 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time Lane Marker Detection Using Template Matching with RGB-D Camera
Jun 05, 2018
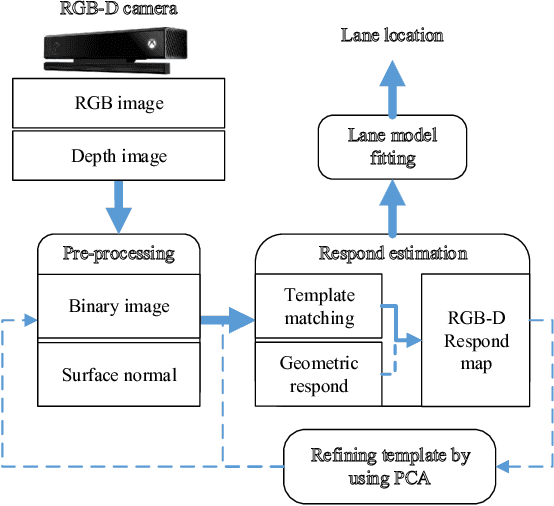



This paper addresses the problem of lane detection which is fundamental for self-driving vehicles. Our approach exploits both colour and depth information recorded by a single RGB-D camera to better deal with negative factors such as lighting conditions and lane-like objects. In the approach, colour and depth images are first converted to a half-binary format and a 2D matrix of 3D points. They are then used as the inputs of template matching and geometric feature extraction processes to form a response map so that its values represent the probability of pixels being lane markers. To further improve the results, the template and lane surfaces are finally refined by principal component analysis and lane model fitting techniques. A number of experiments have been conducted on both synthetic and real datasets. The result shows that the proposed approach can effectively eliminate unwanted noise to accurately detect lane markers in various scenarios. Moreover, the processing speed of 20 frames per second under hardware configuration of a popular laptop computer allows the proposed algorithm to be implemented for real-time autonomous driving applications.
Epidemic Dynamics via Wavelet Theory and Machine Learning, with Applications to Covid-19
Oct 27, 2020
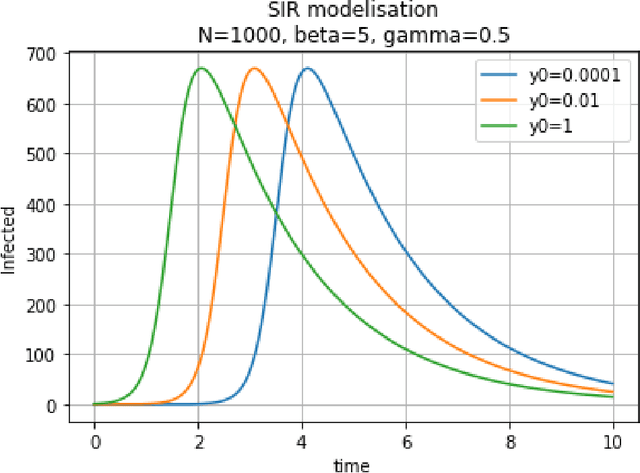
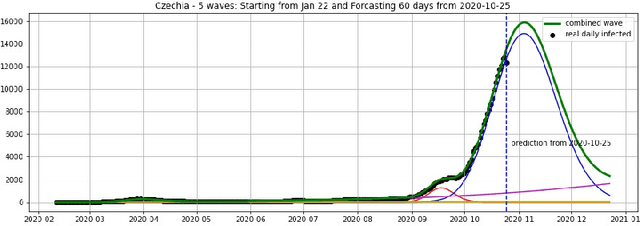
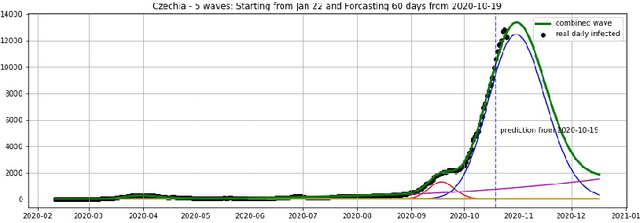
We introduce the concept of epidemic-fitted wavelets which comprise, in particular, as special cases the number $I(t)$ of infectious individuals at time $t$ in classical SIR models and their derivatives. We present a novel method for modelling epidemic dynamics by a model selection method using wavelet theory and, for its applications, machine learning based curve fitting techniques. Our universal models are functions that are finite linear combinations of epidemic-fitted wavelets. We apply our method by modelling and forecasting, based on the John Hopkins University dataset, the spread of the current Covid-19 (SARS-CoV-2) epidemic in France, Germany, Italy and the Czech Republic, as well as in the US federal states New York and Florida.
