 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MORPH-DSLAM: Model Order Reduction for PHysics-based Deformable SLAM
Sep 01, 2020
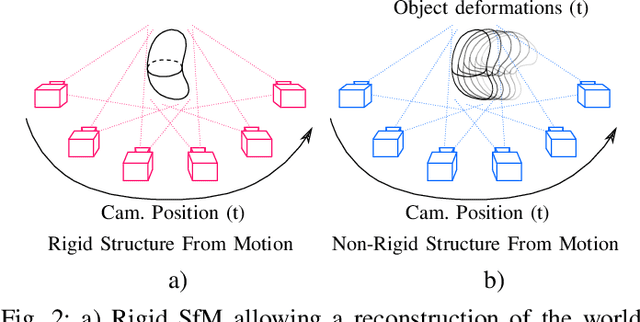
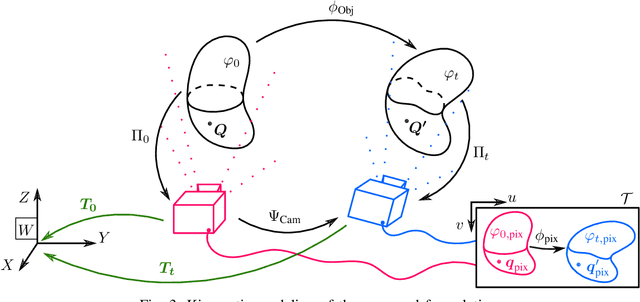
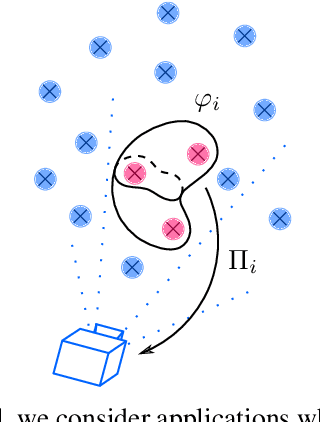
We propose a new methodology to estimate the 3D displacement field of deformable objects from video sequences using standard monocular cameras. We solve in real time the complete (possibly visco-)hyperelasticity problem to properly describe the strain and stress fields that are consistent with the displacements captured by the images, constrained by real physics. We do not impose any ad-hoc prior or energy minimization in the external surface, since the real and complete mechanics problem is solved. This means that we can also estimate the internal state of the objects, even in occluded areas, just by observing the external surface and the knowledge of material properties and geometry. Solving this problem in real time using a realistic constitutive law, usually non-linear, is out of reach for current systems. To overcome this difficulty, we solve off-line a parametrized problem that considers each source of variability in the problem as a new parameter and, consequently, as a new dimension in the formulation. Model Order Reduction methods allow us to reduce the dimensionality of the problem, and therefore, its computational cost, while preserving the visualization of the solution in the high-dimensionality space. This allows an accurate estimation of the object deformations, improving also the robustness in the 3D points estimation.
