 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Experimental Verification of Stability Theory for a Planar Rigid Body with Two Unilateral Frictional Contacts
Aug 24, 2020
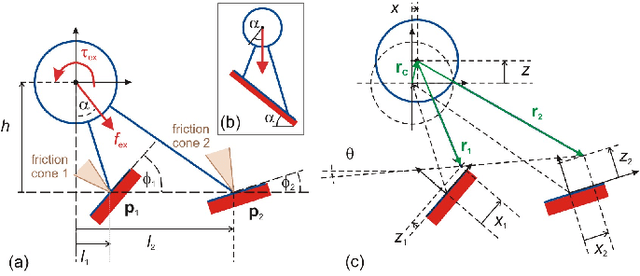
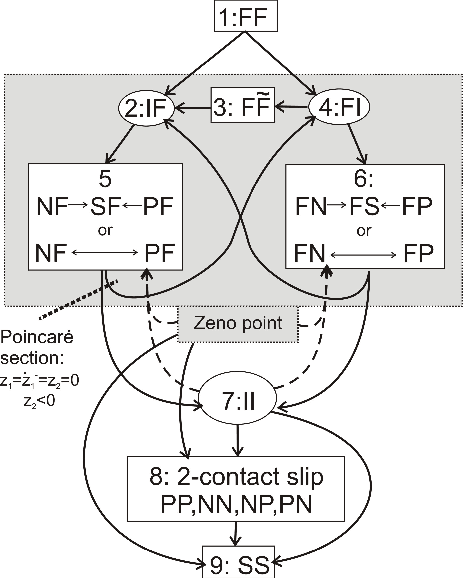
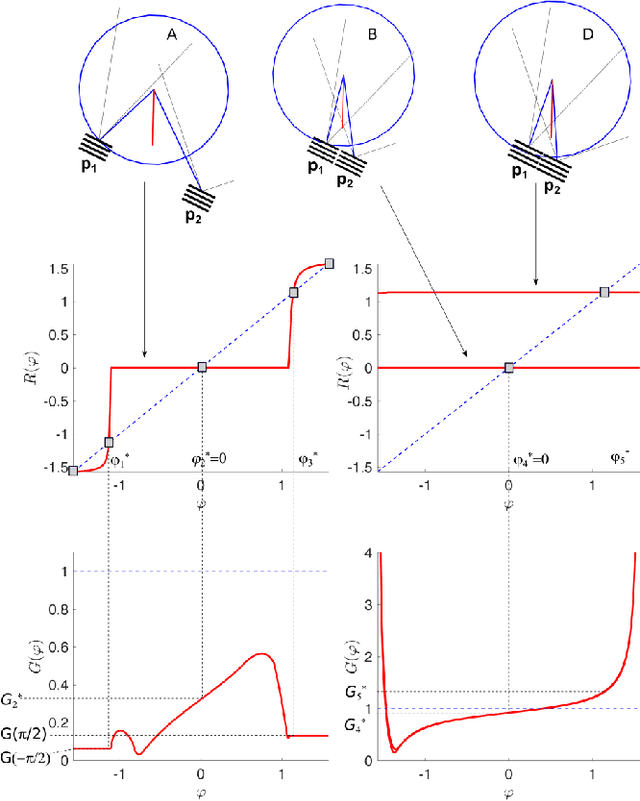
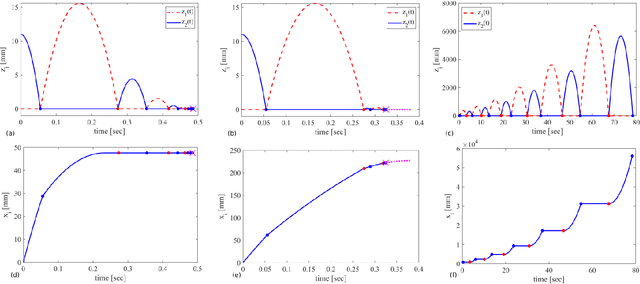
Stability of equilibrium states in mechanical systems with multiple unilateral frictional contacts is an important practical requirement, with high relevance for robotic applications. In our previous work, we theoretically analyzed finite-time Lyapunov stability for a minimal model of planar rigid body with two frictional point contacts. Assuming inelastic impacts and Coulomb friction, conditions for stability and instability of an equilibrium configuration have been derived. In this work, we present for the first time an experimental demonstration of this stability theory, using a variable-structure rigid ''biped'' with frictional footpads on an inclined plane. By changing the biped's center-of-mass location, we attain different equilibrium states, which respond to small perturbations by divergence or convergence, showing remarkable agreement with the predictions of the stability theory. Using high-speed recording of video movies, good quantitative agreement between experiments and numerical simulations is obtained, and limitations of the rigid-body model and inelastic impact assumptions are also studied. The results prove the utility and practical value of our stability theory.
