 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adaptive Contention Window Design using Deep Q-learning
Nov 18, 2020
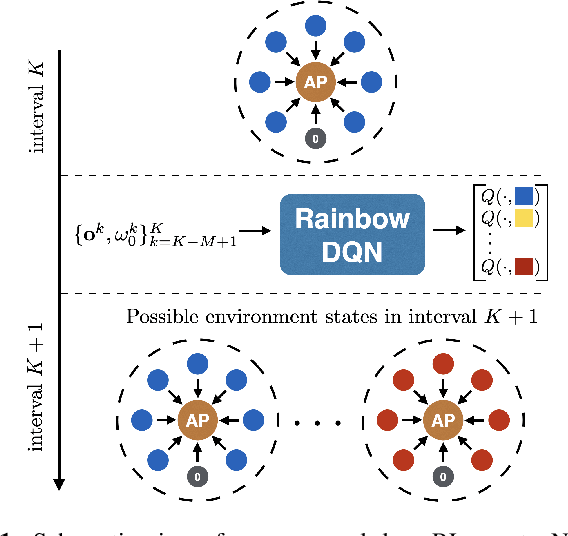
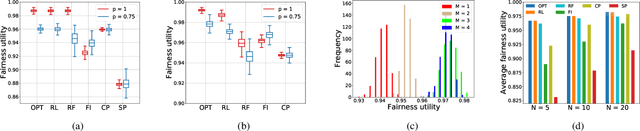
We study the problem of adaptive contention window (CW) design for random-access wireless networks. More precisely, our goal is to design an intelligent node that can dynamically adapt its minimum CW (MCW) parameter to maximize a network-level utility knowing neither the MCWs of other nodes nor how these change over time. To achieve this goal, we adopt a reinforcement learning (RL) framework where we circumvent the lack of system knowledge with local channel observations and we reward actions that lead to high utilities. To efficiently learn these preferred actions, we follow a deep Q-learning approach, where the Q-value function is parametrized using a multi-layer perception. In particular, we implement a rainbow agent, which incorporates several empirical improvements over the basic deep Q-network. Numerical experiments based on the NS3 simulator reveal that the proposed RL agent performs close to optimal and markedly improves upon existing learning and non-learning based alternatives.
Contraction Clustering (RASTER): A Very Fast Big Data Algorithm for Sequential and Parallel Density-Based Clustering in Linear Time, Constant Memory, and a Single Pass
Jul 08, 2019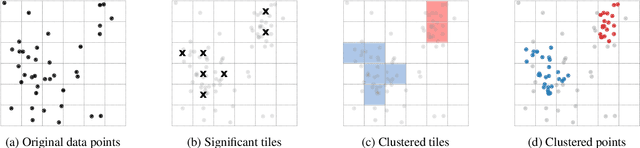
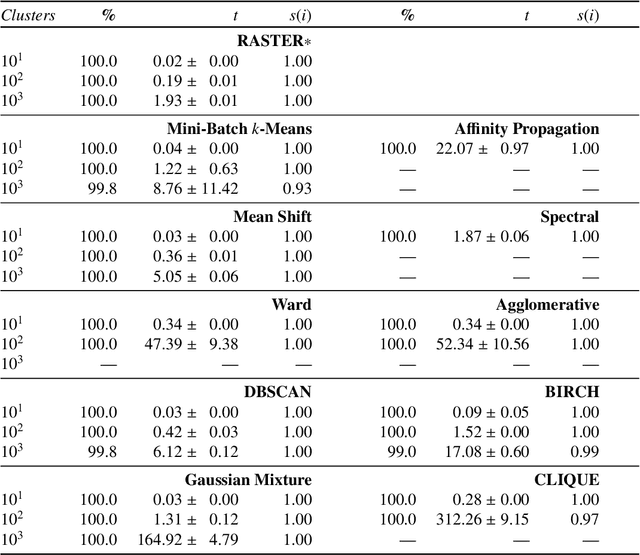
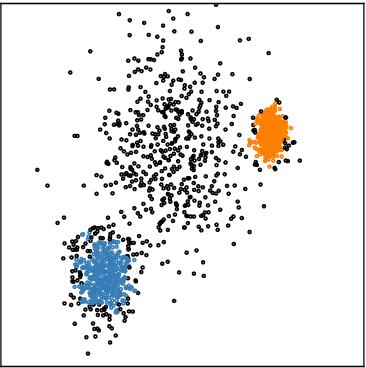
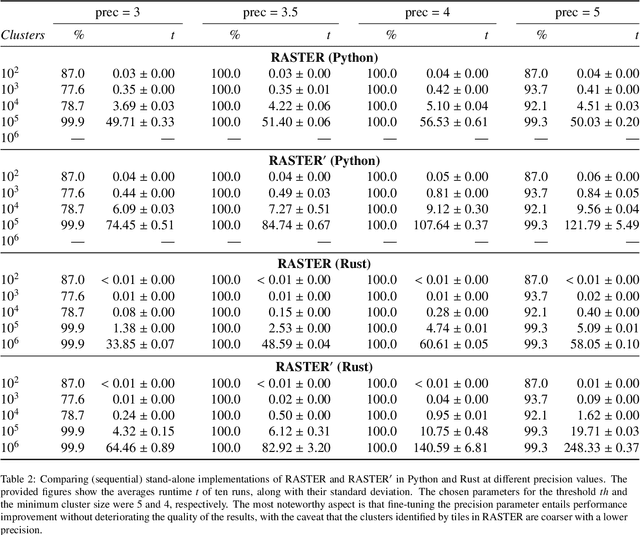
