 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Evaluating (weighted) dynamic treatment effects by double machine learning
Dec 03, 2020

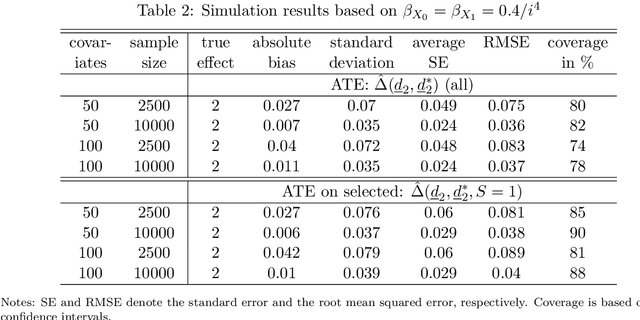

We consider evaluating the causal effects of dynamic treatments, i.e. of multiple treatment sequences in various periods, based on double machine learning to control for observed, time-varying covariates in a data-driven way under a selection-on-observables assumption. To this end, we make use of so-called Neyman-orthogonal score functions, which imply the robustness of treatment effect estimation to moderate (local) misspecifications of the dynamic outcome and treatment models. This robustness property permits approximating outcome and treatment models by double machine learning even under high dimensional covariates and is combined with data splitting to prevent overfitting. In addition to effect estimation for the total population, we consider weighted estimation that permits assessing dynamic treatment effects in specific subgroups, e.g. among those treated in the first treatment period. We demonstrate that the estimators are asymptotically normal and $\sqrt{n}$-consistent under specific regularity conditions and investigate their finite sample properties in a simulation study. Finally, we apply the methods to the Job Corps study in order to assess different sequences of training programs under a large set of covariates.
Contextual BERT: Conditioning the Language Model Using a Global State
Oct 29, 2020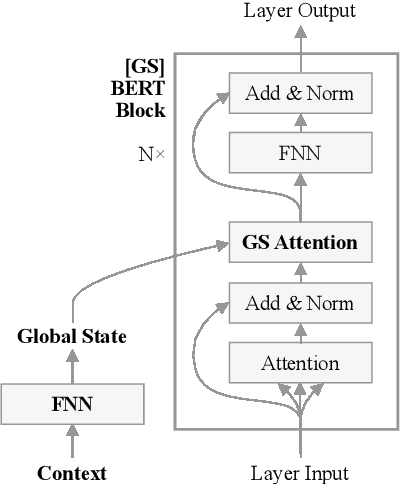

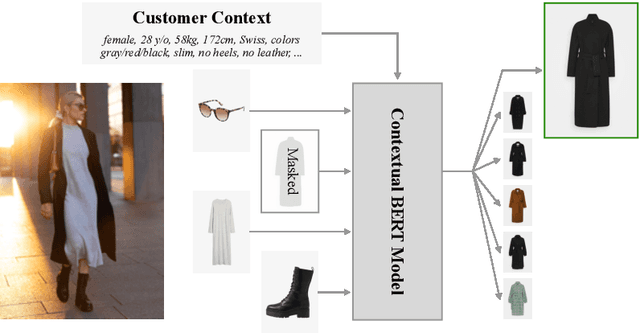
BERT is a popular language model whose main pre-training task is to fill in the blank, i.e., predicting a word that was masked out of a sentence, based on the remaining words. In some applications, however, having an additional context can help the model make the right prediction, e.g., by taking the domain or the time of writing into account. This motivates us to advance the BERT architecture by adding a global state for conditioning on a fixed-sized context. We present our two novel approaches and apply them to an industry use-case, where we complete fashion outfits with missing articles, conditioned on a specific customer. An experimental comparison to other methods from the literature shows that our methods improve personalization significantly.
