 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Combining Shape Features with Multiple Color Spaces in Open-Ended 3D Object Recognition
Sep 19, 2020

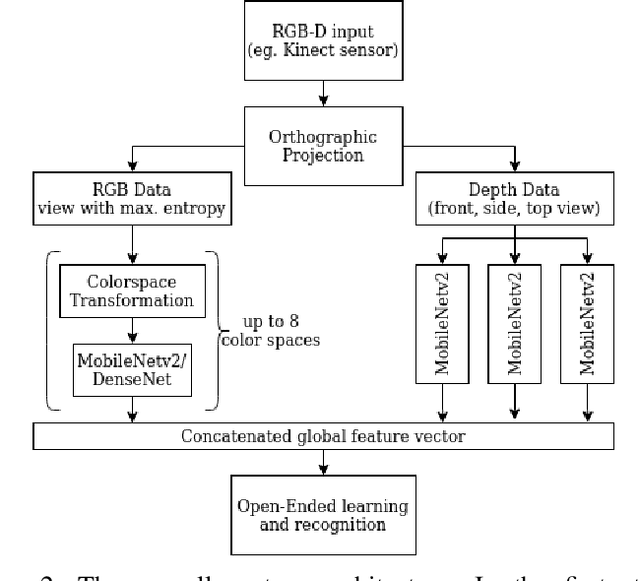


As a consequence of an ever-increasing number of camera-based service robots, there is a growing demand for highly accurate real-time 3D object recognition. Considering the expansion of robot applications in more complex and dynamic environments, it is evident that it is impossible to pre-program all possible object categories. Robots will have to be able to learn new object categories in the field. The network architecture proposed in this work expands from the OrthographicNet, an approach recently proposed by Kasaei et al., using a deep transfer learning strategy which not only meets the aforementioned requirements but additionally generates a scale and rotation-invariant reference frame for the classification of objects. In its current iteration, the OrthographicNet only uses shape-information. With the addition of multiple color spaces, the upgraded network architecture proposed here, can achieve an even higher descriptiveness while simultaneously increasing the robustness of predictions for similarly shaped objects. Multiple color space combinations and network architectures are evaluated to find the most descriptive system. However, this performance increase is not achieved at the cost of longer processing times, because any system deployed in robotic applications will need the ability to provide real-time information about its environment. Experimental results show that the proposed network architecture ranks competitively among other state-of-the-art algorithms.
Frame-To-Frame Consistent Semantic Segmentation
Aug 20, 2020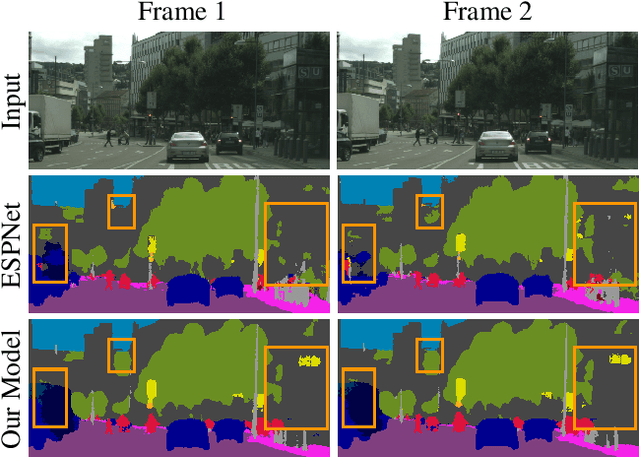
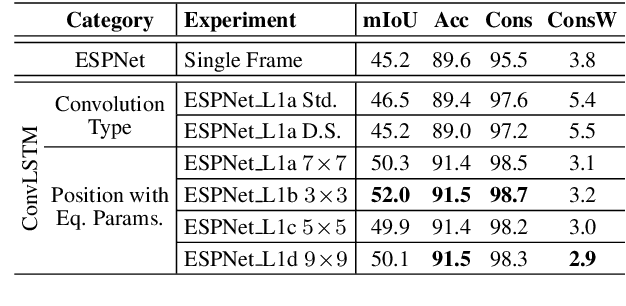
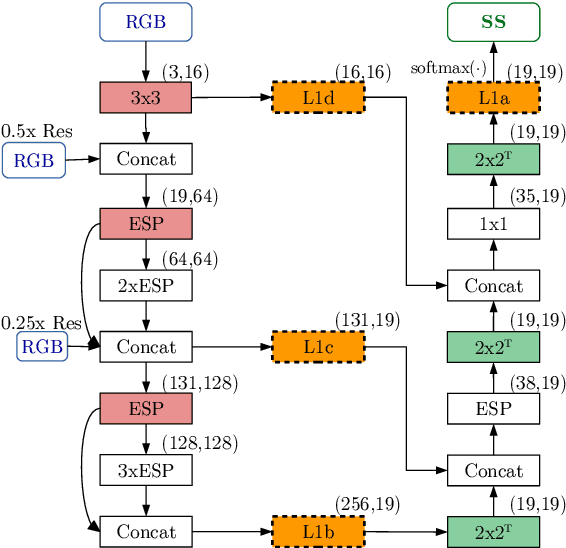
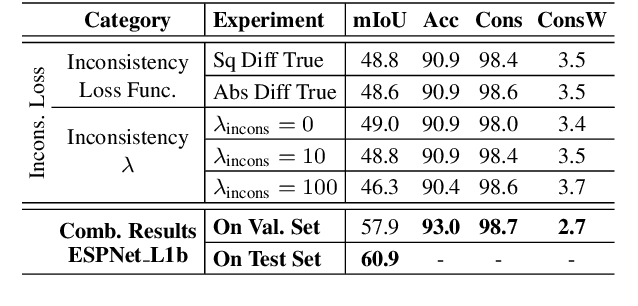
In this work, we aim for temporally consistent semantic segmentation throughout frames in a video. Many semantic segmentation algorithms process images individually which leads to an inconsistent scene interpretation due to illumination changes, occlusions and other variations over time. To achieve a temporally consistent prediction, we train a convolutional neural network (CNN) which propagates features through consecutive frames in