 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Logic-based Clustering and Learning for Time-Series Data
May 15, 2017
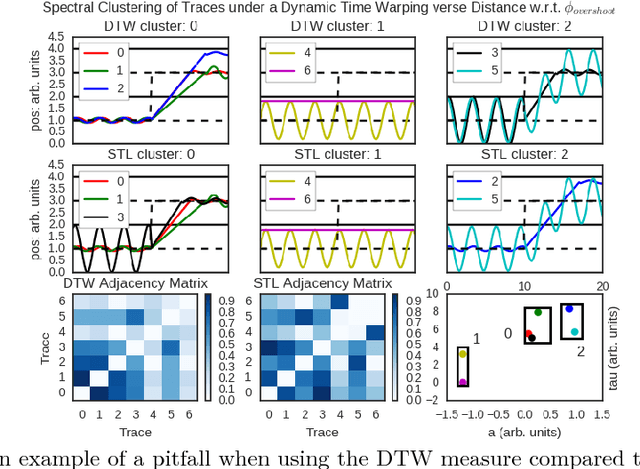
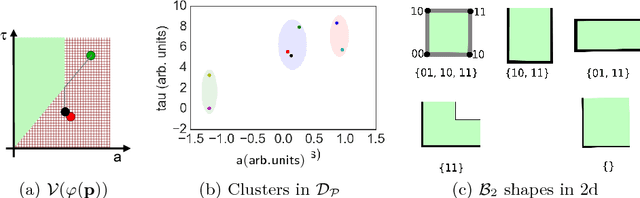
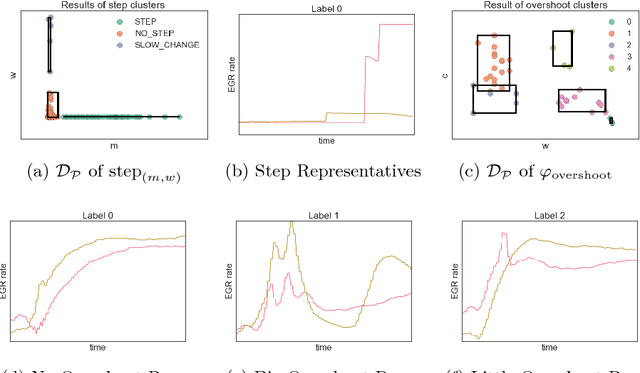
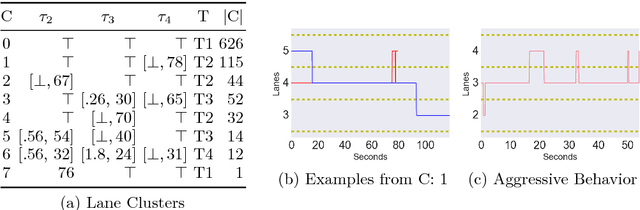
To effectively analyze and design cyberphysical systems (CPS), designers today have to combat the data deluge problem, i.e., the burden of processing intractably large amounts of data produced by complex models and experiments. In this work, we utilize monotonic Parametric Signal Temporal Logic (PSTL) to design features for unsupervised classification of time series data. This enables using off-the-shelf machine learning tools to automatically cluster similar traces with respect to a given PSTL formula. We demonstrate how this technique produces interpretable formulas that are amenable to analysis and understanding using a few representative examples. We illustrate this with case studies related to automotive engine testing, highway traffic analysis, and auto-grading massively open online courses.
A Framework for Addressing the Risks and Opportunities In AI-Supported Virtual Health Coaches
Oct 12, 2020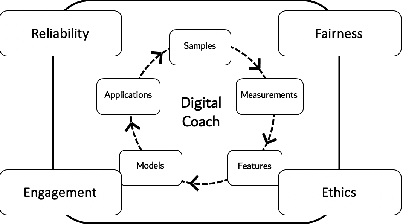
Virtual coaching has rapidly evolved into a foundational component of modern clinical practice. At a time when healthcare professionals are in short supply and the demand for low-cost treatments is ever-increasing, virtual health coaches (VHCs) offer intervention-on-demand for those limited by finances or geographic access to care. More recently, AI-powered virtual coaches have become a viable complement to human coaches. However, the push for AI-powered coaching systems raises several important issues for researchers, designers, clinicians, and patients. In this paper, we present a novel framework to guide the design and development of virtual coaching systems. This framework augments a traditional data science pipeline with four key guiding goals: reliability, fairness, engagement, and ethics.
