 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficiently Solving MDPs with Stochastic Mirror Descent
Aug 28, 2020
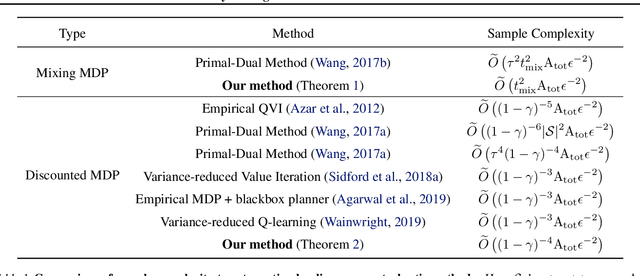
We present a unified framework based on primal-dual stochastic mirror descent for approximately solving infinite-horizon Markov decision processes (MDPs) given a generative model. When applied to an average-reward MDP with $A_{tot}$ total state-action pairs and mixing time bound $t_{mix}$ our method computes an $\epsilon$-optimal policy with an expected $\widetilde{O}(t_{mix}^2 A_{tot} \epsilon^{-2})$ samples from the state-transition matrix, removing the ergodicity dependence of prior art. When applied to a $\gamma$-discounted MDP with $A_{tot}$ total state-action pairs our method computes an $\epsilon$-optimal policy with an expected $\widetilde{O}((1-\gamma)^{-4} A_{tot} \epsilon^{-2})$ samples, matching the previous state-of-the-art up to a $(1-\gamma)^{-1}$ factor. Both methods are model-free, update state values and policies simultaneously, and run in time linear in the number of samples taken. We achieve these results through a more general stochastic mirror descent framework for solving bilinear saddle-point problems with simplex and box domains and we demonstrate the flexibility of this framework by providing further applications to constrained MDPs.
High-Fidelity Neural Human Motion Transfer from Monocular Video
Dec 20, 2020
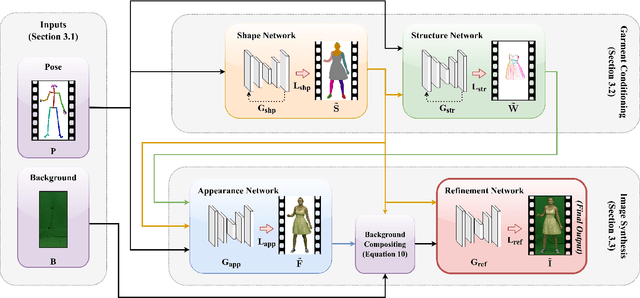


Video-based human motion transfer creates video animations of humans following a source motion. Current methods show remarkable results for tightly-clad subjects. However, the lack of temporally consistent handling of plausible clothing dynamics, including fine and high-frequency details, significantly limits the attainable visual quality. We address these limitations for the first time in the literature and present a new framework which performs high-fidelity and temporally-consistent human motion transfer with natural pose-dependent non-rigid deformations, for several types of loose garments. In contrast to the previous techniques, we perform image generation in three subsequent stages, synthesizing human shape, structure, and appearance. Given a monocular RGB video of an actor, we train a stack of recurrent deep neural networks that generate these intermediate representations from 2D poses and their temporal derivatives. Splitting the difficult motion transfer problem into subtasks that are aware of the temporal motion context helps us to synthesize results with plausible dynamics and pose-dependent detail. It also allows artistic control of results by manipulation of individual framework stages. In the experimental results, we significantly outperform the state-of-the-art in terms of video realism. Our code and data will be made publicly available.