Incremental Text-to-Speech Synthesis Using Pseudo Lookahead with Large Pretrained Language Model
Dec 23, 2020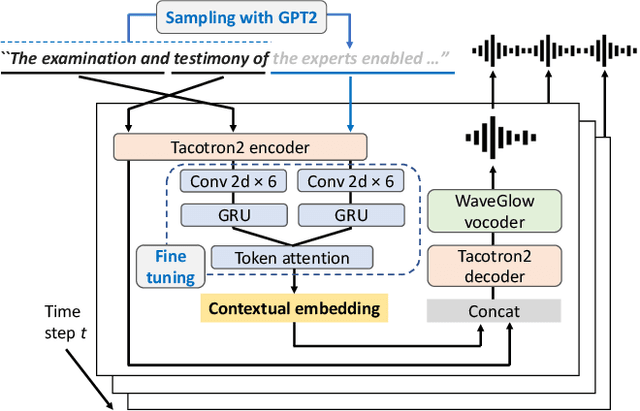
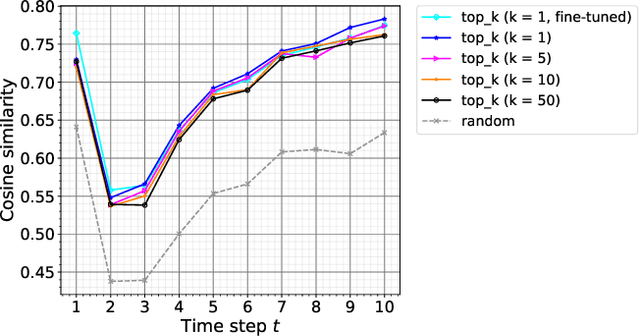
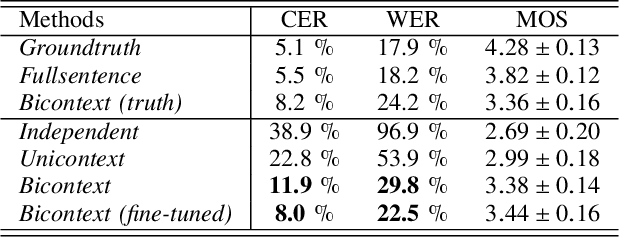
Text-to-speech (TTS) synthesis, a technique for artificially generating human-like utterances from texts, has dramatically evolved with the advances of end-to-end deep neural network-based methods in recent years. The majority of these methods are sentence-level TTS, which can take into account time-series information in the whole sentence. However, it is necessary to establish incremental TTS, which performs synthesis in smaller linguistic units, to realize low-latency synthesis usable for simultaneous speech-to-speech translation systems. In general, incremental TTS is subject to a trade-off between the latency and quality of output speech. It is challenging to produce high-quality speech with a low-latency setup that does not make much use of an unobserved future sentence (hereafter, "lookahead"). This study proposes an incremental TTS method that uses the pseudo lookahead generated with a language model to consider the future contextual information without increasing latency. Our method can be regarded as imitating a human's incremental reading and uses pretrained GPT2, which accounts for the large-scale linguistic knowledge, for the lookahead generation. Evaluation results show that our method 1) achieves higher speech quality without increasing the latency than the method using only observed information and 2) reduces the latency while achieving the equivalent speech quality to waiting for the future context observation.
Fighting Copycat Agents in Behavioral Cloning from Observation Histories
Oct 28, 2020



Imitation learning trains policies to map from input observations to the actions that an expert would choose. In this setting, distribution shift frequently exacerbates the effect of misattributing expert actions to nuisance correlates among the observed variables. We observe that a common instance of this causal confusion occurs in partially observed settings when expert actions are strongly correlated over time: the imitator learns to cheat by predicting the expert's previous action, rather than the next action. To combat this "copycat problem", we propose an adversarial approach to learn a feature representation that removes excess information about the previous expert action nuisance correlate, while retaining the information necessary to predict the next action. In our experiments, our approach improves performance significantly across a variety of partially observed imitation learning tasks.
