 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Honey Bee Dance Modeling in Real-time using Machine Learning
May 20, 2017
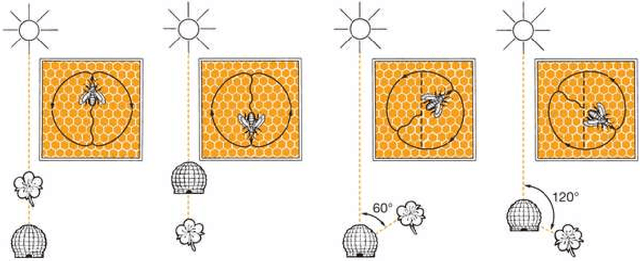
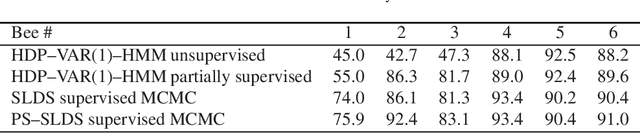
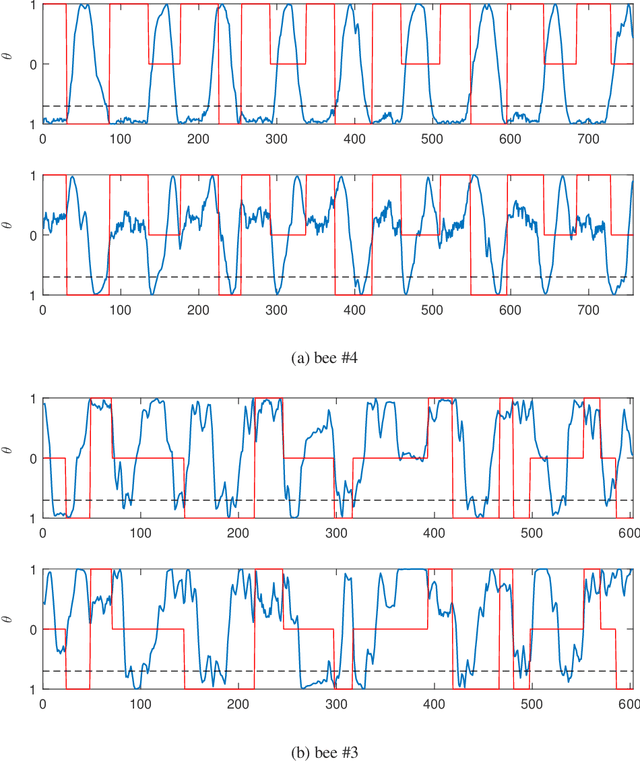
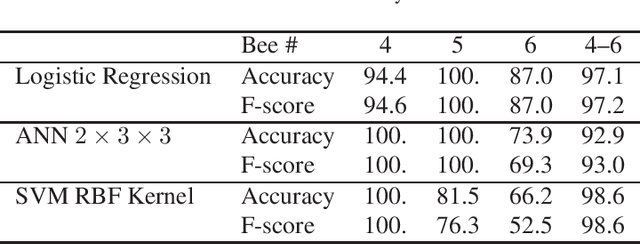
The waggle dance that honeybees perform is an astonishing way of communicating the location of food source. After over 60 years of its discovery, researchers still use manual labeling by watching hours of dance videos to detect different transitions between dance components thus extracting information regarding the distance and direction to the food source. We propose an automated process to monitor and segment different components of honeybee waggle dance. The process is highly accurate, runs in real-time, and can use shared information between multiple dances.
