 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Average Cost Optimal Control of Stochastic Systems Using Reinforcement Learning
Oct 13, 2020

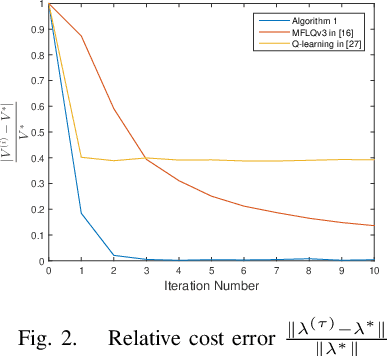
This paper addresses the average cost minimization problem for discrete-time systems with multiplicative and additive noises via reinforcement learning. By using Q-function, we propose an online learning scheme to estimate the kernel matrix of Q-function and to update the control gain using the data along the system trajectories. The obtained control gain and kernel matrix are proved to converge to the optimal ones. To implement the proposed learning scheme, an online model-free reinforcement learning algorithm is given, where recursive least squares method is used to estimate the kernel matrix of Q-function. A numerical example is presented to illustrate the proposed approach.
Autoencoding Neural Networks as Musical Audio Synthesizers
Apr 27, 2020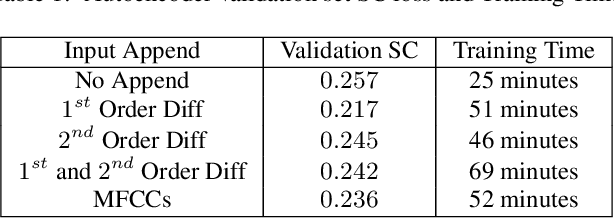
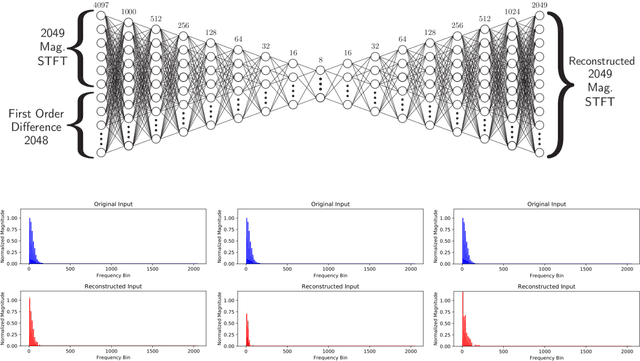
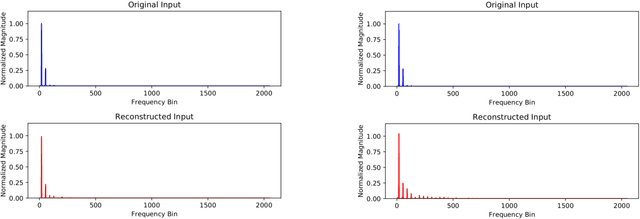
A method for musical audio synthesis using autoencoding neural networks is proposed. The autoencoder is trained to compress and reconstruct magnitude short-time Fourier transform frames. The autoencoder produces a spectrogram by activating its smallest hidden layer, and a phase response is calculated using real-time phase gradient heap integration. Taking an inverse short-time Fourier transform produces the audio signal. Our algorithm is light-weight when compared to current state-of-the-art audio-producing machine learning algorithms. We outline our design process, produce metrics, and detail an open-source Python implementation of our model.