a video using a convolutional long short term memory (ConvLSTM) cell. Besides the temporal feature propagation, we penalize inconsistencies in our loss function. We show in our experiments that the performance improves when utilizing video information compared to single frame prediction. The mean intersection over union (mIoU) metric on the Cityscapes validation set increases from 45.2 % for the single frames to 57.9 % for video data after implementing the ConvLSTM to propagate features trough time on the ESPNet. Most importantly, inconsistency decreases from 4.5 % to 1.3 % which is a reduction by 71.1 %. Our results indicate that the added temporal information produces a frame-to-frame consistent and more accurate image understanding compared to single frame processing.
A Method for Tumor Treating Fields Fast Estimation
Oct 06, 2020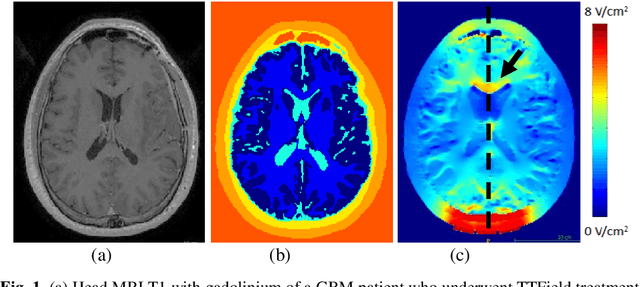
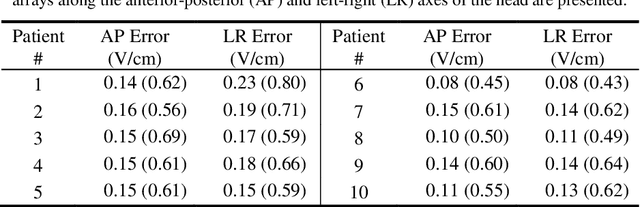
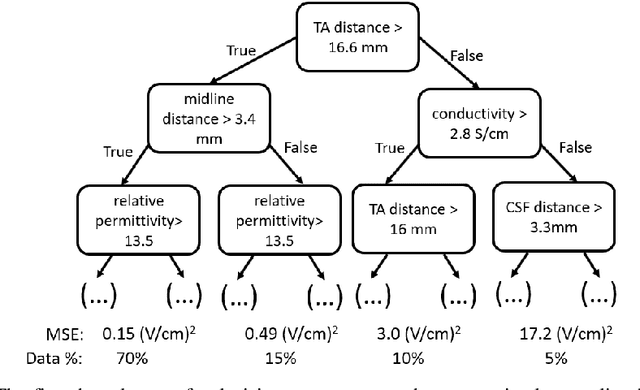
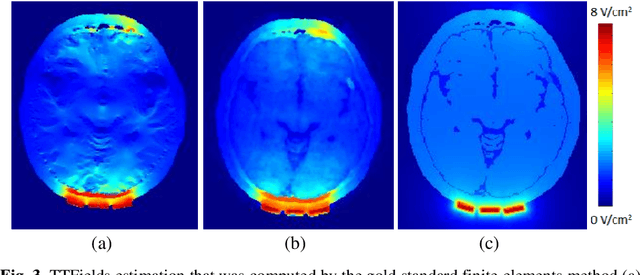
Tumor Treating Fields (TTFields) is an FDA approved treatment for specific types of cancer and significantly extends patients life. The intensity of the TTFields within the tumor was associated with the treatment outcomes: the larger the intensity the longer the patients are likely to survive. Therefore, it was suggested to optimize TTFields transducer array location such that their intensity is maximized. Such optimization requires multiple computations of TTFields in a simulation framework. However, these computations are typically performed using finite element methods or similar approaches that are time consuming. Therefore, only a limited number of transducer array locations can be examined in practice. To overcome this issue, we have developed a method for fast estimation of TTFields intensity. We have designed and implemented a method that inputs a segmentation of the patients head, a table of tissues electrical properties and the location of the transducer array. The method outputs a spatial estimation of the TTFields intensity by incorporating a few relevant parameters in a random-forest regressor. The method was evaluated on 10 patients (20 TA layouts) in a leave-one-out framework. The computation time was 1.5 minutes using the suggested method, and 180-240 minutes using the commercial simulation. The average error was 0.14 V/cm (SD = 0.06 V/cm) in comparison to the result of the commercial simulation. These results suggest that a fast estimation of TTFields based on a few parameters is feasible. The presented method may facilitate treatment optimization and further extend patients life.
