 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Challenges of Context and Time in Reinforcement Learning: Introducing Space Fortress as a Benchmark
Sep 06, 2018
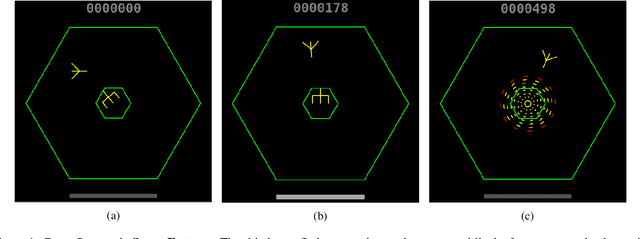

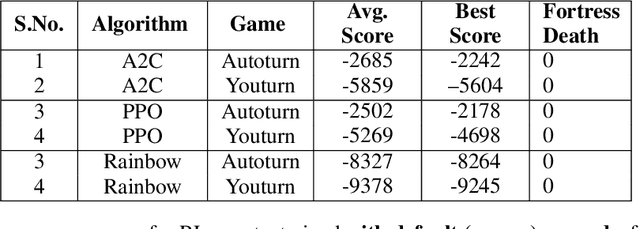
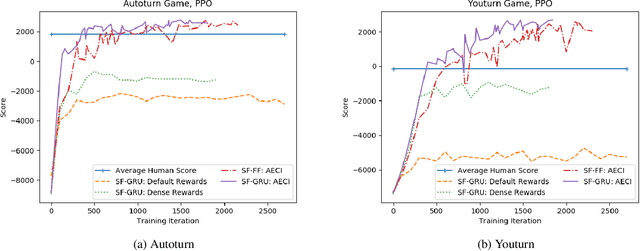
Research in deep reinforcement learning (RL) has coalesced around improving performance on benchmarks like the Arcade Learning Environment. However, these benchmarks conspicuously miss important characteristics like abrupt context-dependent shifts in strategy and temporal sensitivity that are often present in real-world domains. As a result, RL research has not focused on these challenges, resulting in algorithms which do not understand critical changes in context, and have little notion of real world time. To tackle this issue, this paper introduces the game of Space Fortress as a RL benchmark which incorporates these characteristics. We show that existing state-of-the-art RL algorithms are unable to learn to play the Space Fortress game. We then confirm that this poor performance is due to the RL algorithms' context insensitivity and reward sparsity. We also identify independent axes along which to vary context and temporal sensitivity, allowing Space Fortress to be used as a testbed for understanding both characteristics in combination and also in isolation. We release Space Fortress as an open-source Gym environment.
Kaleidoscope: An Efficient, Learnable Representation For All Structured Linear Maps
Jan 05, 2021

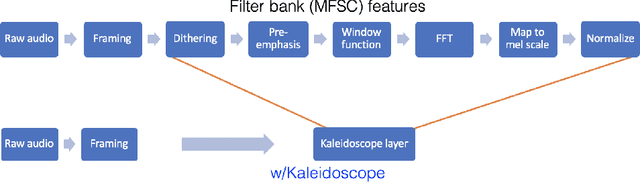

Modern neural network architectures use structured linear transformations, such as low-rank matrices, sparse matrices, permutations, and the Fourier transform, to improve inference speed and reduce memory usage compared to general linear maps. However, choosing which of the myriad structured transformations to use (and its associated parameterization) is a laborious task that requires trading off speed, space, and accuracy. We consider a different approach: we introduce a family of matrices called kaleidoscope matrices (K-matrices) that provably capture any structured matrix with near-optimal space (parameter) and time (arithmetic operation) complexity. We empirically validate that K-matrices can be automatically learned within end-to-end pipelines to replace hand-crafted procedures, in order to improve model quality. For example, replacing channel shuffles in ShuffleNet improves classification accuracy on ImageNet by up to 5%. K-matrices can also simplify hand-engineered pipelines -- we replace filter bank feature computation in speech data preprocessing with a learnable kaleidoscope layer, resulting in only 0.4% loss in accuracy on the TIMIT speech recognition task. In addition, K-matrices can capture latent structure in models: for a challenging permuted image classification task, a K-matrix based representation of permutations is able to learn the right latent structure and improves accuracy of a downstream convolutional model by over 9%. We provide a practically efficient implementation of our approach, and use K-matrices in a Transformer network to attain 36% faster end-to-end inference speed on a language translation task.
