 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Cost-Effective Federated Learning Design
Dec 15, 2020
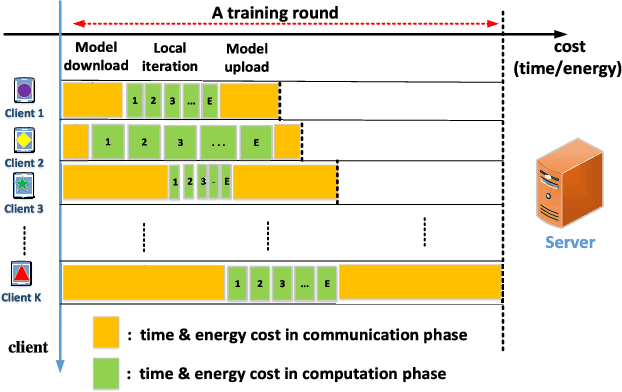
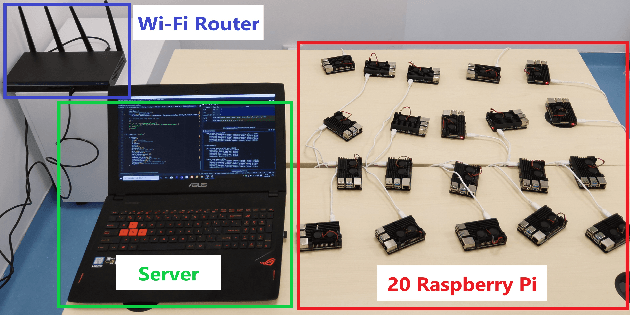

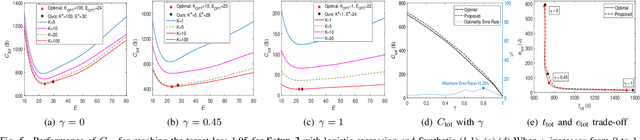
Federated learning (FL) is a distributed learning paradigm that enables a large number of devices to collaboratively learn a model without sharing their raw data. Despite its practical efficiency and effectiveness, the iterative on-device learning process incurs a considerable cost in terms of learning time and energy consumption, which depends crucially on the number of selected clients and the number of local iterations in each training round. In this paper, we analyze how to design adaptive FL that optimally chooses these essential control variables to minimize the total cost while ensuring convergence. Theoretically, we analytically establish the relationship between the total cost and the control variables with the convergence upper bound. To efficiently solve the cost minimization problem, we develop a low-cost sampling-based algorithm to learn the convergence related unknown parameters. We derive important solution properties that effectively identify the design principles for different metric preferences. Practically, we evaluate our theoretical results both in a simulated environment and on a hardware prototype. Experimental evidence verifies our derived properties and demonstrates that our proposed solution achieves near-optimal performance for various datasets, different machine learning models, and heterogeneous system settings.
Wireless Localisation in WiFi using Novel Deep Architectures
Oct 16, 2020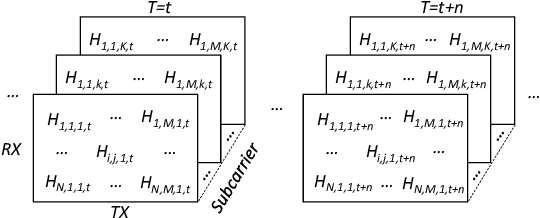
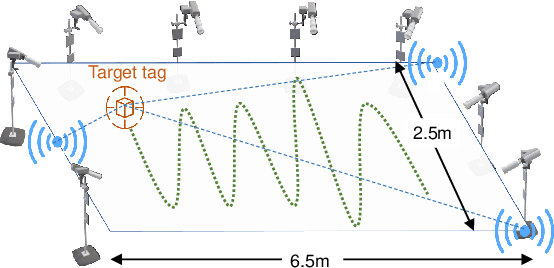
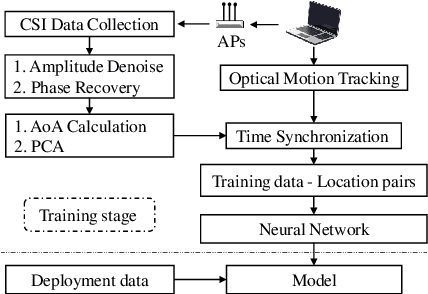
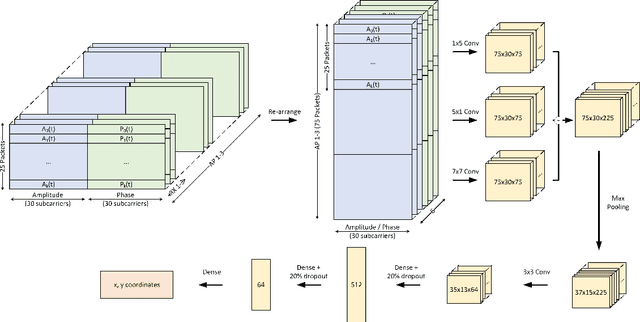
This paper studies the indoor localisation of WiFi devices based on a commodity chipset and standard channel sounding. First, we present a novel shallow neural network (SNN) in which features are extracted from the channel state information (CSI) corresponding to WiFi subcarriers received on different antennas and used to train the model. The single-layer architecture of this localisation neural network makes it lightweight and