 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Compact Gated-Synapse Model for Neuromorphic Circuits
Jun 29, 2020
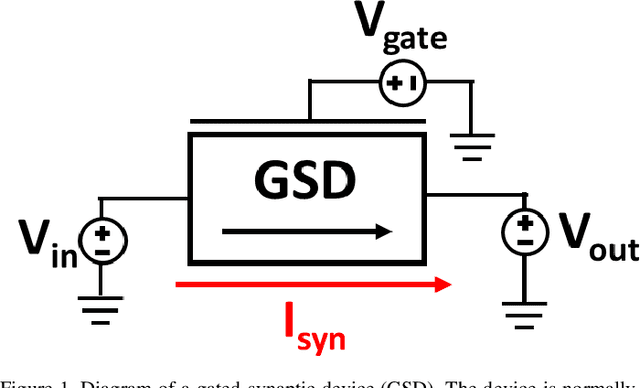
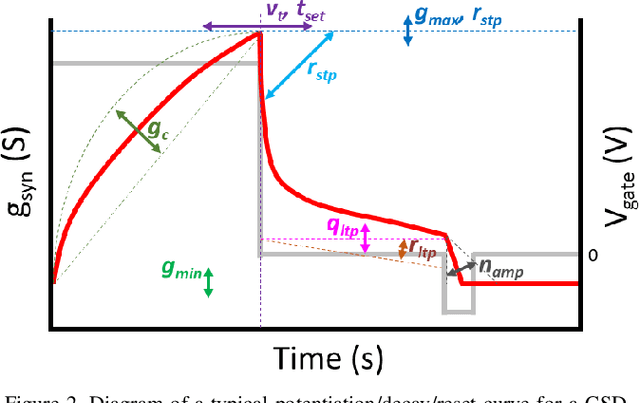
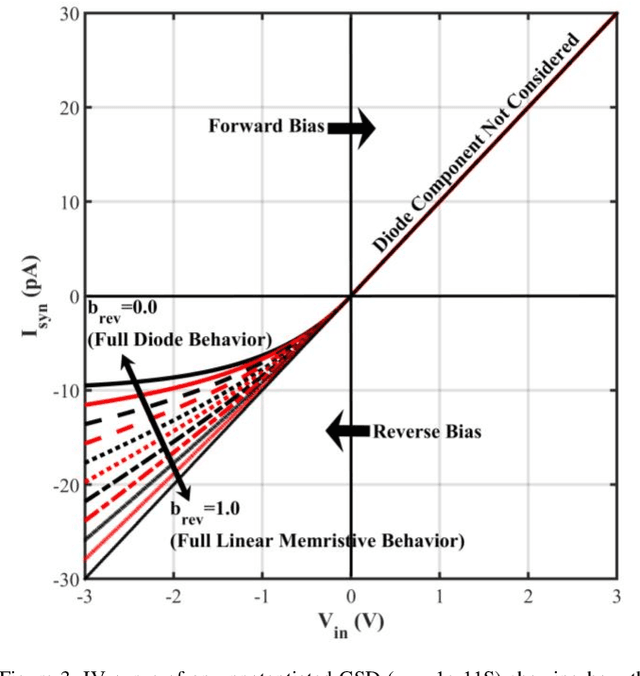
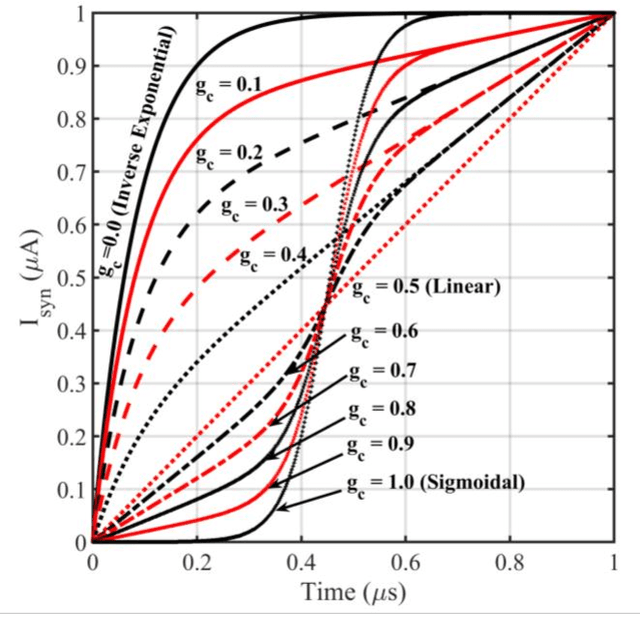
This work reports a compact behavioral model for gated-synaptic memory. The model is developed in Verilog-A for easy integration into computer-aided design of neuromorphic circuits using emerging memory. The model encompasses various forms of gated synapses within a single framework and is not restricted to only a single type. The behavioral theory of the model is described in detail along with a full list of the default parameter settings. The model includes parameters such as a device's ideal set time, threshold voltage, general evolution of the conductance with respect to time, decay of the device's state, etc. Finally, the model's validity is shown via extensive simulation and fitting to experimentally reported data on published gated-synapses.