Novel Structured Low-rank algorithm to recover spatially smooth exponential image time series
Mar 29, 2017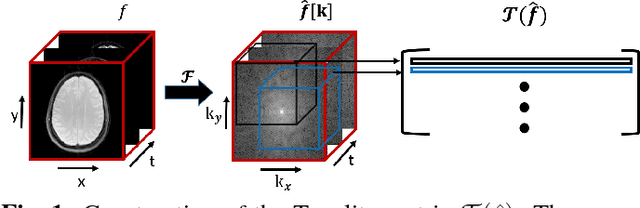
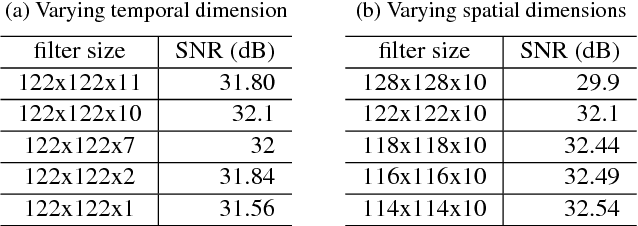
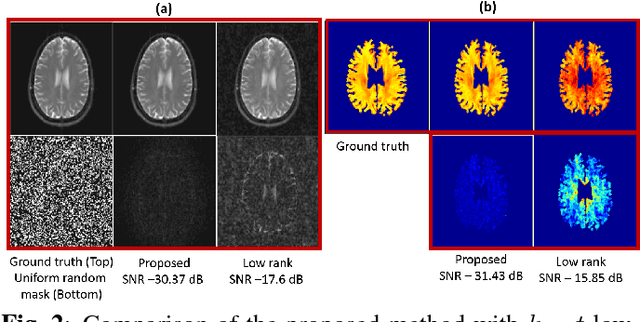
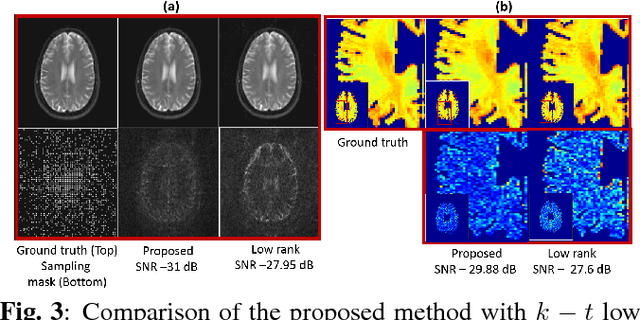
We propose a structured low rank matrix completion algorithm to recover a time series of images consisting of linear combination of exponential parameters at every pixel, from under-sampled Fourier measurements. The spatial smoothness of these parameters is exploited along with the exponential structure of the time series at every pixel, to derive an annihilation relation in the $k-t$ domain. This annihilation relation translates into a structured low rank matrix formed from the $k-t$ samples. We demonstrate the algorithm in the parameter mapping setting and show significant improvement over state of the art methods.
Sensor-based, time-critical mobility of autonomous robots in cluttered spaces: a harmonic potential approach
Aug 26, 2018This paper suggests an integrated navigation system for an unmanned ground vehicle operating in an unknown cluttered environment. The navigator supports time-critical mobility making it possible for a mobile robot to reach a target from the first attempt without the need for a dedicated exploration and mapping stage. The robot only uses necessary and sufficient egocentric local sensory data collected on its way to the target. The construction of the navigation structure revolves around key properties of the harmonic potential field approach to motion planning. The robots trajectory is well-behaved and direct-to-the-goal. It contains only the minimum number of detours necessary to accommodate the sensory data and maintain the robot in a safe, goal-oriented state. The navigation structure is developed and its theoretical basis is explained. Extensive experimental validation of its properties and performance is carried-out using the X80 robotic platform
* 32 pages, 56 figures, Journal paper
GIFT: A Real-time and Scalable 3D Shape Search Engine
Mar 31, 2017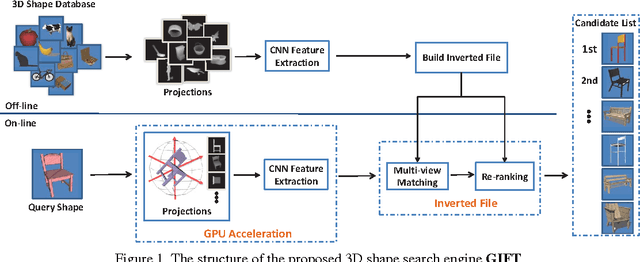
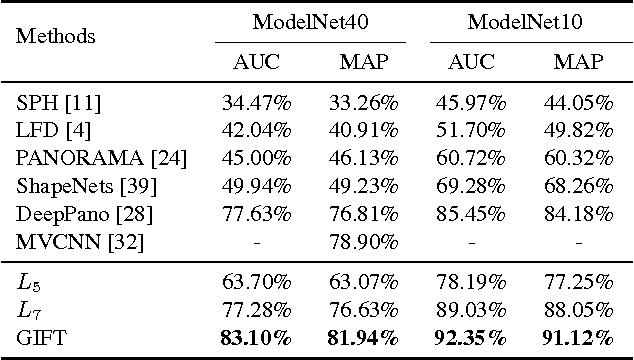
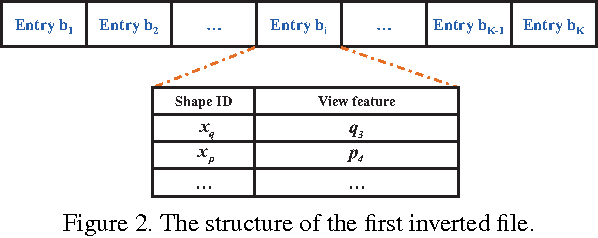
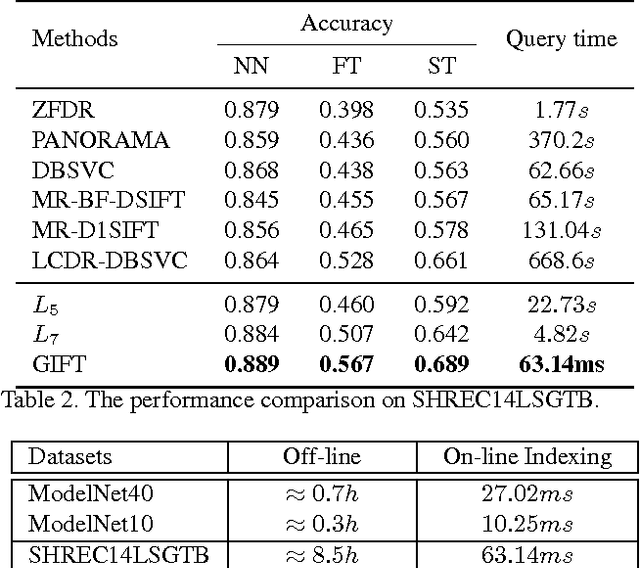
