 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient CNN Building Blocks for Encrypted Data
Jan 30, 2021
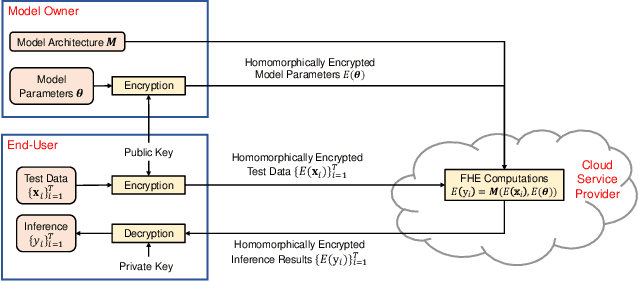

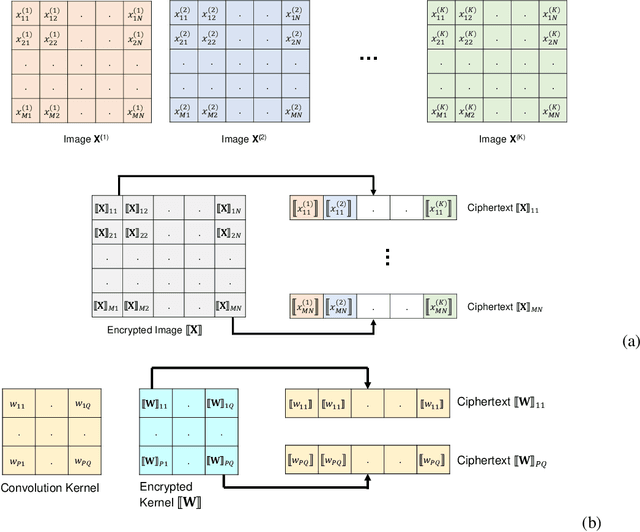
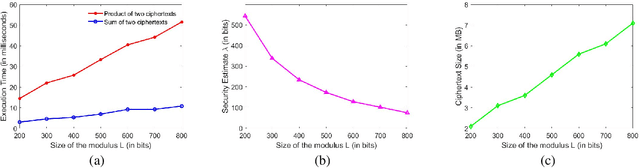
Machine learning on encrypted data can address the concerns related to privacy and legality of sharing sensitive data with untrustworthy service providers. Fully Homomorphic Encryption (FHE) is a promising technique to enable machine learning and inferencing while providing strict guarantees against information leakage. Since deep convolutional neural networks (CNNs) have become the machine learning tool of choice in several applications, several attempts have been made to harness CNNs to extract insights from encrypted data. However, existing works focus only on ensuring data security and ignore security of model parameters. They also report high level implementations without providing rigorous analysis of the accuracy, security, and speed trade-offs involved in the FHE implementation of generic primitive operators of a CNN such as convolution, non-linear activation, and pooling. In this work, we consider a Machine Learning as a Service (MLaaS) scenario where both input data and model parameters are secured using FHE. Using the CKKS scheme available in the open-source HElib library, we show that operational parameters of the chosen FHE scheme such as the degree of the cyclotomic polynomial, depth limitations of the underlying leveled HE scheme, and the computational precision parameters have a major impact on the design of the machine learning model (especially, the choice of the activation function and pooling method). Our empirical study shows that choice of aforementioned design parameters result in significant trade-offs between accuracy, security level, and computational time. Encrypted inference experiments on the MNIST dataset indicate that other design choices such as ciphertext packing strategy and parallelization using multithreading are also critical in determining the throughput and latency of the inference process.
Distributed Gaussian Learning over Time-varying Directed Graphs
Dec 07, 2016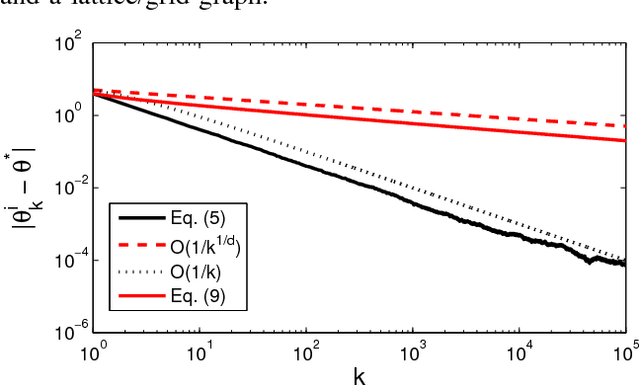
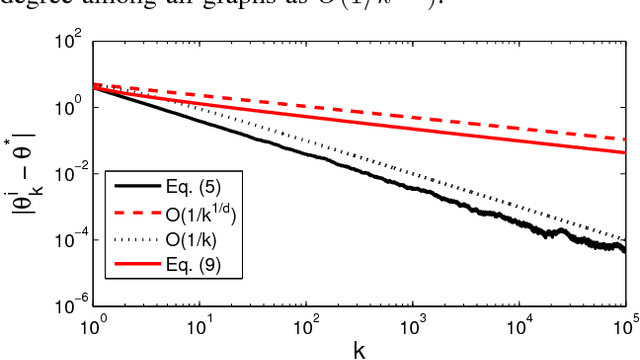
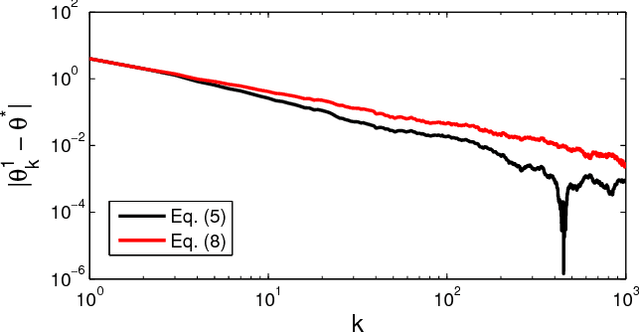
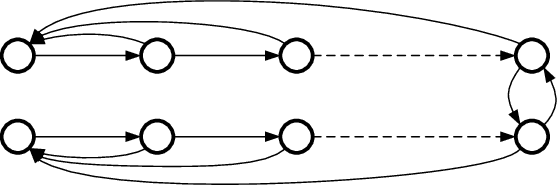
We present a distributed (non-Bayesian) learning algorithm for the problem of parameter estimation with Gaussian noise. The algorithm is expressed as explicit updates on the parameters of the Gaussian beliefs (i.e. means and precision). We show a convergence rate of $O(1/k)$ with the constant term depending on the number of agents and the topology of the network. Moreover, we show almost sure convergence to the optimal solution of the estimation problem for the general case of time-varying directed graphs.