Optimizing Neural Networks via Koopman Operator Theory
Jun 11, 2020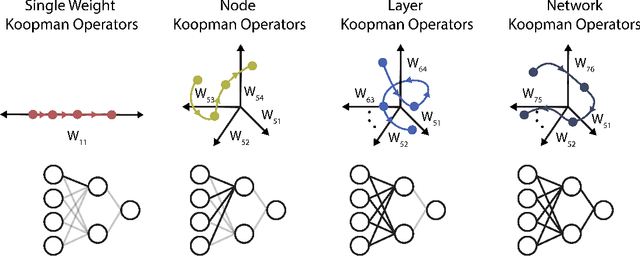

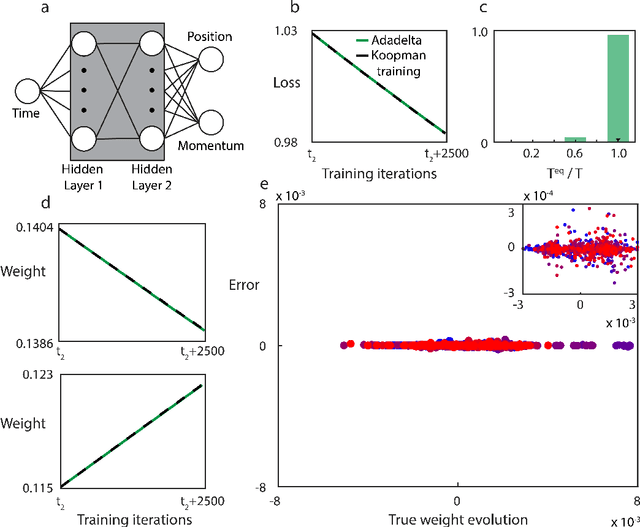

Koopman operator theory, a powerful framework for discovering the underlying dynamics of nonlinear dynamical systems, was recently shown to be intimately connected with neural network training. In this work, we take the first steps in making use of this connection. As Koopman operator theory is a linear theory, a successful implementation of it in evolving network weights and biases offers the promise of accelerated training, especially in the context of deep networks, where optimization is inherently a non-convex problem. We show that Koopman operator theory methods allow for accurate predictions of the weights and biases of a feedforward, fully connected deep network over a non-trivial range of training time. During this time window, we find that our approach is at least 10x faster than gradient descent based methods, in line with the results expected from our complexity analysis. We highlight additional methods by which our results can be expanded to broader classes of networks and larger time intervals, which shall be the focus of future work in this novel intersection between dynamical systems and neural network theory.
