 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Truly shift-invariant convolutional neural networks
Dec 04, 2020
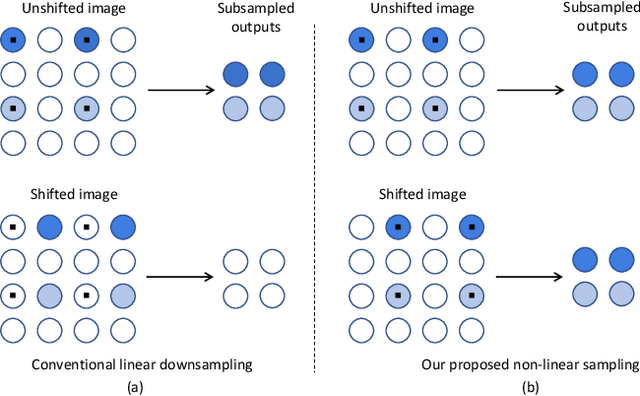
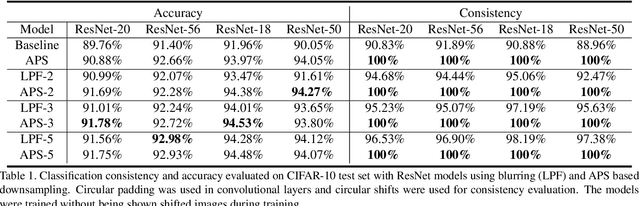
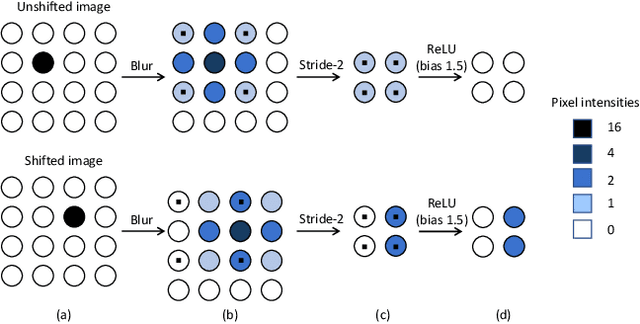
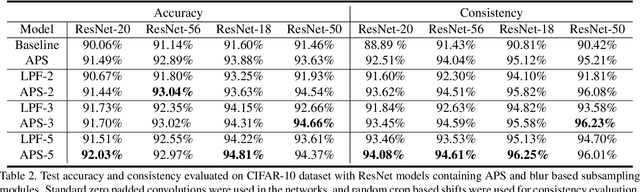
Thanks to the use of convolution and pooling layers, convolutional neural networks were for a long time thought to be shift-invariant. However, recent works have shown that the output of a CNN can change significantly with small shifts in input: a problem caused by the presence of downsampling (stride) layers. The existing solutions rely either on data augmentation or on anti-aliasing, both of which have limitations and neither of which enables perfect shift invariance. Additionally, the gains obtained from these methods do not extend to image patterns not seen during training. To address these challenges, we propose adaptive polyphase sampling (APS), a simple sub-sampling scheme that allows convolutional neural networks to achieve 100% consistency in classification performance under shifts, without any loss in accuracy. With APS the networks exhibit perfect consistency to shifts even before training, making it the first approach that makes convolutional neural networks truly shift invariant.
