 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A PDE Approach to the Prediction of a Binary Sequence with Advice from Two History-Dependent Experts
Jul 24, 2020
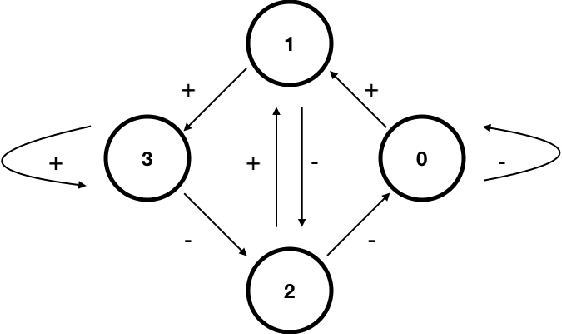

The prediction of a binary sequence is a classic example of online machine learning. We like to call it the 'stock prediction problem,' viewing the sequence as the price history of a stock that goes up or down one unit at each time step. In this problem, an investor has access to the predictions of two or more 'experts,' and strives to minimize her final-time regret with respect to the best-performing expert. Probability plays no role; rather, the market is assumed to be adversarial. We consider the case when there are two history-dependent experts, whose predictions are determined by the d most recent stock moves. Focusing on an appropriate continuum limit and using methods from optimal control, graph theory, and partial differential equations, we discuss strategies for the investor and the adversarial market, and we determine associated upper and lower bounds for the investor's final-time regret. When d is less than 4 our upper and lower bounds coalesce, so the proposed strategies are asymptotically optimal. Compared to other recent applications of partial differential equations to prediction, ours has a new element: there are two timescales, since the recent history changes at every step whereas regret accumulates more slowly.
ESMFL: Efficient and Secure Models for Federated Learning
Sep 03, 2020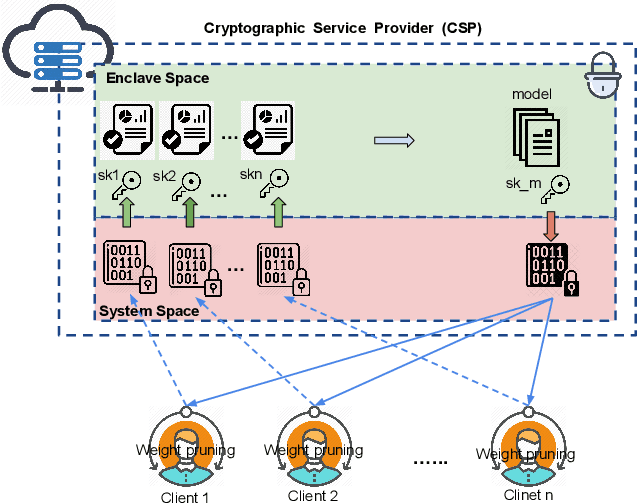
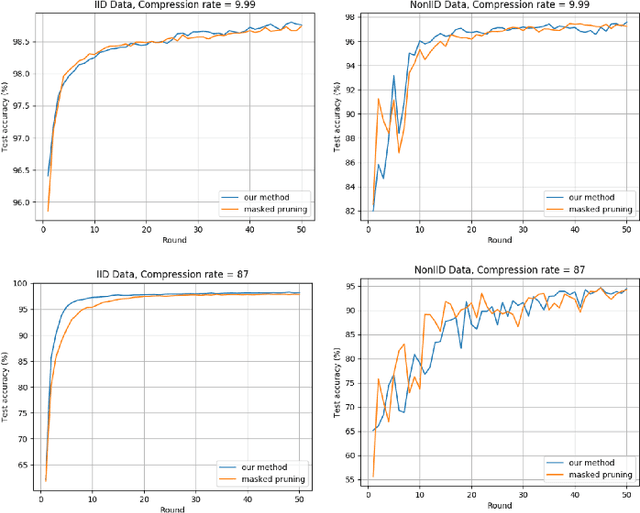
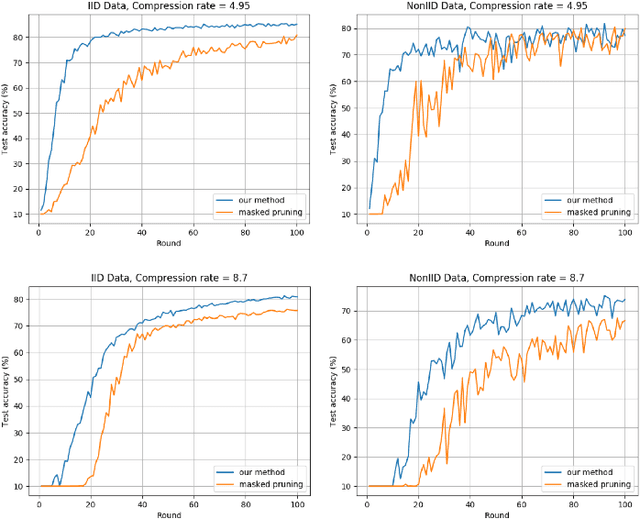

Deep Neural Networks are widely applied to various domains. The successful deployment of these applications is everywhere and it depends on the availability of big data. However, massive data collection required for deep neural network reveals the potential privacy issues and also consumes large mounts of