 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Wearing a MASK: Compressed Representations of Variable-Length Sequences Using Recurrent Neural Tangent Kernels
Oct 27, 2020
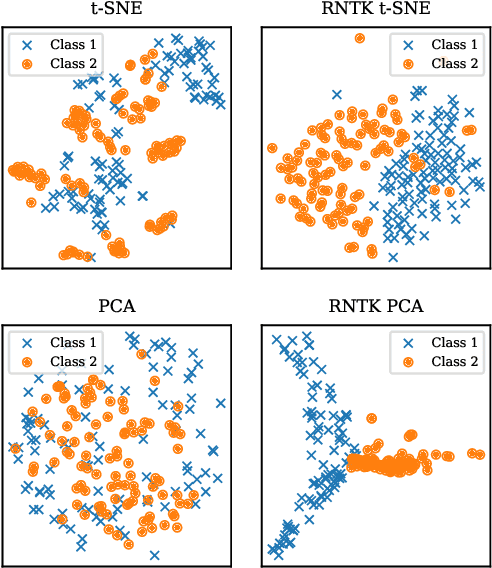
High dimensionality poses many challenges to the use of data, from visualization and interpretation, to prediction and storage for historical preservation. Techniques abound to reduce the dimensionality of fixed-length sequences, yet these methods rarely generalize to variable-length sequences. To address this gap, we extend existing methods that rely on the use of kernels to variable-length sequences via use of the Recurrent Neural Tangent Kernel (RNTK). Since a deep neural network with ReLu activation is a Max-Affine Spline Operator (MASO), we dub our approach Max-Affine Spline Kernel (MASK). We demonstrate how MASK can be used to extend principal components analysis (PCA) and t-distributed stochastic neighbor embedding (t-SNE) and apply these new algorithms to separate synthetic time series data sampled from second-order differential equations.
MP-Boost: Minipatch Boosting via Adaptive Feature and Observation Sampling
Nov 14, 2020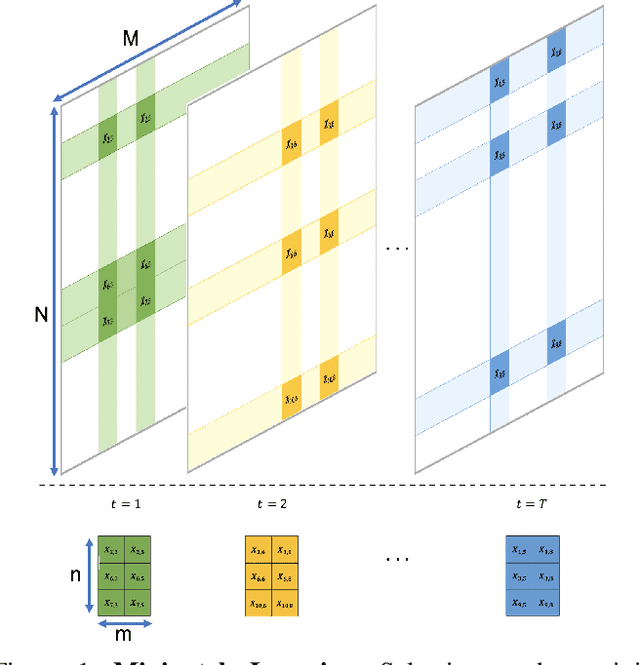

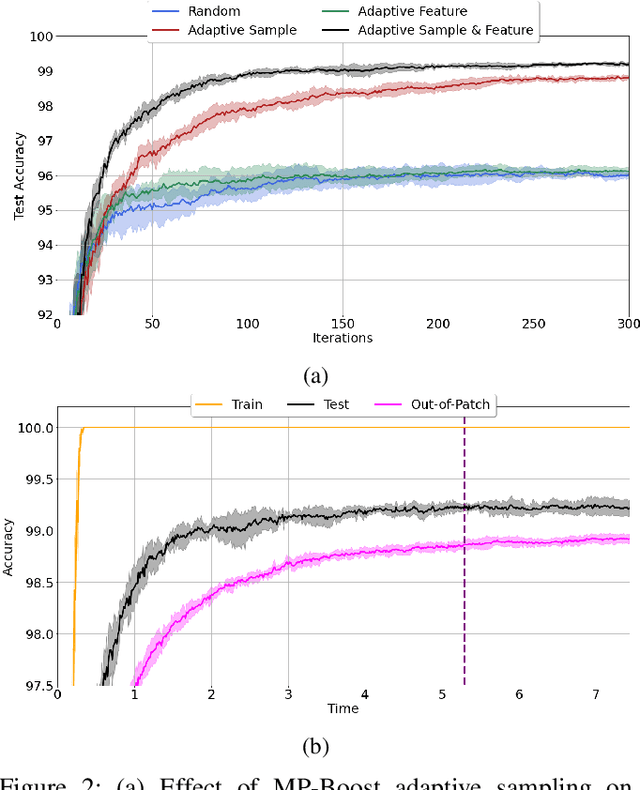
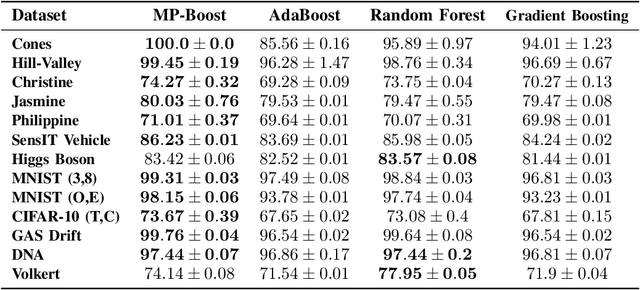
Boosting methods are among the best general-purpose and off-the-shelf machine learning approaches, gaining widespread popularity. In this paper, we seek to develop a boosting method that yields comparable accuracy to popular AdaBoost and gradient boosting methods, yet is faster computationally and whose solution is more interpretable. We achieve this by developing MP-Boost, an algorithm loosely based on AdaBoost that learns by adaptively selecting small subsets of instances and features, or what we term minipatches (MP), at each iteration. By sequentially learning on tiny subsets of the data, our approach is computationally faster than other