The Effect of the Rooney Rule on Implicit Bias in the Long Term
Oct 21, 2020
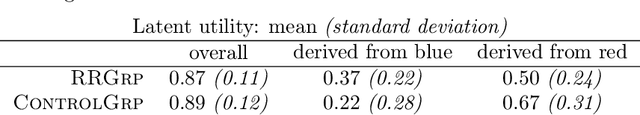
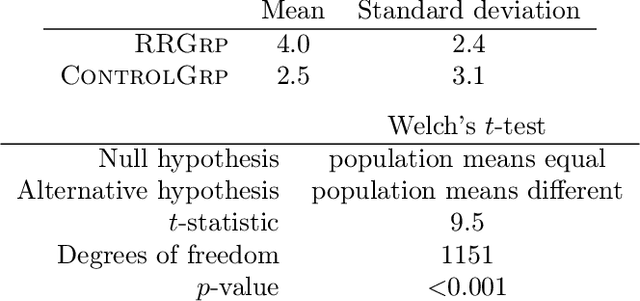

A robust body of evidence demonstrates the adverse effects of implicit bias in various contexts--from hiring to health care. The Rooney Rule is an intervention developed to counter implicit bias and has been implemented in the private and public sectors. The Rooney Rule requires that a selection panel include at least one candidate from an underrepresented group in their shortlist of candidates. Recently, Kleinberg and Raghavan proposed a model of implicit bias and studied the effectiveness of the Rooney Rule when applied to a single selection decision. However, selection decisions often occur repeatedly over time. Further, it has been observed that, given consistent counterstereotypical feedback, implicit biases against underrepresented candidates can change. We consider a model of how a selection panel's implicit bias changes over time given their hiring decisions either with or without the Rooney Rule in place. Our main result is that, when the panel is constrained by the Rooney Rule, their implicit bias roughly reduces at a rate that is the inverse of the size of the shortlist--independent of the number of candidates, whereas without the Rooney Rule, the rate is inversely proportional to the number of candidates. Thus, when the number of candidates is much larger than the size of the shortlist, the Rooney Rule enables a faster reduction in implicit bias, providing an additional reason in favor of using it as a strategy to mitigate implicit bias. Towards empirically evaluating the long-term effect of the Rooney Rule in repeated selection decisions, we conduct an iterative candidate selection experiment on Amazon MTurk. We observe that, indeed, decision-makers subject to the Rooney Rule select more minority candidates in addition to those required by the rule itself than they would if no rule is in effect, and do so without considerably decreasing the utility of candidates selected.