communication bandwidth. To address this problem, we propose a privacy-preserving method for the federated learning distributed system, operated on Intel Software Guard Extensions, a set of instructions that increases the security of application code and data. Meanwhile, the encrypted models make the transmission overhead larger. Hence, we reduce the commutation cost by sparsification and achieve reasonable accuracy with different model architectures. Experimental results under our privacy-preserving framework show that, for LeNet-5, we obtain 98.78% accuracy on IID data and 97.60% accuracy on Non-IID data with 34.85% communication saving, and 1.8X total elapsed time acceleration. For MobileNetV2, we obtain 85.40% accuracy on IID data and 81.66% accuracy on Non-IID data with 15.85% communication saving, and 1.2X total elapsed time acceleration.
Effective and Scalable Clustering on Massive Attributed Graphs
Feb 07, 2021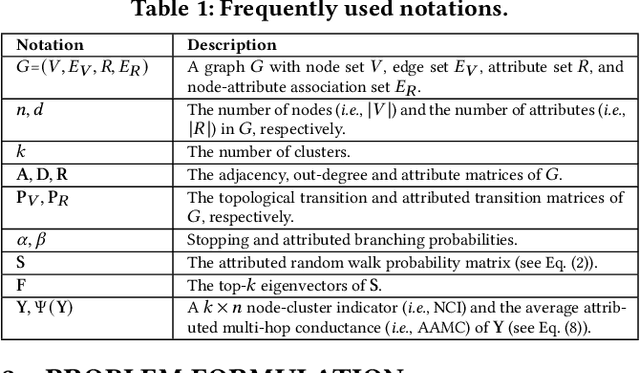
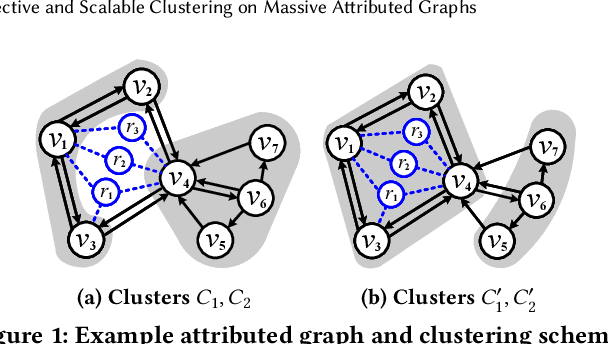
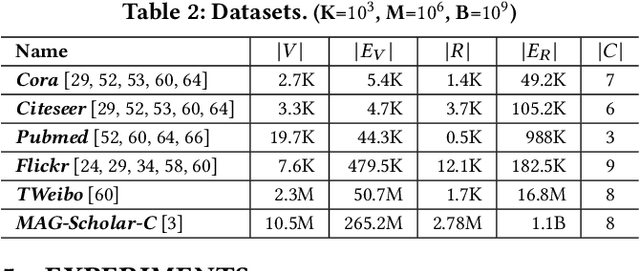
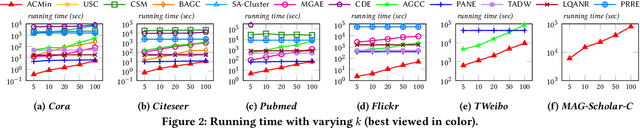
Given a graph G where each node is associated with a set of attributes, and a parameter k specifying the number of output clusters, k-attributed graph clustering (k-AGC) groups nodes in G into k disjoint clusters, such that nodes within the same cluster share similar topological and attribute characteristics, while those in different clusters are dissimilar. This problem is challenging on massive graphs, e.g., with millions of nodes and billions of edges. For such graphs, existing solutions either incur prohibitively high costs, or produce clustering results with compromised quality. In this paper, we propose ACMin, an effective approach to k-AGC that yields high-quality clusters with cost linear to the size of the input graph G. The main contributions of ACMin are twofold: (i) a novel formulation of the k-AGC problem based on an attributed multi-hop