A Scalable Approach for Privacy-Preserving Collaborative Machine Learning
Nov 03, 2020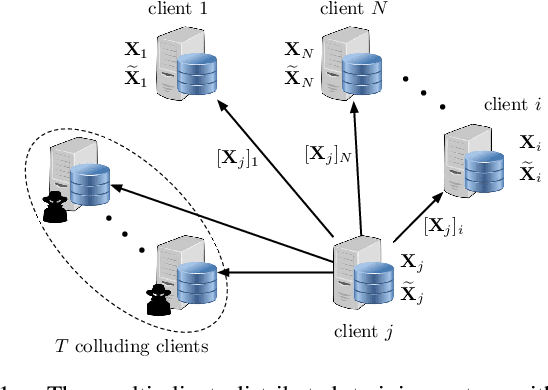

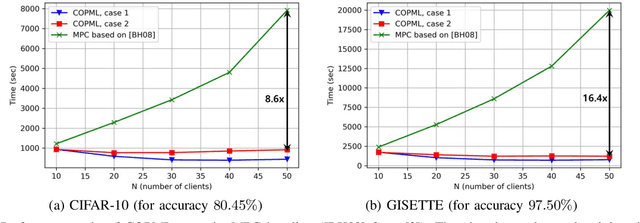
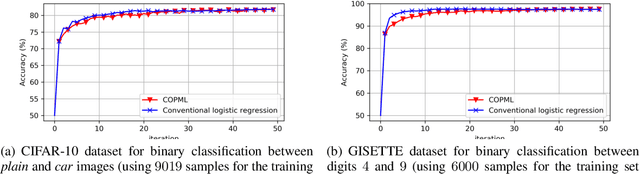
We consider a collaborative learning scenario in which multiple data-owners wish to jointly train a logistic regression model, while keeping their individual datasets private from the other parties. We propose COPML, a fully-decentralized training framework that achieves scalability and privacy-protection simultaneously. The key idea of COPML is to securely encode the individual datasets to distribute the computation load effectively across many parties and to perform the training computations as well as the model updates in a distributed manner on the securely encoded data. We provide the privacy analysis of COPML and prove its convergence. Furthermore, we experimentally demonstrate that COPML can achieve significant speedup in training over the benchmark protocols. Our protocol provides strong statistical privacy guarantees against colluding parties (adversaries) with unbounded computational power, while achieving up to $16\times$ speedup in the training time against the benchmark protocols.
Improving Sequential Latent Variable Models with Autoregressive Flows
Oct 07, 2020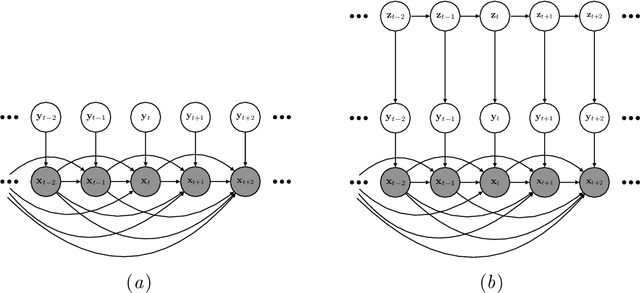
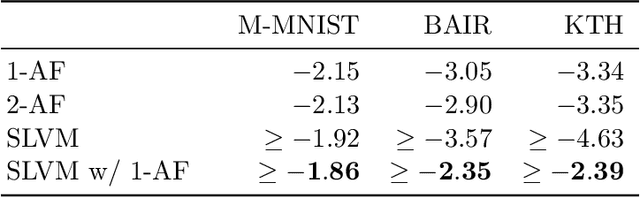


We propose an approach for improving sequence modeling based on autoregressive normalizing flows. Each autoregressive transform, acting across time, serves as a moving frame of reference, removing temporal correlations, and simplifying the modeling of higher-level dynamics. This technique provides a simple, general-purpose method for improving sequence modeling, with connections to existing and classical techniques. We demonstrate the proposed approach both with standalone flow-based models and as a component within sequential latent variable models. Results are presented on three benchmark video datasets, where autoregressive flow-based dynamics improve log-likelihood performance over baseline models. Finally, we illustrate the decorrelation and improved generalization properties of using flow-based dynamics.