DAN -- An optimal Data Assimilation framework based on machine learning Recurrent Networks
Oct 19, 2020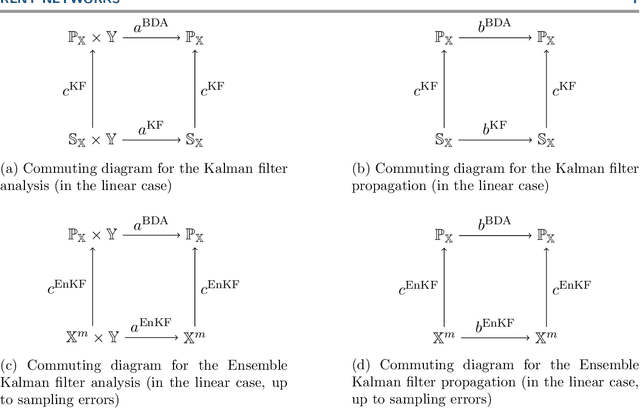

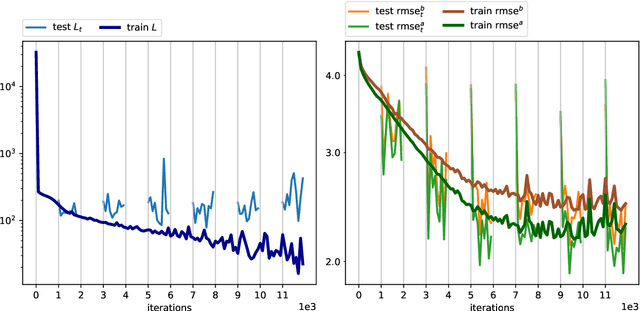
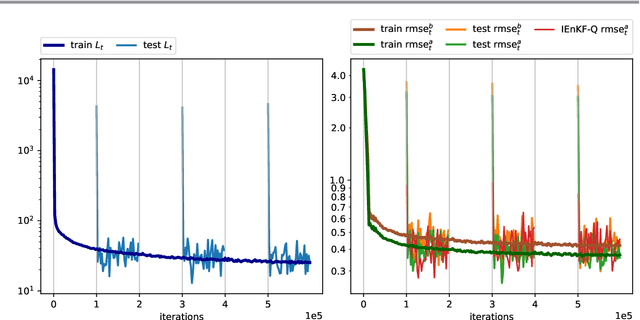
Data assimilation algorithms aim at forecasting the state of a dynamical system by combining a mathematical representation of the system with noisy observations thereof. We propose a fully data driven deep learning architecture generalizing recurrent Elman networks and data assimilation algorithms which provably reaches the same prediction goals as the latter. On numerical experiments based on the well-known Lorenz system and when suitably trained using snapshots of the system trajectory (i.e. batches of state trajectories) and observations, our architecture successfully reconstructs both the analysis and the propagation of probability density functions of the system state at a given time conditioned to past observations.
