 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time Hand Tracking under Occlusion from an Egocentric RGB-D Sensor
Oct 05, 2017

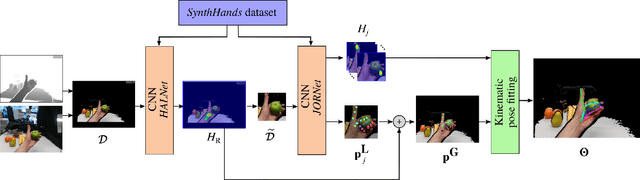
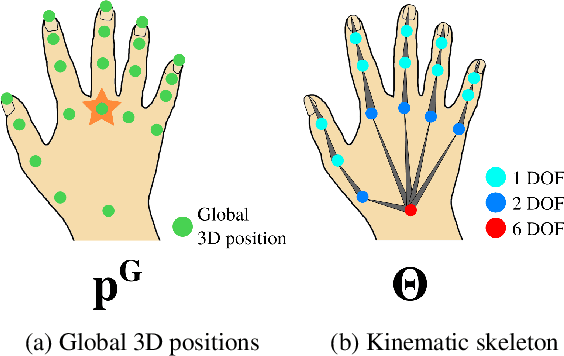

We present an approach for real-time, robust and accurate hand pose estimation from moving egocentric RGB-D cameras in cluttered real environments. Existing methods typically fail for hand-object interactions in cluttered scenes imaged from egocentric viewpoints, common for virtual or augmented reality applications. Our approach uses two subsequently applied Convolutional Neural Networks (CNNs) to localize the hand and regress 3D joint locations. Hand localization is achieved by using a CNN to estimate the 2D position of the hand center in the input, even in the presence of clutter and occlusions. The localized hand position, together with the corresponding input depth value, is used to generate a normalized cropped image that is fed into a second CNN to regress relative 3D hand joint locations in real time. For added accuracy, robustness and temporal stability, we refine the pose estimates using a kinematic pose tracking energy. To train the CNNs, we introduce a new photorealistic dataset that uses a merged reality approach to capture and synthesize large amounts of annotated data of natural hand interaction in cluttered scenes. Through quantitative and qualitative evaluation, we show that our method is robust to self-occlusion and occlusions by objects, particularly in moving egocentric perspectives.
Automated Respiratory Event Detection Using Deep Neural Networks
Jan 12, 2021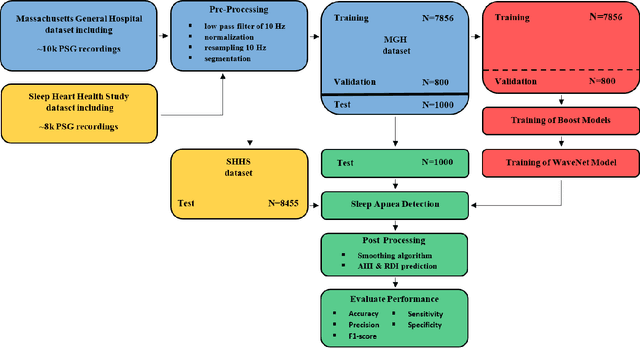
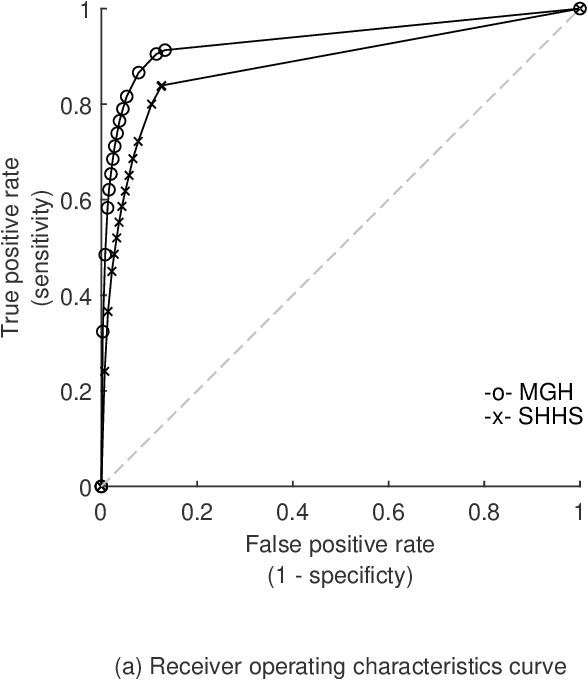
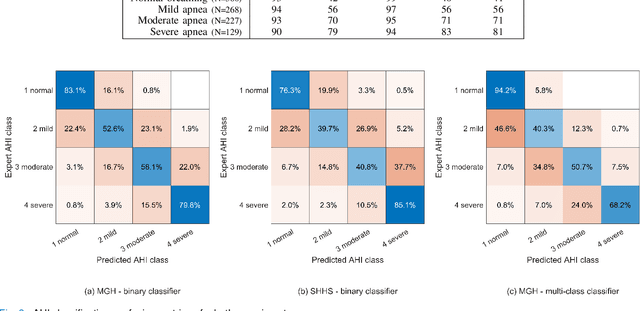
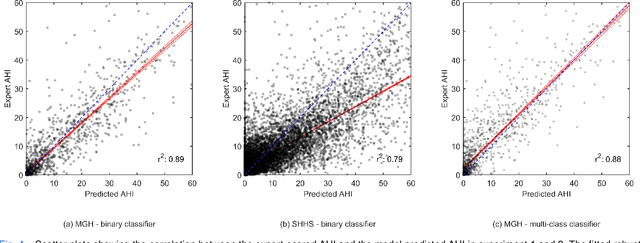
The gold standard to assess respiration during sleep is polysomnography; a technique that is burdensome, expensive (both in analysis time and measurement costs), and difficult to repeat. Automation of respiratory analysis can improve test efficiency and enable accessible implementation opportunities worldwide. Using 9,656 polysomnography recordings from the Massachusetts General Hospital (MGH), we trained a neural network (WaveNet) based on a single respiratory effort belt to detect obstructive apnea, central apnea, hypopnea and respiratory-effort related arousals. Performance evaluation included event-based and recording-based metrics - using an apnea-hypopnea index analysis. The