Multi-Agent Online Optimization with Delays: Asynchronicity, Adaptivity, and Optimism
Dec 21, 2020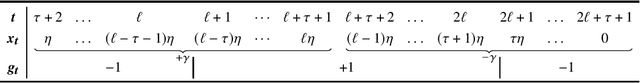
Online learning has been successfully applied to many problems in which data are revealed over time. In this paper, we provide a general framework for studying multi-agent online learning problems in the presence of delays and asynchronicities. Specifically, we propose and analyze a class of adaptive dual averaging schemes in which agents only need to accumulate gradient feedback received from the whole system, without requiring any between-agent coordination. In the single-agent case, the adaptivity of the proposed method allows us to extend a range of existing results to problems with potentially unbounded delays between playing an action and receiving the corresponding feedback. In the multi-agent case, the situation is significantly more complicated because agents may not have access to a global clock to use as a reference point; to overcome this, we focus on the information that is available for producing each prediction rather than the actual delay associated with each feedback. This allows us to derive adaptive learning strategies with optimal regret bounds, at both the agent and network levels. Finally, we also analyze an "optimistic" variant of the proposed algorithm which is capable of exploiting the predictability of problems with a slower variation and leads to improved regret bounds.
From Points to Multi-Object 3D Reconstruction
Dec 21, 2020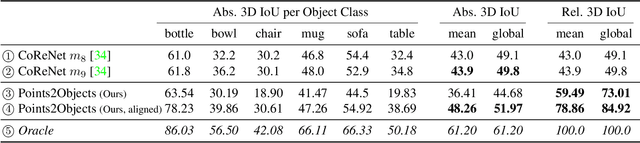
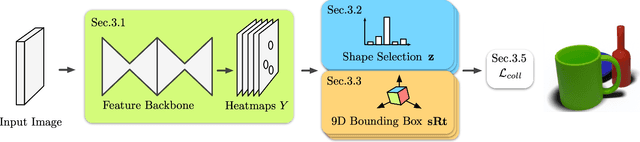

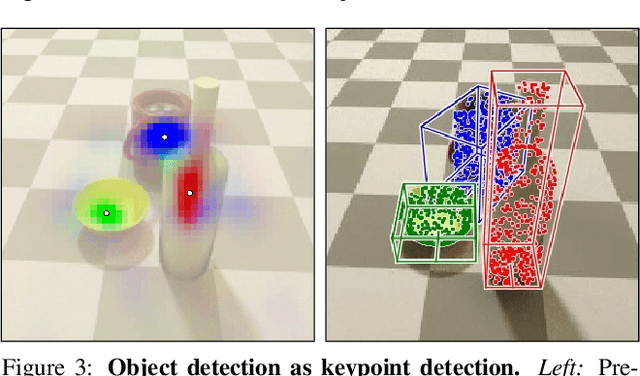
We propose a method to detect and reconstruct multiple 3D objects from a single RGB image. The key idea is to optimize for detection, alignment and shape jointly over all objects in the RGB image, while focusing on realistic and physically plausible reconstructions. To this end, we propose a keypoint detector that localizes objects as center points and directly predicts all object properties, including 9-DoF bounding boxes and 3D shapes -- all in a single forward pass. The proposed method formulates 3D shape reconstruction as a shape selection problem, i.e. it selects among exemplar shapes from a given database. This makes it agnostic to shape representations, which enables a lightweight reconstruction of realistic and visually-pleasing shapes based on CAD-models, while the training objective is formulated around point clouds and voxel representations. A collision-loss promotes non-intersecting objects, further increasing the reconstruction realism. Given the RGB image, the presented approach performs lightweight reconstruction in a single-stage, it is real-time capable, fully differentiable and end-to-end trainable. Our experiments compare multiple approaches for 9-DoF bounding box estimation, evaluate the novel shape-selection mechanism and compare to recent methods in terms of 3D bounding box estimation and 3D shape reconstruction quality.