Poisoned classifiers are not only backdoored, they are fundamentally broken
Oct 18, 2020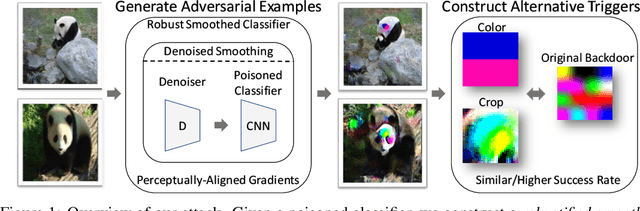
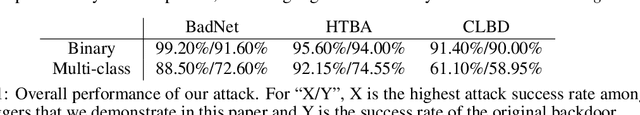
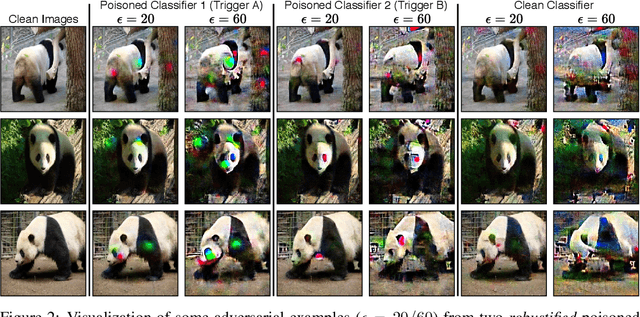

Under a commonly-studied "backdoor" poisoning attack against classification models, an attacker adds a small "trigger" to a subset of the training data, such that the presence of this trigger at test time causes the classifier to always predict some target class. It is often implicitly assumed that the poisoned classifier is vulnerable exclusively to the adversary who possesses the trigger. In this paper, we show empirically that this view of backdoored classifiers is fundamentally incorrect. We demonstrate that anyone with access to the classifier, even without access to any original training data or trigger, can construct several alternative triggers that are as effective or more so at eliciting the target class at test time. We construct these alternative triggers by first generating adversarial examples for a smoothed version of the classifier, created with a recent process called Denoised Smoothing, and then extracting colors or cropped portions of adversarial images. We demonstrate the effectiveness of our attack through extensive experiments on ImageNet and TrojAI datasets, including a user study which demonstrates that our method allows users to easily determine the existence of such backdoors in existing poisoned classifiers. Furthermore, we demonstrate that our alternative triggers can in fact look entirely different from the original trigger, highlighting that the backdoor actually learned by the classifier differs substantially from the trigger image itself. Thus, we argue that there is no such thing as a "secret" backdoor in poisoned classifiers: poisoning a classifier invites attacks not just by the party that possesses the trigger, but from anyone with access to the classifier. Code is available at https://github.com/locuslab/breaking-poisoned-classifier.
Smart Weather Forecasting Using Machine Learning:A Case Study in Tennessee
Aug 25, 2020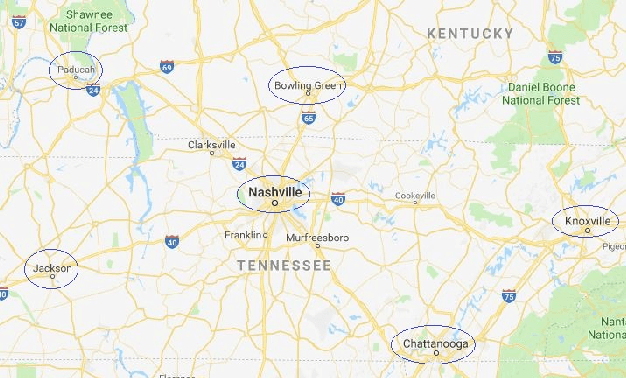
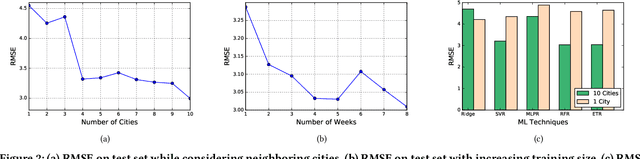
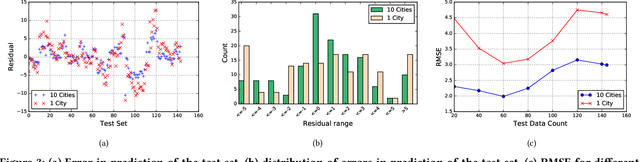
Traditionally, weather predictions are performed with the help of large complex models of physics, which utilize different atmospheric conditions over a long period of time. These conditions are often unstable because of perturbations of the weather system, causing the models to provide inaccurate forecasts. The models are generally run on hundreds of nodes in a large High Performance Computing (HPC) environment which consumes a large amount of energy. In this paper, we present a weather prediction technique that utilizes historical data from multiple weather stations to train simple machine learning models, which can provide usable forecasts about certain weather conditions for the near future within a very short period of time. The models can be run on much less resource intensive environments. The evaluation results show that the accuracy of the models is good enough to be used alongside the current state-of-the-art techniques. Furthermore, we show that it is beneficial to leverage the weather station data from multiple neighboring areas over the data of only the area for which weather forecasting is being performed.
