 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Few-Shot Learning with Class Imbalance
Jan 07, 2021
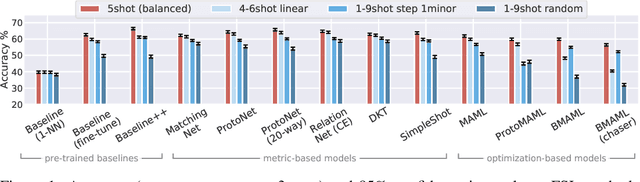
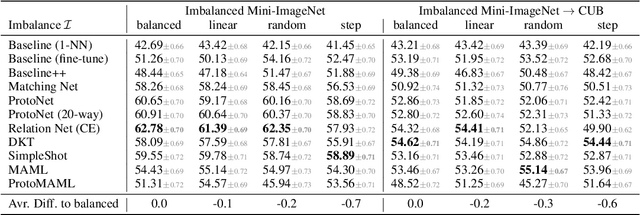
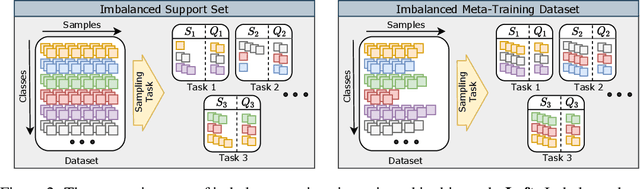
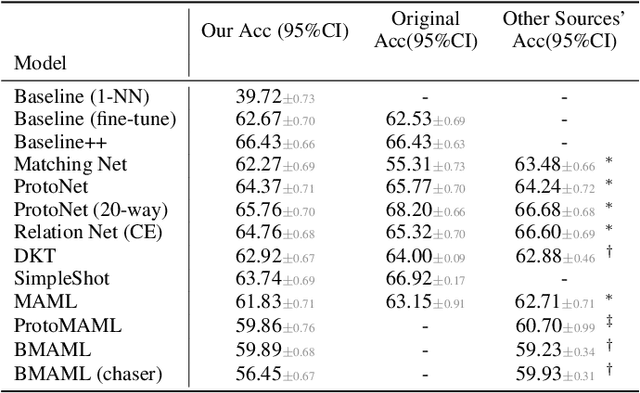
Few-shot learning aims to train models on a limited number of labeled samples given in a support set in order to generalize to unseen samples from a query set. In the standard setup, the support set contains an equal amount of data points for each class. However, this assumption overlooks many practical considerations arising from the dynamic nature of the real world, such as class-imbalance. In this paper, we present a detailed study of few-shot class-imbalance along three axes: meta-dataset vs. task imbalance, effect of different imbalance distributions (linear, step, random), and effect of rebalancing techniques. We extensively compare over 10 state-of-the-art few-shot learning and meta-learning methods using unbalanced tasks and meta-datasets. Our analysis using Mini-ImageNet reveals that 1) compared to the balanced task, the performances on class-imbalance tasks counterparts always drop, by up to $18.0\%$ for optimization-based methods, and up to $8.4$ for metric-based methods, 2) contrary to popular belief, meta-learning algorithms, such as MAML, do not automatically learn to balance by being exposed to imbalanced tasks during (meta-)training time, 3) strategies used to mitigate imbalance in supervised learning, such as oversampling, can offer a stronger solution to the class imbalance problem, 4) the effect of imbalance at the meta-dataset level is less significant than the effect at the task level with similar imbalance magnitude. The code to reproduce the experiments is released under an open-source license.
