 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Measuring Data Collection Quality for Community Healthcare
Nov 05, 2020
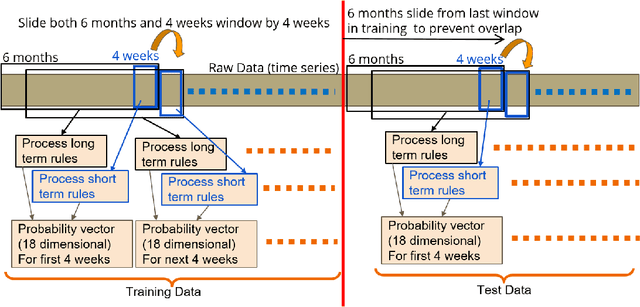
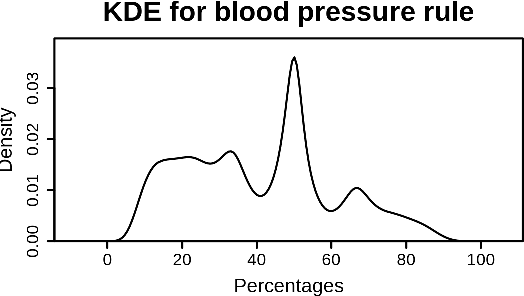
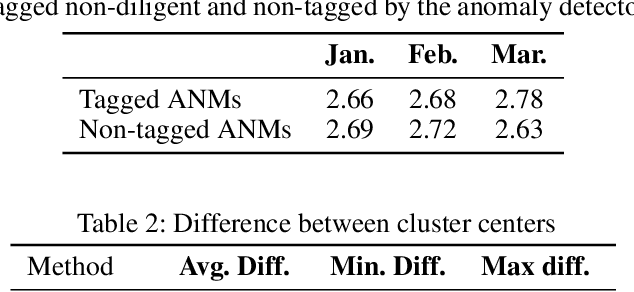
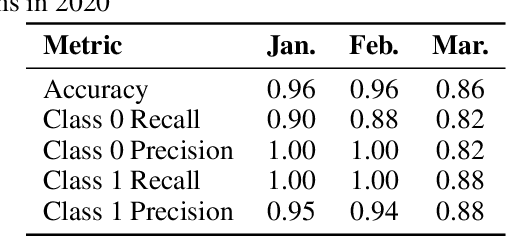
Machine learning has tremendous potential to provide targeted interventions in low-resource communities, however the availability of high-quality public health data is a significant challenge. In this work, we partner with field experts at an non-governmental organization (NGO) in India to define and test a data collection quality score for each health worker who collects data. This challenging unlabeled data problem is handled by building upon domain-expert's guidance to design a useful data representation that is then clustered to infer a data quality score. We also provide a more interpretable version of the score. These scores already provide for a measurement of data collection quality; in addition, we also predict the quality for future time steps and find our results to be very accurate. Our work was successfully field tested and is in the final stages of deployment in Rajasthan, India.
Diagnosing and Preventing Instabilities in Recurrent Video Processing
Oct 17, 2020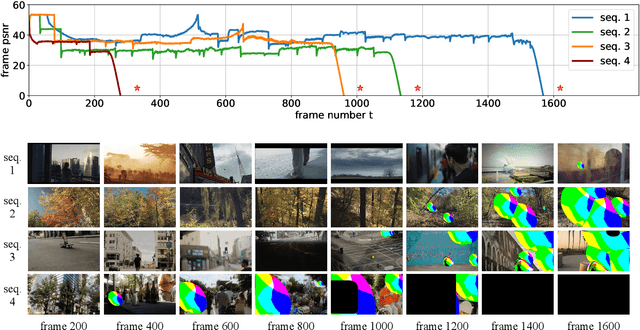
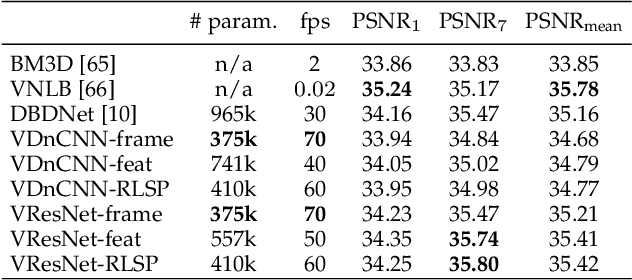
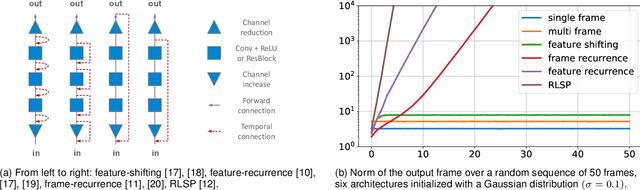
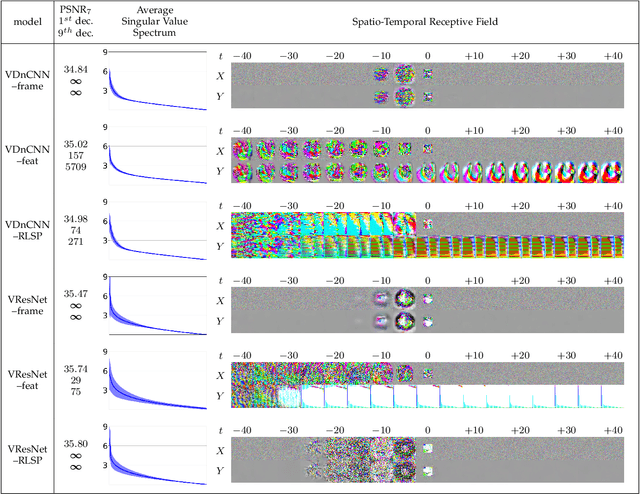