Revisiting Mahalanobis Distance for Transformer-Based Out-of-Domain Detection
Jan 11, 2021Real-life applications, heavily relying on machine learning, such as dialog systems, demand out-of-domain detection methods. Intent classification models should be equipped with a mechanism to distinguish seen intents from unseen ones so that the dialog agent is capable of rejecting the latter and avoiding undesired behavior. However, despite increasing attention paid to the task, the best practices for out-of-domain intent detection have not yet been fully established. This paper conducts a thorough comparison of out-of-domain intent detection methods. We prioritize the methods, not requiring access to out-of-domain data during training, gathering of which is extremely time- and labor-consuming due to lexical and stylistic variation of user utterances. We evaluate multiple contextual encoders and methods, proven to be efficient, on three standard datasets for intent classification, expanded with out-of-domain utterances. Our main findings show that fine-tuning Transformer-based encoders on in-domain data leads to superior results. Mahalanobis distance, together with utterance representations, derived from Transformer-based encoders, outperforms other methods by a wide margin and establishes new state-of-the-art results for all datasets. The broader analysis shows that the reason for success lies in the fact that the fine-tuned Transformer is capable of constructing homogeneous representations of in-domain utterances, revealing geometrical disparity to out of domain utterances. In turn, the Mahalanobis distance captures this disparity easily.
Worldsheet: Wrapping the World in a 3D Sheet for View Synthesis from a Single Image
Dec 17, 2020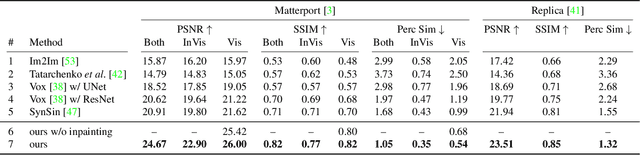
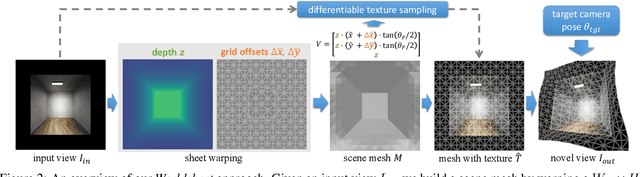
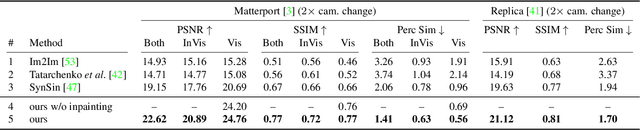

We present Worldsheet, a method for novel view synthesis using just a single RGB image as input. This is a challenging problem as it requires an understanding of the 3D geometry of the scene as well as texture mapping to generate both visible and occluded regions from new view-points. Our main insight is that simply shrink-wrapping a planar mesh sheet onto the input image, consistent with the learned intermediate depth, captures underlying geometry sufficient