Learning the Distribution: A Unified Distillation Paradigm for Fast Uncertainty Estimation in Computer Vision
Jul 31, 2020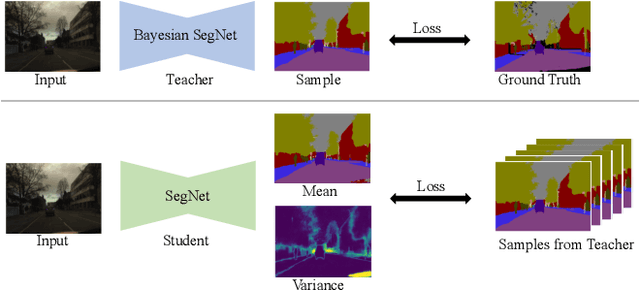
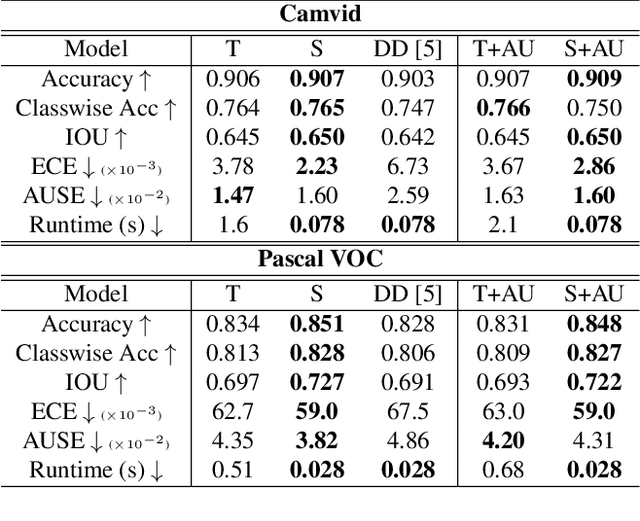

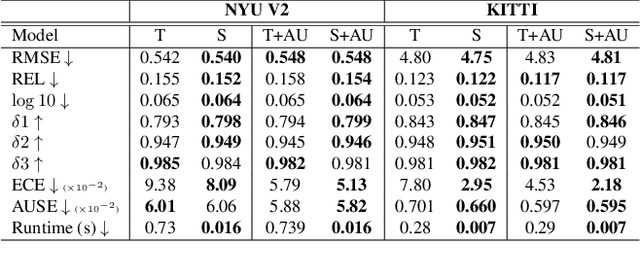
Calibrated estimates of uncertainty are critical for many real-world computer vision applications of deep learning. While there are several widely-used uncertainty estimation methods, dropout inference stands out for its simplicity and efficacy. This technique, however, requires multiple forward passes through the network during inference and therefore can be too resource-intensive to be deployed in real-time applications. To tackle this issue, we propose a unified distillation paradigm for learning the conditional predictive distribution of a pre-trained dropout model for fast uncertainty estimation of both aleatoric and epistemic uncertainty at the same time. We empirically test the effectiveness of the proposed method on both semantic segmentation and depth estimation tasks, and observe that the student model can well approximate the probability distribution generated by the teacher model, i.e the pre-trained dropout model. In addition to a significant boost in speed, we demonstrate the quality of uncertainty estimates and the overall predictive performance can also be improved with the proposed method.
