 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
xVIO: A Range-Visual-Inertial Odometry Framework
Oct 13, 2020
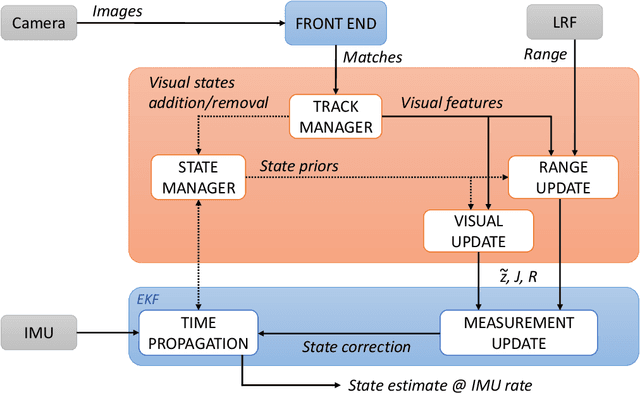
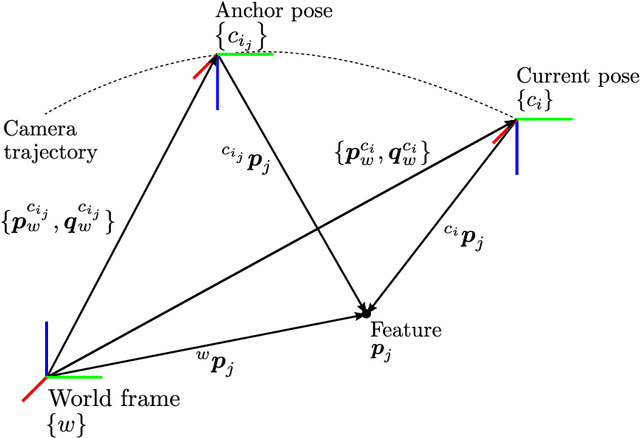
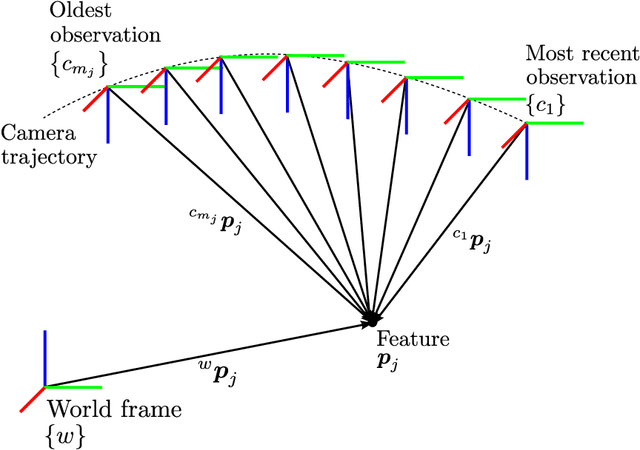
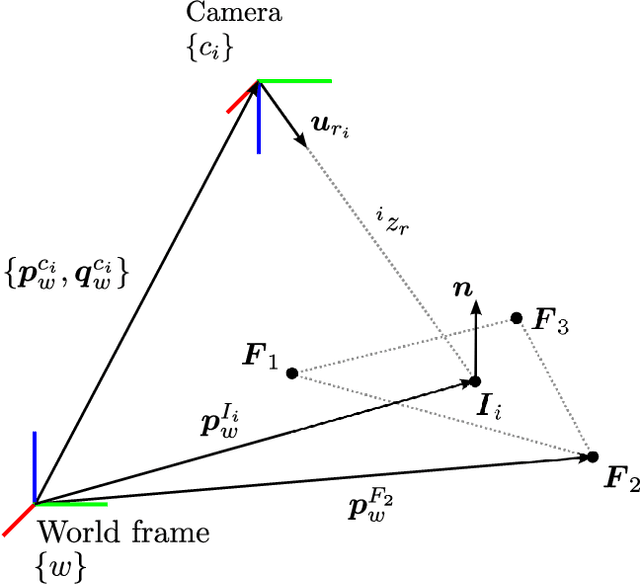
xVIO is a range-visual-inertial odometry algorithm implemented at JPL. It has been demonstrated with closed-loop controls on-board unmanned rotorcraft equipped with off-the-shelf embedded computers and sensors. It can operate at daytime with visible-spectrum cameras, or at night time using thermal infrared cameras. This report is a complete technical description of xVIO. It includes an overview of the system architecture, the implementation of the navigation filter, along with the derivations of the Jacobian matrices which are not already published in the literature.
