 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Probabilistic Analysis of RRT Trees
May 04, 2020
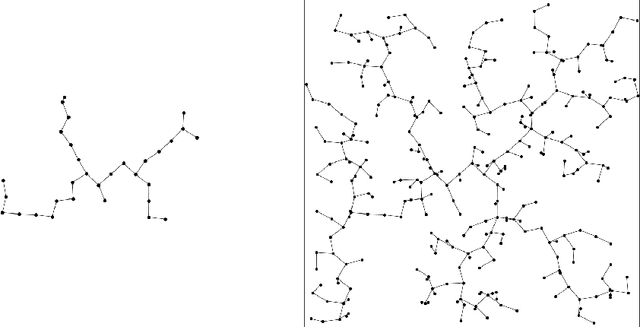
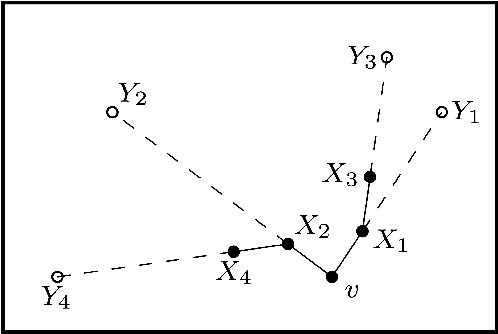

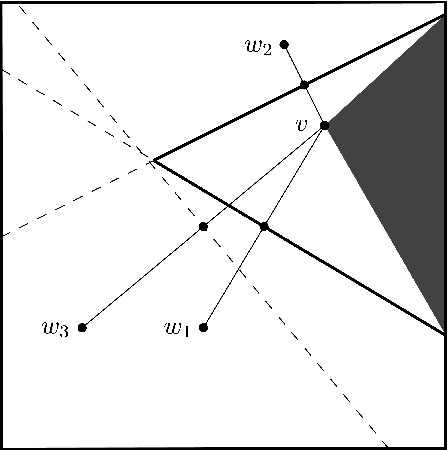
This thesis presents analysis of the properties and run-time of the Rapidly-exploring Random Tree (RRT) algorithm. It is shown that the time for the RRT with stepsize $\epsilon$ to grow close to every point in the $d$-dimensional unit cube is $\Theta\left(\frac1{\epsilon^d} \log \left(\frac1\epsilon\right)\right)$. Also, the time it takes for the tree to reach a region of positive probability is $O\left(\epsilon^{-\frac32}\right)$. Finally, a relationship is shown to the Nearest Neighbour Tree (NNT). This relationship shows that the total Euclidean path length after $n$ steps is $O(\sqrt n)$ and the expected height of the tree is bounded above by $(e + o(1)) \log n$.
Modeling bike counts in a bike-sharing system considering the effect of weather conditions
Jun 13, 2020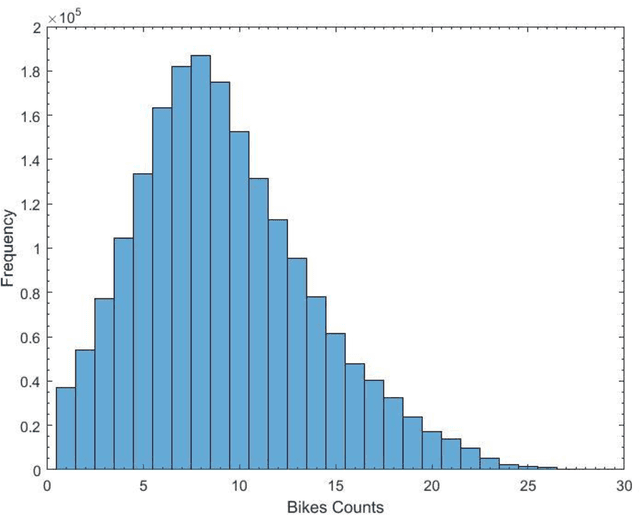

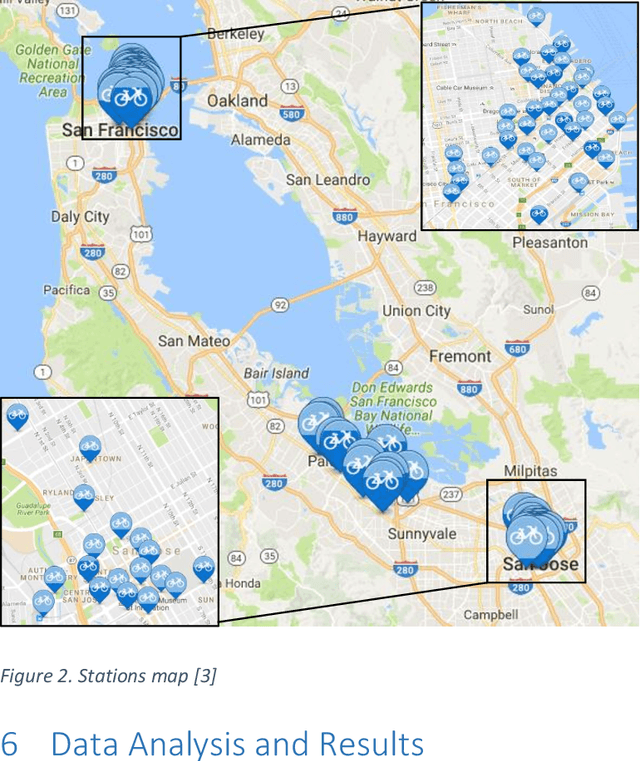