UAV Trajectory and Communication Co-design: Flexible Path Discretization and Path Compression
Oct 14, 2020
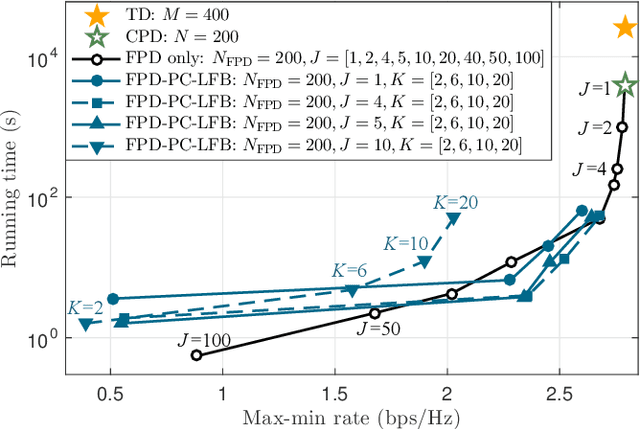
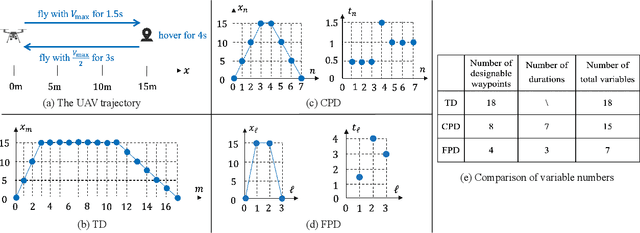
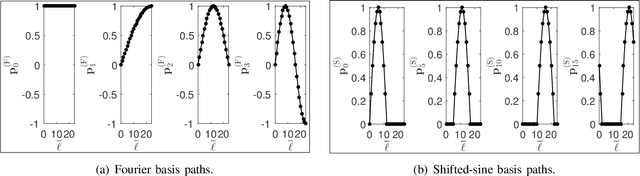
The performance optimization of UAV communication systems requires the joint design of UAV trajectory and communication efficiently. To tackle the challenge of infinite design variables arising from the continuous-time UAV trajectory optimization, a commonly adopted approach is by approximating the UAV trajectory with piecewise-linear path segments in three-dimensional (3D) space. However, this approach may still incur prohibitive computational complexity in practice when the UAV flight period/distance becomes long, as the distance between consecutive waypoints needs to be kept sufficiently small to retain high approximation accuracy. To resolve this fundamental issue, we propose in this paper a new and general framework for UAV trajectory and communication co-design. First, we propose a flexible path discretization scheme that optimizes only a number of selected waypoints (designable waypoints) along the UAV path for complexity reduction, while all the designable and non-designable waypoints are used in calculating the approximated communication utility along the UAV trajectory for ensuring high trajectory discretization accuracy. Next, given any number of designable waypoints, we propose a novel path compression scheme where the UAV 3D path is first decomposed into three one-dimensional (1D) sub-paths and each sub-path is then approximated by superimposing a number of selected basis paths weighted by their corresponding path coefficients, thus further reducing the path design complexity. Finally, we provide a case study on UAV trajectory design for aerial data harvesting from distributed ground sensors, and numerically show that the proposed schemes can significantly reduce the UAV trajectory design complexity yet achieve favorable rate performance as compared to conventional path/time discretization schemes.