Push, Stop, and Replan: An Application of Pebble Motion on Graphs to Planning in Automated Warehouses
Jul 20, 2020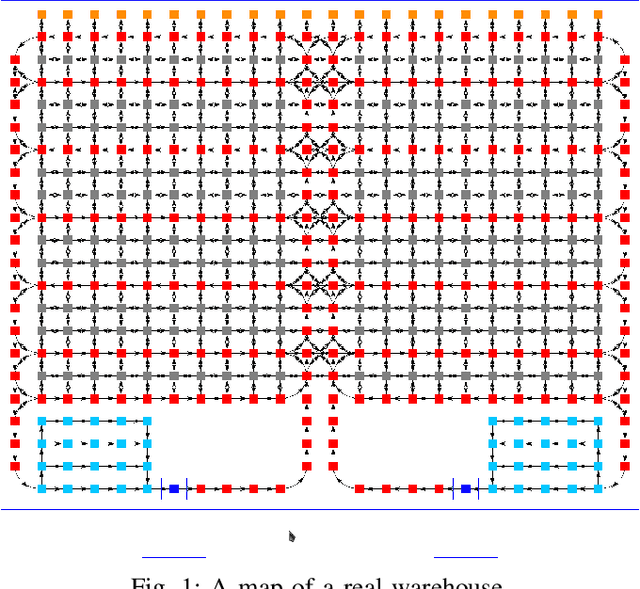
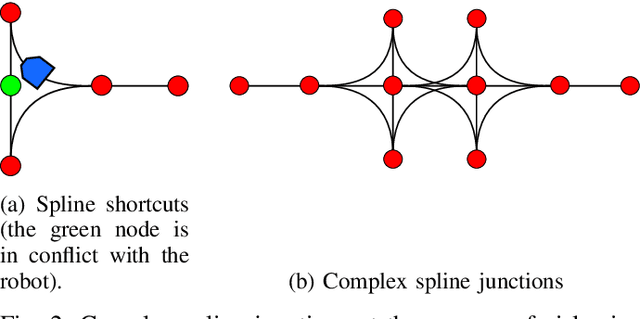
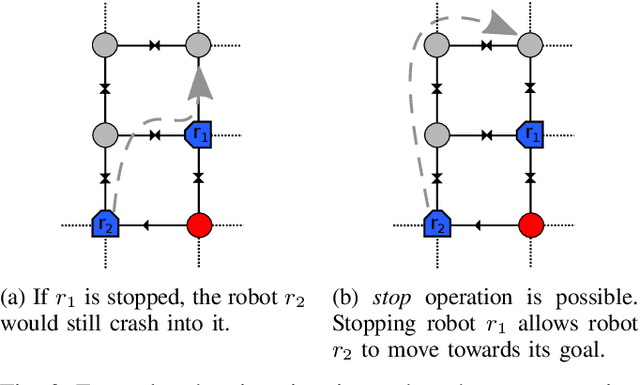
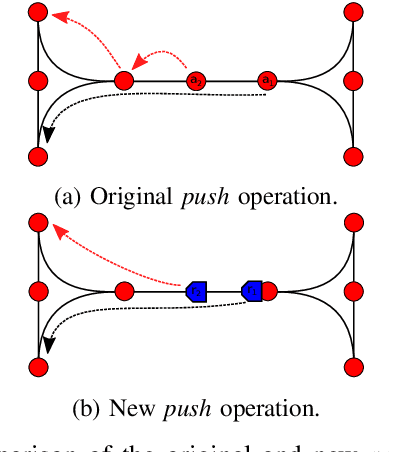
The pebble-motion on graphs is a subcategory of multi-agent pathfinding problems dealing with moving multiple pebble-like objects from a node to a node in a graph with a constraint that only one pebble can occupy one node at a given time. Additionally, algorithms solving this problem assume that individual pebbles (robots) cannot move at the same time and their movement is discrete. These assumptions disqualify them from being directly used in practical applications, although they have otherwise nice theoretical properties. We present modifications of the Push and Rotate algorithm [1], which relax the presumptions mentioned above and demonstrate, through a set of experiments, that the modified algorithm is applicable for planning in automated warehouses.
