 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Accurate Cell Segmentation in Digital Pathology Images via Attention Enforced Networks
Dec 14, 2020

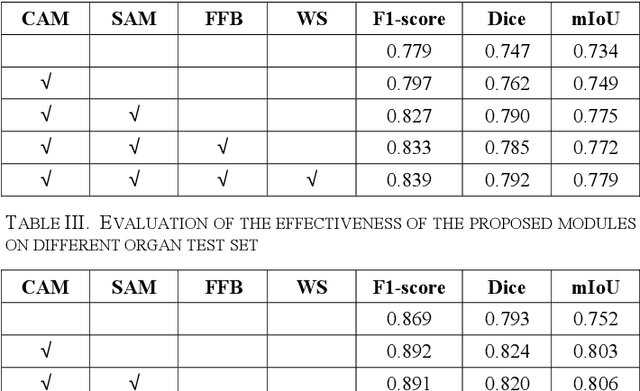
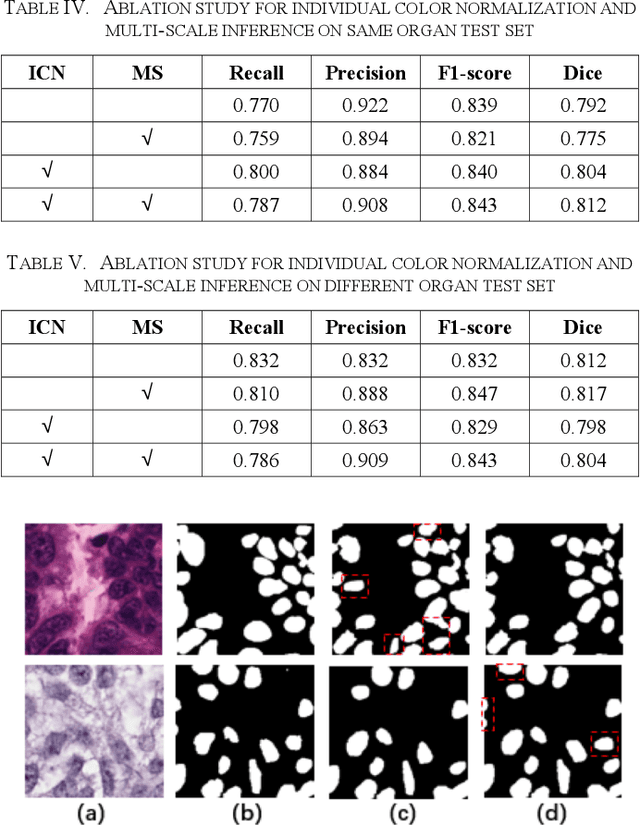

Automatic cell segmentation is an essential step in the pipeline of computer-aided diagnosis (CAD), such as the detection and grading of breast cancer. Accurate segmentation of cells can not only assist the pathologists to make a more precise diagnosis, but also save much time and labor. However, this task suffers from stain variation, cell inhomogeneous intensities, background clutters and cells from different tissues. To address these issues, we propose an Attention Enforced Network (AENet), which is built on spatial attention module and channel attention module, to integrate local features with global dependencies and weight effective channels adaptively. Besides, we introduce a feature fusion branch to bridge high-level and low-level features. Finally, the marker controlled watershed algorithm is applied to post-process the predicted segmentation maps for reducing the fragmented regions. In the test stage, we present an individual color normalization method to deal with the stain variation problem. We evaluate this model on the MoNuSeg dataset. The quantitative comparisons against several prior methods demonstrate the superiority of our approach.