A Robotic System for Implant Modification in Single-stage Cranioplasty
Jan 12, 2021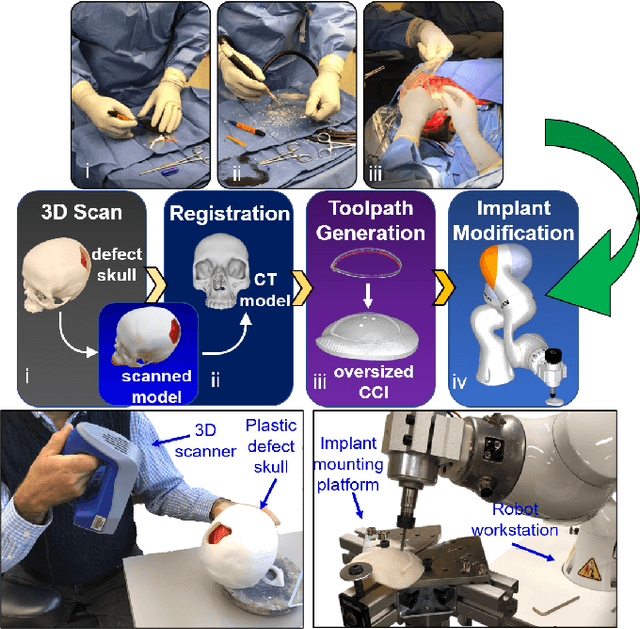
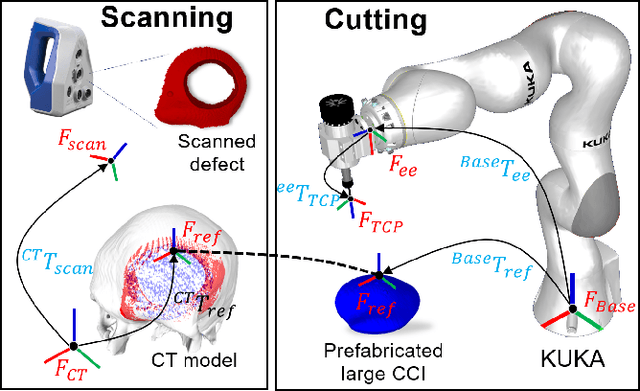
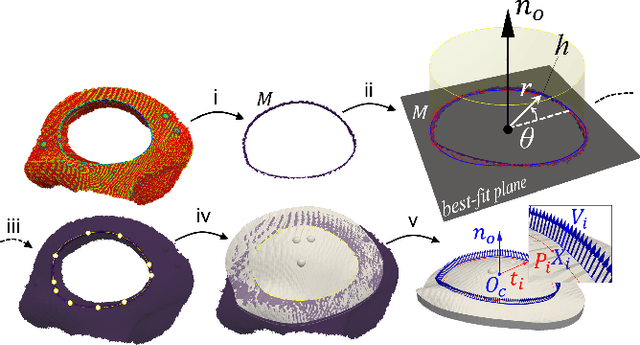
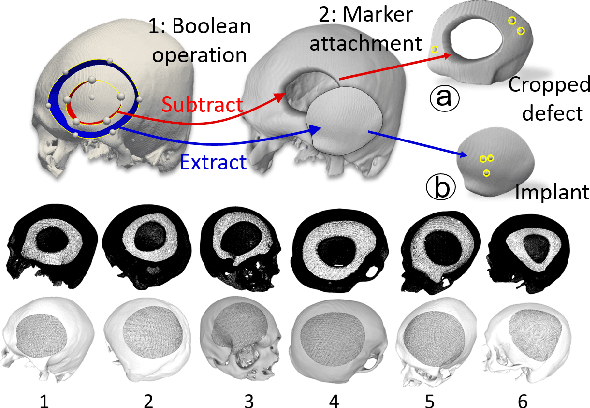
Craniomaxillofacial reconstruction with patient-specific customized craniofacial implants (CCIs) is most commonly performed for large-sized skeletal defects. Because the exact size of skull resection may not be known prior to the surgery, in the single-stage cranioplasty, a large CCI is prefabricated and resized intraoperatively with a manual-cutting process provided by a surgeon. The manual resizing, however, may be inaccurate and significantly add to the operating time. This paper introduces a fast and non-contact approach for intraoperatively determining the exact contour of the skull resection and automatically resizing the implant to fit the resection area. Our approach includes four steps: First, a patient's defect information is acquired by a 3D scanner. Second, the scanned defect is aligned to the CCI by registering the scanned defect to the reconstructed CT model. Third, a cutting toolpath is generated from the contour of the scanned defect. Lastly, the large CCI is resized by a cutting robot to fit the resection area according to the given toolpath. To evaluate the resizing performance of our method, six different resection shapes were used in the cutting experiments. We compared the performance of our method to the performances of surgeon's manual resizing and an existing technique which collects the defect contour with an optical tracking system and projects the contour on the CCI to guide the manual modification. The results show that our proposed method improves the resizing accuracy by 56% compared to the surgeon's manual modification and 42% compared to the projection method.
Handling Missing Data in Decision Trees: A Probabilistic Approach
Jun 29, 2020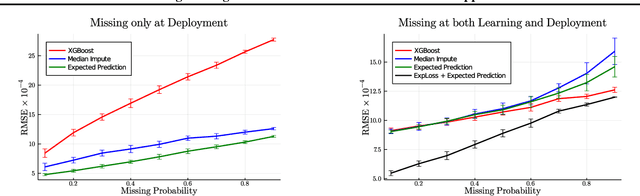

