 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Population-based Hybrid Approach to Hyperparameter Optimization for Neural Networks
Nov 22, 2020
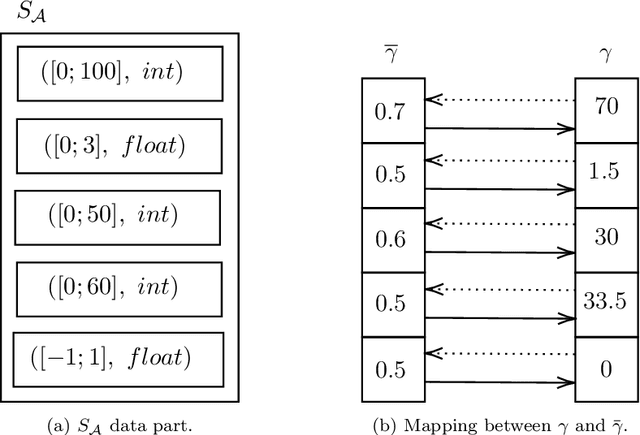
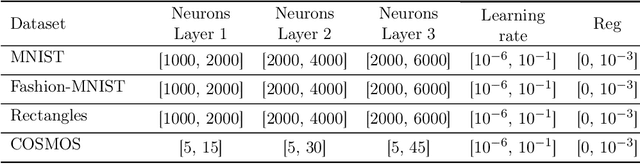
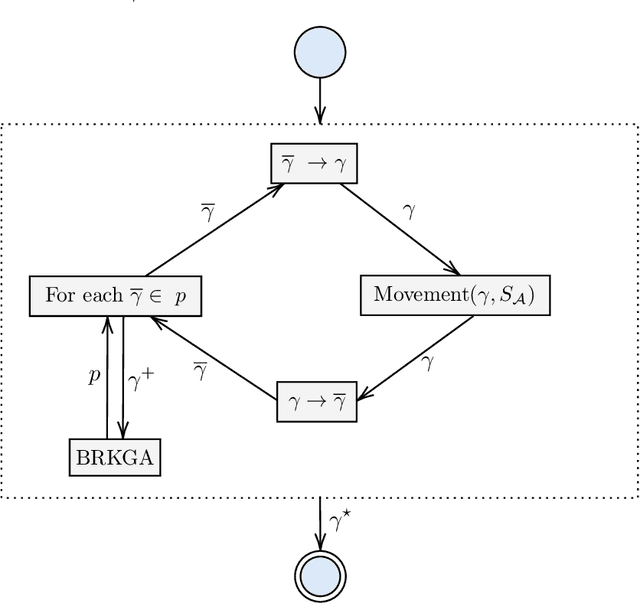

In recent years, large amounts of data have been generated, and computer power has kept growing. This scenario has led to a resurgence in the interest in artificial neural networks. One of the main challenges in training effective neural network models is finding the right combination of hyperparameters to be used. Indeed, the choice of an adequate approach to search the hyperparameter space directly influences the accuracy of the resulting neural network model. Common approaches for hyperparameter optimization are Grid Search, Random Search, and Bayesian Optimization. There are also population-based methods such as CMA-ES. In this paper, we present HBRKGA, a new population-based approach for hyperparameter optimization. HBRKGA is a hybrid approach that combines the Biased Random Key Genetic Algorithm with a Random Walk technique to search the hyperparameter space efficiently. Several computational experiments on eight different datasets were performed to assess the effectiveness of the proposed approach. Results showed that HBRKGA could find hyperparameter configurations that outperformed (in terms of predictive quality) the baseline methods in six out of eight datasets while showing a reasonable execution time.