Recurrent models are becoming a popular choice for video enhancement tasks such as video denoising. In this work, we focus on their stability as dynamical systems and show that they tend to fail catastrophically at inference time on long video sequences. To address this issue, we (1) introduce a diagnostic tool which produces adversarial input sequences optimized to trigger instabilities and that can be interpreted as visualizations of spatio-temporal receptive fields, and (2) propose two approaches to enforce the stability of a model: constraining the spectral norm or constraining the stable rank of its convolutional layers. We then introduce Stable Rank Normalization of the Layers (SRNL), a new algorithm that enforces these constraints, and verify experimentally that it successfully results in stable recurrent video processing.
Controllable Text Generation with Focused Variation
Sep 25, 2020
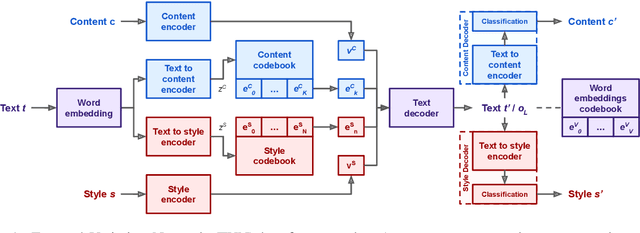
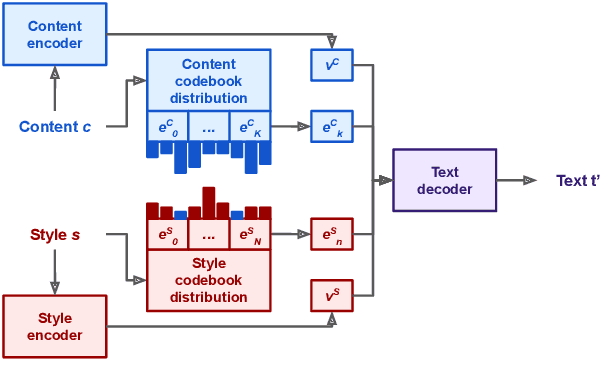
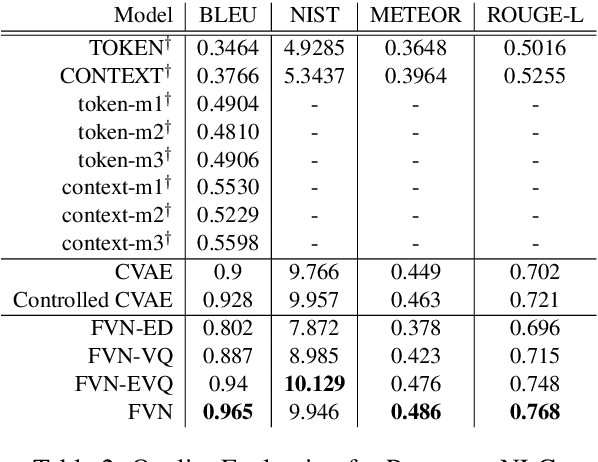
This work introduces Focused-Variation Network (FVN), a novel model to control language generation. The main problems in previous controlled language generation models range from the difficulty of generating text according to the given attributes, to the lack of diversity of the generated texts. FVN addresses these issues by learning disjoint discrete latent spaces for each attribute inside codebooks, which allows for both controllability and diversity, while at the same time generating fluent text. We evaluate FVN on two text generation datasets with annotated content and style, and show state-of-the-art performance as assessed by automatic and human evaluations.