Asset Price Forecasting using Recurrent Neural Networks
Oct 19, 2020
This thesis serves three primary purposes, first of which is to forecast two stocks, i.e. Goldman Sachs (GS) and General Electric (GE). In order to forecast stock prices, we used a long short-term memory (LSTM) model in which we inputted the prices of two other stocks that lie in rather close correlation with GS. Other models such as ARIMA were used as benchmark. Empirical results manifest the practical challenges when using LSTM for forecasting stocks. One of the main upheavals was a recurring lag which we called "forecasting lag". The second purpose is to develop a more general and objective perspective on the task of time series forecasting so that it could be applied to assist in an arbitrary that of forecasting by ANNs. Thus, attempts are made for distinguishing previous works by certain criteria (introduced by a review paper written by Ahmed Tealab) so as to summarise those including effective information. The summarised information is then unified and expressed through a common terminology that can be applied to different steps of a time series forecasting task. The last but not least purpose of this thesis is to elaborate on a mathematical framework on which ANNs are based. We are going to use the framework introduced in the book "Neural Networks in Mathematical Framework" by Anthony L. Caterini in which the structure of a generic neural network is introduced and the gradient descent algorithm (which incorporates backpropagation) is introduced in terms of their described framework. In the end, we use this framework for a specific architecture, which is recurrent neural networks on which we concentrated and our implementations are based. The book proves its theorems mostly for classification case. Instead, we proved theorems for regression case, which is the case of our problem.
Generating Human-Like Movement: A Comparison Between Two Approaches Based on Environmental Features
Dec 11, 2020

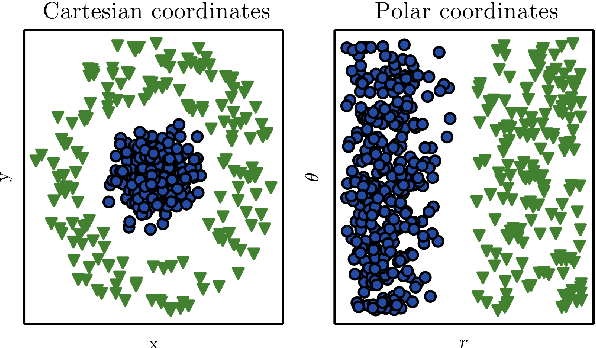
Modelling realistic human behaviours in simulation is an ongoing challenge that resides between several fields like social sciences, philosophy, and artificial intelligence. Human movement is a special type of behaviour driven by intent (e.g. to get groceries) and the surrounding environment (e.g. curiosity to see new interesting places). Services available online and offline do not