simulated driving scenarios: distraction, gaze allocation, drowsiness, hands-wheel interaction and context data, in 41 hours of RGB, depth and IR videos from 3 cameras capturing face, body and hands of 37 drivers. A comparison with existing similar datasets is included, which shows the DMD is more extensive, diverse, and multi-purpose. The usage of the DMD is illustrated by extracting a subset of it, the dBehaviourMD dataset, containing 13 distraction activities, prepared to be used in DL training processes. Furthermore, we propose a robust and real-time driver behaviour recognition system targeting a real-world application that can run on cost-efficient CPU-only platforms, based on the dBehaviourMD. Its performance is evaluated with different types of fusion strategies, which all reach enhanced accuracy still providing real-time response.
SPAA: Stealthy Projector-based Adversarial Attacks on Deep Image Classifiers
Dec 10, 2020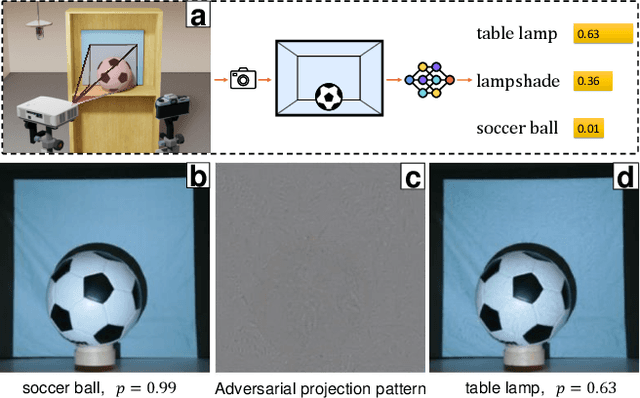
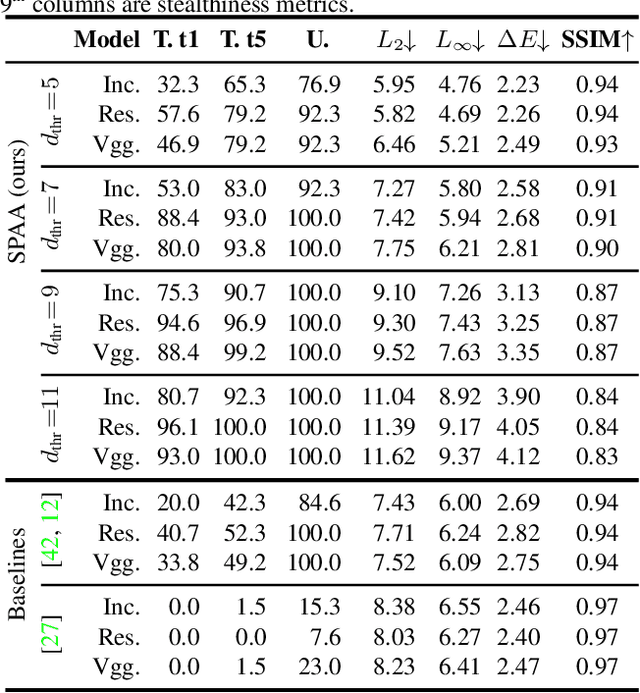

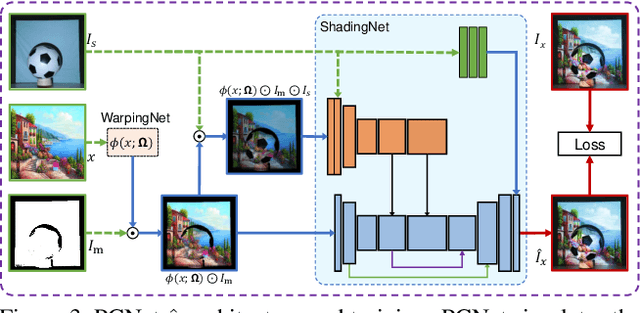
Light-based adversarial attacks aim to fool deep learning-based image classifiers by altering the physical light condition using a controllable light source, e.g., a projector. Compared with physical attacks that place carefully designed stickers or printed adversarial objects, projector-based ones obviate modifying the physical entities. Moreover, projector-based attacks can be performed transiently and dynamically by altering the projection pattern. However, existing approaches focus on projecting adversarial patterns that result in clearly perceptible camera-captured perturbations, while the more interesting yet challenging goal, stealthy projector-based attack, remains an open problem. In this paper, for the first time, we formulate this problem as an end-to-end differentiable process and propose Stealthy Projector-based Adversarial Attack (SPAA). In SPAA, we approximate the real project-and-capture operation using a deep neural network named PCNet, then we include PCNet in the optimization of projector-based attacks such that the generated adversarial projection is physically plausible. Finally, to generate robust and stealthy adversarial projections, we propose an optimization algorithm that uses minimum perturbation and adversarial confidence thresholds to alternate between the adversarial loss and stealthiness loss optimization. Our experimental evaluations show that the proposed SPAA clearly outperforms other methods by achieving higher attack success rates and meanwhile being stealthier.
