 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PowerNet: Transferable Dynamic IR Drop Estimation via Maximum Convolutional Neural Network
Nov 26, 2020
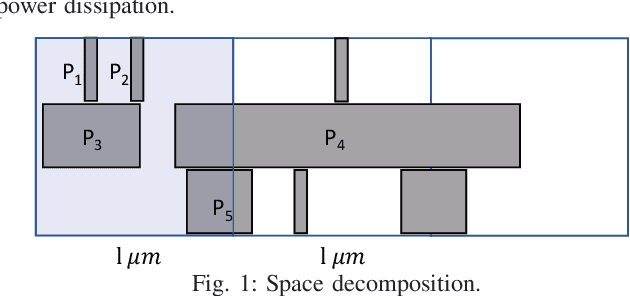
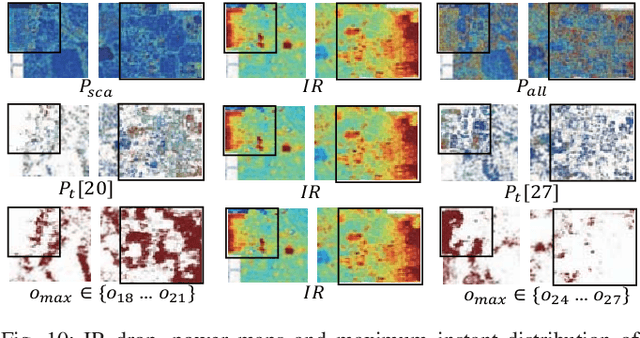
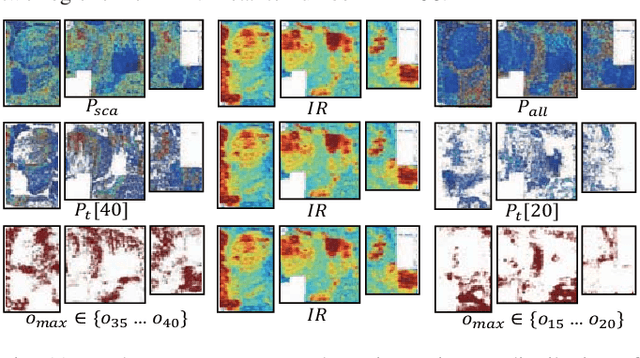
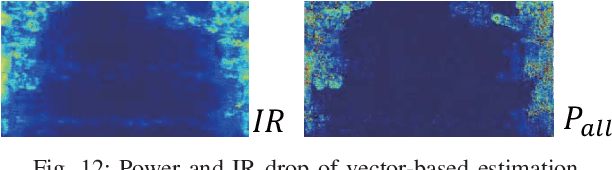
IR drop is a fundamental constraint required by almost all chip designs. However, its evaluation usually takes a long time that hinders mitigation techniques for fixing its violations. In this work, we develop a fast dynamic IR drop estimation technique, named PowerNet, based on a convolutional neural network (CNN). It can handle both vector-based and vectorless IR analyses. Moreover, the proposed CNN model is general and transferable to different designs. This is in contrast to most existing machine learning (ML) approaches, where a model is applicable only to a specific design. Experimental results show that PowerNet outperforms the latest ML method by 9% in accuracy for the challenging case of vectorless IR drop and achieves a 30 times speedup compared to an accurate IR drop commercial tool. Further, a mitigation tool guided by PowerNet reduces IR drop hotspots by 26% and 31% on two industrial designs, respectively, with very limited modification on their power grids.