Clustering is an essential data mining tool for analyzing and grouping similar objects. In big data applications, however, many clustering algorithms are infeasible due to their high memory requirements and/or unfavorable runtime complexity. In contrast, Contraction Clustering (RASTER) is a single-pass algorithm for identifying density-based clusters with linear time complexity. Due to its favorable runtime and the fact that its memory requirements are constant, this algorithm is highly suitable for big data applications where the amount of data to be processed is huge. It consists of two steps: (1) a contraction step which projects objects onto tiles and (2) an agglomeration step which groups tiles into clusters. This algorithm is extremely fast in both sequential and parallel execution. In single-threaded execution on a contemporary workstation, an implementation in Rust processes a batch of 500 million points with 1 million clusters in less than 50 seconds. The speedup due to parallelization is significant, amounting to a factor of around 4 on an 8-core machine.
Boosting the Sliding Frank-Wolfe solver for 3D deconvolution
Sep 11, 2020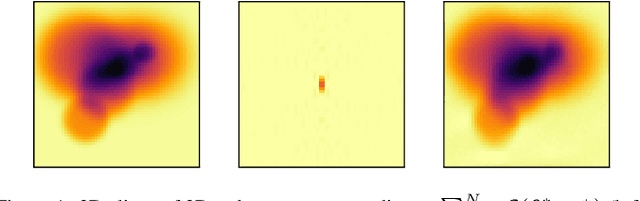
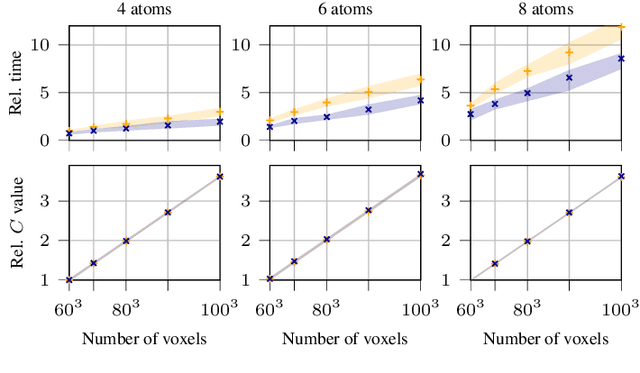
In the context of gridless sparse optimization, the Sliding Frank Wolfe algorithm recently introduced has shown interesting analytical and practical properties. Nevertheless, is application to large data, such as in the case of 3D deconvolution, is computationally heavy. In this paper, we investigate a strategy for leveraging this burden, in order to make this method more tractable for 3D deconvolution. We show that a boosted SFW can achieve the same results in a significantly reduced amount of time.