Continual Adaptation for Deep Stereo
Jul 14, 2020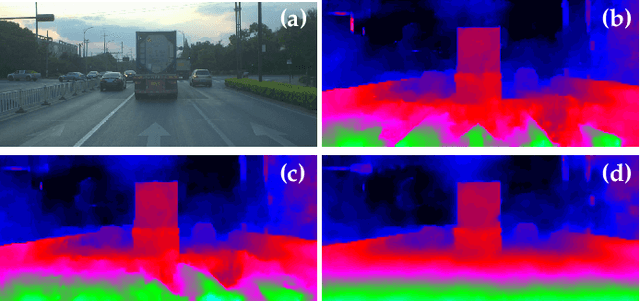
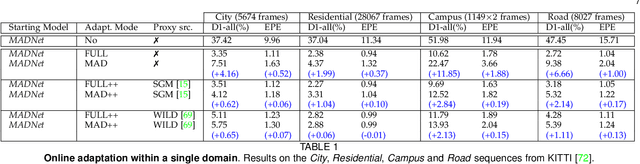
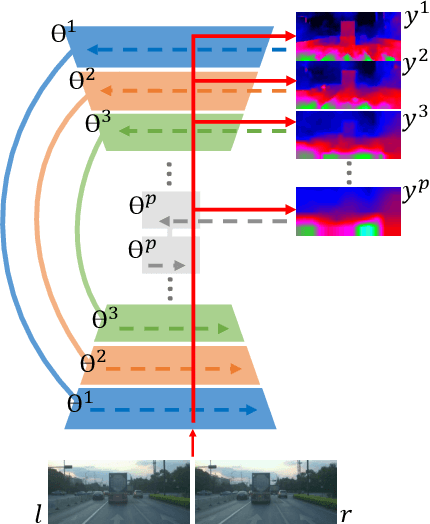

Depth estimation from stereo images is carried out with unmatched results by convolutional neural networks trained end-to-end to regress dense disparities. Like for most tasks, this is possible if large amounts of labelled samples are available for training, possibly covering the whole data distribution encountered at deployment time. Being such an assumption systematically unmet in real applications, the capacity of adapting to any unseen setting becomes of paramount importance. Purposely, we propose a continual adaptation paradigm for deep stereo networks designed to deal with challenging and ever-changing environments. We design a lightweight and modular architecture, Modularly ADaptive Network (MADNet), and formulate Modular ADaptation algorithms (MAD, MAD++) which permit efficient optimization of independent sub-portions of the entire network. In our paradigm, the learning signals needed to continuously adapt models online can be sourced from self-supervision via right-to-left image warping or from traditional stereo algorithms. With both sources, no other data than the input images being gathered at deployment time are needed. Thus, our network architecture and adaptation algorithms realize the first real-time self-adaptive deep stereo system and pave the way for a new paradigm that can facilitate practical deployment of end-to-end architectures for dense disparity regression.