easy-to-deploy on devices with stringent constraints on computational resources. We further investigate for localisation the use of deep learning models and design novel architectures for convolutional neural network (CNN) and long-short term memory (LSTM). We extensively evaluate these localisation algorithms for continuous tracking in indoor environments. Experimental results prove that even an SNN model, after a careful handcrafted feature extraction, can achieve accurate localisation. Meanwhile, using a well-organised architecture, the neural network models can be trained directly with raw data from the CSI and localisation features can be automatically extracted to achieve accurate position estimates. We also found that the performance of neural network-based methods are directly affected by the number of anchor access points (APs) regardless of their structure. With three APs, all neural network models proposed in this paper can obtain localisation accuracy of around 0.5 metres. In addition the proposed deep NN architecture reduces the data pre-processing time by 6.5 hours compared with a shallow NN using the data collected in our testbed. In the deployment phase, the inference time is also significantly reduced to 0.1 ms per sample. We also demonstrate the generalisation capability of the proposed method by evaluating models using different target movement characteristics to the ones in which they were trained.
Learning Determinantal Point Processes in Sublinear Time
Oct 19, 2016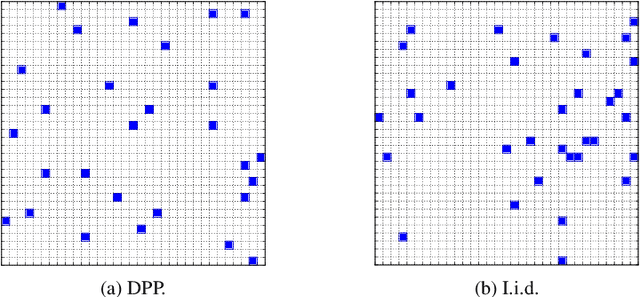
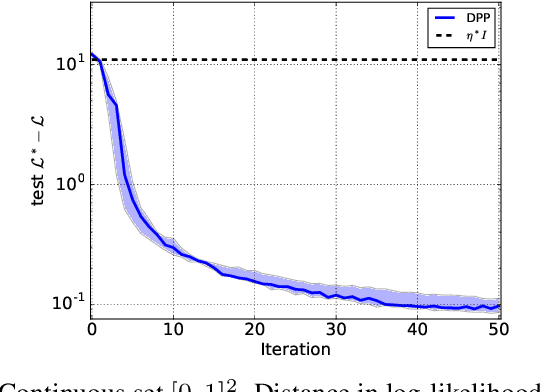
We propose a new class of determinantal point processes (DPPs) which can be manipulated for inference and parameter learning in potentially sublinear time in the number of items. This class, based on a specific low-rank factorization of the marginal kernel, is particularly suited to a subclass of continuous DPPs and DPPs defined on exponentially many items. We apply this new class to modelling text documents as sampling a DPP of sentences, and propose a conditional maximum likelihood formulation to model topic proportions, which is made possible with no approximation for our class of DPPs. We present an application to document summarization with a DPP on $2^{500}$ items.