Clustering high dimensional meteorological scenarios: results and performance index
Dec 14, 2020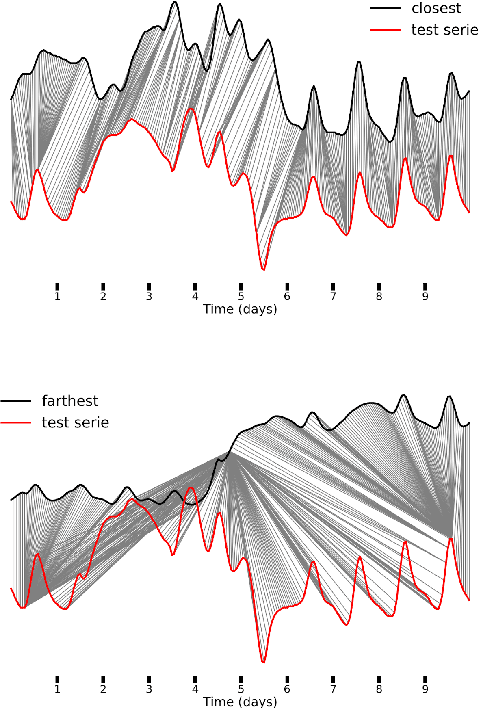
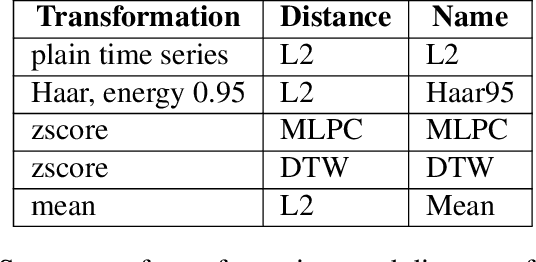
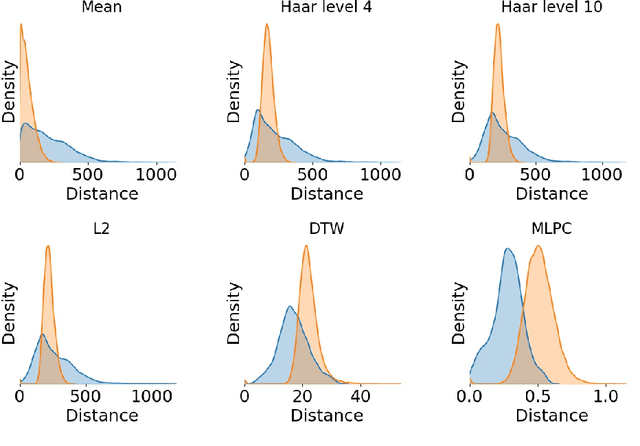
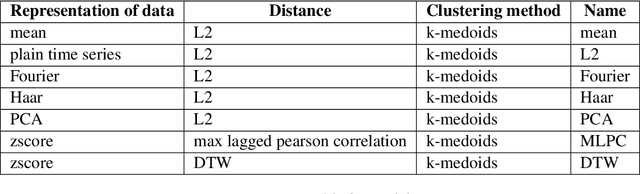
The Reseau de Transport d'Electricit\'e (RTE) is the French main electricity network operational manager and dedicates large number of resources and efforts towards understanding climate time series data. We discuss here the problem and the methodology of grouping and selecting representatives of possible climate scenarios among a large number of climate simulations provided by RTE. The data used is composed of temperature times series for 200 different possible scenarios on a grid of geographical locations in France. These should be clustered in order to detect common patterns regarding temperatures curves and help to choose representative scenarios for network simulations, which in turn can be used for energy optimisation. We first show that the choice of the distance used for the clustering has a strong impact on the meaning of the results: depending on the type of distance used, either spatial or temporal patterns prevail. Then we discuss the difficulty of fine-tuning the distance choice (combined with a dimension reduction procedure) and we propose a methodology based on a carefully designed index.