Experimental Verification of Stability Theory for a Planar Rigid Body with Two Unilateral Frictional Contacts
Aug 24, 2020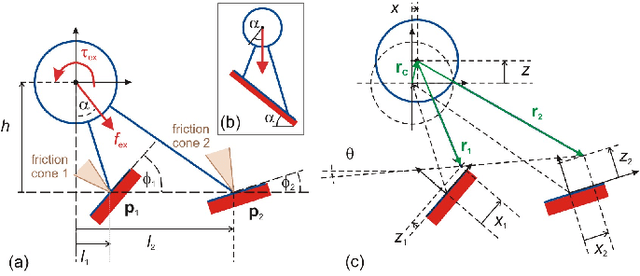
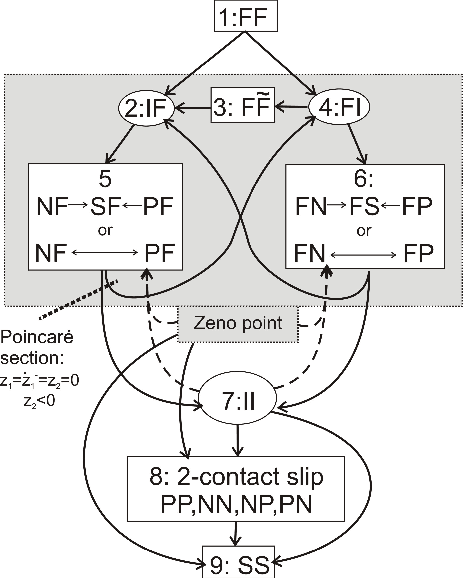
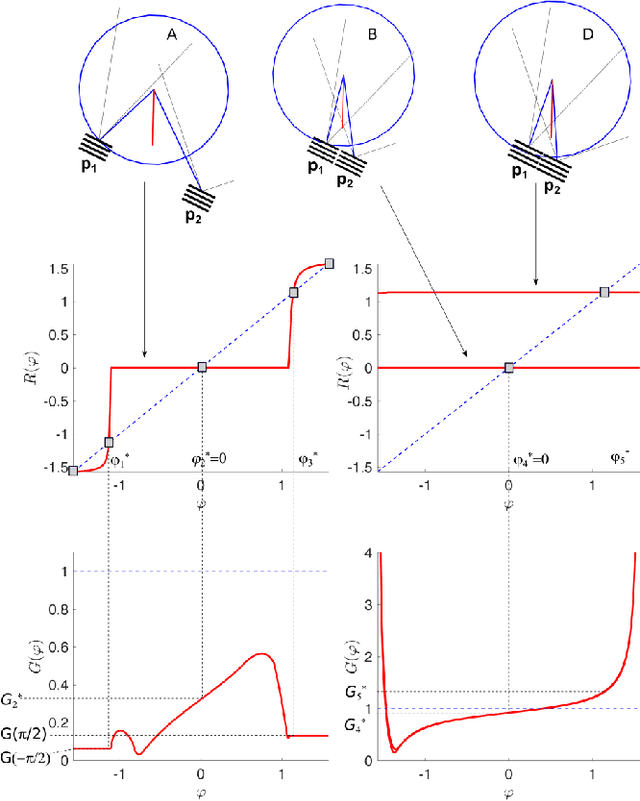
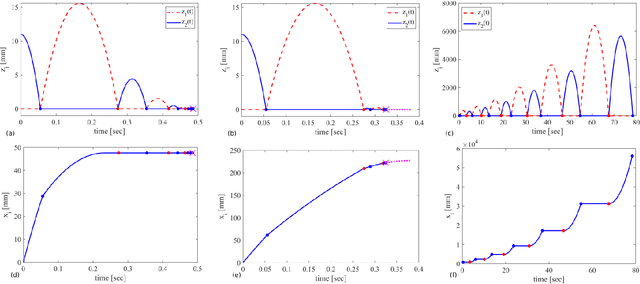
Stability of equilibrium states in mechanical systems with multiple unilateral frictional contacts is an important practical requirement, with high relevance for robotic applications. In our previous work, we theoretically analyzed finite-time Lyapunov stability for a minimal model of planar rigid body with two frictional point contacts. Assuming inelastic impacts and Coulomb friction, conditions for stability and instability of an equilibrium configuration have been derived. In this work, we present for the first time an experimental demonstration of this stability theory, using a variable-structure rigid ''biped'' with frictional footpads on an inclined plane. By changing the biped's center-of-mass location, we attain different equilibrium states, which respond to small perturbations by divergence or convergence, showing remarkable agreement with the predictions of the stability theory. Using high-speed recording of video movies, good quantitative agreement between experiments and numerical simulations is obtained, and limitations of the rigid-body model and inelastic impact assumptions are also studied. The results prove the utility and practical value of our stability theory.