Incremental Text-to-Speech Synthesis Using Pseudo Lookahead with Large Pretrained Language Model
Dec 23, 2020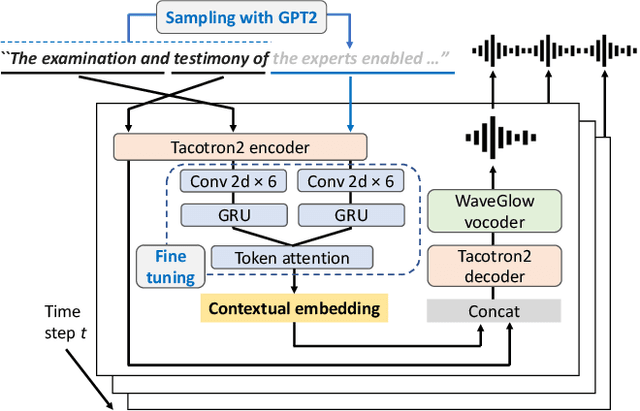
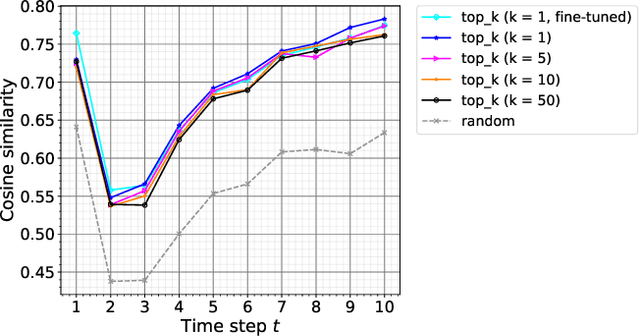
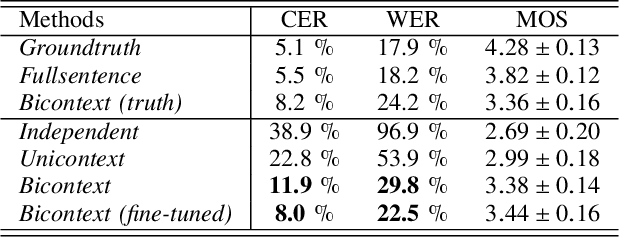
Text-to-speech (TTS) synthesis, a technique for artificially generating human-like utterances from texts, has dramatically evolved with the advances of end-to-end deep neural network-based methods in recent years. The majority of these methods are sentence-level TTS, which can take into account time-series information in the whole sentence. However, it is necessary to establish incremental TTS, which performs synthesis in smaller linguistic units, to realize low-latency synthesis usable for simultaneous speech-to-speech translation systems. In general, incremental TTS is subject to a trade-off between the latency and quality of output speech. It is challenging to produce high-quality speech with a low-latency setup that does not make much use of an unobserved future sentence (hereafter, "lookahead"). This study proposes an incremental TTS method that uses the pseudo lookahead generated with a language model to consider the future contextual information without increasing latency. Our method can be regarded as imitating a human's incremental reading and uses pretrained GPT2, which accounts for the large-scale linguistic knowledge, for the lookahead generation. Evaluation results show that our method 1) achieves higher speech quality without increasing the latency than the method using only observed information and 2) reduces the latency while achieving the equivalent speech quality to waiting for the future context observation.
Input Convex Neural Networks for Building MPC
Nov 26, 2020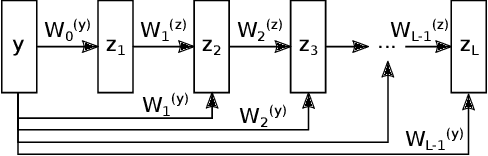
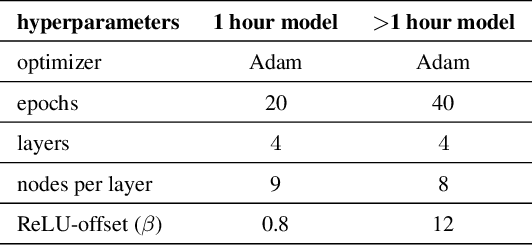
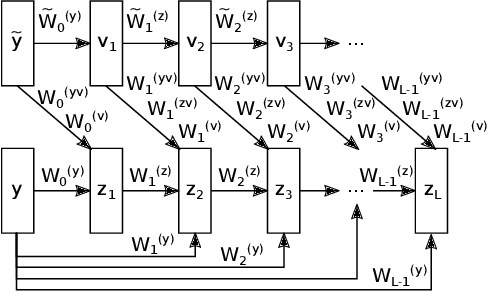
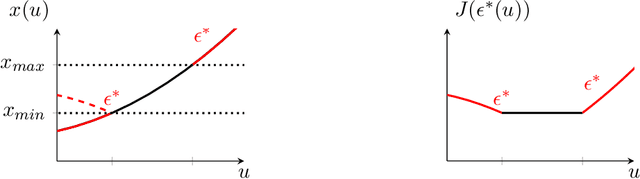
Model Predictive Control in buildings can significantly reduce their energy consumption. The cost and effort necessary for creating and maintaining first principle models for buildings make data-driven modelling an attractive alternative in this domain. In MPC the models form the basis for an optimization problem whose solution provides the control signals to be applied to the system. The fact that this optimization problem has to be solved repeatedly in real-time implies restrictions on the learning architectures that can be used. Here, we adapt Input Convex Neural Networks that are generally only convex for one-step predictions, for use in building MPC. We introduce additional constraints to their structure and weights to achieve a convex input-output relationship for multistep ahead predictions. We assess the consequences of the additional constraints for the model accuracy and test the models in a real-life MPC experiment in an apartment in Switzerland. In two five-day cooling experiments, MPC with Input Convex Neural Networks is able to keep room temperatures within comfort constraints while minimizing cooling energy consumption.