Frame-To-Frame Consistent Semantic Segmentation
Aug 20, 2020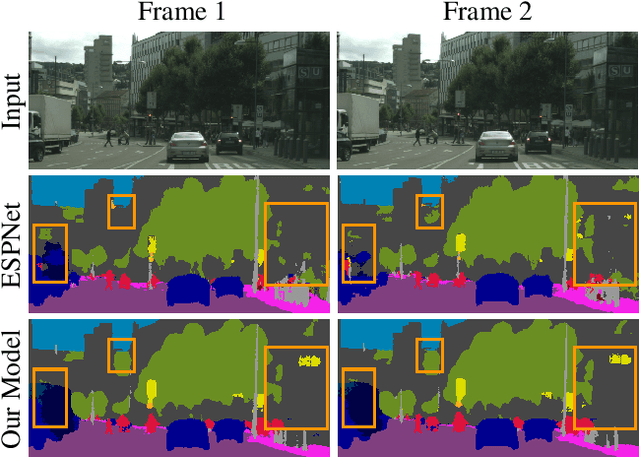
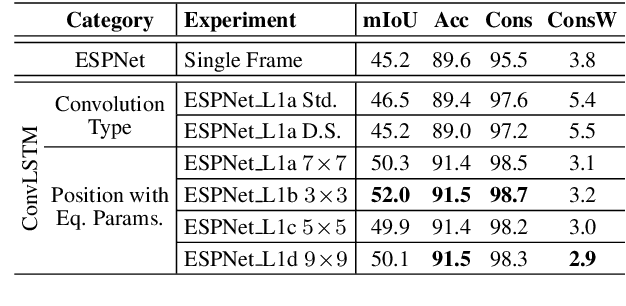
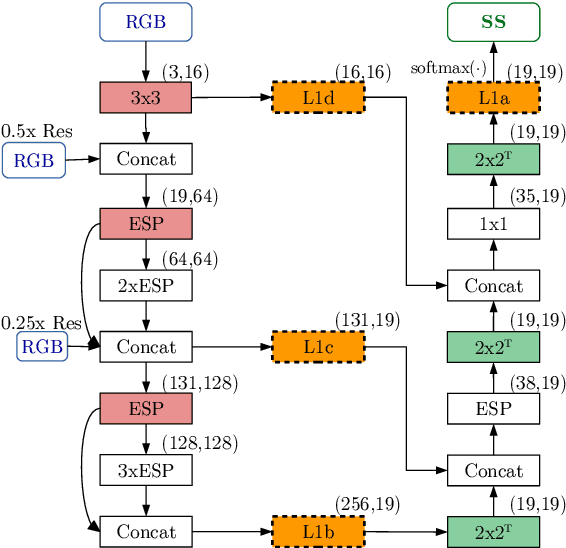
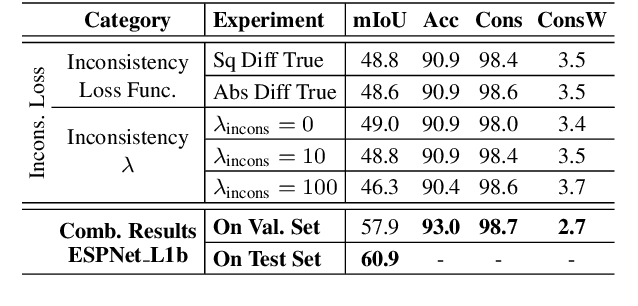
In this work, we aim for temporally consistent semantic segmentation throughout frames in a video. Many semantic segmentation algorithms process images individually which leads to an inconsistent scene interpretation due to illumination changes, occlusions and other variations over time. To achieve a temporally consistent prediction, we train a convolutional neural network (CNN) which propagates features through consecutive frames in a video using a convolutional long short term memory (ConvLSTM) cell. Besides the temporal feature propagation, we penalize inconsistencies in our loss function. We show in our experiments that the performance improves when utilizing video information compared to single frame prediction. The mean intersection over union (mIoU) metric on the Cityscapes validation set increases from 45.2 % for the single frames to 57.9 % for video data after implementing the ConvLSTM to propagate features trough time on the ESPNet. Most importantly, inconsistency decreases from 4.5 % to 1.3 % which is a reduction by 71.1 %. Our results indicate that the added temporal information produces a frame-to-frame consistent and more accurate image understanding compared to single frame processing.
