 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Generation of Human-aware Navigation Maps using Graph Neural Networks
Nov 10, 2020
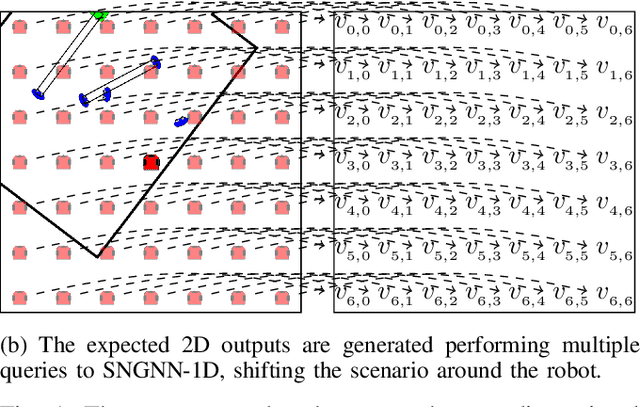
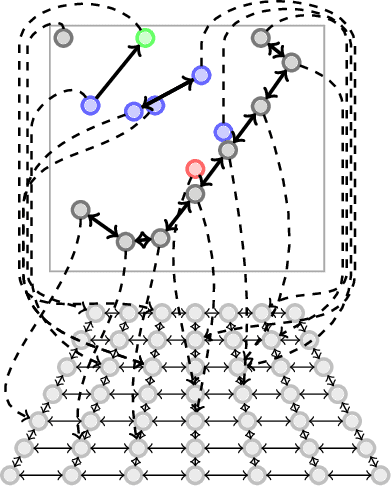
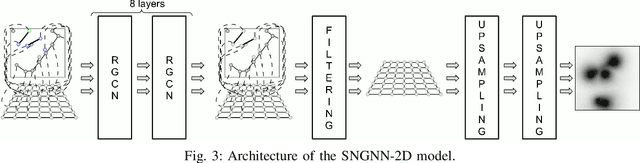
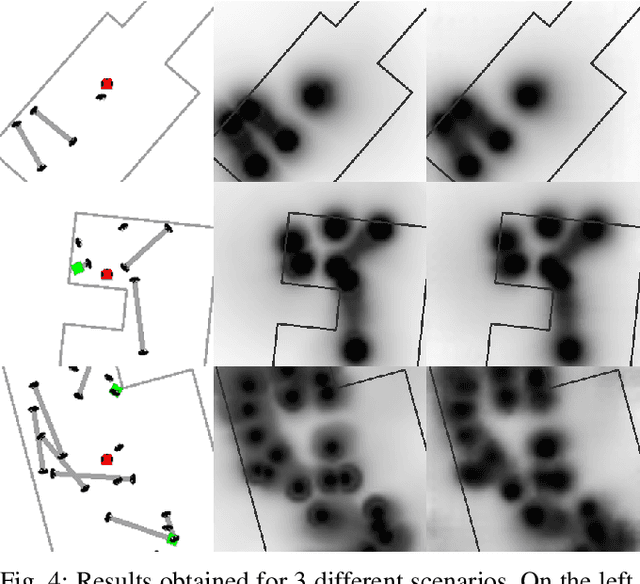
Minimising the discomfort caused by robots when navigating in social situations is crucial for them to be accepted. The paper presents a machine learning-based framework that bootstraps existing one-dimensional datasets to generate a cost map dataset and a model combining Graph Neural Network and Convolutional Neural Network layers to produce cost maps for human-aware navigation in real-time. The proposed framework is evaluated against the original one-dimensional dataset and in simulated navigation tasks. The results outperform similar state-of-the-art-methods considering the accuracy on the dataset and the navigation metrics used. The applications of the proposed framework are not limited to human-aware navigation, it could be applied to other fields where map generation is needed.
