 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MCI Detection using fMRI time series embeddings of Recurrence plots
Nov 30, 2023
The human brain can be conceptualized as a dynamical system. Utilizing resting state fMRI time series imaging, we can study the underlying dynamics at ear-marked Regions of Interest (ROIs) to understand structure or lack thereof. This differential behavior could be key to understanding the neurodegeneration and also to classify between healthy and Mild Cognitive Impairment (MCI) subjects. In this study, we consider 6 brain networks spanning over 160 ROIs derived from Dosenbach template, where each network consists of 25-30 ROIs. Recurrence plot, extensively used to understand evolution of time series, is employed. Representative time series at each ROI is converted to its corresponding recurrence plot visualization, which is subsequently condensed to low-dimensional feature embeddings through Autoencoders. The performance of the proposed method is shown on fMRI volumes of 100 subjects (balanced data), taken from publicly available ADNI dataset. Results obtained show peak classification accuracy of 93% among the 6 brain networks, mean accuracy of 89.3% thereby illustrating promise in the proposed approach.
Learning the 3D Fauna of the Web
Jan 04, 2024Learning 3D models of all animals on the Earth requires massively scaling up existing solutions. With this ultimate goal in mind, we develop 3D-Fauna, an approach that learns a pan-category deformable 3D animal model for more than 100 animal species jointly. One crucial bottleneck of modeling animals is the limited availability of training data, which we overcome by simply learning from 2D Internet images. We show that prior category-specific attempts fail to generalize to rare species with limited training images. We address this challenge by introducing the Semantic Bank of Skinned Models (SBSM), which automatically discovers a small set of base animal shapes by combining geometric inductive priors with semantic knowledge implicitly captured by an off-the-shelf self-supervised feature extractor. To train such a model, we also contribute a new large-scale dataset of diverse animal species. At inference time, given a single image of any quadruped animal, our model reconstructs an articulated 3D mesh in a feed-forward fashion within seconds.
Source-Free Online Domain Adaptive Semantic Segmentation of Satellite Images under Image Degradation
Jan 04, 2024Online adaptation to distribution shifts in satellite image segmentation stands as a crucial yet underexplored problem. In this paper, we address source-free and online domain adaptation, i.e., test-time adaptation (TTA), for satellite images, with the focus on mitigating distribution shifts caused by various forms of image degradation. Towards achieving this goal, we propose a novel TTA approach involving two effective strategies. First, we progressively estimate the global Batch Normalization (BN) statistics of the target distribution with incoming data stream. Leveraging these statistics during inference has the ability to effectively reduce domain gap. Furthermore, we enhance prediction quality by refining the predicted masks using global class centers. Both strategies employ dynamic momentum for fast and stable convergence. Notably, our method is backpropagation-free and hence fast and lightweight, making it highly suitable for on-the-fly adaptation to new domain. Through comprehensive experiments across various domain adaptation scenarios, we demonstrate the robust performance of our method.
Towards a Foundation Purchasing Model: Pretrained Generative Autoregression on Transaction Sequences
Jan 04, 2024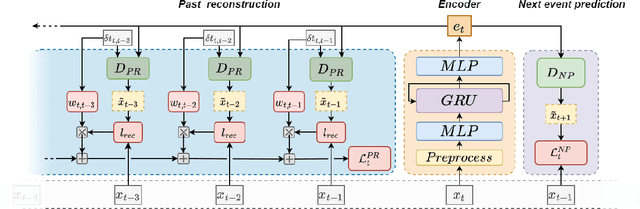
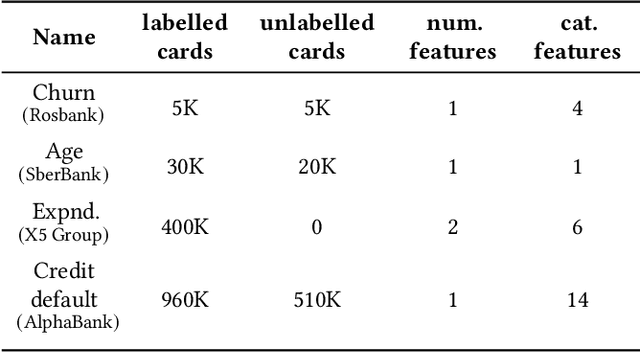
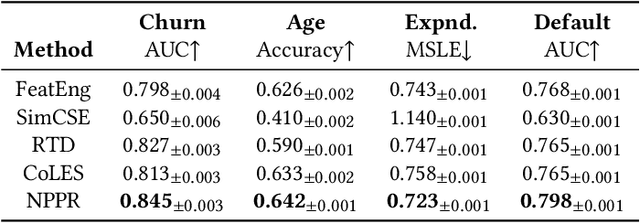
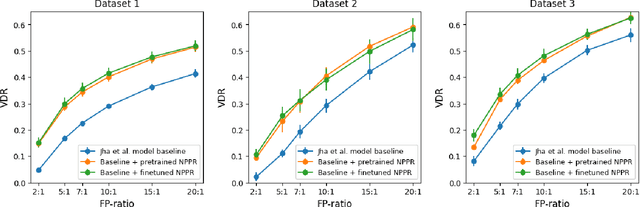
Machine learning models underpin many modern financial systems for use cases such as fraud detection and churn prediction. Most are based on supervised learning with hand-engineered features, which relies heavily on the availability of labelled data. Large self-supervised generative models have shown tremendous success in natural language processing and computer vision, yet so far they haven't been adapted to multivariate time series of financial transactions. In this paper, we present a generative pretraining method that can be used to obtain contextualised embeddings of financial transactions. Benchmarks on public datasets demonstrate that it outperforms state-of-the-art self-supervised methods on a range of downstream tasks. We additionally perform large-scale pretraining of an embedding model using a corpus of data from 180 issuing banks containing 5.1 billion transactions and apply it to the card fraud detection problem on hold-out datasets. The embedding model significantly improves value detection rate at high precision thresholds and transfers well to out-of-domain distributions.