MyWear: A Smart Wear for Continuous Body Vital Monitoring and Emergency Alert
Oct 17, 2020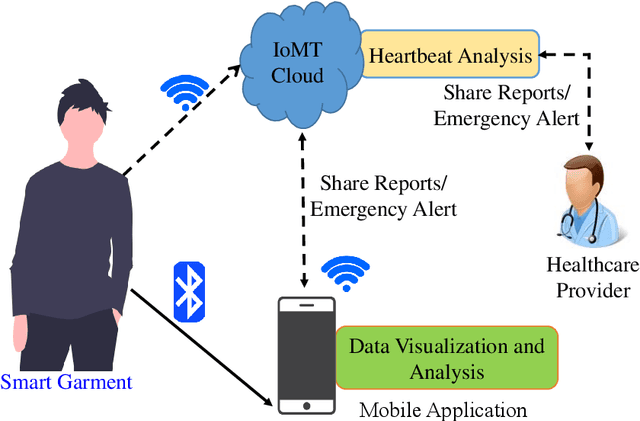
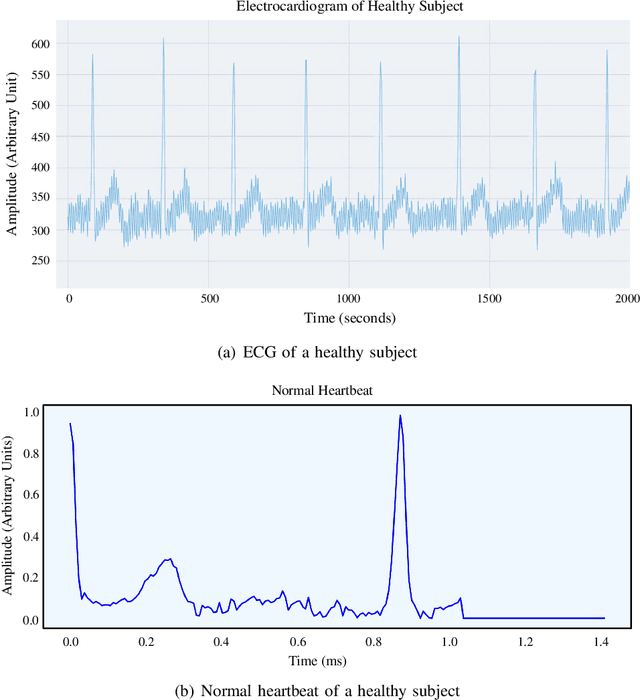
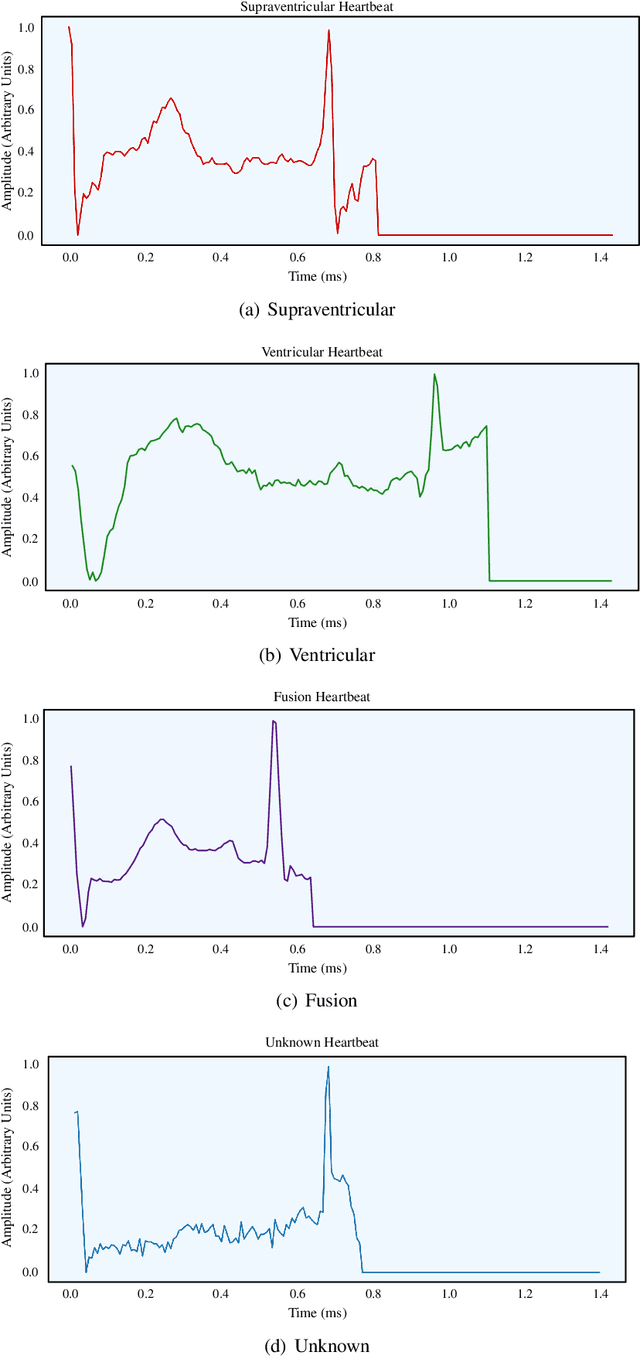
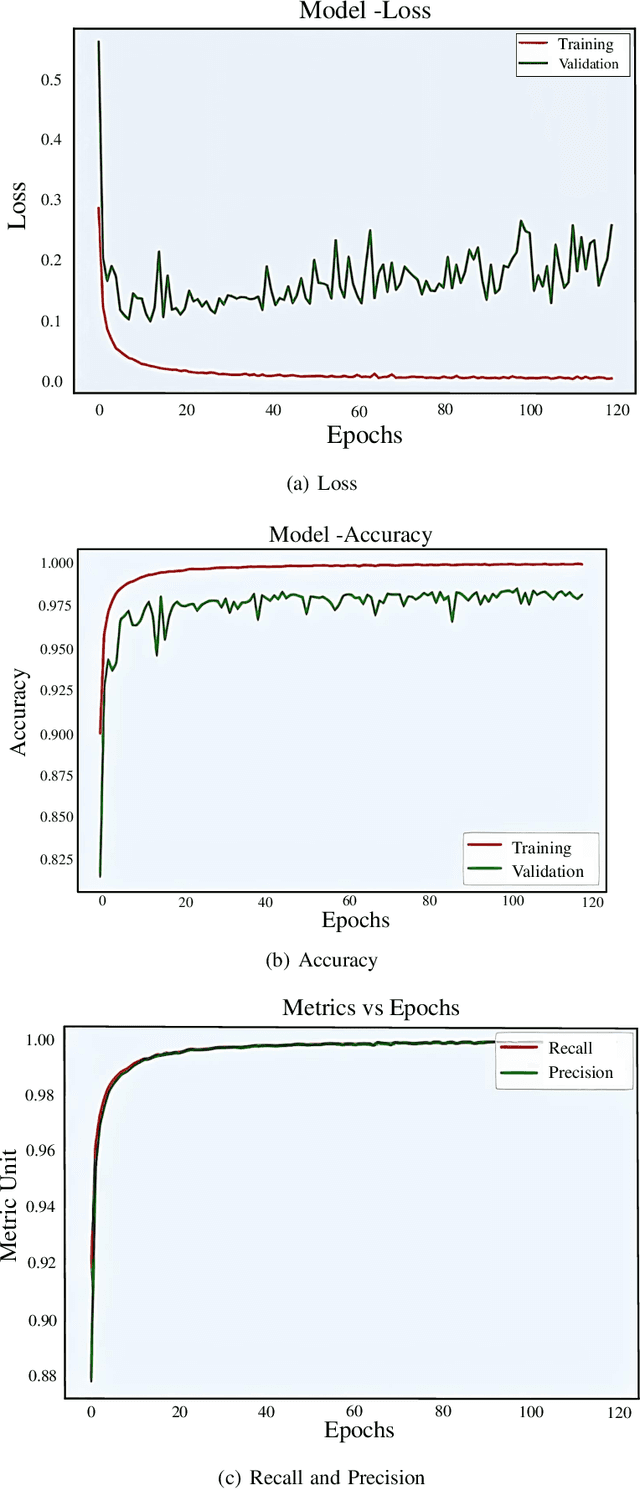
Smart healthcare which is built as healthcare Cyber-Physical System (H-CPS) from Internet-of-Medical-Things (IoMT) is becoming more important than before. Medical devices and their connectivity through Internet with alongwith the electronics health record (EHR) and AI analytics making H-CPS possible. IoMT-end devices like wearables and implantables are key for H-CPS based smart healthcare. Smart garment is a specific wearable which can be used for smart healthcare. There are various smart garments that help users to monitor their body vitals in real-time. Many commercially available garments collect the vital data and transmit it to the mobile application for visualization. However, these don't perform real-time analysis for the user to comprehend their health conditions. Also, such garments are not included with an alert system to alert users and contacts in case of emergency. In MyWear, we propose a wearable body vital monitoring garment that captures physiological data and automatically analyses such heart rate, stress level, muscle activity to detect abnormalities. A copy of the physiological data is transmitted to the cloud for detecting any abnormalities in heart beats and predict any potential heart failure in future. We also propose a deep neural network (DNN) model that automatically classifies abnormal heart beat and potential heart failure. For immediate assistance in such a situation, we propose an alert system that sends an alert message to nearby medical officials. The proposed MyWear has an average accuracy of 96.9% and precision of 97.3% for detection of the abnormalities.