conductance quality measure custom-made for this problem setting, which effectively captures cluster coherence in terms of both topological proximities and attribute similarities, and (ii) a linear-time optimization solver that obtains high-quality clusters iteratively, based on efficient matrix operations such as orthogonal iterations, an alternative optimization approach, as well as an initialization technique that significantly speeds up the convergence of ACMin in practice. Extensive experiments, comparing 11 competitors on 6 real datasets, demonstrate that ACMin consistently outperforms all competitors in terms of result quality measured against ground-truth labels, while being up to orders of magnitude faster. In particular, on the Microsoft Academic Knowledge Graph dataset with 265.2 million edges and 1.1 billion attribute values, ACMin outputs high-quality results for 5-AGC within 1.68 hours using a single CPU core, while none of the 11 competitors finish within 3 days.
The Impact of Text Presentation on Translator Performance
Nov 11, 2020
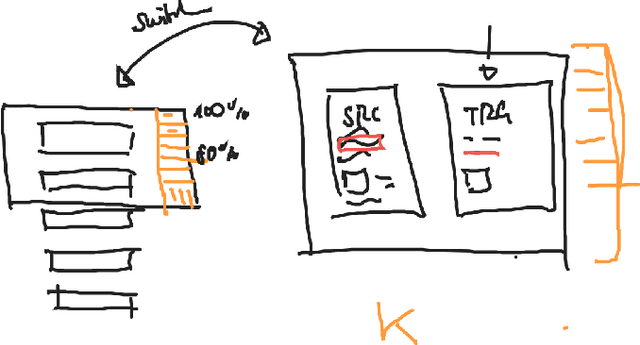

Widely used computer-aided translation (CAT) tools divide documents into segments such as sentences and arrange them in a side-by-side, spreadsheet-like view. We present the first controlled evaluation of these design choices on translator performance, measuring speed and accuracy in three experimental text processing tasks. We find significant evidence that sentence-by-sentence presentation enables faster text reproduction and within-sentence error identification compared to unsegmented text, and that a top-and-bottom arrangement of source and target sentences enables faster text reproduction compared to a side-by-side arrangement. For revision, on the other hand, our results suggest that presenting unsegmented text results in the highest accuracy and time efficiency. Our findings have direct implications for best practices in designing CAT tools.