A Three-Stage Algorithm for the Large Scale Dynamic Vehicle Routing Problem with an Industry 4.0 Approach
Aug 15, 2020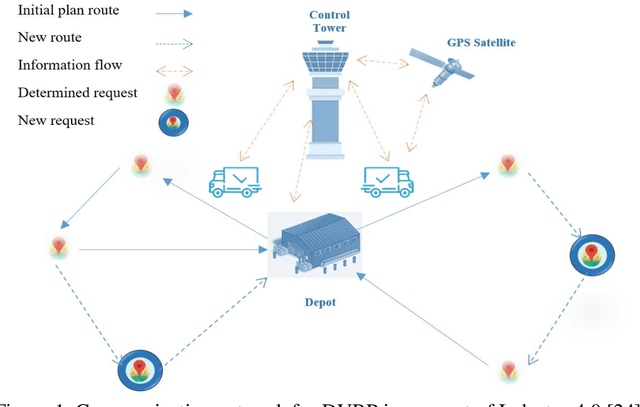

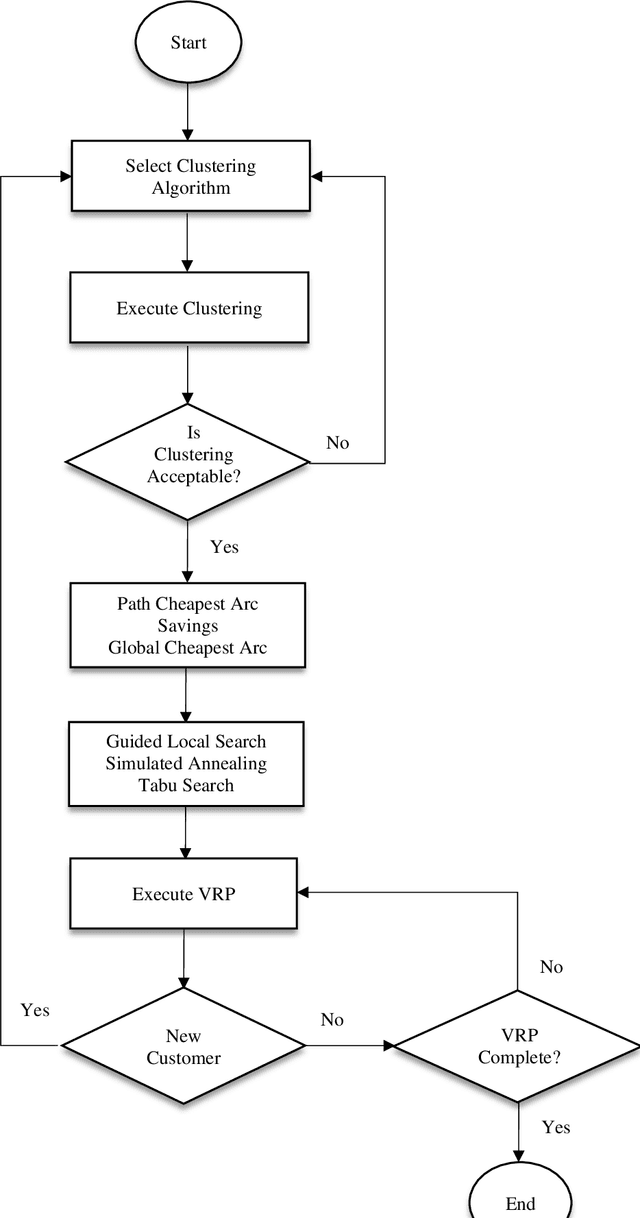
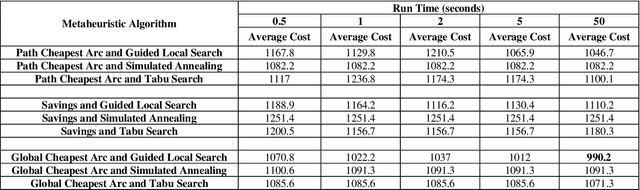
Industry 4.0 is a concept which helps companies to have a smart supply chain system when they are faced with a dynamic process. As Industry 4.0 focuses on mobility and real-time integration, it is a good framework for a Dynamic Vehicle Routing problem (DVRP). The main objective of this research is to solve the DVRP on a large-scale size. The aim of this study is to show that the delivery vehicles must serve customer demands from a common depot to have a minimum transit cost without exceeding the capacity constraint of each vehicle. In VRP, to reach an exact solution is quite difficult, and in large-size real world problems it is often impossible. Also, the computational time complexity of this type of problem grows exponentially. In order to find optimal answers for this problem in medium and large dimensions, using a heuristic approach is recommended as the best approach. A hierarchical approach consisting of three stages as cluster-first, route-construction second, route-improvement third is proposed. In the first stage, customers are clustered based on the number of vehicles with different clustering algorithms (i.e., K-mean, GMM, and BIRCH algorithms). In the second stage, the DVRP is solved using construction algorithms and in the third stage improvement algorithms are applied. The second stage is solved using construction algorithms (i.e. Savings algorithm, path cheapest arc algorithm, etc.). In the third stage, improvement algorithms such as Guided Local Search, Simulated Annealing and Tabu Search are applied. One of the main contributions of this paper is that the proposed approach can deal with large-size real world problems to decrease the computational time complexity. The results of this approach confirmed that the proposed methodology is applicable.