Classification with Rejection Based on Cost-sensitive Classification
Oct 31, 2020
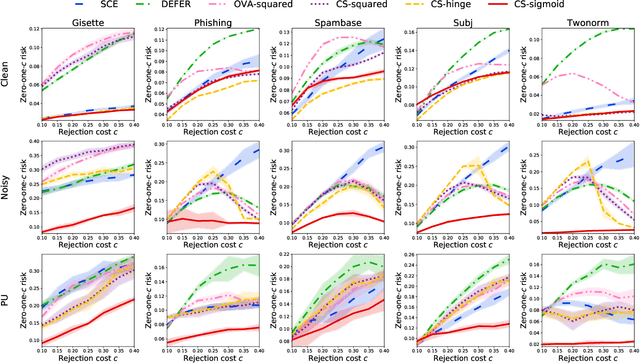
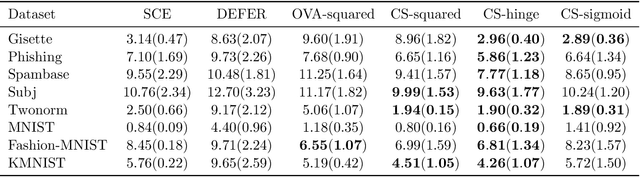

The goal of classification with rejection is to avoid risky misclassification in error-critical applications such as medical diagnosis and product inspection. In this paper, based on the relationship between classification with rejection and cost-sensitive classification, we propose a novel method of classification with rejection by learning an ensemble of cost-sensitive classifiers, which satisfies all the following properties for the first time: (i) it can avoid estimating class-posterior probabilities, resulting in improved classification accuracy. (ii) it allows a flexible choice of losses including non-convex ones, (iii) it does not require complicated modifications when using different losses, (iv) it is applicable to both binary and multiclass cases, and (v) it is theoretically justifiable for any classification-calibrated loss. Experimental results demonstrate the usefulness of our proposed approach in clean-labeled, noisy-labeled, and positive-unlabeled classification.
Complex networks for event detection in heterogeneous high volume news streams
May 28, 2020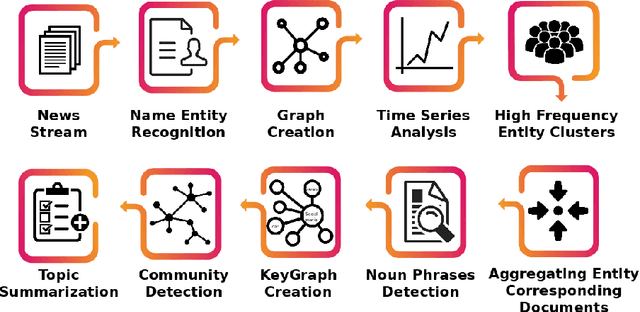
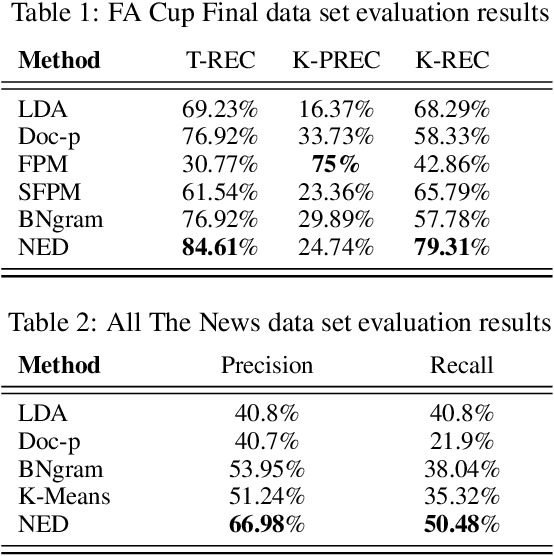
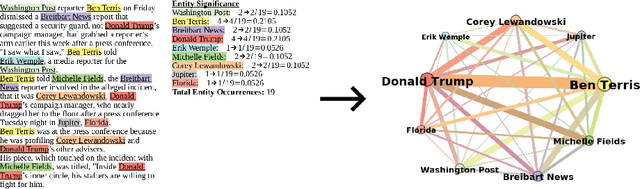
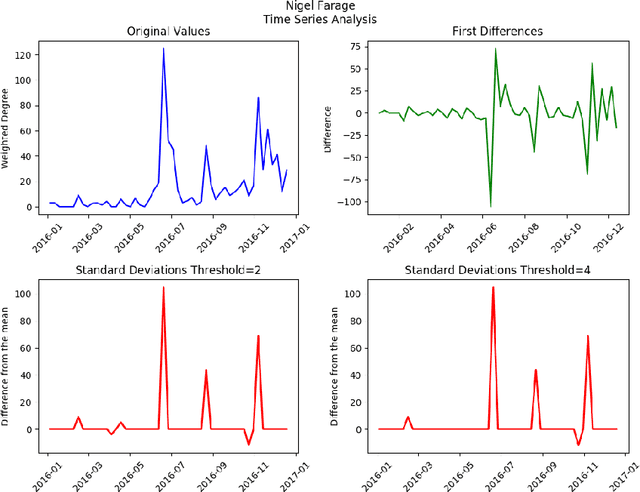
Detecting important events in high volume news streams is an important task for a variety of purposes.The volume and rate of online news increases the need for automated event detection methods thatcan operate in real time. In this paper we develop a network-based approach that makes the workingassumption that important news events always involve named entities (such as persons, locationsand organizations) that are linked in news articles. Our approach uses natural language processingtechniques to detect these entities in a stream of news articles and then creates a time-stamped seriesof networks in which the detected entities are linked by co-occurrence in articles and sentences. Inthis prototype, weighted node degree is tracked over time and change-point detection used to locateimportant events. Potential events are characterized and distinguished using community detectionon KeyGraphs that relate named entities and informative noun-phrases from related articles. Thismethodology already produces promising results and will be extended in future to include a widervariety of complex network analysis techniques.