Rewriter-Evaluator Framework for Neural Machine Translation
Dec 14, 2020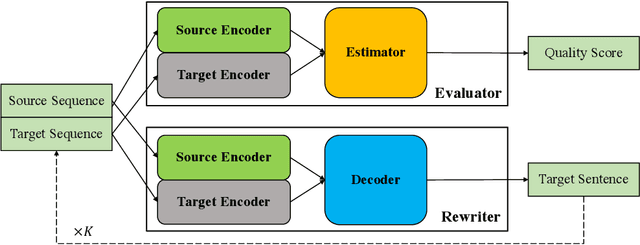
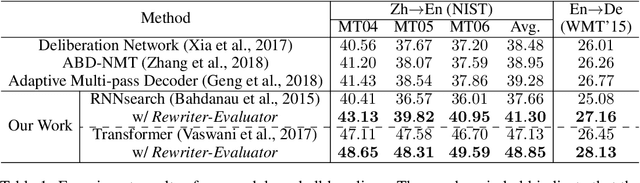
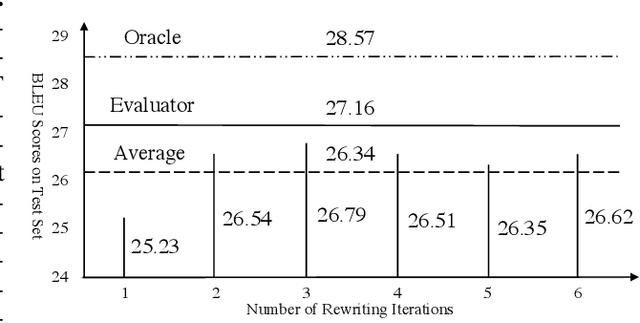
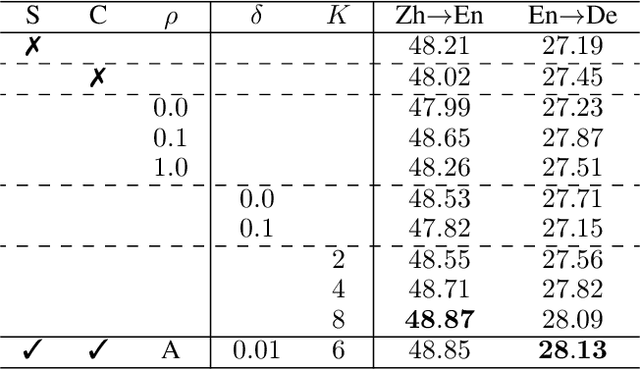
Encoder-decoder architecture has been widely used in neural machine translation (NMT). A few methods have been proposed to improve it with multiple passes of decoding. However, their full potential is limited by a lack of appropriate termination policy. To address this issue, we present a novel framework, Rewriter-Evaluator. It consists of a rewriter and an evaluator. Translating a source sentence involves multiple passes. At every pass, the rewriter produces a new translation to improve the past translation and the evaluator estimates the translation quality to decide whether to terminate the rewriting process. We also propose a prioritized gradient descent (PGD) method that facilitates training the rewriter and the evaluator jointly. Though incurring multiple passes of decoding, Rewriter-Evaluator with the proposed PGD method can be trained with similar time to that of training encoder-decoder models. We apply the proposed framework to improve the general NMT models (e.g., Transformer). We conduct extensive experiments on two translation tasks, Chinese-English and English-German, and show that the proposed framework notably improves the performances of NMT models and significantly outperforms previous baselines.
A Data Stream Ensemble Assisted Multifactorial Evolutionary Algorithm for Offline Data-driven Dynamic Optimization
Dec 14, 2020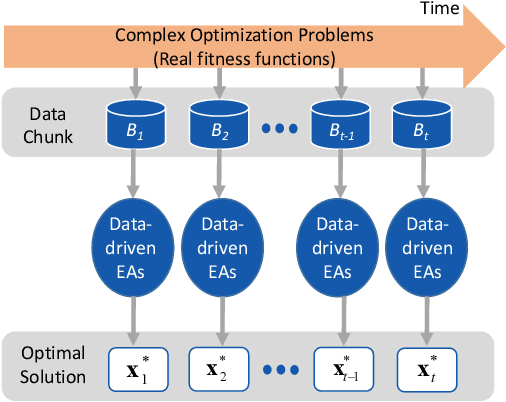
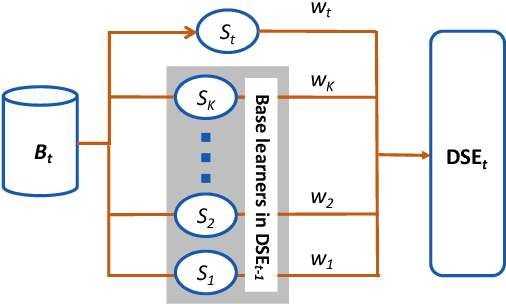
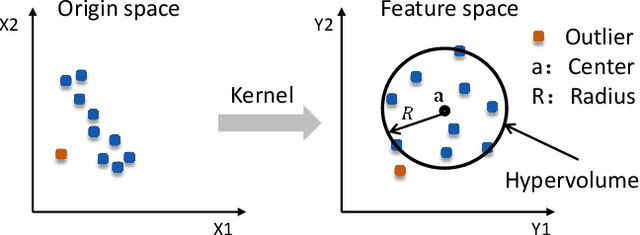
Existing work on data-driven optimization focuses on problems in static environments, but little attention has been paid to problems in dynamic environments. This paper proposes a data-driven optimization algorithm to deal with the challenges presented by the dynamic environments. First, a data stream ensemble learning method is adopted to train the surrogates so that each base learner of the ensemble learns the time-varying objective function in the previous environments. After that, a multi-task evolutionary algorithm is employed to simultaneously optimize the problems in the past environments assisted by the ensemble surrogate. This way, the optimization tasks in the previous environments can be used to accelerate the tracking of the optimum in the current environment. Since the real fitness function is not available for verifying the surrogates in offline data-driven optimization, a support vector domain description that was designed for outlier detection is introduced to select a reliable solution. Empirical results on six dynamic optimization benchmark problems demonstrate the effectiveness of the proposed algorithm compared with four state-of-the-art data-driven optimization algorithms.