Warm Starting CMA-ES for Hyperparameter Optimization
Dec 13, 2020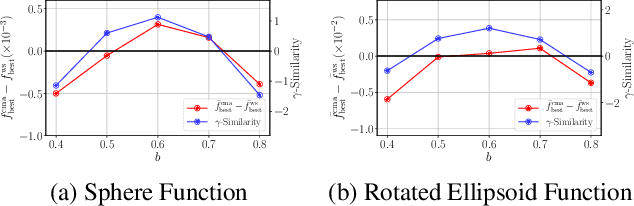

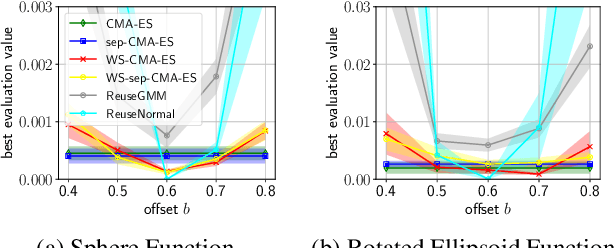
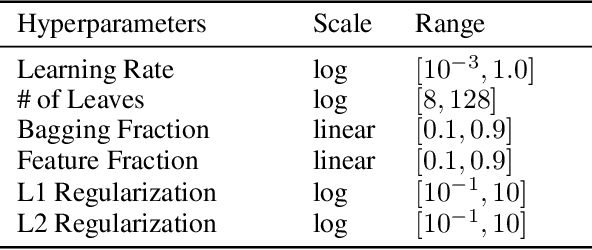
Hyperparameter optimization (HPO), formulated as black-box optimization (BBO), is recognized as essential for automation and high performance of machine learning approaches. The CMA-ES is a promising BBO approach with a high degree of parallelism, and has been applied to HPO tasks, often under parallel implementation, and shown superior performance to other approaches including Bayesian optimization (BO). However, if the budget of hyperparameter evaluations is severely limited, which is often the case for end users who do not deserve parallel computing, the CMA-ES exhausts the budget without improving the performance due to its long adaptation phase, resulting in being outperformed by BO approaches. To address this issue, we propose to transfer prior knowledge on similar HPO tasks through the initialization of the CMA-ES, leading to significantly shortening the adaptation time. The knowledge transfer is designed based on the novel definition of task similarity, with which the correlation of the performance of the proposed approach is confirmed on synthetic problems. The proposed warm starting CMA-ES, called WS-CMA-ES, is applied to different HPO tasks where some prior knowledge is available, showing its superior performance over the original CMA-ES as well as BO approaches with or without using the prior knowledge.