normally consider the environment when planning a path, which is decisive especially on a leisure trip. Two novel algorithms have been presented to generate human-like trajectories based on environmental features. The Attraction-Based A* algorithm includes in its computation information from the environmental features meanwhile, the Feature-Based A* algorithm also injects information from the real trajectories in its computation. The human-likeness aspect has been tested by a human expert judging the final generated trajectories as realistic. This paper presents a comparison between the two approaches in some key metrics like efficiency, efficacy, and hyper-parameters sensitivity. We show how, despite generating trajectories that are closer to the real one according to our predefined metrics, the Feature-Based A* algorithm fall short in time efficiency compared to the Attraction-Based A* algorithm, hindering the usability of the model in the real world.
Contraction Clustering (RASTER): A Very Fast Big Data Algorithm for Sequential and Parallel Density-Based Clustering in Linear Time, Constant Memory, and a Single Pass
Jul 08, 2019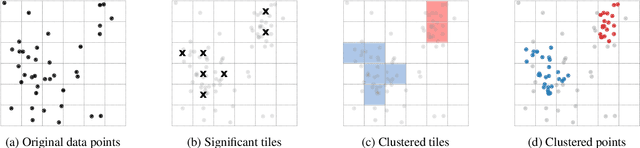
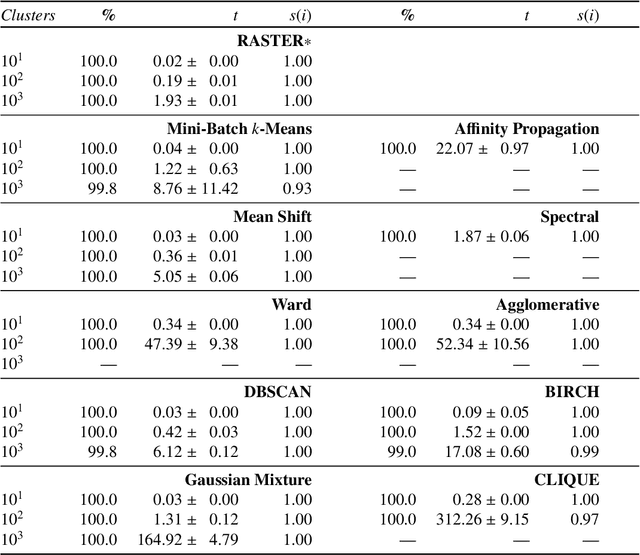
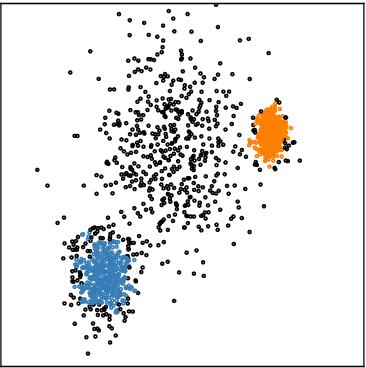
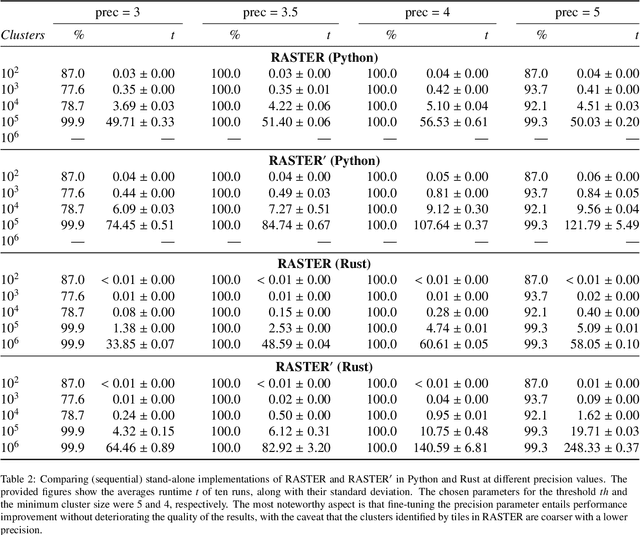
Clustering is an essential data mining tool for analyzing and grouping similar objects. In big data applications, however, many clustering algorithms are infeasible due to their high memory requirements and/or unfavorable runtime complexity. In contrast, Contraction Clustering (RASTER) is a single-pass algorithm for identifying density-based clusters with linear time complexity. Due to its favorable runtime and the fact that its memory requirements are constant, this algorithm is highly suitable for big data applications where the amount of data to be processed is huge. It consists of two steps: (1) a contraction step which projects objects onto tiles and (2) an agglomeration step which groups tiles into clusters. This algorithm is extremely fast in both sequential and parallel execution. In single-threaded execution on a contemporary workstation, an implementation in Rust processes a batch of 500 million points with 1 million clusters in less than 50 seconds. The speedup due to parallelization is significant, amounting to a factor of around 4 on an 8-core machine.
