 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
How Shift Equivariance Impacts Metric Learning for Instance Segmentation
Jan 14, 2021
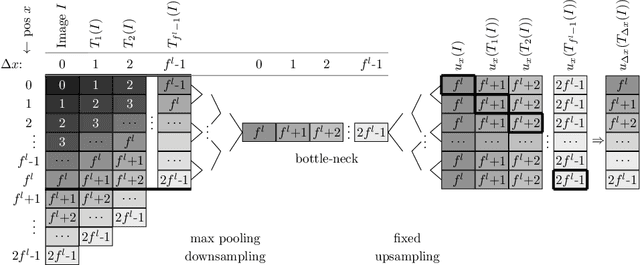

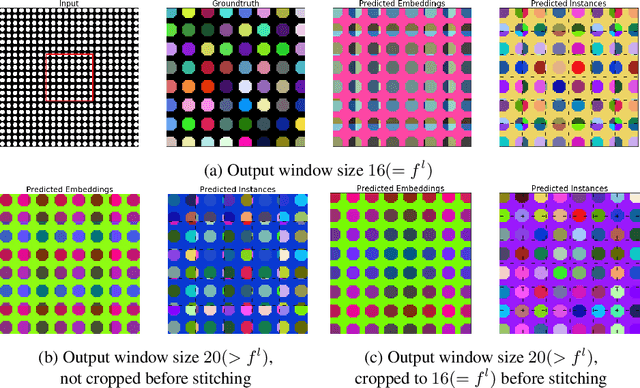

Metric learning has received conflicting assessments concerning its suitability for solving instance segmentation tasks. It has been dismissed as theoretically flawed due to the shift equivariance of the employed CNNs and their respective inability to distinguish same-looking objects. Yet it has been shown to yield state of the art results for a variety of tasks, and practical issues have mainly been reported in the context of tile-and-stitch approaches, where discontinuities at tile boundaries have been observed. To date, neither of the reported issues have undergone thorough formal analysis. In our work, we contribute a comprehensive formal analysis of the shift equivariance properties of encoder-decoder-style CNNs, which yields a clear picture of what can and cannot be achieved with metric learning in the face of same-looking objects. In particular, we prove that a standard encoder-decoder network that takes $d$-dimensional images as input, with $l$ pooling layers and pooling factor $f$, has the capacity to distinguish at most $f^{dl}$ same-looking objects, and we show that this upper limit can be reached. Furthermore, we show that to avoid discontinuities in a tile-and-stitch approach, assuming standard batch size 1, it is necessary to employ valid convolutions in combination with a training output window size strictly greater than $f^l$, while at test-time it is necessary to crop tiles to size $n\cdot f^l$ before stitching, with $n\geq 1$. We complement these theoretical findings by discussing a number of insightful special cases for which we show empirical results on synthetic data.
Deep Portfolio Optimization via Distributional Prediction of Residual Factors
Dec 14, 2020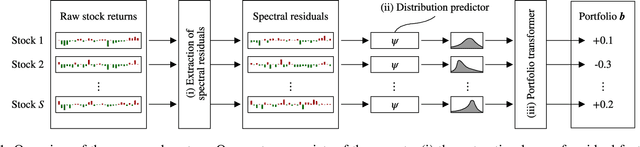
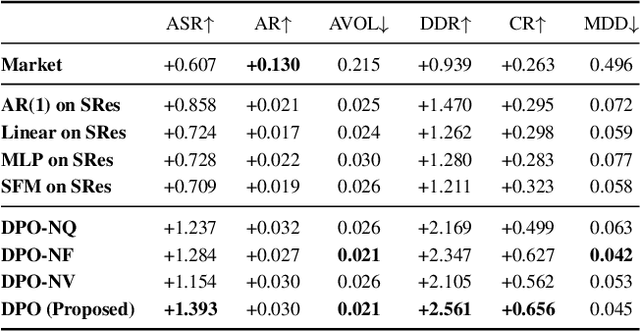
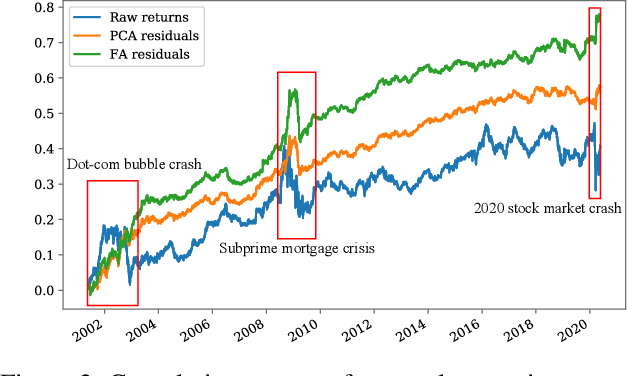
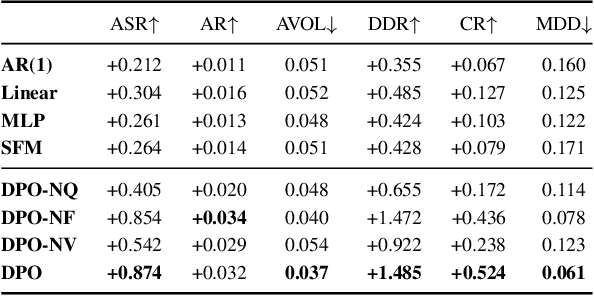