Efficient power allocation using graph neural networks and deep algorithm unfolding
Nov 18, 2020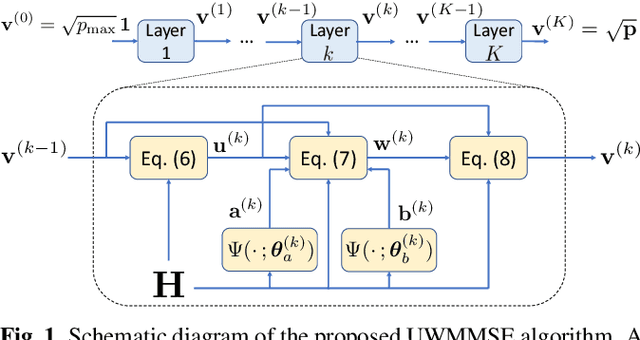
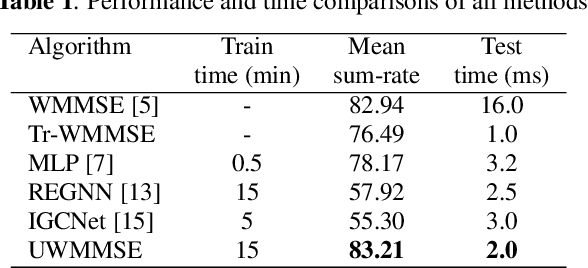
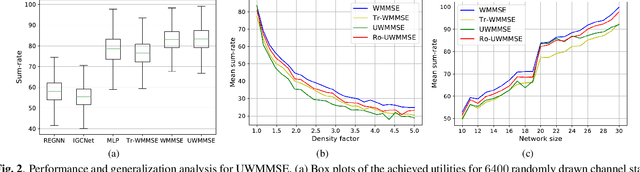
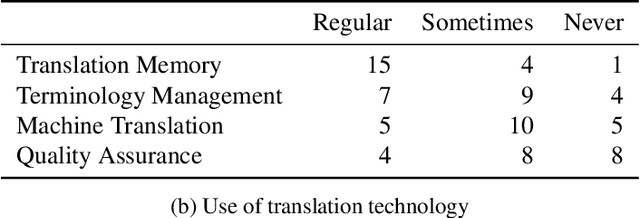
We study the problem of optimal power allocation in a single-hop ad hoc wireless network. In solving this problem, we propose a hybrid neural architecture inspired by the algorithmic unfolding of the iterative weighted minimum mean squared error (WMMSE) method, that we denote as unfolded WMMSE (UWMMSE). The learnable weights within UWMMSE are parameterized using graph neural networks (GNNs), where the time-varying underlying graphs are given by the fading interference coefficients in the wireless network. These GNNs are trained through a gradient descent approach based on multiple instances of the power allocation problem. Once trained, UWMMSE achieves performance comparable to that of WMMSE while significantly reducing the computational complexity. This phenomenon is illustrated through numerical experiments along with the robustness and generalization to wireless networks of different densities and sizes.
Funnel Libraries for Real-Time Robust Feedback Motion Planning
Apr 29, 2017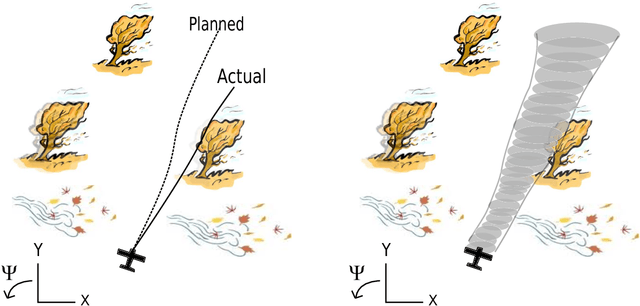
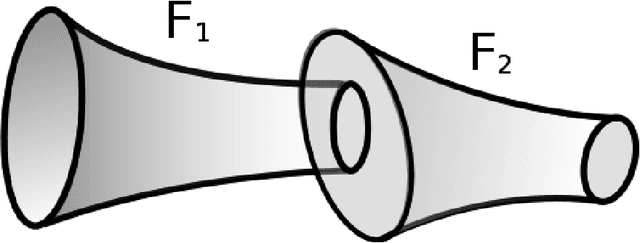
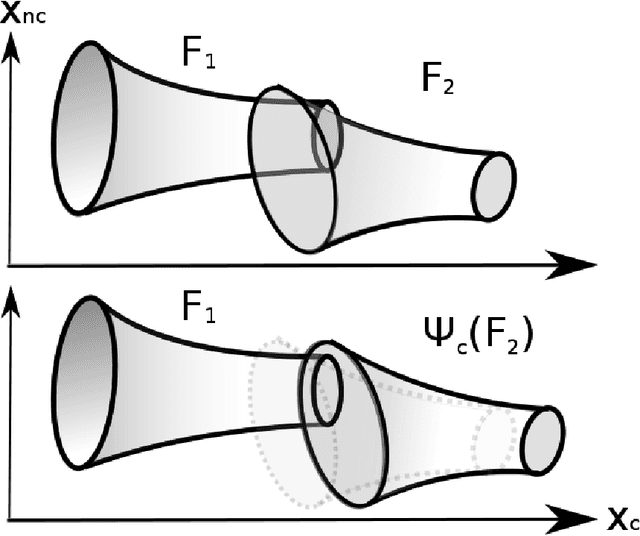
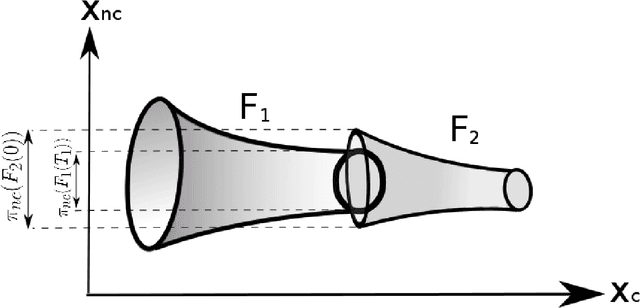
We consider the problem of generating motion plans for a robot that are guaranteed to succeed despite uncertainty in the environment, parametric model uncertainty, and disturbances. Furthermore, we consider scenarios where these plans must be generated in real-time, because constraints such as obstacles in the environment may not be known until they are perceived (with a noisy sensor) at runtime. Our approach is to pre-compute a library of "funnels" along different maneuvers of the system that the state is guaranteed to remain within (despite bounded disturbances) when