 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
POMP: Pomcp-based Online Motion Planning for active visual search in indoor environments
Sep 17, 2020
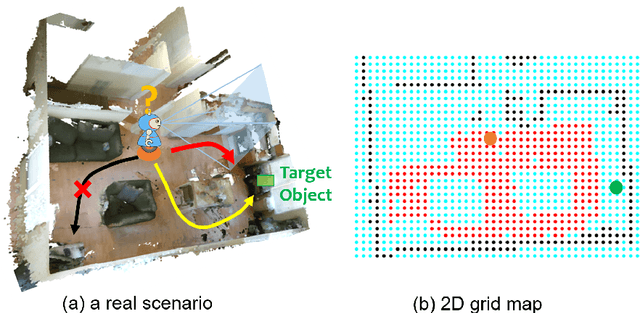
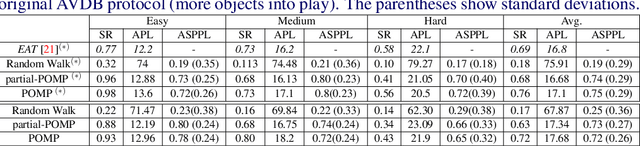
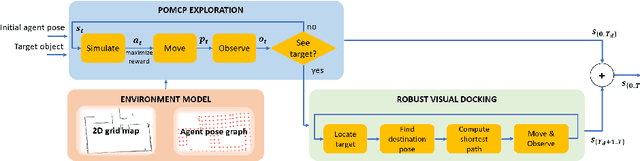

In this paper we focus on the problem of learning an optimal policy for Active Visual Search (AVS) of objects in known indoor environments with an online setup. Our POMP method uses as input the current pose of an agent (e.g. a robot) and a RGB-D frame. The task is to plan the next move that brings the agent closer to the target object. We model this problem as a Partially Observable Markov Decision Process solved by a Monte-Carlo planning approach. This allows us to make decisions on the next moves by iterating over the known scenario at hand, exploring the environment and searching for the object at the same time. Differently from the current state of the art in Reinforcement Learning, POMP does not require extensive and expensive (in time and computation) labelled data so being very agile in solving AVS in small and medium real scenarios. We only require the information of the floormap of the environment, an information usually available or that can be easily extracted from an a priori single exploration run. We validate our method on the publicly available AVD benchmark, achieving an average success rate of 0.76 with an average path length of 17.1, performing close to the state of the art but without any training needed. Additionally, we show experimentally the robustness of our method when the quality of the object detection goes from ideal to faulty.
Misinformation has High Perplexity
Jun 08, 2020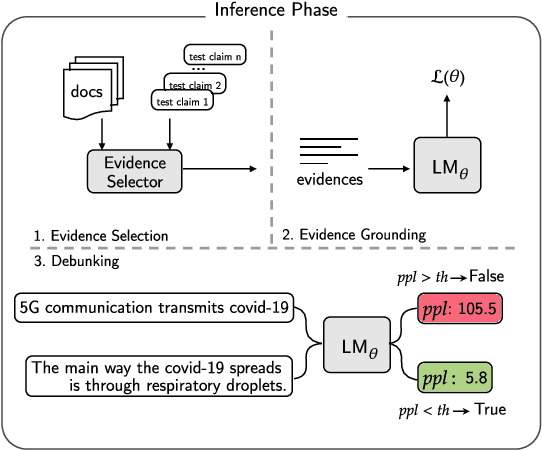


Debunking misinformation is an important and time-critical task as there could be adverse consequences when misinformation is not quashed promptly. However, the usual supervised approach to debunking via misinformation classification requires human-annotated data and is not suited to the fast time-frame of newly emerging events such as the COVID-19 outbreak. In this paper, we postulate that misinformation itself has higher perplexity compared to truthful statements, and propose to leverage the perplexity to debunk false claims in an unsupervised manner. First, we extract reliable evidence from scientific and news sources according to sentence similarity to the claims. Second, we prime a language model with the extracted evidence and finally evaluate the correctness of given claims based on the perplexity scores at debunking time. We construct two new COVID-19-related test sets, one is scientific, and another is political in content, and empirically verify that our system performs favorably compared to existing systems. We are releasing these datasets publicly to encourage more research in debunking misinformation on COVID-19 and other topics.