Control of Stochastic Quantum Dynamics with Differentiable Programming
Jan 04, 2021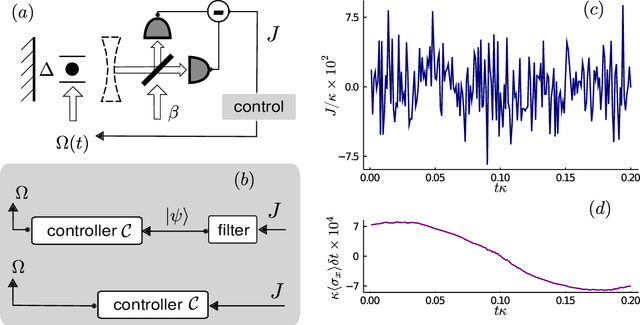
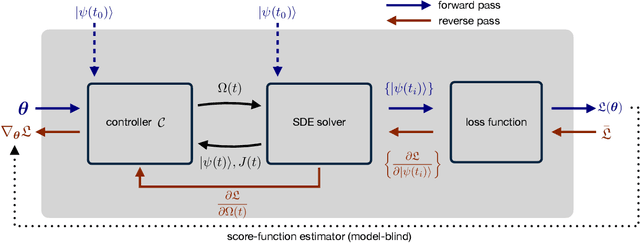
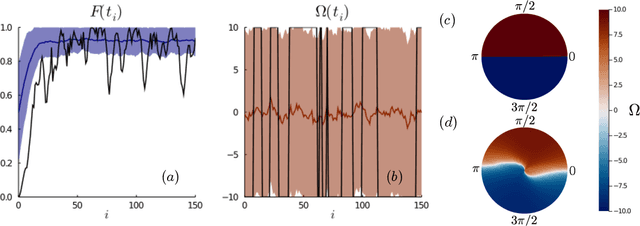
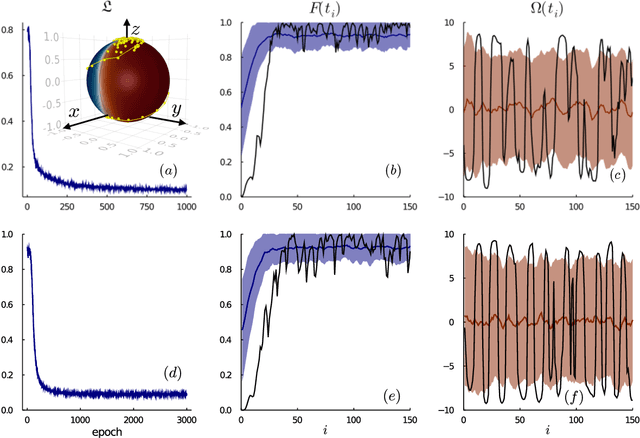
Controlling stochastic dynamics of a quantum system is an indispensable task in fields such as quantum information processing and metrology. Yet, there is no general ready-made approach to design efficient control strategies. Here, we propose a framework for the automated design of control schemes based on differentiable programming ($\partial \mathrm{P}$). We apply this approach to state preparation and stabilization of a qubit subjected to homodyne detection. To this end, we formulate the control task as an optimization problem where the loss function quantifies the distance from the target state and we employ neural networks (NNs) as controllers. The system's time evolution is governed by a stochastic differential equation (SDE). To implement efficient training, we backpropagate the gradient information from the loss function through the SDE solver using adjoint sensitivity methods. As a first example, we feed the quantum state to the controller and focus on different methods to obtain gradients. As a second example, we directly feed the homodyne detection signal to the controller. The instantaneous value of the homodyne current contains only very limited information on the actual state of the system, covered in unavoidable photon-number fluctuations. Despite the resulting poor signal-to-noise ratio, we can train our controller to prepare and stabilize the qubit to a target state with a mean fidelity around 85%. We also compare the solutions found by the NN to a hand-crafted control strategy.
Asset Price Forecasting using Recurrent Neural Networks
Oct 19, 2020
This thesis serves three primary purposes, first of which is to forecast two stocks, i.e. Goldman Sachs (GS) and General Electric (GE). In order to forecast stock prices, we used a long short-term memory (LSTM) model in which we inputted the prices of two other stocks that lie in rather close correlation with GS. Other models such as ARIMA were used as benchmark. Empirical results manifest the practical challenges when using LSTM for forecasting stocks. One of the main upheavals was a recurring lag which we called "forecasting lag". The second purpose is to develop a more general and objective perspective on the task of time series forecasting so that it could be applied to assist in an arbitrary that of forecasting by ANNs. Thus, attempts are made for distinguishing previous works by certain criteria (introduced by a review paper written by Ahmed Tealab) so as to summarise those including effective information. The summarised information is then unified and expressed through a common terminology that can be applied to different steps of a time series forecasting task. The last but not least purpose of this thesis is to elaborate on a mathematical framework on which ANNs are based. We are going to use the framework introduced in the book "Neural Networks in Mathematical Framework" by Anthony L. Caterini in which the structure of a generic neural network is introduced and the gradient descent algorithm (which incorporates backpropagation) is introduced in terms of their described framework. In the end, we use this framework for a specific architecture, which is recurrent neural networks on which we concentrated and our implementations are based. The book proves its theorems mostly for classification case. Instead, we proved theorems for regression case, which is the case of our problem.