Natural Language Processing to Detect Cognitive Concerns in Electronic Health Records Using Deep Learning
Nov 12, 2020
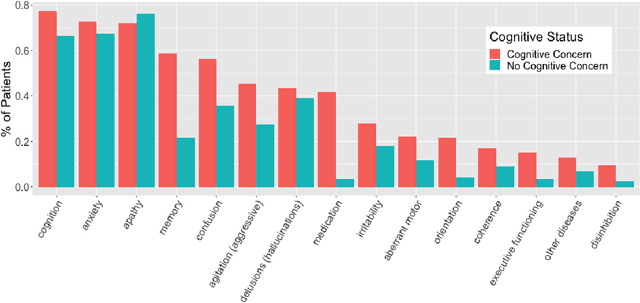

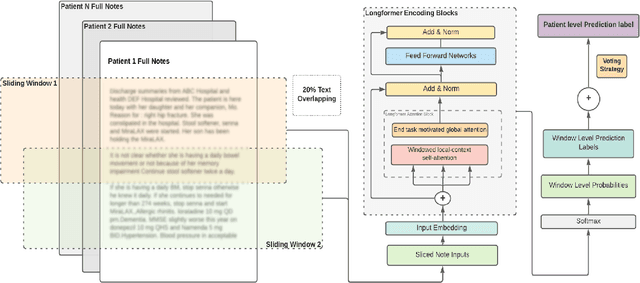
Dementia is under-recognized in the community, under-diagnosed by healthcare professionals, and under-coded in claims data. Information on cognitive dysfunction, however, is often found in unstructured clinician notes within medical records but manual review by experts is time consuming and often prone to errors. Automated mining of these notes presents a potential opportunity to label patients with cognitive concerns who could benefit from an evaluation or be referred to specialist care. In order to identify patients with cognitive concerns in electronic medical records, we applied natural language processing (NLP) algorithms and compared model performance to a baseline model that used structured diagnosis codes and medication data only. An attention-based deep learning model outperformed the baseline model and other simpler models.
Super-Human Performance in Gran Turismo Sport Using Deep Reinforcement Learning
Aug 18, 2020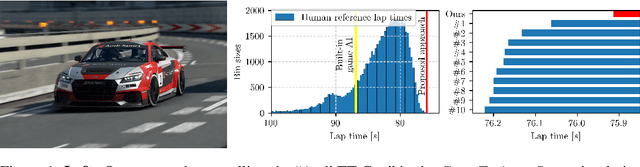

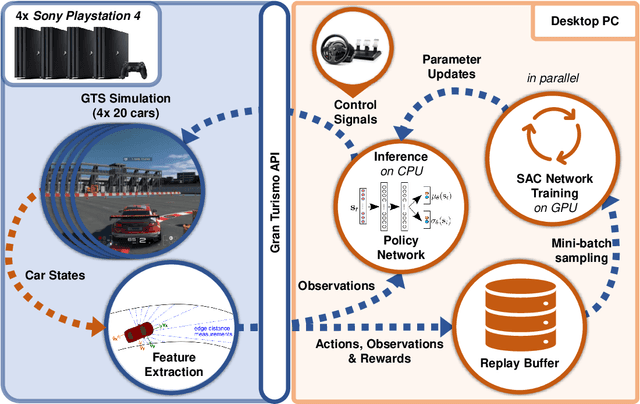

Autonomous car racing raises fundamental robotics challenges such as planning minimum-time trajectories under uncertain dynamics and controlling the car at its friction limits. In this project, we consider the task of autonomous car racing in the top-selling car racing game Gran Turismo Sport. Gran Turismo Sport is known for its detailed physics simulation of various cars and tracks. Our approach makes use of maximum-entropy deep reinforcement learning and a new reward design to train a sensorimotor policy to complete a given race track as fast as possible. We evaluate our approach in three different time trial settings with different cars and tracks. Our results show that the obtained controllers not only beat the built-in non-player character of Gran Turismo Sport, but also outperform the fastest known times in a dataset of personal best lap times of over 50,000 human drivers.