R2Human: Real-Time 3D Human Appearance Rendering from a Single Image
Dec 10, 2023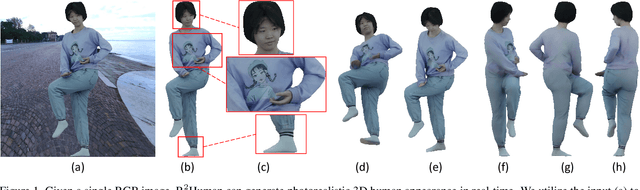
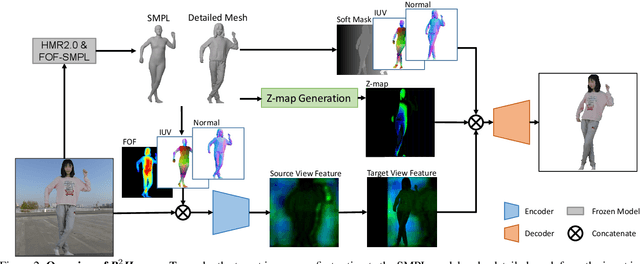
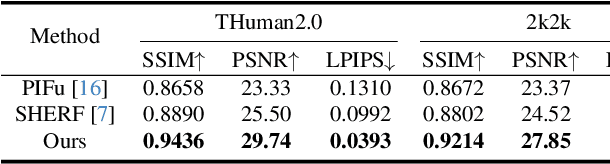
Reconstructing 3D human appearance from a single image is crucial for achieving holographic communication and immersive social experiences. However, this remains a challenge for existing methods, which typically rely on multi-camera setups or are limited to offline operations. In this paper, we propose R$^2$Human, the first approach for real-time inference and rendering of photorealistic 3D human appearance from a single image. The core of our approach is to combine the strengths of implicit texture fields and explicit neural rendering with our novel representation, namely Z-map. Based on this, we present an end-to-end network that performs high-fidelity color reconstruction of visible areas and provides reliable color inference for occluded regions. To further enhance the 3D perception ability of our network, we leverage the Fourier occupancy field to reconstruct a detailed 3D geometry, which serves as a prior for the texture field generation and provides a sampling surface in the rendering stage. Experiments show that our end-to-end method achieves state-of-the-art performance on both synthetic data and challenging real-world images and even outperforms many offline methods. The project page is available for research purposes at http://cic.tju.edu.cn/faculty/likun/projects/R2Human.
Coordinated Deep Neural Networks: A Versatile Edge Offloading Algorithm
Jan 01, 2024As artificial intelligence (AI) applications continue to expand, there is a growing need for deep neural network (DNN) models. Although DNN models deployed at the edge are promising to provide AI as a service with low latency, their cooperation is yet to be explored. In this paper, we consider the DNN service providers share their computing resources as well as their models' parameters and allow other DNNs to offload their computations without mirroring. We propose a novel algorithm called coordinated DNNs on edge (\textbf{CoDE}) that facilitates coordination among DNN services by creating multi-task DNNs out of individual models. CoDE aims to find the optimal path that results in the lowest possible cost, where the cost reflects the inference delay, model accuracy, and local computation workload. With CoDE, DNN models can make new paths for inference by using their own or other models' parameters. We then evaluate the performance of CoDE through numerical experiments. The results demonstrate a $75\%$ reduction in the local service computation workload while degrading the accuracy by only $2\%$ and having the same inference time in a balanced load condition. Under heavy load, CoDE can further decrease the inference time by $30\%$ while the accuracy is reduced by only $4\%$.