Explainability Matters: Backdoor Attacks on Medical Imaging
Dec 30, 2020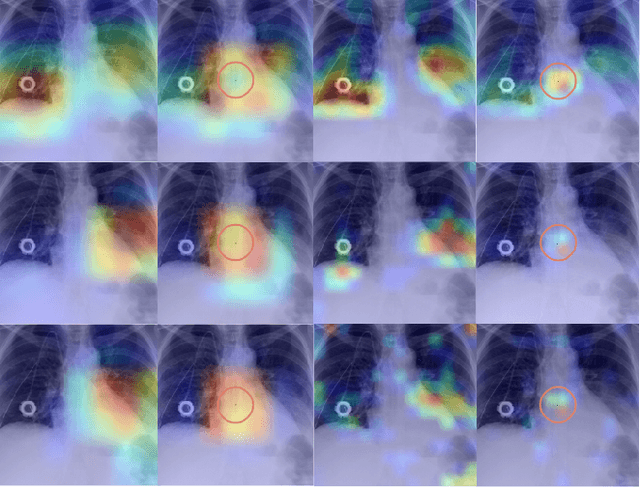
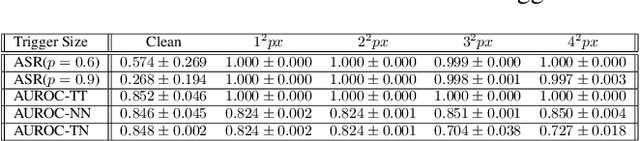
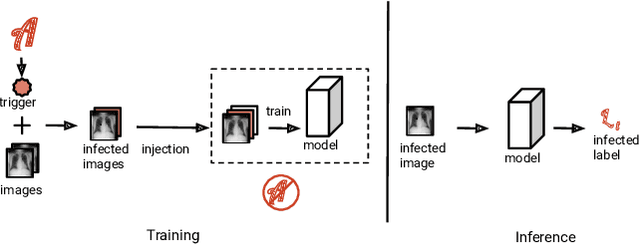
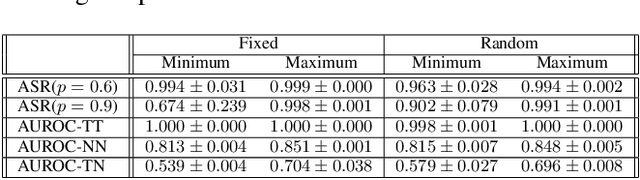
Deep neural networks have been shown to be vulnerable to backdoor attacks, which could be easily introduced to the training set prior to model training. Recent work has focused on investigating backdoor attacks on natural images or toy datasets. Consequently, the exact impact of backdoors is not yet fully understood in complex real-world applications, such as in medical imaging where misdiagnosis can be very costly. In this paper, we explore the impact of backdoor attacks on a multi-label disease classification task using chest radiography, with the assumption that the attacker can manipulate the training dataset to execute the attack. Extensive evaluation of a state-of-the-art architecture demonstrates that by introducing images with few-pixel perturbations into the training set, an attacker can execute the backdoor successfully without having to be involved with the training procedure. A simple 3$\times$3 pixel trigger can achieve up to 1.00 Area Under the Receiver Operating Characteristic (AUROC) curve on the set of infected images. In the set of clean images, the backdoored neural network could still achieve up to 0.85 AUROC, highlighting the stealthiness of the attack. As the use of deep learning based diagnostic systems proliferates in clinical practice, we also show how explainability is indispensable in this context, as it can identify spatially localized backdoors in inference time.