Efficient Golf Ball Detection and Tracking Based on Convolutional Neural Networks and Kalman Filter
Dec 17, 2020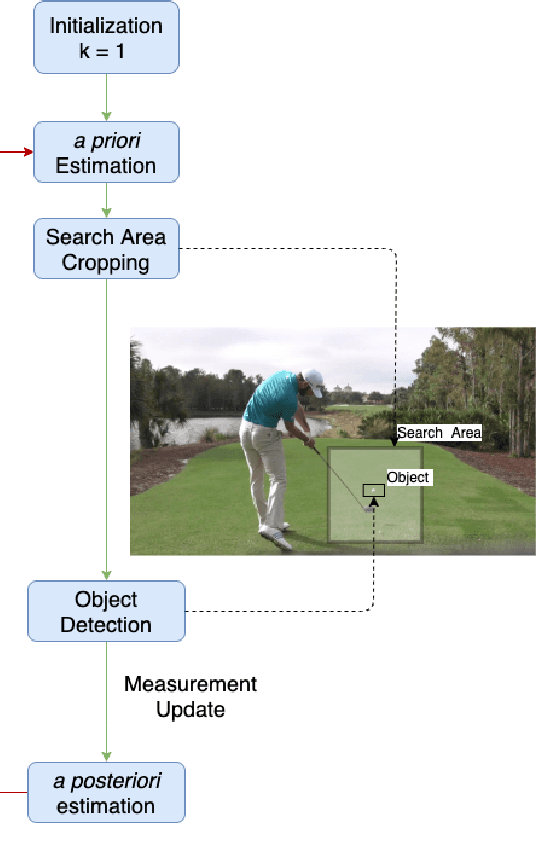

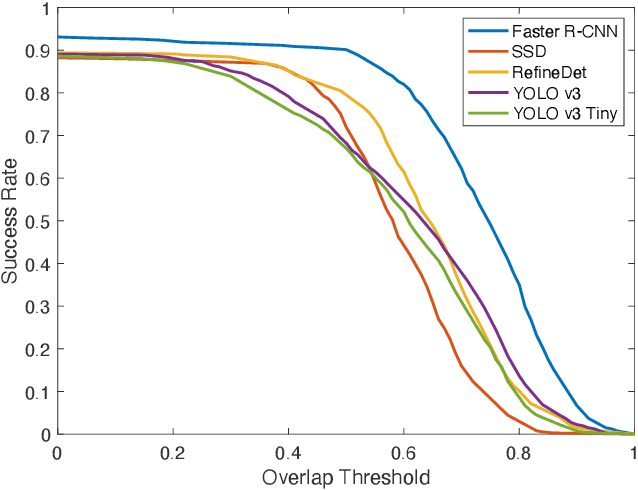
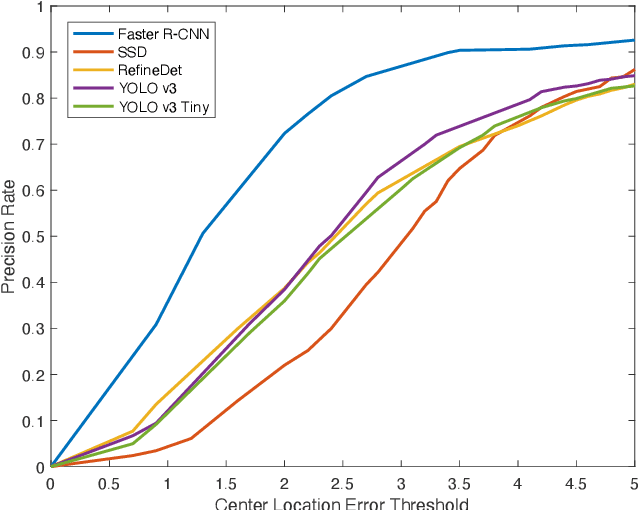
This paper focuses on the problem of online golf ball detection and tracking from image sequences. An efficient real-time approach is proposed by exploiting convolutional neural networks (CNN) based object detection and a Kalman filter based prediction. Five classical deep learning-based object detection networks are implemented and evaluated for ball detection, including YOLO v3 and its tiny version, YOLO v4, Faster R-CNN, SSD, and RefineDet. The detection is performed on small image patches instead of the entire image to increase the performance of small ball detection. At the tracking stage, a discrete Kalman filter is employed to predict the location of the ball and a small image patch is cropped based on the prediction. Then, the object detector is utilized to refine the location of the ball and update the parameters of Kalman filter. In order to train the detection models and test the tracking algorithm, a collection of golf ball dataset is created and annotated. Extensive comparative experiments are performed to demonstrate the effectiveness and superior tracking performance of the proposed scheme.