A Recurrent Vision-and-Language BERT for Navigation
Nov 26, 2020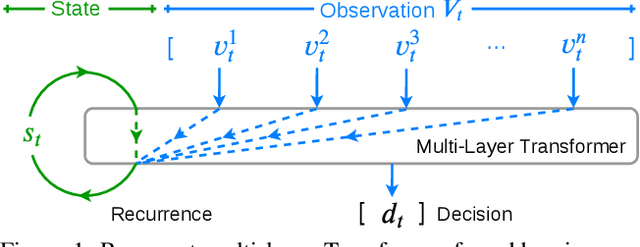
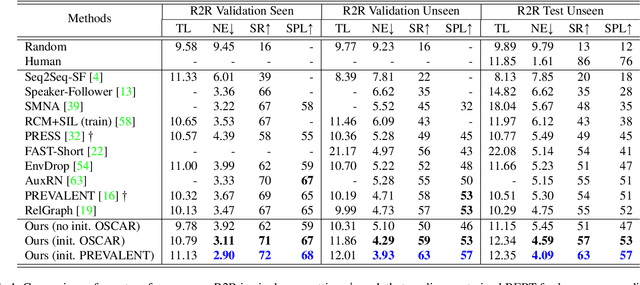
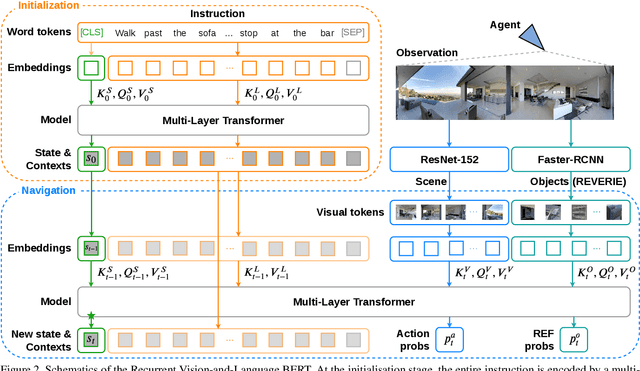
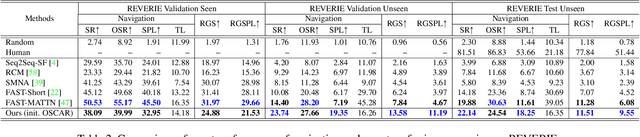
Accuracy of many visiolinguistic tasks has benefited significantly from the application of vision-and-language (V&L) BERT. However, its application for the task of vision-and-language navigation (VLN) remains limited. One reason for this is the difficulty adapting the BERT architecture to the partially observable Markov decision process present in VLN, requiring history-dependent attention and decision making. In this paper we propose a recurrent BERT model that is time-aware for use in VLN. Specifically, we equip the BERT model with a recurrent function that maintains cross-modal state information for the agent. Through extensive experiments on R2R and REVERIE we demonstrate that our model can replace more complex encoder-decoder models to achieve state-of-the-art results. Moreover, our approach can be generalised to other transformer-based architectures, supports pre-training, and is capable of multi-task learning suggesting the potential to merge a wide range of BERT-like models for other vision and language tasks.