Resource-efficient adaptive Bayesian tracking of magnetic fields with a quantum sensor
Aug 20, 2020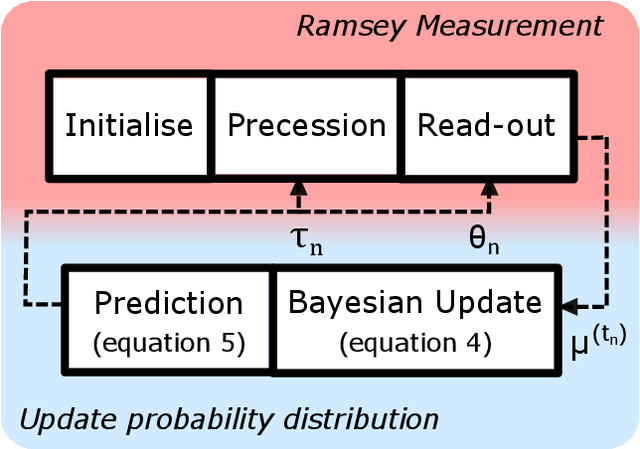
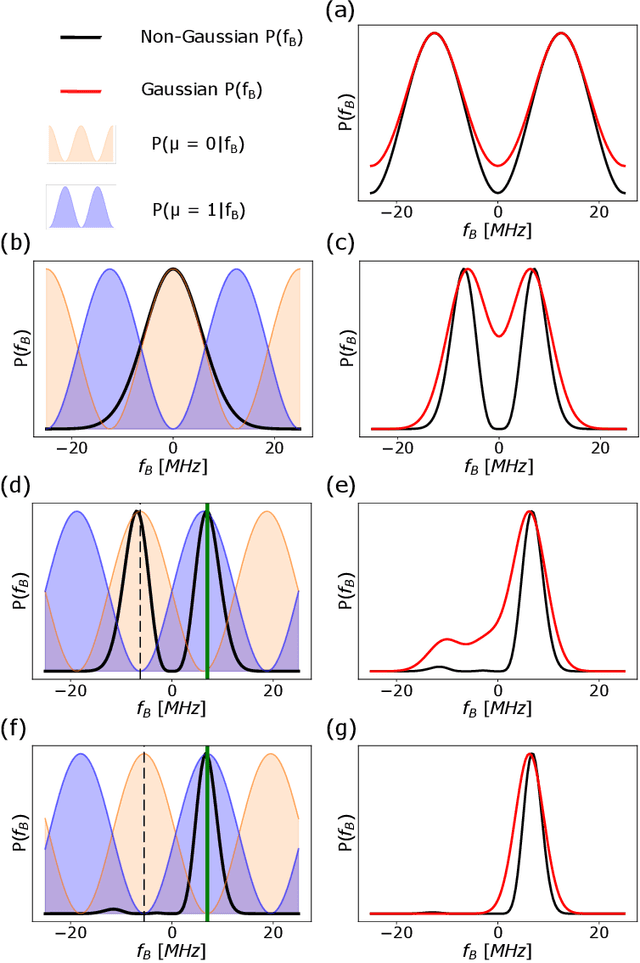
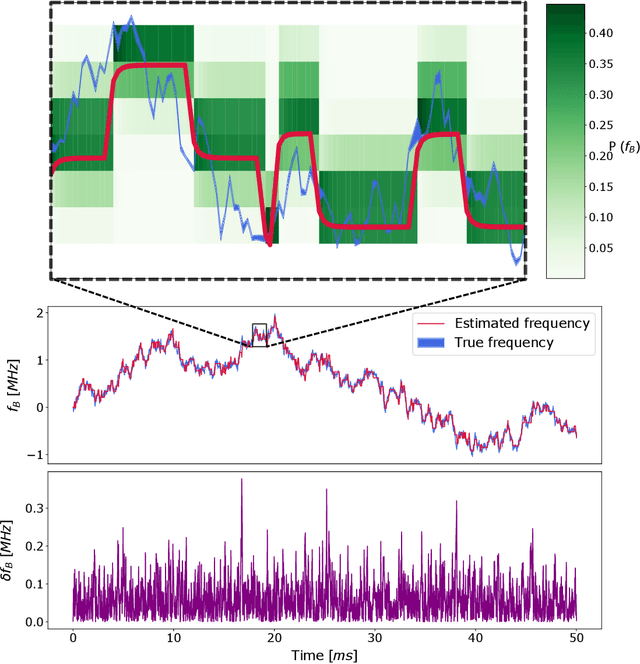
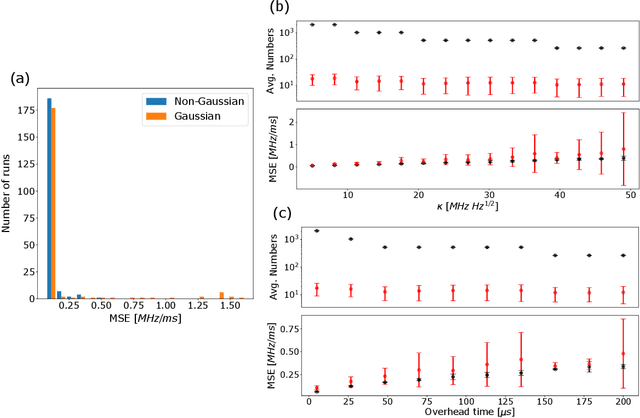
By addressing single electron spins through Ramsey experiments, nitrogen-vacancy centres can act as high-resolution sensors of magnetic field. In applications where the magnetic field may be changing rapidly, total sensing time is crucial and must be minimised. Bayesian estimation and adaptive experiment optimisation protocols work by computing the probability distribution of the magnetic field based on measurement outcomes and, by computing aquisition settings for the next measurement. These protocols can speed up the sensing process by reducing the number of measurements required. However, the computations feeding into the next iteration measurement settings must be performed quickly enough to allow real-time updates. This paper addresses the issue of computational speed by implementing an approximated Bayesian estimation technique, where probability distributions are approximated by a superposition of Gaussian functions. Given that only three parameters are required to fully describe a Gaussian, we find that the magnetic field probability distribution can typically be described by fewer than ten numbers, achieving a reduction in the number of operations by factor 20 compared to existing approaches, allowing for faster processing.