model was further evaluated on a public dataset, the Sleep-Heart-Health-Study-1, containing 8,455 polysomnographic recordings. For binary apnea event detection in the MGH dataset, the neural network obtained an accuracy of 95%, an apnea-hypopnea index $r^2$ of 0.89 and area under the curve for the receiver operating characteristics curve and precision-recall curve of 0.93 and 0.74, respectively. For the multiclass task, we obtained varying performances: 81% of all labeled central apneas were correctly classified, whereas this metric was 46% for obstructive apneas, 29% for respiratory effort related arousals and 16% for hypopneas. The majority of false predictions were misclassifications as another type of respiratory event. Our fully automated method can detect respiratory events and assess the apnea-hypopnea index with sufficient accuracy for clinical utilization. Differentiation of event types is more difficult and may reflect in part the complexity of human respiratory output and some degree of arbitrariness in the clinical thresholds and criteria used during manual annotation.
TinaFace: Strong but Simple Baseline for Face Detection
Dec 02, 2020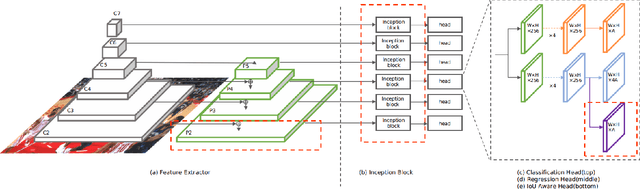
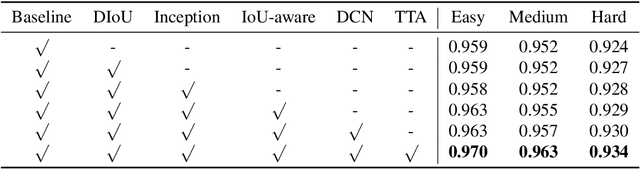
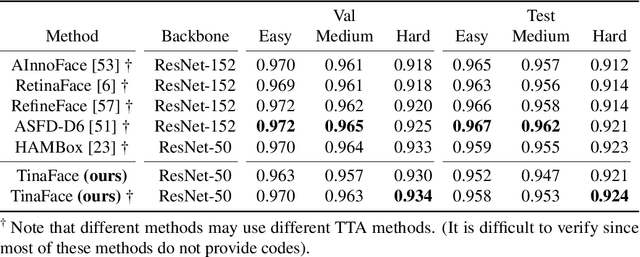
Face detection has received intensive attention in recent years. Many works present lots of special methods for face detection from different perspectives like model architecture, data augmentation, label assignment and etc., which make the overall algorithm and system become more and more complex. In this paper, we point out that \textbf{there is no gap between face detection and generic object detection}. Then we provide a strong but simple baseline method to deal with face detection named TinaFace. We use ResNet-50 \cite{he2016deep} as backbone, and all modules and techniques in TinaFace are constructed on existing modules, easily implemented and based on generic object detection. On the hard test set of the most popular and challenging face detection benchmark WIDER FACE \cite{yang2016wider}, with single-model and single-scale, our TinaFace achieves 92.1\% average precision (AP), which exceeds most of the recent face detectors with larger backbone. And after using test time augmentation (TTA), our TinaFace outperforms the current state-of-the-art method and achieves 92.4\% AP. The code will be available at \url{https://github.com/Media-Smart/vedadet}.