Projective analysis is an important solution for 3D shape retrieval, since human visual perceptions of 3D shapes rely on various 2D observations from different view points. Although multiple informative and discriminative views are utilized, most projection-based retrieval systems suffer from heavy computational cost, thus cannot satisfy the basic requirement of scalability for search engines. In this paper, we present a real-time 3D shape search engine based on the projective images of 3D shapes. The real-time property of our search engine results from the following aspects: (1) efficient projection and view feature extraction using GPU acceleration; (2) the first inverted file, referred as F-IF, is utilized to speed up the procedure of multi-view matching; (3) the second inverted file (S-IF), which captures a local distribution of 3D shapes in the feature manifold, is adopted for efficient context-based re-ranking. As a result, for each query the retrieval task can be finished within one second despite the necessary cost of IO overhead. We name the proposed 3D shape search engine, which combines GPU acceleration and Inverted File Twice, as GIFT. Besides its high efficiency, GIFT also outperforms the state-of-the-art methods significantly in retrieval accuracy on various shape benchmarks and competitions.
Active Learning in CNNs via Expected Improvement Maximization
Nov 27, 2020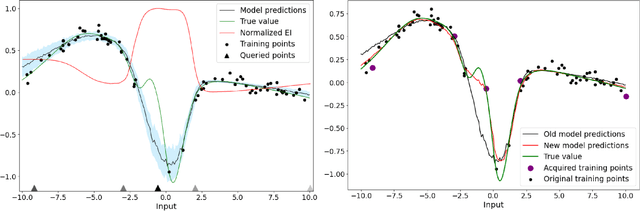

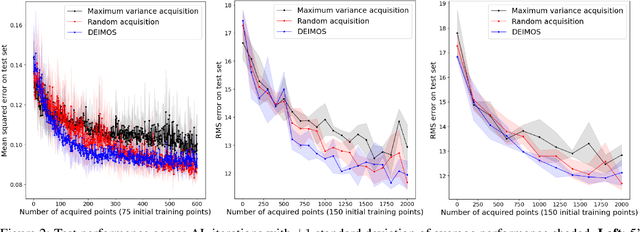

Deep learning models such as Convolutional Neural Networks (CNNs) have demonstrated high levels of effectiveness in a variety of domains, including computer vision and more recently, computational biology. However, training effective models often requires assembling and/or labeling large datasets, which may be prohibitively time-consuming or costly. Pool-based active learning techniques have the potential to mitigate these issues, leveraging models trained on limited data to selectively query unlabeled data points from a pool in an attempt to expedite the learning process. Here we present "Dropout-based Expected IMprOvementS" (DEIMOS), a flexible and computationally-efficient approach to active learning that queries points that are expected to maximize the model's improvement across a representative sample of points. The proposed framework enables us to maintain a prediction covariance matrix capturing model uncertainty, and to dynamically update this matrix in order to generate diverse batches of points in the batch-mode setting. Our active learning results demonstrate that DEIMOS outperforms several existing baselines across multiple regression and classification tasks taken from computer vision and genomics.