Decision trees are a popular family of models due to their attractive properties such as interpretability and ability to handle heterogeneous data. Concurrently, missing data is a prevalent occurrence that hinders performance of machine learning models. As such, handling missing data in decision trees is a well studied problem. In this paper, we tackle this problem by taking a probabilistic approach. At deployment time, we use tractable density estimators to compute the "expected prediction" of our models. At learning time, we fine-tune parameters of already learned trees by minimizing their "expected prediction loss" w.r.t.\ our density estimators. We provide brief experiments showcasing effectiveness of our methods compared to few baselines.
Generating Human-Like Movement: A Comparison Between Two Approaches Based on Environmental Features
Dec 11, 2020
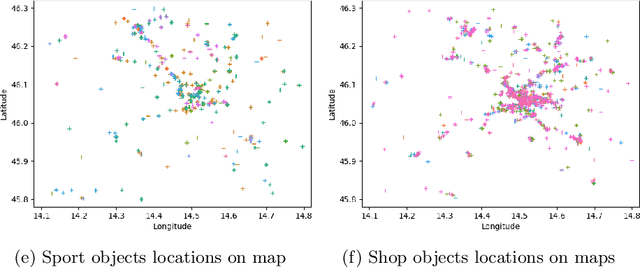

Modelling realistic human behaviours in simulation is an ongoing challenge that resides between several fields like social sciences, philosophy, and artificial intelligence. Human movement is a special type of behaviour driven by intent (e.g. to get groceries) and the surrounding environment (e.g. curiosity to see new interesting places). Services available online and offline do not normally consider the environment when planning a path, which is decisive especially on a leisure trip. Two novel algorithms have been presented to generate human-like trajectories based on environmental features. The Attraction-Based A* algorithm includes in its computation information from the environmental features meanwhile, the Feature-Based A* algorithm also injects information from the real trajectories in its computation. The human-likeness aspect has been tested by a human expert judging the final generated trajectories as realistic. This paper presents a comparison between the two approaches in some key metrics like efficiency, efficacy, and hyper-parameters sensitivity. We show how, despite generating trajectories that are closer to the real one according to our predefined metrics, the Feature-Based A* algorithm fall short in time efficiency compared to the Attraction-Based A* algorithm, hindering the usability of the model in the real world.