MonoComb: A Sparse-to-Dense Combination Approach for Monocular Scene Flow
Oct 21, 2020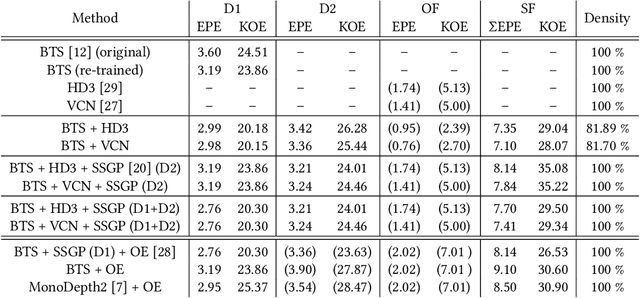


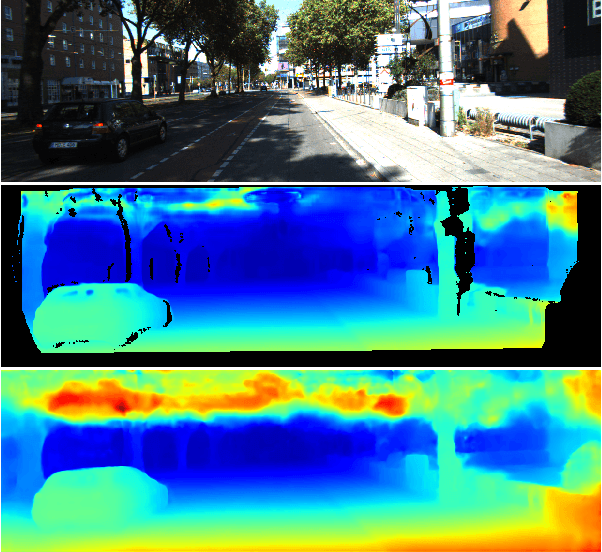
Contrary to the ongoing trend in automotive applications towards usage of more diverse and more sensors, this work tries to solve the complex scene flow problem under a monocular camera setup, i.e. using a single sensor. Towards this end, we exploit the latest achievements in single image depth estimation, optical flow, and sparse-to-dense interpolation and propose a monocular combination approach (MonoComb) to compute dense scene flow. MonoComb uses optical flow to relate reconstructed 3D positions over time and interpolates occluded areas. This way, existing monocular methods are outperformed in dynamic foreground regions which leads to the second best result among the competitors on the challenging KITTI 2015 scene flow benchmark.