Multi-view Graph Learning by Joint Modeling of Consistency and Inconsistency
Aug 24, 2020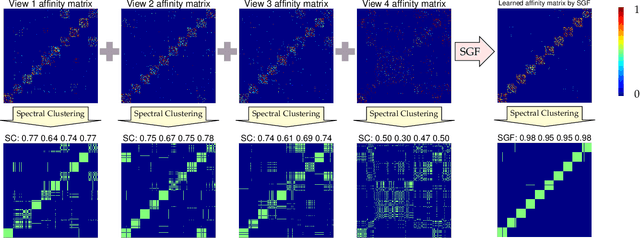
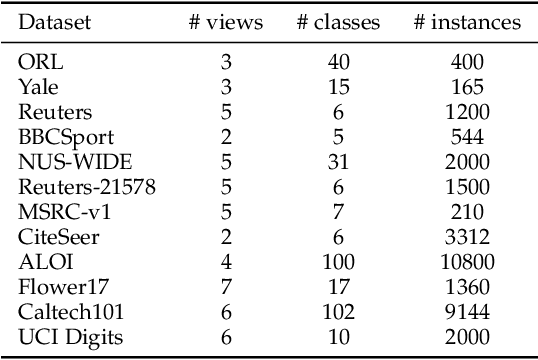
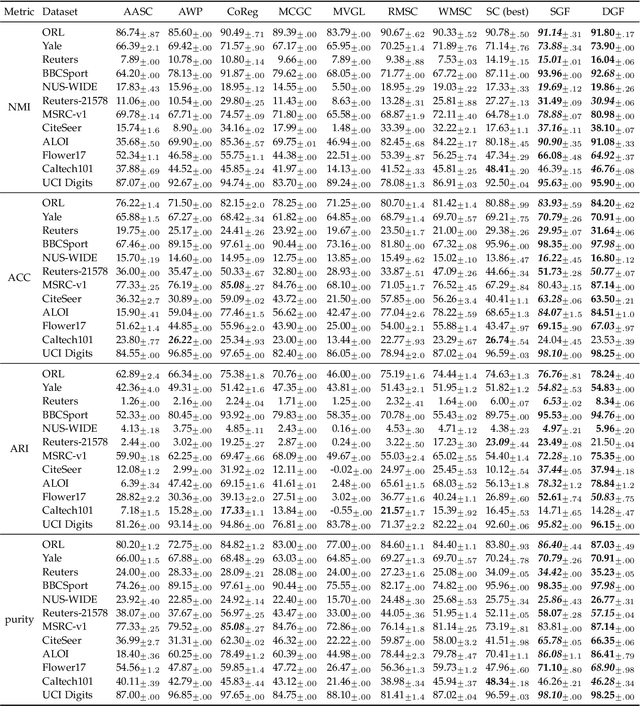
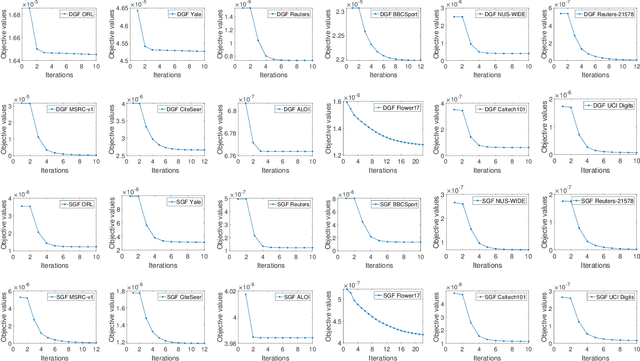
Graph learning has emerged as a promising technique for multi-view clustering with its ability to learn a unified and robust graph from multiple views. However, existing graph learning methods mostly focus on the multi-view consistency issue, yet often neglect the inconsistency across multiple views, which makes them vulnerable to possibly low-quality or noisy datasets. To overcome this limitation, we propose a new multi-view graph learning framework, which for the first time simultaneously and explicitly models multi-view consistency and multi-view inconsistency in a unified objective function, through which the consistent and inconsistent parts of each single-view graph as well as the unified graph that fuses the consistent parts can be iteratively learned. Though optimizing the objective function is NP-hard, we design a highly efficient optimization algorithm which is able to obtain an approximate solution with linear time complexity in the number of edges in the unified graph. Furthermore, our multi-view graph learning approach can be applied to both similarity graphs and dissimilarity graphs, which lead to two graph fusion-based variants in our framework. Experiments on twelve multi-view datasets have demonstrated the robustness and efficiency of the proposed approach.