Entity Recognition and Relation Extraction from Scientific and Technical Texts in Russian
Dec 14, 2020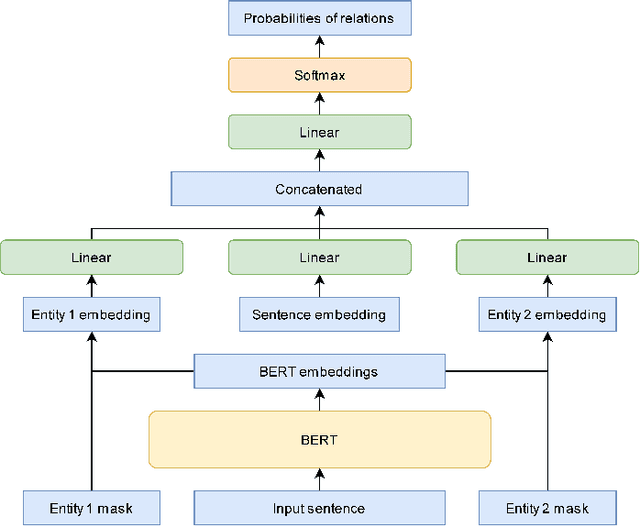
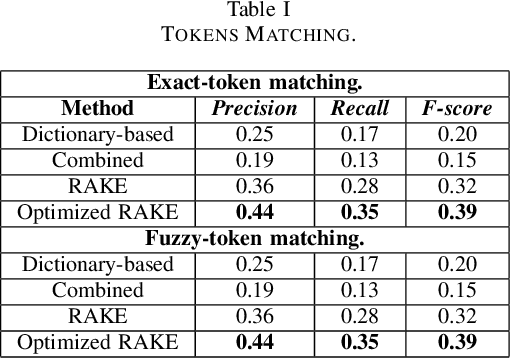
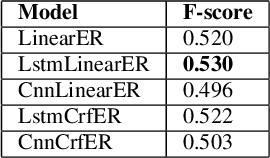
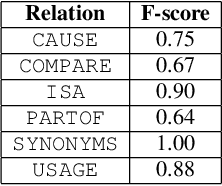
This paper is devoted to the study of methods for information extraction (entity recognition and relation classification) from scientific texts on information technology. Scientific publications provide valuable information into cutting-edge scientific advances, but efficient processing of increasing amounts of data is a time-consuming task. In this paper, several modifications of methods for the Russian language are proposed. It also includes the results of experiments comparing a keyword extraction method, vocabulary method, and some methods based on neural networks. Text collections for these tasks exist for the English language and are actively used by the scientific community, but at present, such datasets in Russian are not publicly available. In this paper, we present a corpus of scientific texts in Russian, RuSERRC. This dataset consists of 1600 unlabeled documents and 80 labeled with entities and semantic relations (6 relation types were considered). The dataset and models are available at https://github.com/iis-research-team. We hope they can be useful for research purposes and development of information extraction systems.