An Entropic Relevance Measure for Stochastic Conformance Checking in Process Mining
Aug 26, 2020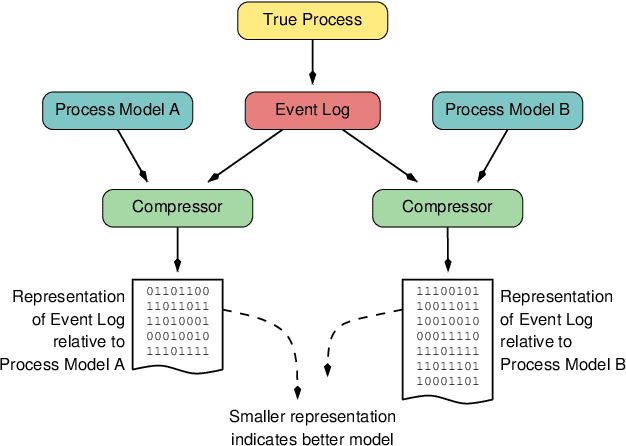
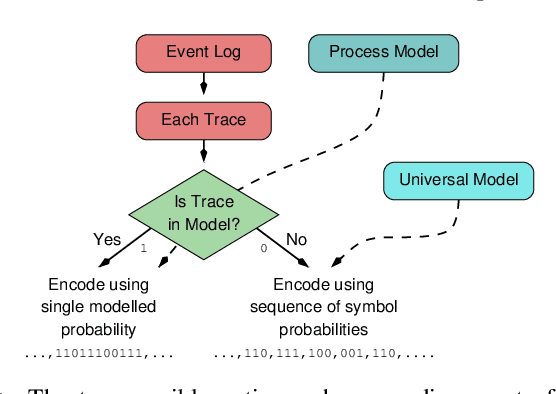
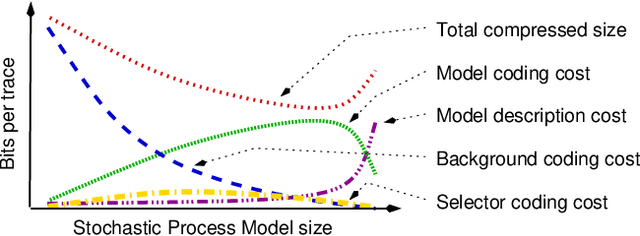
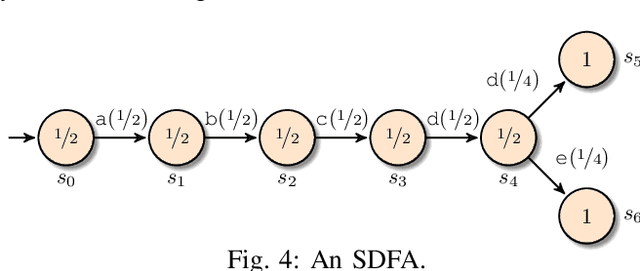
Given an event log as a collection of recorded real-world process traces, process mining aims to automatically construct a process model that is both simple and provides a useful explanation of the traces. Conformance checking techniques are then employed to characterize and quantify commonalities and discrepancies between the log's traces and the candidate models. Recent approaches to conformance checking acknowledge that the elements being compared are inherently stochastic - for example, some traces occur frequently and others infrequently - and seek to incorporate this knowledge in their analyses. Here we present an entropic relevance measure for stochastic conformance checking, computed as the average number of bits required to compress each of the log's traces, based on the structure and information about relative likelihoods provided by the model. The measure penalizes traces from the event log not captured by the model and traces described by the model but absent in the event log, thus addressing both precision and recall quality criteria at the same time. We further show that entropic relevance is computable in time linear in the size of the log, and provide evaluation outcomes that demonstrate the feasibility of using the new approach in industrial settings.