Towards High-Performance Solid-State-LiDAR-Inertial Odometry and Mapping
Oct 25, 2020
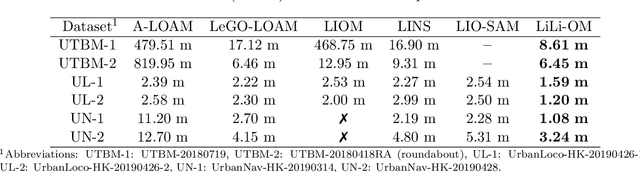
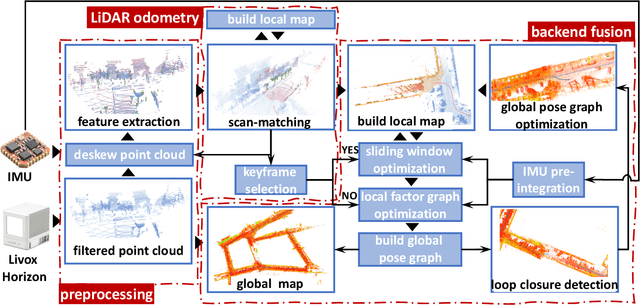

We present a novel tightly-coupled LiDAR-inertial odometry and mapping scheme for both solid-state and mechanical LiDARs. As frontend, a feature-based lightweight LiDAR odometry provides fast motion estimates for adaptive keyframe selection. As backend, a hierarchical keyframe-based sliding window optimization is performed through marginalization for directly fusing IMU and LiDAR measurements. For the Livox Horizon, a new low-cost solid-state LiDAR, a novel feature extraction method is proposed to handle its irregular scan pattern during preprocessing. LiLi-OM (Livox LiDAR-inertial odometry and mapping) is real-time capable and achieves superior accuracy over state-of-the-art systems for both types of LiDARs on public data sets of mechanical LiDARs and experimental data recorded by Livox Horizon. Source code and recorded experimental data sets are available on Github.
PoP-Net: Pose over Parts Network for Multi-Person 3D Pose Estimation from a Depth Image
Dec 12, 2020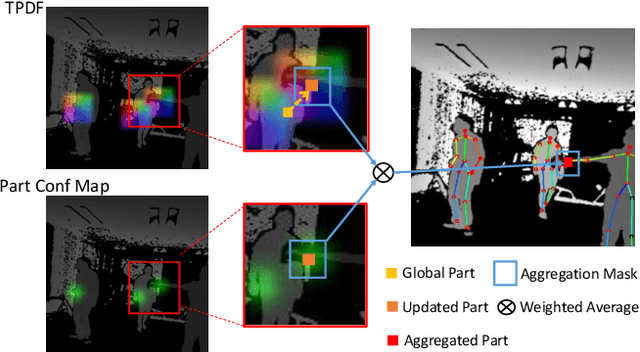
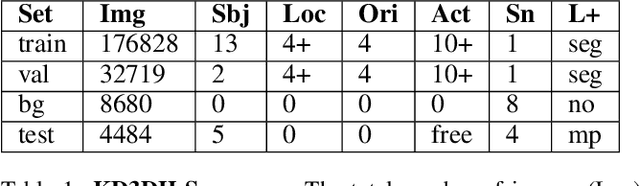

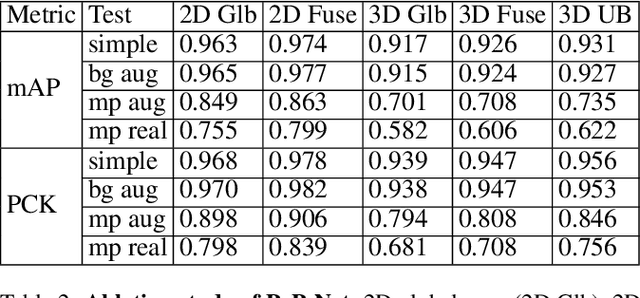
In this paper, a real-time method called PoP-Net is proposed to predict multi-person 3D poses from a depth image. PoP-Net learns to predict bottom-up part detection maps and top-down global poses in a single-shot framework. A simple and effective fusion process is applied to fuse the global poses and part detection. Specifically, a new part-level representation, called Truncated Part Displacement Field (TPDF), is introduced. It drags low-precision global poses towards more accurate part locations while maintaining the advantage of global poses in handling severe occlusion and truncation cases. A mode selection scheme is developed to automatically resolve the conflict between global poses and local detection. Finally, due to the lack of high-quality depth datasets for developing and evaluating multi-person 3D pose estimation methods, a comprehensive depth dataset with 3D pose labels is released. The dataset is designed to enable effective multi-person and background data augmentation such that the developed models are more generalizable towards uncontrolled real-world multi-person scenarios. We show that PoP-Net has significant advantages in efficiency for multi-person processing and achieves the state-of-the-art results both on the released challenging dataset and on the widely used ITOP dataset.