Noise-Robust End-to-End Quantum Control using Deep Autoregressive Policy Networks
Dec 12, 2020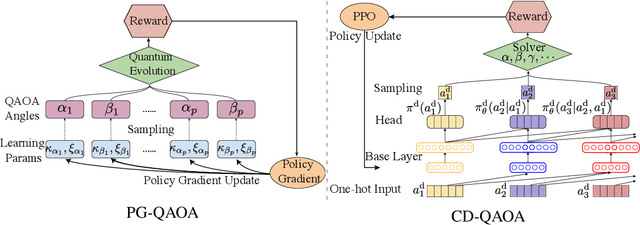
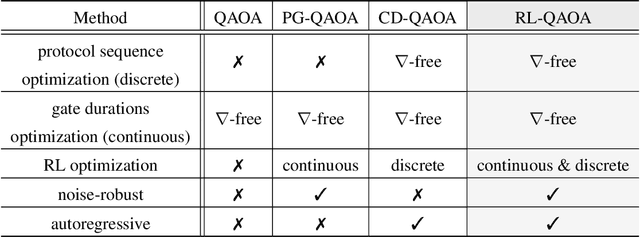
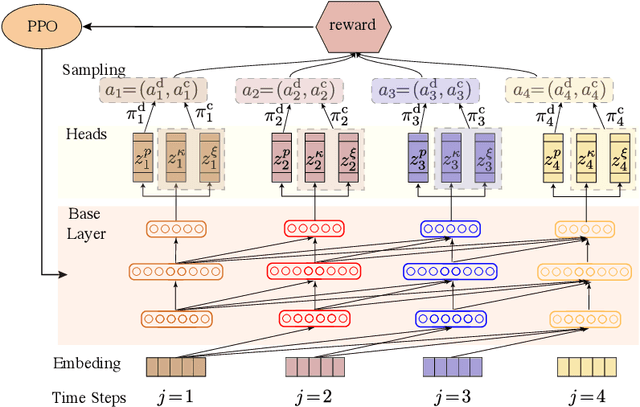

Variational quantum eigensolvers have recently received increased attention, as they enable the use of quantum computing devices to find solutions to complex problems, such as the ground energy and ground state of strongly-correlated quantum many-body systems. In many applications, it is the optimization of both continuous and discrete parameters that poses a formidable challenge. Using reinforcement learning (RL), we present a hybrid policy gradient algorithm capable of simultaneously optimizing continuous and discrete degrees of freedom in an uncertainty-resilient way. The hybrid policy is modeled by a deep autoregressive neural network to capture causality. We employ the algorithm to prepare the ground state of the nonintegrable quantum Ising model in a unitary process, parametrized by a generalized quantum approximate optimization ansatz: the RL agent solves the discrete combinatorial problem of constructing the optimal sequences of unitaries out of a predefined set and, at the same time, it optimizes the continuous durations for which these unitaries are applied. We demonstrate the noise-robust features of the agent by considering three sources of uncertainty: classical and quantum measurement noise, and errors in the control unitary durations. Our work exhibits the beneficial synergy between reinforcement learning and quantum control.
Towards Class-incremental Object Detection with Nearest Mean of Exemplars
Aug 19, 2020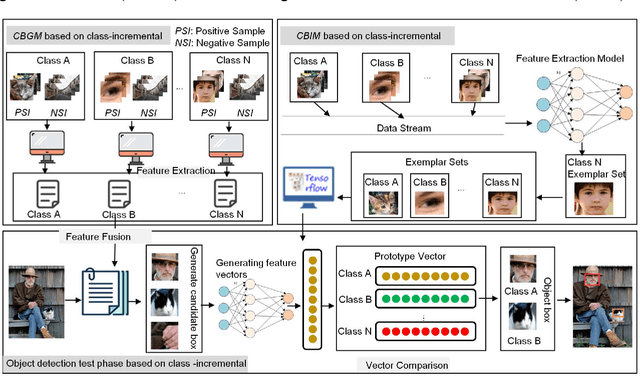
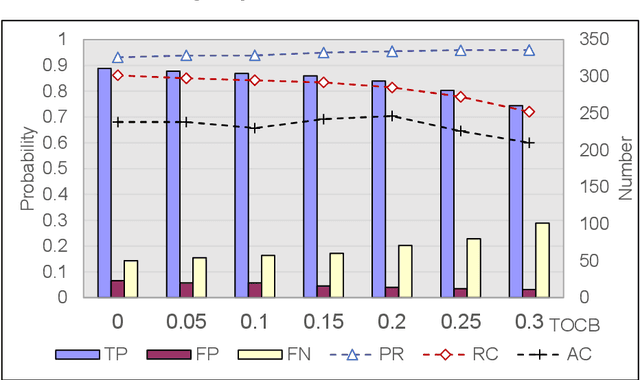
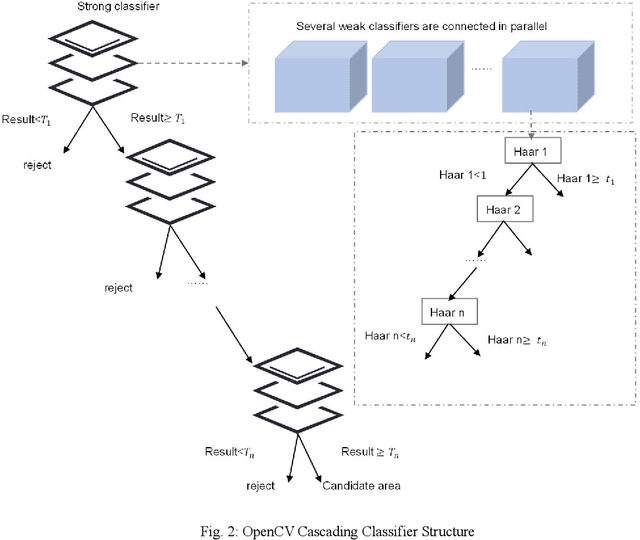
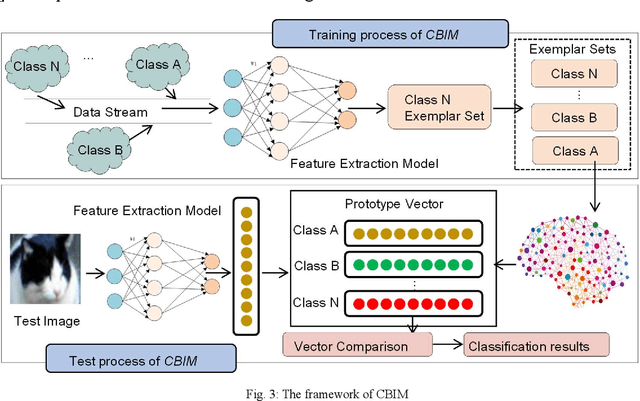