ACP: Automatic Channel Pruning via Clustering and Swarm Intelligence Optimization for CNN
Jan 16, 2021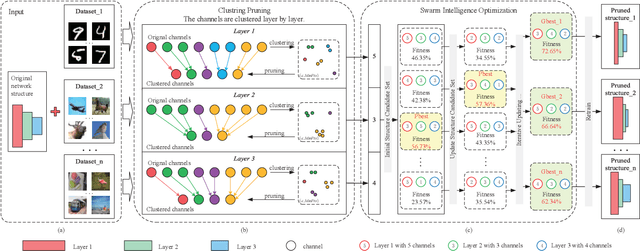
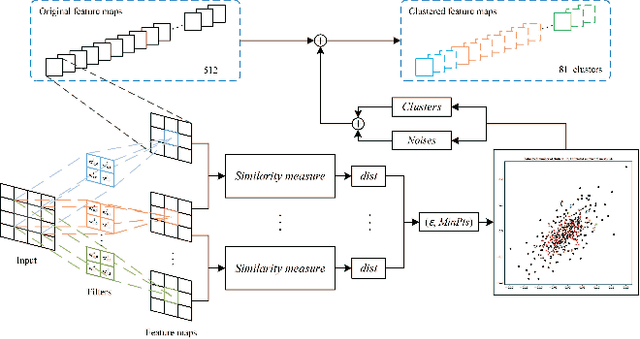
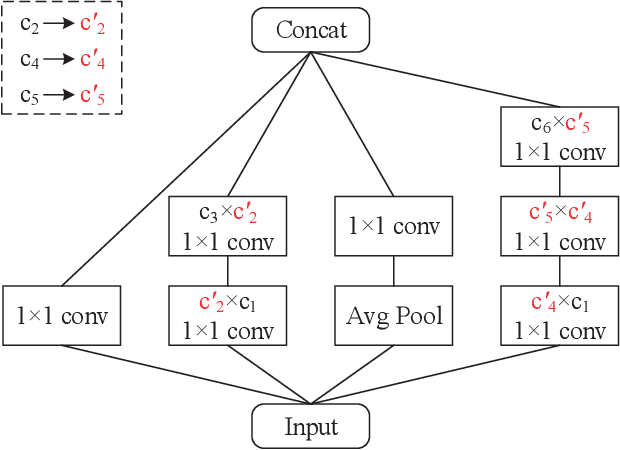
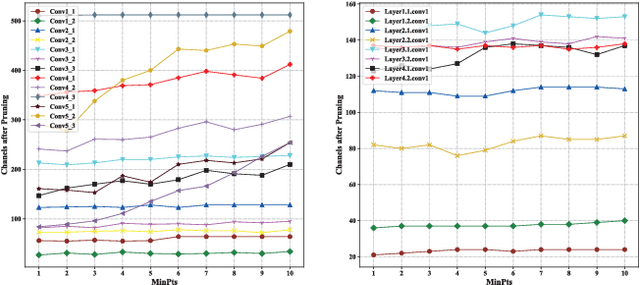
As the convolutional neural network (CNN) gets deeper and wider in recent years, the requirements for the amount of data and hardware resources have gradually increased. Meanwhile, CNN also reveals salient redundancy in several tasks. The existing magnitude-based pruning methods are efficient, but the performance of the compressed network is unpredictable. While the accuracy loss after pruning based on the structure sensitivity is relatively slight, the process is time-consuming and the algorithm complexity is notable. In this article, we propose a novel automatic channel pruning method (ACP). Specifically, we firstly perform layer-wise channel clustering via the similarity of the feature maps to perform preliminary pruning on the network. Then a population initialization method is introduced to transform the pruned structure into a candidate population. Finally, we conduct searching and optimizing iteratively based on the particle swarm optimization (PSO) to find the optimal compressed structure. The compact network is then retrained to mitigate the accuracy loss from pruning. Our method is evaluated against several state-of-the-art CNNs on three different classification datasets CIFAR-10/100 and ILSVRC-2012. On the ILSVRC-2012, when removing 64.36% parameters and 63.34% floating-point operations (FLOPs) of ResNet-50, the Top-1 and Top-5 accuracy drop are less than 0.9%. Moreover, we demonstrate that without harming overall performance it is possible to compress SSD by more than 50% on the target detection dataset PASCAL VOC. It further verifies that the proposed method can also be applied to other CNNs and application scenarios.