Neural Random Projection: From the Initial Task To the Input Similarity Problem
Oct 09, 2020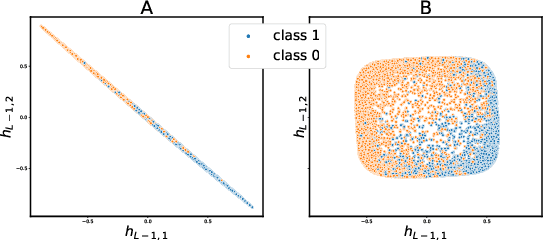
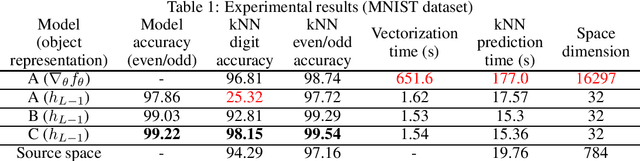
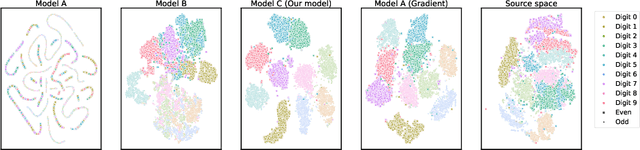
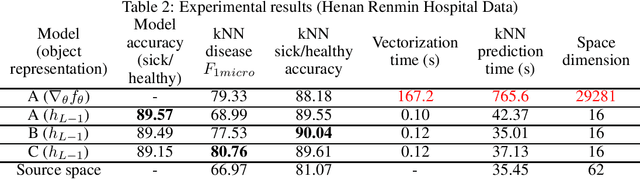
In this paper, we propose a novel approach for implicit data representation to evaluate similarity of input data using a trained neural network. In contrast to the previous approach, which uses gradients for representation, we utilize only the outputs from the last hidden layer of a neural network and do not use a backward step. The proposed technique explicitly takes into account the initial task and significantly reduces the size of the vector representation, as well as the computation time. The key point is minimization of information loss between layers. Generally, a neural network discards information that is not related to the problem, which makes the last hidden layer representation useless for input similarity task. In this work, we consider two main causes of information loss: correlation between neurons and insufficient size of the last hidden layer. To reduce the correlation between neurons we use orthogonal weight initialization for each layer and modify the loss function to ensure orthogonality of the weights during training. Moreover, we show that activation functions can potentially increase correlation. To solve this problem, we apply modified Batch-Normalization with Dropout. Using orthogonal weight matrices allow us to consider such neural networks as an application of the Random Projection method and get a lower bound estimate for the size of the last hidden layer. We perform experiments on MNIST and physical examination datasets. In both experiments, initially, we split a set of labels into two disjoint subsets to train a neural network for binary classification problem, and then use this model to measure similarity between input data and define hidden classes. Our experimental results show that the proposed approach achieves competitive results on the input similarity task while reducing both computation time and the size of the input representation.