DeepGMR: Learning Latent Gaussian Mixture Models for Registration
Aug 20, 2020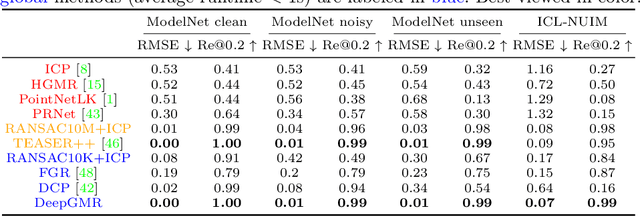
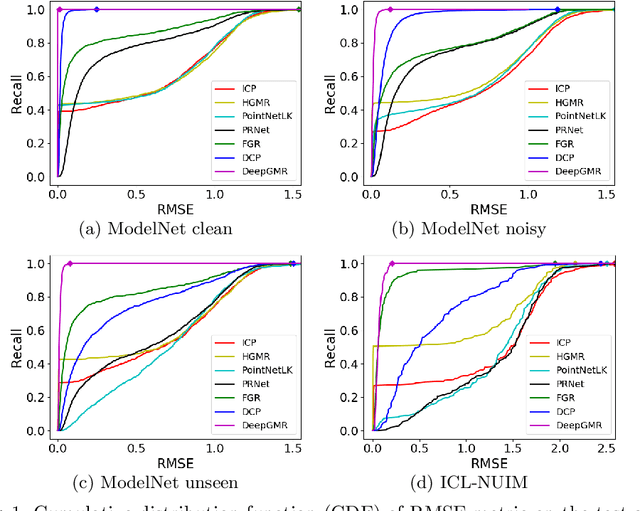
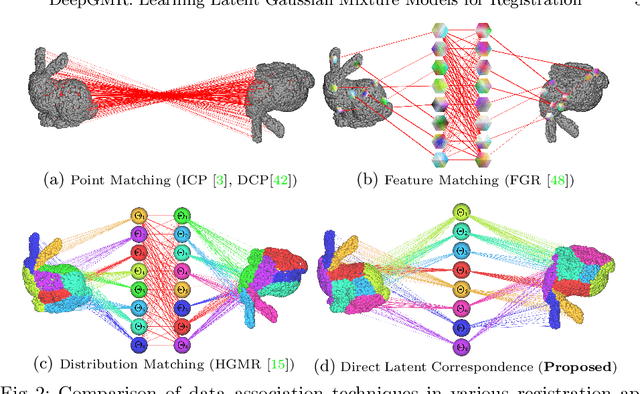
Point cloud registration is a fundamental problem in 3D computer vision, graphics and robotics. For the last few decades, existing registration algorithms have struggled in situations with large transformations, noise, and time constraints. In this paper, we introduce Deep Gaussian Mixture Registration (DeepGMR), the first learning-based registration method that explicitly leverages a probabilistic registration paradigm by formulating registration as the minimization of KL-divergence between two probability distributions modeled as mixtures of Gaussians. We design a neural network that extracts pose-invariant correspondences between raw point clouds and Gaussian Mixture Model (GMM) parameters and two differentiable compute blocks that recover the optimal transformation from matched GMM parameters. This construction allows the network learn an SE(3)-invariant feature space, producing a global registration method that is real-time, generalizable, and robust to noise. Across synthetic and real-world data, our proposed method shows favorable performance when compared with state-of-the-art geometry-based and learning-based registration methods.
Tag-based Genetic Regulation for Genetic Programming
Dec 23, 2020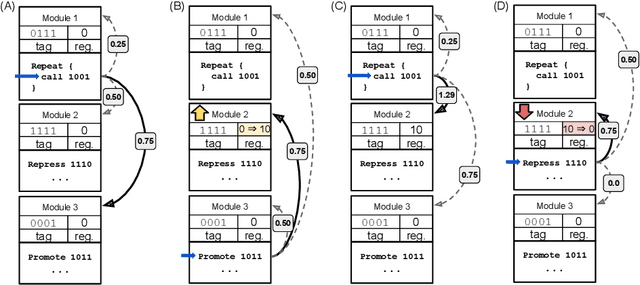
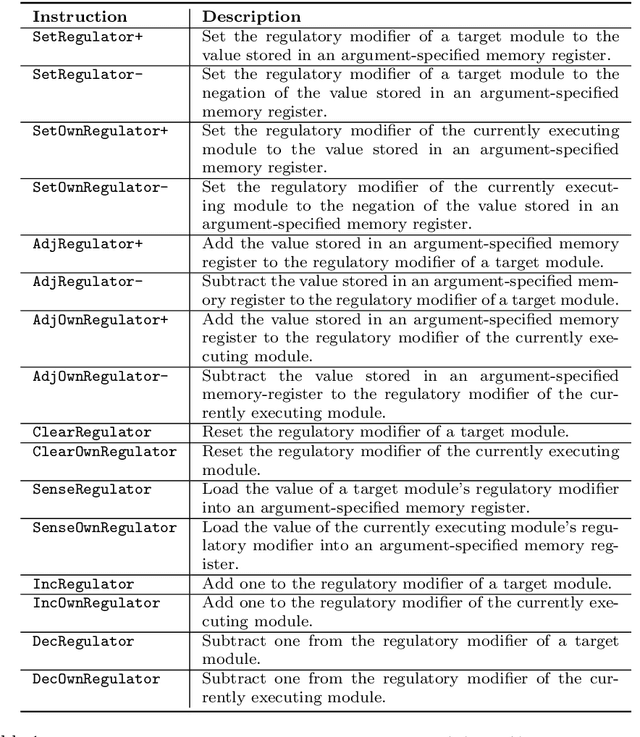
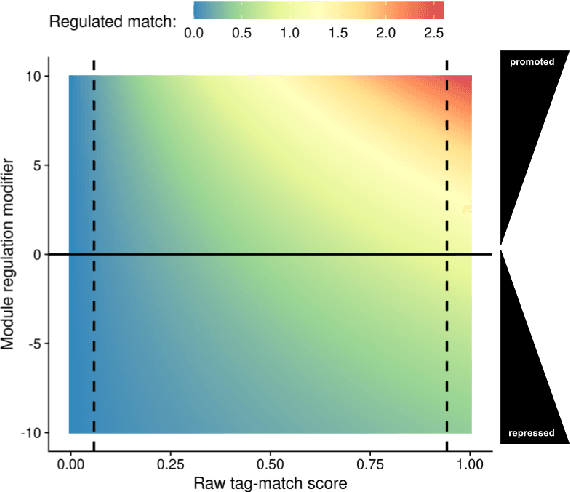
We introduce and experimentally demonstrate tag-based genetic regulation, a new genetic programming (GP) technique that allows evolving programs to dynamically adjust which code modules to express. Tags are evolvable labels that provide a flexible mechanism for referring to code modules. Tag-based genetic regulation extends existing tag-based naming schemes to allow programs to "promote" and "repress" code modules. This extension allows evolution to