Exploring grid topology reconfiguration using a simple deep reinforcement learning approach
Nov 26, 2020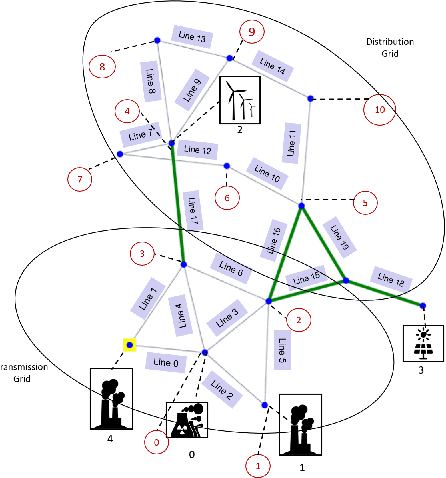
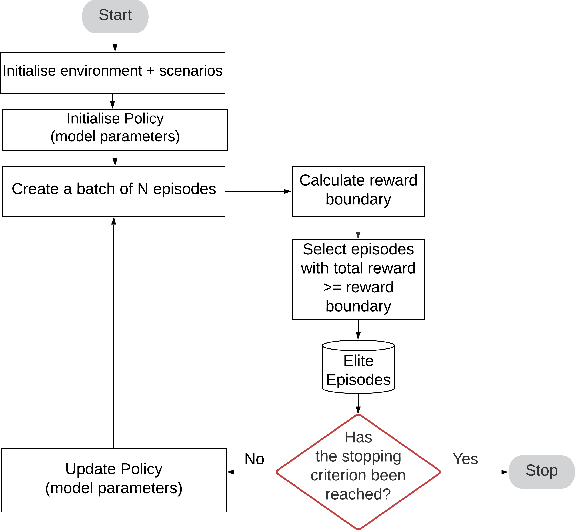
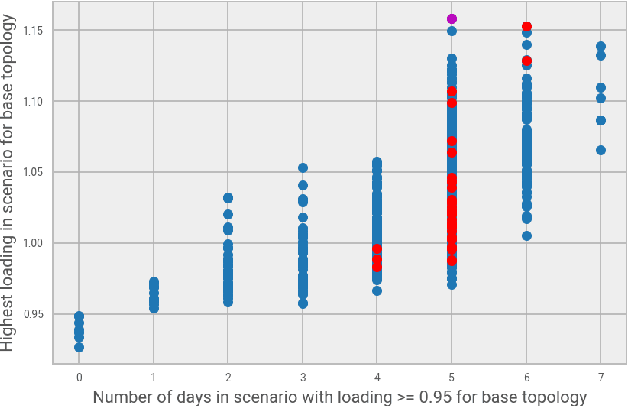
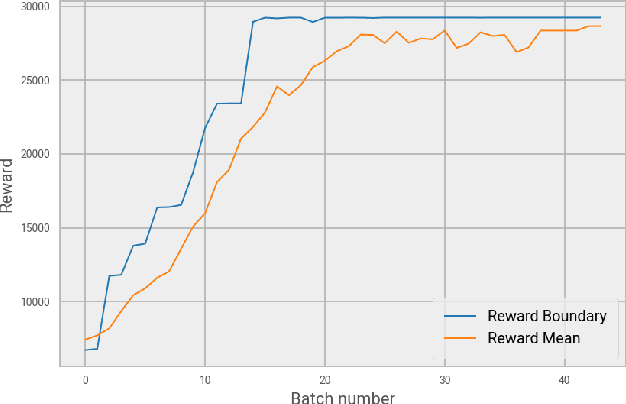
System operators are faced with increasingly volatile operating conditions. In order to manage system reliability in a cost-effective manner, control room operators are turning to computerised decision support tools based on AI and machine learning. Specifically, Reinforcement Learning (RL) is a promising technique to train agents that suggest grid control actions to operators. In this paper, a simple baseline approach is presented using RL to represent an artificial control room operator that can operate a IEEE 14-bus test case for a duration of 1 week. This agent takes topological switching actions to control power flows on the grid, and is trained on only a single well-chosen scenario. The behaviour of this agent is tested on different time-series of generation and demand, demonstrating its ability to operate the grid successfully in 965 out of 1000 scenarios. The type and variability of topologies suggested by the agent are analysed across the test scenarios, demonstrating efficient and diverse agent behaviour.