Diffusion is All You Need for Learning on Surfaces
Dec 01, 2020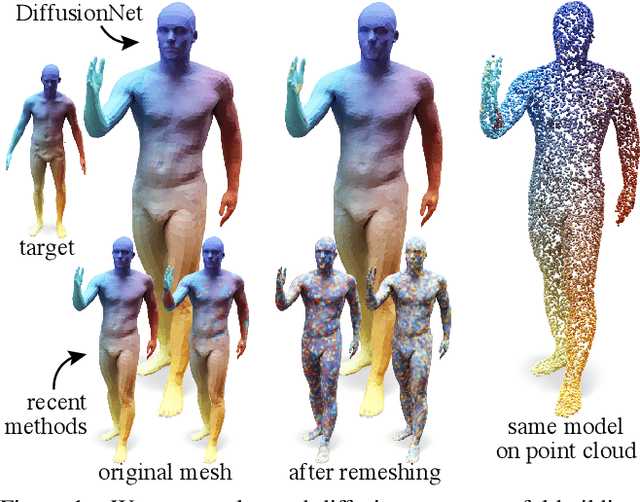

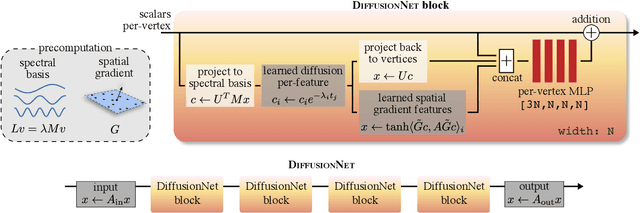
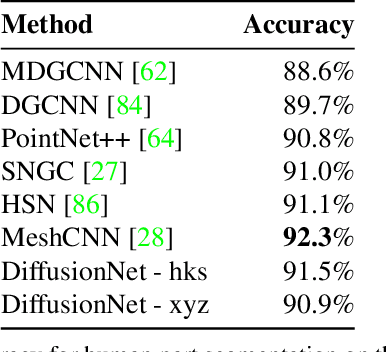
We introduce a new approach to deep learning on 3D surfaces such as meshes or point clouds. Our key insight is that a simple learned diffusion layer can spatially share data in a principled manner, replacing operations like convolution and pooling which are complicated and expensive on surfaces. The only other ingredients in our network are a spatial gradient operation, which uses dot-products of derivatives to encode tangent-invariant filters, and a multi-layer perceptron applied independently at each point. The resulting architecture, which we call DiffusionNet, is remarkably simple, efficient, and scalable. Continuously optimizing for spatial support avoids the need to pick neighborhood sizes or filter widths a priori, or worry about their impact on network size/training time. Furthermore, the principled, geometric nature of these networks makes them agnostic to the underlying representation and insensitive to discretization. In practice, this means significant robustness to mesh sampling, and even the ability to train on a mesh and evaluate on a point cloud. Our experiments demonstrate that these networks achieve state-of-the-art results for a variety of tasks on both meshes and point clouds, including surface classification, segmentation, and non-rigid correspondence.
Comparative analysis of criteria for filtering time series of word usage frequencies
Dec 10, 2017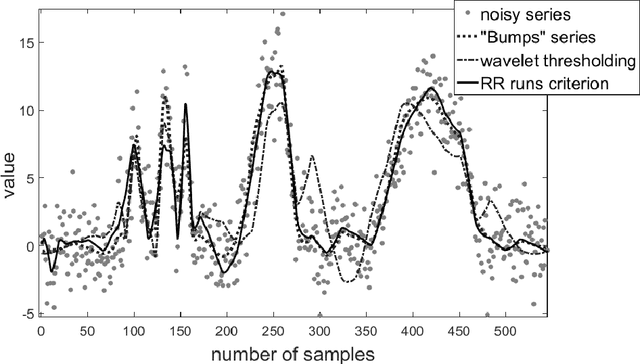
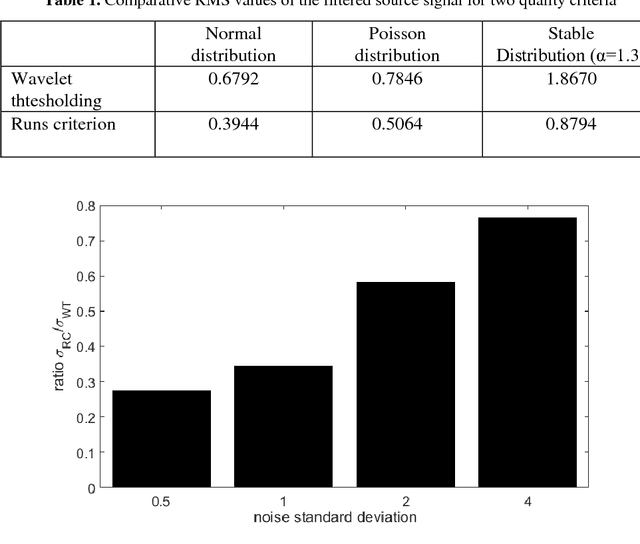
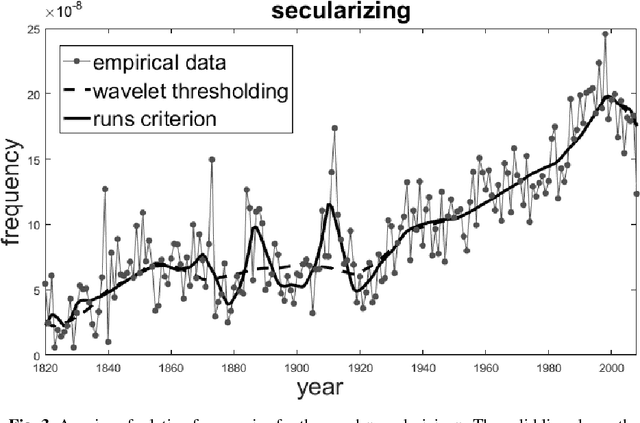
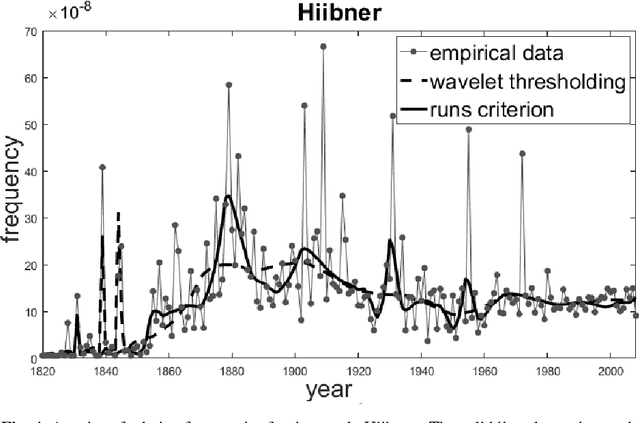