Object detection has been widely used in the field of Internet, and deep learning plays a very important role in object detection. However, the existing object detection methods need to be trained in the static setting, which requires obtaining all the data at one time, and it does not support training in the way of class-incremental. In this paper, an object detection framework named class-incremental object detection (CIOD) is proposed. CIOD divides object detection into two stages. Firstly, the traditional OpenCV cascade classifier is improved in the object candidate box generation stage to meet the needs of class increment. Secondly, we use the concept of prototype vector on the basis of deep learning to train a classifier based on class-incremental to identify the generated object candidate box, so as to extract the real object box. A large number of experiments on CIOD have been carried out to verify that CIOD can detect the object in the way of class-incremental and can control the training time and memory capacity.
Autoencoding Neural Networks as Musical Audio Synthesizers
Apr 27, 2020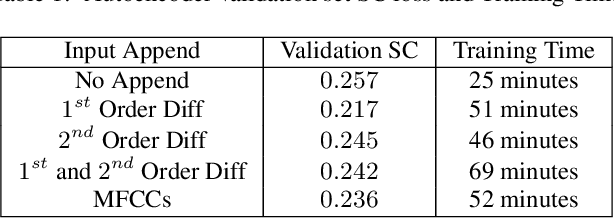
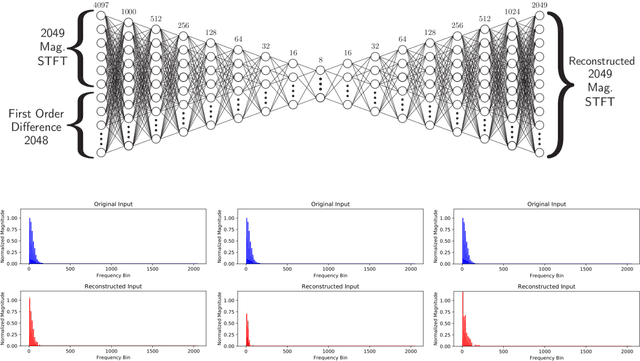
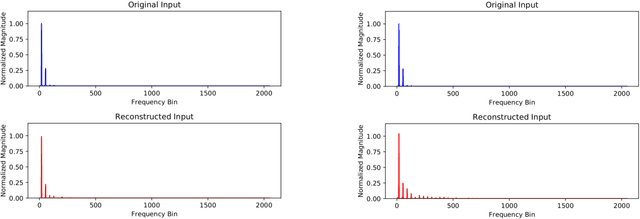
A method for musical audio synthesis using autoencoding neural networks is proposed. The autoencoder is trained to compress and reconstruct magnitude short-time Fourier transform frames. The autoencoder produces a spectrogram by activating its smallest hidden layer, and a phase response is calculated using real-time phase gradient heap integration. Taking an inverse short-time Fourier transform produces the audio signal. Our algorithm is light-weight when compared to current state-of-the-art audio-producing machine learning algorithms. We outline our design process, produce metrics, and detail an open-source Python implementation of our model.