the feedback controller corresponding to the maneuver is executed. We leverage powerful computational machinery from convex optimization (sums-of-squares programming in particular) to compute these funnels. The resulting funnel library is then used to sequentially compose motion plans at runtime while ensuring the safety of the robot. A major advantage of the work presented here is that by explicitly taking into account the effect of uncertainty, the robot can evaluate motion plans based on how vulnerable they are to disturbances. We demonstrate and validate our method using extensive hardware experiments on a small fixed-wing airplane avoiding obstacles at high speed (~12 mph), along with thorough simulation experiments of ground vehicle and quadrotor models navigating through cluttered environments. To our knowledge, these demonstrations constitute one of the first examples of provably safe and robust control for robotic systems with complex nonlinear dynamics that need to plan in real-time in environments with complex geometric constraints.
Age Gap Reducer-GAN for Recognizing Age-Separated Faces
Nov 11, 2020
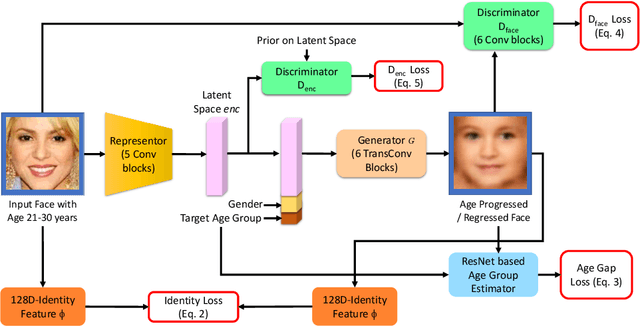

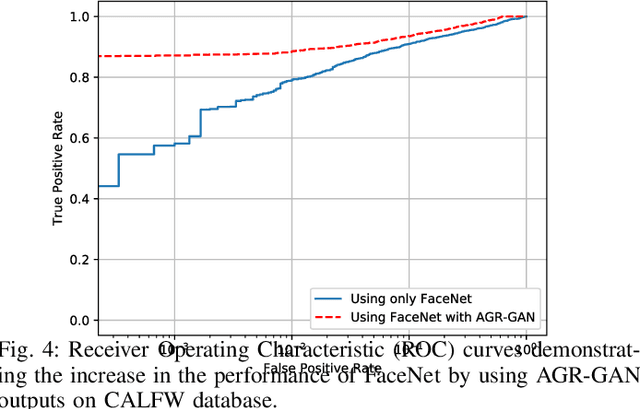
In this paper, we propose a novel algorithm for matching faces with temporal variations caused due to age progression. The proposed generative adversarial network algorithm is a unified framework that combines facial age estimation and age-separated face verification. The key idea of this approach is to learn the age variations across time by conditioning the input image on the subject's gender and the target age group to which the face needs to be progressed. The loss function accounts for reducing the age gap between the original image and generated face image as well as preserving the identity. Both visual fidelity and quantitative evaluations demonstrate the efficacy of the proposed architecture on different facial age databases for age-separated face recognition.