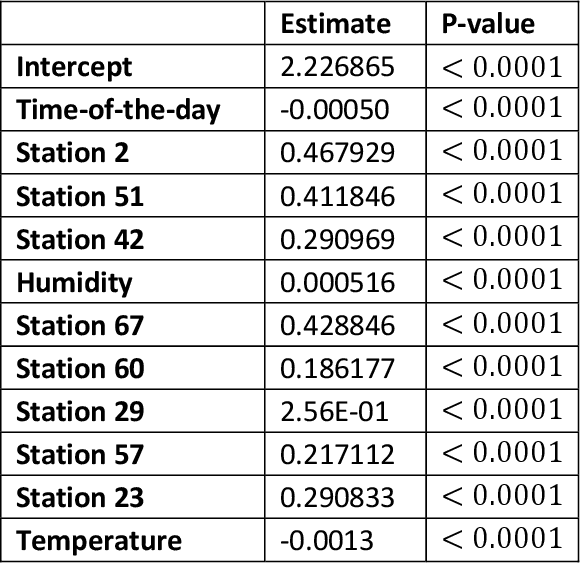
The paper develops a method that quantifies the effect of weather conditions on the prediction of bike station counts in the San Francisco Bay Area Bike Share System. The Random Forest technique was used to rank the predictors that were then used to develop a regression model using a guided forward step-wise regression approach. The Bayesian Information Criterion was used in the development and comparison of the various prediction models. We demonstrated that the proposed approach is promising to quantify the effect of various features on a large BSS and on each station in cases of large networks with big data. The results show that the time-of-the-day, temperature, and humidity level (which has not been studied before) are significant count predictors. It also shows that as weather variables are geographic location dependent and thus should be quantified before using them in modeling. Further, findings show that the number of available bikes at station i at time t-1 and time-of-the-day were the most significant variables in estimating the bike counts at station i.