DeepAtrophy: Teaching a Neural Network to Differentiate Progressive Changes from Noise on Longitudinal MRI in Alzheimer's Disease
Oct 24, 2020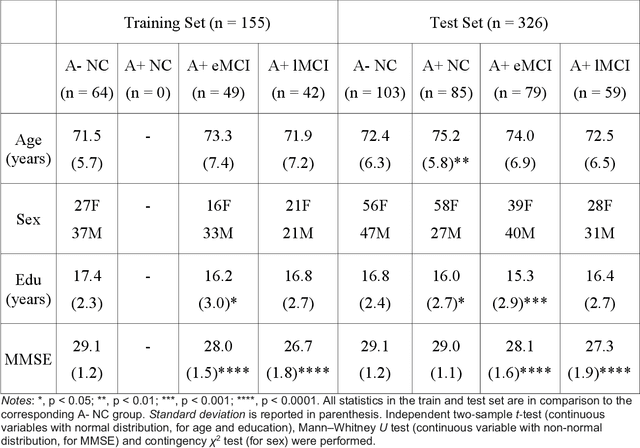


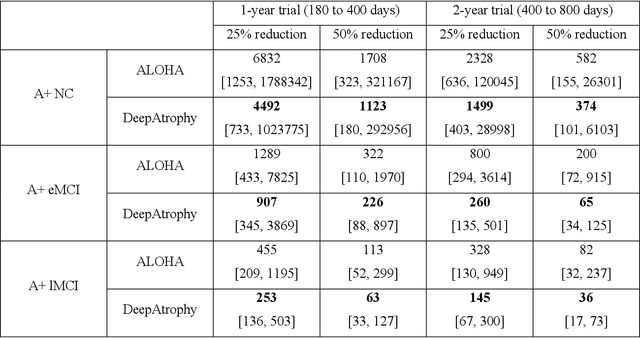
Volume change measures derived from longitudinal MRI (e.g. hippocampal atrophy) are a well-studied biomarker of disease progression in Alzheimer's Disease (AD) and are used in clinical trials to track the therapeutic efficacy of disease-modifying treatments. However, longitudinal MRI change measures can be confounded by non-biological factors, such as different degrees of head motion and susceptibility artifact between pairs of MRI scans. We hypothesize that deep learning methods applied directly to pairs of longitudinal MRI scans can be trained to differentiate between biological changes and non-biological factors better than conventional approaches based on deformable image registration. To achieve this, we make a simplifying assumption that biological factors are associated with time (i.e. the hippocampus shrinks overtime in the aging population) whereas non-biological factors are independent of time. We then formulate deep learning networks to infer the temporal order of same-subject MRI scans input to the network in arbitrary order; as well as to infer ratios between interscan intervals for two pairs of same-subject MRI scans. In the test dataset, these networks perform better in tasks of temporal ordering (89.3%) and interscan interval inference (86.1%) than a state-of-the-art deformation-based morphometry method ALOHA (76.6% and 76.1% respectively) (Das et al., 2012). Furthermore, we derive a disease progression score from the network that is able to detect a group difference between 58 preclinical AD and 75 beta-amyloid-negative cognitively normal individuals within one year, compared to two years for ALOHA. This suggests that deep learning can be trained to differentiate MRI changes due to biological factors (tissue loss) from changes due to non-biological factors, leading to novel biomarkers that are more sensitive to longitudinal changes at the earliest stages of AD.
Leave Zero Out: Towards a No-Cross-Validation Approach for Model Selection
Dec 24, 2020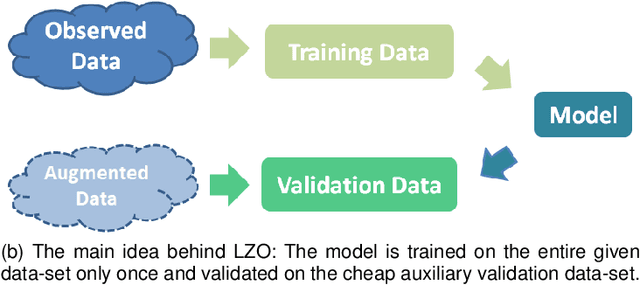
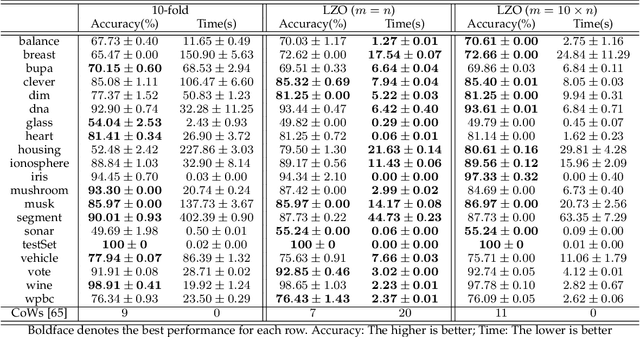
As the main workhorse for model selection, Cross Validation (CV) has achieved an empirical success due to its simplicity and intuitiveness. However, despite its ubiquitous role, CV often falls into the following notorious dilemmas. On the one hand, for small data cases, CV suffers a conservatively biased estimation, since some part of the limited data has to hold out for validation. On the other hand, for large data cases, CV tends to be extremely cumbersome, e.g., intolerant time-consuming, due to the repeated training procedures. Naturally, a straightforward ambition for CV is to validate the models with far less computational cost, while making full use of the entire given data-set for training. Thus, instead of holding out the given data, a cheap and theoretically guaranteed auxiliary/augmented validation is derived strategically in this paper. Such an embarrassingly simple strategy only needs to train models on the entire given data-set once, making the model-selection considerably efficient. In addition, the proposed validation approach is suitable for a wide range of learning settings due to the independence of both augmentation and out-of-sample estimation on learning process. In the end, we demonstrate the accuracy and computational benefits of our proposed method by extensive evaluation on multiple data-sets, models and tasks.