Towards High-Performance Solid-State-LiDAR-Inertial Odometry and Mapping
Oct 31, 2020
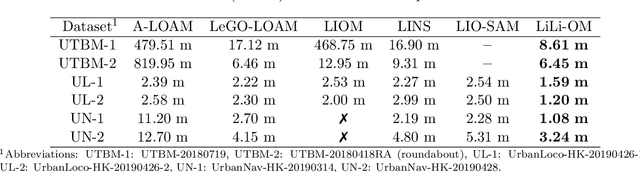
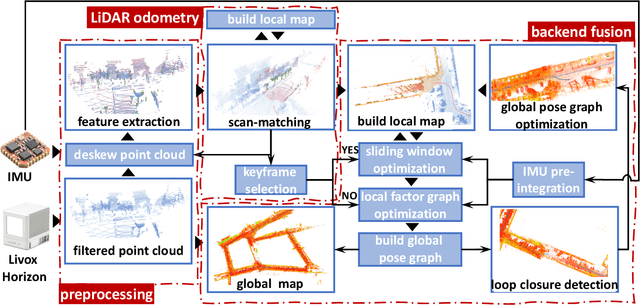

We present a novel tightly-coupled LiDAR-inertial odometry and mapping scheme for both solid-state and mechanical LiDARs. As frontend, a feature-based lightweight LiDAR odometry provides fast motion estimates for adaptive keyframe selection. As backend, a hierarchical keyframe-based sliding window optimization is performed through marginalization for directly fusing IMU and LiDAR measurements. For the Livox Horizon, a newly released solid-state LiDAR, a novel feature extraction method is proposed to handle its irregular scan pattern during preprocessing. LiLi-OM (Livox LiDAR-inertial odometry and mapping) is real-time capable and achieves superior accuracy over state-of-the-art systems for both LiDAR types on public data sets of mechanical LiDARs and in experiments using the Livox Horizon. Source code and recorded experimental data sets are available on Github.
SceneFormer: Indoor Scene Generation with Transformers
Dec 17, 2020


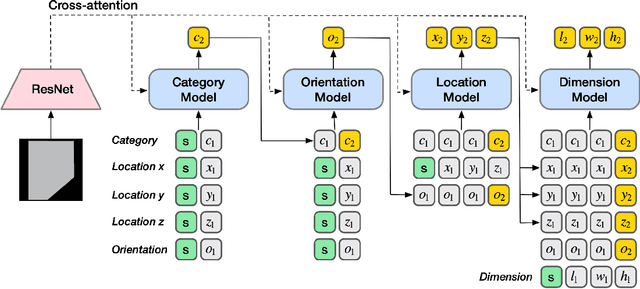
The task of indoor scene generation is to generate a sequence of objects, their locations and orientations conditioned on the shape and size of a room. Large scale indoor scene datasets allow us to extract patterns from user-designed indoor scenes and then generate new scenes based on these patterns. Existing methods rely on the 2D or 3D appearance of these scenes in addition to object positions, and make assumptions about the possible relations between objects. In contrast, we do not use any appearance information, and learn relations between objects using the self attention mechanism of transformers. We show that this leads to faster scene generation compared to existing methods with the same or better levels of realism. We build simple and effective generative models conditioned on the room shape, and on text descriptions of the room using only the cross-attention mechanism of transformers. We carried out a user study showing that our generated scenes are preferred over DeepSynth scenes 57.7% of the time for bedroom scenes, and 63.3% for living room scenes. In addition, we generate a scene in 1.48 seconds on average, 20% faster than the state of the art method Fast & Flexible, allowing interactive scene generation.