Recent developments in deep learning techniques have motivated intensive research in machine learning-aided stock trading strategies. However, since the financial market has a highly non-stationary nature hindering the application of typical data-hungry machine learning methods, leveraging financial inductive biases is important to ensure better sample efficiency and robustness. In this study, we propose a novel method of constructing a portfolio based on predicting the distribution of a financial quantity called residual factors, which is known to be generally useful for hedging the risk exposure to common market factors. The key technical ingredients are twofold. First, we introduce a computationally efficient extraction method for the residual information, which can be easily combined with various prediction algorithms. Second, we propose a novel neural network architecture that allows us to incorporate widely acknowledged financial inductive biases such as amplitude invariance and time-scale invariance. We demonstrate the efficacy of our method on U.S. and Japanese stock market data. Through ablation experiments, we also verify that each individual technique contributes to improving the performance of trading strategies. We anticipate our techniques may have wide applications in various financial problems.
Deep Optimized Priors for 3D Shape Modeling and Reconstruction
Dec 14, 2020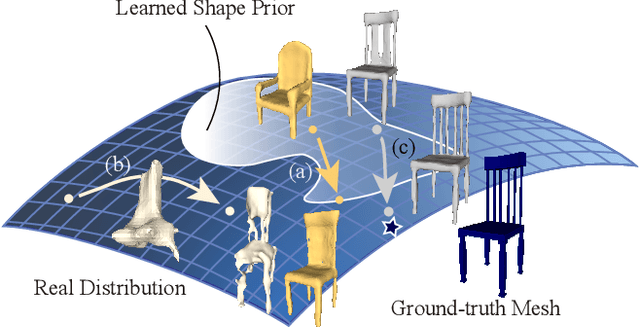
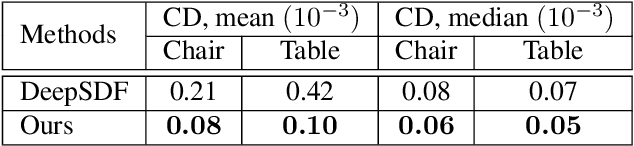
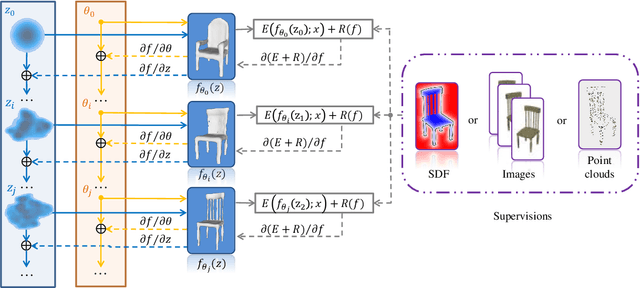
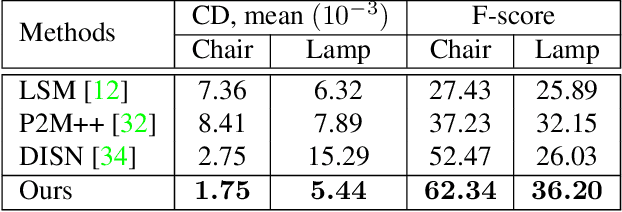
Many learning-based approaches have difficulty scaling to unseen data, as the generality of its learned prior is limited to the scale and variations of the training samples. This holds particularly true with 3D learning tasks, given the sparsity of 3D datasets available. We introduce a new learning framework for 3D modeling and reconstruction that greatly improves the generalization ability of a deep generator. Our approach strives to connect the good ends of both learning-based and optimization-based methods. In particular, unlike the common practice that fixes the pre-trained priors at test time, we propose to further optimize the learned prior and latent code according to the input physical measurements after the training. We show that the proposed strategy effectively breaks the barriers constrained by the pre-trained priors and could lead to high-quality adaptation to unseen data. We realize our framework using the implicit surface representation and validate the efficacy of our approach in a variety of challenging tasks that take highly sparse or collapsed observations as input. Experimental results show that our approach compares favorably with the state-of-the-art methods in terms of both generality and accuracy.
