 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Barycode-based GJK Algorithm
Nov 18, 2020
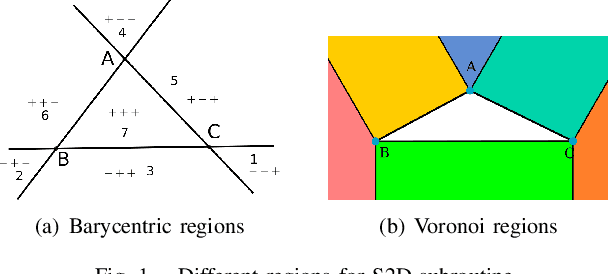
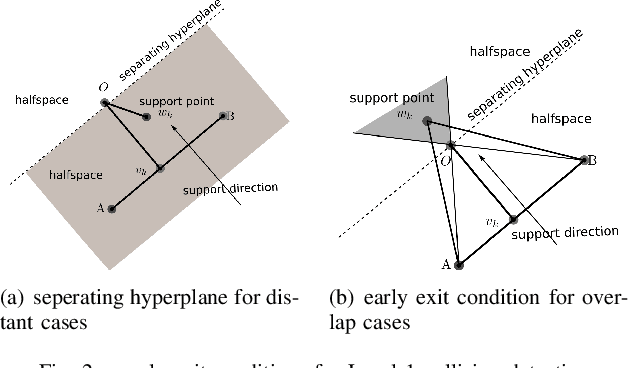
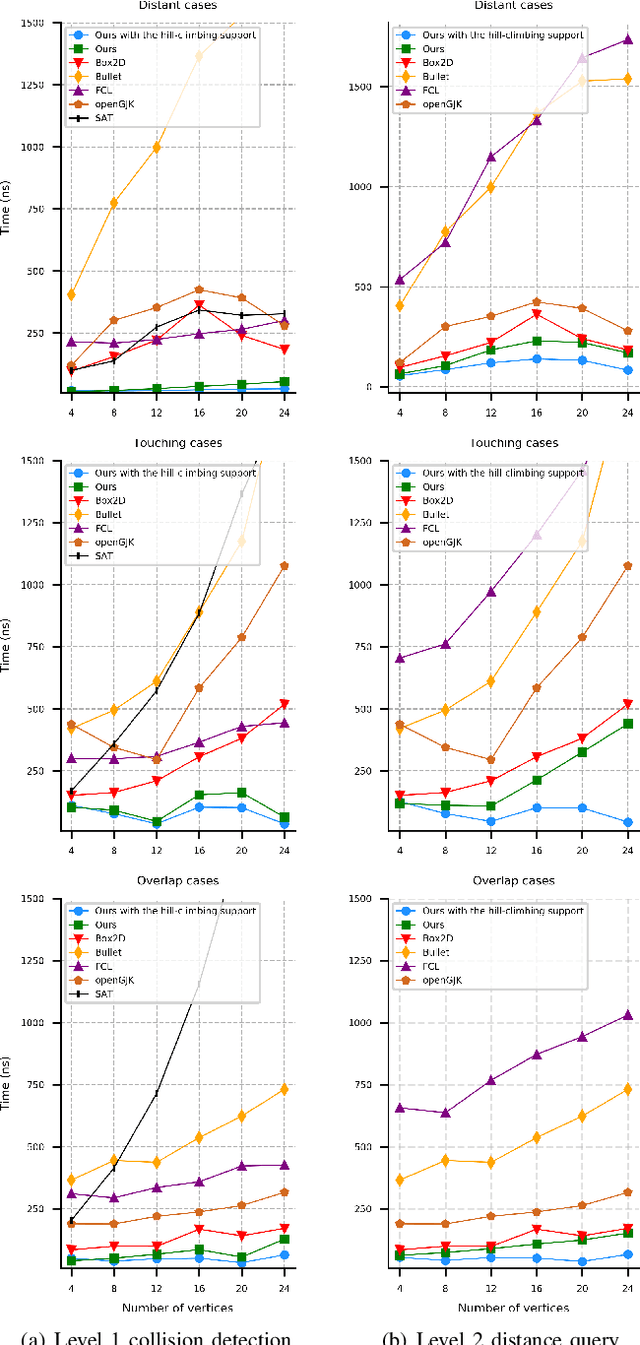
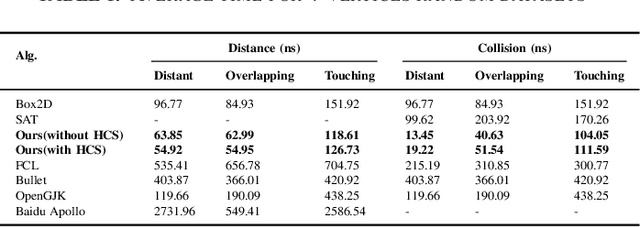
In this paper, we present a more efficient GJK algorithm to solve the collision detection and distance query problems in 2D. We contribute in two aspects: First, we propose a new barycode-based sub-distance algorithm that does not only provide a simple and unified condition to determine the minimum simplex but also improve the efficiency in distant, touching, and overlap cases in distance query. Second, we provide a highly efficient implementation subroutine for collision detection by optimizing the exit conditions of our GJK distance algorithm, which shows dramatic improvements in run-time for applications that only need binary results. We benchmark our methods along with that of the well-known open-source collision detection libraries, such as Bullet, FCL, OpenGJK, Box2D, and Apollo over a range of random datasets. The results indicate that our methods and implementations outperform the state-of-the-art in both collision detection and distance query.