VinDr-CXR: An open dataset of chest X-rays with radiologist's annotations
Jan 03, 2021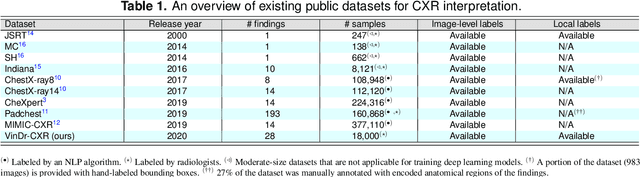
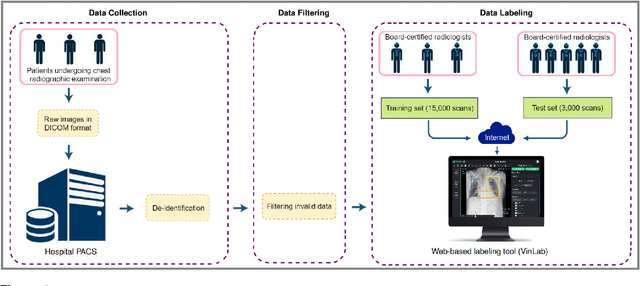
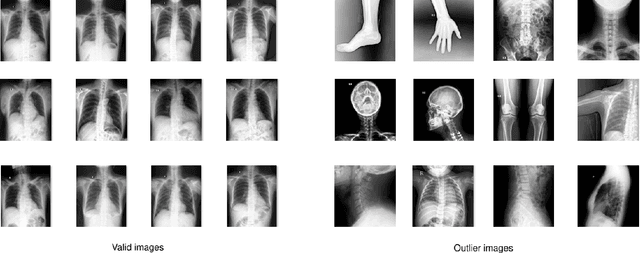
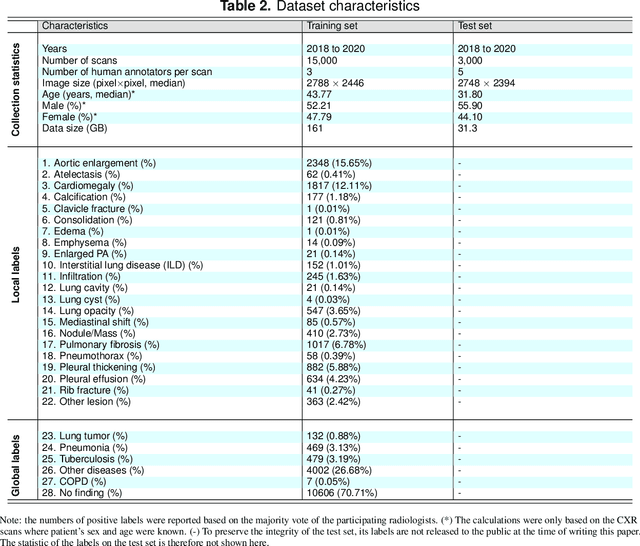
Most of the existing chest X-ray datasets include labels from a list of findings without specifying their locations on the radiographs. This limits the development of machine learning algorithms for the detection and localization of chest abnormalities. In this work, we describe a dataset of more than 100,000 chest X-ray scans that were retrospectively collected from two major hospitals in Vietnam. Out of this raw data, we release 18,000 images that were manually annotated by a total of 17 experienced radiologists with 22 local labels of rectangles surrounding abnormalities and 6 global labels of suspected diseases. The released dataset is divided into a training set of 15,000 and a test set of 3,000. Each scan in the training set was independently labeled by 3 radiologists, while each scan in the test set was labeled by the consensus of 5 radiologists. We designed and built a labeling platform for DICOM images to facilitate these annotation procedures. All images are made publicly available in DICOM format in company with the labels of the training set. The labels of the test set are hidden at the time of writing this paper as they will be used for benchmarking machine learning algorithms on an open platform.