Semi-supervised Gated Recurrent Neural Networks for Robotic Terrain Classification
Nov 24, 2020

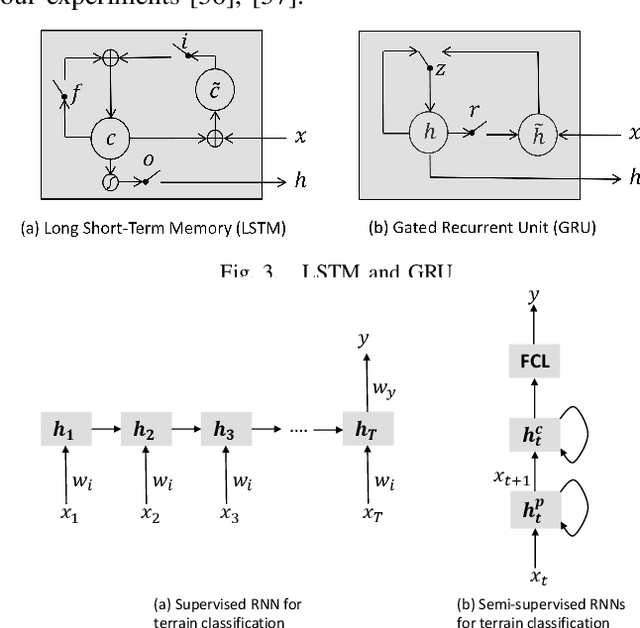
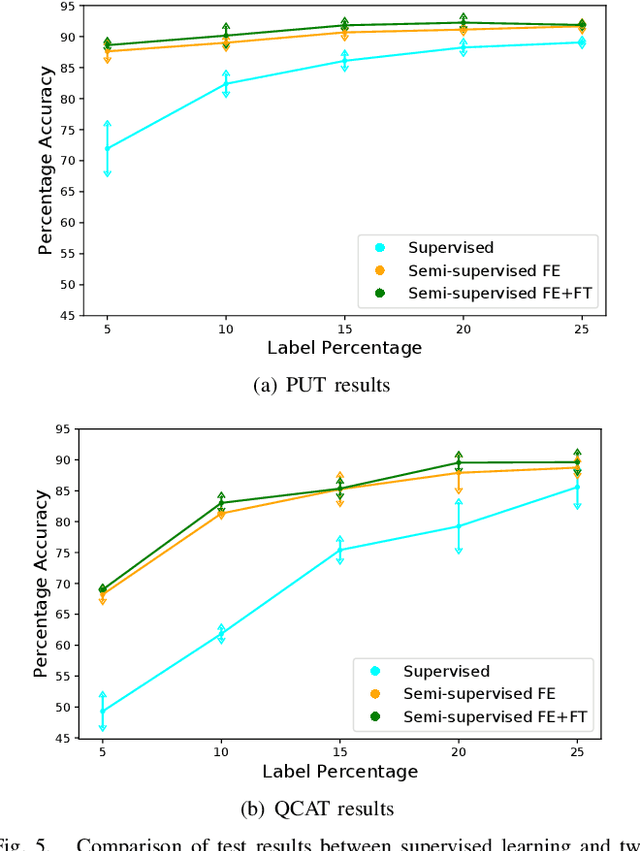
Legged robots are popular candidates for missions in challenging terrains due to the wide variety of locomotion strategies they can employ. Terrain classification is a key enabling technology for autonomous legged robots, as it allows the robot to harness their innate flexibility to adapt their behaviour to the demands of their operating environment. In this paper, we show how highly capable machine learning techniques, namely gated recurrent neural networks, allow our target legged robot to correctly classify the terrain it traverses in both supervised and semi-supervised fashions. Tests on a benchmark data set shows that our time-domain classifiers are well capable of dealing with raw and variable-length data with small amount of labels and perform to a level far exceeding the frequency-domain classifiers. The classification results on our own extended data set opens up a range of high-performance behaviours that are specific to those environments. Furthermore, we show how raw unlabelled data is used to improve significantly the classification results in a semi-supervised model.
A novel machine learning-based optimization algorithm (ActivO) for accelerating simulation-driven engine design
Jan 04, 2021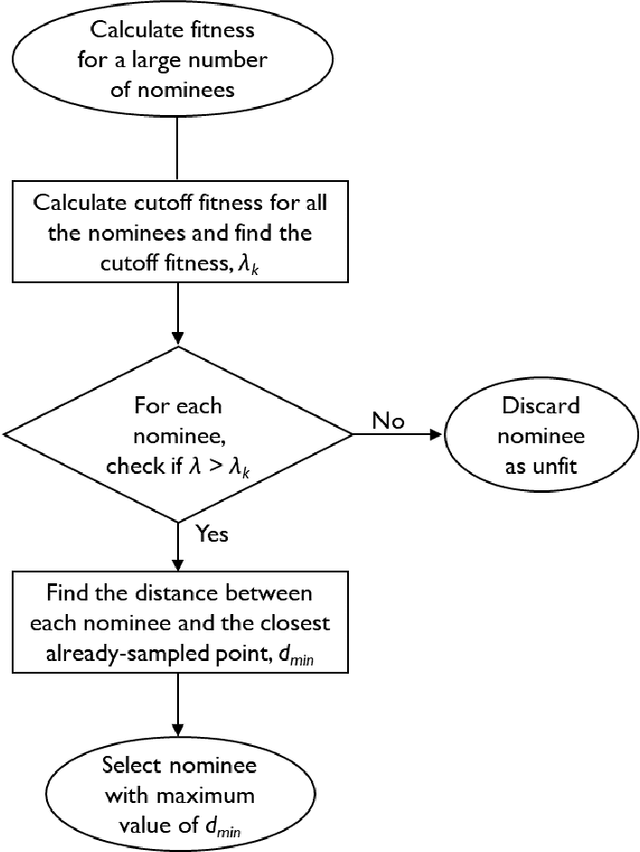
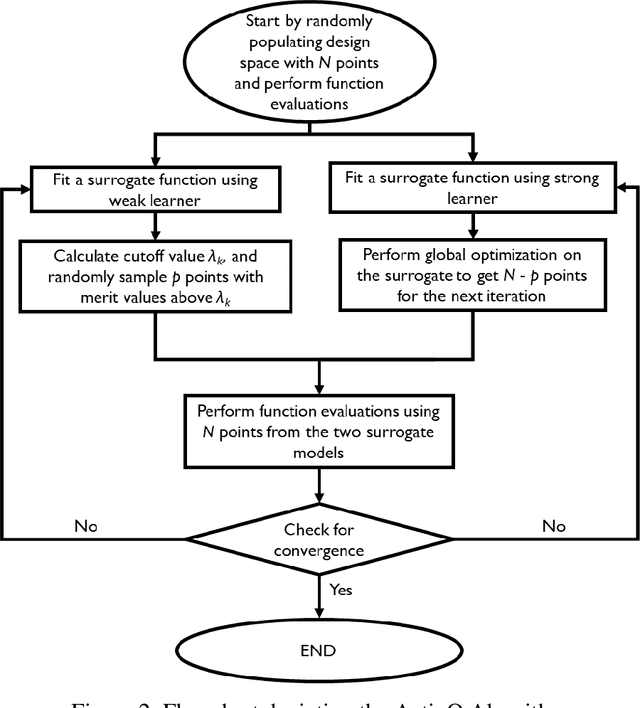
A novel design optimization approach (ActivO) that employs an ensemble of machine learning algorithms is presented. The proposed approach is a surrogate-based scheme, where the predictions of a weak leaner and a strong learner are utilized within an active learning loop. The weak learner is used to identify promising regions within the design space to explore, while the strong learner is used to determine the exact location of the optimum within promising regions. For each design iteration, exploration is done by randomly selecting evaluation points within regions where the weak learner-predicted fitness is high. The global optimum obtained by using the strong learner as a surrogate is also evaluated to enable rapid convergence once the most promising region has been identified. First, the performance of ActivO was compared against five other optimizers on a cosine mixture function with 25 local optima and one global optimum. In the second problem, the objective was to minimize indicated specific fuel consumption of a compression-ignition internal combustion (IC) engine while adhering to desired constraints associated with in-cylinder pressure and emissions. Here, the efficacy of the proposed approach is compared to that of a genetic algorithm, which is widely used within the internal combustion engine community for engine optimization, showing that ActivO reduces the number of function evaluations needed to reach the global optimum, and thereby time-to-design by 80%. Furthermore, the optimization of engine design parameters leads to savings of around 1.9% in energy consumption, while maintaining operability and acceptable pollutant emissions.