Controlling the Risk of Conversational Search via Reinforcement Learning
Jan 15, 2021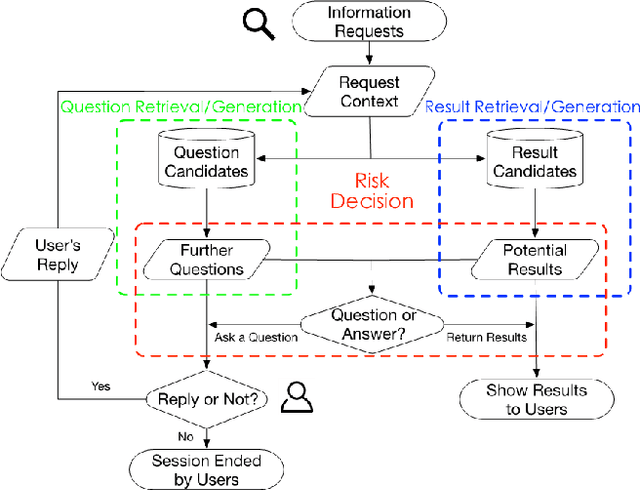

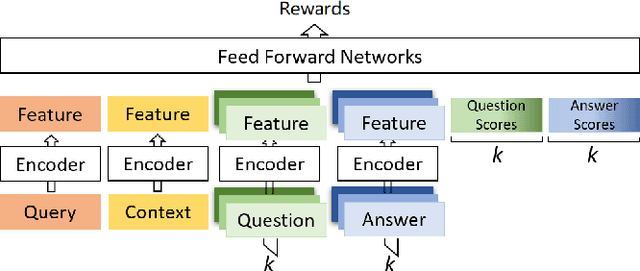
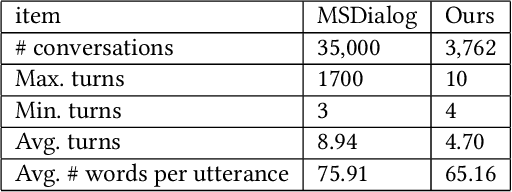
Users often formulate their search queries with immature language without well-developed keywords and complete structures. Such queries fail to express their true information needs and raise ambiguity as fragmental language often yield various interpretations and aspects. This gives search engines a hard time processing and understanding the query, and eventually leads to unsatisfactory retrieval results. An alternative approach to direct answer while facing an ambiguous query is to proactively ask clarifying questions to the user. Recent years have seen many works and shared tasks from both NLP and IR community about identifying the need for asking clarifying question and methodology to generate them. An often neglected fact by these works is that although sometimes the need for clarifying questions is correctly recognized, the clarifying questions these system generate are still off-topic and dissatisfaction provoking to users and may just cause users to leave the conversation. In this work, we propose a risk-aware conversational search agent model to balance the risk of answering user's query and asking clarifying questions. The agent is fully aware that asking clarifying questions can potentially collect more information from user, but it will compare all the choices it has and evaluate the risks. Only after then, it will make decision between answering or asking. To demonstrate that our system is able to retrieve better answers, we conduct experiments on the MSDialog dataset which contains real-world customer service conversations from Microsoft products community. We also purpose a reinforcement learning strategy which allows us to train our model on the original dataset directly and saves us from any further data annotation efforts. Our experiment results show that our risk-aware conversational search agent is able to significantly outperform strong non-risk-aware baselines.