WaveFuse: A Unified Deep Framework for Image Fusion with Wavelet Transform
Jul 28, 2020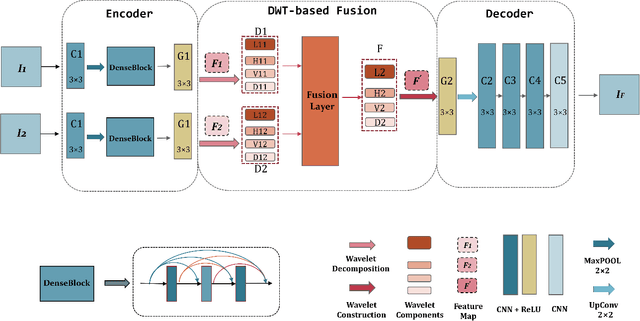
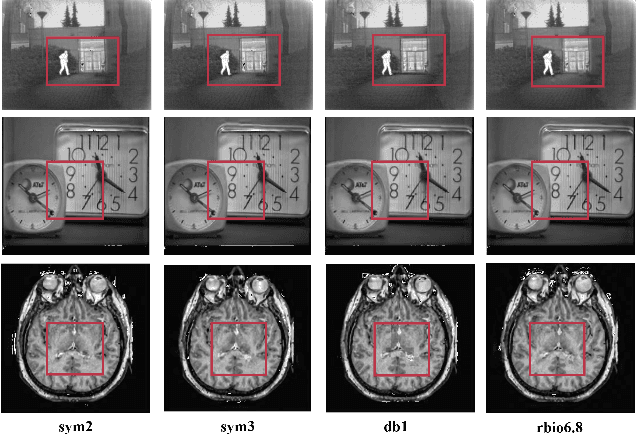
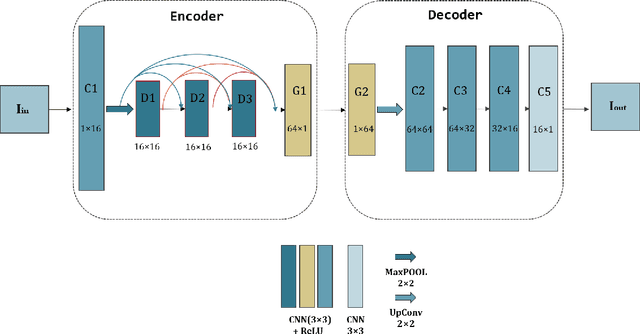
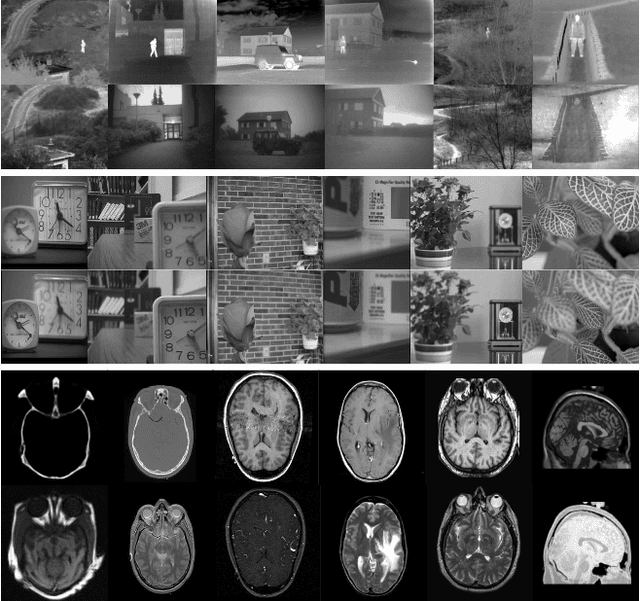
We propose an unsupervised image fusion architecture for multiple application scenarios based on the combination of multi-scale discrete wavelet transform through regional energy and deep learning. To our best knowledge, this is the first time the conventional image fusion method has been combined with deep learning. The useful information of feature maps can be utilized adequately through multi-scale discrete wavelet transform in our proposed method.Compared with other state-of-the-art fusion method, the proposed algorithm exhibits better fusion performance in both subjective and objective evaluation. Moreover, it's worth mentioning that comparable fusion performance trained in COCO dataset can be obtained by training with a much smaller dataset with only hundreds of images chosen randomly from COCO. Hence, the training time is shortened substantially, leading to the improvement of the model's performance both in practicality and training efficiency.