Depth Reconstruction of Translucent Objects from a Single Time-of-Flight Camera using Deep Residual Networks
Sep 28, 2018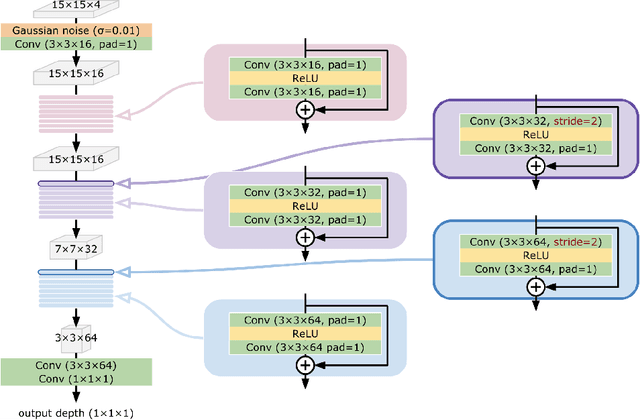
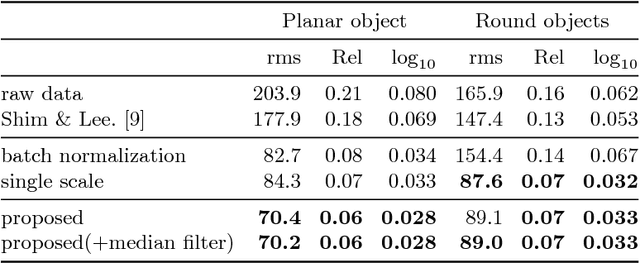

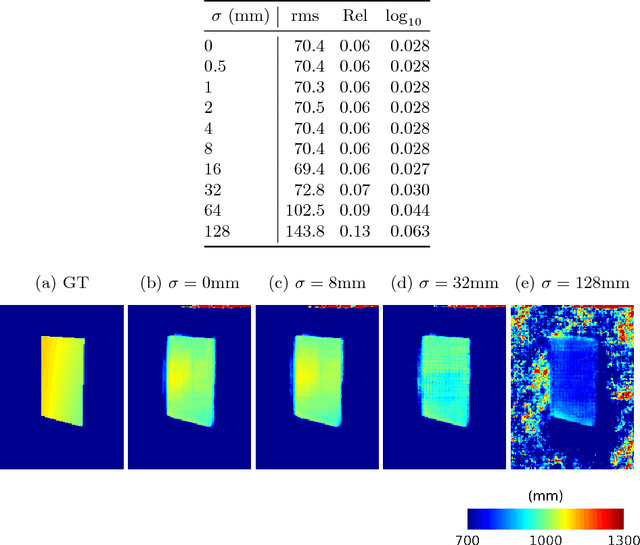
We propose a novel approach to recovering the translucent objects from a single time-of-flight (ToF) depth camera using deep residual networks. When recording the translucent objects using the ToF depth camera, their depth values are severely contaminated due to complex light interactions with the surrounding environment. While existing methods suggested new capture systems or developed the depth distortion models, their solutions were less practical because of strict assumptions or heavy computational complexity. In this paper, we adopt the deep residual networks for modeling the ToF depth distortion caused by translucency. To fully utilize both the local and semantic information of objects, multi-scale patches are used to predict the depth value. Based on the quantitative and qualitative evaluation on our benchmark database, we show the effectiveness and robustness of the proposed algorithm.