When Deep Reinforcement Learning Meets Federated Learning: Intelligent Multi-Timescale Resource Management for Multi-access Edge Computing in 5G Ultra Dense Network
Sep 22, 2020

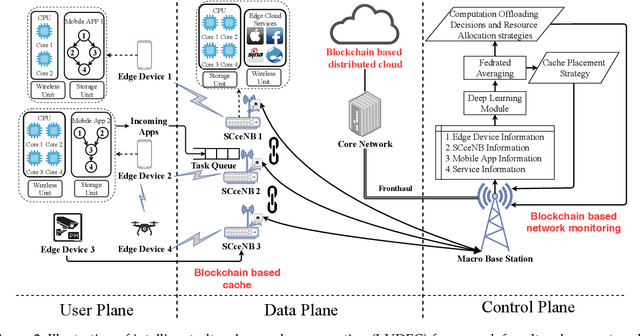
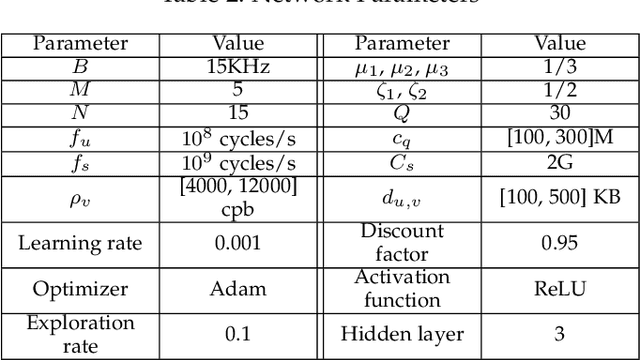
Ultra-dense edge computing (UDEC) has great potential, especially in the 5G era, but it still faces challenges in its current solutions, such as the lack of: i) efficient utilization of multiple 5G resources (e.g., computation, communication, storage and service resources); ii) low overhead offloading decision making and resource allocation strategies; and iii) privacy and security protection schemes. Thus, we first propose an intelligent ultra-dense edge computing (I-UDEC) framework, which integrates blockchain and Artificial Intelligence (AI) into 5G ultra-dense edge computing networks. First, we show the architecture of the framework. Then, in order to achieve real-time and low overhead computation offloading decisions and resource allocation strategies, we design a novel two-timescale deep reinforcement learning (\textit{2Ts-DRL}) approach, consisting of a fast-timescale and a slow-timescale learning process, respectively. The primary objective is to minimize the total offloading delay and network resource usage by jointly optimizing computation offloading, resource allocation and service caching placement. We also leverage federated learning (FL) to train the \textit{2Ts-DRL} model in a distributed manner, aiming to protect the edge devices' data privacy. Simulation results corroborate the effectiveness of both the \textit{2Ts-DRL} and FL in the I-UDEC framework and prove that our proposed algorithm can reduce task execution time up to 31.87%.