YieldNet: A Convolutional Neural Network for Simultaneous Corn and Soybean Yield Prediction Based on Remote Sensing Data
Dec 05, 2020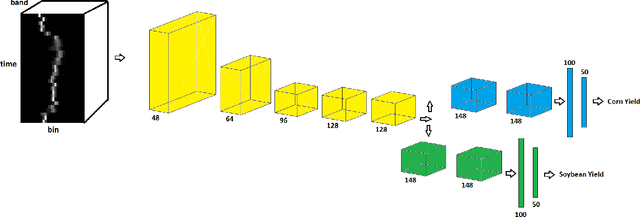
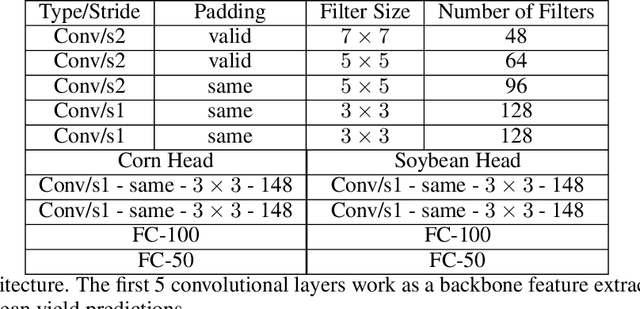
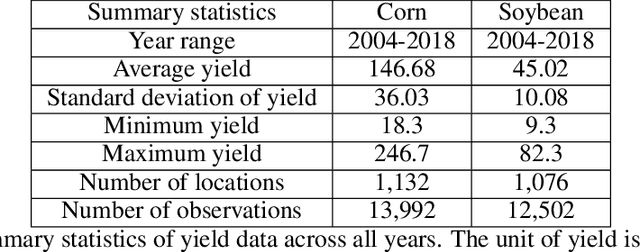
Large scale crop yield estimation is, in part, made possible due to the availability of remote sensing data allowing for the continuous monitoring of crops throughout its growth state. Having this information allows stakeholders the ability to make real-time decisions to maximize yield potential. Although various models exist that predict yield from remote sensing data, there currently does not exist an approach that can estimate yield for multiple crops simultaneously, and thus leads to more accurate predictions. A model that predicts yield of multiple crops and concurrently considers the interaction between multiple crop's yield. We propose a new model called YieldNet which utilizes a novel deep learning framework that uses transfer learning between corn and soybean yield predictions by sharing the weights of the backbone feature extractor. Additionally, to consider the multi-target response variable, we propose a new loss function. Numerical results demonstrate that our proposed method accurately predicts yield from one to four months before the harvest, and is competitive to other state-of-the-art approaches.
A Generalizable Model for Fault Detection in Offshore Wind Turbines Based on Deep Learning
Nov 25, 2020
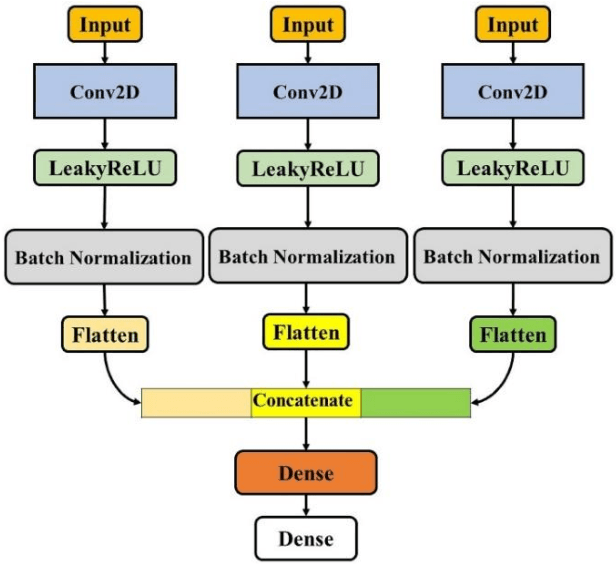
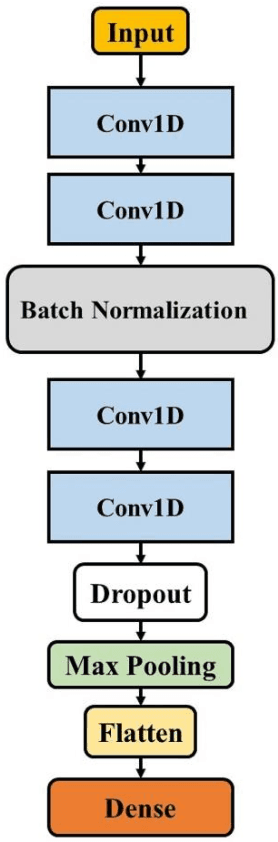
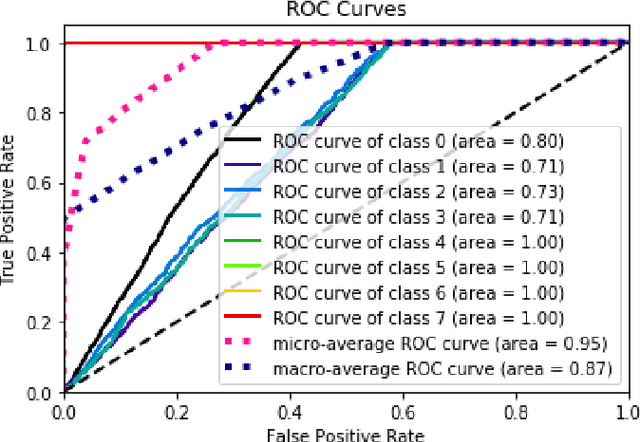