Occlusion-Aware Search for Object Retrieval in Clutter
Nov 10, 2020

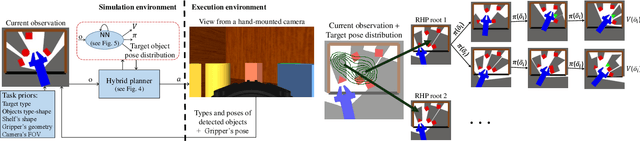

We address the manipulation task of retrieving a target object from a cluttered shelf. When the target object is hidden, the robot must search through the clutter for retrieving it. Solving this task requires reasoning over the likely locations of the target object. It also requires physics reasoning over multi-object interactions and future occlusions. In this work, we present a data-driven approach for generating occlusion-aware actions in closed-loop. We present a hybrid planner that explores likely states generated from a learned distribution over the location of the target object. The search is guided by a heuristic trained with reinforcement learning to evaluate occluded observations. We evaluate our approach in different environments with varying clutter densities and physics parameters. The results validate that our approach can search and retrieve a target object in different physics environments, while only being trained in simulation. It achieves near real-time behaviour with a success rate exceeding 88%.
Recent Developments in Detection of Central Serous Retinopathy through Imaging and Artificial Intelligence Techniques A Review
Dec 26, 2020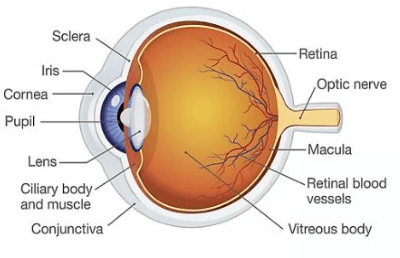
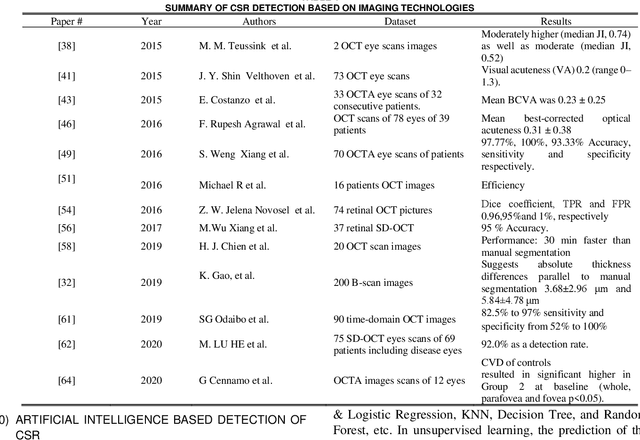
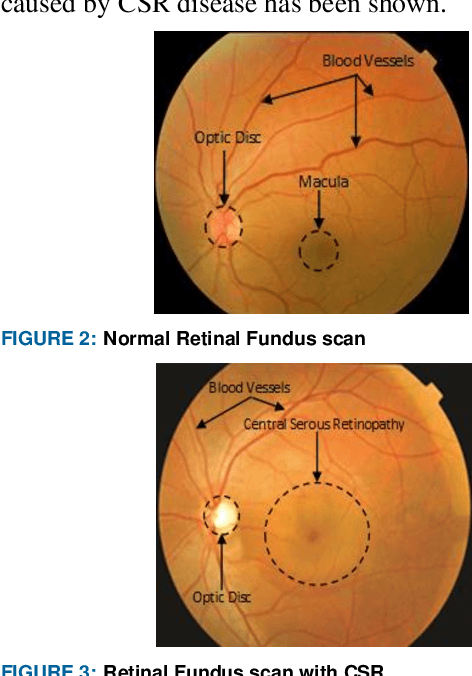
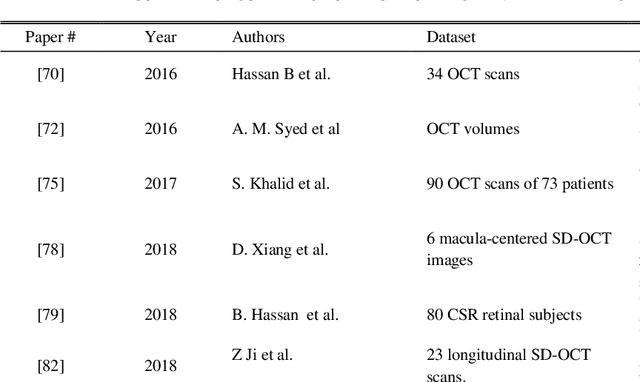
The Central Serous Retinopathy (CSR) is a major significant disease responsible for causing blindness and vision loss among numerous people across the globe. This disease is also known as the Central Serous Chorioretinopathy (CSC) occurs due to the accumulation of watery fluids behind the retina. The detection of CSR at an early stage allows taking preventive measures to avert any impairment to the human eye. Traditionally, several manual detection methods were developed for observing CSR, but they were proven to be inaccurate, unreliable, and time-consuming. Consequently, the research community embarked on seeking automated solutions for CSR detection. With the advent of modern technology in the 21st