Frame-To-Frame Consistent Semantic Segmentation
Aug 20, 2020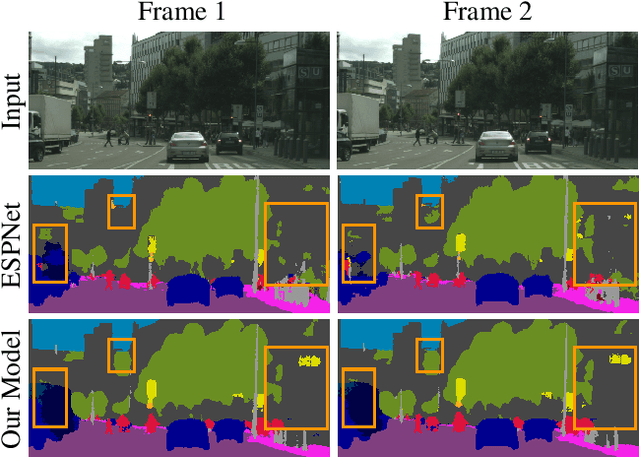
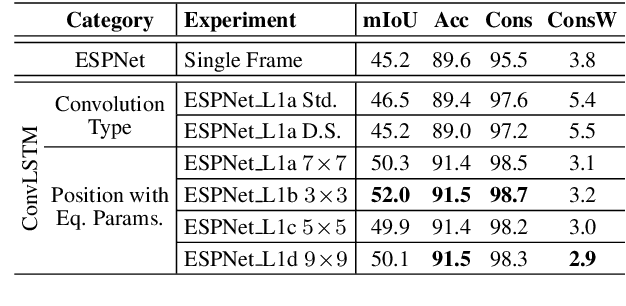
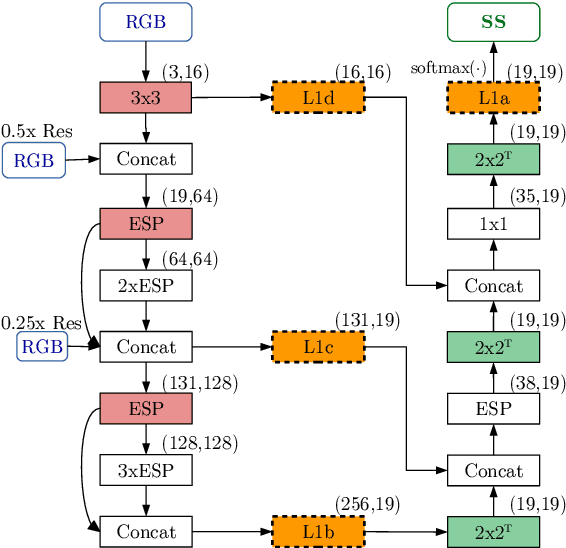
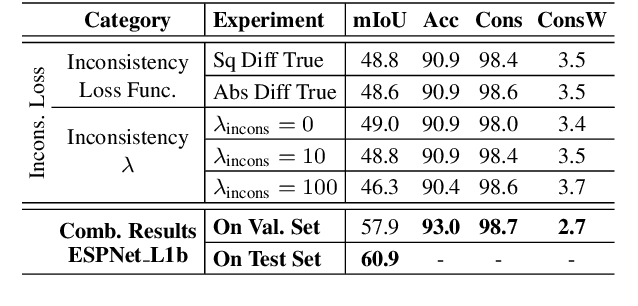
In this work, we aim for temporally consistent semantic segmentation throughout frames in a video. Many semantic segmentation algorithms process images individually which leads to an inconsistent scene interpretation due to illumination changes, occlusions and other variations over time. To achieve a temporally consistent prediction, we train a convolutional neural network (CNN) which propagates features through consecutive frames in a video using a convolutional long short term memory (ConvLSTM) cell. Besides the temporal feature propagation, we penalize inconsistencies in our loss function. We show in our experiments that the performance improves when utilizing video information compared to single frame prediction. The mean intersection over union (mIoU) metric on the Cityscapes validation set increases from 45.2 % for the single frames to 57.9 % for video data after implementing the ConvLSTM to propagate features trough time on the ESPNet. Most importantly, inconsistency decreases from 4.5 % to 1.3 % which is a reduction by 71.1 %. Our results indicate that the added temporal information produces a frame-to-frame consistent and more accurate image understanding compared to single frame processing.