Physics-aware, probabilistic model order reduction with guaranteed stability
Jan 14, 2021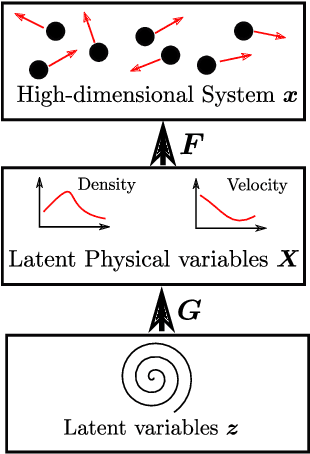
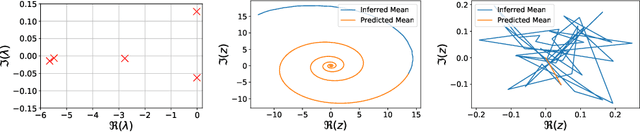
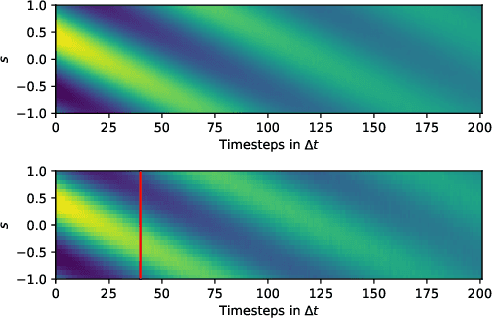

Given (small amounts of) time-series' data from a high-dimensional, fine-grained, multiscale dynamical system, we propose a generative framework for learning an effective, lower-dimensional, coarse-grained dynamical model that is predictive of the fine-grained system's long-term evolution but also of its behavior under different initial conditions. We target fine-grained models as they arise in physical applications (e.g. molecular dynamics, agent-based models), the dynamics of which are strongly non-stationary but their transition to equilibrium is governed by unknown slow processes which are largely inaccessible by brute-force simulations. Approaches based on domain knowledge heavily rely on physical insight in identifying temporally slow features and fail to enforce the long-term stability of the learned dynamics. On the other hand, purely statistical frameworks lack interpretability and rely on large amounts of expensive simulation data (long and multiple trajectories) as they cannot infuse domain knowledge. The generative framework proposed achieves the aforementioned desiderata by employing a flexible prior on the complex plane for the latent, slow processes, and an intermediate layer of physics-motivated latent variables that reduces reliance on data and imbues inductive bias. In contrast to existing schemes, it does not require the a priori definition of projection operators from the fine-grained description and addresses simultaneously the tasks of dimensionality reduction and model estimation. We demonstrate its efficacy and accuracy in multiscale physical systems of particle dynamics where probabilistic, long-term predictions of phenomena not contained in the training data are produced.