Robust Clustering for Time Series Using Spectral Densities and Functional Data Analysis
Feb 07, 2017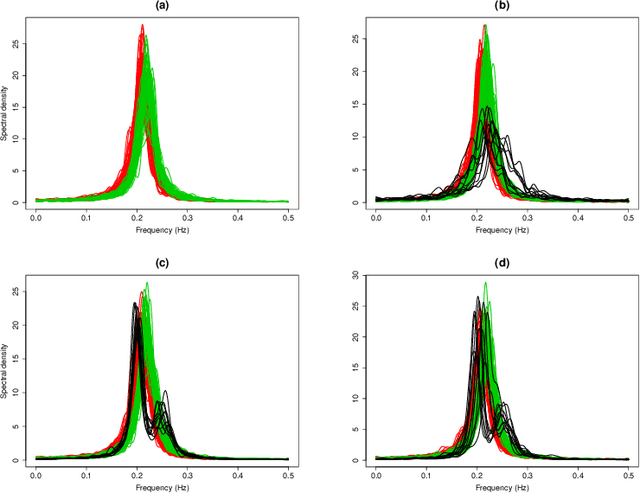
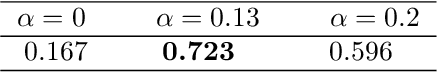
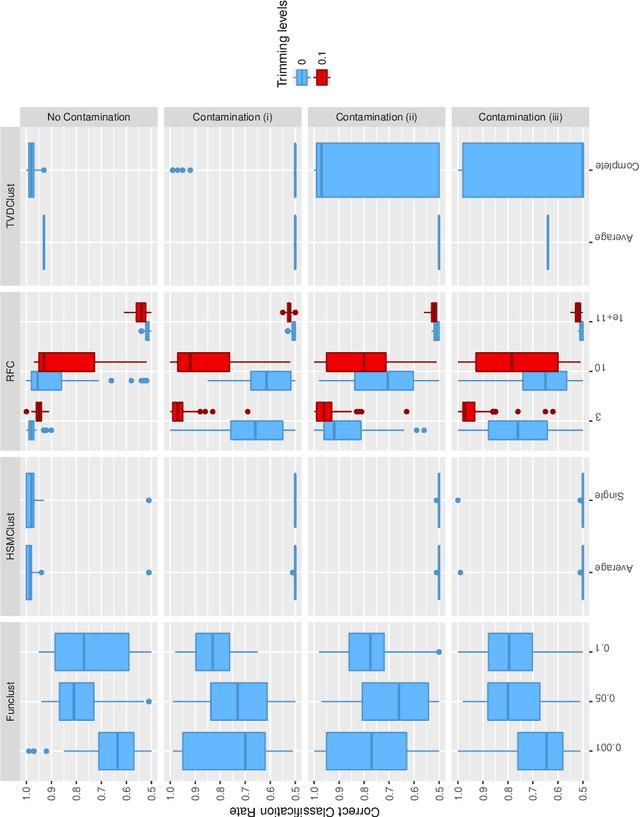
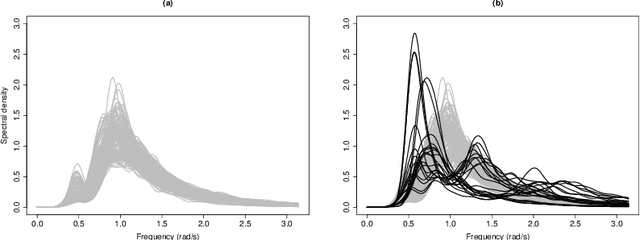
In this work a robust clustering algorithm for stationary time series is proposed. The algorithm is based on the use of estimated spectral densities, which are considered as functional data, as the basic characteristic of stationary time series for clustering purposes. A robust algorithm for functional data is then applied to the set of spectral densities. Trimming techniques and restrictions on the scatter within groups reduce the effect of noise in the data and help to prevent the identification of spurious clusters. The procedure is tested in a simulation study, and is also applied to a real data set.
Handling Missing Data in Decision Trees: A Probabilistic Approach
Jun 29, 2020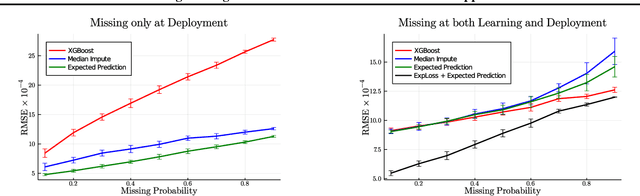

Decision trees are a popular family of models due to their attractive properties such as interpretability and ability to handle heterogeneous data. Concurrently, missing data is a prevalent occurrence that hinders performance of machine learning models. As such, handling missing data in decision trees is a well studied problem. In this paper, we tackle this problem by taking a probabilistic approach. At deployment time, we use tractable density estimators to compute the "expected prediction" of our models. At learning time, we fine-tune parameters of already learned trees by minimizing their "expected prediction loss" w.r.t.\ our density estimators. We provide brief experiments showcasing effectiveness of our methods compared to few baselines.