GnetSeg: Semantic Segmentation Model Optimized on a 224mW CNN Accelerator Chip at the Speed of 318FPS
Jan 09, 2021

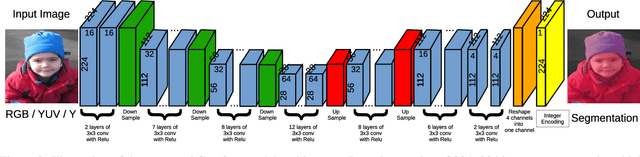
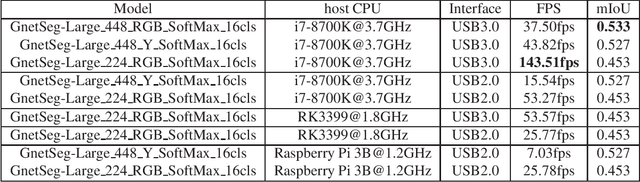
Semantic segmentation is the task to cluster pixels on an image belonging to the same class. It is widely used in the real-world applications including autonomous driving, medical imaging analysis, industrial inspection, smartphone camera for person segmentation and so on. Accelerating the semantic segmentation models on the mobile and edge devices are practical needs for the industry. Recent years have witnessed the wide availability of CNN (Convolutional Neural Networks) accelerators. They have the advantages on power efficiency, inference speed, which are ideal for accelerating the semantic segmentation models on the edge devices. However, the CNN accelerator chips also have the limitations on flexibility and memory. In addition, the CPU load is very critical because the CNN accelerator chip works as a co-processor with a host CPU. In this paper, we optimize the semantic segmentation model in order to fully utilize the limited memory and the supported operators on the CNN accelerator chips, and at the same time reduce the CPU load of the CNN model to zero. The resulting model is called GnetSeg. Furthermore, we propose the integer encoding for the mask of the GnetSeg model, which minimizes the latency of data transfer between the CNN accelerator and the host CPU. The experimental result shows that the model running on the 224mW chip achieves the speed of 318FPS with excellent accuracy for applications such as person segmentation.