Unsupervised Domain Adaptation for Speech Recognition via Uncertainty Driven Self-Training
Nov 26, 2020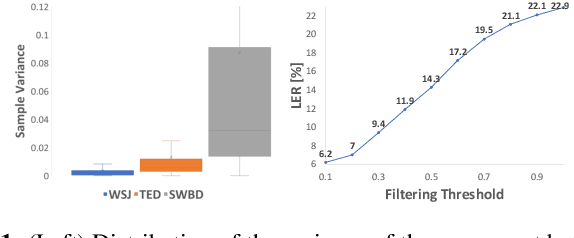
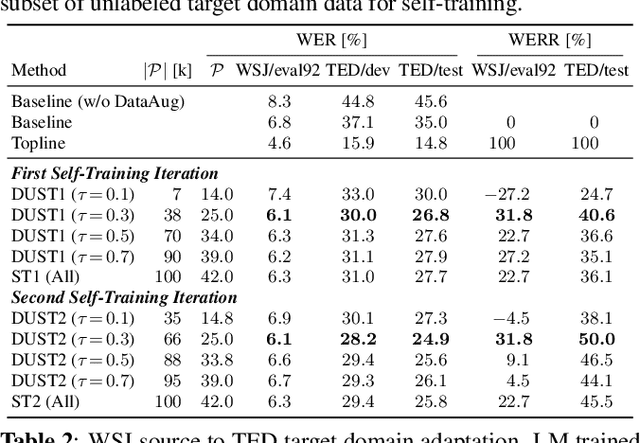
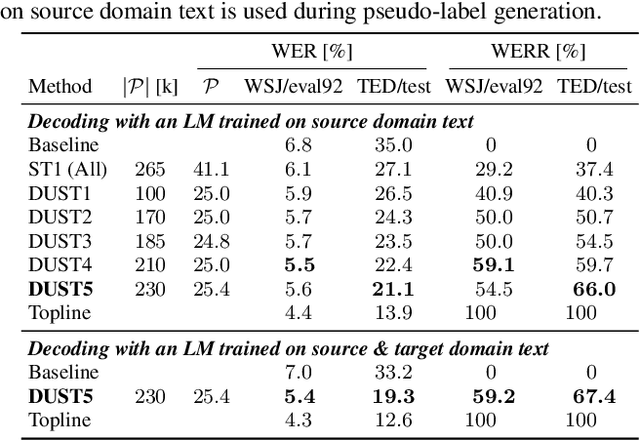
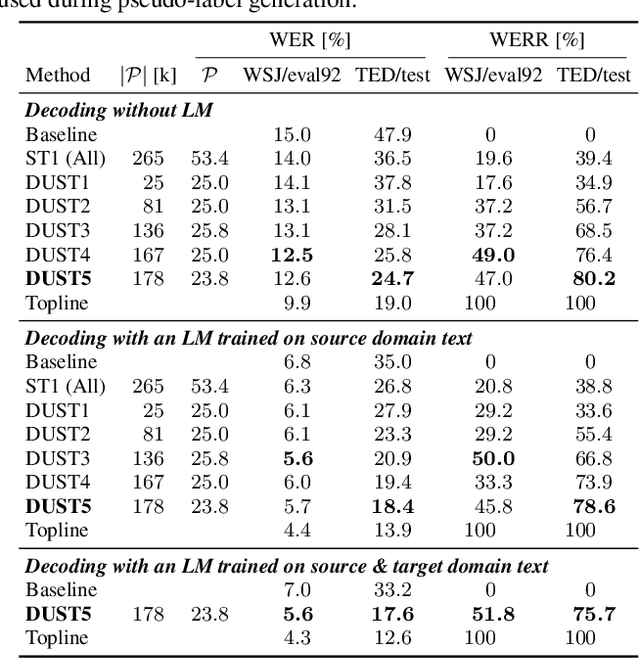
The performance of automatic speech recognition (ASR) systems typically degrades significantly when the training and test data domains are mismatched. In this paper, we show that self-training (ST) combined with an uncertainty-based pseudo-label filtering approach can be effectively used for domain adaptation. We propose DUST, a dropout-based uncertainty-driven self-training technique which uses agreement between multiple predictions of an ASR system obtained for different dropout settings to measure the model's uncertainty about its prediction. DUST excludes pseudo-labeled data with high uncertainties from the training, which leads to substantially improved ASR results compared to ST without filtering, and accelerates the training time due to a reduced training data set. Domain adaptation experiments using WSJ as a source domain and TED-LIUM 3 as well as SWITCHBOARD as the target domains show that up to 80% of the performance of a system trained on ground-truth data can be recovered.