* Published in Case Studies on Transport Policy (Volume 7, Issue 2, June 2019, Pages 261-268)
Honey Bee Dance Modeling in Real-time using Machine Learning
May 20, 2017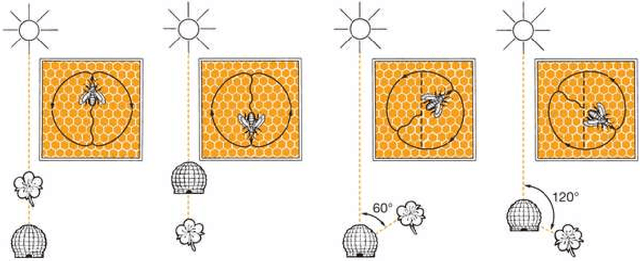
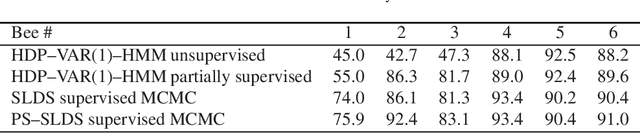
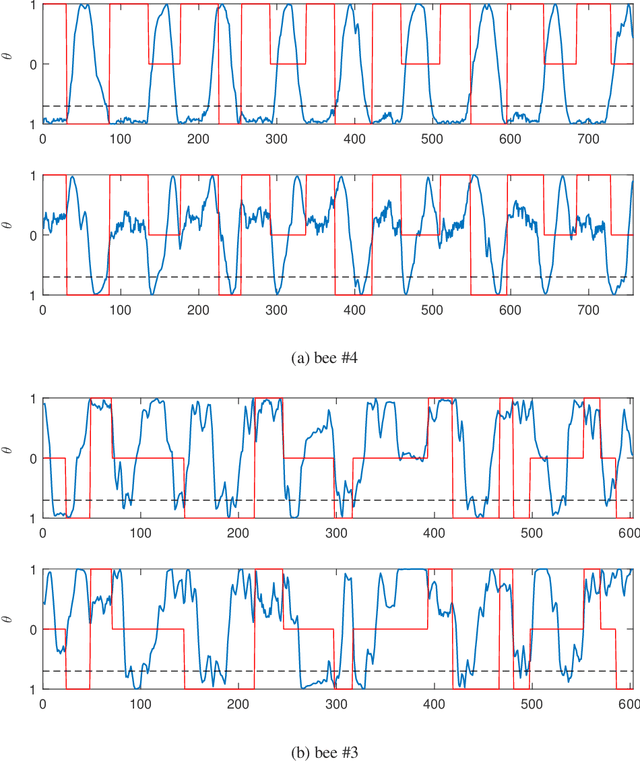
The waggle dance that honeybees perform is an astonishing way of communicating the location of food source. After over 60 years of its discovery, researchers still use manual labeling by watching hours of dance videos to detect different transitions between dance components thus extracting information regarding the distance and direction to the food source. We propose an automated process to monitor and segment different components of honeybee waggle dance. The process is highly accurate, runs in real-time, and can use shared information between multiple dances.
Confounding Feature Acquisition for Causal Effect Estimation
Nov 17, 2020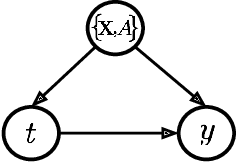
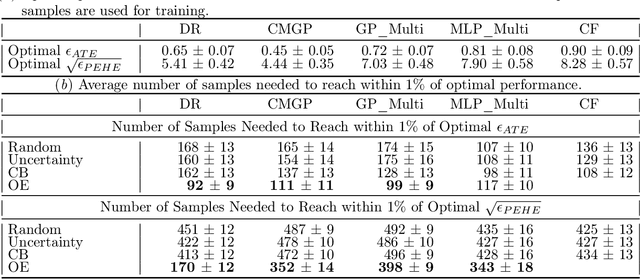
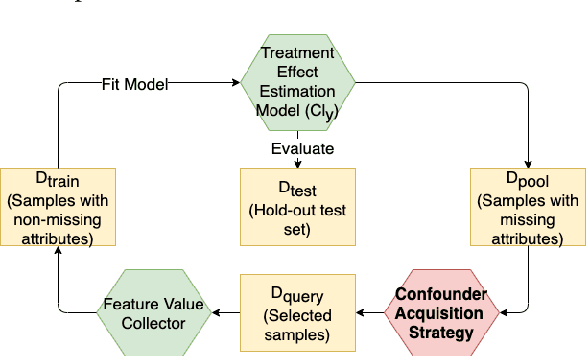

Reliable treatment effect estimation from observational data depends on the availability of all confounding information. While much work has targeted treatment effect estimation from observational data, there is relatively little work in the setting of confounding variable missingness, where collecting more information on confounders is often costly or time-consuming. In this work, we frame this challenge as a problem of feature acquisition of confounding features for causal inference. Our goal is to prioritize acquiring values for a fixed and known subset of missing confounders in samples that lead to efficient average treatment effect estimation. We propose two acquisition strategies based on i) covariate balancing (CB), and ii) reducing statistical estimation error on observed factual outcome error (OE). We compare CB and OE on five common causal effect estimation methods, and demonstrate improved sample efficiency of OE over baseline methods under various settings. We also provide visualizations for further analysis on the difference between our proposed methods.