RAPTOR: Robust and Perception-aware Trajectory Replanning for Quadrotor Fast Flight
Jul 06, 2020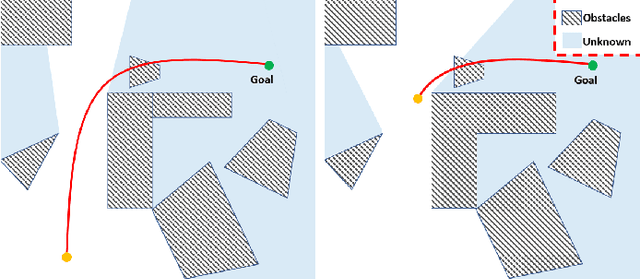
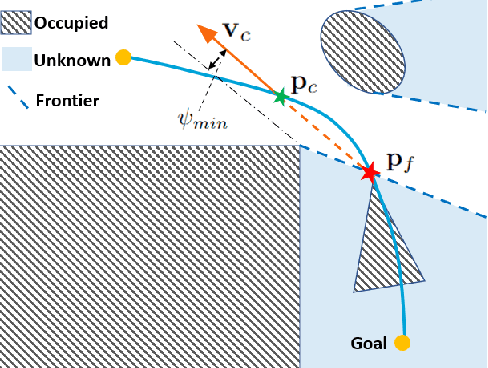
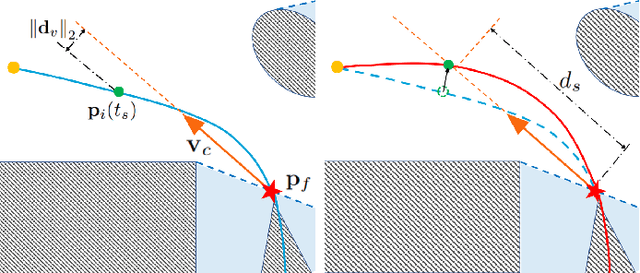
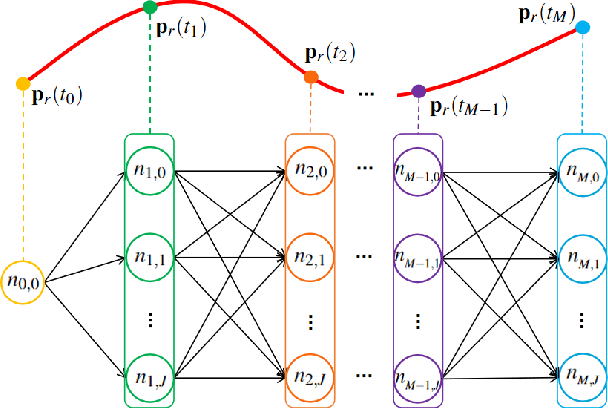
Recent advances in trajectory replanning have enabled quadrotor to navigate autonomously in unknown environments. However, high-speed navigation still remains a significant challenge. Given very limited time, existing methods have no strong guarantee on the feasibility or quality of the solutions. Moreover, most methods do not consider environment perception, which is the key bottleneck to fast flight. In this paper, we present RAPTOR, a robust and perception-aware replanning framework to support fast and safe flight. A path-guided optimization (PGO) approach that incorporates multiple topological paths is devised, to ensure finding feasible and high-quality trajectories in very limited time. We also introduce a perception-aware planning strategy to actively observe and avoid unknown obstacles. A risk-aware trajectory refinement ensures that unknown obstacles which may endanger the quadrotor can be observed earlier and avoid in time. The motion of yaw angle is planned to actively explore the surrounding space that is relevant for safe navigation. The proposed methods are tested extensively. We will release our implementation as an open-source package for the community.