Impatient DNNs - Deep Neural Networks with Dynamic Time Budgets
Oct 10, 2016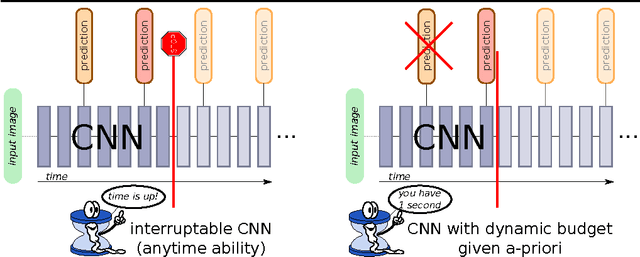
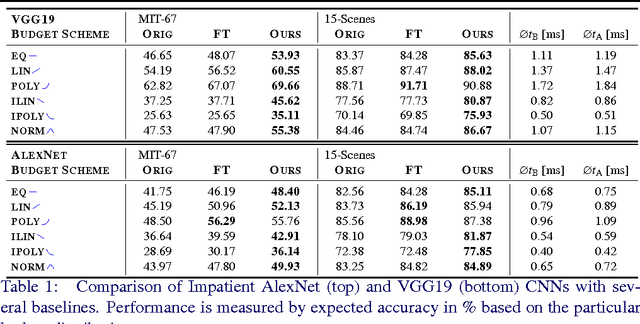
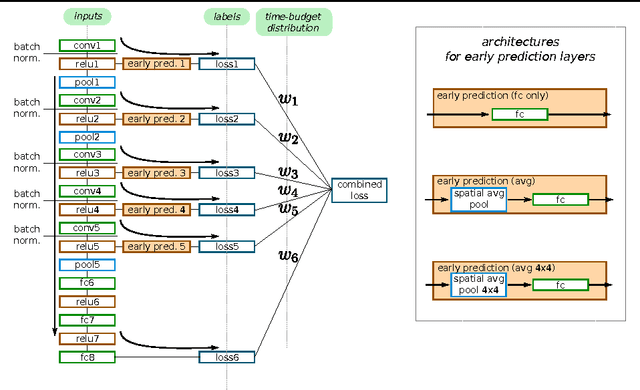

We propose Impatient Deep Neural Networks (DNNs) which deal with dynamic time budgets during application. They allow for individual budgets given a priori for each test example and for anytime prediction, i.e., a possible interruption at multiple stages during inference while still providing output estimates. Our approach can therefore tackle the computational costs and energy demands of DNNs in an adaptive manner, a property essential for real-time applications. Our Impatient DNNs are based on a new general framework of learning dynamic budget predictors using risk minimization, which can be applied to current DNN architectures by adding early prediction and additional loss layers. A key aspect of our method is that all of the intermediate predictors are learned jointly. In experiments, we evaluate our approach for different budget distributions, architectures, and datasets. Our results show a significant gain in expected accuracy compared to common baselines.
Adversarial Black-Box Attacks On Text Classifiers Using Multi-Objective Genetic Optimization Guided By Deep Networks
Nov 10, 2020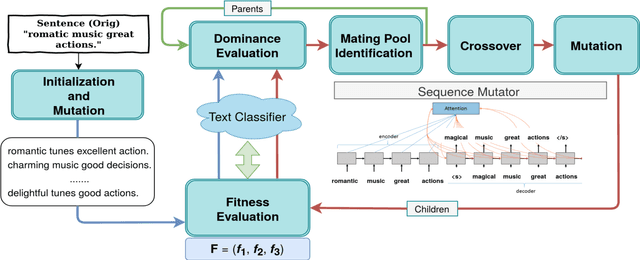


We propose a novel genetic-algorithm technique that generates black-box adversarial examples which successfully fool neural network based text classifiers. We perform a genetic search with multi-objective optimization guided by deep learning based inferences and Seq2Seq mutation to generate semantically similar but imperceptible adversaries. We compare our approach with DeepWordBug (DWB) on SST and IMDB sentiment datasets by attacking three trained models viz. char-LSTM, word-LSTM and elmo-LSTM. On an average, we achieve an attack success rate of 65.67% for SST and 36.45% for IMDB across the three models showing an improvement of 49.48% and 101% respectively. Furthermore, our qualitative study indicates that 94% of the time, the users were not able to distinguish between an original and adversarial sample.