Novel Structured Low-rank algorithm to recover spatially smooth exponential image time series
Mar 29, 2017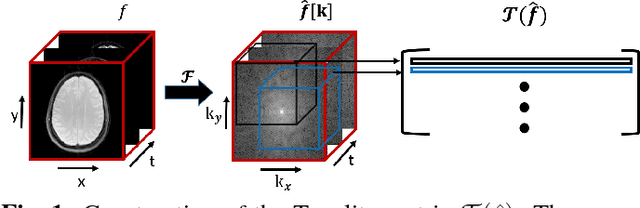
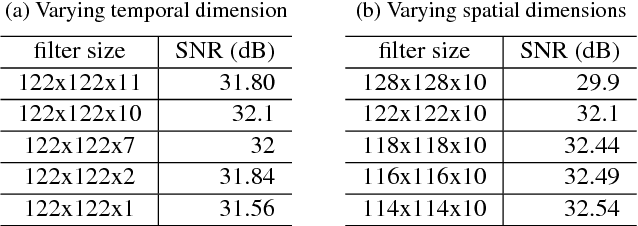
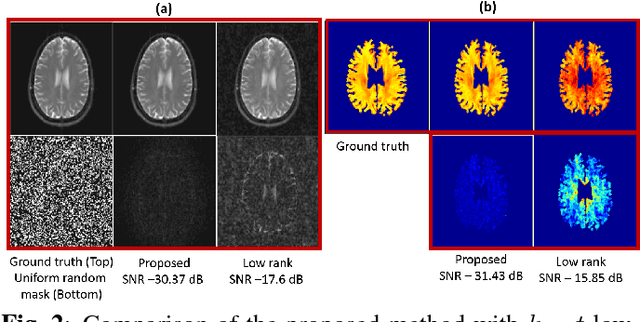
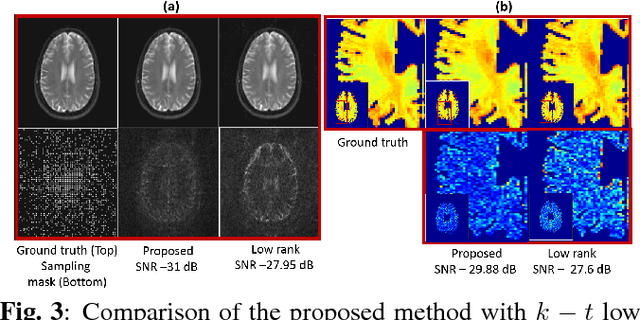
We propose a structured low rank matrix completion algorithm to recover a time series of images consisting of linear combination of exponential parameters at every pixel, from under-sampled Fourier measurements. The spatial smoothness of these parameters is exploited along with the exponential structure of the time series at every pixel, to derive an annihilation relation in the $k-t$ domain. This annihilation relation translates into a structured low rank matrix formed from the $k-t$ samples. We demonstrate the algorithm in the parameter mapping setting and show significant improvement over state of the art methods.