SAFCAR: Structured Attention Fusion for Compositional Action Recognition
Dec 03, 2020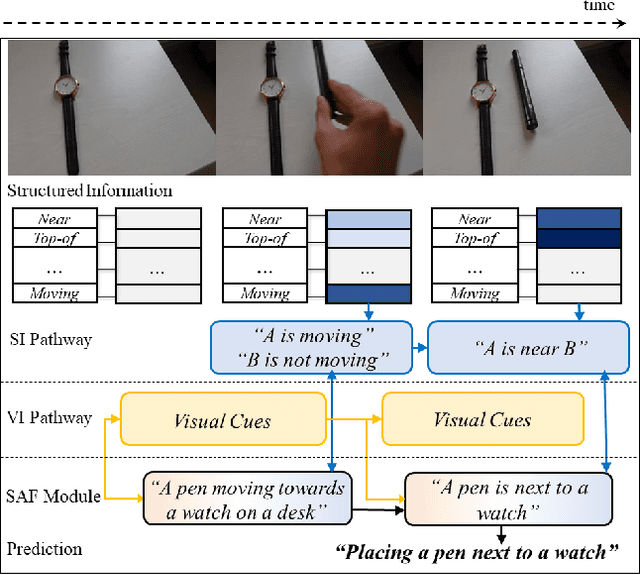
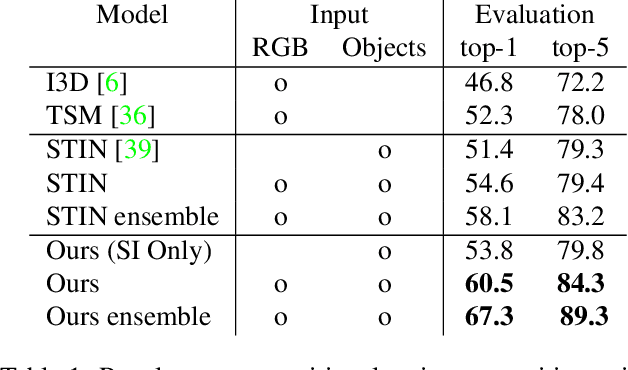
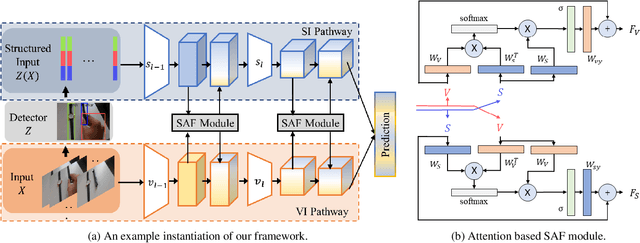
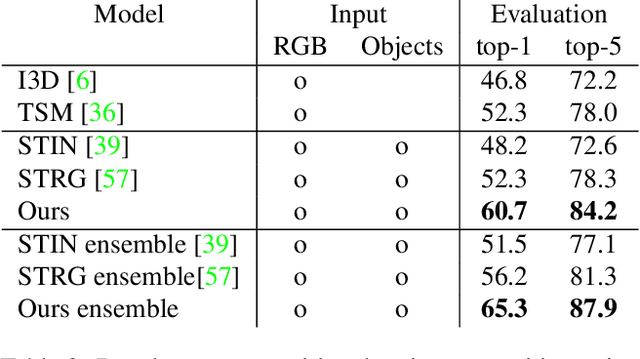
We present a general framework for compositional action recognition -- i.e. action recognition where the labels are composed out of simpler components such as subjects, atomic-actions and objects. The main challenge in compositional action recognition is that there is a combinatorially large set of possible actions that can be composed using basic components. However, compositionality also provides a structure that can be exploited. To do so, we develop and test a novel Structured Attention Fusion (SAF) self-attention mechanism to combine information from object detections, which capture the time-series structure of an action, with visual cues that capture contextual information. We show that our approach recognizes novel verb-noun compositions more effectively than current state of the art systems, and it generalizes to unseen action categories quite efficiently from only a few labeled examples. We validate our approach on the challenging Something-Else tasks from the Something-Something-V2 dataset. We further show that our framework is flexible and can generalize to a new domain by showing competitive results on the Charades-Fewshot dataset.