Learning Deep ReLU Networks Is Fixed-Parameter Tractable
Sep 28, 2020We consider the problem of learning an unknown ReLU network with respect to Gaussian inputs and obtain the first nontrivial results for networks of depth more than two. We give an algorithm whose running time is a fixed polynomial in the ambient dimension and some (exponentially large) function of only the network's parameters. Our bounds depend on the number of hidden units, depth, spectral norm of the weight matrices, and Lipschitz constant of the overall network (we show that some dependence on the Lipschitz constant is necessary). We also give a bound that is doubly exponential in the size of the network but is independent of spectral norm. These results provably cannot be obtained using gradient-based methods and give the first example of a class of efficiently learnable neural networks that gradient descent will fail to learn. In contrast, prior work for learning networks of depth three or higher requires exponential time in the ambient dimension, even when the above parameters are bounded by a constant. Additionally, all prior work for the depth-two case requires well-conditioned weights and/or positive coefficients to obtain efficient run-times. Our algorithm does not require these assumptions. Our main technical tool is a type of filtered PCA that can be used to iteratively recover an approximate basis for the subspace spanned by the hidden units in the first layer. Our analysis leverages new structural results on lattice polynomials from tropical geometry.
LADDER: A Human-Level Bidding Agent for Large-Scale Real-Time Online Auctions
Sep 01, 2017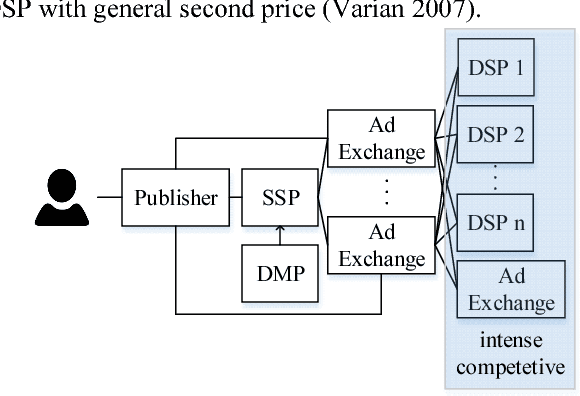
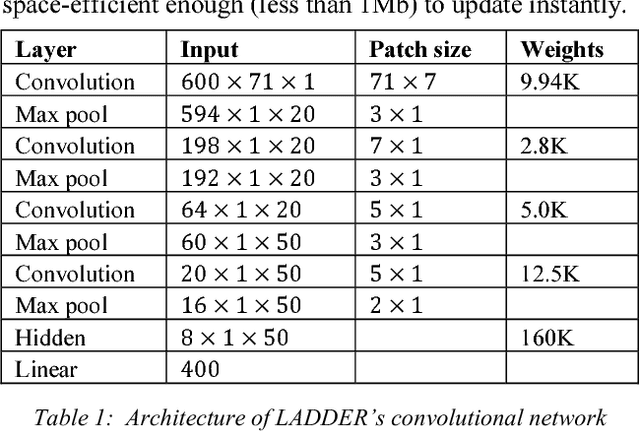
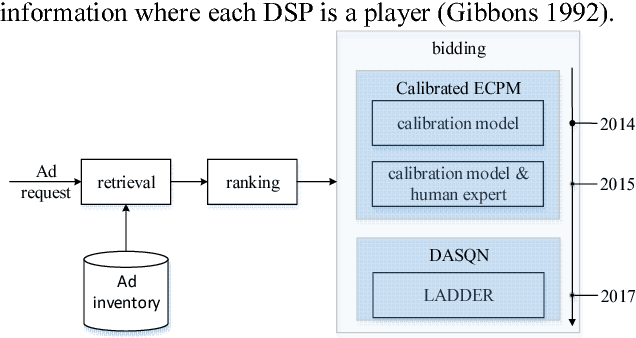
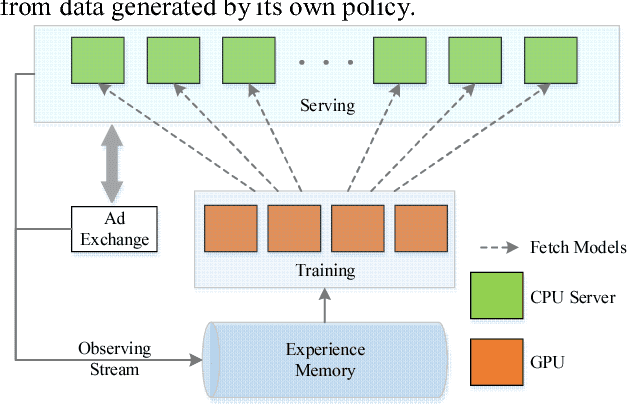
We present LADDER, the first deep reinforcement learning agent that can successfully learn control policies for large-scale real-world problems directly from raw inputs composed of high-level semantic information. The agent is based on an asynchronous stochastic variant of DQN (Deep Q Network) named DASQN. The inputs of the agent are plain-text