Numerically Solving Parametric Families of High-Dimensional Kolmogorov Partial Differential Equations via Deep Learning
Nov 09, 2020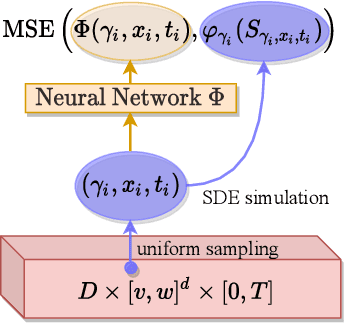
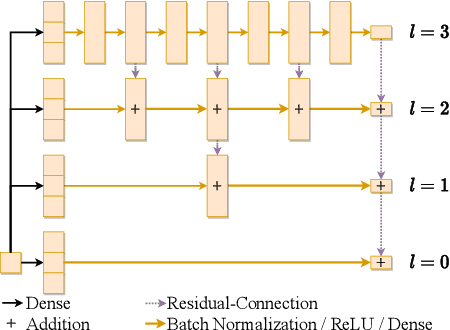
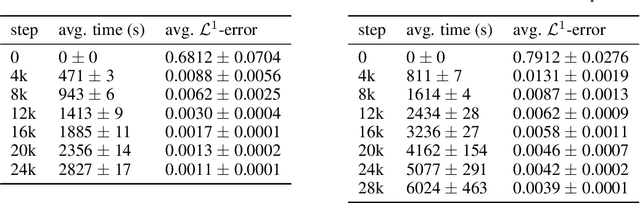
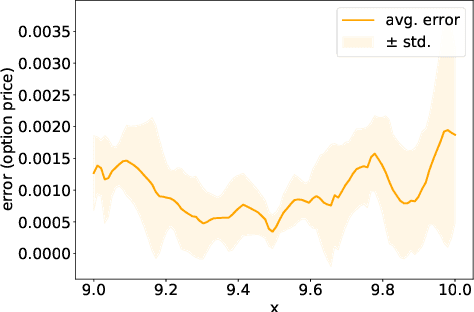
We present a deep learning algorithm for the numerical solution of parametric families of high-dimensional linear Kolmogorov partial differential equations (PDEs). Our method is based on reformulating the numerical approximation of a whole family of Kolmogorov PDEs as a single statistical learning problem using the Feynman-Kac formula. Successful numerical experiments are presented, which empirically confirm the functionality and efficiency of our proposed algorithm in the case of heat equations and Black-Scholes option pricing models parametrized by affine-linear coefficient functions. We show that a single deep neural network trained on simulated data is capable of learning the solution functions of an entire family of PDEs on a full space-time region. Most notably, our numerical observations and theoretical results also demonstrate that the proposed method does not suffer from the curse of dimensionality, distinguishing it from almost all standard numerical methods for PDEs.
Automated Large-scale Class Scheduling in MiniZinc
Nov 15, 2020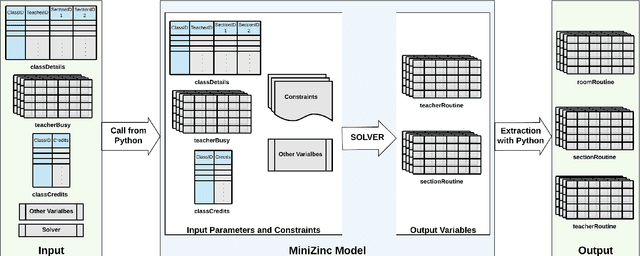
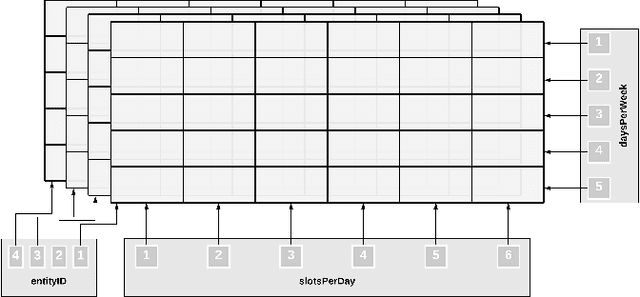
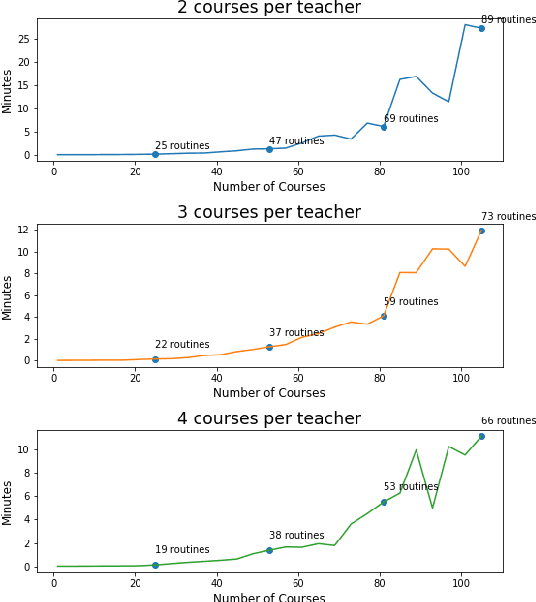
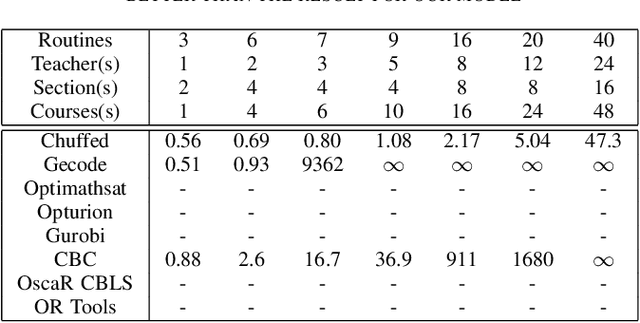