Ensembles of Randomized Time Series Shapelets Provide Improved Accuracy while Reducing Computational Costs
Feb 22, 2017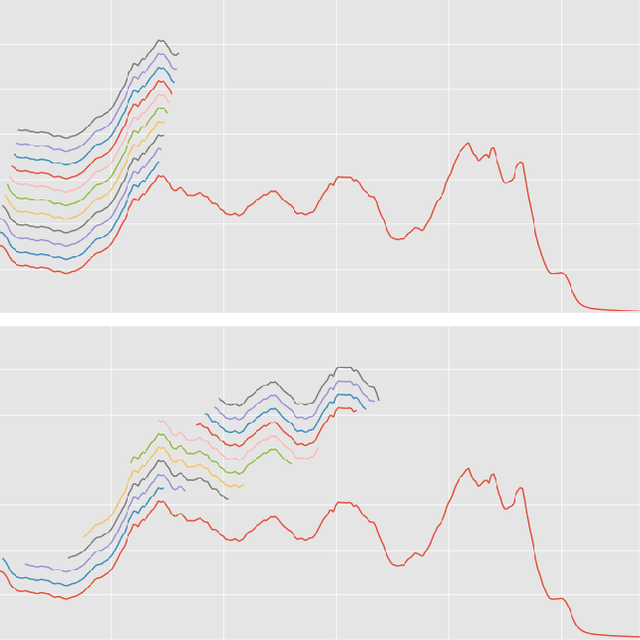
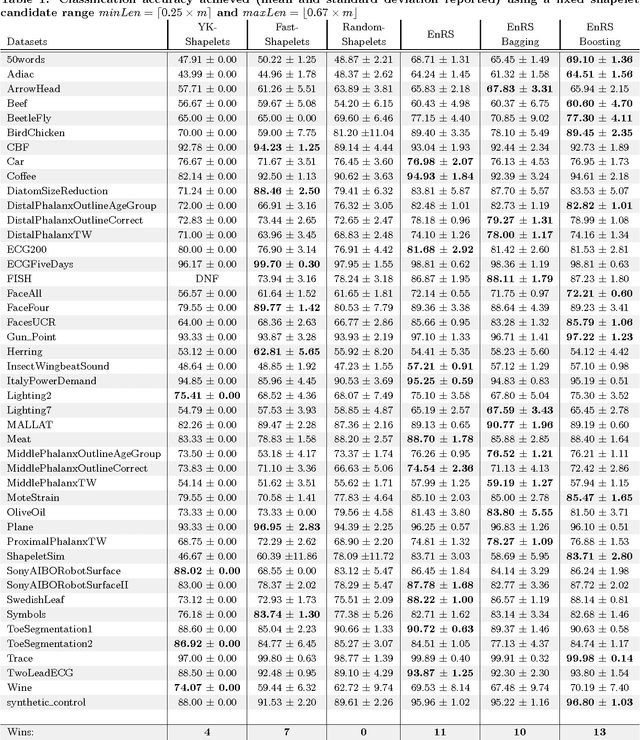
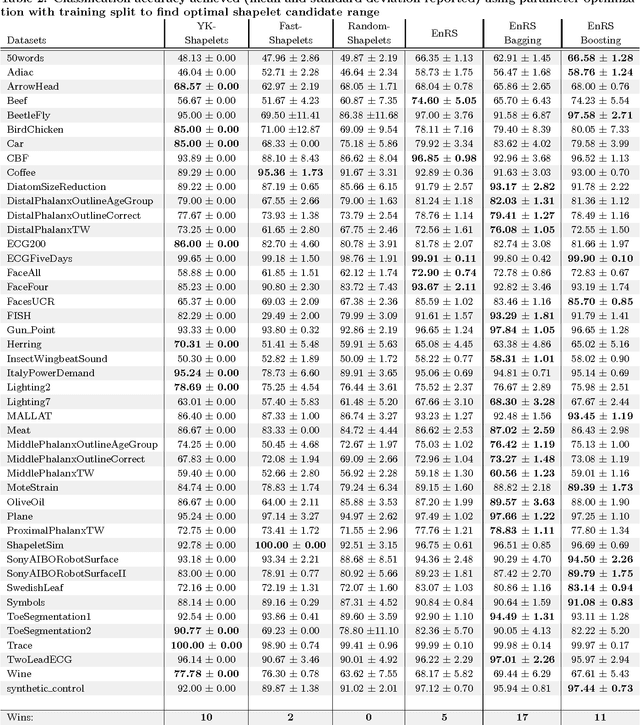
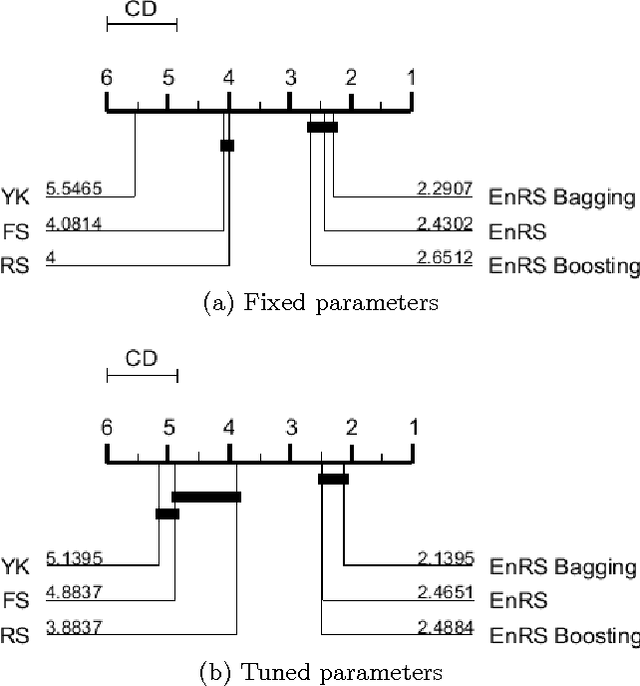
Shapelets are discriminative time series subsequences that allow generation of interpretable classification models, which provide faster and generally better classification than the nearest neighbor approach. However, the shapelet discovery process requires the evaluation of all possible subsequences of all time series in the training set, making it extremely computation intensive. Consequently, shapelet discovery for large time series datasets quickly becomes intractable. A number of improvements have been proposed to reduce the training time. These techniques use approximation or discretization and often lead to reduced classification accuracy compared to the exact method. We are proposing the use of ensembles of shapelet-based classifiers obtained using random sampling of the shapelet candidates. Using random sampling reduces the number of evaluated candidates and consequently the required computational cost, while the classification accuracy of the resulting models is also not significantly different than that of the exact algorithm. The combination of randomized classifiers rectifies the inaccuracies of individual models because of the diversity of the solutions. Based on the experiments performed, it is shown that the proposed approach of using an ensemble of inexpensive classifiers provides better classification accuracy compared to the exact method at a significantly lesser computational cost.