Industrial object, machine part and defect recognition towards fully automated industrial monitoring employing deep learning. The case of multilevel VGG19
Nov 23, 2020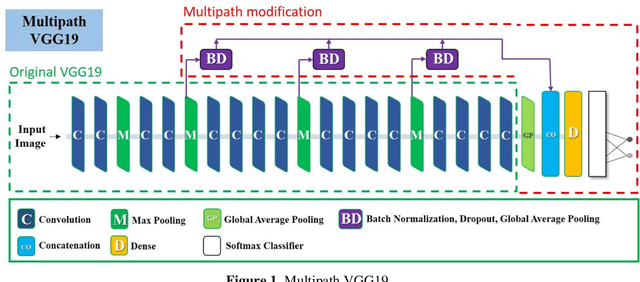
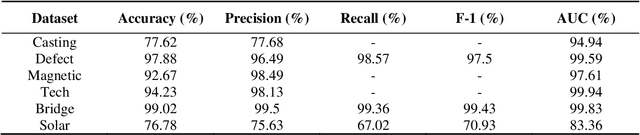

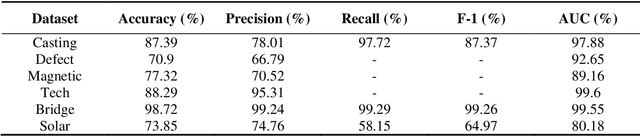
Modern industry requires modern solutions for monitoring the automatic production of goods. Smart monitoring of the functionality of the mechanical parts of technology systems or machines is mandatory for a fully automatic production process. Although Deep Learning has been advancing, allowing for real-time object detection and other tasks, little has been investigated about the effectiveness of specially designed Convolutional Neural Networks for defect detection and industrial object recognition. In the particular study, we employed six publically available industrial-related datasets containing defect materials and industrial tools or engine parts, aiming to develop a specialized model for pattern recognition. Motivated by the recent success of the Virtual Geometry Group (VGG) network, we propose a modified version of it, called Multipath VGG19, which allows for more local and global feature extraction, while the extra features are fused via concatenation. The experiments verified the effectiveness of MVGG19 over the traditional VGG19. Specifically, top classification performance was achieved in five of the six image datasets, while the average classification improvement was 6.95%.
LazyBatching: An SLA-aware Batching System for Cloud Machine Learning Inference
Oct 25, 2020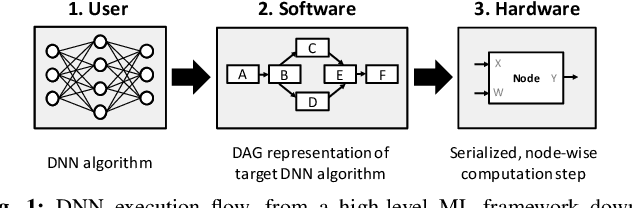
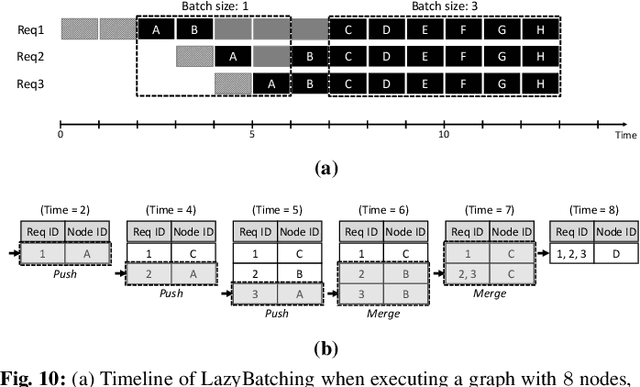
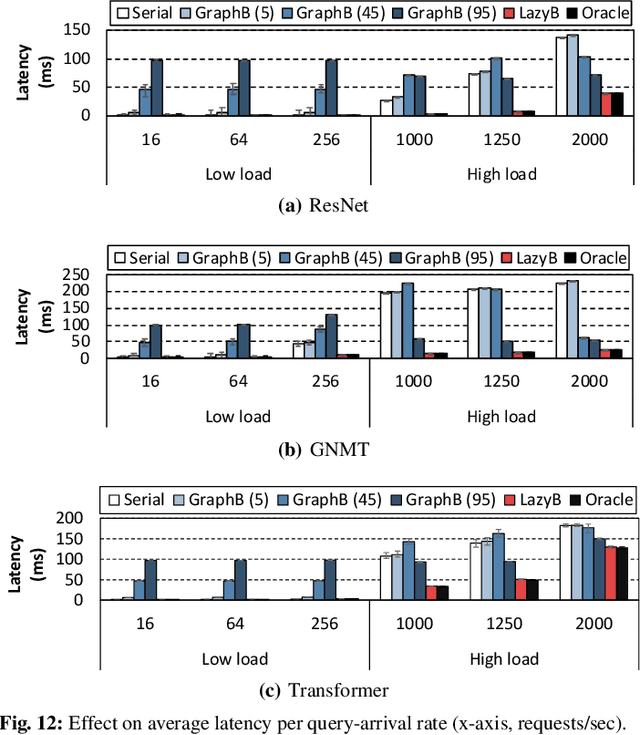
In cloud ML inference systems, batching is an essential technique to increase throughput which helps optimize total-cost-of-ownership. Prior graph batching combines the individual DNN graphs into a single one, allowing multiple inputs to be concurrently executed in parallel. We observe that the coarse-grained graph batching becomes suboptimal in effectively handling the dynamic inference request traffic, leaving significant