Impatient DNNs - Deep Neural Networks with Dynamic Time Budgets
Oct 10, 2016
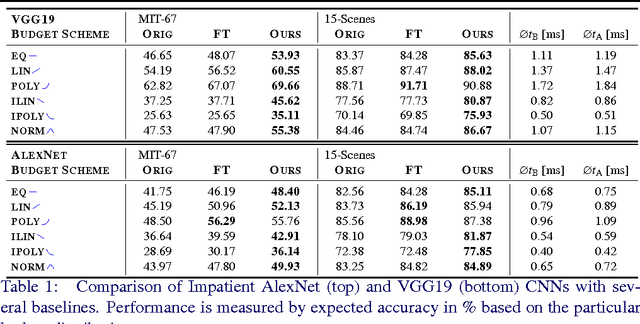
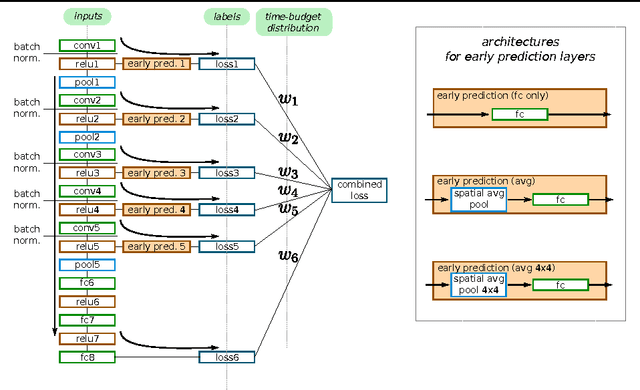

We propose Impatient Deep Neural Networks (DNNs) which deal with dynamic time budgets during application. They allow for individual budgets given a priori for each test example and for anytime prediction, i.e., a possible interruption at multiple stages during inference while still providing output estimates. Our approach can therefore tackle the computational costs and energy demands of DNNs in an adaptive manner, a property essential for real-time applications. Our Impatient DNNs are based on a new general framework of learning dynamic budget predictors using risk minimization, which can be applied to current DNN architectures by adding early prediction and additional loss layers. A key aspect of our method is that all of the intermediate predictors are learned jointly. In experiments, we evaluate our approach for different budget distributions, architectures, and datasets. Our results show a significant gain in expected accuracy compared to common baselines.
DoubleFusion: Real-time Capture of Human Performances with Inner Body Shapes from a Single Depth Sensor
Apr 17, 2018
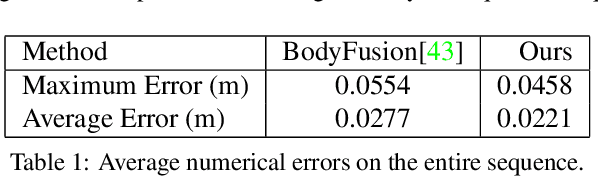
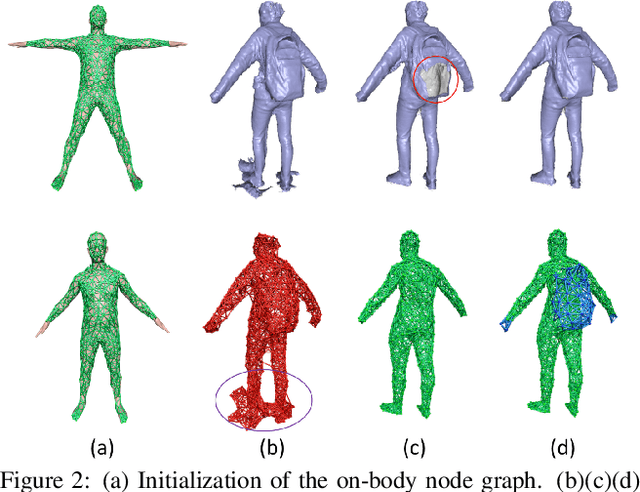
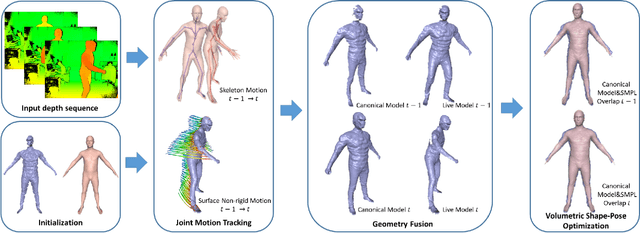
We propose DoubleFusion, a new real-time system that combines volumetric dynamic reconstruction with data-driven template fitting to simultaneously reconstruct detailed geometry, non-rigid motion and the inner human body shape from a single depth camera. One of the key contributions of this method is a double layer representation consisting of a complete parametric body shape inside, and a gradually fused outer surface layer. A pre-defined node graph on the body surface parameterizes the non-rigid deformations near the body, and a free-form dynamically changing graph parameterizes the outer surface layer far from the body, which allows more general reconstruction. We further propose a joint motion tracking method based on the double layer representation to enable robust and fast motion tracking performance. Moreover, the inner body shape is optimized online and forced to fit inside the outer surface layer. Overall, our method enables increasingly denoised, detailed and complete surface reconstructions, fast motion tracking performance and plausible inner body shape reconstruction in real-time. In particular, experiments show improved fast motion tracking and loop closure performance on more challenging scenarios.