WaveFuse: A Unified Deep Framework for Image Fusion with Wavelet Transform
Jul 28, 2020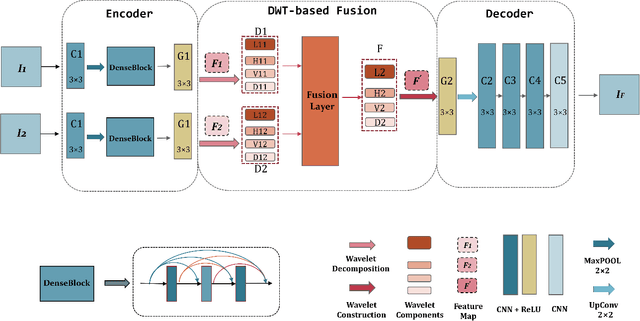
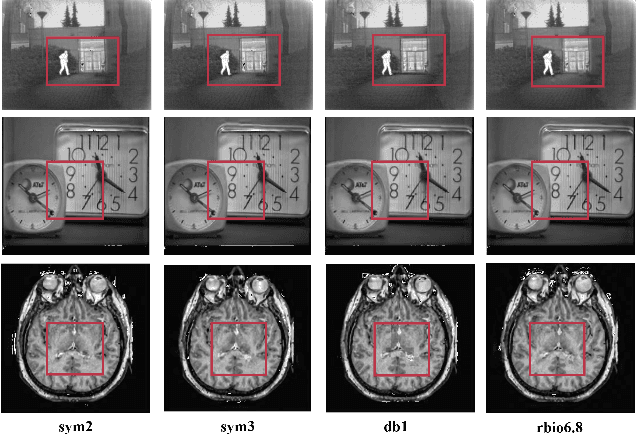
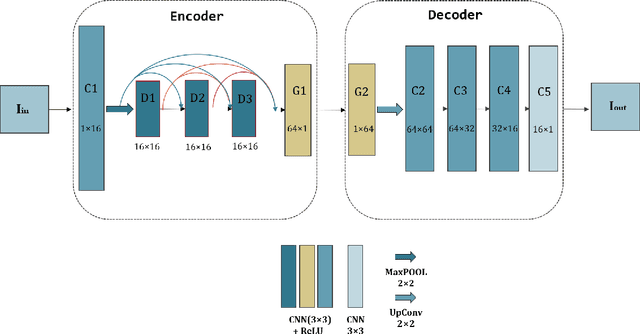
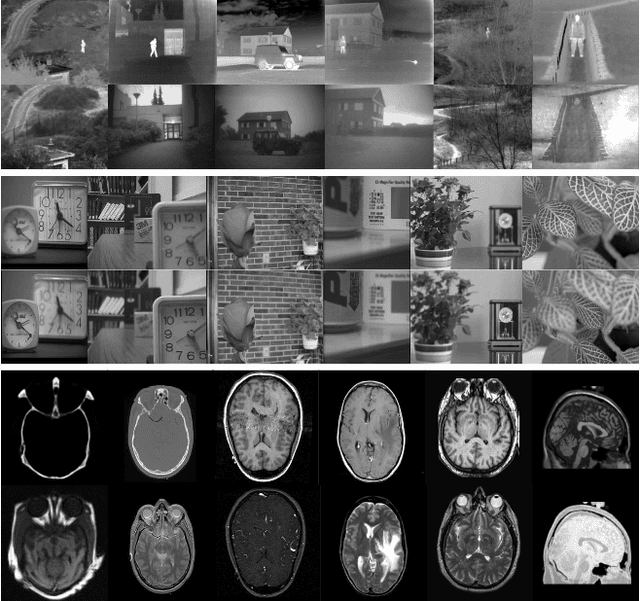
We propose an unsupervised image fusion architecture for multiple application scenarios based on the combination of multi-scale discrete wavelet transform through regional energy and deep learning. To our best knowledge, this is the first time the conventional image fusion method has been combined with deep learning. The useful information of feature maps can be utilized adequately through multi-scale discrete wavelet transform in our proposed method.Compared with other state-of-the-art fusion method, the proposed algorithm exhibits better fusion performance in both subjective and objective evaluation. Moreover, it's worth mentioning that comparable fusion performance trained in COCO dataset can be obtained by training with a much smaller dataset with only hundreds of images chosen randomly from COCO. Hence, the training time is shortened substantially, leading to the improvement of the model's performance both in practicality and training efficiency.