Meningioma segmentation in T1-weighted MRI leveraging global context and attention mechanisms
Jan 19, 2021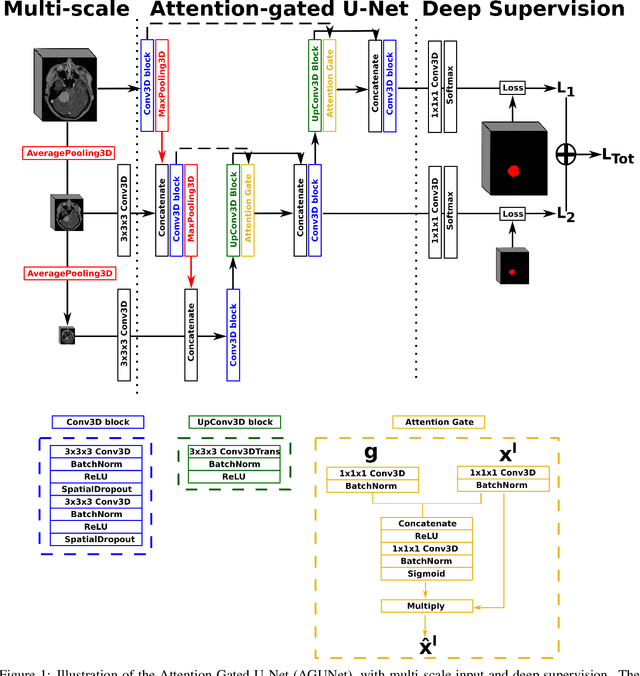
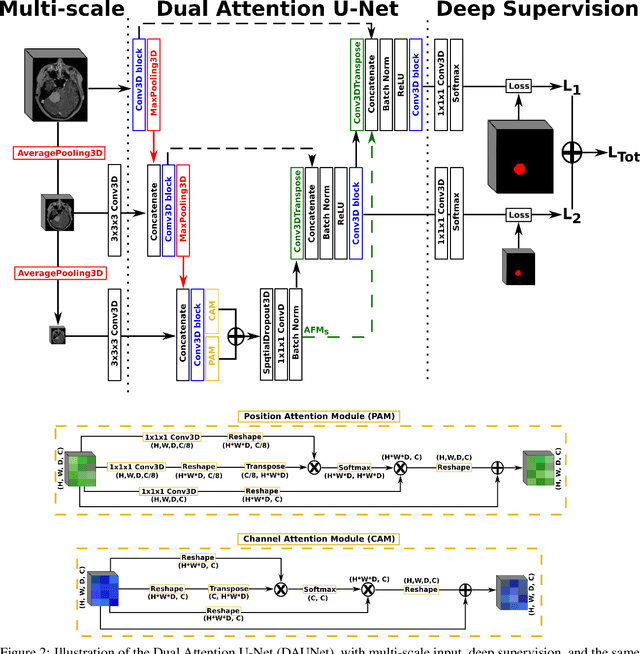
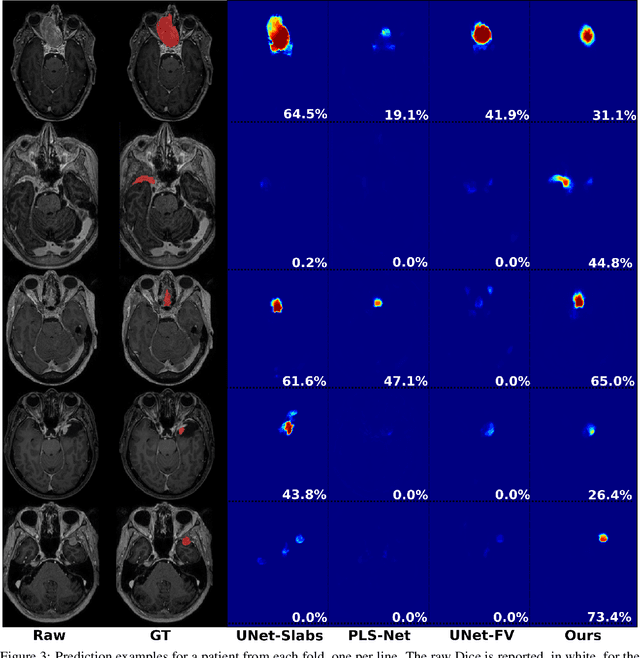

Meningiomas are the most common type of primary brain tumor, accounting for approximately 30% of all brain tumors. A substantial number of these tumors are never surgically removed but rather monitored over time. Automatic and precise meningioma segmentation is therefore beneficial to enable reliable growth estimation and patient-specific treatment planning. In this study, we propose the inclusion of attention mechanisms over a U-Net architecture: (i) Attention-gated U-Net (AGUNet) and (ii) Dual Attention U-Net (DAUNet), using a 3D MRI volume as input. Attention has the potential to leverage the global context and identify features' relationships across the entire volume. To limit spatial resolution degradation and loss of detail inherent to encoder-decoder architectures, we studied the impact of multi-scale input and deep supervision components. The proposed architectures are trainable end-to-end and each concept can be seamlessly disabled for ablation studies. The validation studies were performed using a 5-fold cross validation over 600 T1-weighted MRI volumes from St. Olavs University Hospital, Trondheim, Norway. For the best performing architecture, an average Dice score of 81.6% was reached for an F1-score of 95.6%. With an almost perfect precision of 98%, meningiomas smaller than 3ml were occasionally missed hence reaching an overall recall of 93%. Leveraging global context from a 3D MRI volume provided the best performances, even if the native volume resolution could not be processed directly. Overall, near-perfect detection was achieved for meningiomas larger than 3ml which is relevant for clinical use. In the future, the use of multi-scale designs and refinement networks should be further investigated to improve the performance. A larger number of cases with meningiomas below 3ml might also be needed to improve the performance for the smallest tumors.