Distributed Bandits: Probabilistic Communication on $d$-regular Graphs
Nov 16, 2020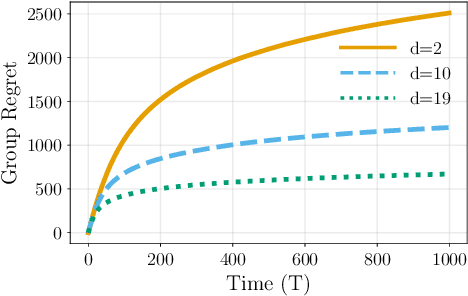
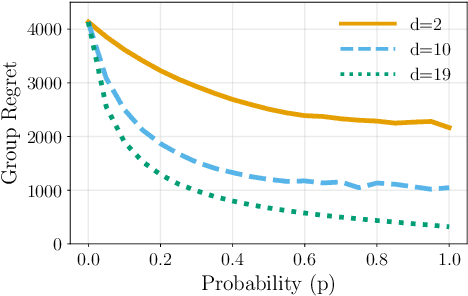
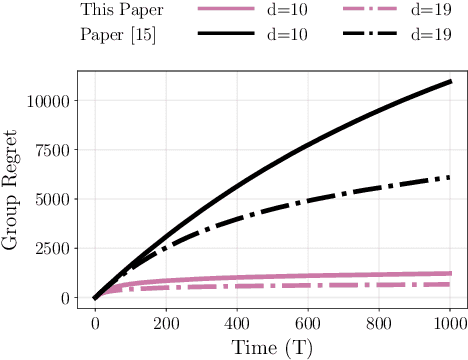
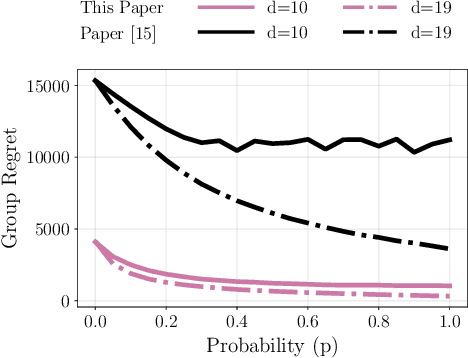
We study the decentralized multi-agent multi-armed bandit problem for agents that communicate with probability over a network defined by a $d$-regular graph. Every edge in the graph has probabilistic weight $p$ to account for the ($1\!-\!p$) probability of a communication link failure. At each time step, each agent chooses an arm and receives a numerical reward associated with the chosen arm. After each choice, each agent observes the last obtained reward of each of its neighbors with probability $p$. We propose a new Upper Confidence Bound (UCB) based algorithm and analyze how agent-based strategies contribute to minimizing group regret in this probabilistic communication setting. We provide theoretical guarantees that our algorithm outperforms state-of-the-art algorithms. We illustrate our results and validate the theoretical claims using numerical simulations.
Curb Your Normality: On the Quality Requirements of Demand Prediction for Dynamic Public Transport
Sep 01, 2020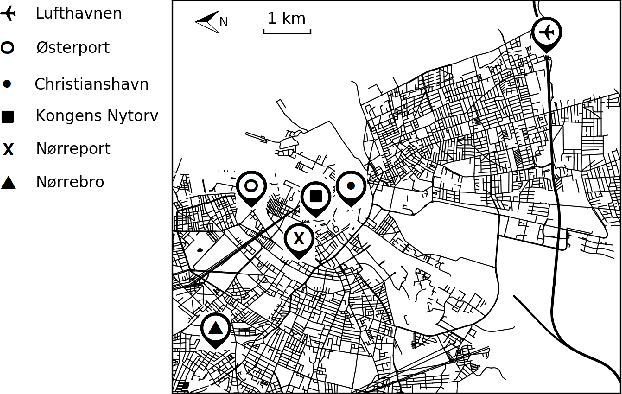
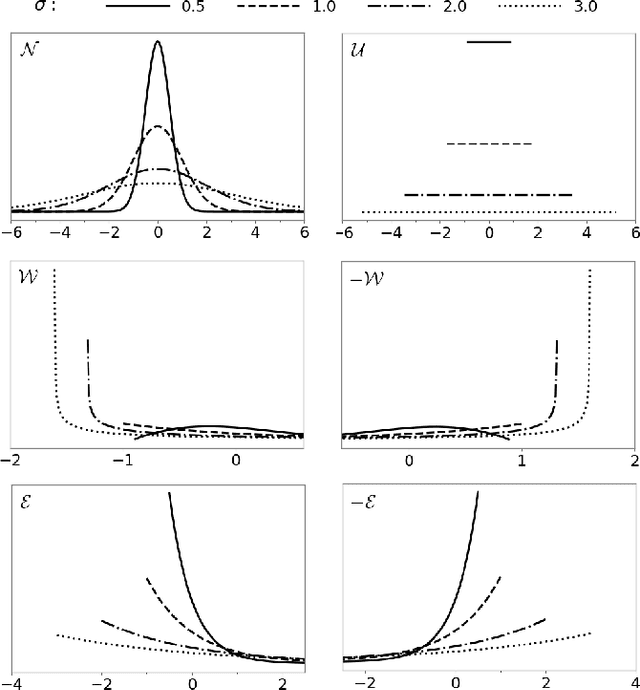
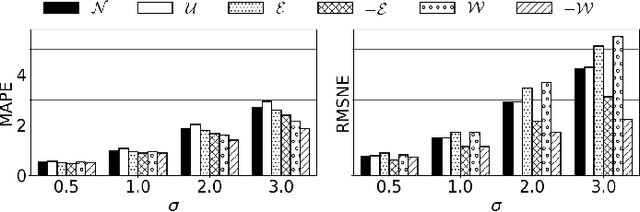
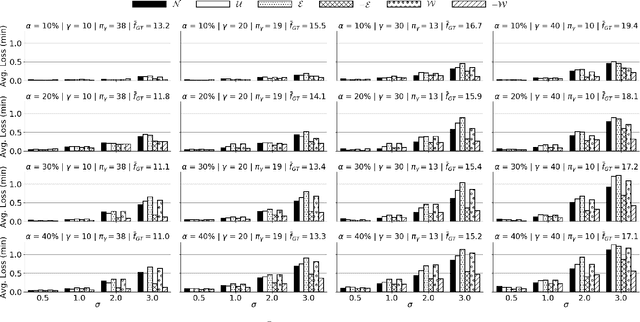
As Public Transport (PT) becomes more dynamic and demand-responsive, it increasingly depends on predictions of transport demand. But how accurate need such predictions be for effective PT operation? We address this question through an experimental case study of PT trips in Metropolitan Copenhagen, Denmark, which we conduct independently of any specific prediction models. First, we simulate errors in demand prediction through unbiased noise distributions that vary considerably in shape. Using the noisy predictions, we then simulate and optimize demand-responsive PT fleets via a commonly used linear programming formulation and measure their performance. Our results suggest that the optimized performance is mainly affected by the skew of the noise distribution and the presence of infrequently large prediction errors. In particular, the optimized performance can improve under non-Gaussian vs. Gaussian noise. We also obtain that dynamic routing can reduce trip time by at least 23% vs. static routing. This reduction is estimated at 809,000 EUR per year in terms of Value of Travel Time Savings for the case study.