Temporal Pyramid Network for Pedestrian Trajectory Prediction with Multi-Supervision
Dec 04, 2020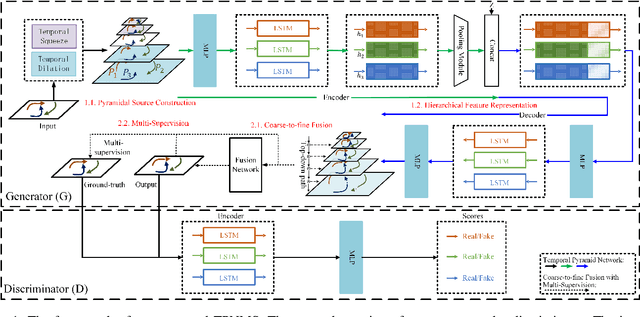
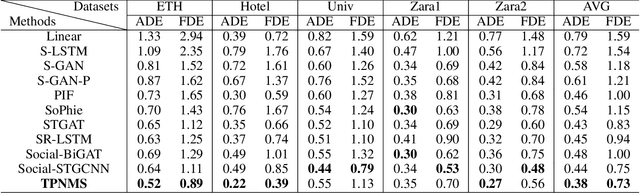
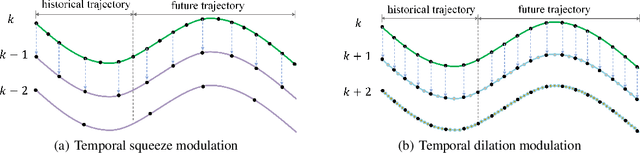
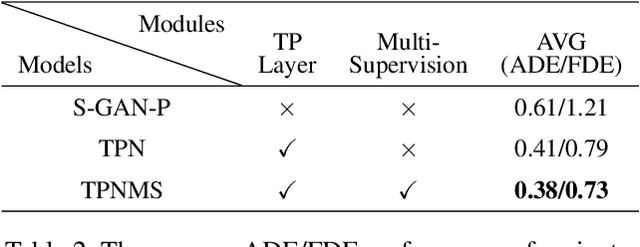
Predicting human motion behavior in a crowd is important for many applications, ranging from the natural navigation of autonomous vehicles to intelligent security systems of video surveillance. All the previous works model and predict the trajectory with a single resolution, which is rather inefficient and difficult to simultaneously exploit the long-range information (e.g., the destination of the trajectory), and the short-range information (e.g., the walking direction and speed at a certain time) of the motion behavior. In this paper, we propose a temporal pyramid network for pedestrian trajectory prediction through a squeeze modulation and a dilation modulation. Our hierarchical framework builds a feature pyramid with increasingly richer temporal information from top to bottom, which can better capture the motion behavior at various tempos. Furthermore, we propose a coarse-to-fine fusion strategy with multi-supervision. By progressively merging the top coarse features of global context to the bottom fine features of rich local context, our method can fully exploit both the long-range and short-range information of the trajectory. Experimental results on several benchmarks demonstrate the superiority of our method.