Thompson sampling for linear quadratic mean-field teams
Nov 09, 2020

We consider optimal control of an unknown multi-agent linear quadratic (LQ) system where the dynamics and the cost are coupled across the agents through the mean-field (i.e., empirical mean) of the states and controls. Directly using single-agent LQ learning algorithms in such models results in regret which increases polynomially with the number of agents. We propose a new Thompson sampling based learning algorithm which exploits the structure of the system model and show that the expected Bayesian regret of our proposed algorithm for a system with agents of $|M|$ different types at time horizon $T$ is $\tilde{\mathcal{O}} \big( |M|^{1.5} \sqrt{T} \big)$ irrespective of the total number of agents, where the $\tilde{\mathcal{O}}$ notation hides logarithmic factors in $T$. We present detailed numerical experiments to illustrate the salient features of the proposed algorithm.
Apollonius Allocation Algorithm for Heterogeneous Pursuers to Capture Multiple Evaders
Jun 19, 2020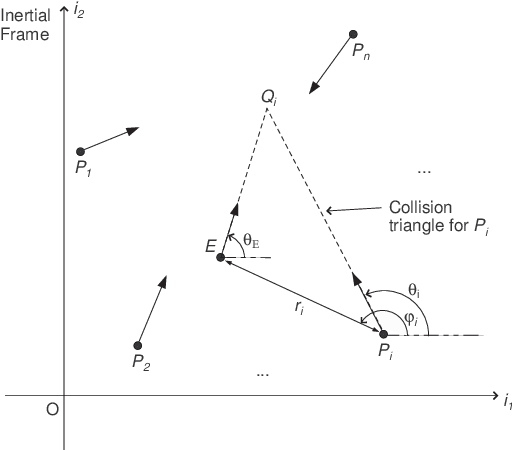
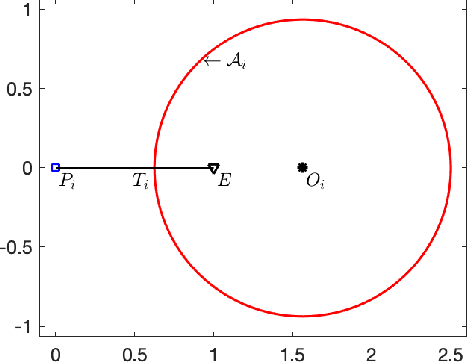
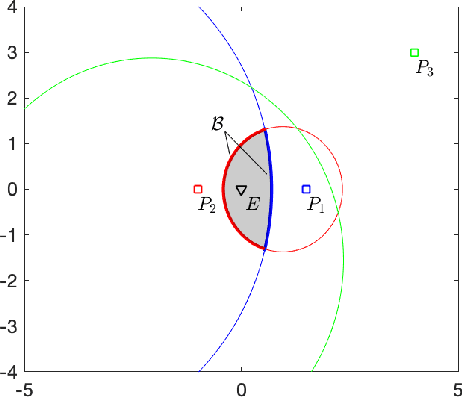
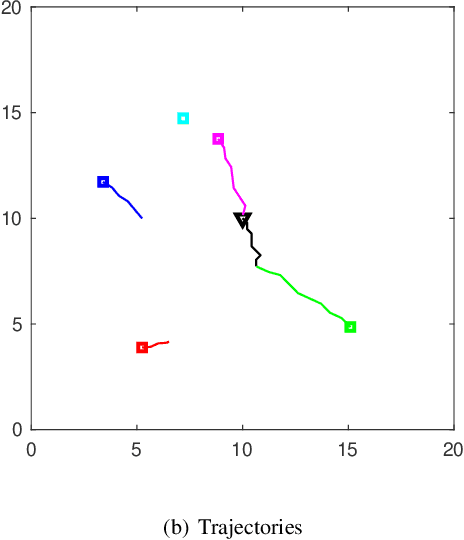
In this paper, we address pursuit-evasion problems involving multiple pursuers and multiple evaders. The pursuer and the evader teams are assumed to be heterogeneous, in the sense that each team has agents with different speed capabilities. The pursuers are all assumed to be following a constant bearing strategy. A dynamic divide and conquer approach, where at every time instant each evader is assigned to a set of pursuers based on the instantaneous positions of all the players, is introduced to solve the multi-agent pursuit problem. In this regard, the corresponding multi-pursuer single-evader problem is analyzed first. Assuming that the evader can follow any strategy, a dynamic task allocation algorithm is proposed for the pursuers. The algorithm is based on the well-known Apollonius circle and allows the pursuers to allocate their resources in an intelligent manner while guaranteeing the capture of the evader in minimum time. The proposed algorithm is then extended to assign pursuers in multi-evader settings that is proven to capture all the evaders in finite time.