performance left on the table. This paper proposes LazyBatching, an SLA-aware batching system that considers both scheduling and batching in the granularity of individual graph nodes, rather than the entire graph for flexible batching. We show that LazyBatching can intelligently determine the set of nodes that can be efficiently batched together, achieving an average 15x, 1.5x, and 5.5x improvement than graph batching in terms of average response time, throughput, and SLA satisfaction, respectively.
Parameter Estimation with Dense and Convolutional Neural Networks Applied to the FitzHugh-Nagumo ODE
Dec 12, 2020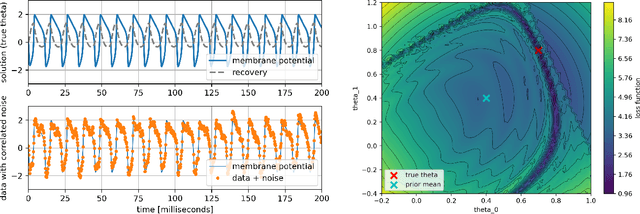
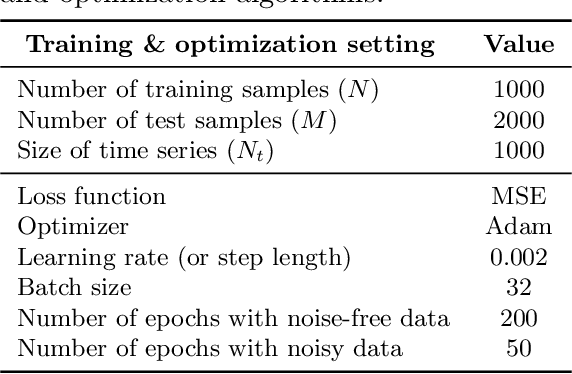

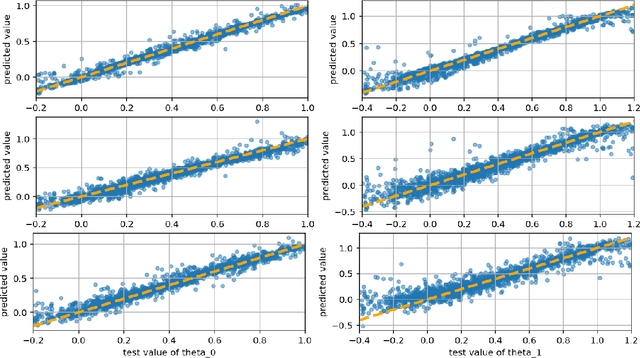
Machine learning algorithms have been successfully used to approximate nonlinear maps under weak assumptions on the structure and properties of the maps. We present deep neural networks using dense and convolutional layers to solve an inverse problem, where we seek to estimate parameters in a FitzHugh-Nagumo model, which consists of a nonlinear system of ordinary differential equations (ODEs). We employ the neural networks to approximate reconstruction maps for model parameter estimation from observational data, where the data comes from the solution of the ODE and takes the form of a time series representing dynamically spiking membrane potential of a (biological) neuron. We target this dynamical model because of the computational challenges it poses in an inference setting, namely, having a highly nonlinear and nonconvex data misfit term and permitting only weakly informative priors on parameters. These challenges cause traditional optimization to fail and alternative algorithms to exhibit large computational costs. We quantify the predictability of model parameters obtained from the neural networks with statistical metrics and investigate the effects of network architectures and presence of noise in observational data. Our results demonstrate that deep neural networks are capable of very accurately estimating parameters in dynamical models from observational data.