century, Artificial Intelligence (AI) techniques are immensely popular in numerous research fields including the automated CSR detection. This paper offers a comprehensive review of various advanced technologies and researches, contributing to the automated CSR detection in this scenario. Additionally, it discusses the benefits and limitations of many classical imaging methods ranging from Optical Coherence Tomography (OCT) and the Fundus imaging, to more recent approaches like AI based Machine/Deep Learning techniques. Study primary objective is to analyze and compare many Artificial Intelligence (AI) algorithms that have efficiently achieved automated CSR detection using OCT imaging. Furthermore, it describes various retinal datasets and strategies proposed for CSR assessment and accuracy. Finally, it is concluded that the most recent Deep Learning (DL) classifiers are performing accurate, fast, and reliable detection of CSR.
Self-supervised Learning of LiDAR Odometry for Robotic Applications
Nov 10, 2020


Reliable robot pose estimation is a key building block of many robot autonomy pipelines, with LiDAR localization being an active research domain. In this work, a versatile self-supervised LiDAR odometry estimation method is presented, in order to enable the efficient utilization of all available LiDAR data while maintaining real-time performance. The proposed approach selectively applies geometric losses during training, being cognizant of the amount of information that can be extracted from scan points. In addition, no labeled or ground-truth data is required, hence making the presented approach suitable for pose estimation in applications where accurate ground-truth is difficult to obtain. Furthermore, the presented network architecture is applicable to a wide range of environments and sensor modalities without requiring any network or loss function adjustments. The proposed approach is thoroughly tested for both indoor and outdoor real-world applications through a variety of experiments using legged, tracked and wheeled robots, demonstrating the suitability of learning-based LiDAR odometry for complex robotic applications.