Learning from History: Modeling Temporal Knowledge Graphs with Sequential Copy-Generation Networks
Dec 15, 2020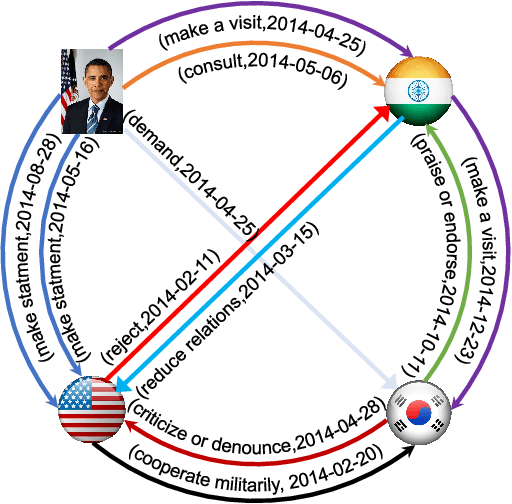
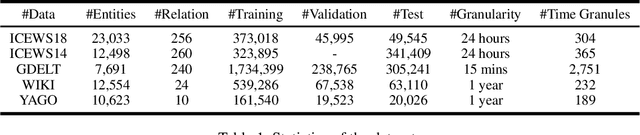
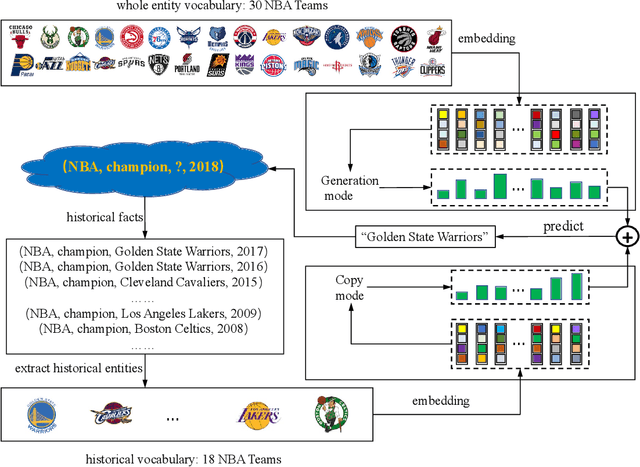
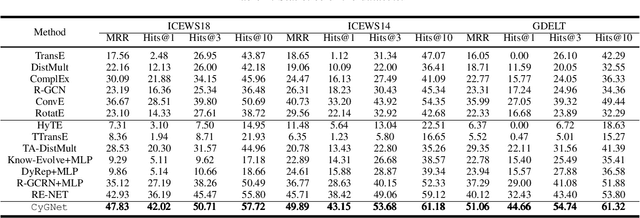
Large knowledge graphs often grow to store temporal facts that model the dynamic relations or interactions of entities along the timeline. Since such temporal knowledge graphs often suffer from incompleteness, it is important to develop time-aware representation learning models that help to infer the missing temporal facts. While the temporal facts are typically evolving, it is observed that many facts often show a repeated pattern along the timeline, such as economic crises and diplomatic activities. This observation indicates that a model could potentially learn much from the known facts appeared in history. To this end, we propose a new representation learning model for temporal knowledge graphs, namely CyGNet, based on a novel timeaware copy-generation mechanism. CyGNet is not only able to predict future facts from the whole entity vocabulary, but also capable of identifying facts with repetition and accordingly predicting such future facts with reference to the known facts in the past. We evaluate the proposed method on the knowledge graph completion task using five benchmark datasets. Extensive experiments demonstrate the effectiveness of CyGNet for predicting future facts with repetition as well as de novo fact prediction.