AdnFM: An Attentive DenseNet based Factorization Machine for CTR Prediction
Dec 20, 2020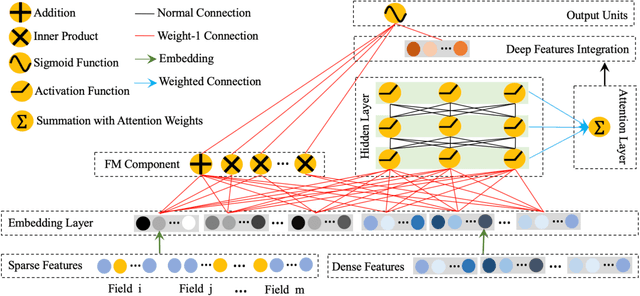
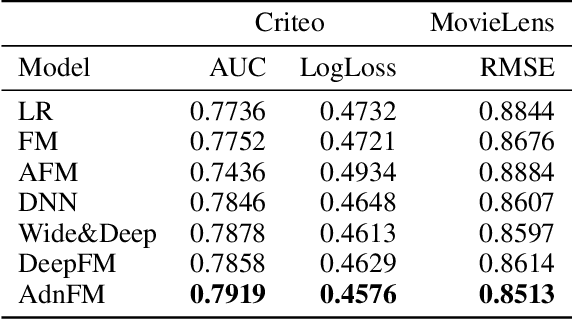
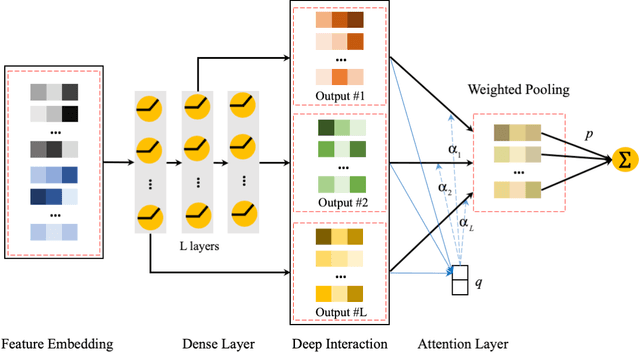
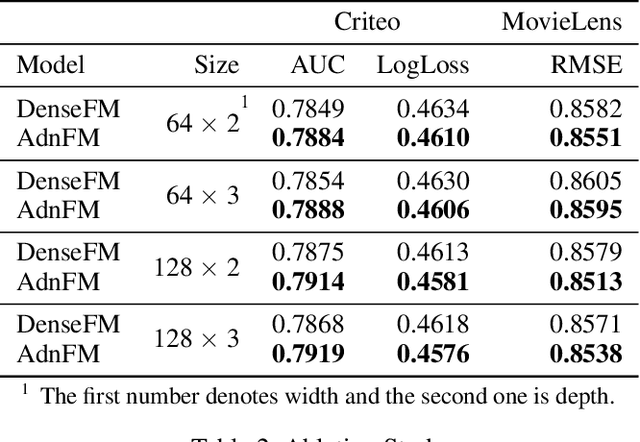
In this paper, we consider the Click-Through-Rate (CTR) prediction problem. Factorization Machines and their variants consider pair-wise feature interactions, but normally we won't do high-order feature interactions using FM due to high time complexity. Given the success of deep neural networks (DNNs) in many fields, researchers have proposed several DNN-based models to learn high-order feature interactions. Multi-layer perceptrons (MLP) have been widely employed to learn reliable mappings from feature embeddings to final logits. In this paper, we aim to explore more about these high-order features interactions. However, high-order feature interaction deserves more attention and further development. Inspired by the great achievements of Densely Connected Convolutional Networks (DenseNet) in computer vision, we propose a novel model called Attentive DenseNet based Factorization Machines (AdnFM). AdnFM can extract more comprehensive deep features by using all the hidden layers from a feed-forward neural network as implicit high-order features, then selects dominant features via an attention mechanism. Also, high-order interactions in the implicit way using DNNs are more cost-efficient than in the explicit way, for example in FM. Extensive experiments on two real-world datasets show that the proposed model can effectively improve the performance of CTR prediction.