Continual Adaptation for Deep Stereo
Jul 10, 2020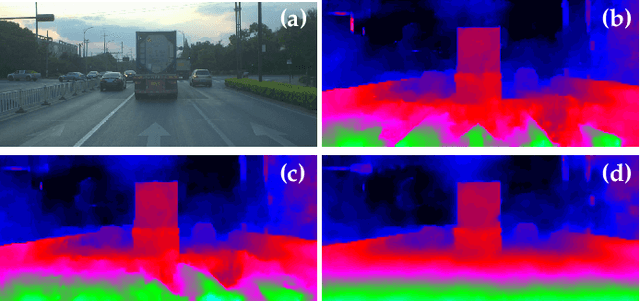
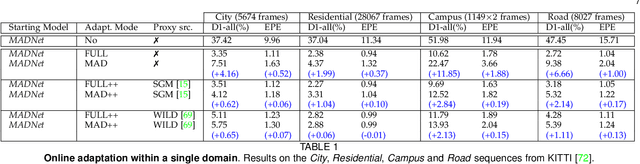
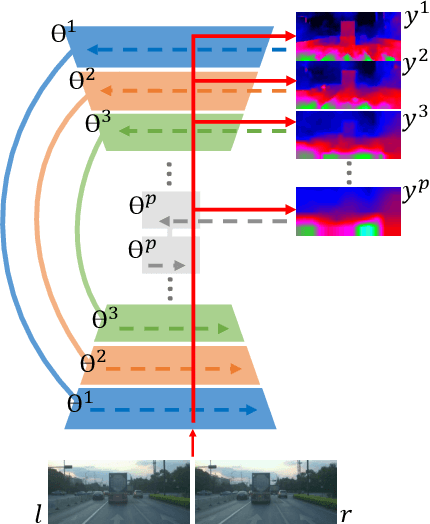

Depth estimation from stereo images is carried out with unmatched results by convolutional neural networks trained end-to-end to regress dense disparities. Like for most tasks, this is possible if large amounts of labelled samples are available for training, possibly covering the whole data distribution encountered at deployment time. Being such an assumption systematically met in real applications, the capacity of adapting to any unseen setting becomes of paramount importance. Purposely, we propose a continual adaptation paradigm for deep stereo networks designed to deal with challenging and ever-changing environments. We design a lightweight and modular architecture, Modularly ADaptive Network (MADNet), and formulate Modular ADaptation algorithms(MAD,MAD++) which permit efficient optimization of independent sub-portions of the entire network. In our paradigm the learning signals needed to continuously adapt models online can be sourced from self-supervision via right-to-left image warping or from traditional stereo algorithms. With both sources no other data than the input images being gathered at deployment time are needed.Thus, our network architecture and adaptation algorithms realize the first real-time self-adaptive deep stereo system and pave the way for a new paradigm that can facilitate practical deployment of end-to-end architectures for dense disparity regression.
Median regression with differential privacy
Jun 04, 2020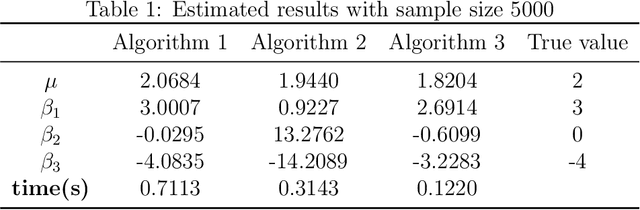
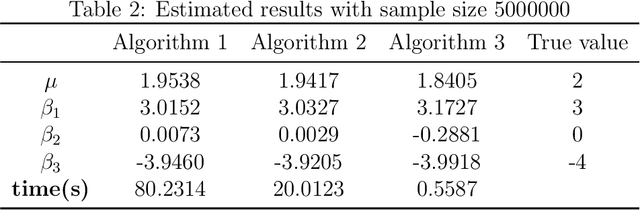
Median regression analysis has robustness properties which make it attractive compared with regression based on the mean, while differential privacy can protect individual privacy during statistical analysis of certain datasets. In this paper, three privacy preserving methods are proposed for median regression. The first algorithm is based on a finite smoothing method, the second provides an iterative way and the last one further employs the greedy coordinate descent approach. Privacy preserving properties of these three methods are all proved. Accuracy bound or convergence properties of these algorithms are also provided. Numerical calculation shows that the first method has better accuracy than the others when the sample size is small. When the sample size becomes larger, the first method needs more time while the second method needs less time with well-matched accuracy. For the third method, it costs less time in both cases, while it highly depends on step size.