structure a program as a gene regulatory network where program modules are regulated based on instruction executions. We demonstrate the functionality of tag-based regulation on a range of program synthesis problems. We find that tag-based regulation improves problem-solving performance on context-dependent problems; that is, problems where programs must adjust how they respond to current inputs based on prior inputs (i.e., current context). We also observe that our implementation of tag-based genetic regulation can impede adaptive evolution when expected outputs are not context-dependent (i.e., the correct response to a particular input remains static over time). Tag-based genetic regulation broadens our repertoire of techniques for evolving more dynamic genetic programs and can easily be incorporated into existing tag-enabled GP systems.
Online Discriminative Graph Learning from Multi-Class Smooth Signals
Jan 01, 2021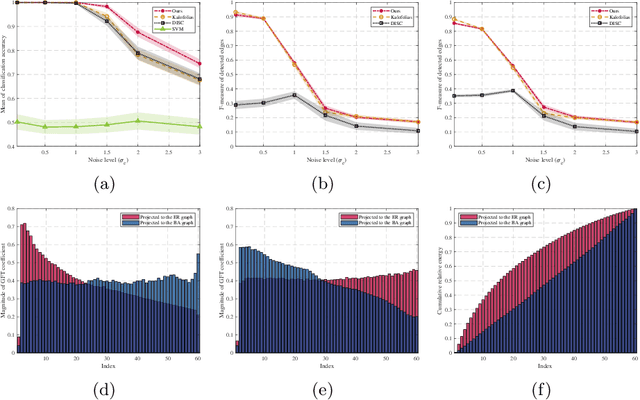
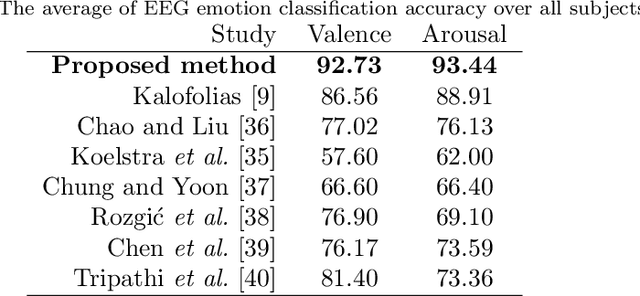
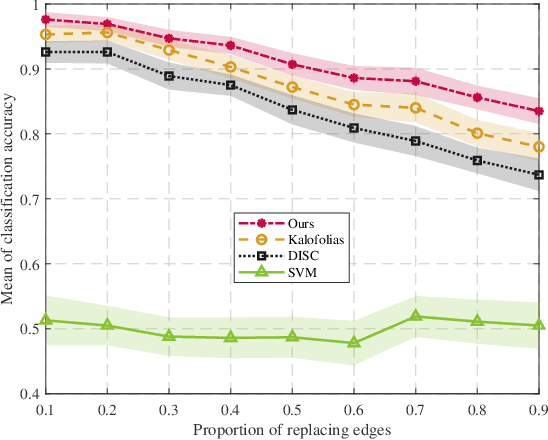
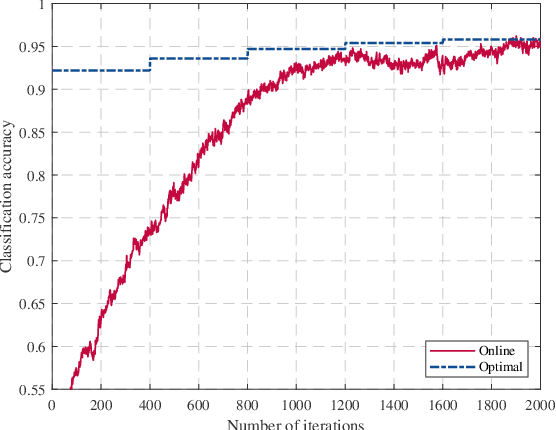
Graph signal processing (GSP) is a key tool for satisfying the growing demand for information processing over networks. However, the success of GSP in downstream learning and inference tasks is heavily dependent on the prior identification of the relational structures. Graphs are natural descriptors of the relationships between entities of complex environments. The underlying graph is not readily detectable in many cases and one has to infer the topology from the observed signals. Firstly, we address the problem of graph signal classification by proposing a novel framework for discriminative graph learning. To learn discriminative graphs, we invoke the assumption that signals belonging to each class are smooth with respect to the corresponding graph while maintaining non-smoothness with respect to the graphs corresponding to other classes. Secondly, we extend our work to tackle increasingly dynamic