Selection of Optimal Parameters in the Fast K-Word Proximity Search Based on Multi-component Key Indexes
Jan 09, 2021
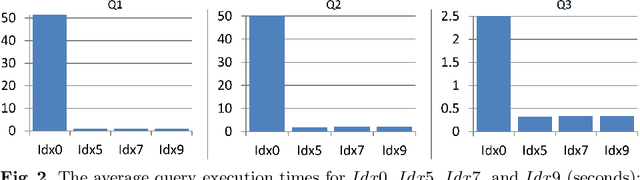
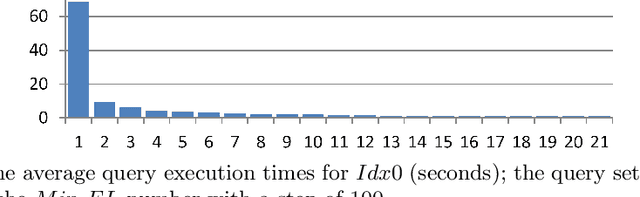
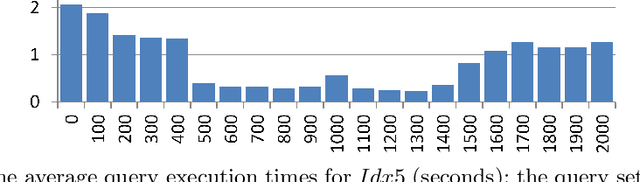
Proximity full-text search is commonly implemented in contemporary full-text search systems. Let us assume that the search query is a list of words. It is natural to consider a document as relevant if the queried words are near each other in the document. The proximity factor is even more significant for the case where the query consists of frequently occurring words. Proximity full-text search requires the storage of information for every occurrence in documents of every word that the user can search. For every occurrence of every word in a document, we employ additional indexes to store information about nearby words, that is, the words that occur in the document at distances from the given word of less than or equal to the MaxDistance parameter. We showed in previous works that these indexes can be used to improve the average query execution time by up to 130 times for queries that consist of words occurring with high-frequency. In this paper, we consider how both the search performance and the search quality depend on the value of MaxDistance and other parameters. Well-known GOV2 text collection is used in the experiments for reproducibility of the results. We propose a new index schema after the analysis of the results of the experiments. This is a pre-print of a contribution published in Supplementary Proceedings of the XXII International Conference on Data Analytics and Management in Data Intensive Domains (DAMDID/RCDL 2020), Voronezh, Russia, October 13-16, 2020, P. 336-350, published by CEUR Workshop Proceedings. The final authenticated version is available online at: http://ceur-ws.org/Vol-2790/
* Indexing: Scopus
Policy Teaching in Reinforcement Learning via Environment Poisoning Attacks
Nov 21, 2020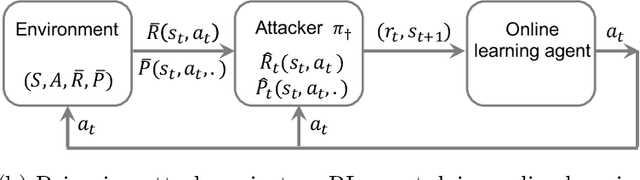
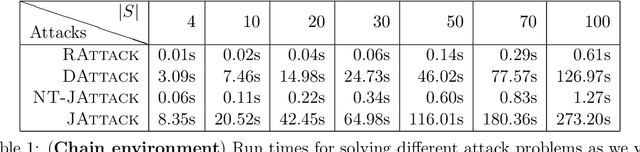
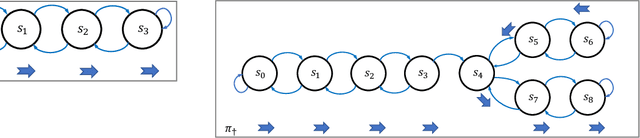
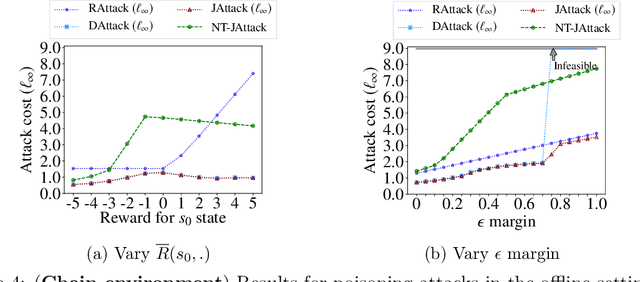
We study a security threat to reinforcement learning where an attacker poisons the learning environment to force the agent into executing a target policy chosen by the attacker. As a victim, we consider RL agents whose objective is to find a policy that maximizes reward in infinite-horizon problem settings. The attacker can manipulate the rewards and the transition dynamics in the learning environment at training-time, and is interested in doing so in a stealthy manner. We propose an optimization framework for finding an optimal stealthy attack for different measures of attack cost. We provide lower/upper bounds on the attack cost, and instantiate our attacks in two settings: (i) an offline setting where the agent is doing planning in the poisoned environment, and (ii) an online setting where the agent is learning a policy with poisoned feedback. Our results show that the attacker can easily succeed in teaching any target policy to the victim under mild conditions and highlight a significant security threat to reinforcement learning agents in practice.