Multi-stream Convolutional Neural Network with Frequency Selection for Robust Speaker Verification
Jan 12, 2021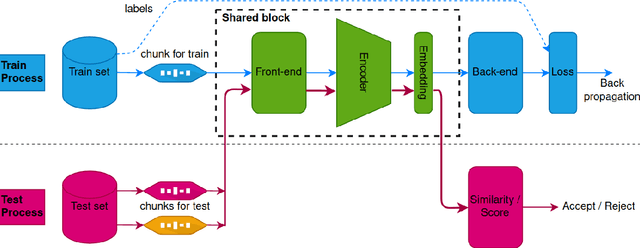
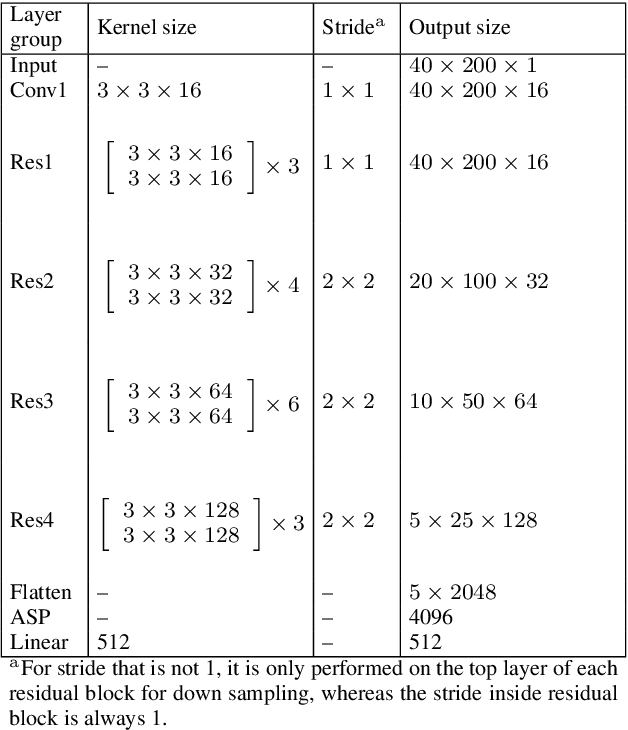
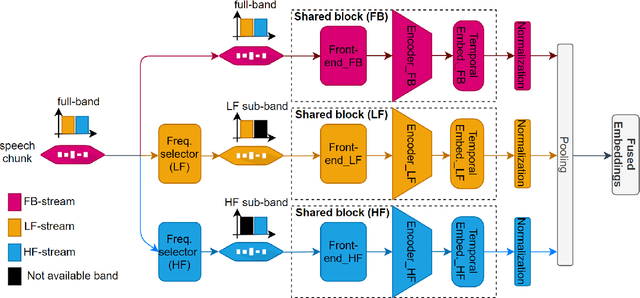

Speaker verification aims to verify whether an input speech corresponds to the claimed speaker, and conventionally, this kind of system is deployed based on single-stream scenario, wherein the feature extractor operates in full frequency range. In this paper, we hypothesize that machine can learn enough knowledge to do classification task when listening to partial frequency range instead of full frequency range, which is so called frequency selection technique, and further propose a novel framework of multi-stream Convolutional Neural Network (CNN) with this technique for speaker verification tasks. The proposed framework accommodates diverse temporal embeddings generated from multiple streams to enhance the robustness of acoustic modeling. For the diversity of temporal embeddings, we consider feature augmentation with frequency selection, which is to manually segment the full-band of frequency into several sub-bands, and the feature extractor of each stream can select which sub-bands to use as target frequency domain. Different from conventional single-stream solution wherein each utterance would only be processed for one time, in this framework, there are multiple streams processing it in parallel. The input utterance for each stream is pre-processed by a frequency selector within specified frequency range, and post-processed by mean normalization. The normalized temporal embeddings of each stream will flow into a pooling layer to generate fused embeddings. We conduct extensive experiments on VoxCeleb dataset, and the experimental results demonstrate that multi-stream CNN significantly outperforms single-stream baseline with 20.53 % of relative improvement in minimum Decision Cost Function (minDCF).
Imitation-Based Active Camera Control with Deep Convolutional Neural Network
Dec 11, 2020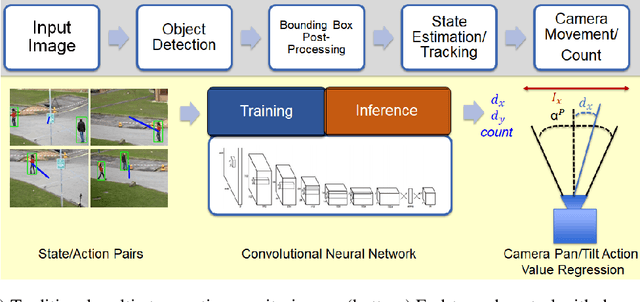

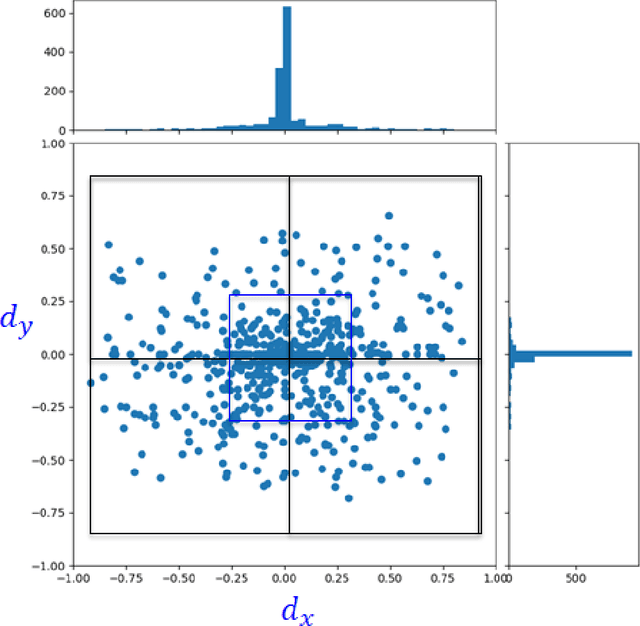
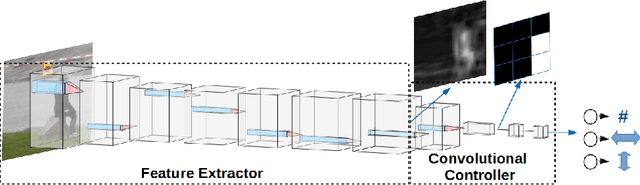