enough to generate photorealistic unseen views with arbitrarily large view-point changes. To operationalize this, we propose a novel differentiable texture sampler that allows our wrapped mesh sheet to be textured; which is then transformed into a target image via differentiable rendering. Our approach is category-agnostic, end-to-end trainable without using any 3D supervision and requires a single image at test time. Worldsheet consistently outperforms prior state-of-the-art methods on single-image view synthesis across several datasets. Furthermore, this simple idea captures novel views surprisingly well on a wide range of high resolution in-the-wild images in converting them into a navigable 3D pop-up. Video results and code at https://worldsheet.github.io
Balance-Oriented Focal Loss with Linear Scheduling for Anchor Free Object Detection
Dec 26, 2020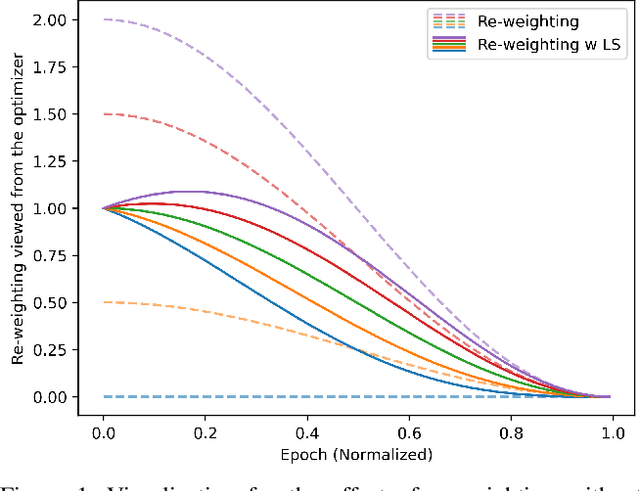
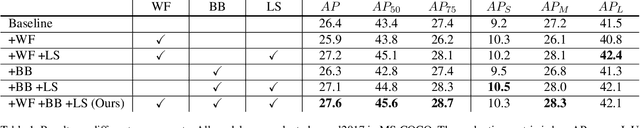
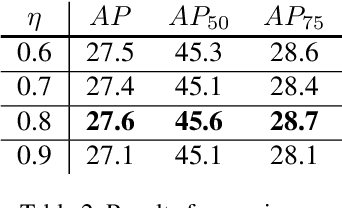
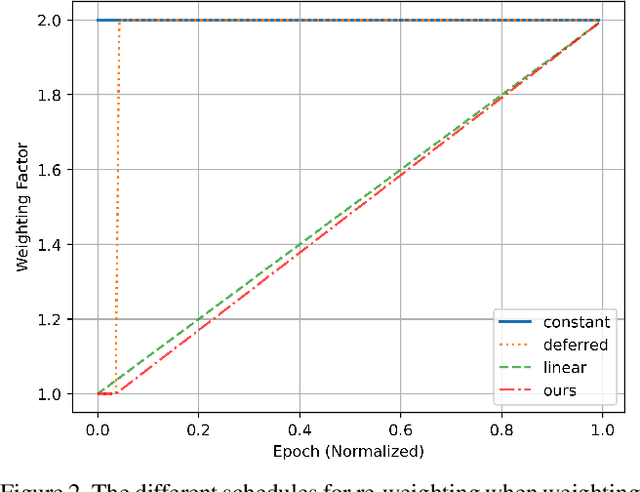
Most existing object detectors suffer from class imbalance problems that hinder balanced performance. In particular, anchor free object detectors have to solve the background imbalance problem due to detection in a per-pixel prediction fashion as well as foreground imbalance problem simultaneously. In this work, we propose Balance-oriented focal loss that can induce balanced learning by considering both background and foreground balance comprehensively. This work aims to address imbalance problem in the situation of using a general unbalanced data of non-extreme distribution not including few shot and the focal loss for anchor free object detector. We use a batch-wise alpha-balanced variant of the focal loss to deal with this imbalance problem elaborately. It is a simple and practical solution using only re-weighting for general unbalanced data. It does require neither additional learning cost nor structural change during inference and grouping classes is also unnecessary. Through extensive experiments, we show the performance improvement for each component and analyze the effect of linear scheduling when using re-weighting for the loss. By improving the focal loss in terms of balancing foreground classes, our method achieves AP gains of +1.2 in MS-COCO for the anchor free real-time detector.