Concept Drift Monitoring and Diagnostics of Supervised Learning Models via Score Vectors
Dec 12, 2020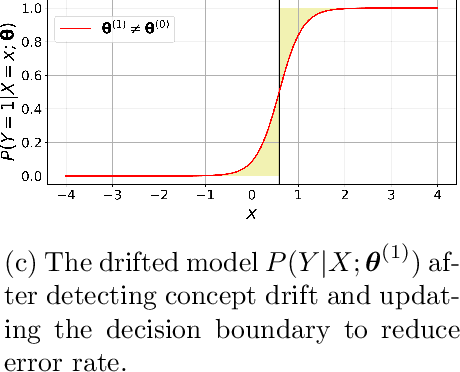
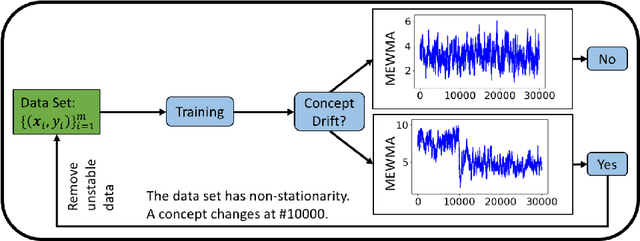
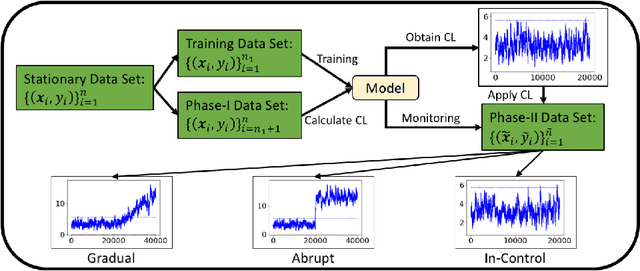
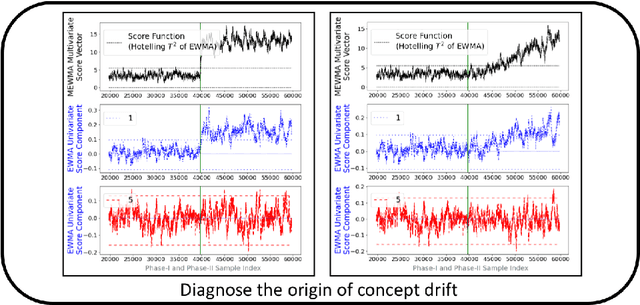
Supervised learning models are one of the most fundamental classes of models. Viewing supervised learning from a probabilistic perspective, the set of training data to which the model is fitted is usually assumed to follow a stationary distribution. However, this stationarity assumption is often violated in a phenomenon called concept drift, which refers to changes over time in the predictive relationship between covariates $\mathbf{X}$ and a response variable $Y$ and can render trained models suboptimal or obsolete. We develop a comprehensive and computationally efficient framework for detecting, monitoring, and diagnosing concept drift. Specifically, we monitor the Fisher score vector, defined as the gradient of the log-likelihood for the fitted model, using a form of multivariate exponentially weighted moving average, which monitors for general changes in the mean of a random vector. In spite of the substantial performance advantages that we demonstrate over popular error-based methods, a score-based approach has not been previously considered for concept drift monitoring. Advantages of the proposed score-based framework include applicability to any parametric model, more powerful detection of changes as shown in theory and experiments, and inherent diagnostic capabilities for helping to identify the nature of the changes.