FPGA deep learning acceleration based on convolutional neural network
Nov 17, 2020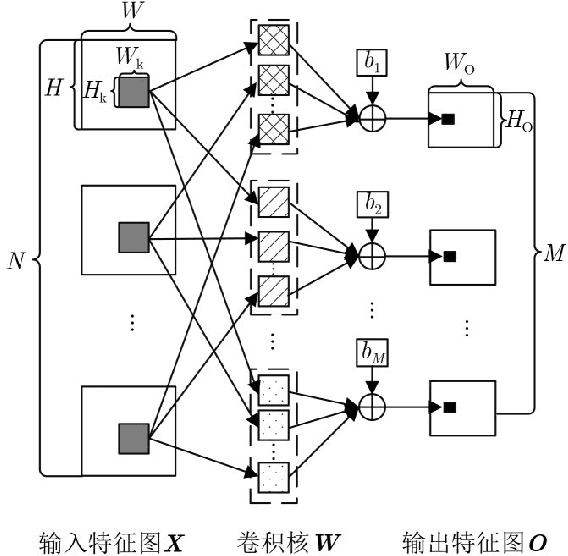
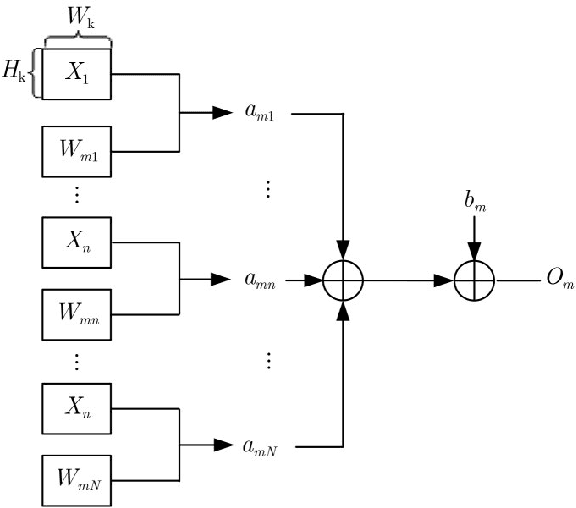
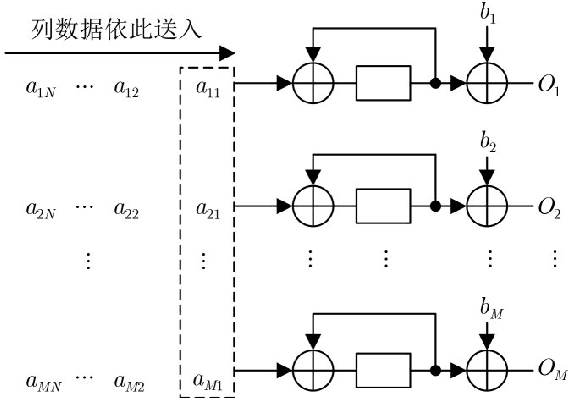
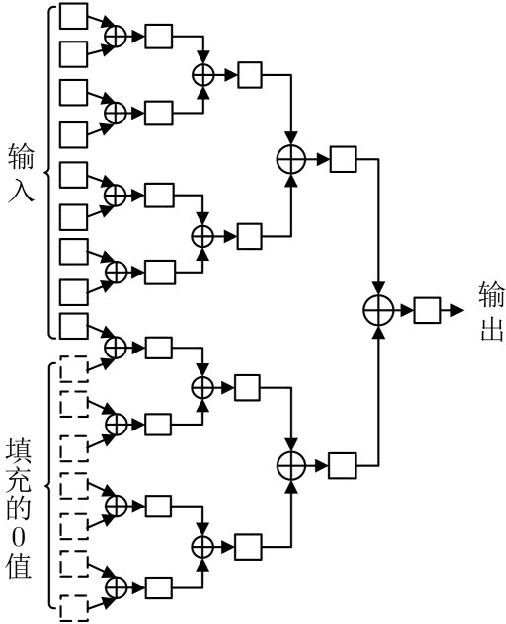
In view of the large amount of calculation and long calculation time of convolutional neural network (CNN), this paper proposes a convolutional neural network hardware accelerator based on field programmable logic gate array (FPGA). First, through in-depth analysis of the forward operation principle of the convolutional layer and exploration of the parallelism of the convolutional layer operation, a hardware architecture of input channel parallelism, output channel parallelism and convolution window deep pipeline is designed. Then in the above architecture, a fully parallel multiplication-addition tree module is designed to accelerate the convolution operation and an efficient window buffer module to implement the pipeline operation of the convolution window. The final experimental results show that the energy efficiency ratio of the accelerator proposed in this article reaches 32.73 GOPS/W, which is 34% higher than the existing solution, and the performance reaches 317.86 GOPS.