Reconfigurable Intelligent Surfaces and Machine Learning for Wireless Fingerprinting Localization
Oct 07, 2020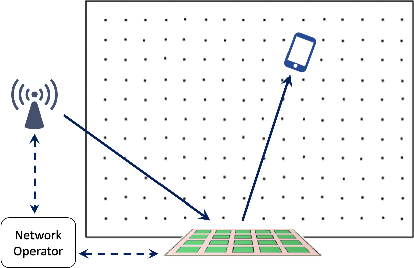
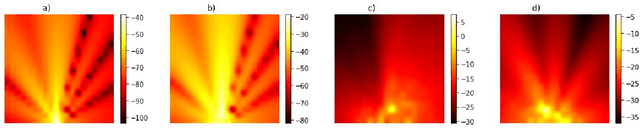
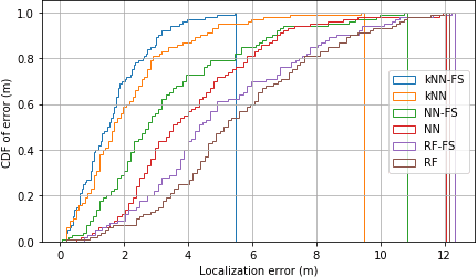
Reconfigurable Intelligent Surfaces (RISs) promise improved, secure and more efficient wireless communications. We propose and demonstrate how to exploit the diversity offered by RISs to generate and select easily differentiable radio maps for use in wireless fingerprinting localization applications. Further, we apply machine learning feature selection methods to prune the large state space of the RIS, thus reducing complexity and enhancing localization accuracy and position acquisition time. We evaluate our proposed approach by generation of radio maps with a novel radio propagation modelling and simulations.
Robustness to Spurious Correlations via Human Annotations
Jul 13, 2020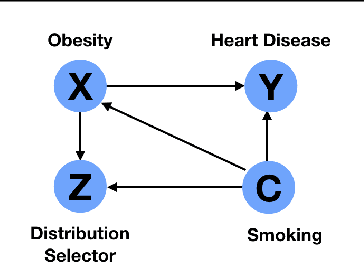
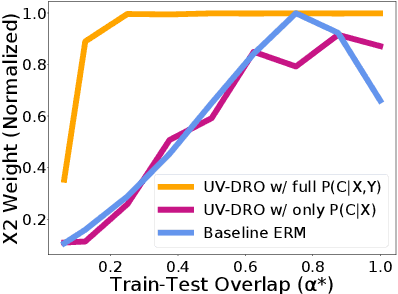
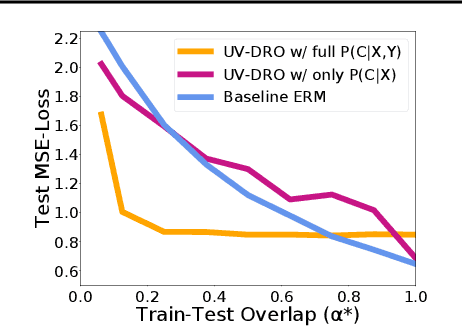
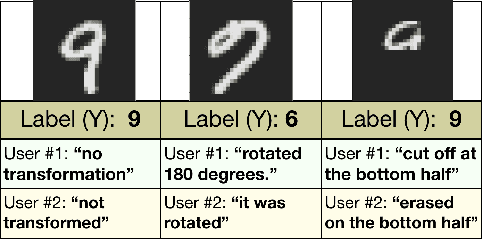
The reliability of machine learning systems critically assumes that the associations between features and labels remain similar between training and test distributions. However, unmeasured variables, such as confounders, break this assumption---useful correlations between features and labels at training time can become useless or even harmful at test time. For example, high obesity is generally predictive for heart disease, but this relation may not hold for smokers who generally have lower rates of obesity and higher rates of heart disease. We present a framework for making models robust to spurious correlations by leveraging humans' common sense knowledge of causality. Specifically, we use human annotation to augment each training example with a potential unmeasured