This paper presents a new deep learning-based model for fault detection in offshore wind turbines. To design a generalizable model for fault detection, we use 5 sensors and a sliding window to exploit the inherent temporal information contained in the raw time-series data obtained from sensors. The proposed model uses the nonlinear relationships among multiple sensor variables and the temporal dependency of each sensor on others that considerably increases the performance of fault detection model. A 10-fold cross-validation is used to verify the generalization of the model and evaluate the classification metrics. To evaluate the performance of the model, simulated data from a benchmark floating offshore wind turbine (FOWT) with supervisory control and data acquisition (SCADA) are used. The results illustrate that the proposed model would accurately disclose and classify more than 99% of the faults. Moreover, it is generalizable and can be used to detect faults for different types of systems.
Storage Fit Learning with Feature Evolvable Streams
Jul 22, 2020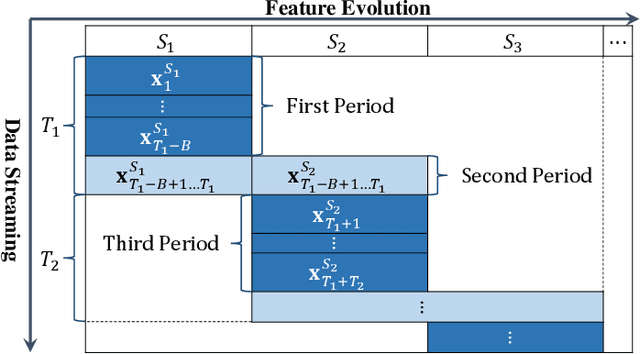
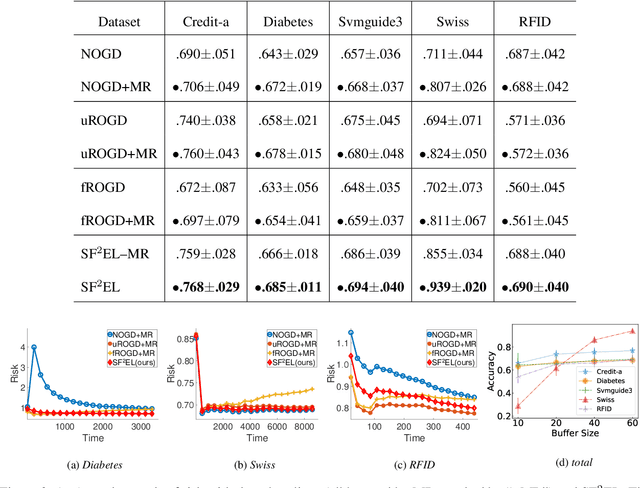
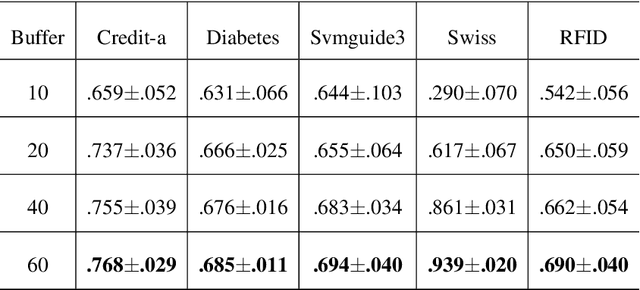
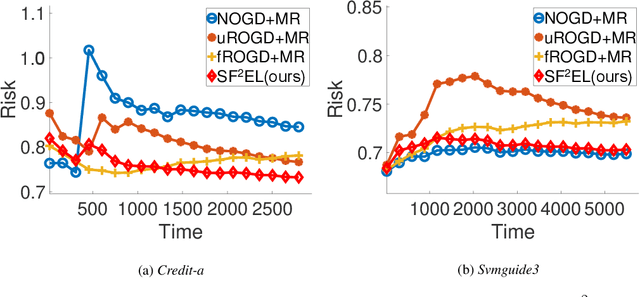
Feature evolvable learning has been widely studied in recent years where old features will vanish and new features will emerge when learning with streams. Conventional methods usually assume that a label will be revealed after prediction at each time step. However, in practice, this assumption may not hold whereas no label will be given at most time steps. To tackle this problem, we leverage the technique of manifold regularization to utilize the previous similar data to assist the refinement of the online model. Nevertheless, this approach needs to store all previous data which is impossible in learning with streams that arrive sequentially in large volume. Thus we need a buffer to store part of them. Considering that different devices may have different storage budgets, the learning approaches should be flexible