Class Scheduling is a highly constrained task. Educational institutes spend a lot of resources, in the form of time and manual computation, to find a satisficing schedule that fulfills all the requirements. A satisficing class schedule accommodates all the students to all their desired courses at convenient timing. The scheduler also needs to take into account the availability of course teachers on the given slots. With the added limitation of available classrooms, the number of solutions satisfying all constraints in this huge search-space, further decreases. This paper proposes an efficient system to generate class schedules that can fulfill every possible need of a typical university. Though it is primarily a fixed-credit scheduler, it can be adjusted for open-credit systems as well. The model is designed in MiniZinc and solved using various off-the-shelf solvers. The proposed scheduling system can find a balanced schedule for a moderate-sized educational institute in less than a minute.
Meningioma segmentation in T1-weighted MRI leveraging global context and attention mechanisms
Jan 19, 2021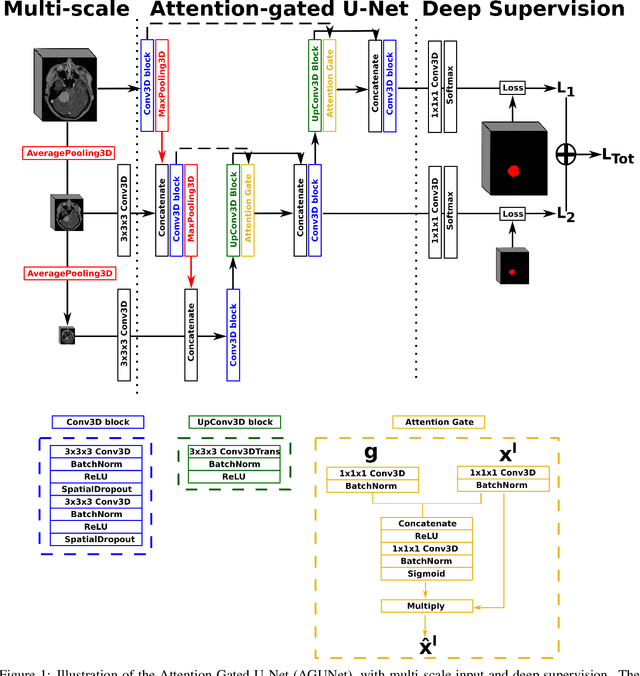
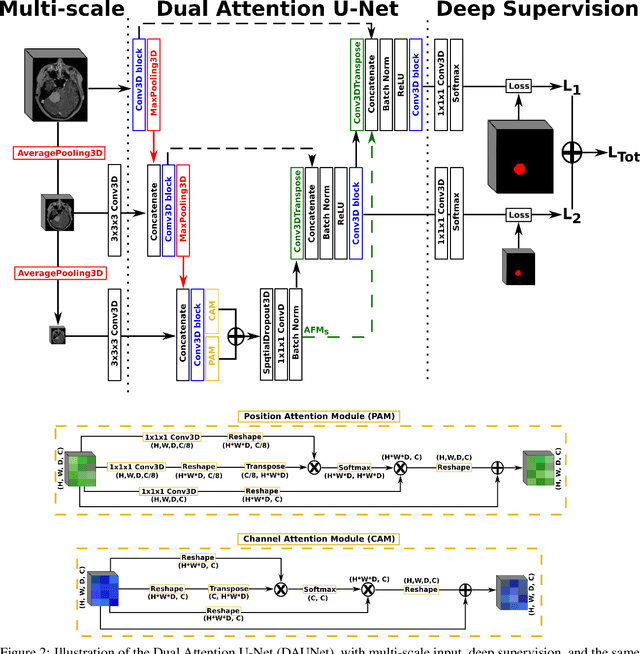
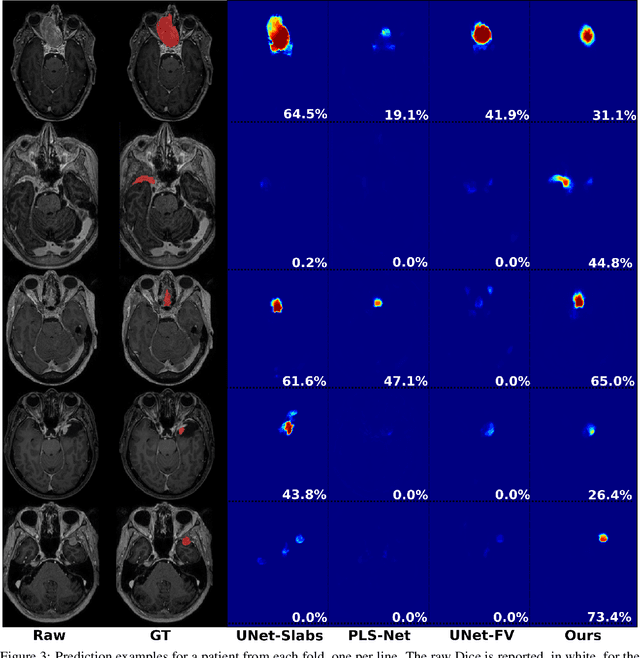

Meningiomas are the most common type of primary brain tumor, accounting for approximately 30% of all brain tumors. A substantial number of these tumors are never surgically removed but rather monitored over time. Automatic and precise meningioma segmentation is therefore beneficial to enable reliable growth estimation and patient-specific treatment planning. In this study, we propose the inclusion of attention mechanisms over a U-Net architecture: (i) Attention-gated U-Net (AGUNet) and (ii) Dual Attention U-Net (DAUNet), using a 3D MRI volume as input. Attention has the potential to leverage the global context and identify features' relationships across the entire volume. To limit spatial resolution degradation and loss of detail inherent to encoder-decoder architectures, we studied the impact of multi-scale input and deep supervision components. The proposed architectures are trainable end-to-end and each concept can be seamlessly disabled for ablation studies. The validation studies were performed using a 5-fold cross validation over 600 T1-weighted MRI volumes from St. Olavs University Hospital, Trondheim, Norway. For the best performing architecture, an average Dice score of 81.6% was reached for an F1-score of 95.6%. With an almost perfect precision of 98%, meningiomas smaller than 3ml were occasionally missed hence reaching an overall recall of 93%. Leveraging global context from a 3D MRI volume provided the best performances, even if the native volume resolution could not be processed directly. Overall, near-perfect detection was achieved for meningiomas larger than 3ml which is relevant for clinical use. In the future, the use of multi-scale designs and refinement networks should be further investigated to improve the performance. A larger number of cases with meningiomas below 3ml might also be needed to improve the performance for the smallest tumors.