variable (i.e. an underweight patient with heart disease may be a smoker), reducing the problem to a covariate shift problem. We then introduce a new distributionally robust optimization objective over unmeasured variables (UV-DRO) to control the worst-case loss over possible test-time shifts. Empirically, we show improvements of 5-10% on a digit recognition task confounded by rotation, and 1.5-5% on the task of analyzing NYPD Police Stops confounded by location.
Improving Weakly Supervised Visual Grounding by Contrastive Knowledge Distillation
Jul 03, 2020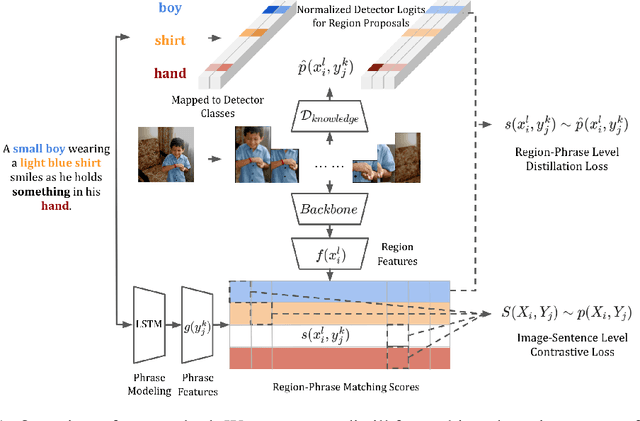
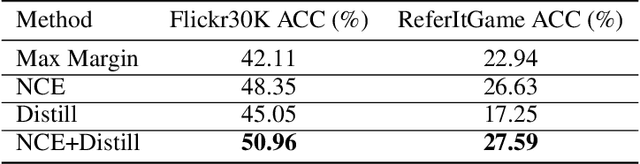

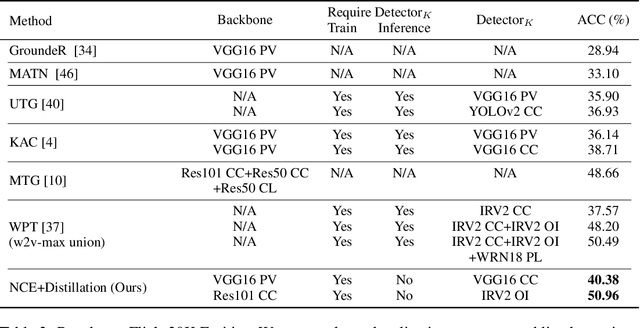
Weakly supervised phrase grounding aims at learning region-phrase correspondences using only image-sentence pairs. A major challenge thus lies in the missing links between image regions and sentence phrases during training. To address this challenge, we leverage a generic object detector at training time, and propose a contrastive learning framework that accounts for both region-phrase and image-sentence matching. Our core innovation is the learning of a region-phrase score function, based on which an image-sentence score function is further constructed. Importantly, our region-phrase score function is learned by distilling from soft matching scores between the detected object class names and candidate phrases within an image-sentence pair, while the image-sentence score function is supervised by ground-truth image-sentence pairs. The design of such score functions removes the need of object detection at test time, thereby significantly reducing the inference cost. Without bells and whistles, our approach achieves state-of-the-art results on the task of visual phrase grounding, surpassing previous methods that require expensive object detectors at test time.