classic boosting algorithms. Also as it progresses, MP-Boost adaptively learns a probability distribution on the features and instances that upweight the most important features and challenging instances, hence adaptively selecting the most relevant minipatches for learning. These learned probability distributions also aid in interpretation of our method. We empirically demonstrate the interpretability, comparative accuracy, and computational time of our approach on a variety of binary classification tasks.
Bayesian Active Learning for Wearable Stress and Affect Detection
Dec 04, 2020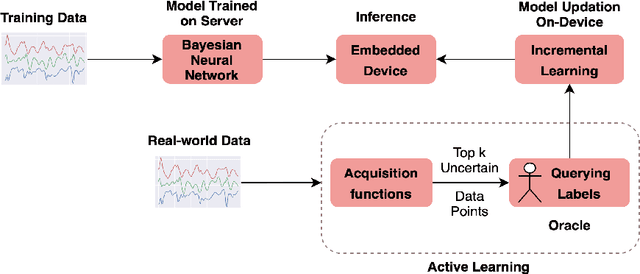
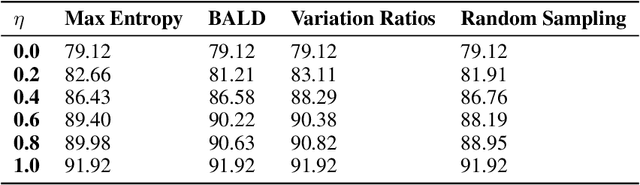

In the recent past, psychological stress has been increasingly observed in humans, and early detection is crucial to prevent health risks. Stress detection using on-device deep learning algorithms has been on the rise owing to advancements in pervasive computing. However, an important challenge that needs to be addressed is handling unlabeled data in real-time via suitable ground truthing techniques (like Active Learning), which should help establish affective states (labels) while also selecting only the most informative data points to query from an oracle. In this paper, we propose a framework with capabilities to represent model uncertainties through approximations in Bayesian Neural Networks using Monte-Carlo (MC) Dropout. This is combined with suitable acquisition functions for active learning. Empirical results on a popular stress and affect detection dataset experimented on a Raspberry Pi 2 indicate that our proposed framework achieves a considerable efficiency boost during inference, with a substantially low number of acquired pool points during active learning across various acquisition functions. Variation Ratios achieves an accuracy of 90.38% which is comparable to the maximum test accuracy achieved while training on about 40% lesser data.