Analysis and Prediction of Deforming 3D Shapes using Oriented Bounding Boxes and LSTM Autoencoders
Aug 31, 2020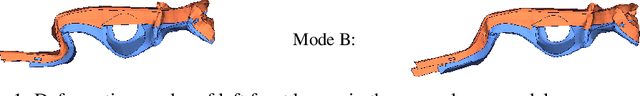
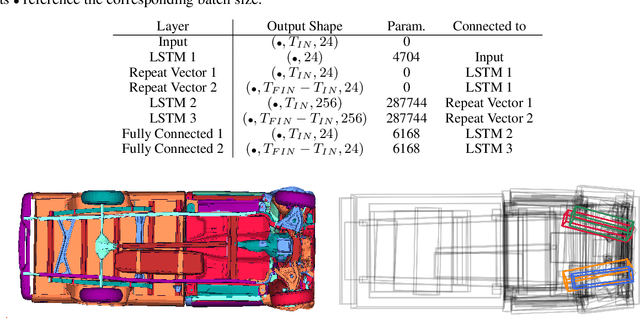
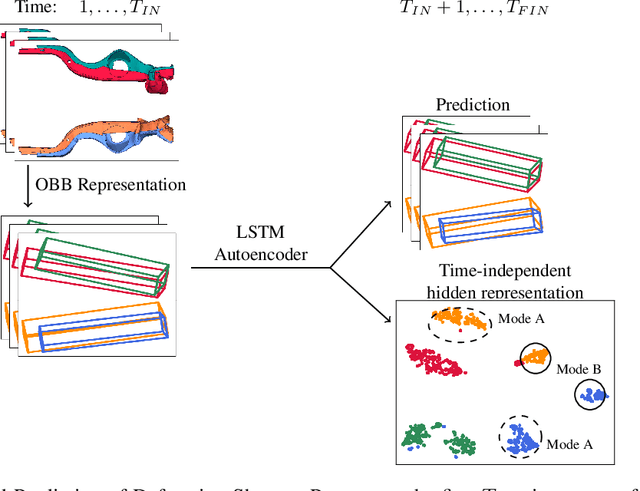
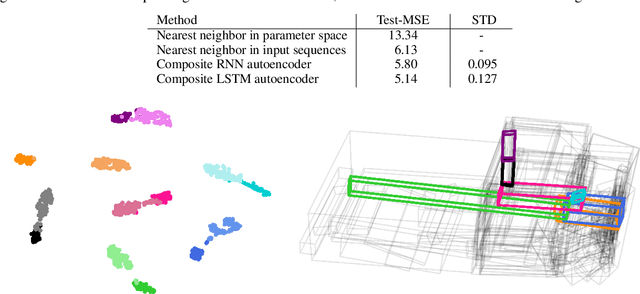
For sequences of complex 3D shapes in time we present a general approach to detect patterns for their analysis and to predict the deformation by making use of structural components of the complex shape. We incorporate long short-term memory (LSTM) layers into an autoencoder to create low dimensional representations that allow the detection of patterns in the data and additionally detect the temporal dynamics in the deformation behavior. This is achieved with two decoders, one for reconstruction and one for prediction of future time steps of the sequence. In a preprocessing step the components of the studied object are converted to oriented bounding boxes which capture the impact of plastic deformation and allow reducing the dimensionality of the data describing the structure. The architecture is tested on the results of 196 car crash simulations of a model with 133 different components, where material properties are varied. In the latent representation we can detect patterns in the plastic deformation for the different components. The predicted bounding boxes give an estimate of the final simulation result and their quality is improved in comparison to different baselines.