Contextual BERT: Conditioning the Language Model Using a Global State
Oct 29, 2020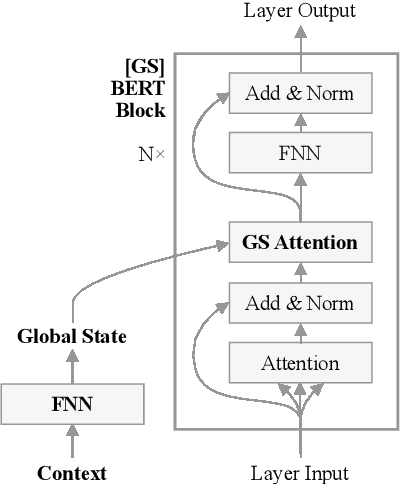

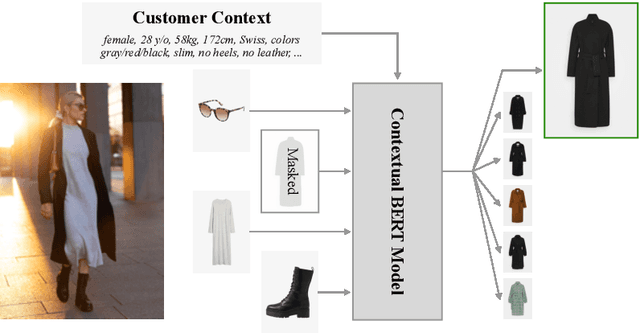
BERT is a popular language model whose main pre-training task is to fill in the blank, i.e., predicting a word that was masked out of a sentence, based on the remaining words. In some applications, however, having an additional context can help the model make the right prediction, e.g., by taking the domain or the time of writing into account. This motivates us to advance the BERT architecture by adding a global state for conditioning on a fixed-sized context. We present our two novel approaches and apply them to an industry use-case, where we complete fashion outfits with missing articles, conditioned on a specific customer. An experimental comparison to other methods from the literature shows that our methods improve personalization significantly.
Deep Learning Methods for Vessel Trajectory Prediction based on Recurrent Neural Networks
Jan 07, 2021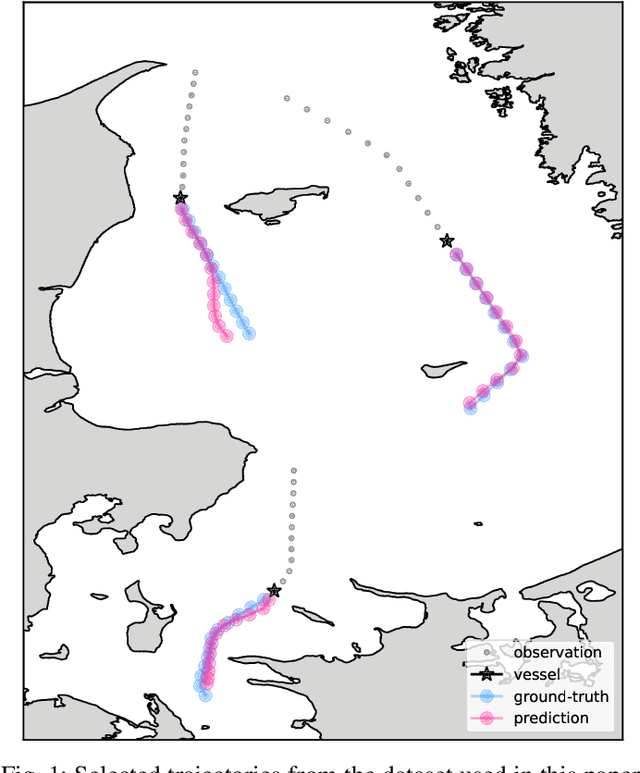
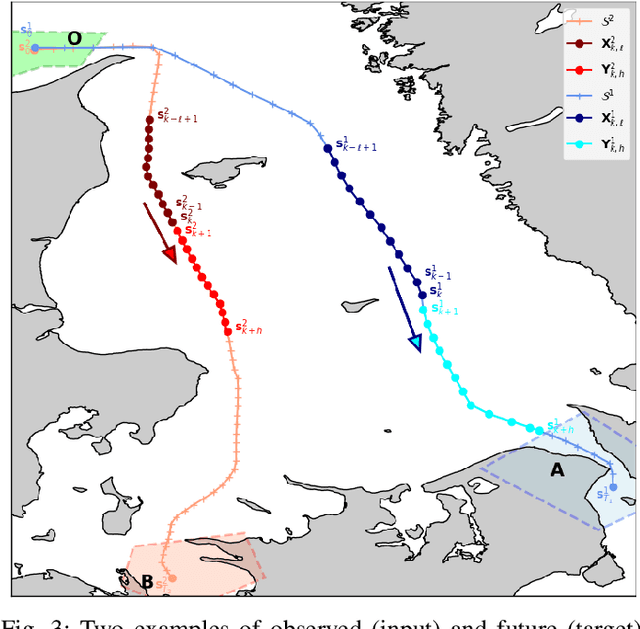
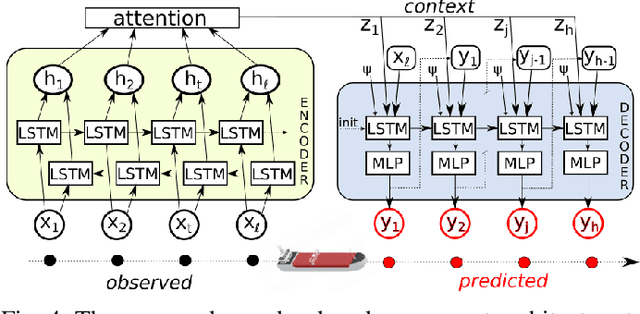
Data-driven methods open up unprecedented possibilities for maritime surveillance using Automatic Identification System (AIS) data. In this work, we explore deep learning strategies using historical AIS observations to address the problem of predicting future vessel trajectories with a prediction horizon of several hours. We propose novel sequence-to-sequence vessel trajectory prediction models based on encoder-decoder recurrent neural networks (RNNs) that are trained on historical trajectory data to predict future trajectory samples given previous observations. The proposed architecture combines Long Short-Term Memory (LSTM) RNNs for sequence modeling to encode the observed data and generate future predictions with different intermediate aggregation layers to capture space-time dependencies in