Static object detection and segmentation in videos based on dual foregrounds difference with noise filtering
Dec 19, 2020
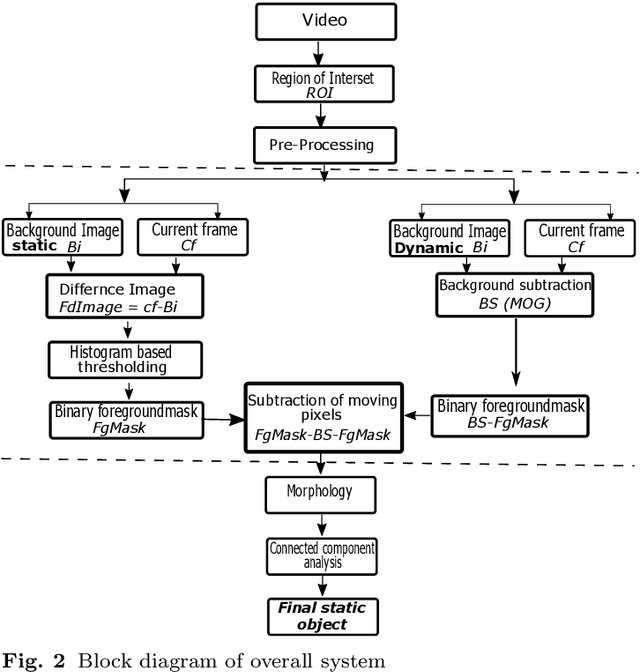


This paper presents static object detection and segmentation method in videos from cluttered scenes. Robust static object detection is still challenging task due to presence of moving objects in many surveillance applications. The level of difficulty is extremely influenced by on how you label the object to be identified as static that do not establish the original background but appeared in the video at different time. In this context, background subtraction technique based on the frame difference concept is applied to the identification of static objects. Firstly, we estimate a frame differencing foreground mask image by computing the difference of each frame with respect to a static reference frame. The Mixture of Gaussian MOG method is applied to detect the moving particles and then outcome foreground mask is subtracted from frame differencing foreground mask. Pre-processing techniques, illumination equalization and de-hazing methods are applied to handle low contrast and to reduce the noise from scattered materials in the air e.g. water droplets and dust particles. Finally, a set of mathematical morphological operation and largest connected-component analysis is applied to segment the object and suppress the noise. The proposed method was built for rock breaker station application and effectively validated with real, synthetic and two public data sets. The results demonstrate the proposed approach can robustly detect, segmented the static objects without any prior information of tracking.
LAVAPilot: Lightweight UAV Trajectory Planner with Situational Awareness for Embedded Autonomy to Track and Locate Radio-tags
Jul 31, 2020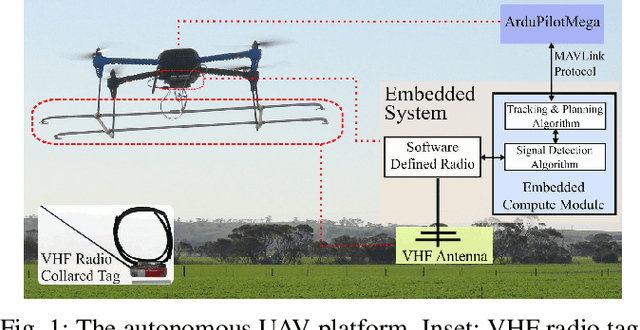
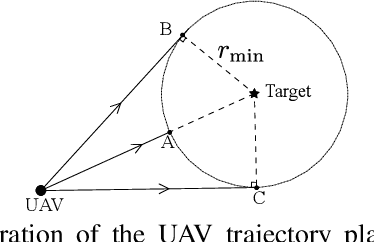
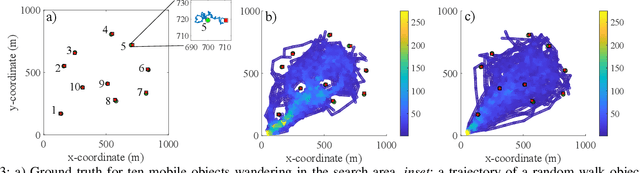
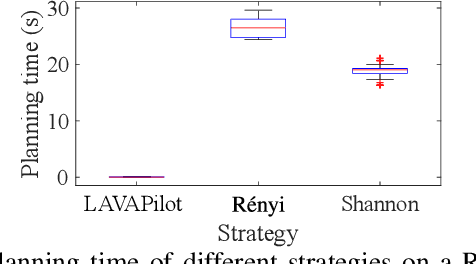
Tracking and locating radio-tagged wildlife is a labor-intensive and time-consuming task necessary in wildlife conservation. In this article, we focus on the problem of achieving embedded autonomy for a resource-limited aerial robot for the task capable of avoiding undesirable disturbances to wildlife. We employ a lightweight sensor system capable of simultaneous (noisy) measurements of radio signal strength information from multiple tags for estimating object locations. We formulate a new lightweight task-based trajectory planning method-LAVAPilot-with a greedy evaluation strategy and a void functional formulation to achieve situational awareness to maintain a safe distance from objects of interest. Conceptually, we embed our intuition of moving closer to reduce the uncertainty of measurements into LAVAPilot instead of employing a computationally intensive information gain based planning strategy. We employ LAVAPilot and