The increasing need for automated visual monitoring and control for applications such as smart camera surveillance, traffic monitoring, and intelligent environments, necessitates the improvement of methods for visual active monitoring. Traditionally, the active monitoring task has been handled through a pipeline of modules such as detection, filtering, and control. In this paper we frame active visual monitoring as an imitation learning problem to be solved in a supervised manner using deep learning, to go directly from visual information to camera movement in order to provide a satisfactory solution by combining computer vision and control. A deep convolutional neural network is trained end-to-end as the camera controller that learns the entire processing pipeline needed to control a camera to follow multiple targets and also estimate their density from a single image. Experimental results indicate that the proposed solution is robust to varying conditions and is able to achieve better monitoring performance both in terms of number of targets monitored as well as in monitoring time than traditional approaches, while reaching up to 25 FPS. Thus making it a practical and affordable solution for multi-target active monitoring in surveillance and smart-environment applications.
Estimation of Trocar and Tool Interaction Forces on the da Vinci Research Kit with Two-Step Deep Learning
Dec 11, 2020
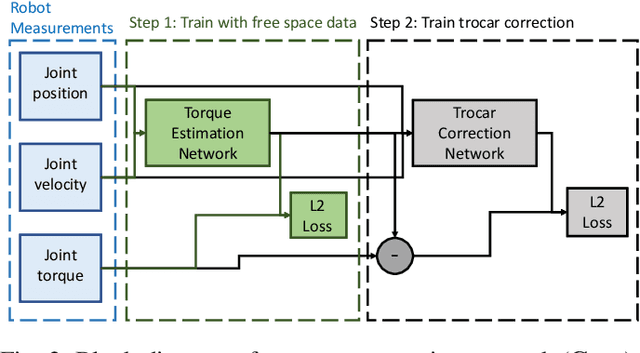
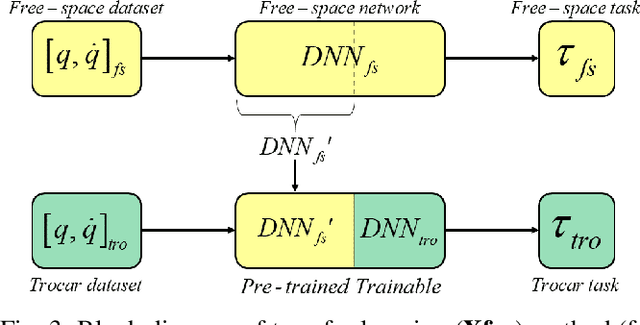
Measurement of environment interaction forces during robotic minimally-invasive surgery would enable haptic feedback to the surgeon, thereby solving one long-standing limitation. Estimating this force from existing sensor data avoids the challenge of retrofitting systems with force sensors, but is difficult due to mechanical effects such as friction and compliance in the robot mechanism. We have previously shown that neural networks can be trained to estimate the internal robot joint torques, thereby enabling estimation of external forces. In this work, we extend the method to estimate external Cartesian forces and torques, and also present a two-step approach to adapt to the specific surgical setup by compensating for forces due to the interactions between the instrument shaft and cannula seal and between the trocar and patient body. Experiments show that this approach provides estimates of external forces and torques within a mean root-mean-square error (RMSE) of 2 N and 0.08 Nm, respectively. Furthermore, the two-step approach can add as little as 5 minutes to the surgery setup time, with about 4 minutes to collect intraoperative training data and 1 minute to train the second-step network.