This paper describes a method of nonlinear wavelet thresholding of time series. The Ramachandran-Ranganathan runs test is used to assess the quality of approximation. To minimize the objective function, it is proposed to use genetic algorithms - one of the stochastic optimization methods. The suggested method is tested both on the model series and on the word frequency series using the Google Books Ngram data. It is shown that method of filtering which uses the runs criterion shows significantly better results compared with the standard wavelet thresholding. The method can be used when quality of filtering is of primary importance but not the speed of calculations.
A Three-Stage Self-Training Framework for Semi-Supervised Semantic Segmentation
Dec 01, 2020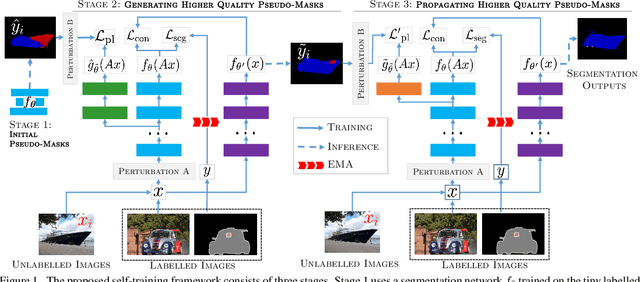
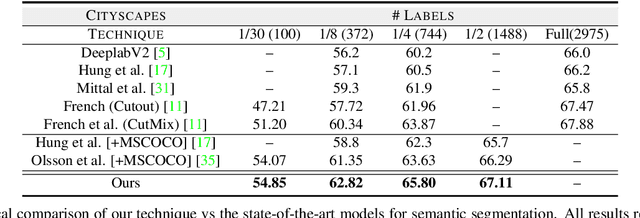
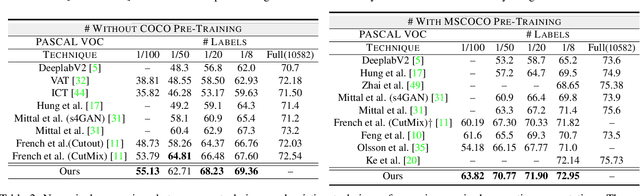

Semantic segmentation has been widely investigated in the community, in which the state of the art techniques are based on supervised models. Those models have reported unprecedented performance at the cost of requiring a large set of high quality segmentation masks. To obtain such annotations is highly expensive and time consuming, in particular, in semantic segmentation where pixel-level annotations are required. In this work, we address this problem by proposing a holistic solution framed as a three-stage self-training framework for semi-supervised semantic segmentation. The key idea of our technique is the extraction of the pseudo-masks statistical information to decrease uncertainty in the predicted probability whilst enforcing segmentation consistency in a multi-task fashion. We achieve this through a three-stage solution. Firstly, we train a segmentation network to produce rough pseudo-masks which predicted probability is highly uncertain. Secondly, we then decrease the uncertainty of the pseudo-masks using a multi-task model that enforces consistency whilst exploiting the rich statistical information of the data. We compare our approach with existing methods for semi-supervised semantic segmentation and demonstrate its state-of-the-art performance with extensive experiments.