the sensor to build a lightweight aerial robot platform with fully embedded autonomy for jointly tracking and planning to track and locate multiple VHF radio collar tags used by conservation biologists. Using extensive Monte Carlo simulation-based experiments, implementations on a single board compute module, and field experiments using an aerial robot platform with multiple VHF radio collar tags, we evaluate our joint planning and tracking algorithms. Further, we compare our method with other information-based planning methods with and without situational awareness to demonstrate the effectiveness of our robot executing LAVAPilot. Our experiments demonstrate that LAVAPilot significantly reduces (by 98.5%) the computational cost of planning to enable real-time planning decisions whilst achieving similar localization accuracy of objects compared to information gain based planning methods, albeit taking a slightly longer time to complete a mission.
Fisher Information Field: an Efficient and Differentiable Map for Perception-aware Planning
Aug 07, 2020



Considering visual localization accuracy at the planning time gives preference to robot motion that can be better localized and thus has the potential of improving vision-based navigation, especially in visually degraded environments. To integrate the knowledge about localization accuracy in motion planning algorithms, a central task is to quantify the amount of information that an image taken at a 6 degree-of-freedom pose brings for localization, which is often represented by the Fisher information. However, computing the Fisher information from a set of sparse landmarks (i.e., a point cloud), which is the most common map for visual localization, is inefficient. This approach scales linearly with the number of landmarks in the environment and does not allow the reuse of the computed Fisher information. To overcome these drawbacks, we propose the first dedicated map representation for evaluating the Fisher information of 6 degree-of-freedom visual localization for perception-aware motion planning. By formulating the Fisher information and sensor visibility carefully, we are able to separate the rotational invariant component from the Fisher information and store it in a voxel grid, namely the Fisher information field. This step only needs to be performed once for a known environment. The Fisher information for arbitrary poses can then be computed from the field in constant time, eliminating the need of costly iterating all the 3D landmarks at the planning time. Experimental results show that the proposed Fisher information field can be applied to different motion planning algorithms and is at least one order-of-magnitude faster than using the point cloud directly. Moreover,the proposed map representation is differentiable, resulting in better performance than the point cloud when used in trajectory optimization algorithms.