Assisted Probe Positioning for Ultrasound Guided Radiotherapy Using Image Sequence Classification
Oct 06, 2020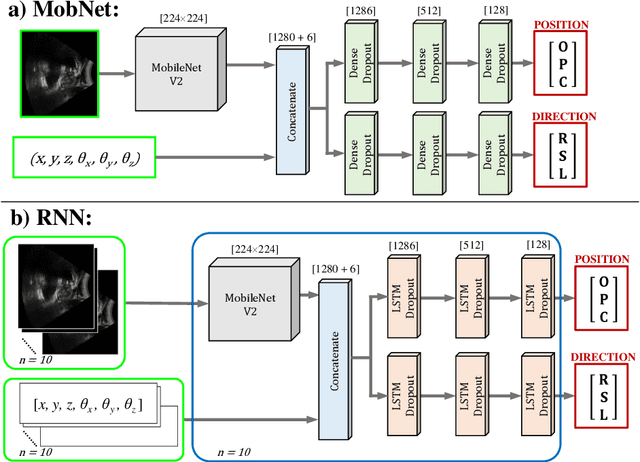
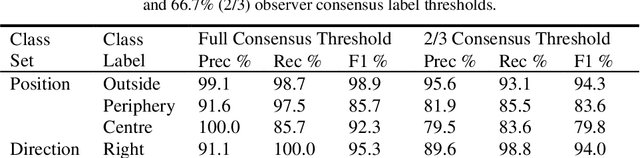
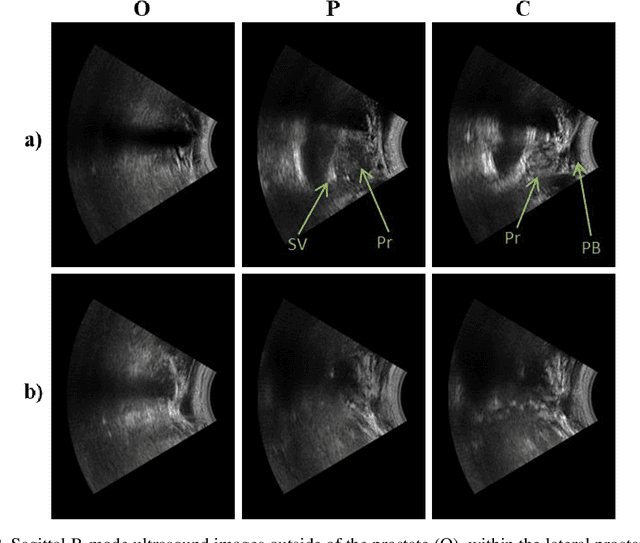
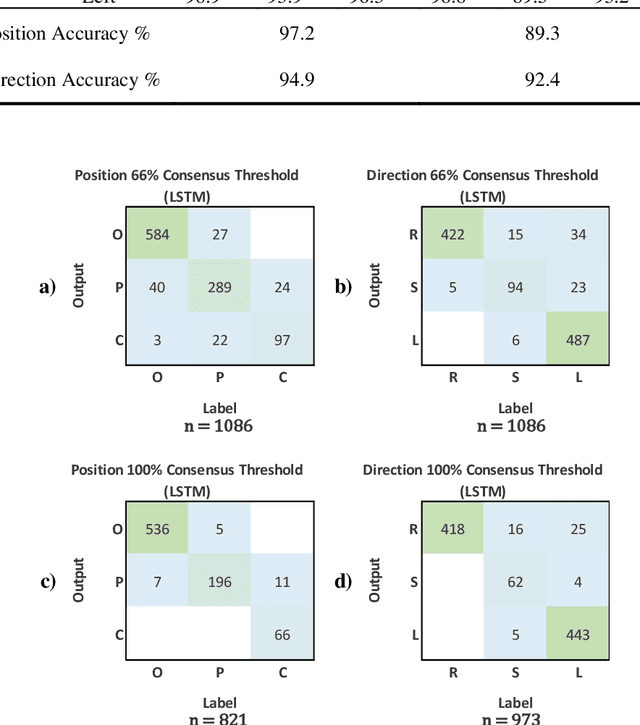
Effective transperineal ultrasound image guidance in prostate external beam radiotherapy requires consistent alignment between probe and prostate at each session during patient set-up. Probe placement and ultrasound image inter-pretation are manual tasks contingent upon operator skill, leading to interoperator uncertainties that degrade radiotherapy precision. We demonstrate a method for ensuring accurate probe placement through joint classification of images and probe position data. Using a multi-input multi-task algorithm, spatial coordinate data from an optically tracked ultrasound probe is combined with an image clas-sifier using a recurrent neural network to generate two sets of predictions in real-time. The first set identifies relevant prostate anatomy visible in the field of view using the classes: outside prostate, prostate periphery, prostate centre. The second set recommends a probe angular adjustment to achieve alignment between the probe and prostate centre with the classes: move left, move right, stop. The algo-rithm was trained and tested on 9,743 clinical images from 61 treatment sessions across 32 patients. We evaluated classification accuracy against class labels de-rived from three experienced observers at 2/3 and 3/3 agreement thresholds. For images with unanimous consensus between observers, anatomical classification accuracy was 97.2% and probe adjustment accuracy