Learning binary or real-valued time-series via spike-timing dependent plasticity
Dec 15, 2016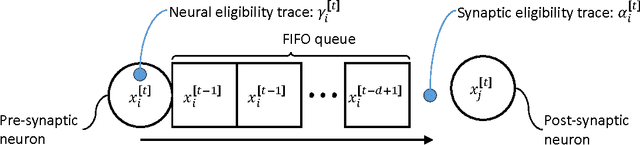
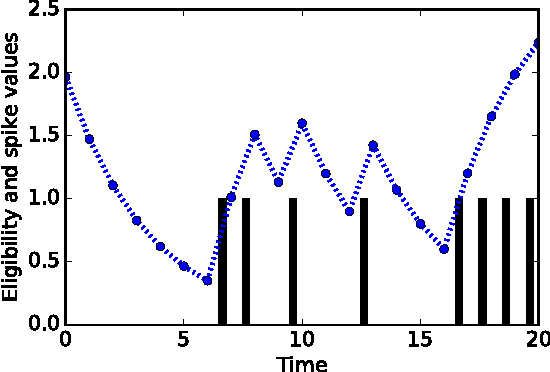
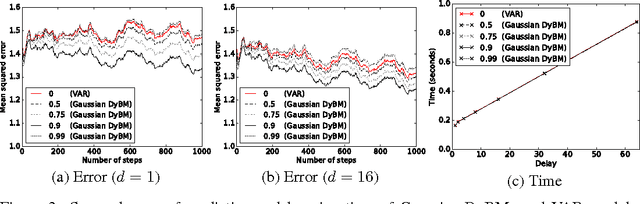
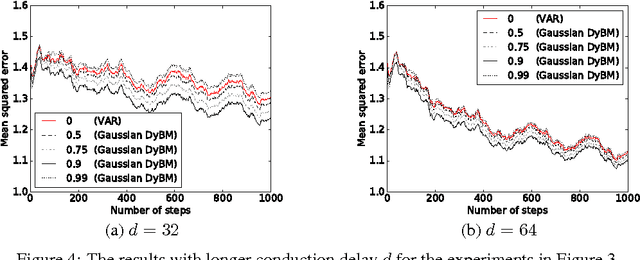
A dynamic Boltzmann machine (DyBM) has been proposed as a model of a spiking neural network, and its learning rule of maximizing the log-likelihood of given time-series has been shown to exhibit key properties of spike-timing dependent plasticity (STDP), which had been postulated and experimentally confirmed in the field of neuroscience as a learning rule that refines the Hebbian rule. Here, we relax some of the constraints in the DyBM in a way that it becomes more suitable for computation and learning. We show that learning the DyBM can be considered as logistic regression for binary-valued time-series. We also show how the DyBM can learn real-valued data in the form of a Gaussian DyBM and discuss its relation to the vector autoregressive (VAR) model. The Gaussian DyBM extends the VAR by using additional explanatory variables, which correspond to the eligibility traces of the DyBM and capture long term dependency of the time-series. Numerical experiments show that the Gaussian DyBM significantly improves the predictive accuracy over VAR.