subject to the storage budget limit. In this paper, we propose a new setting: Storage-Fit Feature-Evolvable streaming Learning (SF2EL) which incorporates the issue of rarely-provided labels into feature evolution. Our framework is able to fit its behavior to different storage budgets when learning with feature evolvable streams with unlabeled data. Besides, both theoretical and empirical results validate that our approach can preserve the merit of the original feature evolvable learning i.e., can always track the best baseline and thus perform well at any time step.
Pixel-level Corrosion Detection on Metal Constructions by Fusion of Deep Learning Semantic and Contour Segmentation
Aug 12, 2020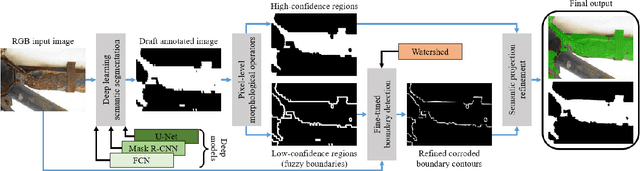
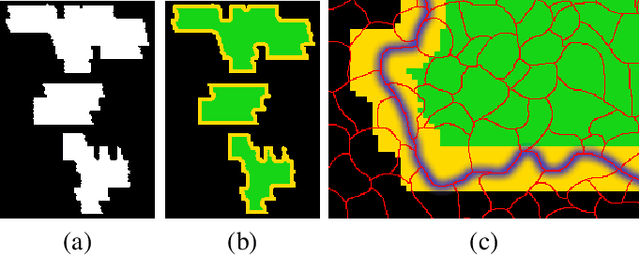

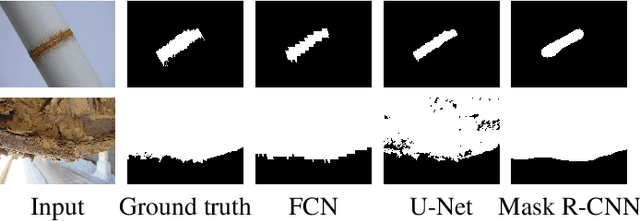
Corrosion detection on metal constructions is a major challenge in civil engineering for quick, safe and effective inspection. Existing image analysis approaches tend to place bounding boxes around the defected region which is not adequate both for structural analysis and pre-fabrication, an innovative construction concept which reduces maintenance cost, time and improves safety. In this paper, we apply three semantic segmentation-oriented deep learning models (FCN, U-Net and Mask R-CNN) for corrosion detection, which perform better in terms of accuracy and time and require a smaller number of annotated samples compared to other deep models, e.g. CNN. However, the final images derived are still not sufficiently accurate for structural analysis and pre-fabrication. Thus, we adopt a novel data projection scheme that fuses the results of color segmentation, yielding accurate but over-segmented contours of a region, with a processed area of the deep masks, resulting in high-confidence corroded pixels.