It Takes Two to Tango: Combining Visual and Textual Information for Detecting Duplicate Video-Based Bug Reports
Feb 05, 2021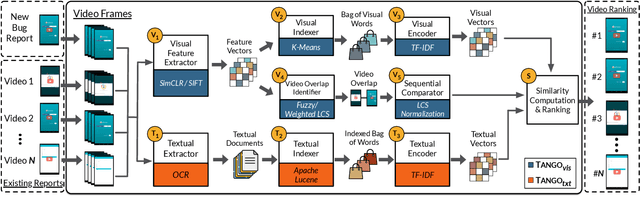
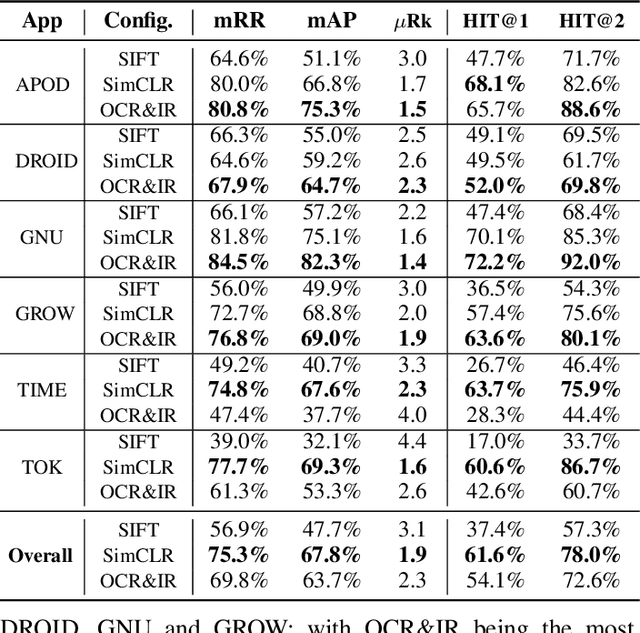
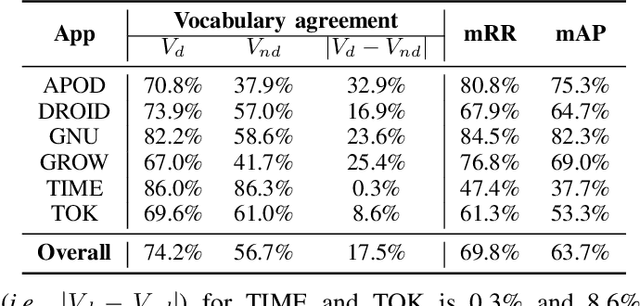
When a bug manifests in a user-facing application, it is likely to be exposed through the graphical user interface (GUI). Given the importance of visual information to the process of identifying and understanding such bugs, users are increasingly making use of screenshots and screen-recordings as a means to report issues to developers. However, when such information is reported en masse, such as during crowd-sourced testing, managing these artifacts can be a time-consuming process. As the reporting of screen-recordings in particular becomes more popular, developers are likely to face challenges related to manually identifying videos that depict duplicate bugs. Due to their graphical nature, screen-recordings present challenges for automated analysis that preclude the use of current duplicate bug report detection techniques. To overcome these challenges and aid developers in this task, this paper presents Tango, a duplicate detection technique that operates purely on video-based bug reports by leveraging both visual and textual information. Tango combines tailored computer vision techniques, optical character recognition, and text retrieval. We evaluated multiple configurations of Tango in a comprehensive empirical evaluation on 4,860 duplicate detection tasks that involved a total of 180 screen-recordings from six Android apps. Additionally, we conducted a user study investigating the effort required for developers to manually detect duplicate video-based bug reports and compared this to the effort required to use Tango. The results reveal that Tango's optimal configuration is highly effective at detecting duplicate video-based bug reports, accurately ranking target duplicate videos in the top-2 returned results in 83% of the tasks. Additionally, our user study shows that, on average, Tango can reduce developer effort by over 60%, illustrating its practicality.