environments and real-time topology inference. We develop a proximal gradient (PG) method which can be adapted to situations where the data are acquired on-the-fly. Beyond discrimination, this is the first work that addresses the problem of dynamic graph learning from smooth signals where the sought network alters slowly. The validation of the proposed frameworks is comprehensively investigated using both synthetic and real data.
A Serverless Cloud-Fog Platform for DNN-Based Video Analytics with Incremental Learning
Feb 05, 2021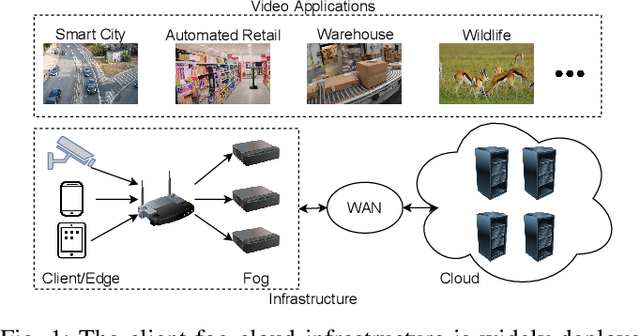
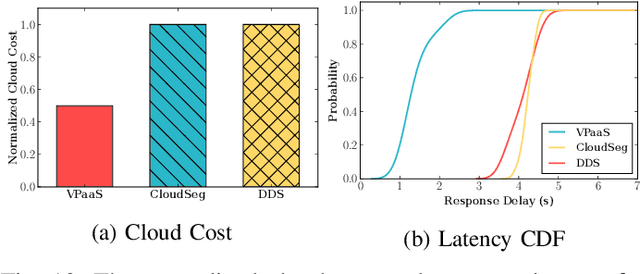
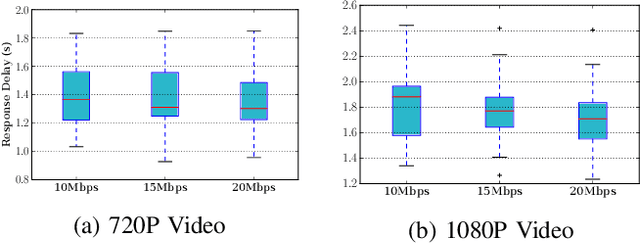
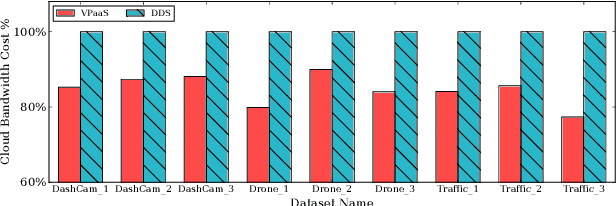
DNN-based video analytics have empowered many new applications (e.g., automated retail). Meanwhile, the proliferation of fog devices provides developers with more design options to improve performance and save cost. To the best of our knowledge, this paper presents the first serverless system that takes full advantage of the client-fog-cloud synergy to better serve the DNN-based video analytics. Specifically, the system aims to achieve two goals: 1) Provide the optimal analytics results under the constraints of lower bandwidth usage and shorter round-trip time (RTT) by judiciously managing the computational and bandwidth resources deployed in the client, fog, and cloud environment. 2) Free developers from tedious administration and operation tasks, including DNN deployment, cloud and fog's resource management. To this end, we implement a holistic cloud-fog system referred to as VPaaS (Video-Platform-as-a-Service). VPaaS adopts serverless computing to enable developers to build a video analytics pipeline by simply programming a set of functions (e.g., model inference), which are then orchestrated to process videos through carefully designed modules. To save bandwidth and reduce RTT, VPaaS provides a new video streaming protocol that only sends low-quality video to the cloud. The