Selection of Optimal Parameters in the Fast K-Word Proximity Search Based on Multi-component Key Indexes
Jan 09, 2021
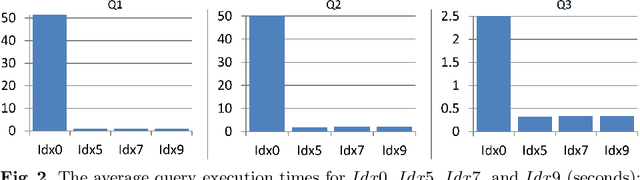
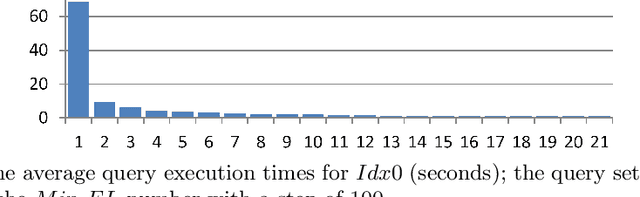
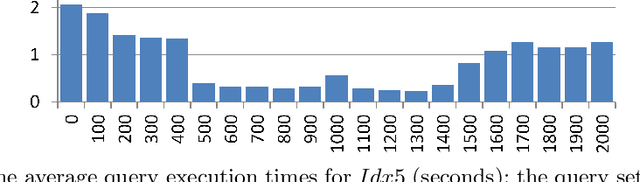
Proximity full-text search is commonly implemented in contemporary full-text search systems. Let us assume that the search query is a list of words. It is natural to consider a document as relevant if the queried words are near each other in the document. The proximity factor is even more significant for the case where the query consists of frequently occurring words. Proximity full-text search requires the storage of information for every occurrence in documents of every word that the user can search. For every occurrence of every word in a document, we employ additional indexes to store information about nearby words, that is, the words that occur in the document at distances from the given word of less than or equal to the MaxDistance parameter. We showed in previous works that these indexes can be used to improve the average query execution time by up to 130 times for queries that consist of words occurring with high-frequency. In this paper, we consider how both the search performance and the search quality depend on the value of MaxDistance and other parameters. Well-known GOV2 text collection is used in the experiments for reproducibility of the results. We propose a new index schema after the analysis of the results of the experiments. This is a pre-print of a contribution published in Supplementary Proceedings of the XXII International Conference on Data Analytics and Management in Data Intensive Domains (DAMDID/RCDL 2020), Voronezh, Russia, October 13-16, 2020, P. 336-350, published by CEUR Workshop Proceedings. The final authenticated version is available online at: http://ceur-ws.org/Vol-2790/
* Indexing: Scopus
Spatio-Temporal Graph Scattering Transform
Dec 10, 2020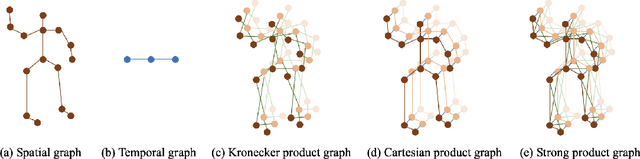
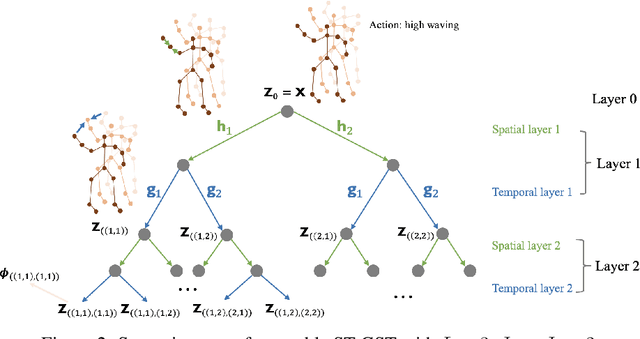

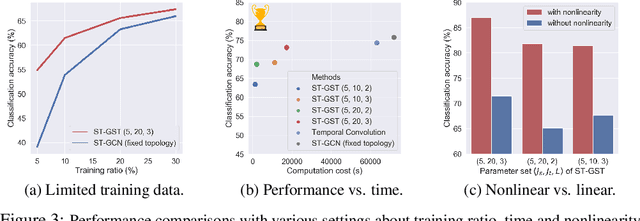
Although spatio-temporal graph neural networks have achieved great empirical success in handling multiple correlated time series, they may be impractical in some real-world scenarios due to a lack of sufficient high-quality training data. Furthermore, spatio-temporal graph neural networks lack theoretical interpretation. To address these issues, we put forth a novel mathematically designed framework to analyze spatio-temporal data. Our proposed spatio-temporal graph scattering transform (ST-GST) extends traditional scattering transforms to the spatio-temporal domain. It performs iterative applications of spatio-temporal graph wavelets and nonlinear activation functions, which can be viewed as a forward pass of spatio-temporal graph convolutional networks without training. Since all the filter coefficients in ST-GST are mathematically designed, it is promising for the real-world scenarios with limited training data, and also allows for a theoretical analysis, which shows that the proposed ST-GST is stable to small perturbations of input signals and structures. Finally, our experiments show that i) ST-GST outperforms spatio-temporal graph convolutional networks by an increase of 35% in accuracy for MSR Action3D dataset; ii) it is better and computationally more efficient to design the transform based on separable spatio-temporal graphs than the joint ones; and iii) the nonlinearity in ST-GST is critical to empirical performance.