UoB at SemEval-2020 Task 1: Automatic Identification of Novel Word Senses
Oct 18, 2020
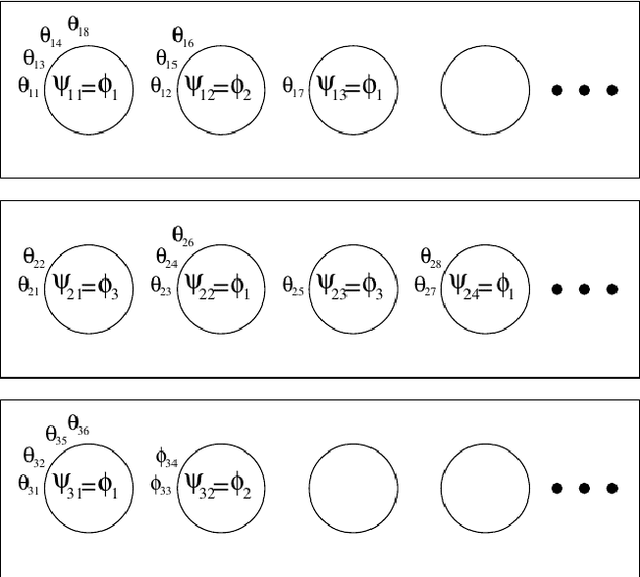


Much as the social landscape in which languages are spoken shifts, language too evolves to suit the needs of its users. Lexical semantic change analysis is a burgeoning field of semantic analysis which aims to trace changes in the meanings of words over time. This paper presents an approach to lexical semantic change detection based on Bayesian word sense induction suitable for novel word sense identification. This approach is used for a submission to SemEval-2020 Task 1, which shows the approach to be capable of the SemEval task. The same approach is also applied to a corpus gleaned from 15 years of Twitter data, the results of which are then used to identify words which may be instances of slang.