state-of-the-art (SOTA) DNNs deployed at the cloud can identify regions of video frames that need further processing at the fog ends. At the fog ends, misidentified labels in these regions can be corrected using a light-weight DNN model. To address the data drift issues, we incorporate limited human feedback into the system to verify the results and adopt incremental learning to improve our system continuously. The evaluation demonstrates that VPaaS is superior to several SOTA systems: it maintains high accuracy while reducing bandwidth usage by up to 21%, RTT by up to 62.5%, and cloud monetary cost by up to 50%.
Extracting full-field subpixel structural displacements from videos via deep learning
Aug 31, 2020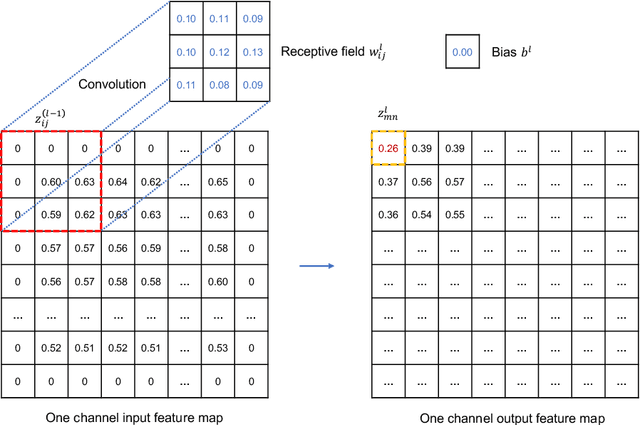
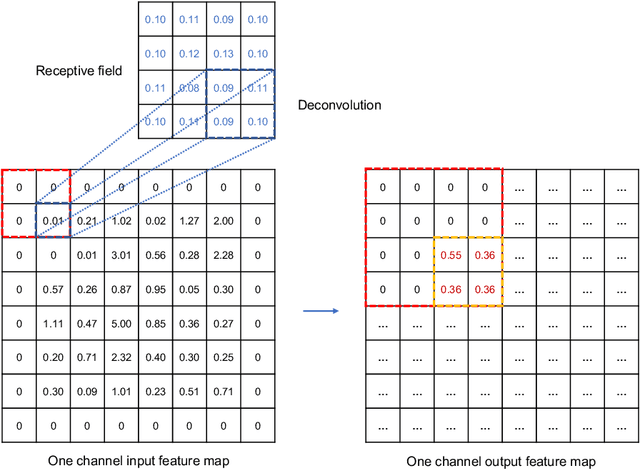
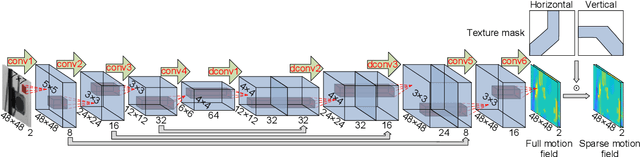
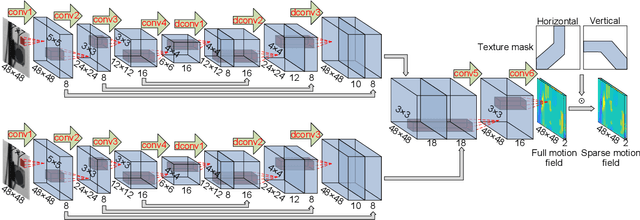
This paper develops a deep learning framework based on convolutional neural networks (CNNs) that enable real-time extraction of full-field subpixel structural displacements from videos. In particular, two new CNN architectures are designed and trained on a dataset generated by the phase-based motion extraction method from a single lab-recorded high-speed video of a dynamic structure. As displacement is only reliable in the regions with sufficient texture contrast, the sparsity of motion field induced by the texture mask is considered via the network architecture design and loss function definition. Results show that, with the supervision of full and sparse motion field, the trained network is capable of identifying the pixels with sufficient texture contrast as well as their subpixel motions. The performance of the trained networks is tested on various videos of other structures to extract the full-field motion (e.g., displacement time histories), which indicates that the trained networks have generalizability to accurately extract full-field subtle displacements for pixels with sufficient texture contrast.