Activation function impact on Sparse Neural Networks
Oct 12, 2020
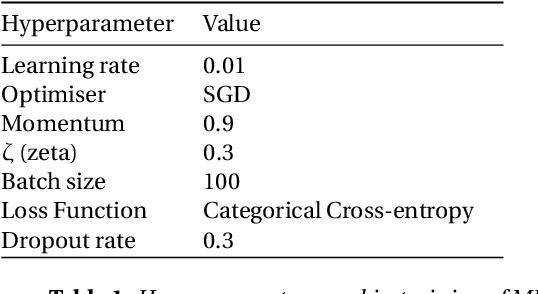
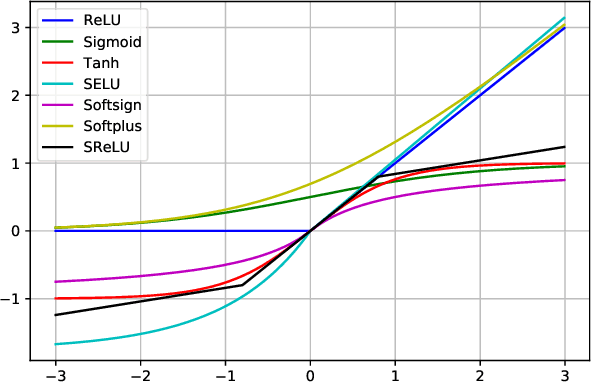
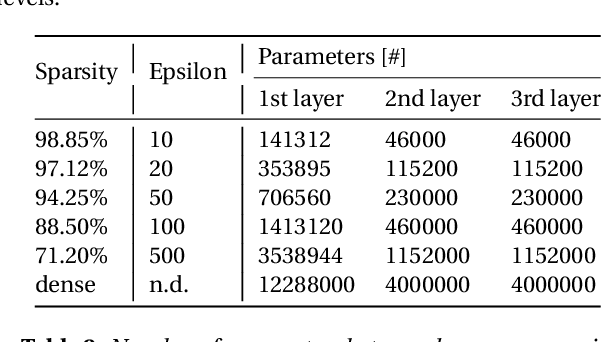
While the concept of a Sparse Neural Network has been researched for some time, researchers have only recently made notable progress in the matter. Techniques like Sparse Evolutionary Training allow for significantly lower computational complexity when compared to fully connected models by reducing redundant connections. That typically takes place in an iterative process of weight creation and removal during network training. Although there have been numerous approaches to optimize the redistribution of the removed weights, there seems to be little or no study on the effect of activation functions on the performance of the Sparse Networks. This research provides insights into the relationship between the activation function used and the network performance at various sparsity levels.
ELF: An Extensive, Lightweight and Flexible Research Platform for Real-time Strategy Games
Nov 10, 2017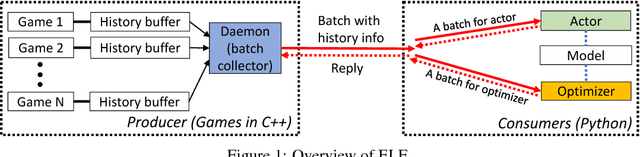
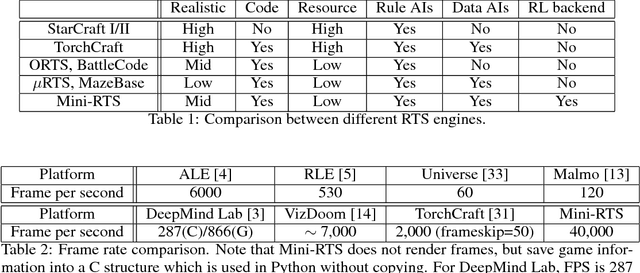
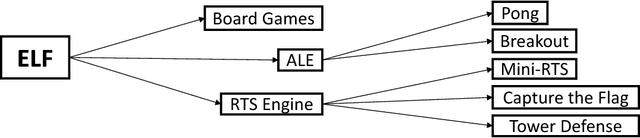
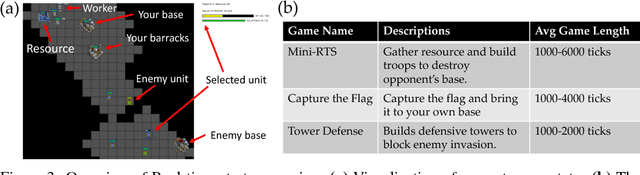
In this paper, we propose ELF, an Extensive, Lightweight and Flexible platform for fundamental reinforcement learning research. Using ELF, we implement a highly customizable real-time strategy (RTS) engine with three game environments (Mini-RTS, Capture the Flag and Tower Defense). Mini-RTS, as a miniature version of StarCraft, captures key game dynamics and runs at 40K frame-per-second (FPS) per core on a Macbook Pro notebook. When coupled with modern reinforcement learning methods, the system can train a full-game bot against built-in AIs end-to-end in one day with 6 CPUs and 1 GPU. In addition, our platform is flexible in terms of environment-agent communication topologies, choices of RL methods, changes in game parameters, and can host existing C/C++-based game environments like Arcade Learning Environment. Using ELF, we thoroughly explore training parameters and show that a network with Leaky ReLU and Batch Normalization coupled with long-horizon training and progressive curriculum beats the rule-based built-in AI more than $70\%$ of the time in the full game of Mini-RTS. Strong performance is also achieved on the other two games. In game replays, we show our agents learn interesting strategies. ELF, along with its RL platform, is open-sourced at https://github.com/facebookresearch/ELF.