Adversarial Robustness Across Representation Spaces
Dec 01, 2020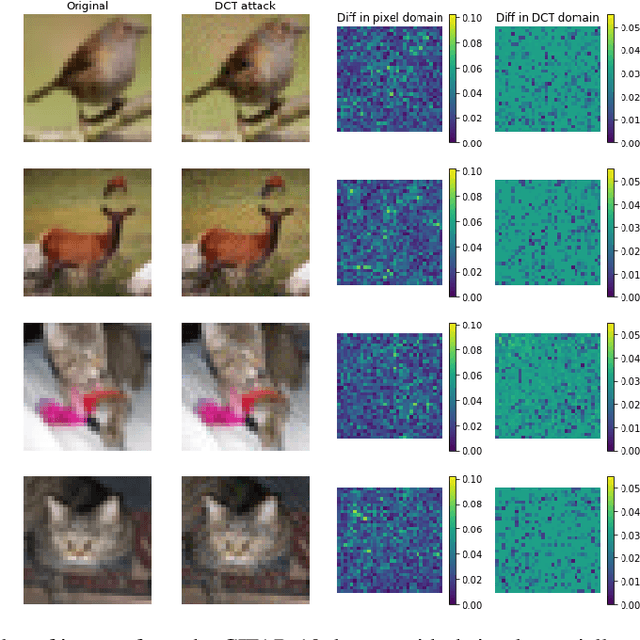
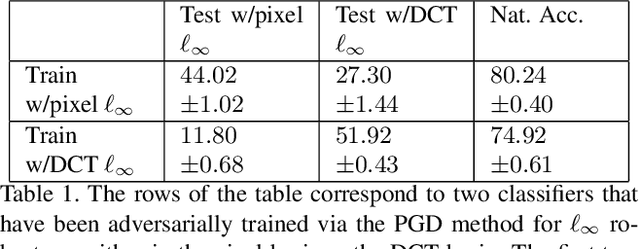

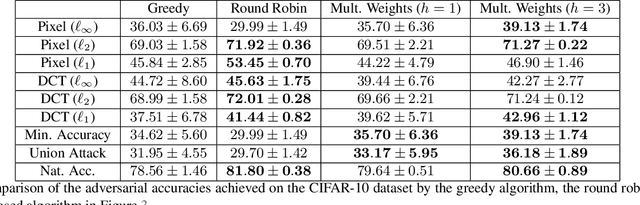
Adversarial robustness corresponds to the susceptibility of deep neural networks to imperceptible perturbations made at test time. In the context of image tasks, many algorithms have been proposed to make neural networks robust to adversarial perturbations made to the input pixels. These perturbations are typically measured in an $\ell_p$ norm. However, robustness often holds only for the specific attack used for training. In this work we extend the above setting to consider the problem of training of deep neural networks that can be made simultaneously robust to perturbations applied in multiple natural representation spaces. For the case of image data, examples include the standard pixel representation as well as the representation in the discrete cosine transform~(DCT) basis. We design a theoretically sound algorithm with formal guarantees for the above problem. Furthermore, our guarantees also hold when the goal is to require robustness with respect to multiple $\ell_p$ norm based attacks. We then derive an efficient practical implementation and demonstrate the effectiveness of our approach on standard datasets for image classification.