Long-Term Prediction of Lane Change Maneuver Through a Multilayer Perceptron
Jun 23, 2020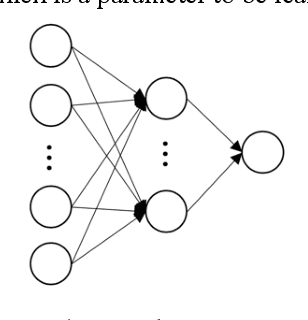
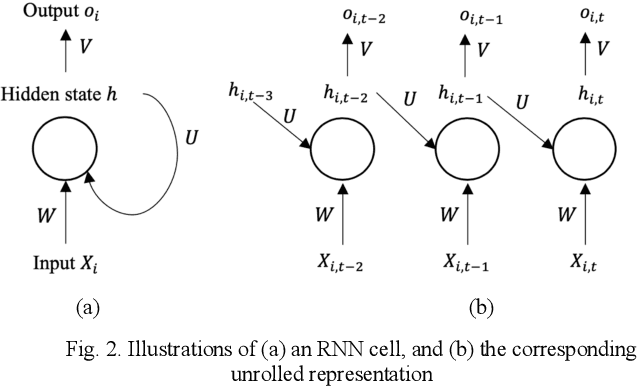
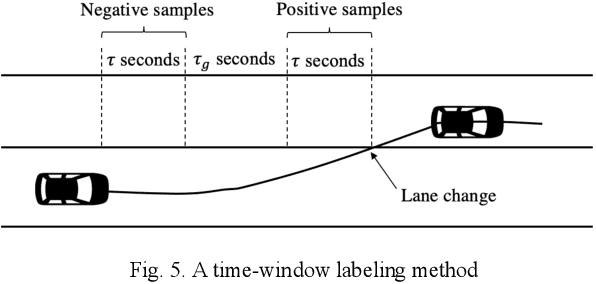
Behavior prediction plays an essential role in both autonomous driving systems and Advanced Driver Assistance Systems (ADAS), since it enhances vehicle's awareness of the imminent hazards in the surrounding environment. Many existing lane change prediction models take as input lateral or angle information and make short-term (< 5 seconds) maneuver predictions. In this study, we propose a longer-term (5~10 seconds) prediction model without any lateral or angle information. Three prediction models are introduced, including a logistic regression model, a multilayer perceptron (MLP) model, and a recurrent neural network (RNN) model, and their performances are compared by using the real-world NGSIM dataset. To properly label the trajectory data, this study proposes a new time-window labeling scheme by adding a time gap between positive and negative samples. Two approaches are also proposed to address the unstable prediction issue, where the aggressive approach propagates each positive prediction for