Single upper limb pose estimation method based on improved stacked hourglass network
Apr 16, 2020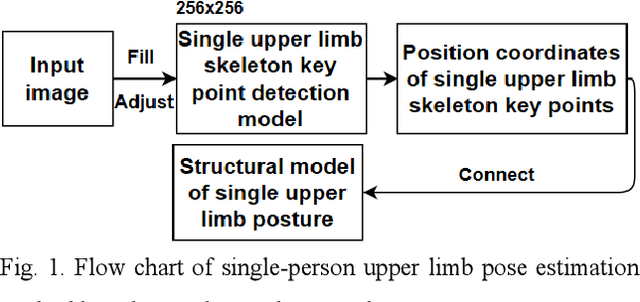
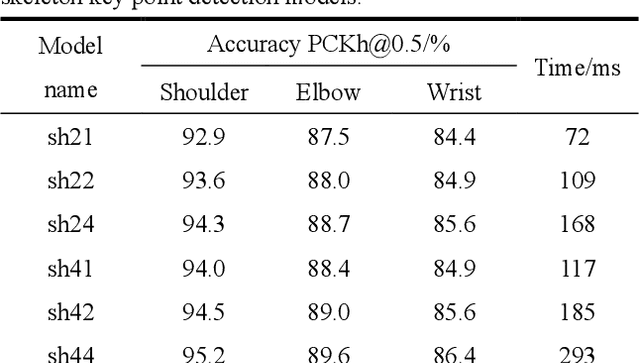
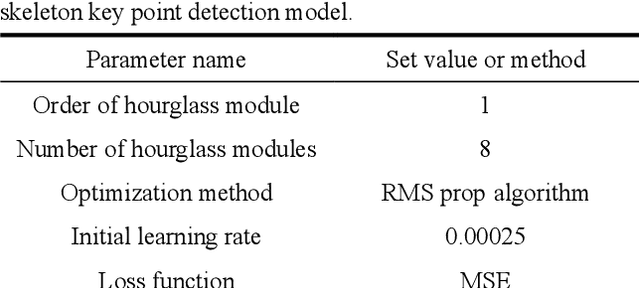

At present, most high-accuracy single-person pose estimation methods have high computational complexity and insufficient real-time performance due to the complex structure of the network model. However, a single-person pose estimation method with high real-time performance also needs to improve its accuracy due to the simple structure of the network model. It is currently difficult to achieve both high accuracy and real-time performance in single-person pose estimation. For use in human-machine cooperative operations, this paper proposes a single-person upper limb pose estimation method based on an end-to-end approach for accurate and real-time limb pose estimation. Using the stacked hourglass network model, a single-person upper limb skeleton key point detection model was designed.Deconvolution was employed to replace the up-sampling operation of the hourglass module in the original model, solving the problem of rough feature maps. Integral regression was used to calculate the position coordinates of key points of the skeleton, reducing quantization errors and calculations. Experiments showed that the developed single-person upper limb skeleton key point detection model achieves high accuracy and that the pose estimation method based on the end-to-end approach provides high accuracy and real-time performance.
Knowledge Enhanced Neural Fashion Trend Forecasting
May 07, 2020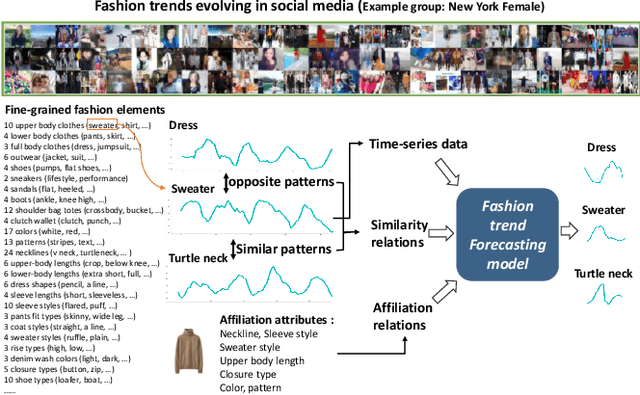
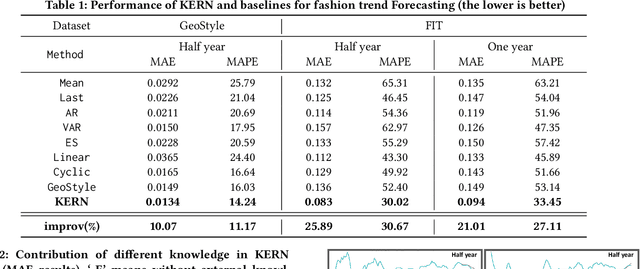
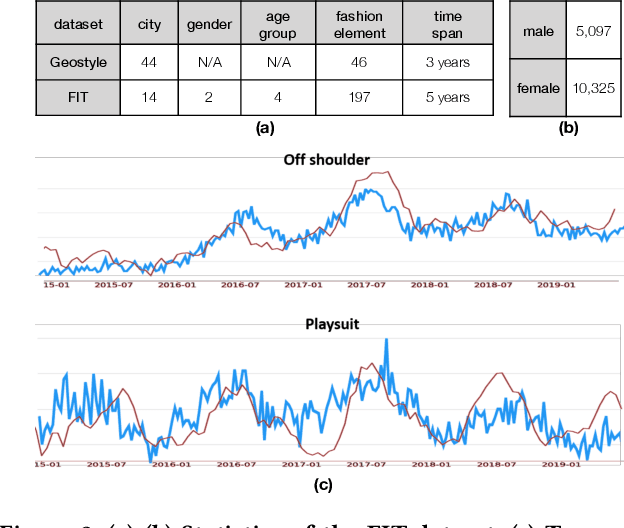
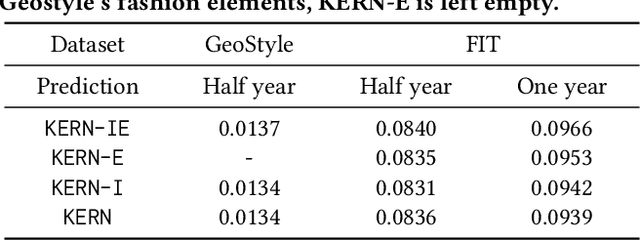
Fashion trend forecasting is a crucial task for both academia and industry. Although some efforts have been devoted to tackling this challenging task, they only studied limited fashion elements with highly seasonal or simple patterns, which could hardly reveal the real fashion trends. Towards insightful fashion trend forecasting, this work focuses on investigating fine-grained fashion