EfficientPose: Efficient Human Pose Estimation with Neural Architecture Search
Dec 13, 2020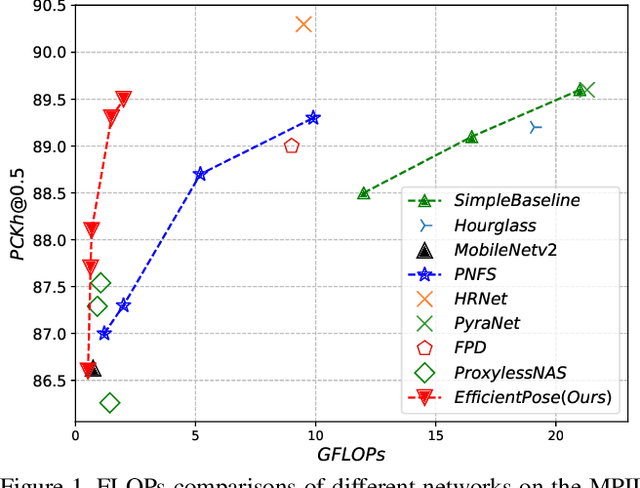
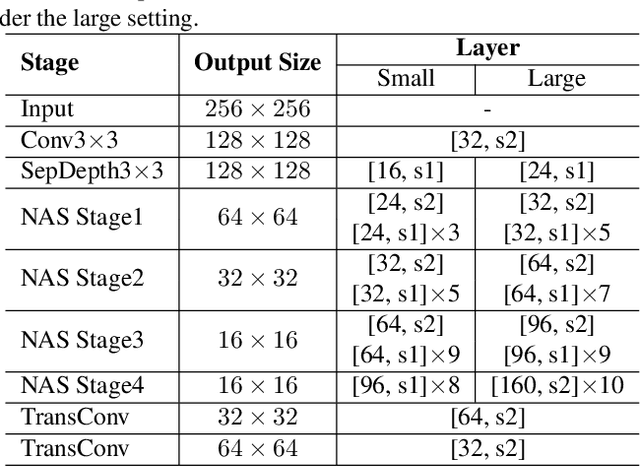
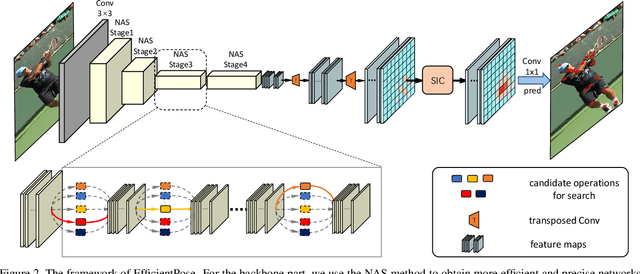
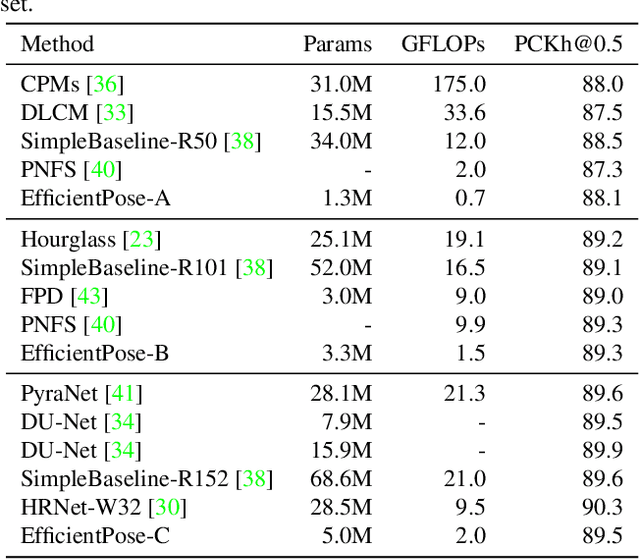
Human pose estimation from image and video is a vital task in many multimedia applications. Previous methods achieve great performance but rarely take efficiency into consideration, which makes it difficult to implement the networks on resource-constrained devices. Nowadays real-time multimedia applications call for more efficient models for better interactions. Moreover, most deep neural networks for pose estimation directly reuse the networks designed for image classification as the backbone, which are not yet optimized for the pose estimation task. In this paper, we propose an efficient framework targeted at human pose estimation including two parts, the efficient backbone and the efficient head. By implementing the differentiable neural architecture search method, we customize the backbone network design for pose estimation and reduce the computation cost with negligible accuracy degradation. For the efficient head, we slim the transposed convolutions and propose a spatial information correction module to promote the performance of the final prediction. In experiments, we evaluate our networks on the MPII and COCO datasets. Our smallest model has only 0.65 GFLOPs with 88.1% PCKh@0.5 on MPII and our large model has only 2 GFLOPs while its accuracy is competitive with the state-of-the-art large model, i.e., HRNet with 9.5 GFLOPs.