DeepLandscape: Adversarial Modeling of Landscape Video
Aug 21, 2020
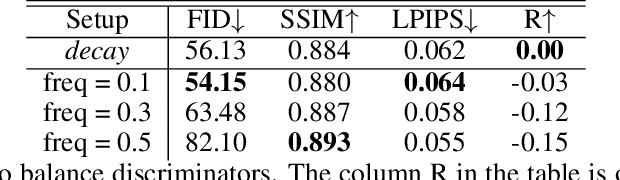
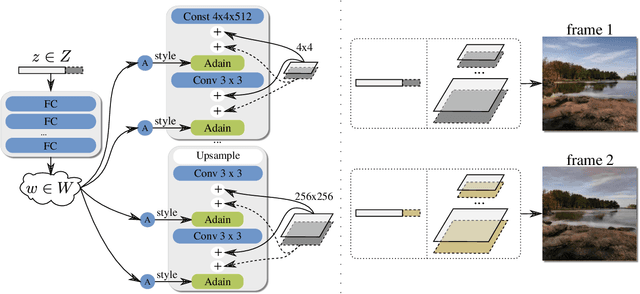
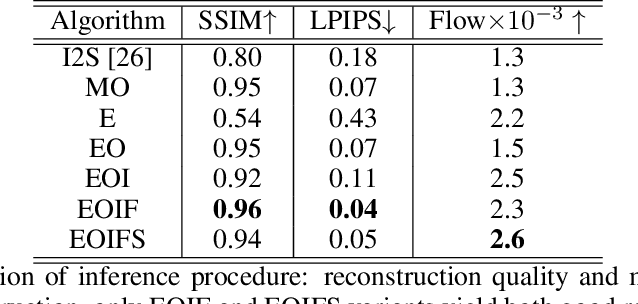
We build a new model of landscape videos that can be trained on a mixture of static landscape images as well as landscape animations. Our architecture extends StyleGAN model by augmenting it with parts that allow to model dynamic changes in a scene. Once trained, our model can be used to generate realistic time-lapse landscape videos with moving objects and time-of-the-day changes. Furthermore, by fitting the learned models to a static landscape image, the latter can be reenacted in a realistic way. We propose simple but necessary modifications to StyleGAN inversion procedure, which lead to in-domain latent codes and allow to manipulate real images. Quantitative comparisons and user studies suggest that our model produces more compelling animations of given photographs than previously proposed methods. The results of our approach including comparisons with prior art can be seen in supplementary materials and on the project page https://saic-mdal.github.io/deep-landscape
Feature Selection for Learning to Predict Outcomes of Compute Cluster Jobs with Application to Decision Support
Dec 14, 2020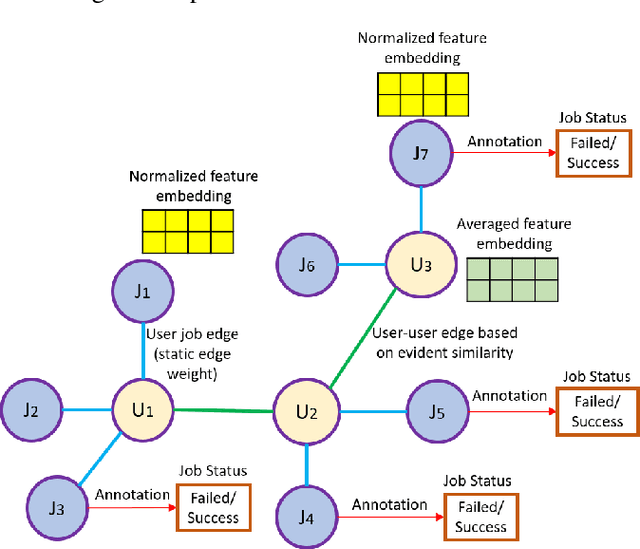

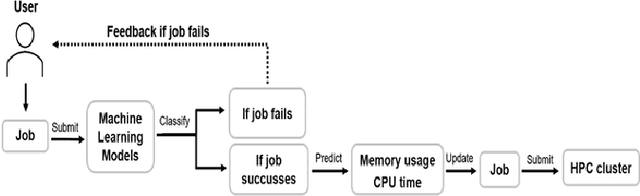
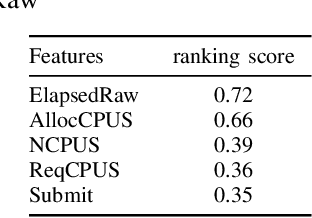
We present a machine learning framework and a new test bed for data mining from the Slurm Workload Manager for high-performance computing (HPC) clusters. The focus was to find a method for selecting features to support decisions: helping users decide whether to resubmit failed jobs with boosted CPU and memory allocations or migrate them to a computing cloud. This task was cast as both supervised classification and regression learning, specifically, sequential problem solving suitable for reinforcement learning. Selecting relevant features can improve training accuracy, reduce training time, and produce a more comprehensible model, with an intelligent system that can explain predictions and inferences. We present a supervised learning model trained on a Simple Linux Utility for Resource Management (Slurm) data set of HPC jobs using three different techniques for selecting features: linear regression, lasso, and ridge regression. Our data set represented both HPC jobs that failed and those that succeeded, so our model was reliable, less likely to overfit, and generalizable. Our model achieved an R^2 of 95\% with 99\% accuracy. We identified five predictors for both CPU and memory properties.