sequential data. Experimental results on vessel trajectories from an AIS dataset made freely available by the Danish Maritime Authority show the effectiveness of deep-learning methods for trajectory prediction based on sequence-to-sequence neural networks, which achieve better performance than baseline approaches based on linear regression or feed-forward networks. The comparative evaluation of results shows: i) the superiority of attention pooling over static pooling for the specific application, and ii) the remarkable performance improvement that can be obtained with labeled trajectories, i.e. when predictions are conditioned on a low-level context representation encoded from the sequence of past observations, as well as on additional inputs (e.g., the port of departure or arrival) about the vessel's high-level intention which may be available from AIS.
Deep learning approaches for fast radio signal prediction
Jul 14, 2020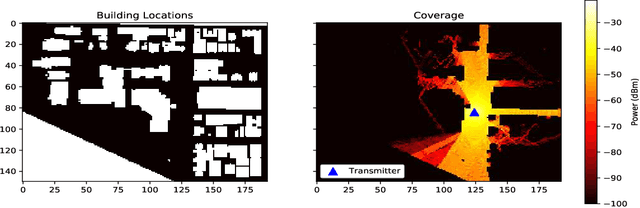
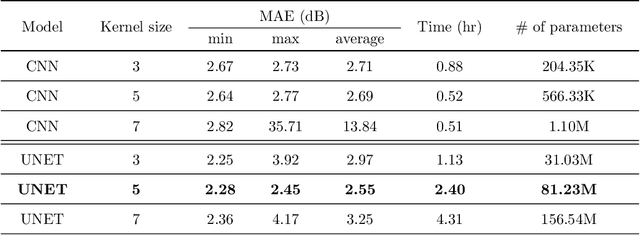
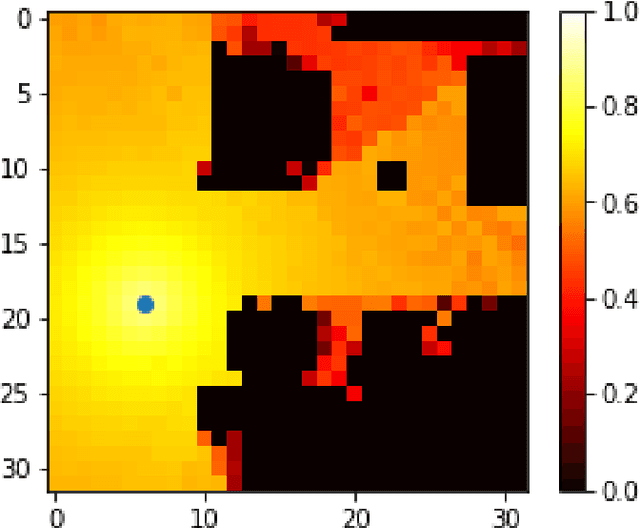
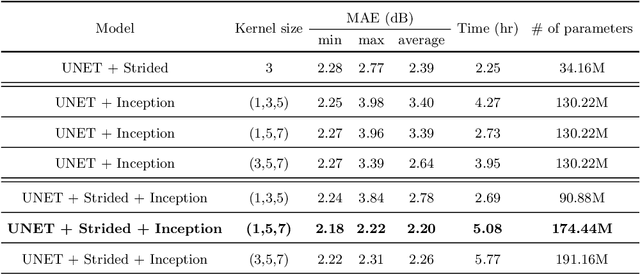
The aim of this work is the prediction of power coverage in a dense urban environment given building and transmitter locations. Conventionally ray-tracing is regarded as the most accurate method to predict energy distribution patterns in the area in the presence of diverse radio propagation phenomena. However, ray-tracing simulations are time consuming and require extensive computational resources. We propose deep neural network models to learn from ray-tracing results and predict the power coverage dynamically from buildings and transmitter properties. The proposed UNET model with strided convolutions and inception modules provide highly accurate results that are close to the ray-tracing output on 32x32 frames. This model will allow practitioners to search for the best transmitter locations effectively and reduce the design time significantly.