Search-based Kinodynamic Motion Planning for Omnidirectional Quadruped Robots
Nov 02, 2020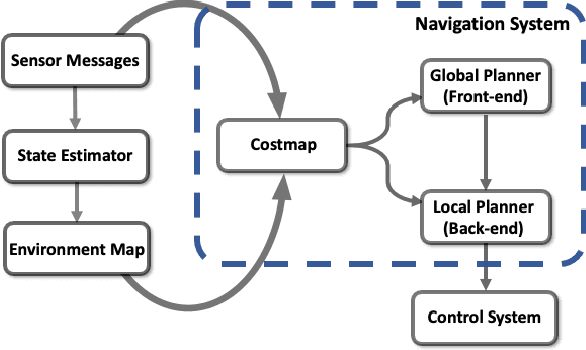
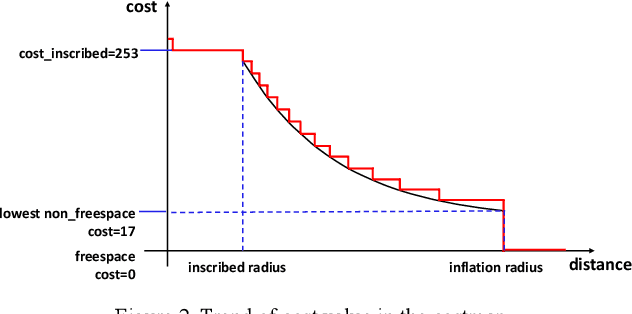

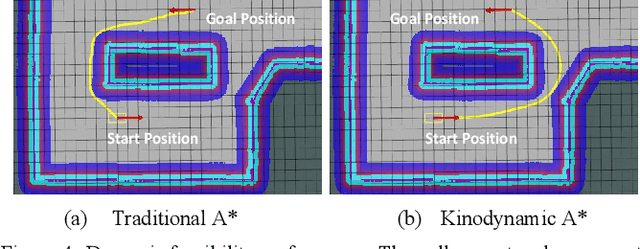
Autonomous navigation has played an increasingly significant role in quadruped robots system. However, existing works on path planning used traditional search-based or sample-based methods which did not consider the kinodynamic characteristics of quadruped robots. And paths generated by these methods contain kinodynamically infeasible parts, which are difficult to track. In the present work, we introduced a complete navigation system considering the omnidirectional abilities of quadruped robots. First, we use kinodynamic path finding method to obtain smooth, dynamically feasible, time-optimal initial paths and added collision cost as a soft constraint to ensure safety. Then the trajectory is refined by timed elastic band (TEB) method based on the omnidirectional model of quadruped robot. The superior performance of our work is demonstrated through simulated comparisons and by using our quadruped robot Jueying Mini in our experiments.