Using Multiple Subwords to Improve English-Esperanto Automated Literary Translation Quality
Nov 28, 2020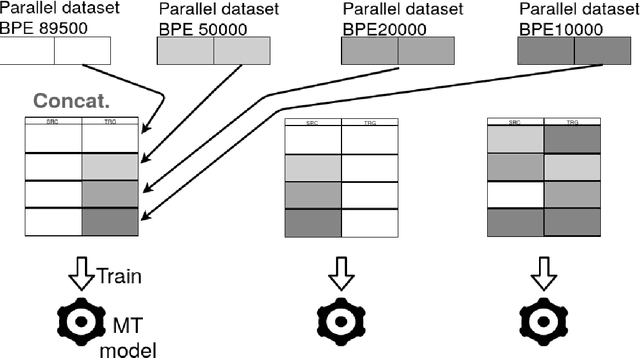
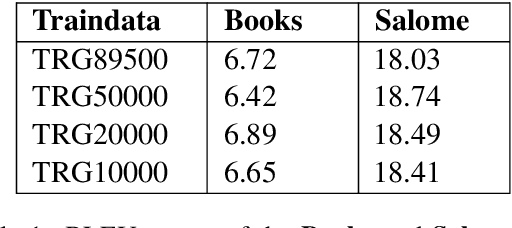
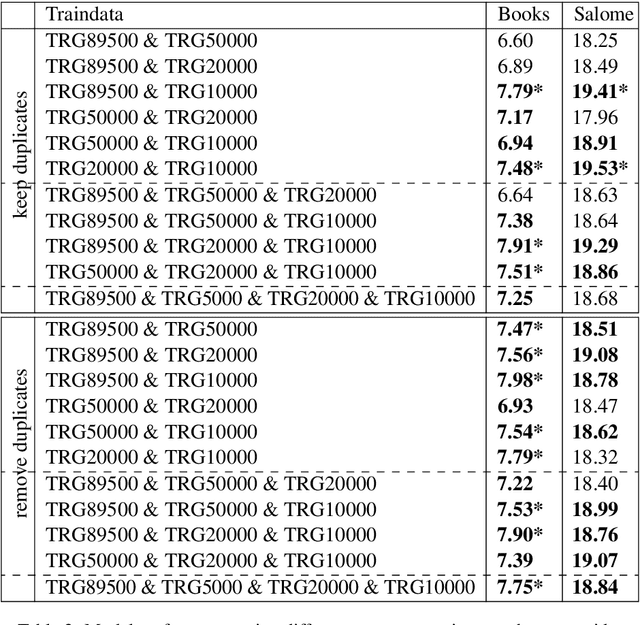
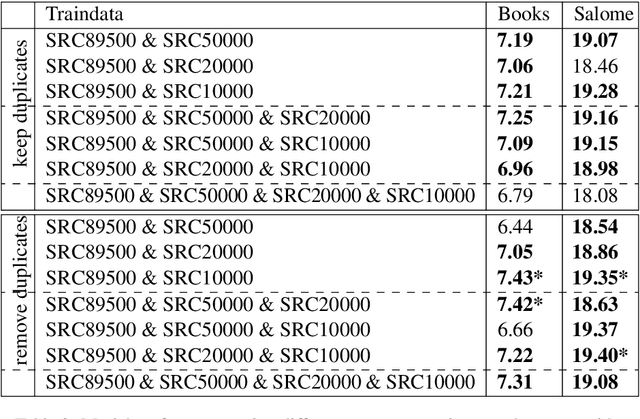
Building Machine Translation (MT) systems for low-resource languages remains challenging. For many language pairs, parallel data are not widely available, and in such cases MT models do not achieve results comparable to those seen with high-resource languages. When data are scarce, it is of paramount importance to make optimal use of the limited material available. To that end, in this paper we propose employing the same parallel sentences multiple times, only changing the way the words are split each time. For this purpose we use several Byte Pair Encoding models, with various merge operations used in their configuration. In our experiments, we use this technique to expand the available data and improve an MT system involving a low-resource language pair, namely English-Esperanto. As an additional contribution, we made available a set of English-Esperanto parallel data in the literary domain.