Straggler-Resilient Federated Learning: Leveraging the Interplay Between Statistical Accuracy and System Heterogeneity
Dec 28, 2020

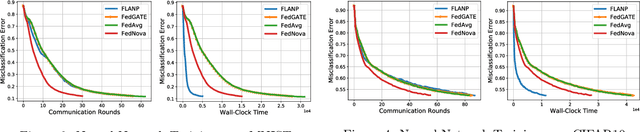
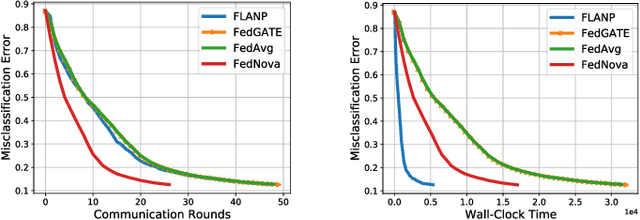
Federated Learning is a novel paradigm that involves learning from data samples distributed across a large network of clients while the data remains local. It is, however, known that federated learning is prone to multiple system challenges including system heterogeneity where clients have different computation and communication capabilities. Such heterogeneity in clients' computation speeds has a negative effect on the scalability of federated learning algorithms and causes significant slow-down in their runtime due to the existence of stragglers. In this paper, we propose a novel straggler-resilient federated learning method that incorporates statistical characteristics of the clients' data to adaptively select the clients in order to speed up the learning procedure. The key idea of our algorithm is to start the training procedure with faster nodes and gradually involve the slower nodes in the model training once the statistical accuracy of the data corresponding to the current participating nodes is reached. The proposed approach reduces the overall runtime required to achieve the statistical accuracy of data of all nodes, as the solution for each stage is close to the solution of the subsequent stage with more samples and can be used as a warm-start. Our theoretical results characterize the speedup gain in comparison to standard federated benchmarks for strongly convex objectives, and our numerical experiments also demonstrate significant speedups in wall-clock time of our straggler-resilient method compared to federated learning benchmarks.
Towards an Adversarially Robust Normalization Approach
Jun 19, 2020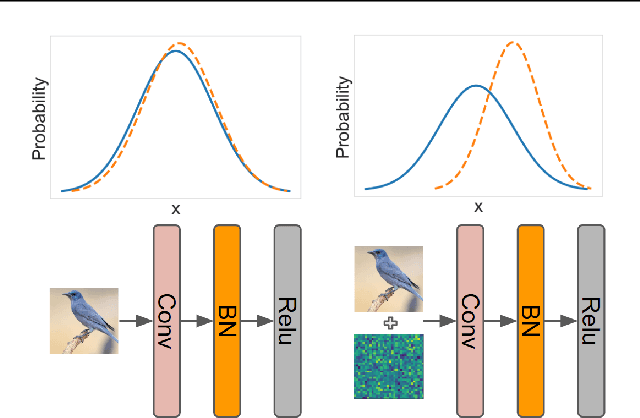
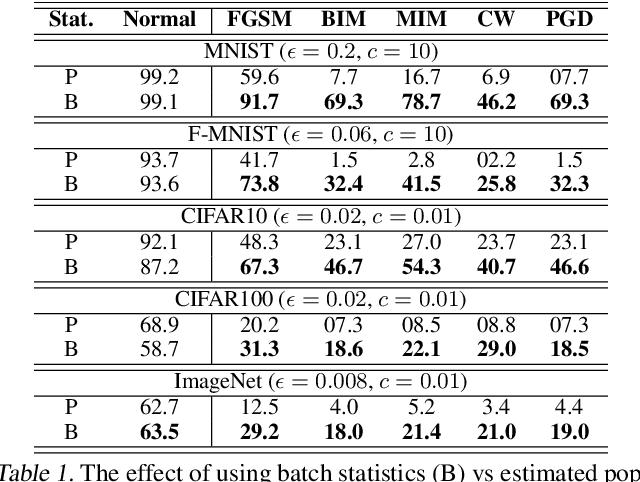
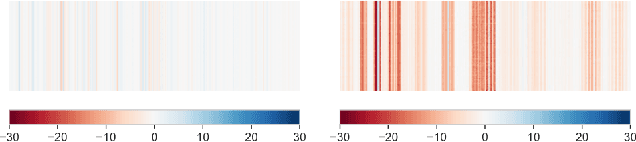
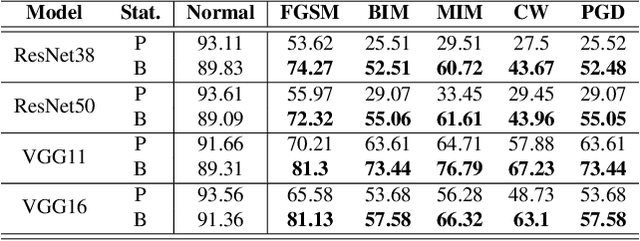
Batch Normalization (BatchNorm) is effective for improving the performance and accelerating the training of deep neural networks. However, it has also shown to be a cause of adversarial vulnerability, i.e., networks without it are more robust to adversarial attacks. In this paper, we investigate how BatchNorm causes this vulnerability and proposed new normalization that is robust to