FusionStitching: Boosting Memory Intensive Computations for Deep Learning Workloads
Sep 23, 2020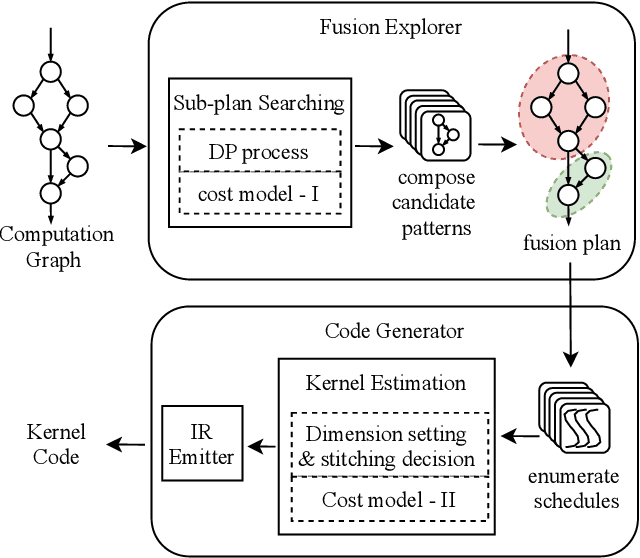
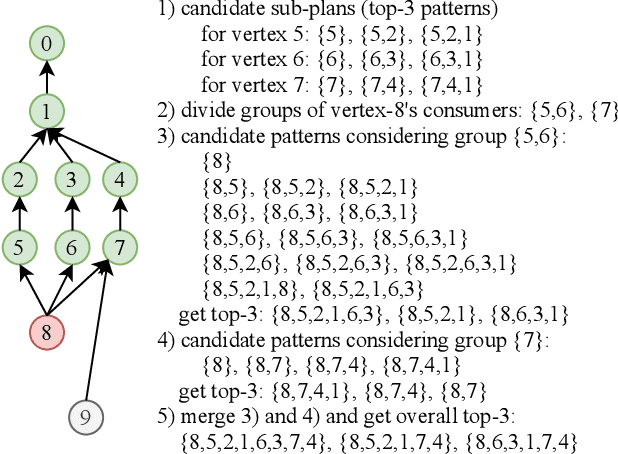
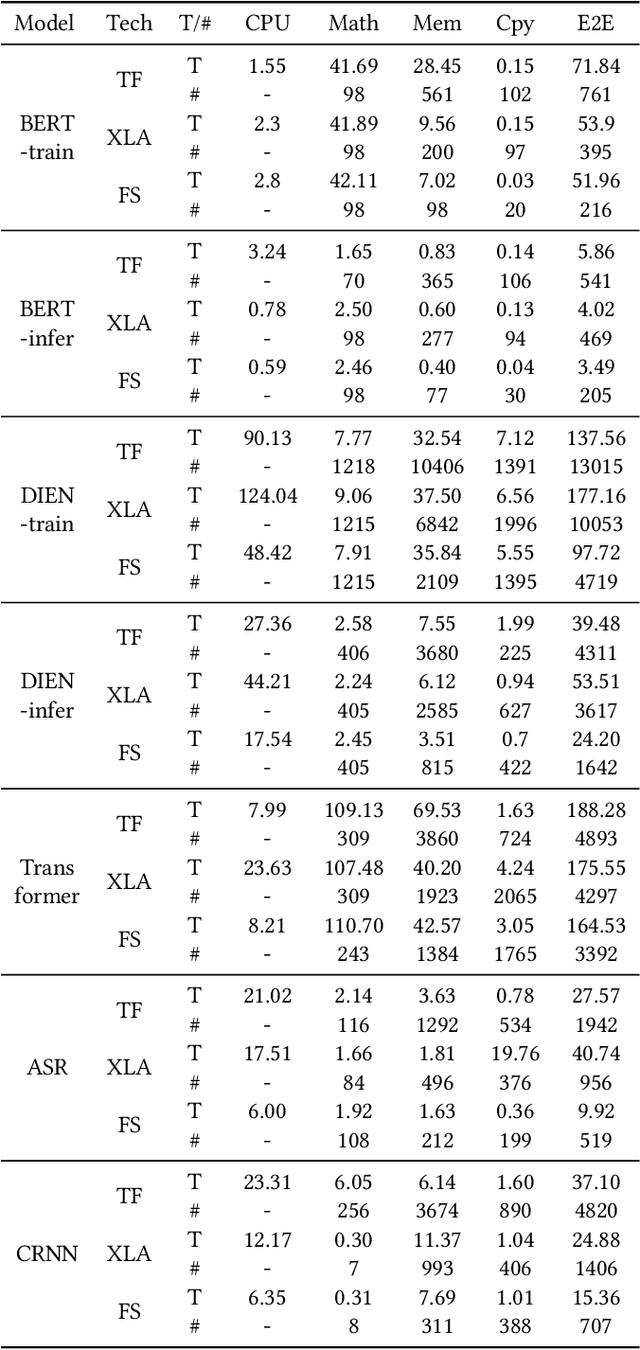
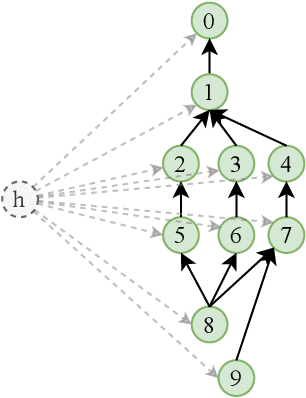
We show in this work that memory intensive computations can result in severe performance problems due to off-chip memory access and CPU-GPU context switch overheads in a wide range of deep learning models. For this problem, current just-in-time kernel fusion and code generation techniques have limitations, such as kernel schedule incompatibilities and rough fusion plan exploration strategies. We propose FusionStitching, a Deep Learning compiler capable of fusing memory intensive operators, with varied data dependencies and non-homogeneous parallelism, into large GPU kernels to reduce global memory access and operation scheduling overhead automatically. FusionStitching explores large fusion spaces to decide optimal fusion plans with considerations of memory access costs, kernel calls and resource usage constraints. We thoroughly study the schemes to stitch operators together for complex scenarios. FusionStitching tunes the optimal stitching scheme just-in-time with a domain-specific cost model efficiently. Experimental results show that FusionStitching can reach up to 2.78x speedup compared to TensorFlow and current state-of-the-art. Besides these experimental results, we integrated our approach into a compiler product and deployed it onto a production cluster for AI workloads with thousands of GPUs. The system has been in operation for more than 4 months and saves 7,000 GPU hours on average for approximately 30,000 tasks per month.
Common equivalence and size after forgetting