Triplet Entropy Loss: Improving The Generalisation of Short Speech Language Identification Systems
Dec 03, 2020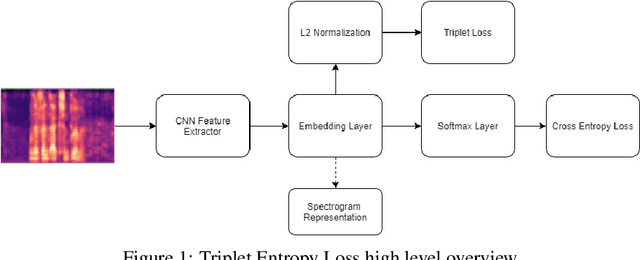
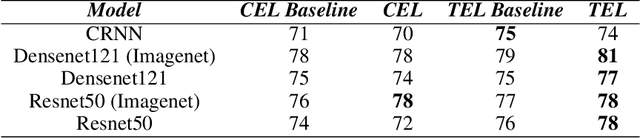
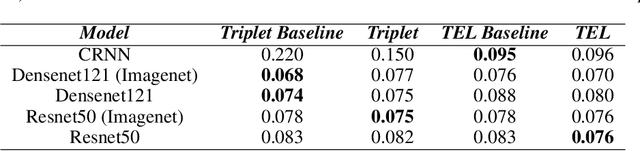
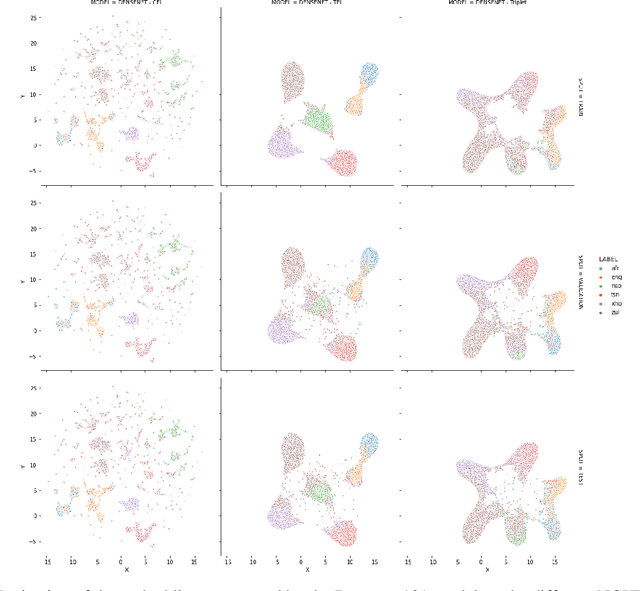
We present several methods to improve the generalisation of language identification (LID) systems to new speakers and to new domains. These methods involve Spectral augmentation, where spectrograms are masked in the frequency or time bands during training and CNN architectures that are pre-trained on the Imagenet dataset. The paper also introduces the novel Triplet Entropy Loss training method, which involves training a network simultaneously using Cross Entropy and Triplet loss. It was found that all three methods improved the generalisation of the models, though not significantly. Even though the models trained using Triplet Entropy Loss showed a better understanding of the languages and higher accuracies, it appears as though the models still memorise word patterns present in the spectrograms rather than learning the finer nuances of a language. The research shows that Triplet Entropy Loss has great potential and should be investigated further, not only in language identification tasks but any classification task.