NP-ODE: Neural Process Aided Ordinary Differential Equations for Uncertainty Quantification of Finite Element Analysis
Dec 12, 2020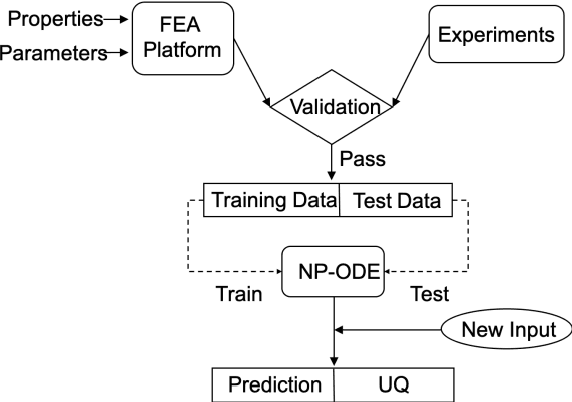
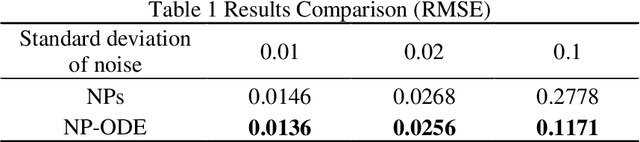
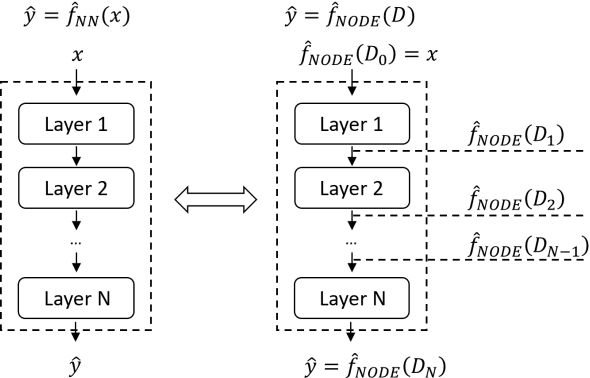
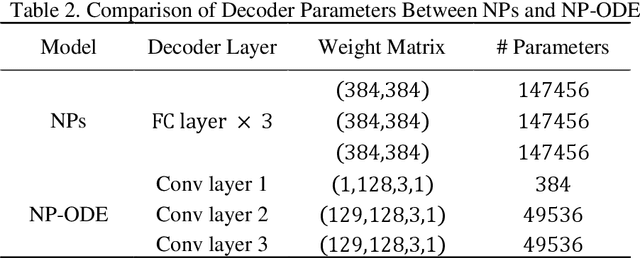
Finite element analysis (FEA) has been widely used to generate simulations of complex and nonlinear systems. Despite its strength and accuracy, the limitations of FEA can be summarized into two aspects: a) running high-fidelity FEA often requires significant computational cost and consumes a large amount of time; b) FEA is a deterministic method that is insufficient for uncertainty quantification (UQ) when modeling complex systems with various types of uncertainties. In this paper, a physics-informed data-driven surrogate model, named Neural Process Aided Ordinary Differential Equation (NP-ODE), is proposed to model the FEA simulations and capture both input and output uncertainties. To validate the advantages of the proposed NP-ODE, we conduct experiments on both the simulation data generated from a given ordinary differential equation and the data collected from a real FEA platform for tribocorrosion. The performances of the proposed NP-ODE and several benchmark methods are compared. The results show that the proposed NP-ODE outperforms benchmark methods. The NP-ODE method realizes the smallest predictive error as well as generates the most reasonable confidence interval having the best coverage on testing data points.