Continual Adaptation for Deep Stereo
Jul 10, 2020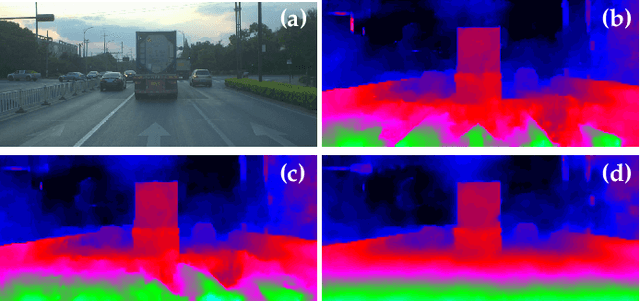
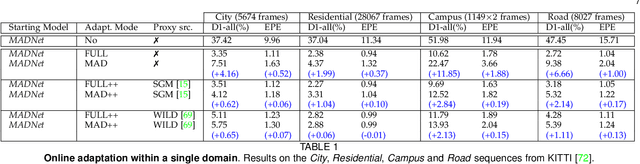
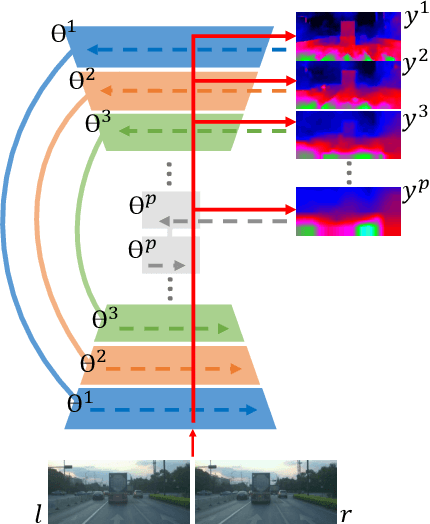

Depth estimation from stereo images is carried out with unmatched results by convolutional neural networks trained end-to-end to regress dense disparities. Like for most tasks, this is possible if large amounts of labelled samples are available for training, possibly covering the whole data distribution encountered at deployment time. Being such an assumption systematically met in real applications, the capacity of adapting to any unseen setting becomes of paramount importance. Purposely, we propose a continual adaptation paradigm for deep stereo networks designed to deal with challenging and ever-changing environments. We design a lightweight and modular architecture, Modularly ADaptive Network (MADNet), and formulate Modular ADaptation algorithms(MAD,MAD++) which permit efficient optimization of independent sub-portions of the entire network. In our paradigm the learning signals needed to continuously adapt models online can be sourced from self-supervision via right-to-left image warping or from traditional stereo algorithms. With both sources no other data than the input images being gathered at deployment time are needed.Thus, our network architecture and adaptation algorithms realize the first real-time self-adaptive deep stereo system and pave the way for a new paradigm that can facilitate practical deployment of end-to-end architectures for dense disparity regression.