ActionXPose: A Novel 2D Multi-view Pose-based Algorithm for Real-time Human Action Recognition
Oct 29, 2018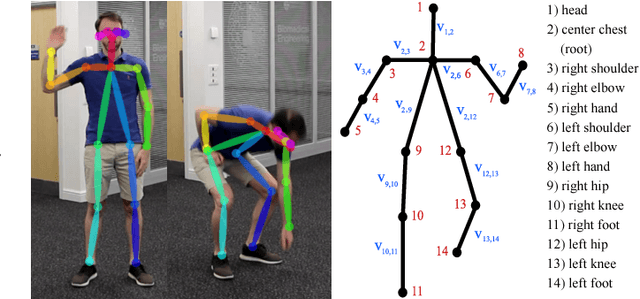
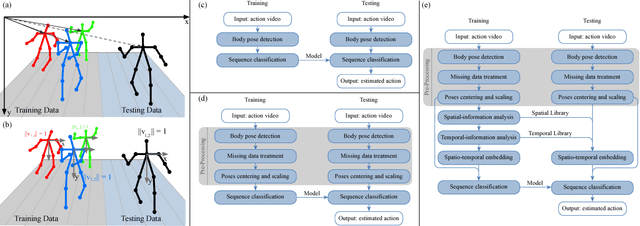
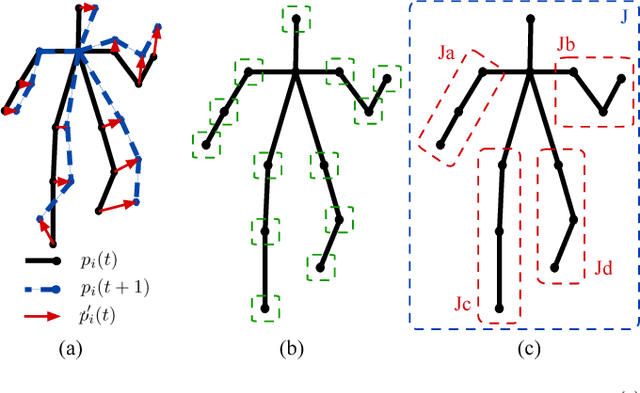

We present ActionXPose, a novel 2D pose-based algorithm for posture-level Human Action Recognition (HAR). The proposed approach exploits 2D human poses provided by OpenPose detector from RGB videos. ActionXPose aims to process poses data to be provided to a Long Short-Term Memory Neural Network and to a 1D Convolutional Neural Network, which solve the classification problem. ActionXPose is one of the first algorithms that exploits 2D human poses for HAR. The algorithm has real-time performance and it is robust to camera movings, subject proximity changes, viewpoint changes, subject appearance changes and provide high generalization degree. In fact, extensive simulations show that ActionXPose can be successfully trained using different datasets at once. State-of-the-art performance on popular datasets for posture-related HAR problems (i3DPost, KTH) are provided and results are compared with those obtained by other methods, including the selected ActionXPose baseline. Moreover, we also proposed two novel datasets called MPOSE and ISLD recorded in our Intelligent Sensing Lab, to show ActionXPose generalization performance.
Common equivalence and size after forgetting
Jun 19, 2020Forgetting variables from a propositional formula may increase its size. Introducing new variables is a way to shorten it. Both operations can be expressed in terms of common equivalence, a weakened version of equivalence. In turn, common equivalence can be expressed in terms of forgetting. An algorithm for forgetting and checking common equivalence in polynomial space is given for the Horn case; it is polynomial-time for the subclass of single-head formulae. Minimizing after forgetting is polynomial-time if the formula is also acyclic and variables cannot be introduced, NP-hard when they can.