Continuous Transfer Learning with Label-informed Distribution Alignment
Jun 05, 2020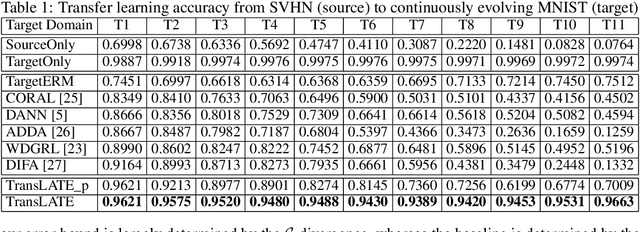
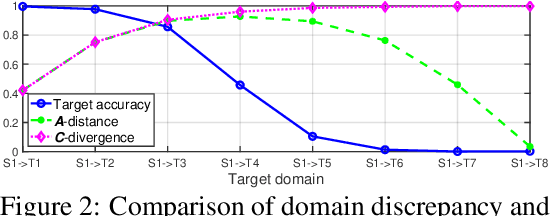
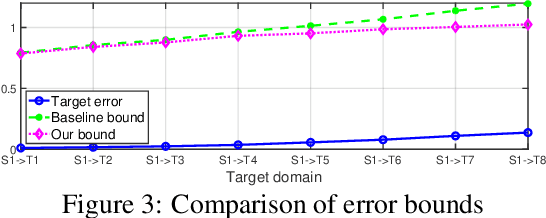
Transfer learning has been successfully applied across many high-impact applications. However, most existing work focuses on the static transfer learning setting, and very little is devoted to modeling the time evolving target domain, such as the online reviews for movies. To bridge this gap, in this paper, we study a novel continuous transfer learning setting with a time evolving target domain. One major challenge associated with continuous transfer learning is the potential occurrence of negative transfer as the target domain evolves over time. To address this challenge, we propose a novel label-informed C-divergence between the source and target domains in order to measure the shift of data distributions as well as to identify potential negative transfer. We then derive the error bound for the target domain using the empirical estimate of our proposed C-divergence. Furthermore, we propose a generic adversarial Variational Auto-encoder framework named TransLATE by minimizing the classification error and C-divergence of the target domain between consecutive time stamps in a latent feature space. In addition, we define a transfer signature for characterizing the negative transfer based on C-divergence, which indicates that larger C-divergence implies a higher probability of negative transfer in real scenarios. Extensive experiments on synthetic and real data sets demonstrate the effectiveness of our TransLATE framework.
Upgraded W-Net with Attention Gates and its Application in Unsupervised 3D Liver Segmentation
Nov 20, 2020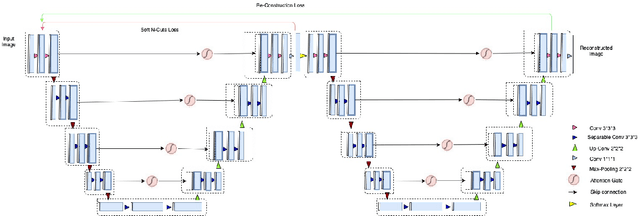

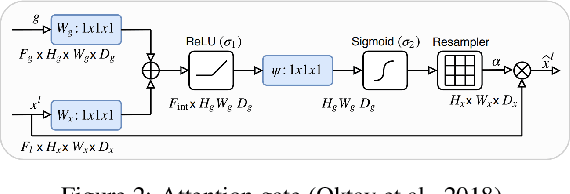

Segmentation of biomedical images can assist radiologists to make a better diagnosis and take decisions faster by helping in the detection of abnormalities, such as tumors. Manual or semi-automated segmentation, however, can be a time-consuming task. Most deep learning based automated segmentation methods are supervised and rely on manually segmented ground-truth. A possible solution for the problem would be an unsupervised deep learning based approach for automated segmentation, which this research work tries to address. We use a W-Net architecture and modified it, such that it can be applied to 3D volumes. In addition, to suppress noise in the segmentation we added attention gates to the skip connections. The loss for the segmentation output was calculated using soft N-Cuts and for the reconstruction output using SSIM. Conditional Random Fields were used as a post-processing step to fine-tune the results. The proposed method has shown promising results, with a dice coefficient of 0.88 for the liver segmentation compared against manual segmentation.