A Comparative Study of Temporal Non-Negative Matrix Factorization with Gamma Markov Chains
Jun 23, 2020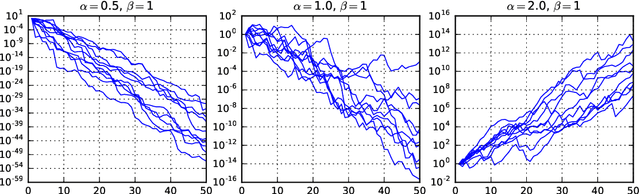

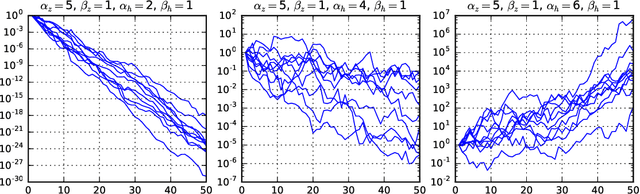

Non-negative matrix factorization (NMF) has become a well-established class of methods for the analysis of non-negative data. In particular, a lot of effort has been devoted to probabilistic NMF, namely estimation or inference tasks in probabilistic models describing the data, based for example on Poisson or exponential likelihoods. When dealing with time series data, several works have proposed to model the evolution of the activation coefficients as a non-negative Markov chain, most of the time in relation with the Gamma distribution, giving rise to so-called temporal NMF models. In this paper, we review three Gamma Markov chains of the NMF literature, and show that they all share the same drawback: the absence of a well-defined stationary distribution. We then introduce a fourth process, an overlooked model of the time series literature named BGAR(1), which overcomes this limitation. These four temporal NMF models are then compared in a MAP framework on a prediction task, in the context of the Poisson likelihood.
ScribbleBox: Interactive Annotation Framework for Video Object Segmentation
Aug 22, 2020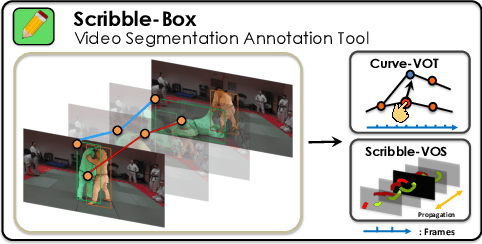
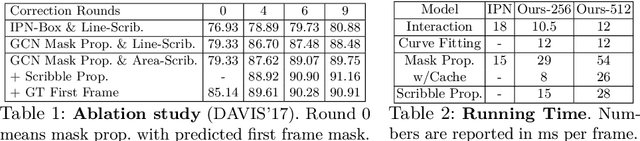
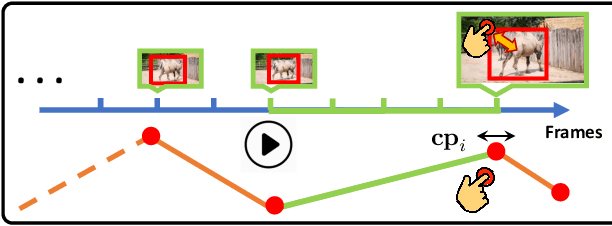
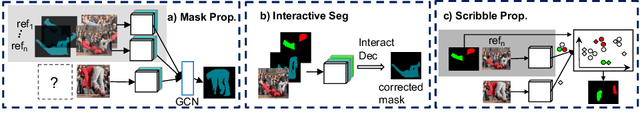
Manually labeling video datasets for segmentation tasks is extremely time consuming. In this paper, we introduce ScribbleBox, a novel interactive framework for annotating object instances with masks in videos. In particular, we split annotation into two steps: annotating objects with tracked boxes, and labeling masks inside these tracks. We introduce automation and interaction in both steps. Box tracks are annotated efficiently by approximating the trajectory using a parametric curve with a small number of control points which the annotator can interactively correct. Our approach tolerates a modest amount of noise in the box placements, thus typically only a few clicks are needed to annotate tracked boxes to a sufficient accuracy. Segmentation masks are corrected via scribbles which are efficiently propagated through time. We show significant performance gains in annotation efficiency over past work. We show that our ScribbleBox approach reaches 88.92% J&F on DAVIS2017 with 9.14 clicks per box track, and 4 frames of scribble annotation.