Continuous Gesture Recognition from sEMG Sensor Data with Recurrent Neural Networks and Adversarial Domain Adaptation
Dec 16, 2020
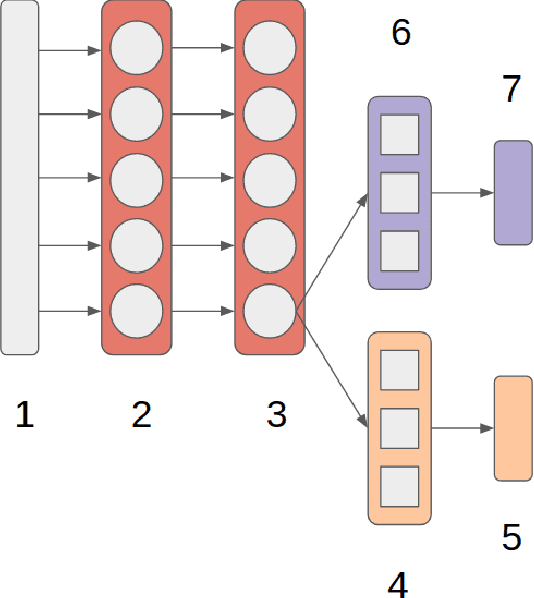
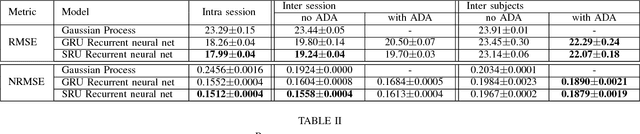
Movement control of artificial limbs has made big advances in recent years. New sensor and control technology enhanced the functionality and usefulness of artificial limbs to the point that complex movements, such as grasping, can be performed to a limited extent. To date, the most successful results were achieved by applying recurrent neural networks (RNNs). However, in the domain of artificial hands, experiments so far were limited to non-mobile wrists, which significantly reduces the functionality of such prostheses. In this paper, for the first time, we present empirical results on gesture recognition with both mobile and non-mobile wrists. Furthermore, we demonstrate that recurrent neural networks with simple recurrent units (SRU) outperform regular RNNs in both cases in terms of gesture recognition accuracy, on data acquired by an arm band sensing electromagnetic signals from arm muscles (via surface electromyography or sEMG). Finally, we show that adding domain adaptation techniques to continuous gesture recognition with RNN improves the transfer ability between subjects, where a limb controller trained on data from one person is used for another person.
A Bayesian neural network predicts the dissolution of compact planetary systems
Jan 11, 2021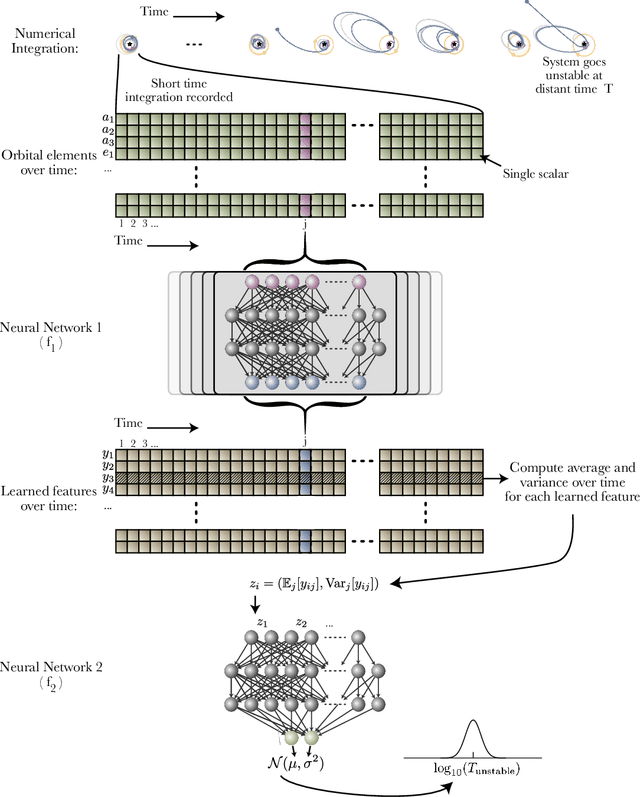
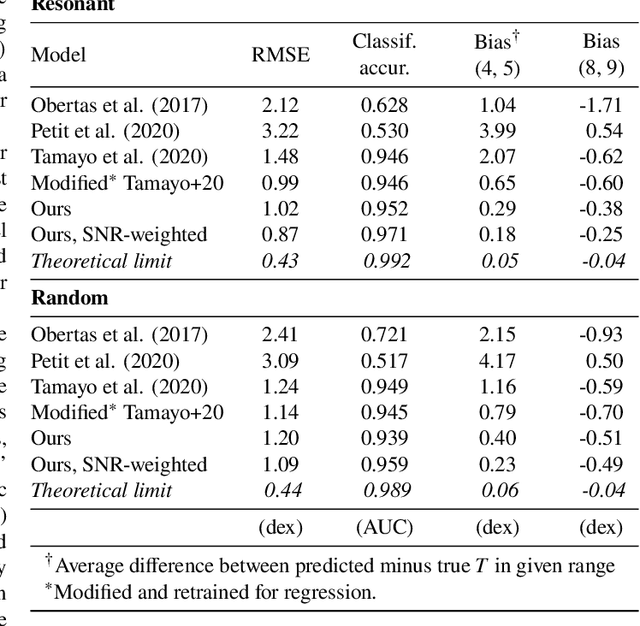