Multi-Scale 2D Temporal Adjacent Networks for Moment Localization with Natural Language
Dec 04, 2020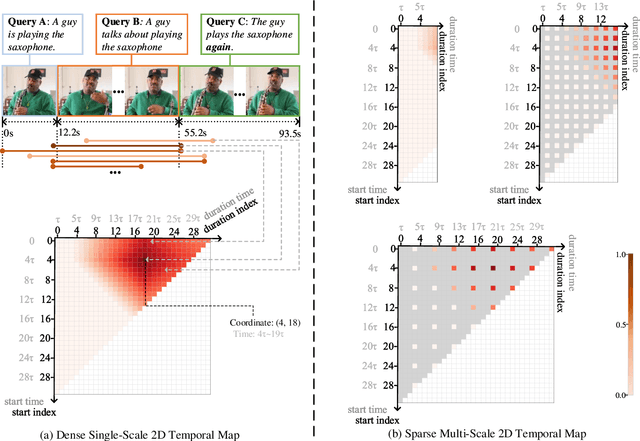
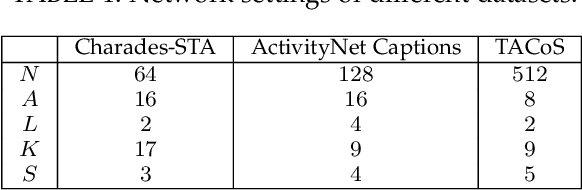
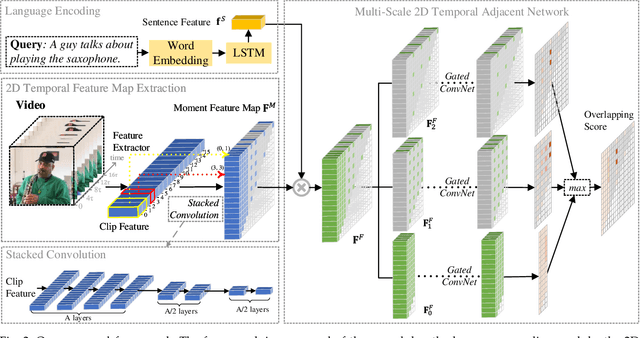
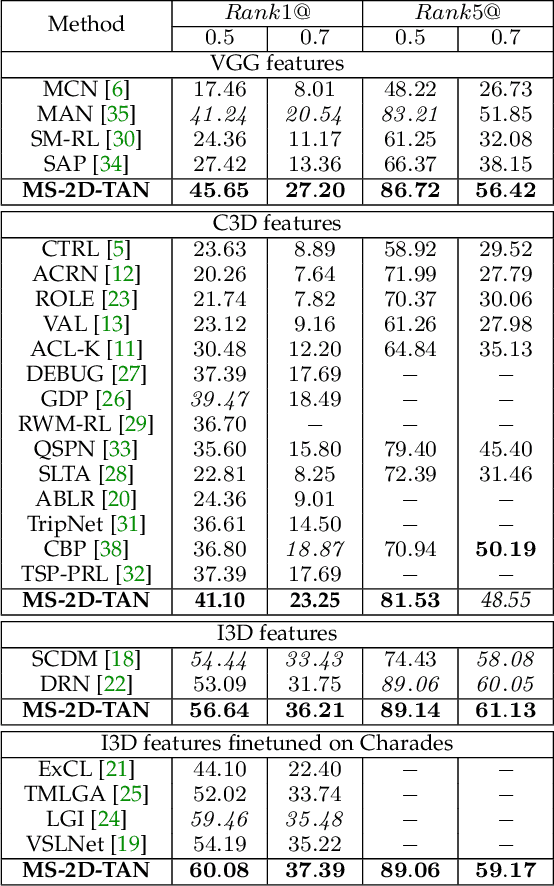
We address the problem of retrieving a specific moment from an untrimmed video by natural language. It is a challenging problem because a target moment may take place in the context of other temporal moments in the untrimmed video. Existing methods cannot tackle this challenge well since they do not fully consider the temporal contexts between temporal moments. In this paper, we model the temporal context between video moments by a set of predefined two-dimensional maps under different temporal scales. For each map, one dimension indicates the starting time of a moment and the other indicates the duration. These 2D temporal maps can cover diverse video moments with different lengths, while representing their adjacent contexts at different temporal scales. Based on the 2D temporal maps, we propose a Multi-Scale Temporal Adjacent Network (MS-2D-TAN), a single-shot framework for moment localization. It is capable of encoding the adjacent temporal contexts at each scale, while learning discriminative features for matching video moments with referring expressions. We evaluate the proposed MS-2D-TAN on three challenging benchmarks, i.e., Charades-STA, ActivityNet Captions, and TACoS, where our MS-2D-TAN outperforms the state of the art.