descriptions of states of a game of incomplete information, i.e. real-time large scale online auctions, and the rewards are auction profits of very large scale. We apply the agent to an essential portion of JD's online RTB (real-time bidding) advertising business and find that it easily beats the former state-of-the-art bidding policy that had been carefully engineered and calibrated by human experts: during JD.com's June 18th anniversary sale, the agent increased the company's ads revenue from the portion by more than 50%, while the advertisers' ROI (return on investment) also improved significantly.
Seeing is Knowing! Fact-based Visual Question Answering using Knowledge Graph Embeddings
Dec 31, 2020

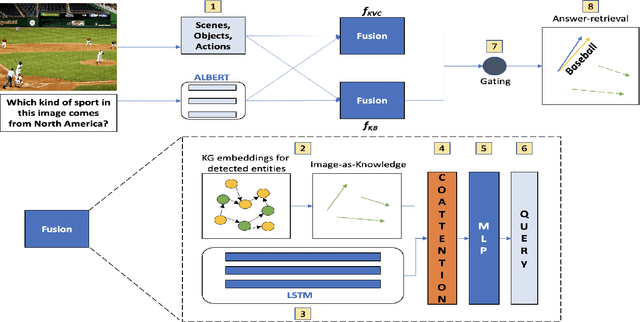

Fact-based Visual Question Answering (FVQA), a challenging variant of VQA, requires a QA-system to include facts from a diverse knowledge graph (KG) in its reasoning process to produce an answer. Large KGs, especially common-sense KGs, are known to be incomplete, i.e. not all non-existent facts are always incorrect. Therefore, being able to reason over incomplete KGs for QA is a critical requirement in real-world applications that has not been addressed extensively in the literature. We develop a novel QA architecture that allows us to reason over incomplete KGs, something current FVQA state-of-the-art (SOTA) approaches lack.We use KG Embeddings, a technique widely used for KG completion, for the downstream task of FVQA. We also employ a new image representation technique we call "Image-as-Knowledge" to enable this capability, alongside a simple one-step co-Attention mechanism to attend to text and image during QA. Our FVQA architecture is faster during inference time, being O(m), as opposed to existing FVQA SOTA methods which are O(N logN), where m is number of vertices, N is number of edges (which is O(m^2)). We observe that our architecture performs comparably in the standard answer-retrieval baseline with existing methods; while for missing-edge reasoning, our KG representation outperforms the SOTA representation by 25%, and image representation outperforms the SOTA representation by 2.6%.