Generating Knowledge Graphs by Employing Natural Language Processing and Machine Learning Techniques within the Scholarly Domain
Oct 28, 2020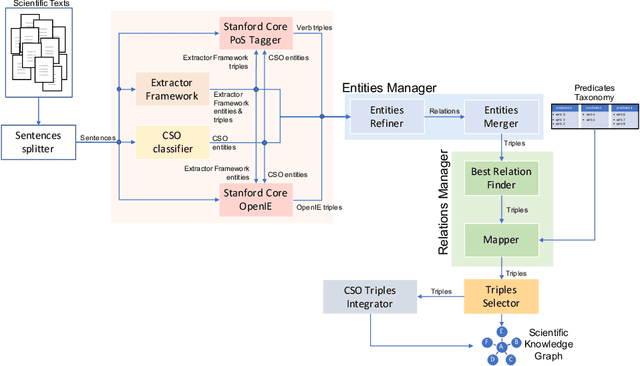
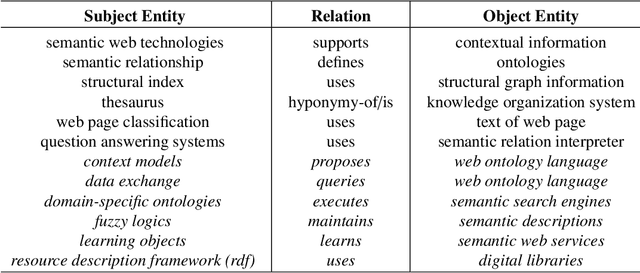
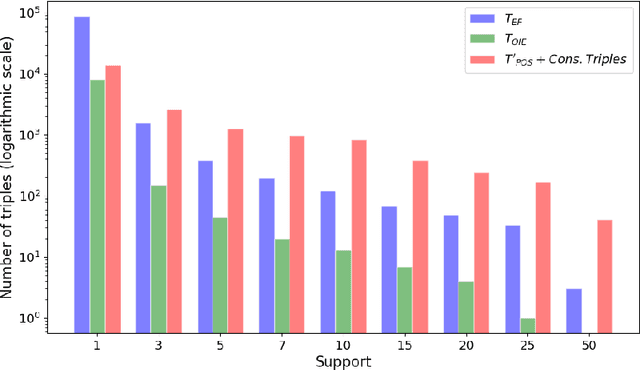
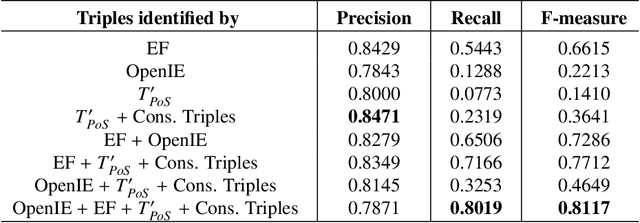
The continuous growth of scientific literature brings innovations and, at the same time, raises new challenges. One of them is related to the fact that its analysis has become difficult due to the high volume of published papers for which manual effort for annotations and management is required. Novel technological infrastructures are needed to help researchers, research policy makers, and companies to time-efficiently browse, analyse, and forecast scientific research. Knowledge graphs i.e., large networks of entities and relationships, have proved to be effective solution in this space. Scientific knowledge graphs focus on the scholarly domain and typically contain metadata describing research publications such as authors, venues, organizations, research topics, and citations. However, the current generation of knowledge graphs lacks of an explicit representation of the knowledge presented in the research papers. As such, in this paper, we present a new architecture that takes advantage of Natural Language Processing and Machine Learning methods for extracting entities and relationships from research publications and integrates them in a large-scale knowledge graph. Within this research work, we i) tackle the challenge of knowledge extraction by employing several state-of-the-art Natural Language Processing and Text Mining tools, ii) describe an approach for integrating entities and relationships generated by these tools, iii) show the advantage of such an hybrid system over alternative approaches, and vi) as a chosen use case, we generated a scientific knowledge graph including 109,105 triples, extracted from 26,827 abstracts of papers within the Semantic Web domain. As our approach is general and can be applied to any domain, we expect that it can facilitate the management, analysis, dissemination, and processing of scientific knowledge.