Extracting the Subhalo Mass Function from Strong Lens Images with Image Segmentation
Sep 14, 2020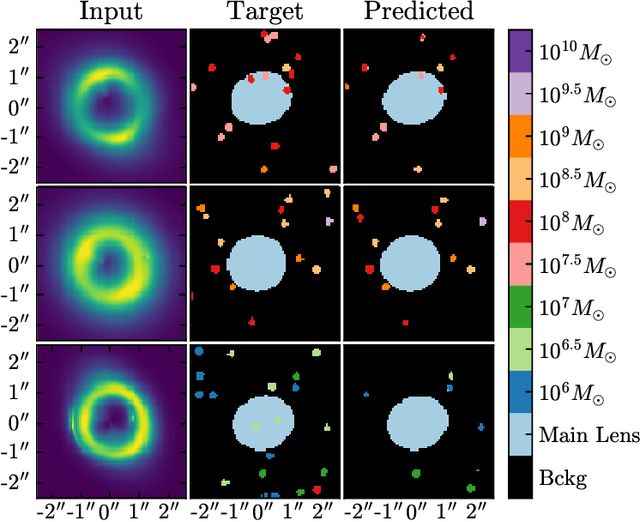
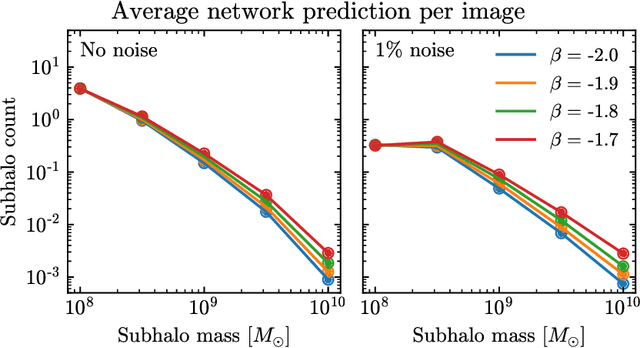
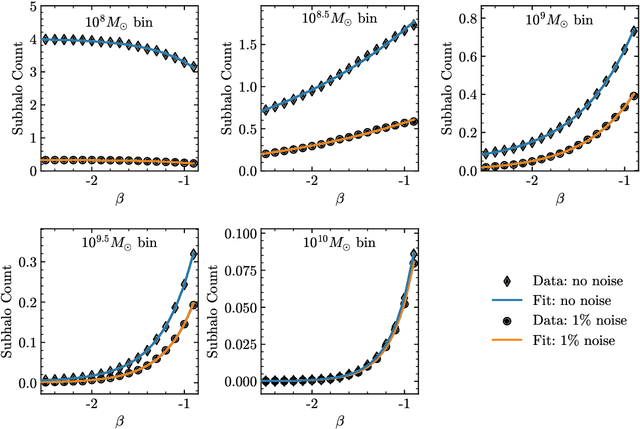
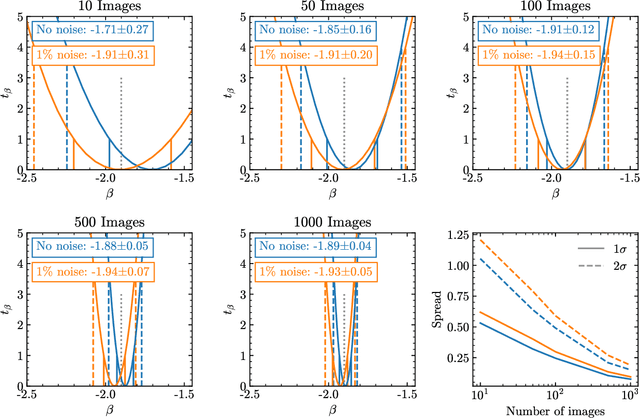
Detecting substructure within strongly lensed images is a promising route to shed light on the nature of dark matter. It is a challenging task, which traditionally requires detailed lens modeling and source reconstruction, taking weeks to analyze each system. We use machine learning to circumvent the need for lens and source modeling and develop a method to both locate subhalos in an image as well as determine their mass using the technique of image segmentation. The network is trained on images with a single subhalo located near the Einstein ring. Training in this way allows the network to learn the gravitational lensing of light and it is then able to accurately detect entire populations of substructure, even far from the Einstein ring. In images with a single subhalo and without noise, the network detects subhalos of mass $10^6 M_{\odot}$ 62% of the time and 78% of these detected subhalos are predicted in the correct mass bin. The detection accuracy increases for heavier masses. When random noise at the level of 1% of the mean brightness of the image is included (which is a realistic approximation HST, for sources brighter than magnitude 20), the network loses sensitivity to the low-mass subhalos; with noise, the $10^{8.5}M_{\odot}$ subhalos are detected 86% of the time, but the $10^8 M_{\odot}$ subhalos are only detected 38% of the time. The false-positive rate is around 2 false subhalos per 100 images with and without noise, coming mostly from masses $\leq10^8 M_{\odot}$. With good accuracy and a low false-positive rate, counting the number of pixels assigned to each subhalo class over multiple images allows for a measurement of the subhalo mass function (SMF). When measured over five mass bins from $10^8 M_{\odot}$ to $10^{10} M_{\odot}$ the SMF slope is recovered with an error of 14.2 (16.3)% for 10 images, and this improves to 2.1 (2.6)% for 1000 images without (with 1%) noise.