Linear Temporal Public Announcement Logic: a new perspective for reasoning the knowledge of multi-classifiers
Sep 09, 2020
Current applied intelligent systems have crucial shortcomings either in reasoning the gathered knowledge, or representation of comprehensive integrated information. To address these limitations, we develop a formal transition system which is applied to the common artificial intelligence (AI) systems, to reason about the findings. The developed model was created by combining the Public Announcement Logic (PAL) and the Linear Temporal Logic (LTL), which will be done to analyze both single-framed data and the following time-series data. To do this, first, the achieved knowledge by an AI-based system (i.e., classifiers) for an individual time-framed data, will be taken, and then, it would be modeled by a PAL. This leads to developing a unified representation of knowledge, and the smoothness in the integration of the gathered and external experiences. Therefore, the model could receive the classifier's predefined -- or any external -- knowledge, to assemble them in a unified manner. Alongside the PAL, all the timed knowledge changes will be modeled, using a temporal logic transition system. Later, following by the translation of natural language questions into the temporal formulas, the satisfaction leads the model to answer that question. This interpretation integrates the information of the recognized input data, rules, and knowledge. Finally, we suggest a mechanism to reduce the investigated paths for the performance improvements, which results in a partial correction for an object-detection system.
Abstractive Opinion Tagging
Jan 18, 2021
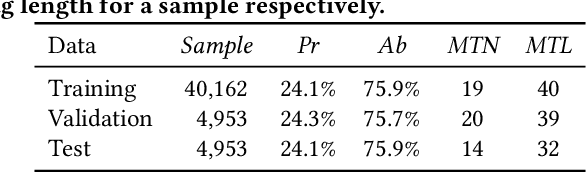
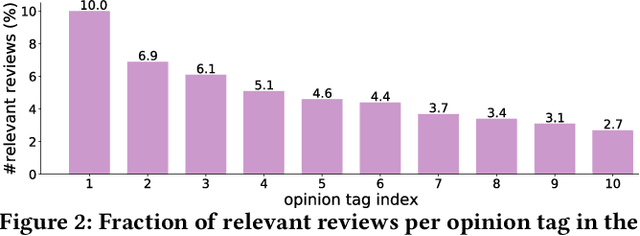
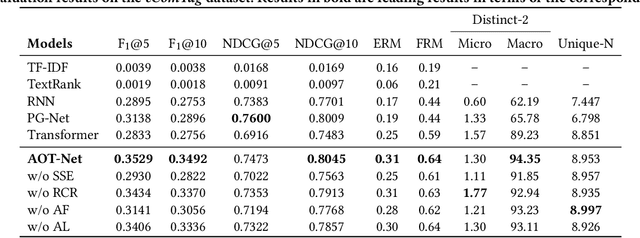
In e-commerce, opinion tags refer to a ranked list of tags provided by the e-commerce platform that reflect characteristics of reviews of an item. To assist consumers to quickly grasp a large number of reviews about an item, opinion tags are increasingly being applied by e-commerce platforms. Current mechanisms for generating opinion tags rely on either manual labelling or heuristic methods, which is time-consuming and ineffective. In this paper, we propose the abstractive opinion tagging task, where systems have to automatically generate a ranked list of opinion tags that are based on, but need not occur in, a given set of user-generated reviews. The abstractive opinion tagging task comes with three main challenges: (1) the noisy nature of reviews; (2) the formal nature of opinion tags vs. the colloquial language usage in reviews; and (3) the need to distinguish between different items with very similar aspects. To address these challenges, we propose an abstractive opinion tagging framework, named AOT-Net, to generate a ranked list of opinion tags given a large number of reviews. First, a sentence-level salience estimation component estimates each review's salience score. Next, a review clustering and ranking component ranks reviews in two steps: first, reviews are grouped into clusters and ranked by cluster size; then, reviews within each cluster are ranked by their distance to the cluster center. Finally, given the ranked reviews, a rank-aware opinion tagging component incorporates an alignment feature and alignment loss to generate a ranked list of opinion tags. To facilitate the study of this task, we create and release a large-scale dataset, called eComTag, crawled from real-world e-commerce websites. Extensive experiments conducted on the eComTag dataset verify the effectiveness of the proposed AOT-Net in terms of various evaluation metrics.