certain seconds, while the conservative approach adopts a roll-window average to smooth the prediction. Evaluation results show that the developed prediction model is able to capture 75% of real lane change maneuvers with an average advanced prediction time of 8.05 seconds.
A Multi-Agent Deep Reinforcement Learning Approach for a Distributed Energy Marketplace in Smart Grids
Sep 23, 2020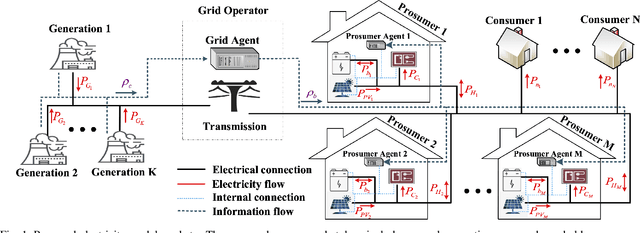
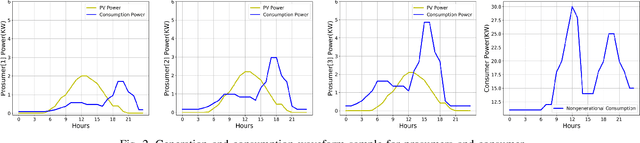
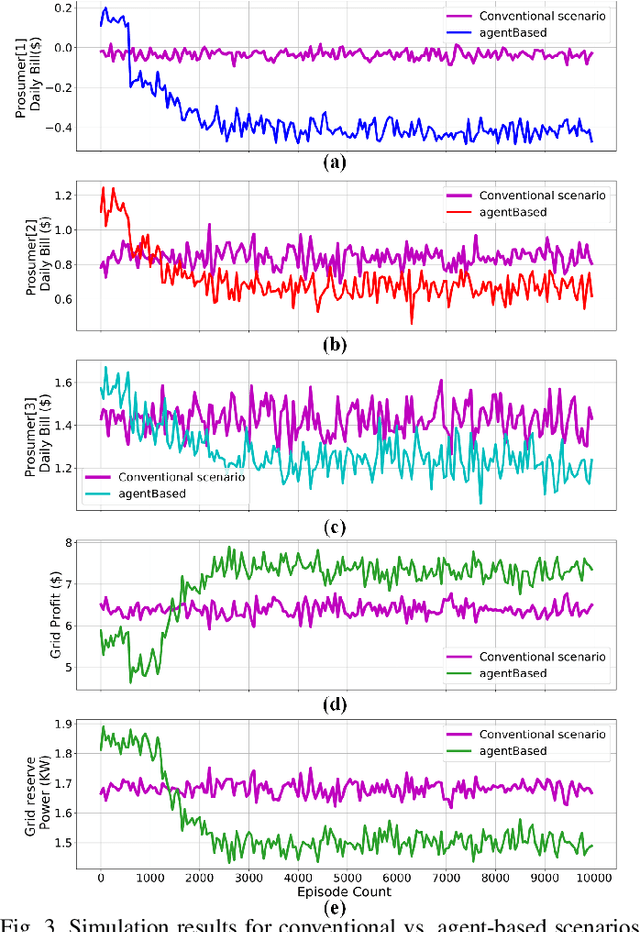
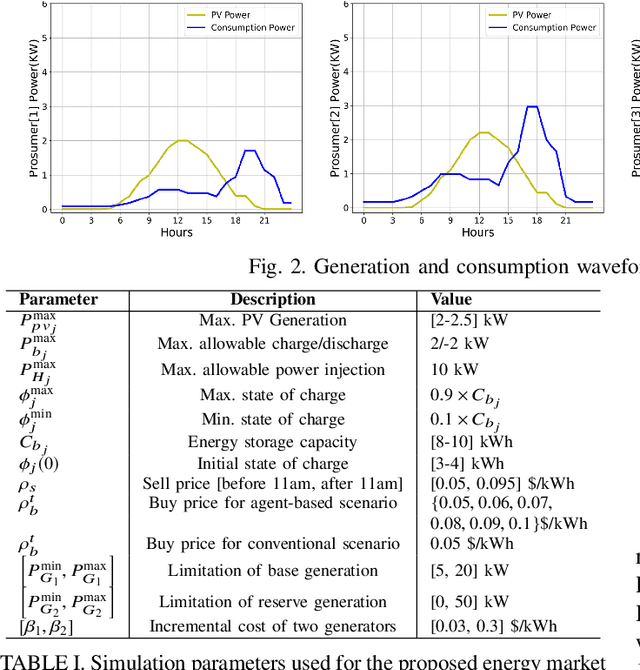
This paper presents a Reinforcement Learning (RL) based energy market for a prosumer dominated microgrid. The proposed market model facilitates a real-time and demanddependent dynamic pricing environment, which reduces grid costs and improves the economic benefits for prosumers. Furthermore, this market model enables the grid operator to leverage prosumers storage capacity as a dispatchable asset for grid support applications. Simulation results based on the Deep QNetwork (DQN) framework demonstrate significant improvements of the 24-hour accumulative profit for both prosumers and the grid operator, as well as major reductions in grid reserve power utilization.