How should a fixed budget of dwell time be spent in scanning electron microscopy to optimize image quality?
Jan 12, 2018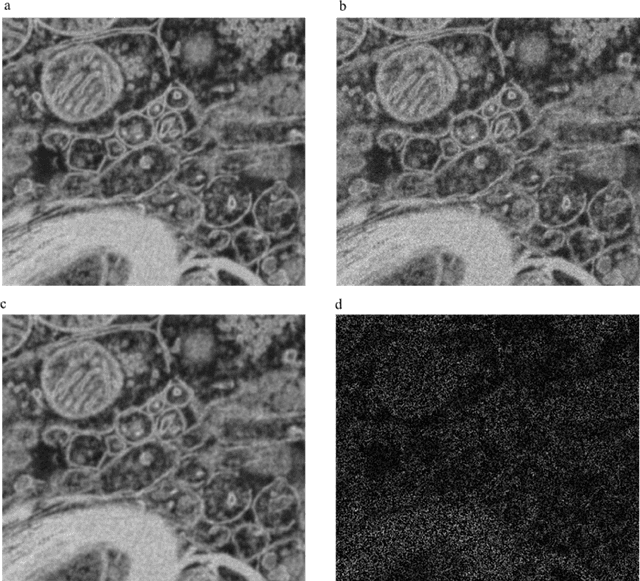
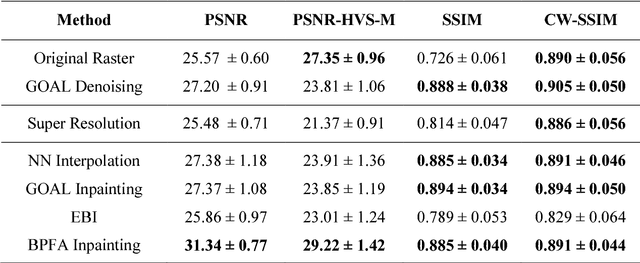

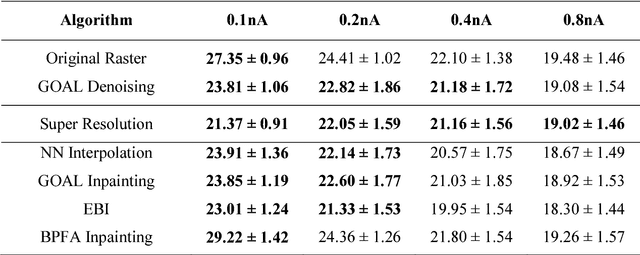
In scanning electron microscopy, the achievable image quality is often limited by a maximum feasible acquisition time per dataset. Particularly with regard to three-dimensional or large field-of-view imaging, a compromise must be found between a high amount of shot noise, which leads to a low signal-to-noise ratio, and excessive acquisition times. Assuming a fixed acquisition time per frame, we compared three different strategies for algorithm-assisted image acquisition in scanning electron microscopy. We evaluated (1) raster scanning with a reduced dwell time per pixel followed by a state-of-the-art Denoising algorithm, (2) raster scanning with a decreased resolution in conjunction with a state-of-the-art Super Resolution algorithm, and (3) a sparse scanning approach where a fixed percentage of pixels is visited by the beam in combination with state-of-the-art inpainting algorithms. Additionally, we considered increased beam currents for each of the strategies. The experiments showed that sparse scanning using an appropriate reconstruction technique was superior to the other strategies.