was 94.9%. The algorithm identified optimal probe alignment within a mean (standard deviation) range of 3.7$^{\circ}$ (1.2$^{\circ}$) from angle labels with full observer consensus, comparable to the 2.8$^{\circ}$ (2.6$^{\circ}$) mean interobserver range. We propose such an algorithm could assist ra-diotherapy practitioners with limited experience of ultrasound image interpreta-tion by providing effective real-time feedback during patient set-up.
Deep ConvLSTM with self-attention for human activity decoding using wearables
May 02, 2020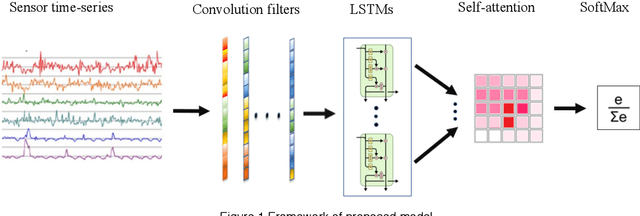
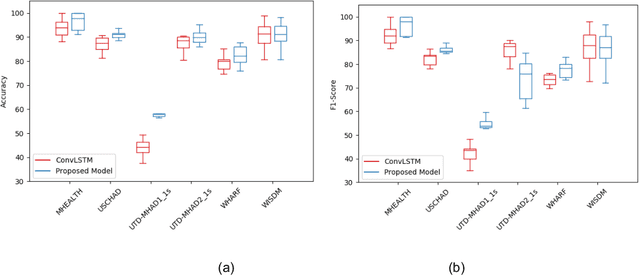

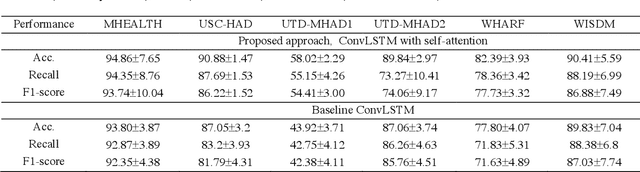
Decoding human activity accurately from wearable sensors can aid in applications related to healthcare and context awareness. The present approaches in this domain use recurrent and/or convolutional models to capture the spatio-temporal features from time series data from multiple sensors. We propose a deep neural network architecture that not only captures the spatio-temporal features of multiple sensor time series data, but also selects, learns important time points by utilizing a self-attention mechanism. We show the validity of the proposed approach across different data sampling strategies on six public datasets and demonstrate that the self-attention mechanism gave significant improvement in performance over deep networks using a combination of recurrent and convolution networks. We also show that the proposed approach gave a statistically significant performance enhancement over previous state-of-the-art methods for the tested datasets. The proposed methods open avenues for better decoding of human activity from multiple body sensors over extended periods of time. The code implementation for the proposed model is available at https://github.com/isukrit/encodingHumanActivity
What if Neural Networks had SVDs?