Dirichlet policies for reinforced factor portfolios
Nov 12, 2020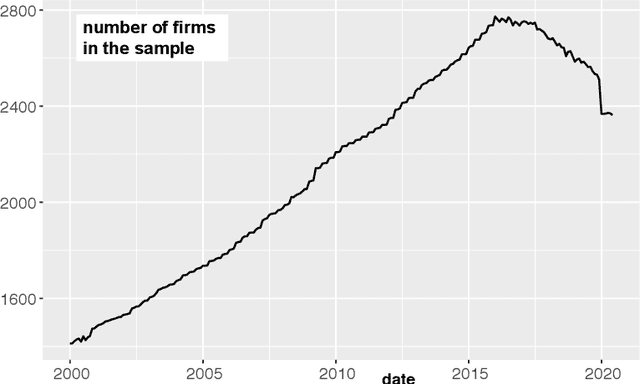

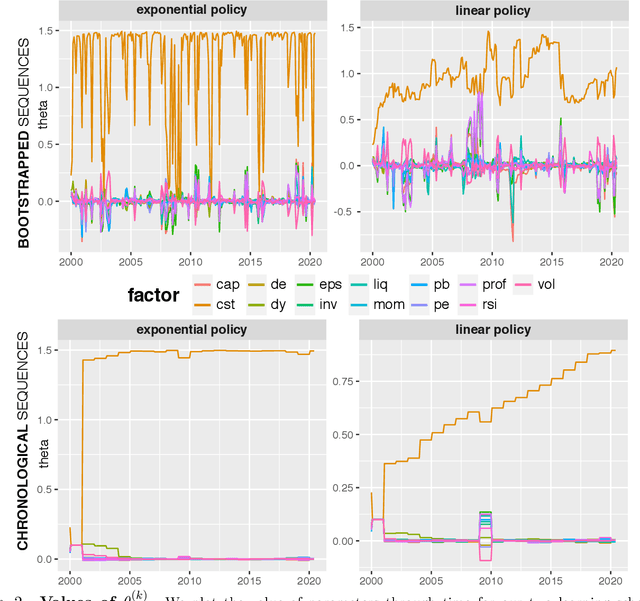
This article aims to combine factor investing and reinforcement learning (RL). The agent learns through sequential random allocations which rely on firms' characteristics. Using Dirichlet distributions as the driving policy, we derive closed forms for the policy gradients and analytical properties of the performance measure. This enables the implementation of REINFORCE methods, which we perform on a large dataset of US equities. Across a large range of implementation choices, our result indicates that RL-based portfolios are very close to the equally-weighted (1/N) allocation. This implies that the agent learns to be agnostic with regard to factors. This is partly consistent with cross-sectional regressions showing a strong time variation in the relationship between returns and firm characteristics.