Entropic Causal Inference: Identifiability and Finite Sample Results
Jan 10, 2021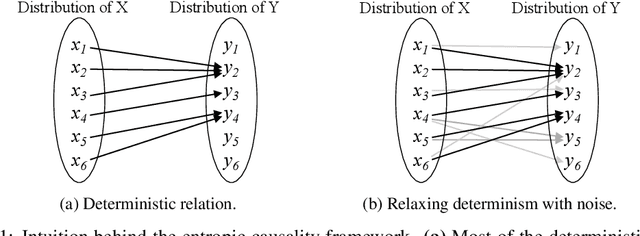
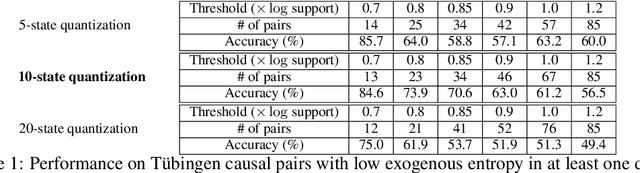
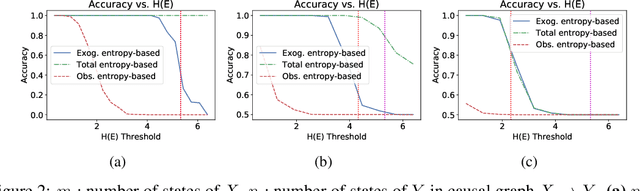
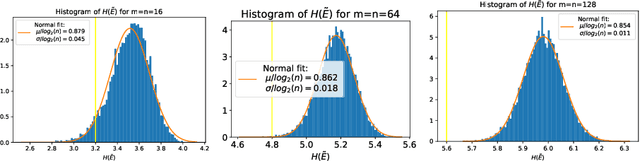
Entropic causal inference is a framework for inferring the causal direction between two categorical variables from observational data. The central assumption is that the amount of unobserved randomness in the system is not too large. This unobserved randomness is measured by the entropy of the exogenous variable in the underlying structural causal model, which governs the causal relation between the observed variables. Kocaoglu et al. conjectured that the causal direction is identifiable when the entropy of the exogenous variable is not too large. In this paper, we prove a variant of their conjecture. Namely, we show that for almost all causal models where the exogenous variable has entropy that does not scale with the number of states of the observed variables, the causal direction is identifiable from observational data. We also consider the minimum entropy coupling-based algorithmic approach presented by Kocaoglu et al., and for the first time demonstrate algorithmic identifiability guarantees using a finite number of samples. We conduct extensive experiments to evaluate the robustness of the method to relaxing some of the assumptions in our theory and demonstrate that both the constant-entropy exogenous variable and the no latent confounder assumptions can be relaxed in practice. We also empirically characterize the number of observational samples needed for causal identification. Finally, we apply the algorithm on Tuebingen cause-effect pairs dataset.