Deep Portfolio Optimization via Distributional Prediction of Residual Factors
Dec 14, 2020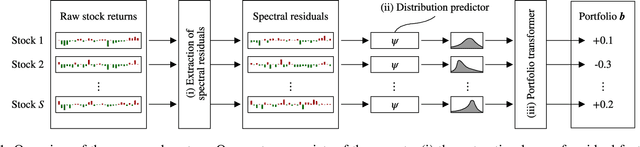
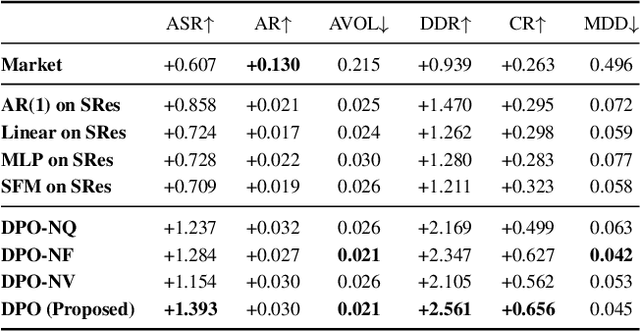
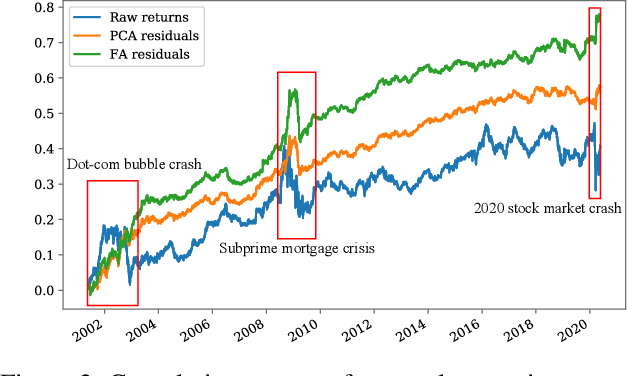
Recent developments in deep learning techniques have motivated intensive research in machine learning-aided stock trading strategies. However, since the financial market has a highly non-stationary nature hindering the application of typical data-hungry machine learning methods, leveraging financial inductive biases is important to ensure better sample efficiency and robustness. In this study, we propose a novel method of constructing a portfolio based on predicting the distribution of a financial quantity called residual factors, which is known to be generally useful for hedging the risk exposure to common market factors. The key technical ingredients are twofold. First, we introduce a computationally efficient extraction method for the residual information, which can be easily combined with various prediction algorithms. Second, we propose a novel neural network architecture that allows us to incorporate widely acknowledged financial inductive biases such as amplitude invariance and time-scale invariance. We demonstrate the efficacy of our method on U.S. and Japanese stock market data. Through ablation experiments, we also verify that each individual technique contributes to improving the performance of trading strategies. We anticipate our techniques may have wide applications in various financial problems.
Deep Optimized Priors for 3D Shape Modeling and Reconstruction
Dec 14, 2020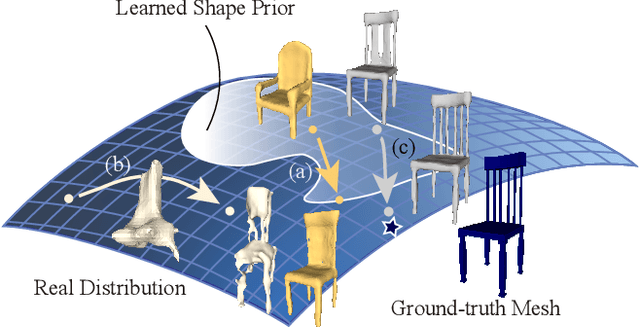
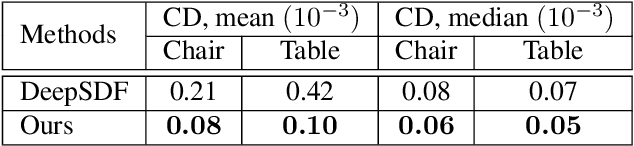
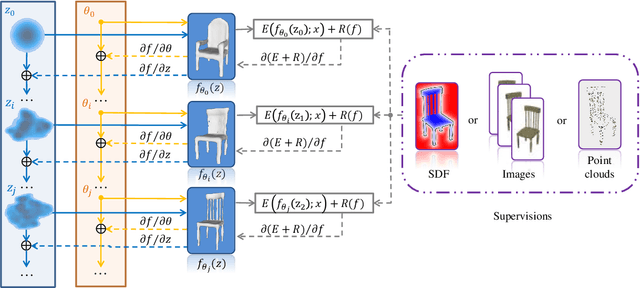
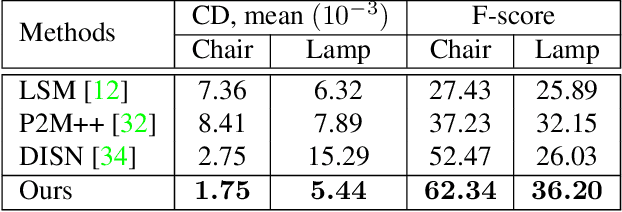
Many learning-based approaches have difficulty scaling to unseen data, as the generality of its learned prior is limited to the scale and variations of the training samples. This holds particularly true with 3D learning tasks, given the sparsity of 3D datasets available. We introduce a new learning framework for 3D modeling and reconstruction that greatly improves the generalization ability of a deep generator. Our approach strives to connect the good ends of both learning-based and optimization-based