V2I Connectivity-Based Dynamic Queue-Jump Lane for Emergency Vehicles: A Deep Reinforcement Learning Approach
Aug 01, 2020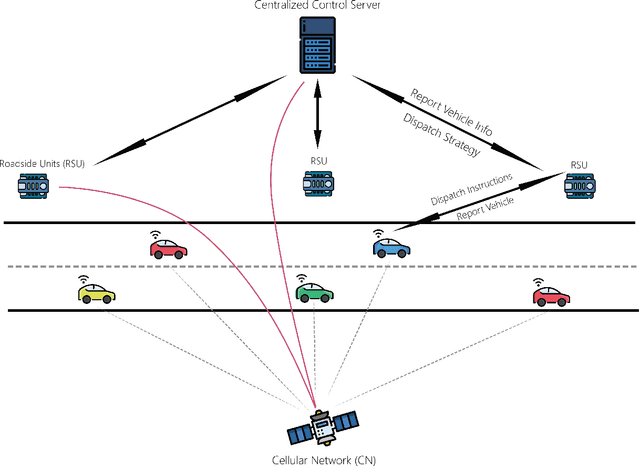


Emergency vehicle (EMV) service is a key function of cities and is exceedingly challenging due to urban traffic congestion. A main reason behind EMV service delay is the lack of communication and cooperation between vehicles blocking EMVs. In this paper, we study the improvement of EMV service under V2I connectivity. We consider the establishment of dynamic queue jump lanes (DQJLs) based on real-time coordination of connected vehicles. We develop a novel Markov decision process formulation for the DQJL problem, which explicitly accounts for the uncertainty of drivers' reaction to approaching EMVs. We propose a deep neural network-based reinforcement learning algorithm that efficiently computes the optimal coordination instructions. We also validate our approach on a micro-simulation testbed using Simulation of Urban Mobility (SUMO). Validation results show that with our proposed methodology, the centralized control system saves approximately 15\% EMV passing time than the benchmark system.
Imitation-Based Active Camera Control with Deep Convolutional Neural Network
Dec 11, 2020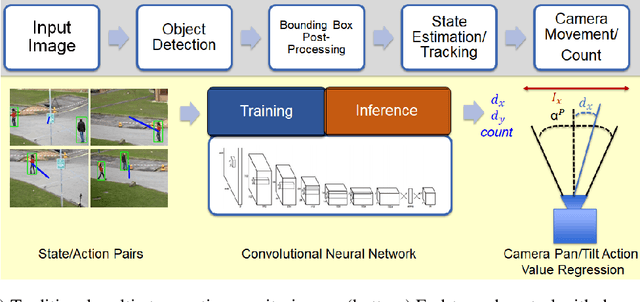

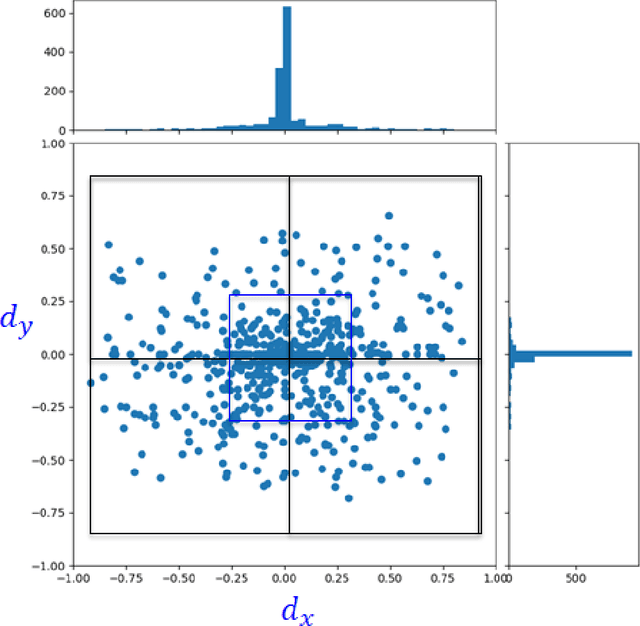
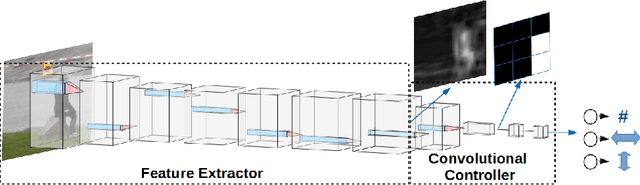