PLE-SLAM: A Visual-Inertial SLAM Based on Point-Line Features and Efficient IMU Initialization
Jan 02, 2024Visual-inertial SLAM is essential in various fields, such as AR/VR, uncrewed aerial vehicles, industrial robots, and autonomous driving. The fusion of a camera and inertial measurement unit (IMU) can make up for the shortcomings of a signal sensor, which significantly improves the accuracy and robustness of localization in challenging environments. Robust tracking and accurate inertial parameter estimation are the basis for the stable operation of the system. This article presents PLE-SLAM, an entirely precise and real-time visual-inertial SLAM algorithm based on point-line features and efficient IMU initialization. First, we introduce line features in a point-based visual-inertial SLAM system. We use parallel computing methods to extract features and compute descriptors to ensure real-time performance. Second, the proposed system estimates gyroscope bias with rotation pre-integration and point and line observations. Accelerometer bias and gravity direction are solved by an analytical method. After initialization, all inertial parameters are refined through maximum a posteriori (MAP) estimation. Moreover, we open a dynamic feature elimination thread to improve the adaptability to dynamic environments and use CNN, bag-of-words and GNN to detect loops and match features. Excellent wide baseline matching capability of DNN-based matching method and illumination robustness significantly improve loop detection recall and loop inter-frame pose estimation. The front-end and back-end are designed for hardware acceleration. The experiments are performed on public datasets, and the results show that the proposed system is one of the state-of-the-art methods in complex scenarios.
GD^2-NeRF: Generative Detail Compensation via GAN and Diffusion for One-shot Generalizable Neural Radiance Fields
Jan 02, 2024In this paper, we focus on the One-shot Novel View Synthesis (O-NVS) task which targets synthesizing photo-realistic novel views given only one reference image per scene. Previous One-shot Generalizable Neural Radiance Fields (OG-NeRF) methods solve this task in an inference-time finetuning-free manner, yet suffer the blurry issue due to the encoder-only architecture that highly relies on the limited reference image. On the other hand, recent diffusion-based image-to-3d methods show vivid plausible results via distilling pre-trained 2D diffusion models into a 3D representation, yet require tedious per-scene optimization. Targeting these issues, we propose the GD$^2$-NeRF, a Generative Detail compensation framework via GAN and Diffusion that is both inference-time finetuning-free and with vivid plausible details. In detail, following a coarse-to-fine strategy, GD$^2$-NeRF is mainly composed of a One-stage Parallel Pipeline (OPP) and a 3D-consistent Detail Enhancer (Diff3DE). At the coarse stage, OPP first efficiently inserts the GAN model into the existing OG-NeRF pipeline for primarily relieving the blurry issue with in-distribution priors captured from the training dataset, achieving a good balance between sharpness (LPIPS, FID) and fidelity (PSNR, SSIM). Then, at the fine stage, Diff3DE further leverages the pre-trained image diffusion models to complement rich out-distribution details while maintaining decent 3D consistency. Extensive experiments on both the synthetic and real-world datasets show that GD$^2$-NeRF noticeably improves the details while without per-scene finetuning.
A Low-Complexity Range Estimation with Adjusted Affine Frequency Division Multiplexing Waveform
Dec 29, 2023Affine frequency division multiplexing (AFDM) is a recently proposed communication waveform for time-varying channel scenarios. As a chirp-based multicarrier modulation technique it can not only satisfy the needs of multiple scenarios in future mobile communication networks but also achieve good performance in radar sensing by adjusting the built-in parameters, making it a promising air interface waveform in integrated sensing and communication (ISAC) applications. In this paper, we investigate an AFDM-based radar system and analyze the radar ambiguity function of AFDM with different built-in parameters, based on which we find an AFDM waveform with the specific parameter c2 owns the near-optimal time-domain ambiguity function. Then a low-complexity algorithm based on matched filtering for high-resolution target range estimation is proposed for this specific AFDM waveform. Through simulation and analysis, the specific AFDM waveform has near-optimal range estimation performance with the proposed low-complexity algorithm while having the same bit error rate (BER) performance as orthogonal time frequency space (OTFS) using simple linear minimum mean square error (LMMSE) equalizer.
VAE-IF: Deep feature extraction with averaging for unsupervised artifact detection in routine acquired ICU time-series
Dec 10, 2023Artifacts are a common problem in physiological time-series data collected from intensive care units (ICU) and other settings. They affect the quality and reliability of clinical research and patient care. Manual annotation of artifacts is costly and time-consuming, rendering it impractical. Automated methods are desired. Here, we propose a novel unsupervised approach to detect artifacts in clinical-standard minute-by-minute resolution ICU data without any prior labeling or signal-specific knowledge. Our approach combines a variational autoencoder (VAE) and an isolation forest (iForest) model to learn features and identify anomalies in different types of vital signs, such as blood pressure, heart rate, and intracranial pressure. We evaluate our approach on a real-world ICU dataset and compare it with supervised models based on long short-term memory (LSTM) and XGBoost. We show that our approach achieves comparable sensitivity and generalizes well to an external dataset. We also visualize the latent space learned by the VAE and demonstrate its ability to disentangle clean and noisy samples. Our approach offers a promising solution for cleaning ICU data in clinical research and practice without the need for any labels whatsoever.