Better Together: Online Probabilistic Clique Change Detection in 3D Landmark-Based Maps
Aug 02, 2020
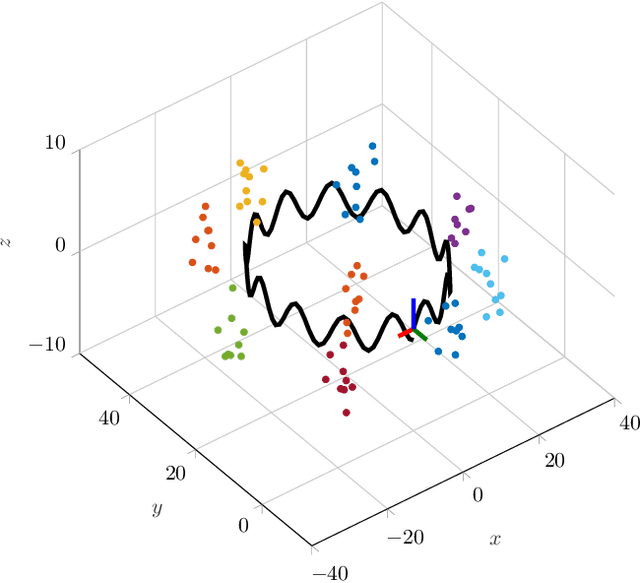
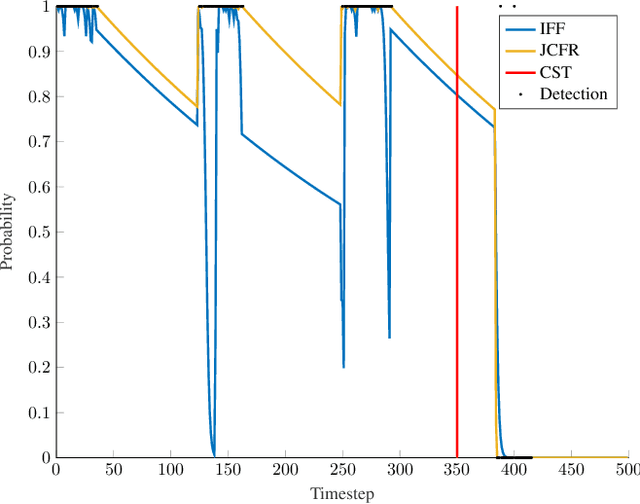
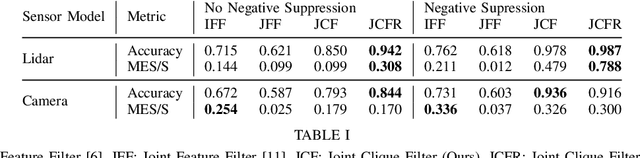
Many modern simultaneous localization and mapping (SLAM) techniques rely on sparse landmark-based maps due to their real-time performance. However, these techniques frequently assert that these landmarks are fixed in position over time, known as the static-world assumption. This is rarely, if ever, the case in most real-world environments. Even worse, over long deployments, robots are bound to observe traditionally static landmarks change, for example when an autonomous vehicle encounters a construction zone. This work addresses this challenge, accounting for changes in complex three-dimensional environments with the creation of a probabilistic filter that operates on the features that give rise to landmarks. To accomplish this, landmarks are clustered into cliques and a filter is developed to estimate their persistence jointly among observations of the landmarks in a clique. This filter uses estimated spatial-temporal priors of geometric objects, allowing for dynamic and semi-static objects to be removed from a formally static map. The proposed algorithm is validated in a 3D simulated environment.