FPGA-based ORB Feature Extraction for Real-Time Visual SLAM
Oct 18, 2017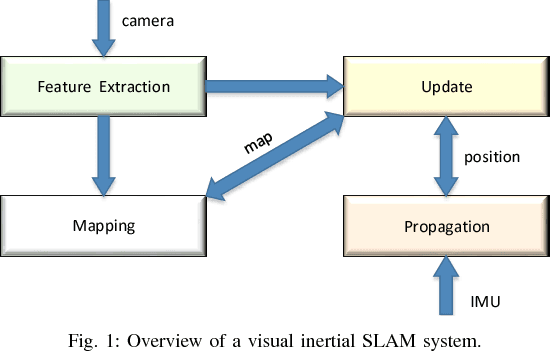
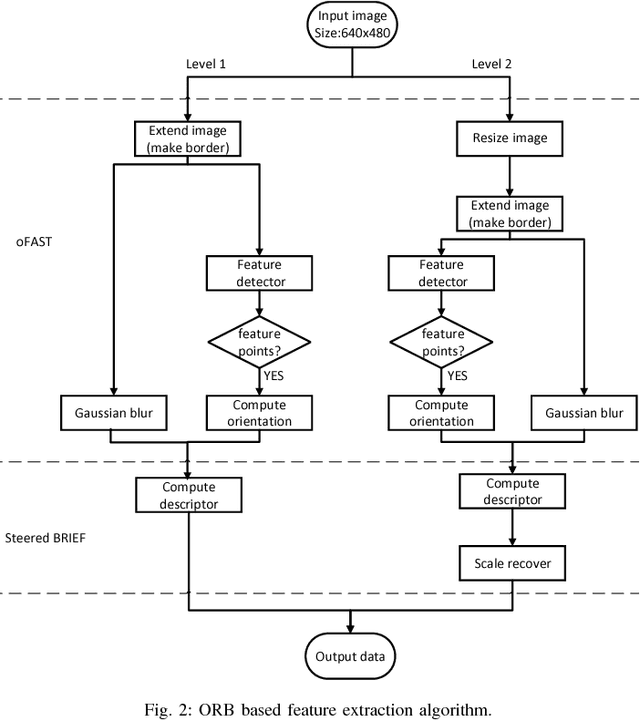
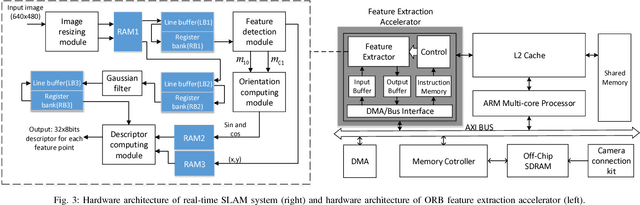
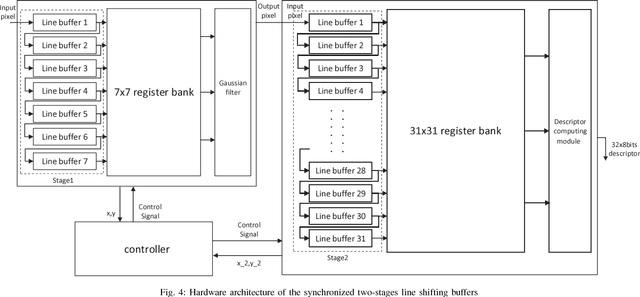
Simultaneous Localization And Mapping (SLAM) is the problem of constructing or updating a map of an unknown environment while simultaneously keeping track of an agent's location within it. How to enable SLAM robustly and durably on mobile, or even IoT grade devices, is the main challenge faced by the industry today. The main problems we need to address are: 1.) how to accelerate the SLAM pipeline to meet real-time requirements; and 2.) how to reduce SLAM energy consumption to extend battery life. After delving into the problem, we found out that feature extraction is indeed the bottleneck of performance and energy consumption. Hence, in this paper, we design, implement, and evaluate a hardware ORB feature extractor and prove that our design is a great balance between performance and energy consumption compared with ARM Krait and Intel Core i5.