adversarial attacks. We first observe that adversarial images tend to shift the distribution of BatchNorm input, and this shift makes train-time estimated population statistics inaccurate. We hypothesize that these inaccurate statistics make models with BatchNorm more vulnerable to adversarial attacks. We prove our hypothesis by replacing train-time estimated statistics with statistics calculated from the inference-time batch. We found that the adversarial vulnerability of BatchNorm disappears if we use these statistics. However, without estimated batch statistics, we can not use BatchNorm in the practice if large batches of input are not available. To mitigate this, we propose Robust Normalization (RobustNorm); an adversarially robust version of BatchNorm. We experimentally show that models trained with RobustNorm perform better in adversarial settings while retaining all the benefits of BatchNorm. Code is available at \url{https://github.com/awaisrauf/RobustNorm}.
Policy Optimization for Markovian Jump Linear Quadratic Control: Gradient-Based Methods and Global Convergence
Nov 24, 2020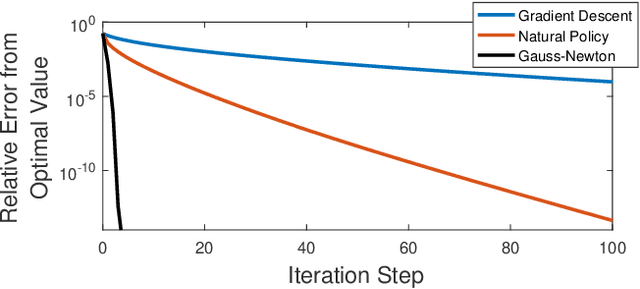
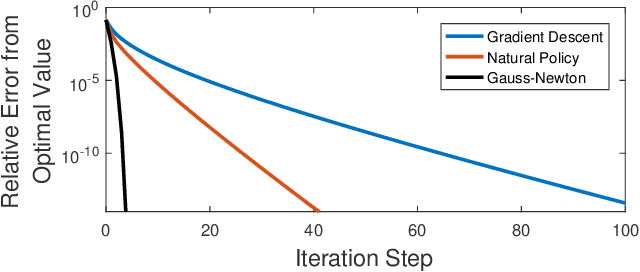
Recently, policy optimization for control purposes has received renewed attention due to the increasing interest in reinforcement learning. In this paper, we investigate the global convergence of gradient-based policy optimization methods for quadratic optimal control of discrete-time Markovian jump linear systems (MJLS). First, we study the optimization landscape of direct policy optimization for MJLS, with static state feedback controllers and quadratic performance costs. Despite the non-convexity of the resultant problem, we are still able to identify several useful properties such as coercivity, gradient dominance, and almost smoothness. Based on these properties, we show global convergence of three types of policy optimization methods: the gradient descent method; the Gauss-Newton method; and the natural policy gradient method. We prove that all three methods converge to the optimal state feedback controller for MJLS at a linear rate if initialized at a controller which is mean-square stabilizing. Some numerical examples are presented to support the theory. This work brings new insights for understanding the performance of policy gradient methods on the Markovian jump linear quadratic control problem.