Learning Deep ReLU Networks Is Fixed-Parameter Tractable
Sep 28, 2020We consider the problem of learning an unknown ReLU network with respect to Gaussian inputs and obtain the first nontrivial results for networks of depth more than two. We give an algorithm whose running time is a fixed polynomial in the ambient dimension and some (exponentially large) function of only the network's parameters. Our bounds depend on the number of hidden units, depth, spectral norm of the weight matrices, and Lipschitz constant of the overall network (we show that some dependence on the Lipschitz constant is necessary). We also give a bound that is doubly exponential in the size of the network but is independent of spectral norm. These results provably cannot be obtained using gradient-based methods and give the first example of a class of efficiently learnable neural networks that gradient descent will fail to learn. In contrast, prior work for learning networks of depth three or higher requires exponential time in the ambient dimension, even when the above parameters are bounded by a constant. Additionally, all prior work for the depth-two case requires well-conditioned weights and/or positive coefficients to obtain efficient run-times. Our algorithm does not require these assumptions. Our main technical tool is a type of filtered PCA that can be used to iteratively recover an approximate basis for the subspace spanned by the hidden units in the first layer. Our analysis leverages new structural results on lattice polynomials from tropical geometry.
WaveFuse: A Unified Deep Framework for Image Fusion with Wavelet Transform
Jul 28, 2020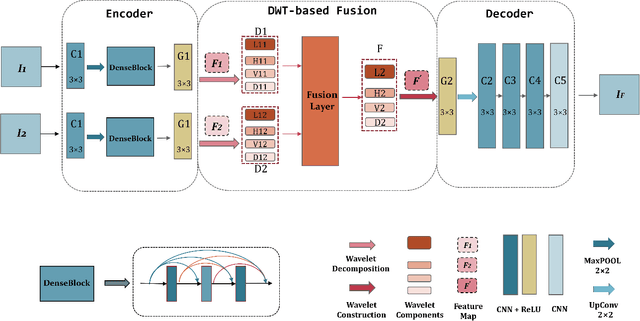
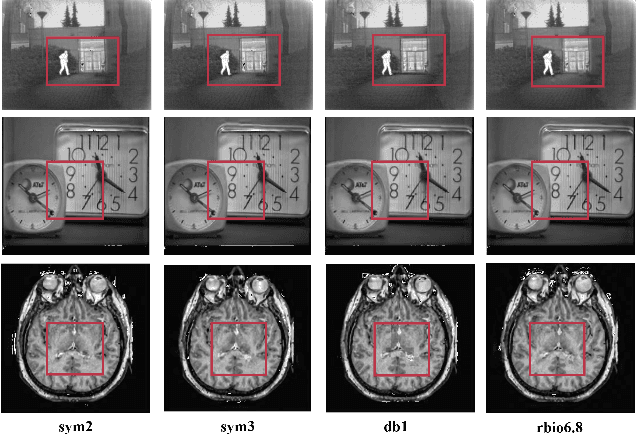
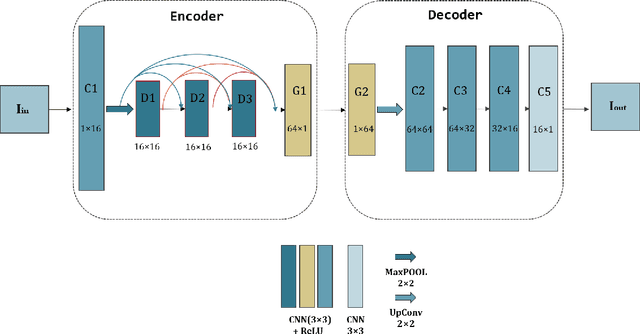
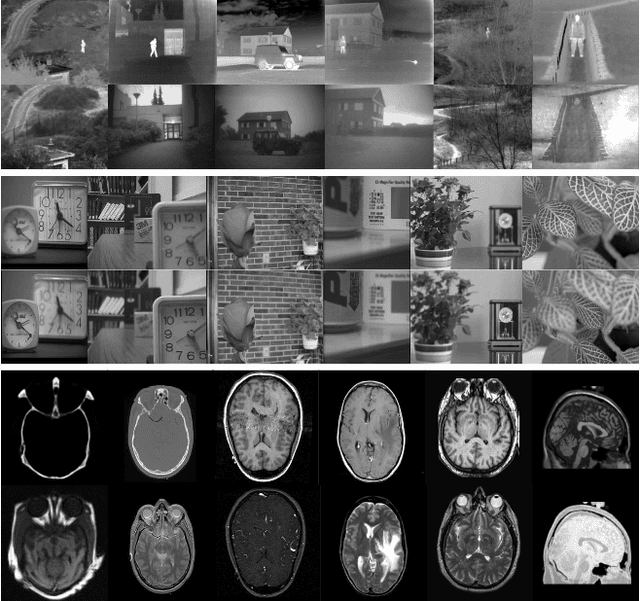
We propose an unsupervised image fusion architecture for multiple application scenarios based on the combination of multi-scale discrete wavelet transform through regional energy and deep learning. To our best knowledge, this is the first time the conventional image fusion method has been combined with deep learning. The useful information of feature maps can be utilized adequately through multi-scale discrete wavelet transform in our proposed method.Compared with other state-of-the-art fusion method, the proposed algorithm exhibits better fusion performance in both subjective and objective evaluation. Moreover, it's worth mentioning that comparable fusion performance trained in COCO dataset can be obtained by training with a much smaller dataset with only hundreds of images chosen randomly from COCO. Hence, the training time is shortened substantially, leading to the improvement of the model's performance both in practicality and training efficiency.