Coarse-grained and emergent distributed parameter systems from data
Nov 17, 2020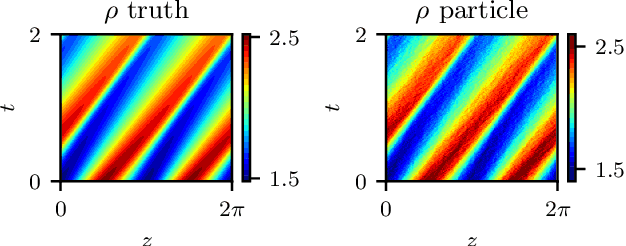
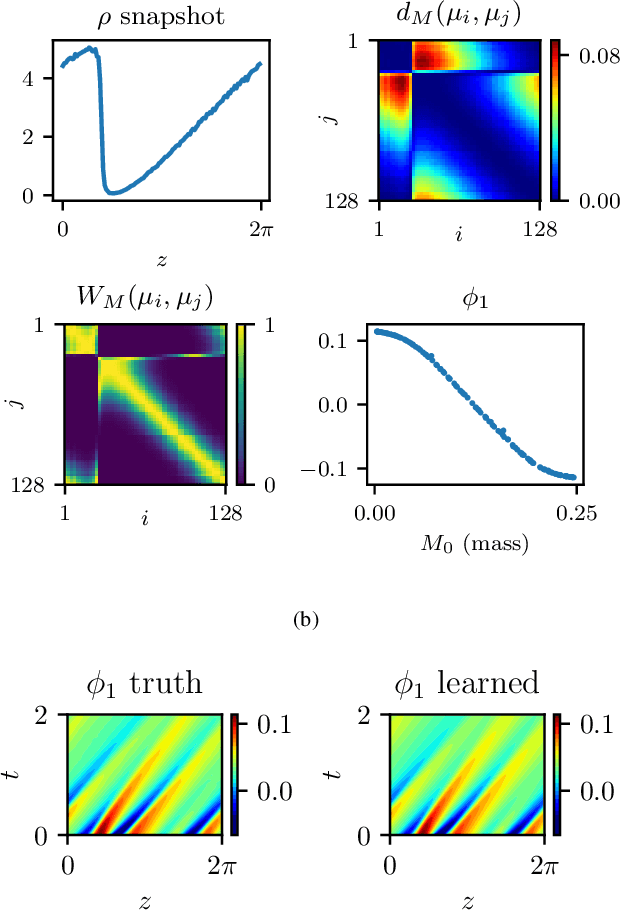
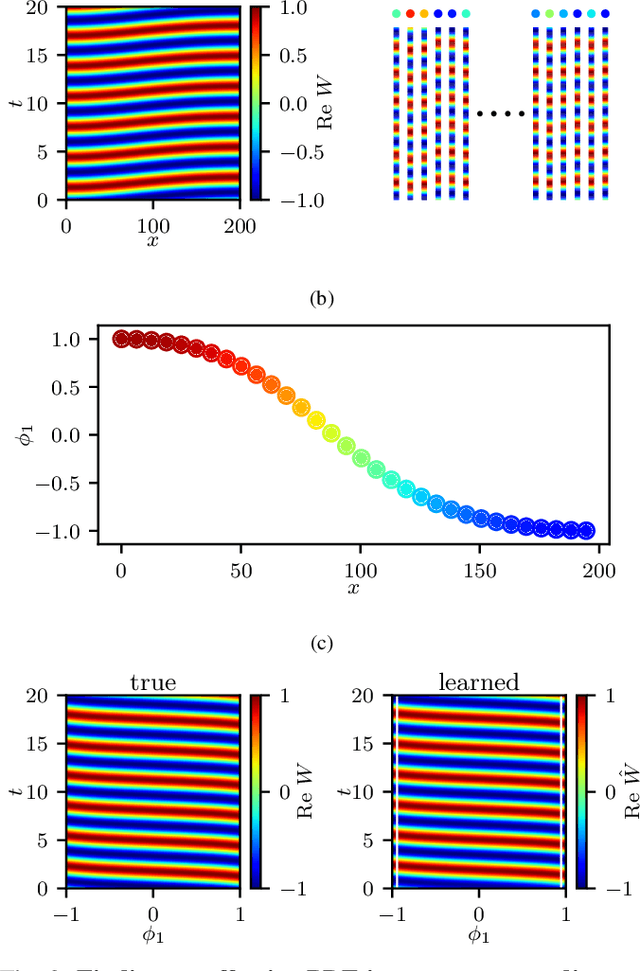
We explore the derivation of distributed parameter system evolution laws (and in particular, partial differential operators and associated partial differential equations, PDEs) from spatiotemporal data. This is, of course, a classical identification problem; our focus here is on the use of manifold learning techniques (and, in particular, variations of Diffusion Maps) in conjunction with neural network learning algorithms that allow us to attempt this task when the dependent variables, and even the independent variables of the PDE are not known a priori and must be themselves derived from the data. The similarity measure used in Diffusion Maps for dependent coarse variable detection involves distances between local particle distribution observations; for independent variable detection we use distances between local short-time dynamics. We demonstrate each approach through an illustrative established PDE example. Such variable-free, emergent space identification algorithms connect naturally with equation-free multiscale computation tools.