Sep 29, 2020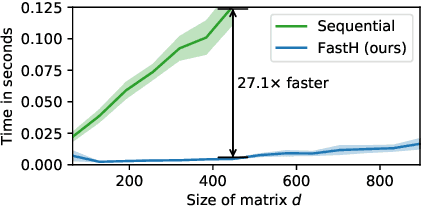


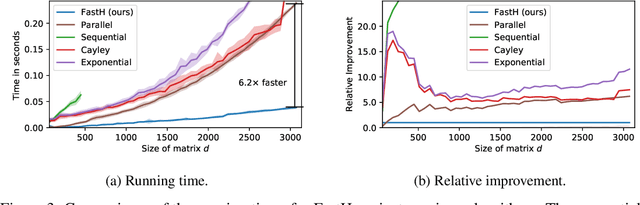
Various Neural Networks employ time-consuming matrix operations like matrix inversion. Many such matrix operations are faster to compute given the Singular Value Decomposition (SVD). Previous work allows using the SVD in Neural Networks without computing it. In theory, the techniques can speed up matrix operations, however, in practice, they are not fast enough. We present an algorithm that is fast enough to speed up several matrix operations. The algorithm increases the degree of parallelism of an underlying matrix multiplication $H\cdot X$ where $H$ is an orthogonal matrix represented by a product of Householder matrices. Code is available at www.github.com/AlexanderMath/fasth .
Image Conditioned Keyframe-Based Video Summarization Using Object Detection
Sep 11, 2020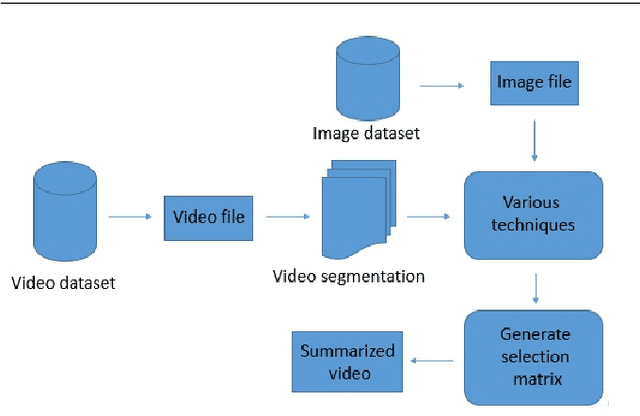
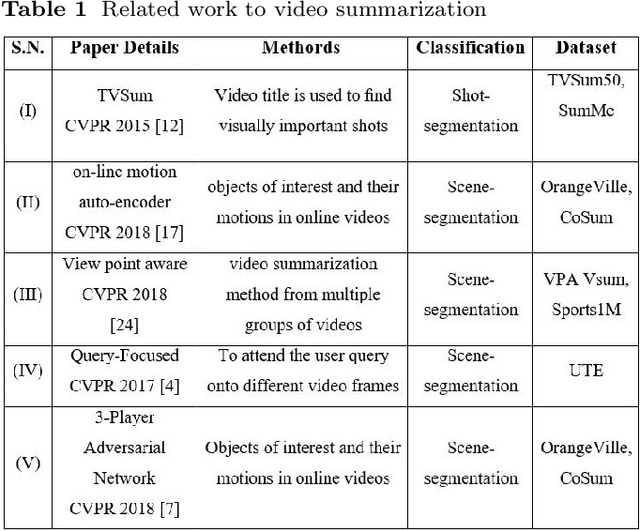
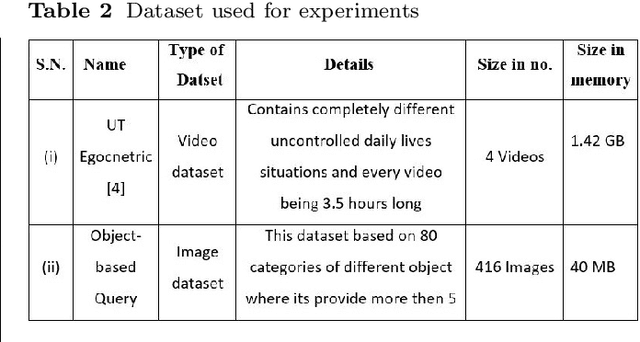
Video summarization plays an important role in selecting keyframe for understanding a video. Traditionally, it aims to find the most representative and diverse contents (or frames) in a video for short summaries. Recently, query-conditioned video summarization has been introduced, which considers user queries to learn more user-oriented summaries and its preference. However, there are obstacles in text queries for user subjectivity and finding similarity between the user query and input frames. In this work, (i) Image is introduced as a query for user preference (ii) a mathematical model is proposed to minimize redundancy based on the loss function & summary variance and (iii) the similarity score between the query image and input video to obtain the summarized video. Furthermore, the Object-based Query Image (OQI) dataset