LINDT: Tackling Negative Federated Learning with Local Adaptation
Nov 23, 2020
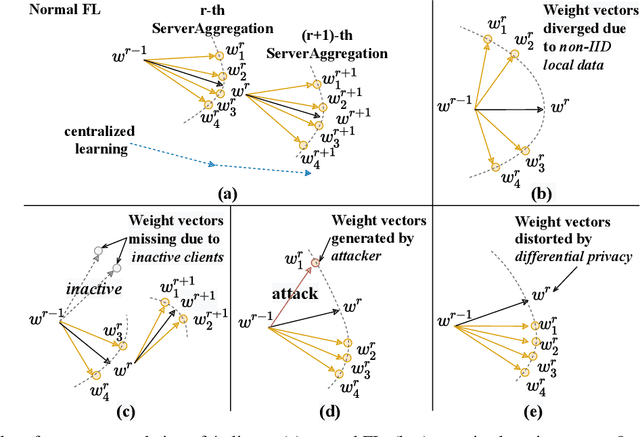
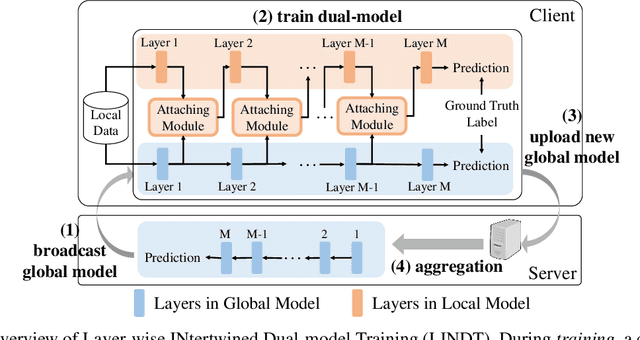

Federated Learning (FL) is a promising distributed learning paradigm, which allows a number of data owners (also called clients) to collaboratively learn a shared model without disclosing each client's data. However, FL may fail to proceed properly, amid a state that we call negative federated learning (NFL). This paper addresses the problem of negative federated learning. We formulate a rigorous definition of NFL and analyze its essential cause. We propose a novel framework called LINDT for tackling NFL in run-time. The framework can potentially work with any neural-network-based FL systems for NFL detection and recovery. Specifically, we introduce a metric for detecting NFL from the server. On occasion of NFL recovery, the framework makes adaptation to the federated model on each client's local data by learning a Layer-wise Intertwined Dual-model. Experiment results show that the proposed approach can significantly improve the performance of FL on local data in various scenarios of NFL.
Contrastive Learning for Label-Efficient Semantic Segmentation
Dec 13, 2020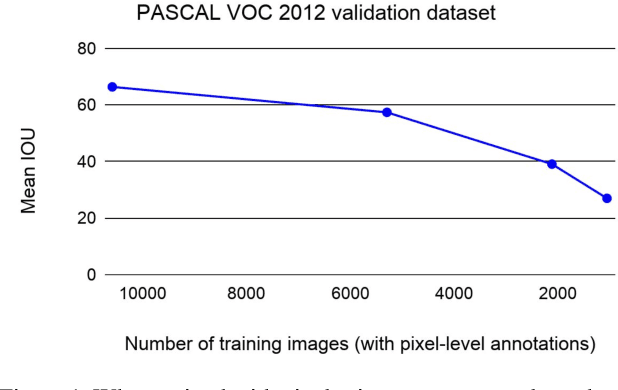



Collecting labeled data for the task of semantic segmentation is expensive and time-consuming, as it requires dense pixel-level annotations. While recent Convolutional Neural Network (CNN) based semantic segmentation approaches have achieved impressive results by using large amounts of labeled training data, their performance drops significantly as the amount of labeled data decreases. This happens because deep CNNs trained with the de facto cross-entropy loss can easily overfit to small amounts of labeled data. To address this issue, we propose a simple and effective contrastive learning-based training strategy in which we first pretrain the network using a pixel-wise class label-based contrastive loss, and then fine-tune it using the cross-entropy loss. This approach increases intra-class compactness and inter-class separability thereby resulting in a better pixel classifier. We demonstrate the effectiveness of the proposed training strategy in both fully-supervised and semi-supervised settings using the Cityscapes and PASCAL VOC 2012 segmentation datasets. Our results show that pretraining with label-based contrastive loss results in large performance gains (more than 20% absolute improvement in some settings) when the amount of labeled data is limited.