Reinforcement Learning for Control of Valves
Dec 29, 2020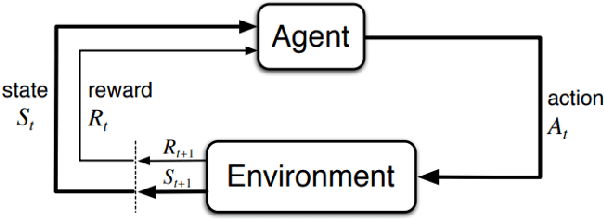
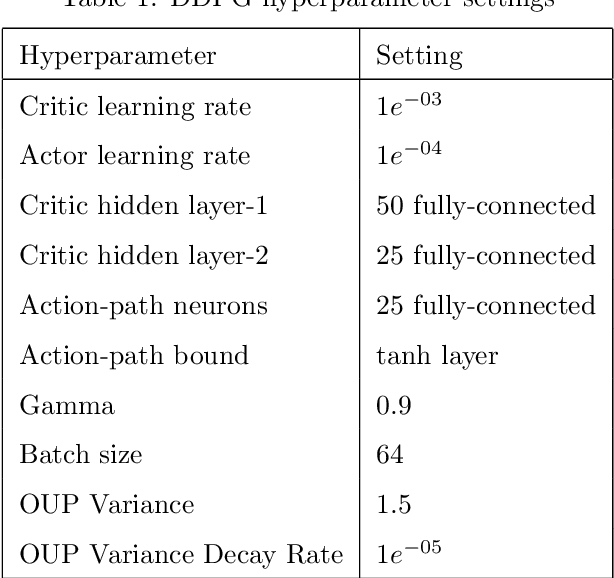
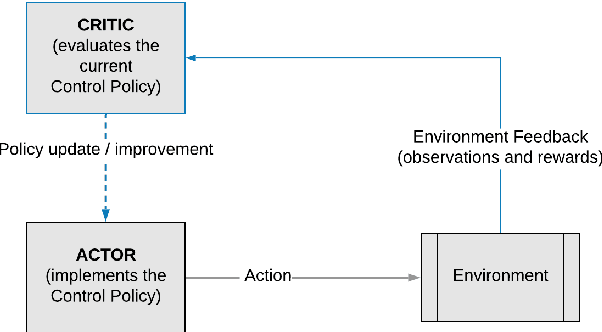
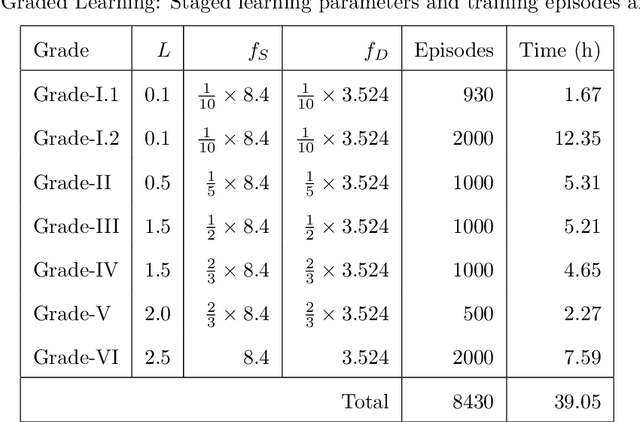
This paper compares reinforcement learning (RL) with PID (proportional-integral-derivative) strategy for control of nonlinear valves using a unified framework. RL is an autonomous learning mechanism that learns by interacting with its environment. It is gaining increasing attention in the world of control systems as a means of building optimal-controllers for challenging dynamic and nonlinear processes. Published RL research often uses open-source tools (Python and OpenAI Gym environments) which could be difficult to adapt and apply by practicing industrial engineers, we therefore used MathWorks tools. MATLAB's recently launched (R2019a) Reinforcement Learning Toolbox was used to develop the valve controller; trained using the DDPG (Deep Deterministic Policy-Gradient) algorithm and Simulink to simulate the nonlinear valve and setup the experimental test-bench to evaluate the RL and PID controllers. Results indicate that the RL controller is extremely good at tracking the signal with speed and produces a lower error with respect to the reference signals. The PID, however, is better at disturbance rejection and hence provides a longer life for the valves. Experiential learnings gained from this research are corroborated against published research. It is known that successful machine learning involves tuning many hyperparameters and significant investment of time and efforts. We introduce ``Graded Learning" as a simplified, application oriented adaptation of the more formal and algorithmic ``Curriculum for Reinforcement Learning''. It is shown via experiments that it helps converge the learning task of complex non-linear real world systems.