Applicability and Challenges of Deep Reinforcement Learning for Satellite Frequency Plan Design
Oct 15, 2020
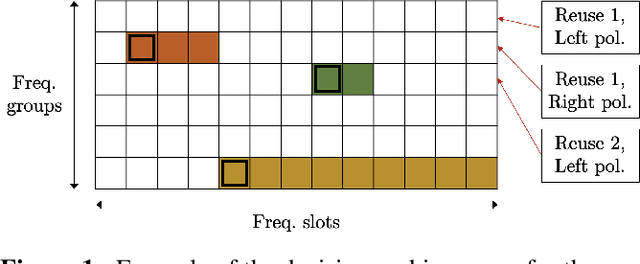
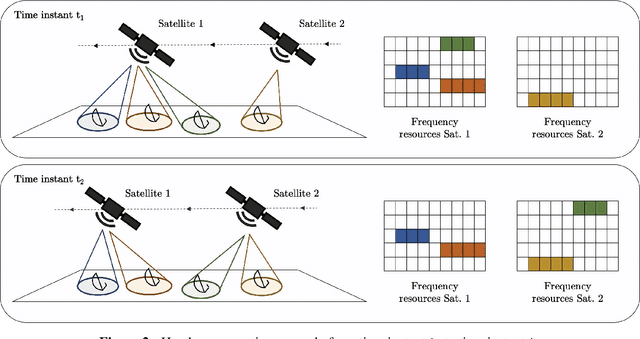

The study and benchmarking of Deep Reinforcement Learning (DRL) models has become a trend in many industries, including aerospace engineering and communications. Recent studies in these fields propose these kinds of models to address certain complex real-time decision-making problems in which classic approaches do not meet time requirements or fail to obtain optimal solutions. While the good performance of DRL models has been proved for specific use cases or scenarios, most studies do not discuss the compromises of such models. In this paper we explore the tradeoffs of different elements of DRL models and how they might impact the final performance. To that end, we choose the Frequency Plan Design (FPD) problem in the context of multibeam satellite constellations as our use case and propose a DRL model to address it. We identify six different core elements that have a major effect in its performance: the policy, the policy optimizer, the state, action, and reward representations, and the training environment. We analyze different alternatives for each of these elements and characterize their effect. We also use multiple environments to account for different scenarios in which we vary the dimensionality or make the environment non-stationary. Our findings show that DRL is a potential method to address the FPD problem in real operations, especially because of its speed in decision-making. However, no single DRL model is able to outperform the rest in all scenarios, and the best approach for each of the six core elements depends on the features of the operation environment. While we agree on the potential of DRL to solve future complex problems in the aerospace industry, we also reflect on the importance of designing appropriate models and training procedures, understanding the applicability of such models, and reporting the main performance tradeoffs.
Distilled Thompson Sampling: Practical and Efficient Thompson Sampling via Imitation Learning
Dec 08, 2020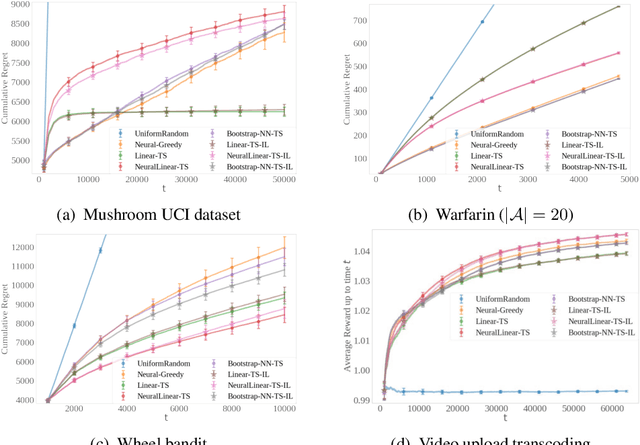
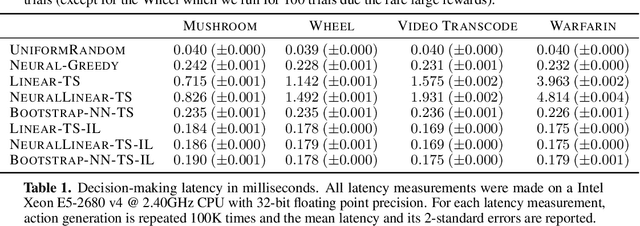
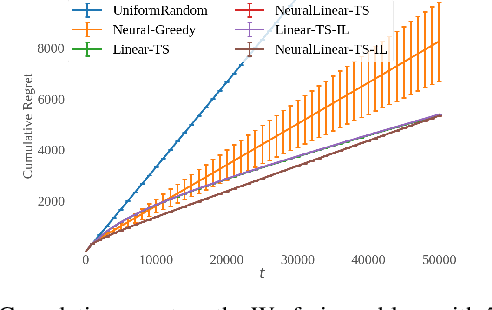