Agile Amulet: Real-Time Salient Object Detection with Contextual Attention
Feb 20, 2018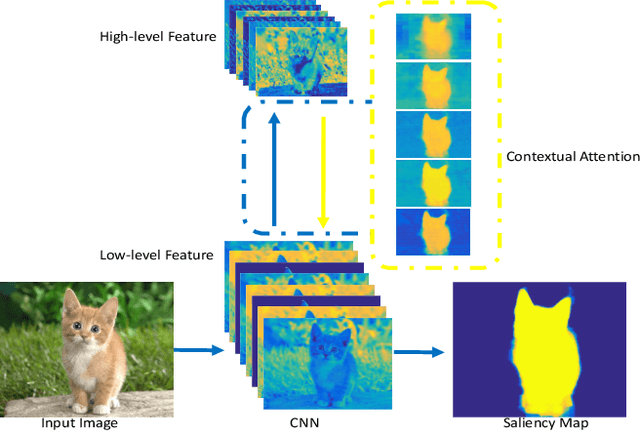
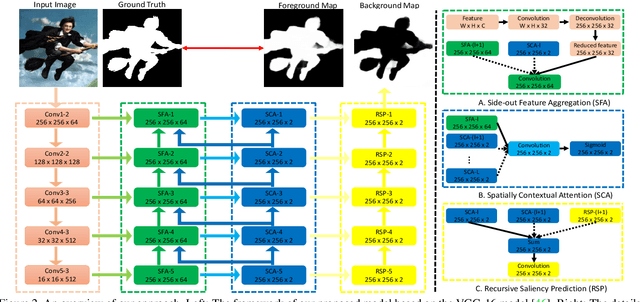
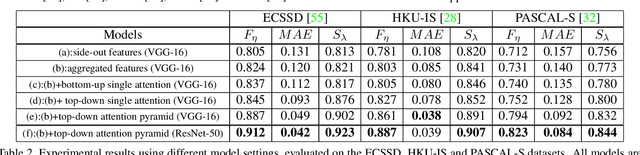
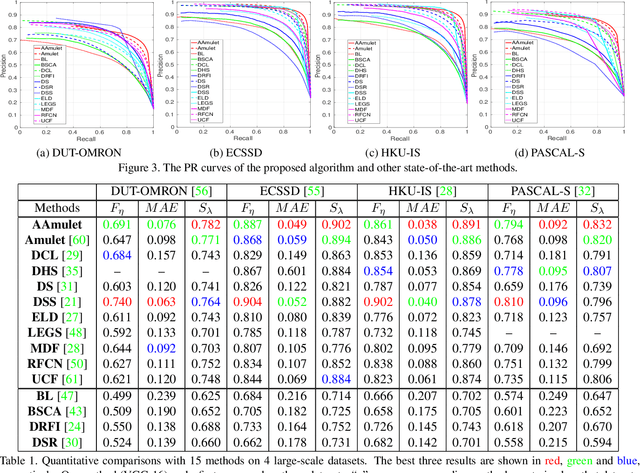
This paper proposes an Agile Aggregating Multi-Level feaTure framework (Agile Amulet) for salient object detection. The Agile Amulet builds on previous works to predict saliency maps using multi-level convolutional features. Compared to previous works, Agile Amulet employs some key innovations to improve training and testing speed while also increase prediction accuracy. More specifically, we first introduce a contextual attention module that can rapidly highlight most salient objects or regions with contextual pyramids. Thus, it effectively guides the learning of low-layer convolutional features and tells the backbone network where to look. The contextual attention module is a fully convolutional mechanism that simultaneously learns complementary features and predicts saliency scores at each pixel. In addition, we propose a novel method to aggregate multi-level deep convolutional features. As a result, we are able to use the integrated side-output features of pre-trained convolutional networks alone, which significantly reduces the model parameters leading to a model size of 67 MB, about half of Amulet. Compared to other deep learning based saliency methods, Agile Amulet is of much lighter-weight, runs faster (30 fps in real-time) and achieves higher performance on seven public benchmarks in terms of both quantitative and qualitative evaluation.