The Life and Death of SSDs and HDDs: Similarities, Differences, and Prediction Models
Dec 22, 2020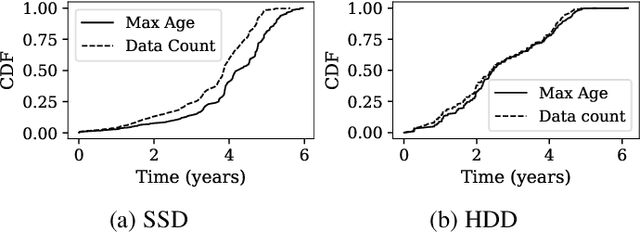
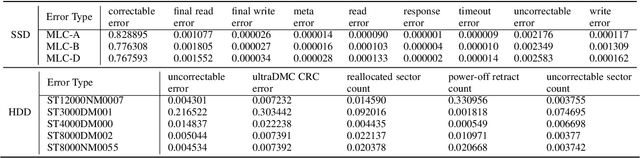
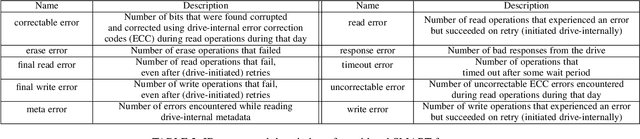
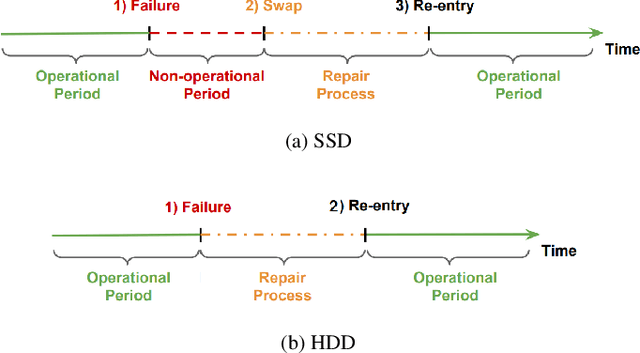
Data center downtime typically centers around IT equipment failure. Storage devices are the most frequently failing components in data centers. We present a comparative study of hard disk drives (HDDs) and solid state drives (SSDs) that constitute the typical storage in data centers. Using a six-year field data of 100,000 HDDs of different models from the same manufacturer from the BackBlaze dataset and a six-year field data of 30,000 SSDs of three models from a Google data center, we characterize the workload conditions that lead to failures and illustrate that their root causes differ from common expectation but remain difficult to discern. For the case of HDDs we observe that young and old drives do not present many differences in their failures. Instead, failures may be distinguished by discriminating drives based on the time spent for head positioning. For SSDs, we observe high levels of infant mortality and characterize the differences between infant and non-infant failures. We develop several machine learning failure prediction models that are shown to be surprisingly accurate, achieving high recall and low false positive rates. These models are used beyond simple prediction as they aid us to untangle the complex interaction of workload characteristics that lead to failures and identify failure root causes from monitored symptoms.