Accurate and Scalable Matching of Translators to Displaced Persons for Overcoming Language Barriers
Nov 30, 2020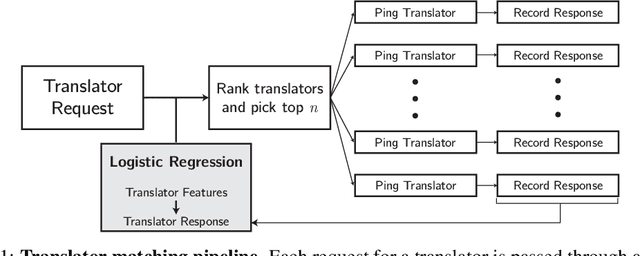
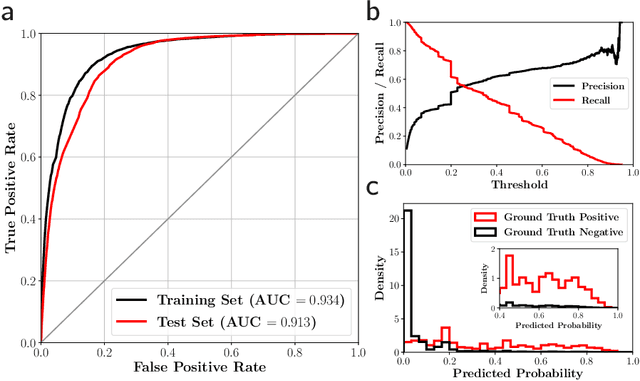
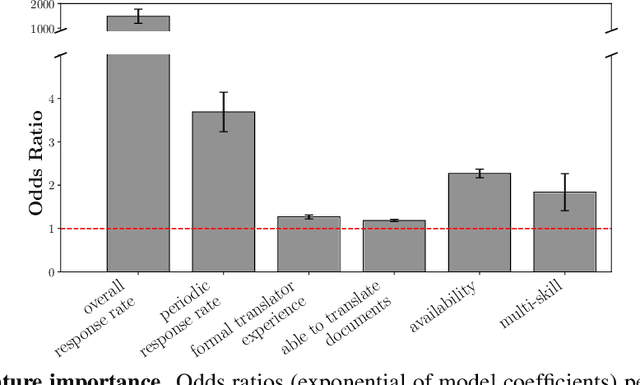
Residents of developing countries are disproportionately susceptible to displacement as a result of humanitarian crises. During such crises, language barriers impede aid workers in providing services to those displaced. To build resilience, such services must be flexible and robust to a host of possible languages. \textit{Tarjimly} aims to overcome the barriers by providing a platform capable of matching bilingual volunteers to displaced persons or aid workers in need of translating. However, Tarjimly's large pool of translators comes with the challenge of selecting the right translator per request. In this paper, we describe a machine learning system that matches translator requests to volunteers at scale. We demonstrate that a simple logistic regression, operating on easily computable features, can accurately predict and rank translator response. In deployment, this lightweight system matches 82\% of requests with a median response time of 59 seconds, allowing aid workers to accelerate their services supporting displaced persons.
Polyblur: Removing mild blur by polynomial reblurring
Dec 16, 2020

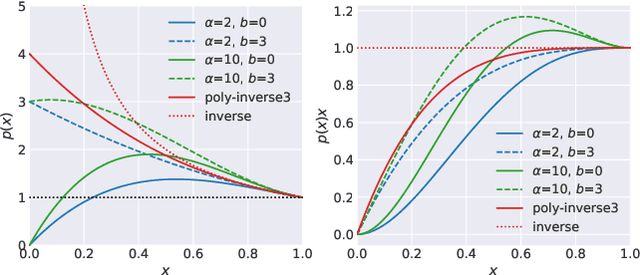
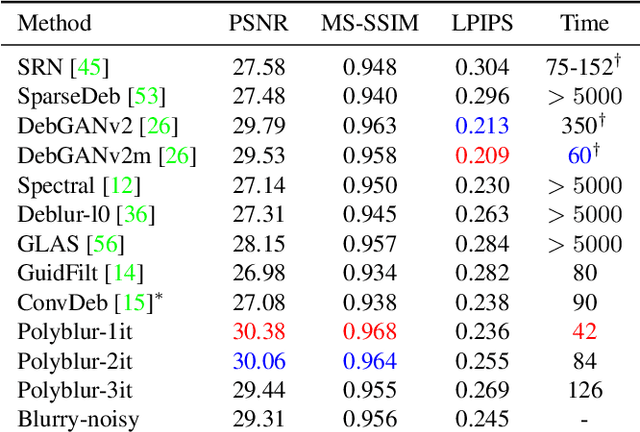
We present a highly efficient blind restoration method to remove mild blur in natural images. Contrary to the mainstream, we focus on removing slight blur that is often present, damaging image quality and commonly generated by small out-of-focus, lens blur, or slight camera motion. The proposed algorithm first estimates image blur and then compensates for it by combining multiple applications of the estimated blur in a principled way. To estimate blur we introduce a simple yet robust algorithm based on empirical observations about the distribution of the gradient in sharp natural images. Our experiments show that, in the context of mild blur, the proposed method outperforms traditional and modern blind deblurring methods and runs in a fraction of the time. Our method can be used to blindly correct blur before applying off-the-shelf deep super-resolution methods leading to superior results than other highly complex and computationally demanding techniques. The proposed method estimates and removes mild blur from a 12MP image on a modern mobile phone in a fraction of a second.