Practical Auto-Calibration for Spatial Scene-Understanding from Crowdsourced Dashcamera Videos
Dec 15, 2020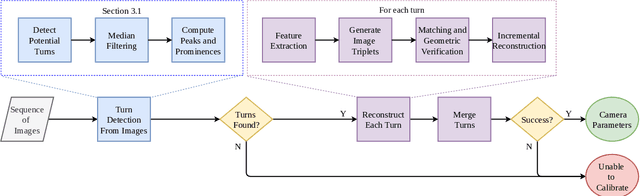
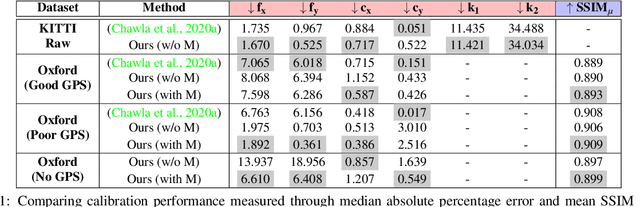


Spatial scene-understanding, including dense depth and ego-motion estimation, is an important problem in computer vision for autonomous vehicles and advanced driver assistance systems. Thus, it is beneficial to design perception modules that can utilize crowdsourced videos collected from arbitrary vehicular onboard or dashboard cameras. However, the intrinsic parameters corresponding to such cameras are often unknown or change over time. Typical manual calibration approaches require objects such as a chessboard or additional scene-specific information. On the other hand, automatic camera calibration does not have such requirements. Yet, the automatic calibration of dashboard cameras is challenging as forward and planar navigation results in critical motion sequences with reconstruction ambiguities. Structure reconstruction of complete visual-sequences that may contain tens of thousands of images is also computationally untenable. Here, we propose a system for practical monocular onboard camera auto-calibration from crowdsourced videos. We show the effectiveness of our proposed system on the KITTI raw, Oxford RobotCar, and the crowdsourced D$^2$-City datasets in varying conditions. Finally, we demonstrate its application for accurate monocular dense depth and ego-motion estimation on uncalibrated videos.
Frame-wise Cross-modal Match for Video Moment Retrieval
Sep 22, 2020
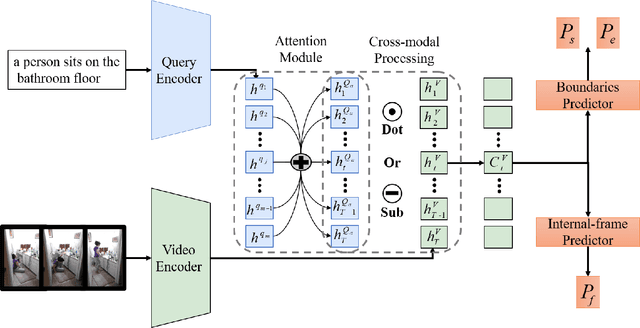
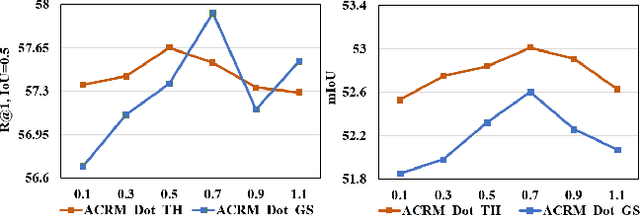

Video moment retrieval targets at retrieving a golden moment in a video for a given natural language query. The main challenges of this task include 1) the requirement of accurately localizing (i.e., the start time and the end time of) the relevant moment in an untrimmed video stream, and 2) bridging the semantic gap between textual query and video contents. To tackle those problems, One mainstream approach is to generate a multimodal feature vector for the target query and video frames (e.g., concatenation) and then use a regression approach upon the multimodal feature vector for boundary detection. Although some progress has been achieved by this approach, we argue that those methods have not well captured the cross-modal interactions between the query and video frames. In this paper, we propose an Attentive Cross-modal Relevance Matching (ACRM) model which predicts the temporal bounders based on an interaction modeling between two modalities. In addition, an attention module is introduced to automatically assign higher weights to query words with richer semantic cues, which are considered to be more important for finding relevant video contents. Another contribution is that we propose an additional predictor to utilize the internal frames in the model training to improve the localization accuracy. Extensive experiments on two public datasetsdemonstrate the superiority of our method over several state-of-the-art methods.