Stacked LSTM Based Deep Recurrent Neural Network with Kalman Smoothing for Blood Glucose Prediction
Jan 18, 2021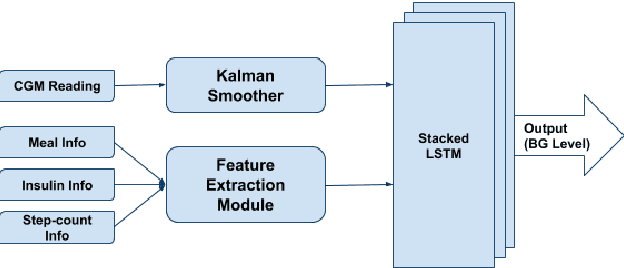
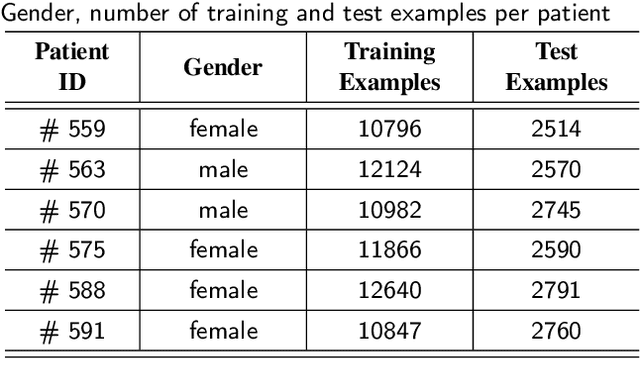
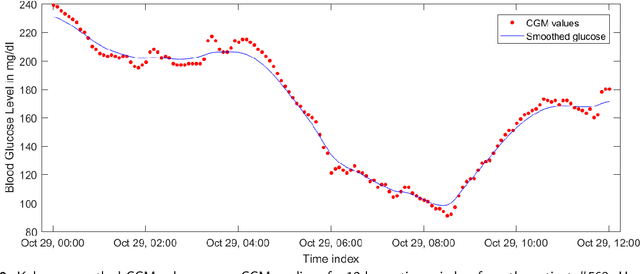
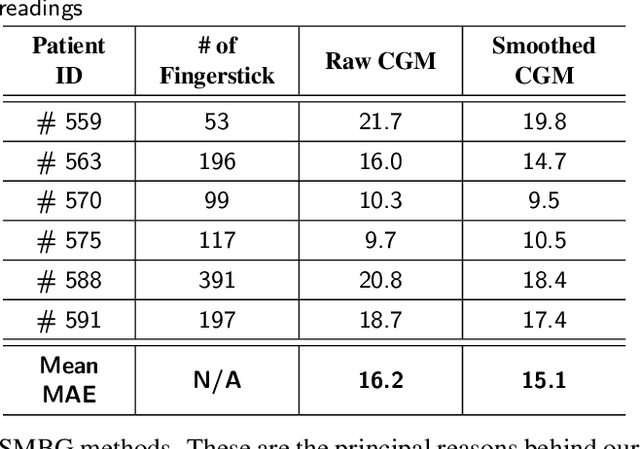
Blood glucose (BG) management is crucial for type-1 diabetes patients resulting in the necessity of reliable artificial pancreas or insulin infusion systems. In recent years, deep learning techniques have been utilized for a more accurate BG level prediction system. However, continuous glucose monitoring (CGM) readings are susceptible to sensor errors. As a result, inaccurate CGM readings would affect BG prediction and make it unreliable, even if the most optimal machine learning model is used. In this work, we propose a novel approach to predicting blood glucose level with a stacked Long short-term memory (LSTM) based deep recurrent neural network (RNN) model considering sensor fault. We use the Kalman smoothing technique for the correction of the inaccurate CGM readings due to sensor error. For the OhioT1DM dataset, containing eight weeks' data from six different patients, we achieve an average RMSE of 6.45 and 17.24 mg/dl for 30 minutes and 60 minutes of prediction horizon (PH), respectively. To the best of our knowledge, this is the leading average prediction accuracy for the ohioT1DM dataset. Different physiological information, e.g., Kalman smoothed CGM data, carbohydrates from the meal, bolus insulin, and cumulative step counts in a fixed time interval, are crafted to represent meaningful features used as input to the model. The goal of our approach is to lower the difference between the predicted CGM values and the fingerstick blood glucose readings - the ground truth. Our results indicate that the proposed approach is feasible for more reliable BG forecasting that might improve the performance of the artificial pancreas and insulin infusion system for T1D diabetes management.