Thompson sampling (TS) has emerged as a robust technique for contextual bandit problems. However, TS requires posterior inference and optimization for action generation, prohibiting its use in many internet applications where latency and ease of deployment are of concern. We propose a novel imitation-learning-based algorithm that distills a TS policy into an explicit policy representation by performing posterior inference and optimization offline. The explicit policy representation enables fast online decision-making and easy deployment in mobile and server-based environments. Our algorithm iteratively performs offline batch updates to the TS policy and learns a new imitation policy. Since we update the TS policy with observations collected under the imitation policy, our algorithm emulates an off-policy version of TS. Our imitation algorithm guarantees Bayes regret comparable to TS, up to the sum of single-step imitation errors. We show these imitation errors can be made arbitrarily small when unlabeled contexts are cheaply available, which is the case for most large-scale internet applications. Empirically, we show that our imitation policy achieves comparable regret to TS, while reducing decision-time latency by over an order of magnitude.
Towards Scalable and Privacy-Preserving Deep Neural Network via Algorithmic-Cryptographic Co-design
Dec 17, 2020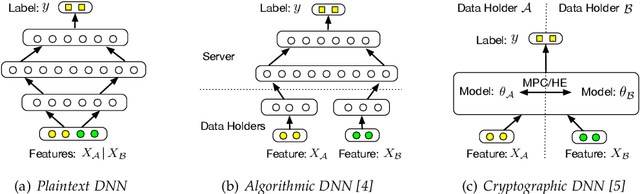
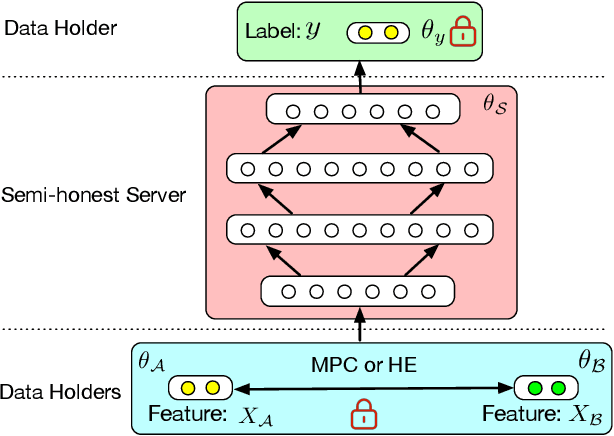
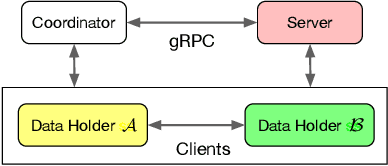

Deep Neural Networks (DNNs) have achieved remarkable progress in various real-world applications, especially when abundant training data are provided. However, data isolation has become a serious problem currently. Existing works build privacy preserving DNN models from either algorithmic perspective or cryptographic perspective. The former mainly splits the DNN computation graph between data holders or between data holders and server, which demonstrates good scalability but suffers from accuracy loss and potential privacy risks. In contrast, the latter leverages time-consuming cryptographic techniques, which has strong privacy guarantee but poor scalability. In this paper, we propose SPNN - a Scalable and Privacy-preserving deep Neural Network learning framework, from algorithmic-cryptographic co-perspective. From algorithmic perspective, we split the computation graph of DNN models into two parts, i.e., the private data related computations that are performed by data holders and the rest heavy computations that are delegated to a server with high computation ability. From cryptographic perspective, we propose using two types of cryptographic techniques, i.e., secret sharing and homomorphic encryption, for the isolated data holders to conduct private data related computations privately and cooperatively. Furthermore, we implement SPNN in a decentralized setting and introduce user-friendly APIs. Experimental results conducted on real-world datasets demonstrate the superiority of SPNN.