CycleQSM: Unsupervised QSM Deep Learning using Physics-Informed CycleGAN
Dec 07, 2020



Quantitative susceptibility mapping (QSM) is a useful magnetic resonance imaging (MRI) technique which provides spatial distribution of magnetic susceptibility values of tissues. QSMs can be obtained by deconvolving the dipole kernel from phase images, but the spectral nulls in the dipole kernel make the inversion ill-posed. In recent times, deep learning approaches have shown a comparable QSM reconstruction performance as the classic approaches, despite the fast reconstruction time. Most of the existing deep learning methods are, however, based on supervised learning, so matched pairs of input phase images and the ground-truth maps are needed. Moreover, it was reported that the supervised learning often leads to underestimated QSM values. To address this, here we propose a novel unsupervised QSM deep learning method using physics-informed cycleGAN, which is derived from optimal transport perspective. In contrast to the conventional cycleGAN, our novel cycleGAN has only one generator and one discriminator thanks to the known dipole kernel. Experimental results confirm that the proposed method provides more accurate QSM maps compared to the existing deep learning approaches, and provide competitive performance to the best classical approaches despite the ultra-fast reconstruction.
Brain Tumor Detection and Classification based on Hybrid Ensemble Classifier
Jan 01, 2021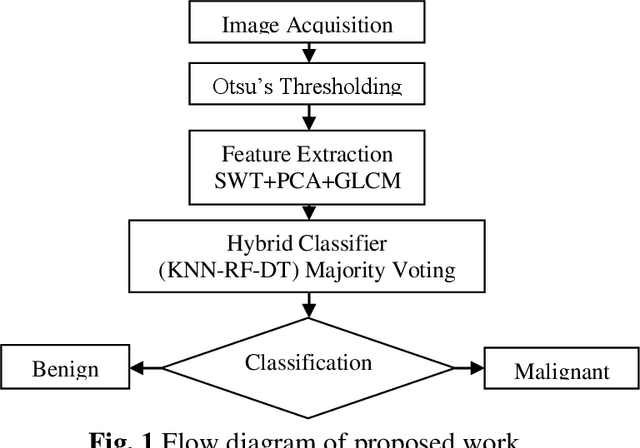

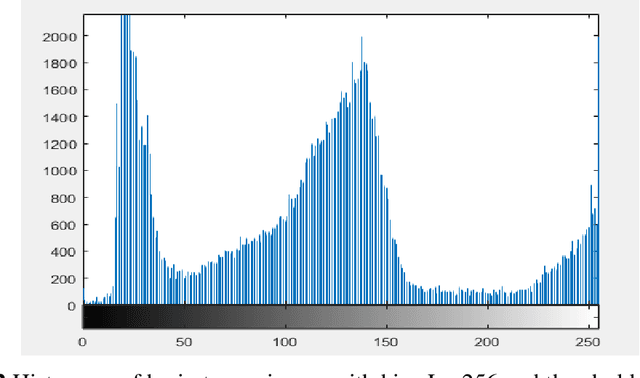
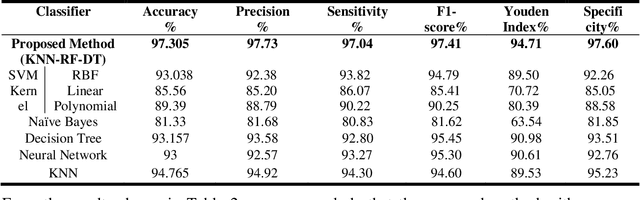
To improve patient survival and treatment outcomes, early diagnosis of brain tumors is an essential task. It is a difficult task to evaluate the magnetic resonance imaging (MRI) images manually. Thus, there is a need for digital methods for tumor diagnosis with better accuracy. However, it is still a very challenging task in assessing their shape, volume, boundaries, tumor detection, size, segmentation, and classification. In this proposed work, we propose a hybrid ensemble method using Random Forest (RF), K-Nearest Neighbour, and Decision Tree (DT) (KNN-RF-DT) based on Majority Voting Method. It aims to calculate the area of the tumor region and classify brain tumors as benign and malignant. In the beginning, segmentation is done by using Otsu's Threshold method. Feature Extraction is done by using Stationary Wavelet Transform (SWT), Principle Component Analysis (PCA), and Gray Level Co-occurrence Matrix (GLCM), which gives thirteen features for classification. The classification is done by hybrid ensemble classifier (KNN-RF-DT) based on the Majority Voting method. Overall it aimed at improving the performance by traditional classifiers instead of going to deep learning. Traditional classifiers have an advantage over deep learning algorithms because they require small datasets for training and have low computational time complexity, low cost to the users, and can be easily adopted by less skilled people. Overall, our proposed method is tested upon dataset of 2556 images, which are used in 85:15 for training and testing respectively and gives good accuracy of 97.305%.