Improving Neural Network with Uniform Sparse Connectivity
Dec 01, 2020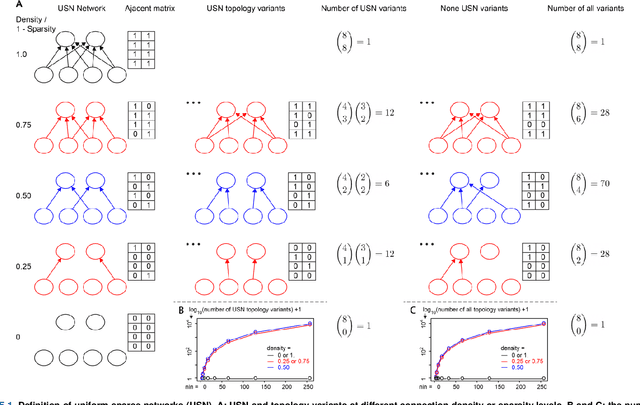
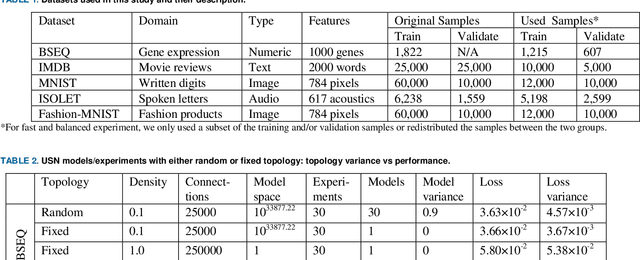
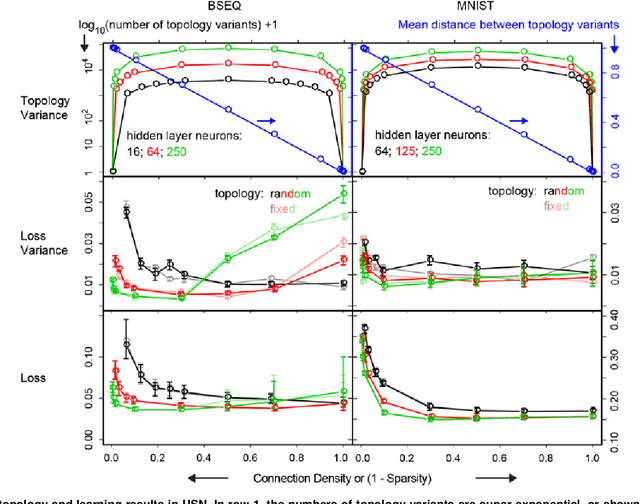
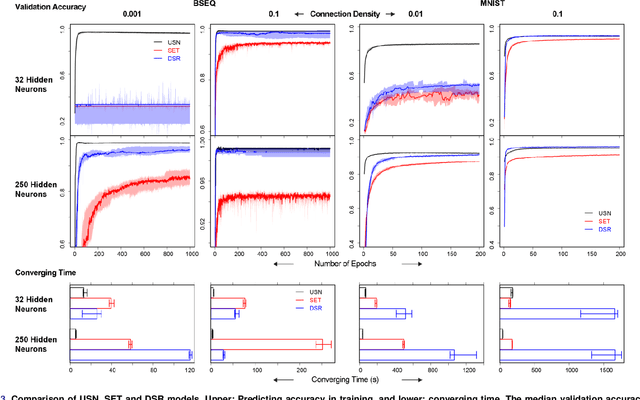
Neural network forms the foundation of deep learning and numerous AI applications. Classical neural networks are fully connected, expensive to train and prone to overfitting. Sparse networks tend to have convoluted structure search, suboptimal performance and limited usage. We proposed the novel uniform sparse network (USN) with even and sparse connectivity within each layer. USN has one striking property that its performance is independent of the substantial topology variation and enormous model space, thus offers a search-free solution to all above mentioned issues of neural networks. USN consistently and substantially outperforms the state-of-the-art sparse network models in prediction accuracy, speed and robustness. It even achieves higher prediction accuracy than the fully connected network with only 0.55% parameters and 1/4 computing time and resources. Importantly, USN is conceptually simple as a natural generalization of fully connected network with multiple improvements in accuracy, robustness and scalability. USN can replace the latter in a range of applications, data types and deep learning architectures. We have made USN open source at https://github.com/datapplab/sparsenet.