Frame-To-Frame Consistent Semantic Segmentation
Aug 20, 2020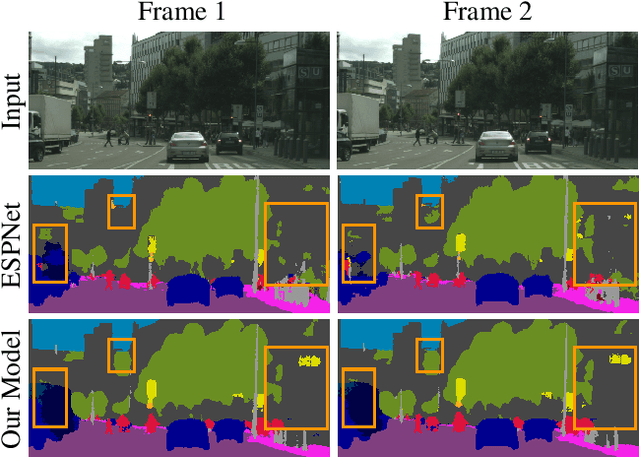
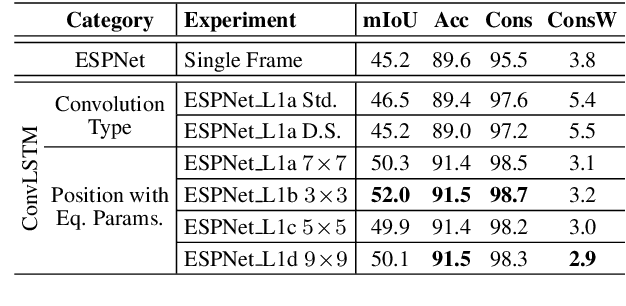
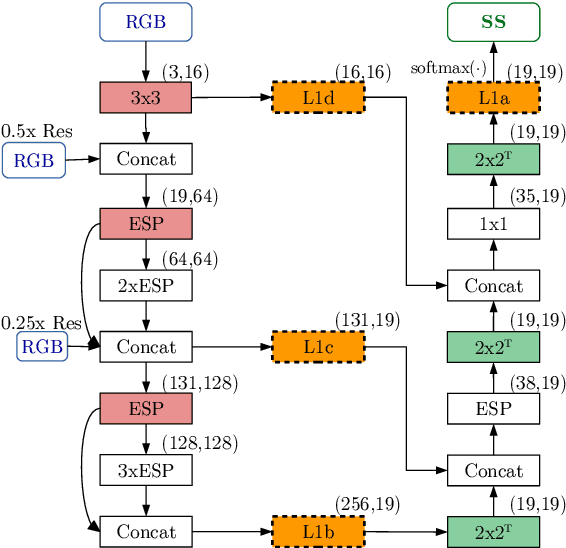
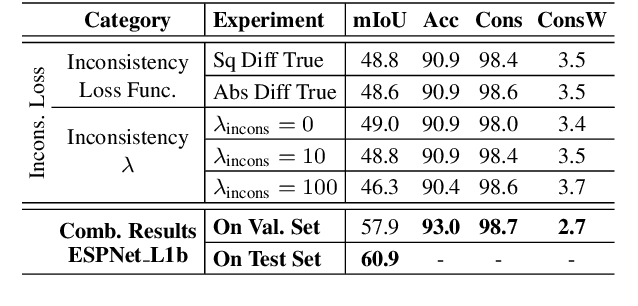
In this work, we aim for temporally consistent semantic segmentation throughout frames in a video. Many semantic segmentation algorithms process images individually which leads to an inconsistent scene interpretation due to illumination changes, occlusions and other variations over time. To achieve a temporally consistent prediction, we train a convolutional neural network (CNN) which propagates features through consecutive frames in a video using a convolutional long short term memory (ConvLSTM) cell. Besides the temporal feature propagation, we penalize inconsistencies in our loss function. We show in our experiments that the performance improves when utilizing video information compared to single frame prediction. The mean intersection over union (mIoU) metric on the Cityscapes validation set increases from 45.2 % for the single frames to 57.9 % for video data after implementing the ConvLSTM to propagate features trough time on the ESPNet. Most importantly, inconsistency decreases from 4.5 % to 1.3 % which is a reduction by 71.1 %. Our results indicate that the added temporal information produces a frame-to-frame consistent and more accurate image understanding compared to single frame processing.