Microsoft Recommenders: Tools to Accelerate Developing Recommender Systems
Aug 27, 2020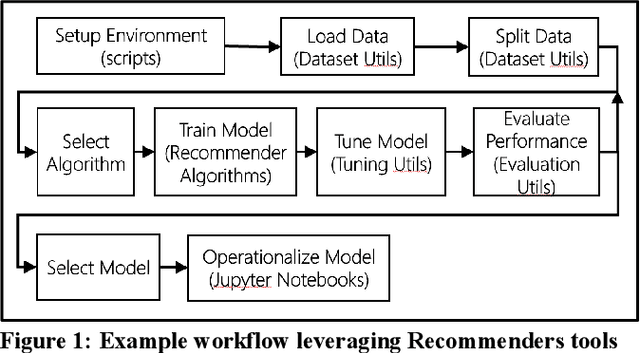
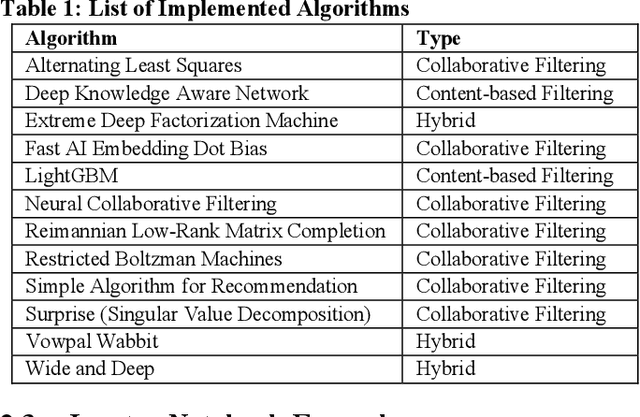
The purpose of this work is to highlight the content of the Microsoft Recommenders repository and show how it can be used to reduce the time involved in developing recommender systems. The open source repository provides python utilities to simplify common recommender-related data science work as well as example Jupyter notebooks that demonstrate use of the algorithms and tools under various environments.
* pages: 2; submitted to: RecSys '19
Leaking Sensitive Financial Accounting Data in Plain Sight using Deep Autoencoder Neural Networks
Dec 13, 2020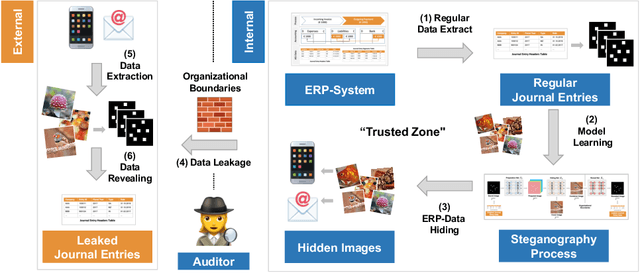
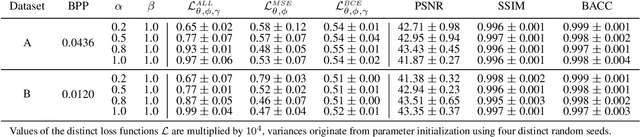
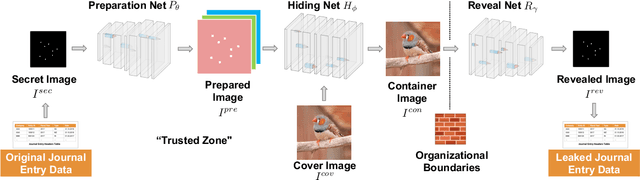
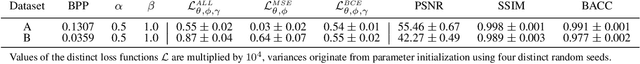
Nowadays, organizations collect vast quantities of sensitive information in `Enterprise Resource Planning' (ERP) systems, such as accounting relevant transactions, customer master data, or strategic sales price information. The leakage of such information poses a severe threat for companies as the number of incidents and the reputational damage to those experiencing them continue to increase. At the same time, discoveries in deep learning research revealed that machine learning models could be maliciously misused to create new attack vectors. Understanding the nature of such attacks becomes increasingly important for the (internal) audit and fraud examination practice. The creation of such an awareness holds in particular for the fraudulent data leakage using deep learning-based steganographic techniques that might remain undetected by state-of-the-art `Computer Assisted Audit Techniques' (CAATs). In this work, we introduce a real-world `threat model' designed to leak sensitive accounting data. In addition, we show that a deep steganographic process, constituted by three neural networks, can be trained to hide such data in unobtrusive `day-to-day' images. Finally, we provide qualitative and quantitative evaluations on two publicly available real-world payment datasets.