Dynamic Bayesian Neural Networks
Apr 15, 2020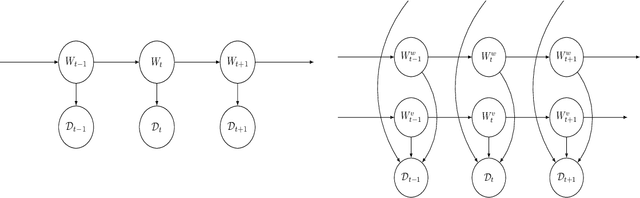

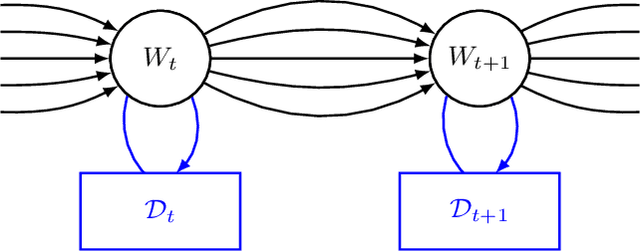
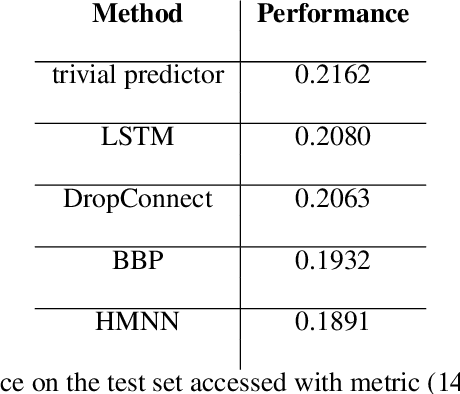
We define an evolving in time Bayesian neural network called a Hidden Markov neural network. The weights of the feed-forward neural network are modelled with the hidden states of a Hidden Markov model, the whose observed process is given by the available data. A filtering algorithm is used to learn a variational approximation to the evolving in time posterior over the weights. Training is pursued through a sequential version of Bayes by Backprop, which is enriched with a stronger regularization technique called variational DropConnect. The experiments are focused on streaming data and time series. On the one hand, we train on MNIST when only a portion of the dataset is available at a time. On the other hand, we perform frames prediction on a waving flag video.
Challenges of Context and Time in Reinforcement Learning: Introducing Space Fortress as a Benchmark
Sep 06, 2018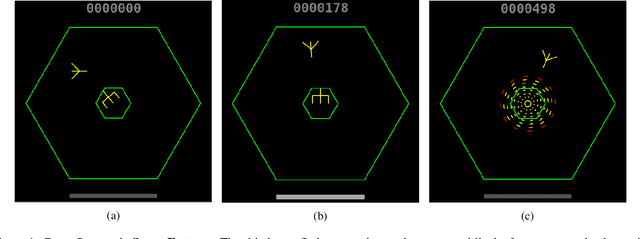

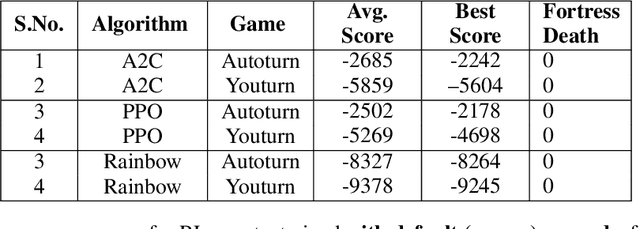
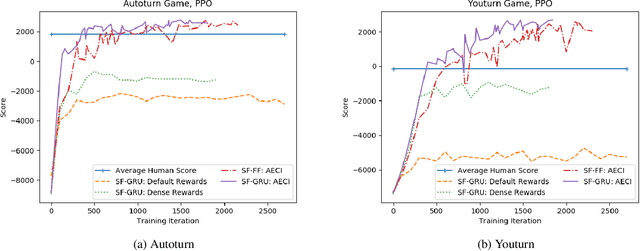
Research in deep reinforcement learning (RL) has coalesced around improving performance on benchmarks like the Arcade Learning Environment. However, these benchmarks conspicuously miss important characteristics like abrupt context-dependent shifts in strategy and temporal sensitivity that are often present in real-world domains. As a result, RL research has not focused on these challenges, resulting in algorithms which do not understand critical changes in context, and have little notion of real world time. To tackle this issue, this paper introduces the game of Space Fortress as a RL benchmark which incorporates these characteristics. We show that existing state-of-the-art RL algorithms are unable to learn to play the Space Fortress game. We then confirm that this poor performance is due to the RL algorithms' context insensitivity and reward sparsity. We also identify independent axes along which to vary context and temporal sensitivity, allowing Space Fortress to be used as a testbed for understanding both characteristics in combination and also in isolation. We release Space Fortress as an open-source Gym environment.