New Perspectives on the Use of Online Learning for Congestion Level Prediction over Traffic Data
Mar 27, 2020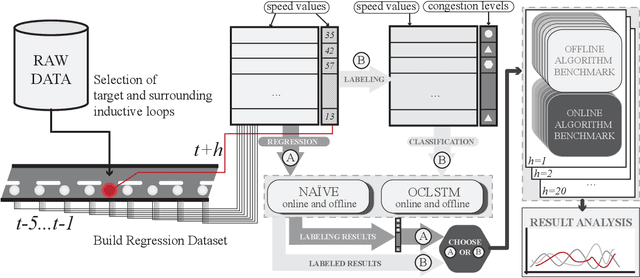
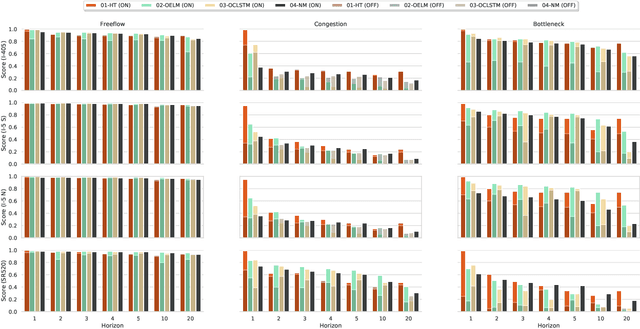
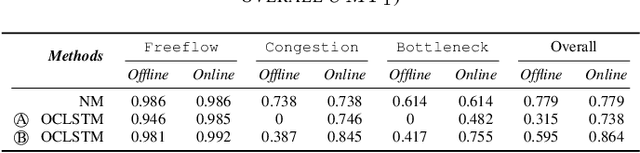
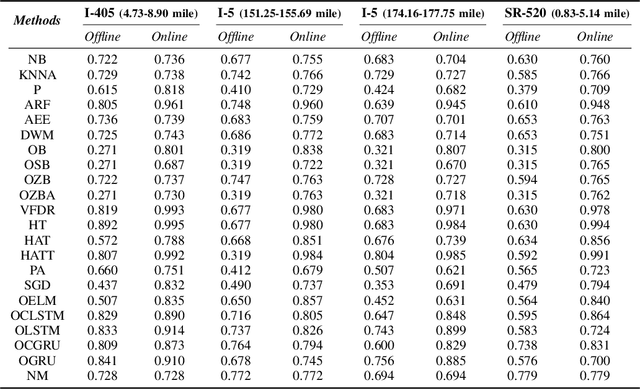
This work focuses on classification over time series data. When a time series is generated by non-stationary phenomena, the pattern relating the series with the class to be predicted may evolve over time (concept drift). Consequently, predictive models aimed to learn this pattern may become eventually obsolete, hence failing to sustain performance levels of practical use. To overcome this model degradation, online learning methods incrementally learn from new data samples arriving over time, and accommodate eventual changes along the data stream by implementing assorted concept drift strategies. In this manuscript we elaborate on the suitability of online learning methods to predict the road congestion level based on traffic speed time series data. We draw interesting insights on the performance degradation when the forecasting horizon is increased. As opposed to what is done in most literature, we provide evidence of the importance of assessing the distribution of classes over time before designing and tuning the learning model. This previous exercise may give a hint of the predictability of the different congestion levels under target. Experimental results are discussed over real traffic speed data captured by inductive loops deployed over Seattle (USA). Several online learning methods are analyzed, from traditional incremental learning algorithms to more elaborated deep learning models. As shown by the reported results, when increasing the prediction horizon, the performance of all models degrade severely due to the distribution of classes along time, which supports our claim about the importance of analyzing this distribution prior to the design of the model.
Personalized Step Counting Using Wearable Sensors: A Domain Adapted LSTM Network Approach
Dec 11, 2020
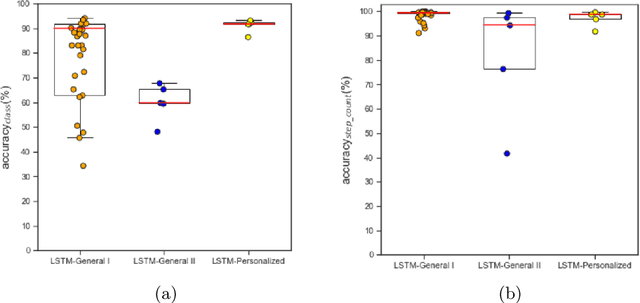
Activity monitors are widely used to measure various physical activities (PA) as an indicator of mobility, fitness and general health. Similarly, real-time monitoring of longitudinal trends in step count has significant clinical potential as a personalized measure of disease related changes in daily activity. However, inconsistent step count accuracy across vendors, body locations, and individual gait differences limits clinical utility. The tri-axial accelerometer inside PA monitors can be exploited to improve step count accuracy across devices and individuals. In this study, we hypothesize: (1) raw tri-axial sensor data can be modeled to create reliable and accurate step count, and (2) a generalized step count model can then be efficiently adapted to each unique gait pattern using very little new data. Firstly, open-source raw sensor data was used to construct a long short term memory (LSTM) deep neural network to model step count. Then we generated a new, fully independent data set using a different device and different subjects. Finally, a small amount of subject-specific data was domain adapted to produce personalized models with high individualized step count accuracy. These results suggest models trained using large freely available datasets can be adapted to patient populations where large historical data sets are rare.