Jun 19, 2020Forgetting variables from a propositional formula may increase its size. Introducing new variables is a way to shorten it. Both operations can be expressed in terms of common equivalence, a weakened version of equivalence. In turn, common equivalence can be expressed in terms of forgetting. An algorithm for forgetting and checking common equivalence in polynomial space is given for the Horn case; it is polynomial-time for the subclass of single-head formulae. Minimizing after forgetting is polynomial-time if the formula is also acyclic and variables cannot be introduced, NP-hard when they can.
Efficient Initial Pose-graph Generation for Global SfM
Nov 26, 2020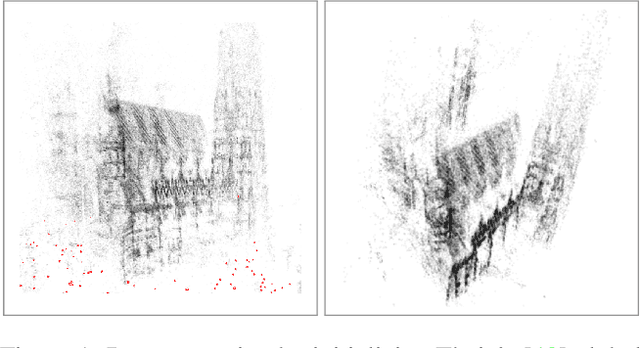
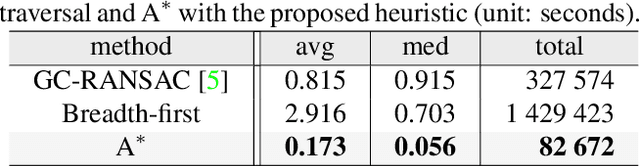
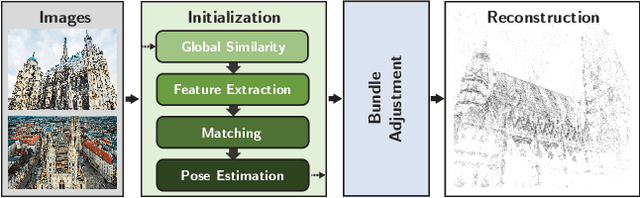
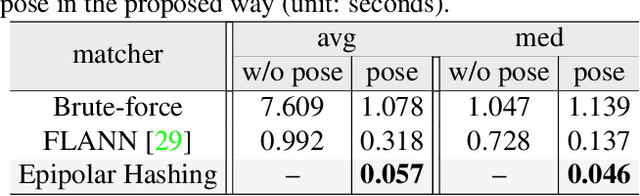
We propose ways to speed up the initial pose-graph generation for global Structure-from-Motion algorithms. To avoid forming tentative point correspondences by FLANN and geometric verification by RANSAC, which are the most time-consuming steps of the pose-graph creation, we propose two new methods - built on the fact that image pairs usually are matched consecutively. Thus, candidate relative poses can be recovered from paths in the partly-built pose-graph. We propose a heuristic for the A* traversal, considering global similarity of images and the quality of the pose-graph edges. Given a relative pose from a path, descriptor-based feature matching is made "light-weight" by exploiting the known epipolar geometry. To speed up PROSAC-based sampling when RANSAC is applied, we propose a third method to order the correspondences by their inlier probabilities from previous estimations. The algorithms are tested on 402130 image pairs from the 1DSfM dataset and they speed up the feature matching 17 times and pose estimation 5 times.
Data-Driven System Level Synthesis
Nov 20, 2020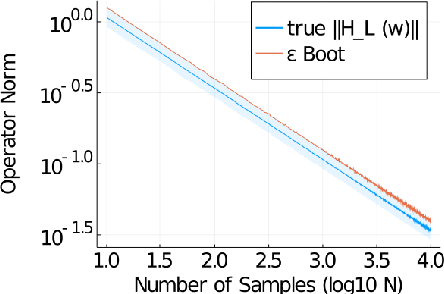
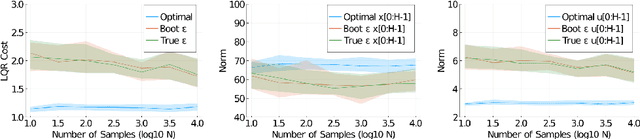
We establish data-driven versions of the System Level Synthesis (SLS) parameterization of stabilizing controllers for linear-time-invariant systems. Inspired by recent work in data-driven control that leverages tools from behavioral theory, we show that optimization problems over system-responses can be posed using only libraries of past system