Predicting Shifting Individuals Using Text Mining and Graph Machine Learning on Twitter
Aug 24, 2020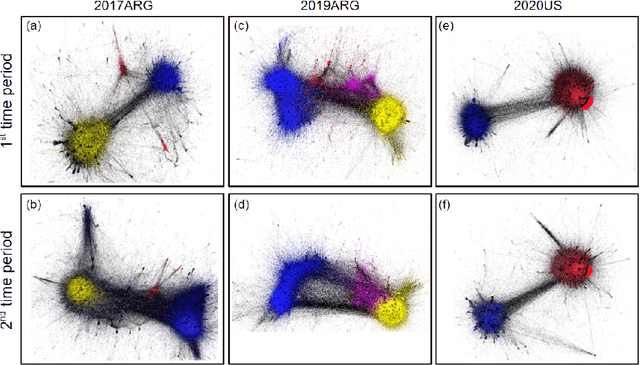
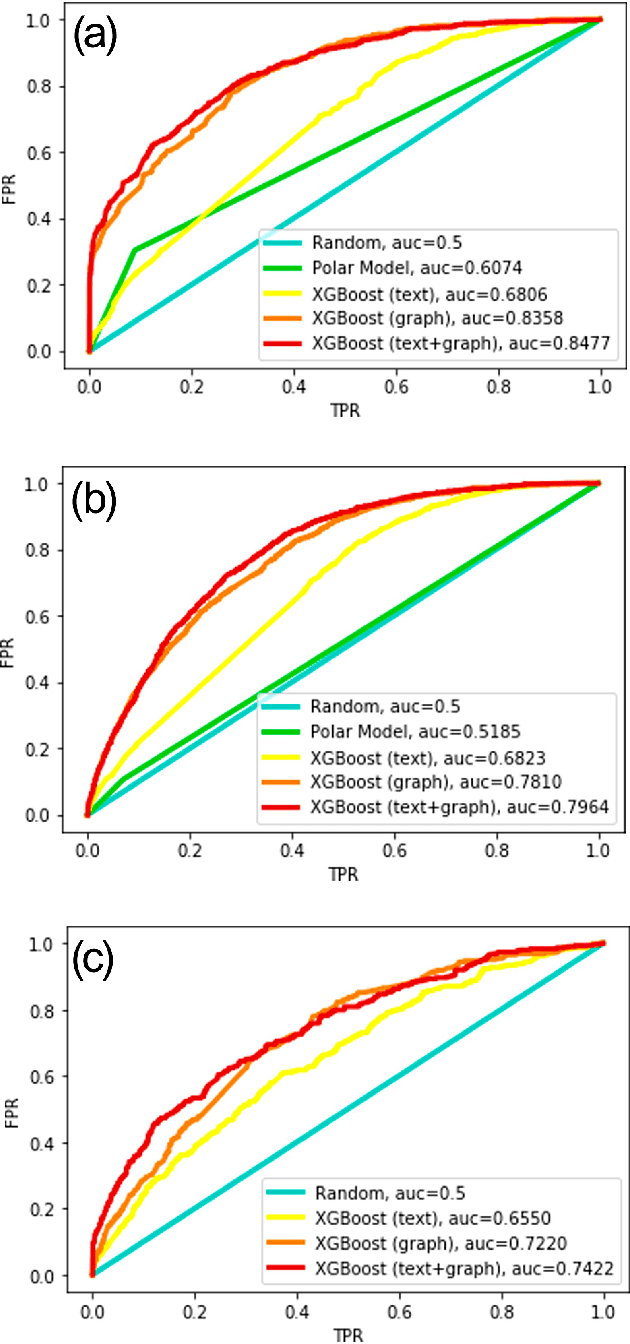
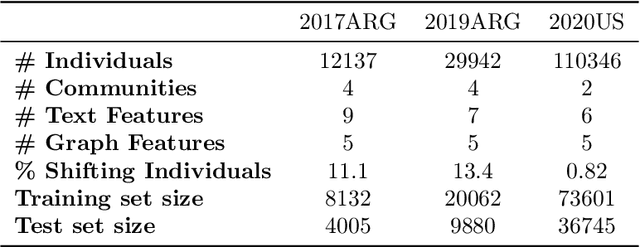
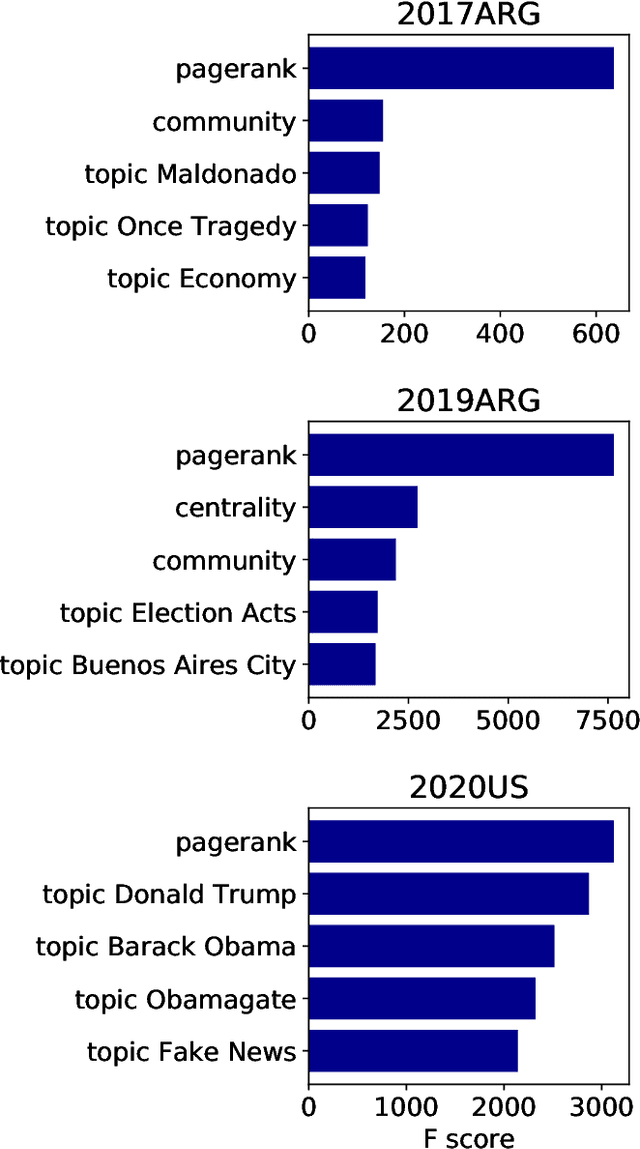
The formation of majorities in public discussions often depends on individuals who shift their opinion over time. The detection and characterization of these type of individuals is therefore extremely important for political analysis of social networks. In this paper, we study changes in individual's affiliations on Twitter using natural language processing techniques and graph machine learning algorithms. In particular, we collected 9 million Twitter messages from 1.5 million users and constructed the retweet networks. We identified communities with explicit political orientation and topics of discussion associated to them which provide the topological representation of the political map on Twitter in the analyzed periods. With that data, we present a machine learning framework for social media users classification which efficiently detects "shifting