Automating Cluster Analysis to Generate Customer Archetypes for Residential Energy Consumers in South Africa
Jun 23, 2020
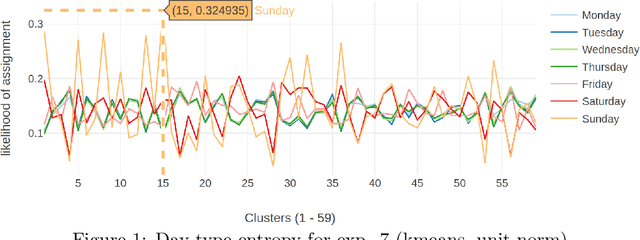
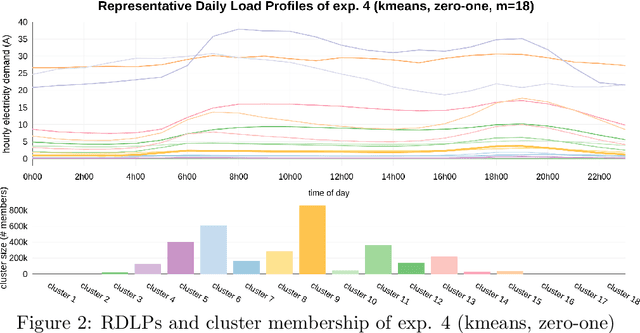
Time series clustering is frequently used in the energy domain to generate representative energy consumption patterns of households, which can be used to construct customer archetypes for long term energy planning. Selecting the optimal set of clusters however requires extensive experimentation and domain knowledge, and typically relies on a combination of metrics together with additional expert guidance through visual inspection of the clustering results. This can be time consuming, subjective and difficult to reproduce. In this work we present an approach that uses competency questions to elicit expert knowledge and to specify the requirements for creating residential energy customer archetypes from energy meter data. The approach enabled a structured and formal cluster analysis process, while easing cluster evaluation and reducing the time to select an optimal cluster set that satisfies the application requirements. The usefulness of the selected cluster set is demonstrated in a use case application that reconstructs a customer archetype developed manually by experts.
Accelerating Road Sign Ground Truth Construction with Knowledge Graph and Machine Learning
Dec 04, 2020
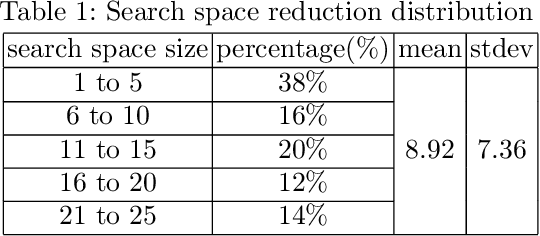


Having a comprehensive, high-quality dataset of road sign annotation is critical to the success of AI-based Road Sign Recognition (RSR) systems. In practice, annotators often face difficulties in learning road sign systems of different countries; hence, the tasks are often time-consuming and produce poor results. We propose a novel approach using knowledge graphs and a machine learning algorithm - variational prototyping-encoder (VPE) - to assist human annotators in classifying road signs effectively. Annotators can query the Road Sign Knowledge Graph using visual attributes and receive closest matching candidates suggested by the VPE model. The VPE model uses the candidates from the knowledge graph and a real sign image patch as inputs. We show that our knowledge graph approach can reduce sign search space by 98.9%. Furthermore, with VPE, our system can propose the correct single candidate for 75% of signs in the tested datasets, eliminating the human search effort entirely in those cases.
* 12 pages, 5 figures