element trends for specific user groups. We first contribute a large-scale fashion trend dataset (FIT) collected from Instagram with extracted time series fashion element records and user information. Further-more, to effectively model the time series data of fashion elements with rather complex patterns, we propose a Knowledge EnhancedRecurrent Network model (KERN) which takes advantage of the capability of deep recurrent neural networks in modeling time-series data. Moreover, it leverages internal and external knowledge in fashion domain that affects the time-series patterns of fashion element trends. Such incorporation of domain knowledge further enhances the deep learning model in capturing the patterns of specific fashion elements and predicting the future trends. Extensive experiments demonstrate that the proposed KERN model can effectively capture the complicated patterns of objective fashion elements, therefore making preferable fashion trend forecast.
Fusion Recurrent Neural Network
Jun 07, 2020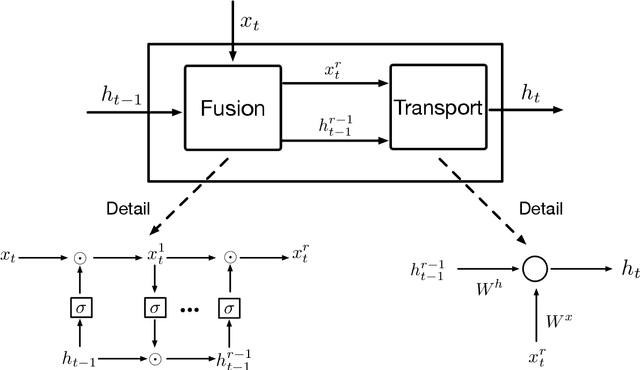


Considering deep sequence learning for practical application, two representative RNNs - LSTM and GRU may come to mind first. Nevertheless, is there no chance for other RNNs? Will there be a better RNN in the future? In this work, we propose a novel, succinct and promising RNN - Fusion Recurrent Neural Network (Fusion RNN). Fusion RNN is composed of Fusion module and Transport module every time step. Fusion module realizes the multi-round fusion of the input and hidden state vector. Transport module which mainly refers to simple recurrent network calculate the hidden state and prepare to pass it to the next time step. Furthermore, in order to evaluate Fusion RNN's sequence feature extraction capability, we choose a representative data mining task for sequence data, estimated time of arrival (ETA) and present a novel model based on Fusion RNN. We contrast our method and other variants of RNN for ETA under massive vehicle travel data from DiDi Chuxing. The results demonstrate that for ETA, Fusion RNN is comparable to state-of-the-art LSTM and GRU which are more complicated than Fusion RNN.