Online Stochastic Convex Optimization: Wasserstein Distance Variation
Jun 02, 2020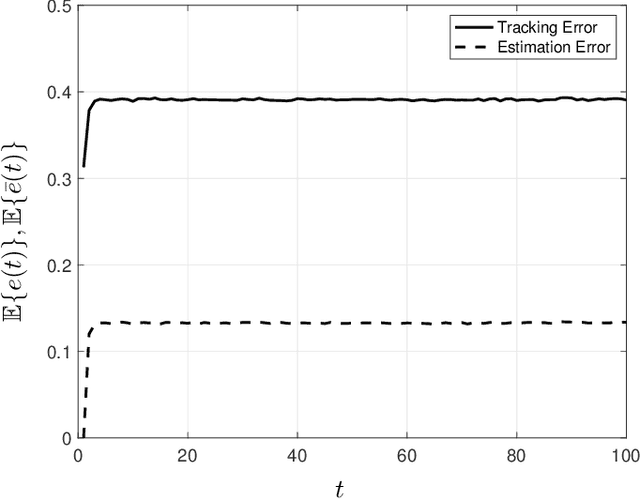
Distributionally-robust optimization is often studied for a fixed set of distributions rather than time-varying distributions that can drift significantly over time (which is, for instance, the case in finance and sociology due to underlying expansion of economy and evolution of demographics). This motivates understanding conditions on probability distributions, using the Wasserstein distance, that can be used to model time-varying environments. We can then use these conditions in conjunction with online stochastic optimization to adapt the decisions. We considers an online proximal-gradient method to track the minimizers of expectations of smooth convex functions parameterised by a random variable whose probability distributions continuously evolve over time at a rate similar to that of the rate at which the decision maker acts. We revisit the concepts of estimation and tracking error inspired by systems and control literature and provide bounds for them under strong convexity, Lipschitzness of the gradient, and bounds on the probability distribution drift characterised by the Wasserstein distance. Further, noting that computing projections for a general feasible sets might not be amenable to online implementation (due to computational constraints), we propose an exact penalty method. Doing so allows us to relax the uniform boundedness of the gradient and establish dynamic regret bounds for tracking and estimation error. We further introduce a constraint-tightening approach and relate the amount of tightening to the probability of satisfying the constraints.
Improving Document-Level Sentiment Analysis with User and Product Context
Nov 18, 2020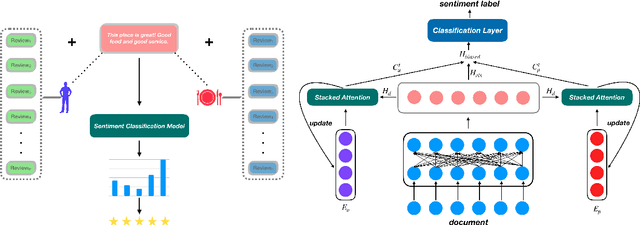

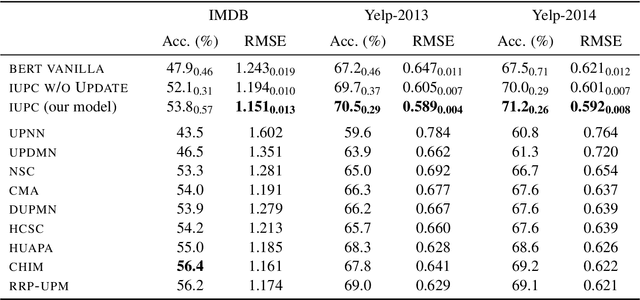

Past work that improves document-level sentiment analysis by encoding user and product information has been limited to considering only the text of the current review. We investigate incorporating additional review text available at the time of sentiment prediction that may prove meaningful for guiding prediction. Firstly, we incorporate all available historical review text belonging to the author of the review in question. Secondly, we investigate the inclusion of historical reviews associated with the current product (written by other users). We achieve this by explicitly storing representations of reviews written by the same user and about the same product and force the model to memorize all reviews for one particular user and product. Additionally, we drop the hierarchical architecture used in previous work to enable words in the text to directly attend to each other. Experiment results on IMDB, Yelp 2013 and Yelp 2014 datasets show improvement to state-of-the-art of more than 2 percentage points in the best case.