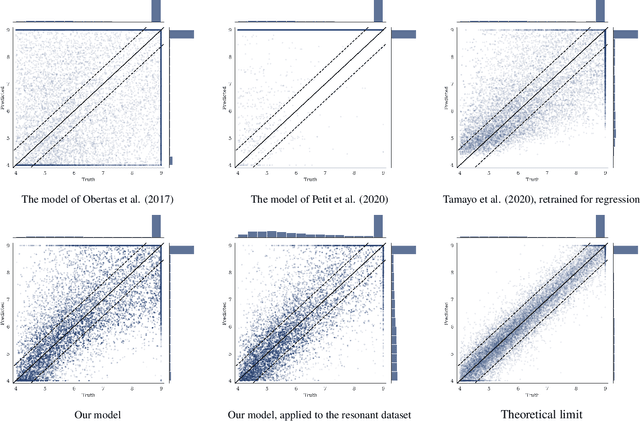
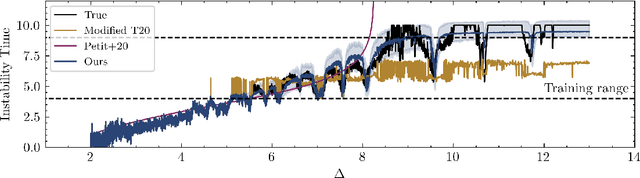
Despite over three hundred years of effort, no solutions exist for predicting when a general planetary configuration will become unstable. We introduce a deep learning architecture to push forward this problem for compact systems. While current machine learning algorithms in this area rely on scientist-derived instability metrics, our new technique learns its own metrics from scratch, enabled by a novel internal structure inspired from dynamics theory. Our Bayesian neural network model can accurately predict not only if, but also when a compact planetary system with three or more planets will go unstable. Our model, trained directly from short N-body time series of raw orbital elements, is more than two orders of magnitude more accurate at predicting instability times than analytical estimators, while also reducing the bias of existing machine learning algorithms by nearly a factor of three. Despite being trained on compact resonant and near-resonant three-planet configurations, the model demonstrates robust generalization to both non-resonant and higher multiplicity configurations, in the latter case outperforming models fit to that specific set of integrations. The model computes instability estimates up to five orders of magnitude faster than a numerical integrator, and unlike previous efforts provides confidence intervals on its predictions. Our inference model is publicly available in the SPOCK package, with training code open-sourced.