users" (i.e. users that may change their affiliation over time). Moreover, this machine learning framework allows us to identify not only which topics are more persuasive (using low dimensional topic embedding), but also which individuals are more likely to change their affiliation given their topological properties in a Twitter graph.
Computational Separation Between Convolutional and Fully-Connected Networks
Oct 03, 2020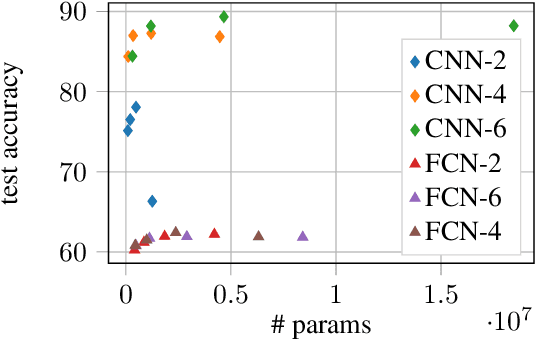

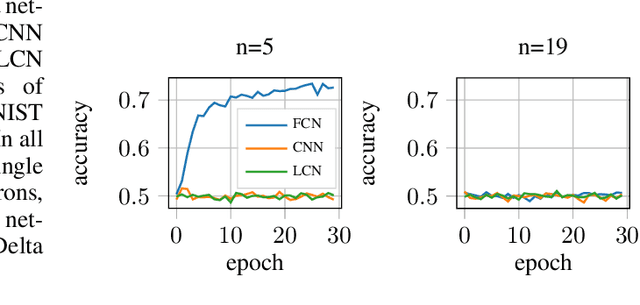
Convolutional neural networks (CNN) exhibit unmatched performance in a multitude of computer vision tasks. However, the advantage of using convolutional networks over fully-connected networks is not understood from a theoretical perspective. In this work, we show how convolutional networks can leverage locality in the data, and thus achieve a computational advantage over fully-connected networks. Specifically, we show a class of problems that can be efficiently solved using convolutional networks trained with gradient-descent, but at the same time is hard to learn using a polynomial-size fully-connected network.