trajectories, without explicitly identifying a system model. We first consider the idealized setting of noise free trajectories, and show an exact equivalence between traditional and data-driven SLS. We then show that in the case of a system driven by process noise, tools from robust SLS can be used to characterize the effects of noise on closed-loop performance, and further draw on tools from matrix concentration to show that a simple trajectory averaging technique can be used to mitigate these effects. We end with numerical experiments showing the soundness of our methods.
RoCUS: Robot Controller Understanding via Sampling
Dec 25, 2020



As robots are deployed in complex situations, engineers and end users must develop a holistic understanding of their capabilities and behaviors. Existing research focuses mainly on factors related to task completion, such as success rate, completion time, or total energy consumption. Other factors like collision avoidance behavior, trajectory smoothness, and motion legibility are equally or more important for safe and trustworthy deployment. While methods exist to analyze these quality factors for individual trajectories or distributions of trajectories, these statistics may be insufficient to develop a mental model of the controller's behaviors, especially uncommon behaviors. We present RoCUS: a Bayesian sampling-based method to find situations that lead to trajectories which exhibit certain behaviors. By analyzing these situations and trajectories, we can gain important insights into the controller that are easily missed in standard task-completion evaluations. On a 2D navigation problem and a 7 degree-of-freedom (DoF) arm reaching problem, we analyze three controllers: a rapidly exploring random tree (RRT) planner, a dynamical system (DS) formulation, and a deep imitation learning (IL) or reinforcement learning (RL) model. We show how RoCUS can uncover insights to further our understanding about them beyond task-completion aspects. The code is available at https://github.com/YilunZhou/RoCUS.