has been introduced, which contains the query images. The proposed method has been validated using UT Egocentric (UTE) dataset. The proposed model successfully resolved the issues of (i) user preference, (ii) recognize important frames and selecting that keyframe in daily life videos, with different illumination conditions. The proposed method achieved 57.06% average F1-Score for UTE dataset and outperforms the existing state-of-theart by 11.01%. The process time is 7.81 times faster than actual time of video Experiments on a recently proposed UTE dataset show the efficiency of the proposed method
A Scalable Approach for Privacy-Preserving Collaborative Machine Learning
Nov 03, 2020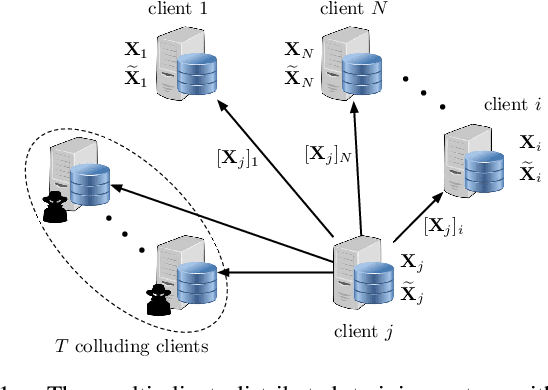

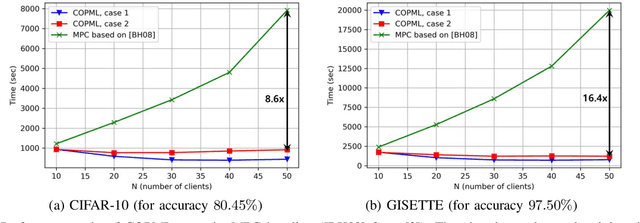
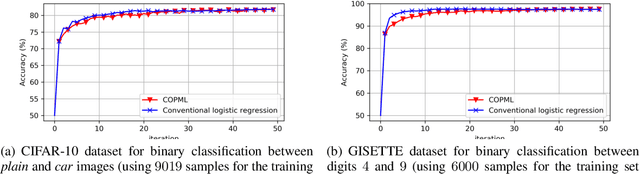
We consider a collaborative learning scenario in which multiple data-owners wish to jointly train a logistic regression model, while keeping their individual datasets private from the other parties. We propose COPML, a fully-decentralized training framework that achieves scalability and privacy-protection simultaneously. The key idea of COPML is to securely encode the individual datasets to distribute the computation load effectively across many parties and to perform the training computations as well as the model updates in a distributed manner on the securely encoded data. We provide the privacy analysis of COPML and prove its convergence. Furthermore, we experimentally demonstrate that COPML can achieve significant speedup in training over the benchmark protocols. Our protocol provides strong statistical privacy guarantees against colluding parties (adversaries) with unbounded computational power, while achieving up to $16\times$ speedup in the training time against the benchmark protocols.