The increasing need for automated visual monitoring and control for applications such as smart camera surveillance, traffic monitoring, and intelligent environments, necessitates the improvement of methods for visual active monitoring. Traditionally, the active monitoring task has been handled through a pipeline of modules such as detection, filtering, and control. In this paper we frame active visual monitoring as an imitation learning problem to be solved in a supervised manner using deep learning, to go directly from visual information to camera movement in order to provide a satisfactory solution by combining computer vision and control. A deep convolutional neural network is trained end-to-end as the camera controller that learns the entire processing pipeline needed to control a camera to follow multiple targets and also estimate their density from a single image. Experimental results indicate that the proposed solution is robust to varying conditions and is able to achieve better monitoring performance both in terms of number of targets monitored as well as in monitoring time than traditional approaches, while reaching up to 25 FPS. Thus making it a practical and affordable solution for multi-target active monitoring in surveillance and smart-environment applications.
3D-ANAS: 3D Asymmetric Neural Architecture Search for Fast Hyperspectral Image Classification
Jan 12, 2021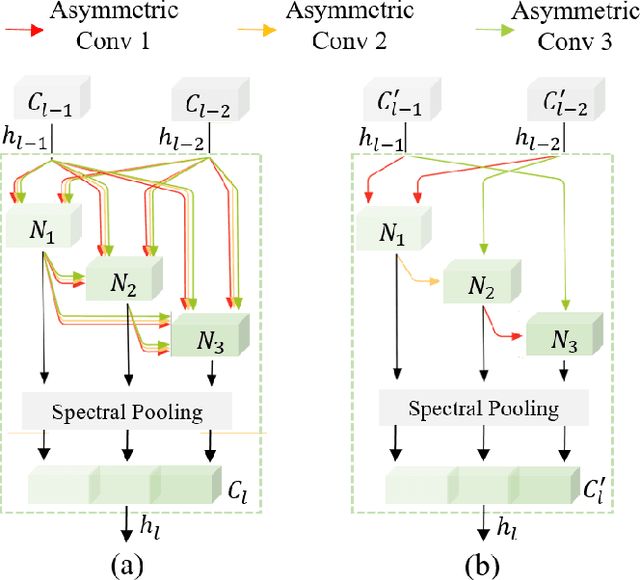
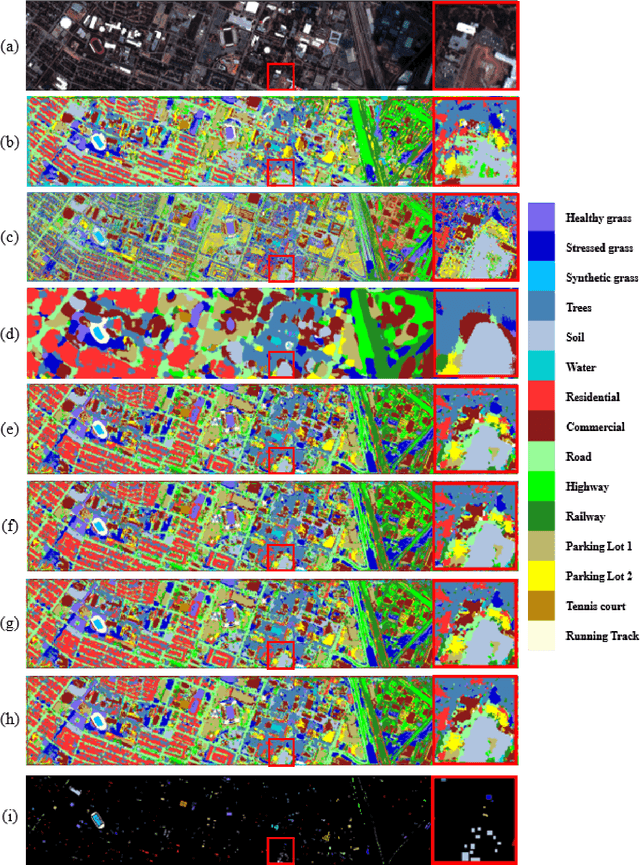
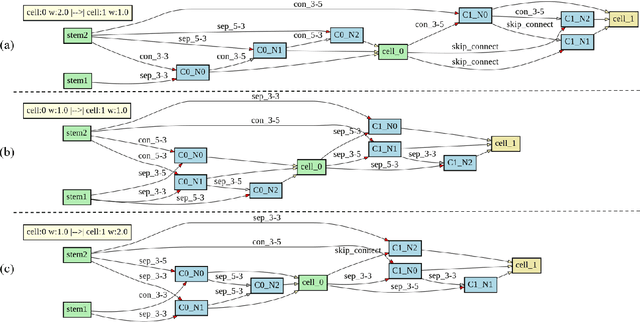
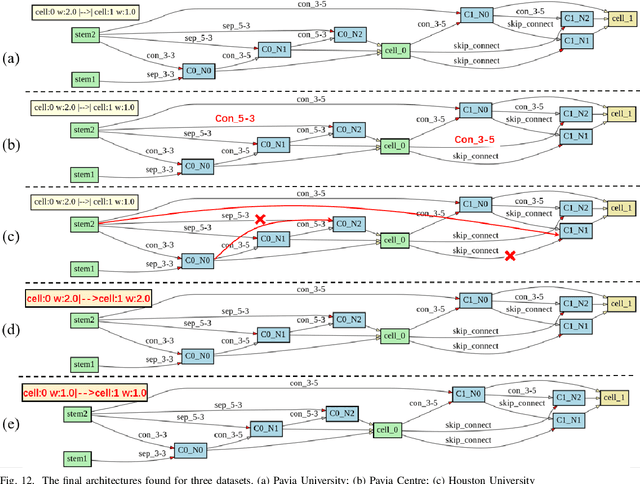
Hyperspectral images involve abundant spectral and spatial information, playing an irreplaceable role in land-cover classification. Recently, based on deep learning technologies, an increasing number of HSI classification approaches have been proposed, which demonstrate promising performance. However, previous studies suffer from two major drawbacks: 1) the architecture of most deep learning models is manually designed, relies on specialized knowledge, and is relatively tedious. Moreover, in HSI classifications, datasets captured by different sensors have different physical properties. Correspondingly, different models need to be designed for different datasets, which further increases the workload of designing architectures; 2) the mainstream framework is a patch-to-pixel framework. The overlap regions of patches of adjacent pixels are calculated repeatedly, which increases computational cost and time cost. Besides, the classification accuracy is sensitive to the patch size, which is artificially set based on extensive investigation experiments. To overcome the issues mentioned above, we firstly propose a 3D asymmetric neural network search algorithm and leverage it to automatically search for efficient architectures for HSI classifications. By analysing the characteristics of HSIs, we specifically build a 3D asymmetric decomposition search space, where spectral and spatial information are processed with different decomposition convolutions. Furthermore, we propose a new fast classification framework, i,e., pixel-to-pixel classification framework, which has no repetitive operations and reduces the overall cost. Experiments on three public HSI datasets captured by different sensors demonstrate the networks designed by our 3D-ANAS achieve competitive performance compared to several state-of-the-art methods, while having a much faster inference speed.