Behavioural pattern discovery from collections of egocentric photo-streams
Aug 21, 2020
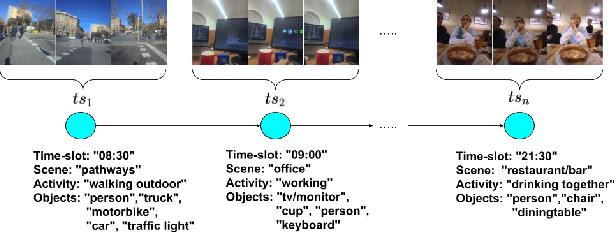
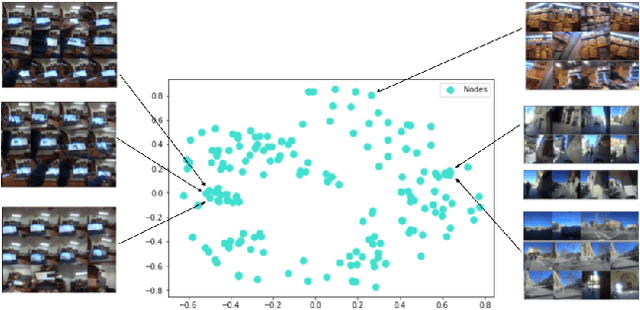
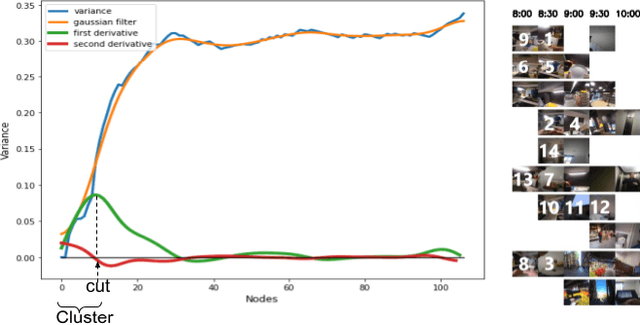
The automatic discovery of behaviour is of high importance when aiming to assess and improve the quality of life of people. Egocentric images offer a rich and objective description of the daily life of the camera wearer. This work proposes a new method to identify a person's patterns of behaviour from collected egocentric photo-streams. Our model characterizes time-frames based on the context (place, activities and environment objects) that define the images composition. Based on the similarity among the time-frames that describe the collected days for a user, we propose a new unsupervised greedy method to discover the behavioural pattern set based on a novel semantic clustering approach. Moreover, we present a new score metric to evaluate the performance of the proposed algorithm. We validate our method on 104 days and more than 100k images extracted from 7 users. Results show that behavioural patterns can be discovered to characterize the routine of individuals and consequently their lifestyle.
Optimising Design Verification Using Machine Learning: An Open Source Solution
Dec 04, 2020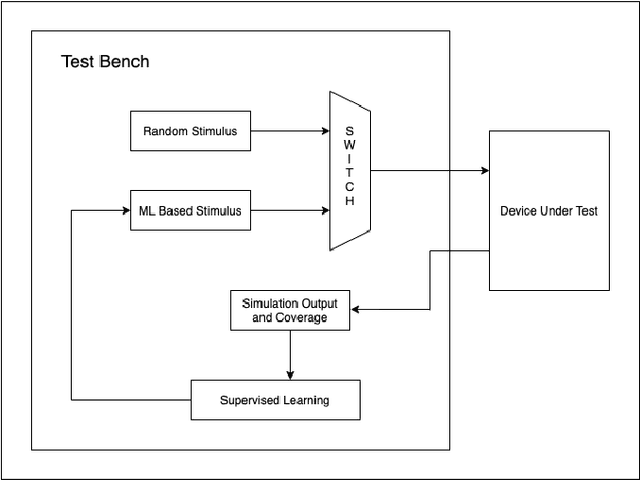

With the complexity of Integrated Circuits increasing, design verification has become the most time consuming part of the ASIC design flow. Nearly 70% of the SoC design cycle is consumed by verification. The most commonly used approach to test all corner cases is through the use of Constrained Random Verification. Random stimulus is given in order to hit all possible combinations and test the design thoroughly. However, this approach often requires significant human expertise to reach all corner cases. This paper presents an alternative using Machine Learning to generate the input stimulus. This will allow for faster thorough verification of the design with less human intervention. Furthermore, it is proposed to use the open source verification environment 'Cocotb'. Based on Python, it is simple, intuitive and has a vast library of functions for machine learning applications. This makes it more convenient to use than the bulkier approach using traditional Hardware Verification Languages such as System Verilog or Specman E.