Boundary-sensitive Pre-training for Temporal Localization in Videos
Nov 21, 2020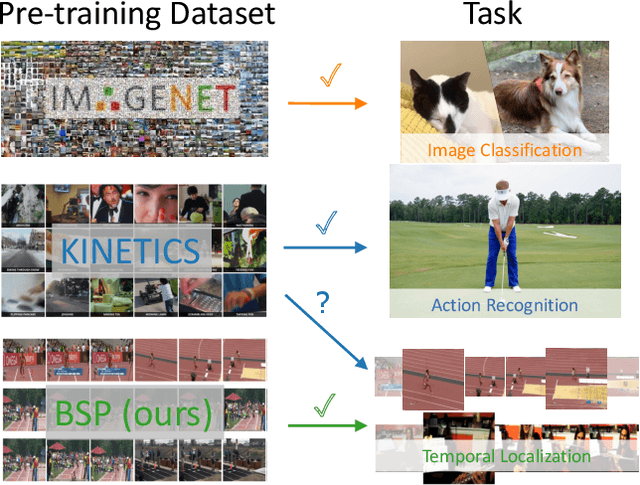
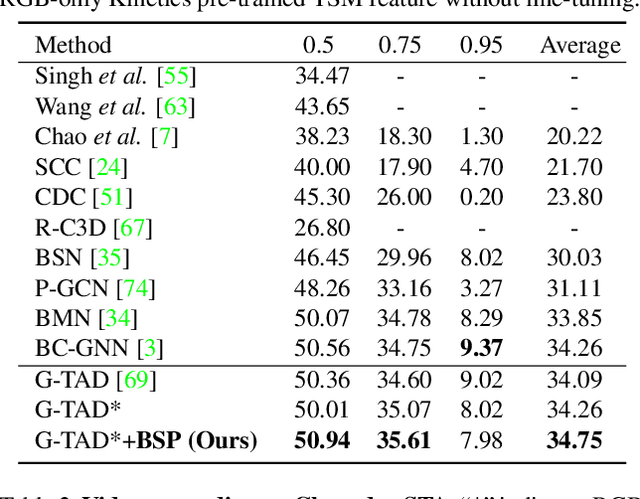

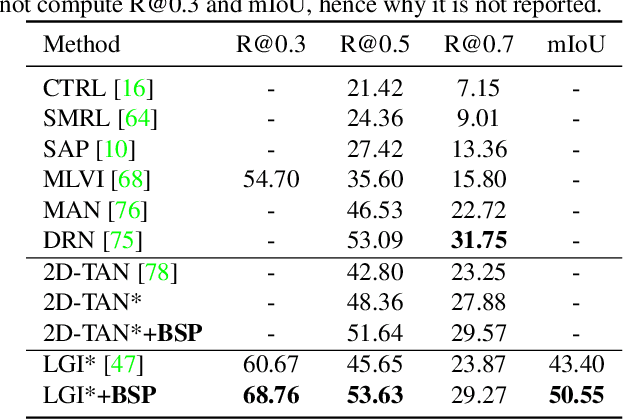
Many video analysis tasks require temporal localization thus detection of content changes. However, most existing models developed for these tasks are pre-trained on general video action classification tasks. This is because large scale annotation of temporal boundaries in untrimmed videos is expensive. Therefore no suitable datasets exist for temporal boundary-sensitive pre-training. In this paper for the first time, we investigate model pre-training for temporal localization by introducing a novel boundary-sensitive pretext (BSP) task. Instead of relying on costly manual annotations of temporal boundaries, we propose to synthesize temporal boundaries in existing video action classification datasets. With the synthesized boundaries, BSP can be simply conducted via classifying the boundary types. This enables the learning of video representations that are much more transferable to downstream temporal localization tasks. Extensive experiments show that the proposed BSP is superior and complementary to the existing action classification based pre-training counterpart, and achieves new state-of-the-art performance on several temporal localization tasks.