The Reflectron: Exploiting geometry for learning generalized linear models
Jun 15, 2020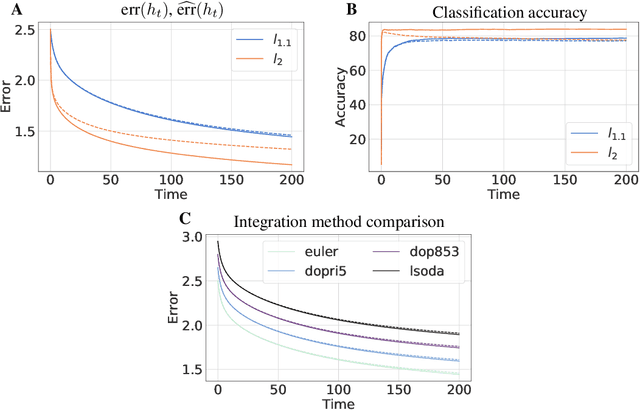
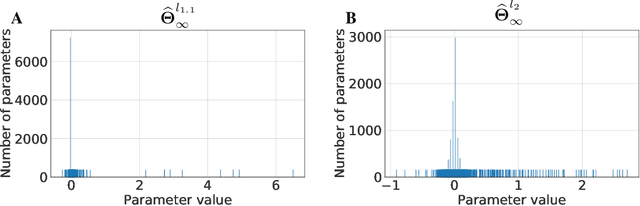
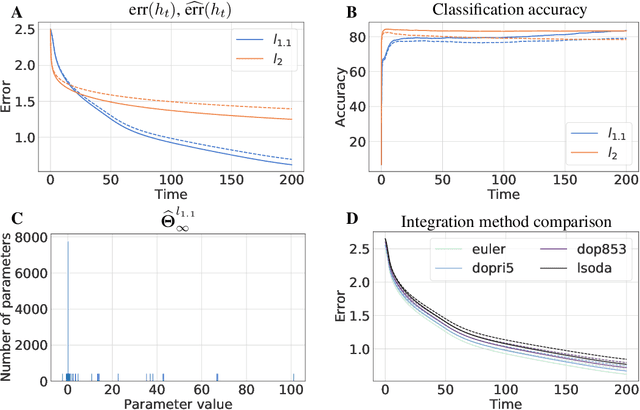
Generalized linear models (GLMs) extend linear regression by generating the dependent variables through a nonlinear function of a predictor in a Reproducing Kernel Hilbert Space. Despite nonconvexity of the underlying optimization problem, the GLM-tron algorithm of Kakade et al. (2011) provably learns GLMs with guarantees of computational and statistical efficiency. We present an extension of the GLM-tron to a mirror descent or natural gradient-like setting, which we call the Reflectron. The Reflectron enjoys the same statistical guarantees as the GLM-tron for any choice of the convex potential function $\psi$ used to define mirror descent. Central to our algorithm, $\psi$ can be chosen to implicitly regularize the learned model when there are multiple hypotheses consistent with the data. Our results extend to the case of multiple outputs with or without weight sharing. We perform our analysis in continuous-time, leading to simple and intuitive derivations, with discrete-time implementations obtained by discretization of the continuous-time dynamics. We supplement our theoretical analysis with simulations on real and synthetic datasets demonstrating the validity of our theoretical results.