Weakly Supervised Temporal Action Localization with Segment-Level Labels
Jul 03, 2020
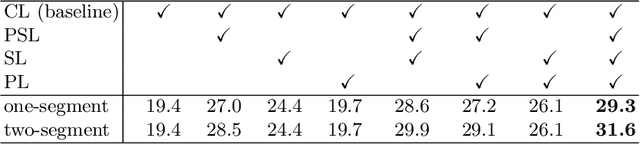
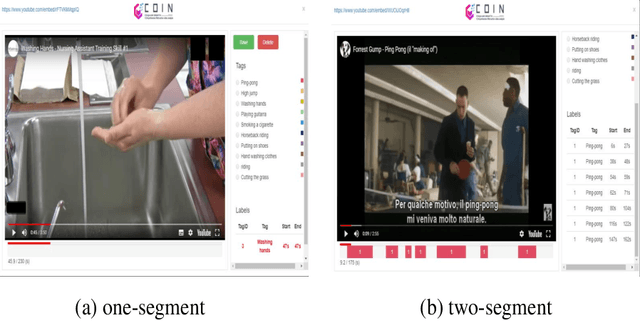
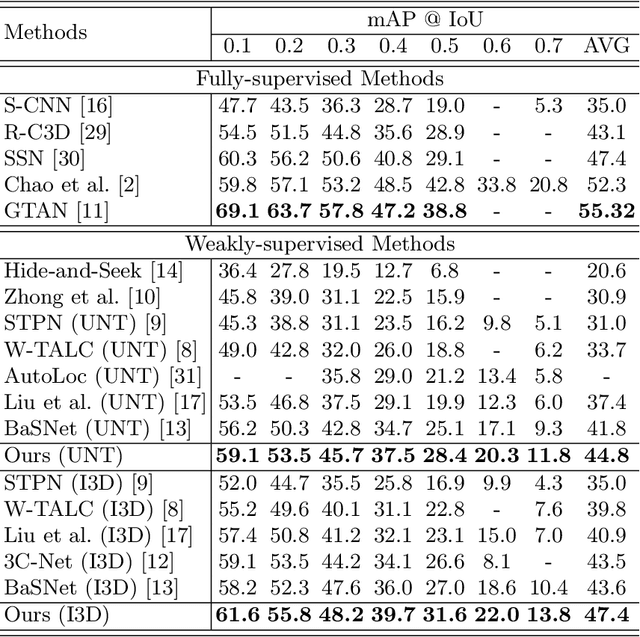
Temporal action localization presents a trade-off between test performance and annotation-time cost. Fully supervised methods achieve good performance with time-consuming boundary annotations. Weakly supervised methods with cheaper video-level category label annotations result in worse performance. In this paper, we introduce a new segment-level supervision setting: segments are labeled when annotators observe actions happening here. We incorporate this segment-level supervision along with a novel localization module in the training. Specifically, we devise a partial segment loss regarded as a loss sampling to learn integral action parts from labeled segments. Since the labeled segments are only parts of actions, the model tends to overfit along with the training process. To tackle this problem, we first obtain a similarity matrix from discriminative features guided by a sphere loss. Then, a propagation loss is devised based on the matrix to act as a regularization term, allowing implicit unlabeled segments propagation during training. Experiments validate that our method can outperform the video-level supervision methods with almost same the annotation time.