Distant-Supervised Slot-Filling for E-Commerce Queries
Dec 15, 2020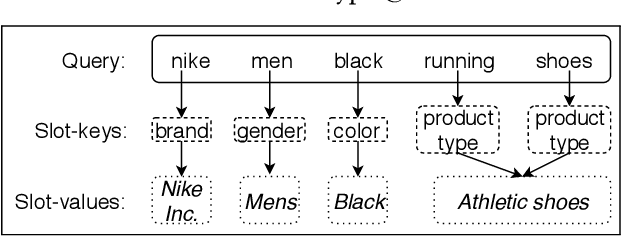
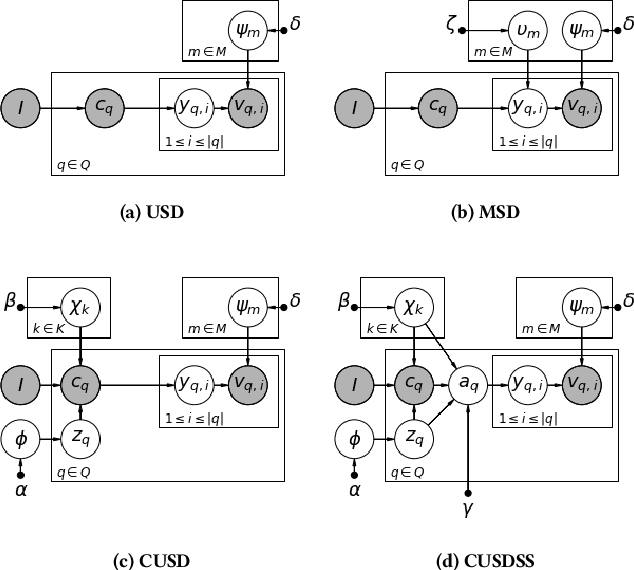
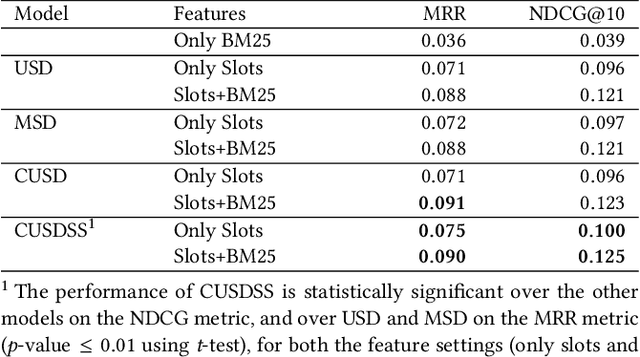
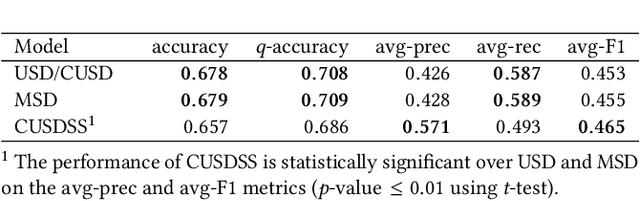
Slot-filling refers to the task of annotating individual terms in a query with the corresponding intended product characteristics (product type, brand, gender, size, color, etc.). These characteristics can then be used by a search engine to return results that better match the query's product intent. Traditional methods for slot-filling require the availability of training data with ground truth slot-annotation information. However, generating such labeled data, especially in e-commerce is expensive and time-consuming because the number of slots increases as new products are added. In this paper, we present distant-supervised probabilistic generative models, that require no manual annotation. The proposed approaches leverage the readily available historical query logs and the purchases that these queries led to, and also exploit co-occurrence information among the slots in order to identify intended product characteristics. We evaluate our approaches by considering how they affect retrieval performance, as well as how well they classify the slots. In terms of retrieval, our approaches achieve better ranking performance (up to 156%) over Okapi BM25. Moreover, our approach that leverages co-occurrence information leads to better performance than the one that does not on both the retrieval and slot classification tasks.