methods. In particular, unlike the common practice that fixes the pre-trained priors at test time, we propose to further optimize the learned prior and latent code according to the input physical measurements after the training. We show that the proposed strategy effectively breaks the barriers constrained by the pre-trained priors and could lead to high-quality adaptation to unseen data. We realize our framework using the implicit surface representation and validate the efficacy of our approach in a variety of challenging tasks that take highly sparse or collapsed observations as input. Experimental results show that our approach compares favorably with the state-of-the-art methods in terms of both generality and accuracy.
The LL(finite) strategy for optimal LL(k) parsing
Oct 15, 2020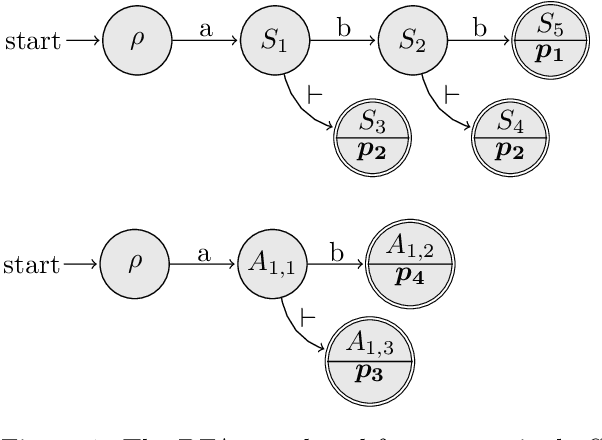
The LL(finite) parsing strategy for parsing of LL(k) grammars where k needs not to be known is presented. The strategy parses input in linear time, uses arbitrary but always minimal lookahead necessary to disambiguate between alternatives of nonterminals, and it is optimal in the number of lookahead terminal scans performed. Modifications to the algorithm are shown that allow for resolution of grammar ambiguities by precedence -- effectively interpreting the input as a parsing expression grammar -- as well as for the use of predicates, and a proof of concept, the open-source parser generator Astir, employs the LL(finite) strategy in the output it generates.
Structural Forecasting for Tropical Cyclone Intensity Prediction: Providing Insight with Deep Learning
Oct 07, 2020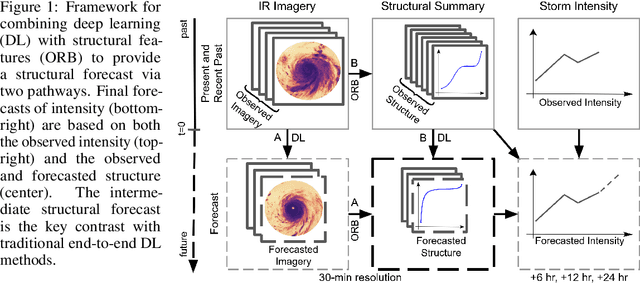
Tropical cyclone (TC) intensity forecasts are ultimately issued by human forecasters. The human in-the-loop pipeline requires that any forecasting guidance must be easily digestible by TC experts if it is to be adopted at operational centers like the National Hurricane Center. Our proposed framework leverages deep learning to provide forecasters with something neither end-to-end prediction models nor traditional intensity guidance does: a powerful tool for monitoring high-dimensional time series of key physically relevant predictors and the means to understand how the predictors relate to one another and to short-term intensity changes.