Data Programming by Demonstration: A Framework for Interactively Learning Labeling Functions
Sep 03, 2020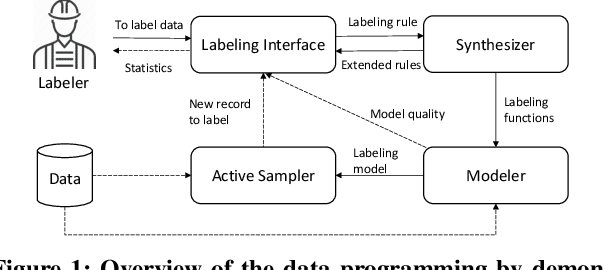
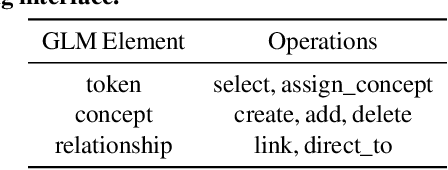
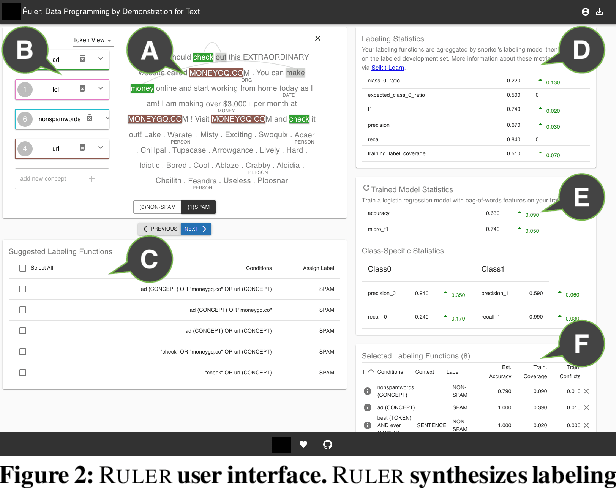

Data programming is a programmatic weak supervision approach to efficiently curate large-scale labeled training data. Writing data programs (labeling functions) requires, however, both programming literacy and domain expertise. Many subject matter experts have neither programming proficiency nor time to effectively write data programs. Furthermore, regardless of one's expertise in coding or machine learning, transferring domain expertise into labeling functions by enumerating rules and thresholds is not only time consuming but also inherently difficult. Here we propose a new framework, data programming by demonstration (DPBD), to generate labeling rules using interactive demonstrations of users. DPBD aims to relieve the burden of writing labeling functions from users, enabling them to focus on higher-level semantics such as identifying relevant signals for labeling tasks. We operationalize our framework with Ruler, an interactive system that synthesizes labeling rules for document classification by using span-level annotations of users on document examples. We compare Ruler with conventional data programming through a user study conducted with 10 data scientists creating labeling functions for sentiment and spam classification tasks. We find that Ruler is easier to use and learn and offers higher overall satisfaction, while providing discriminative model performances comparable to ones achieved by conventional data programming.