 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SMART: Simultaneous Multi-Agent Recurrent Trajectory Prediction
Jul 26, 2020
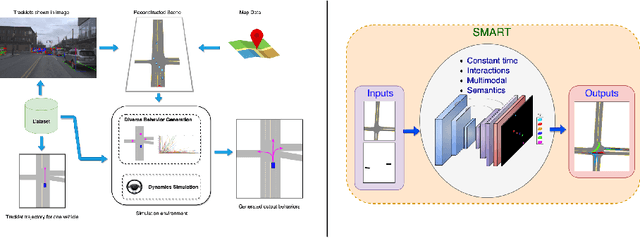

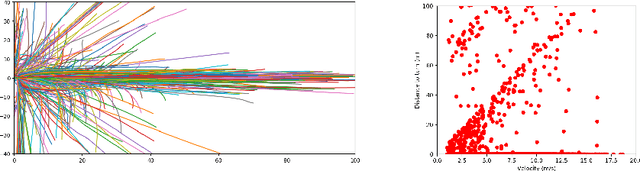
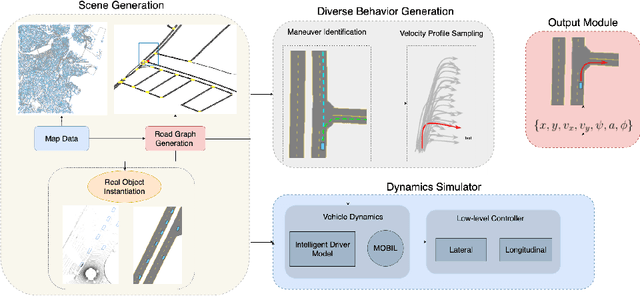
We propose advances that address two key challenges in future trajectory prediction: (i) multimodality in both training data and predictions and (ii) constant time inference regardless of number of agents. Existing trajectory predictions are fundamentally limited by lack of diversity in training data, which is difficult to acquire with sufficient coverage of possible modes. Our first contribution is an automatic method to simulate diverse trajectories in the top-view. It uses pre-existing datasets and maps as initialization, mines existing trajectories to represent realistic driving behaviors and uses a multi-agent vehicle dynamics simulator to generate diverse new trajectories that cover various modes and are consistent with scene layout constraints. Our second contribution is a novel method that generates diverse predictions while accounting for scene semantics and multi-agent interactions, with constant-time inference independent of the number of agents. We propose a convLSTM with novel state pooling operations and losses to predict scene-consistent states of multiple agents in a single forward pass, along with a CVAE for diversity. We validate our proposed multi-agent trajectory prediction approach by training and testing on the proposed simulated dataset and existing real datasets of traffic scenes. In both cases, our approach outperforms SOTA methods by a large margin, highlighting the benefits of both our diverse dataset simulation and constant-time diverse trajectory prediction methods.
Fast Object Classification and Meaningful Data Representation of Segmented Lidar Instances
Jun 17, 2020

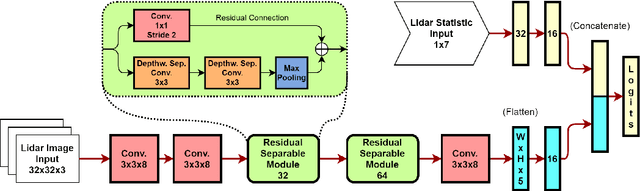
Object detection algorithms for Lidar data have seen numerous publications in recent years, reporting good results on dataset benchmarks oriented towards automotive requirements. Nevertheless, many of these are not deployable to embedded vehicle systems, as they require immense computational power to be executed close to real time. In this work, we propose a way to facilitate real-time Lidar object classification on CPU. We show how our approach uses segmented object instances to extract important features, enabling a computationally efficient batch-wise classification. For this, we introduce a data representation which translates three-dimensional information into small image patches, using decomposed normal vector images. We couple this with dedicated object statistics to handle edge cases. We apply our method on the tasks of object detection and semantic segmentation, as well as the relatively new challenge of panoptic segmentation. Through evaluation, we show, that our algorithm is capable of producing good results on public data, while running in real time on CPU without using specific optimisation.
Panoster: End-to-end Panoptic Segmentation of LiDAR Point Clouds
Oct 28, 2020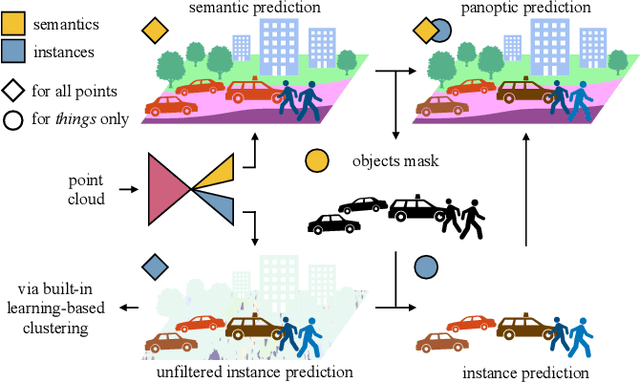
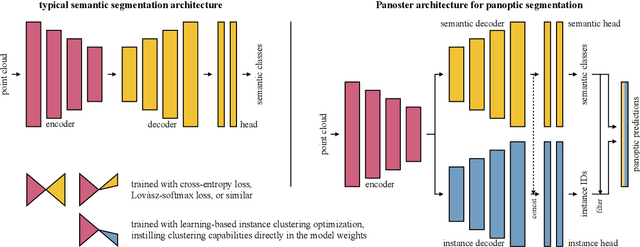
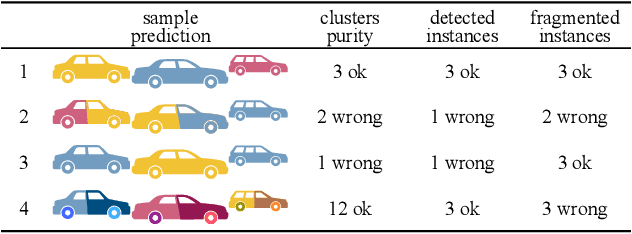
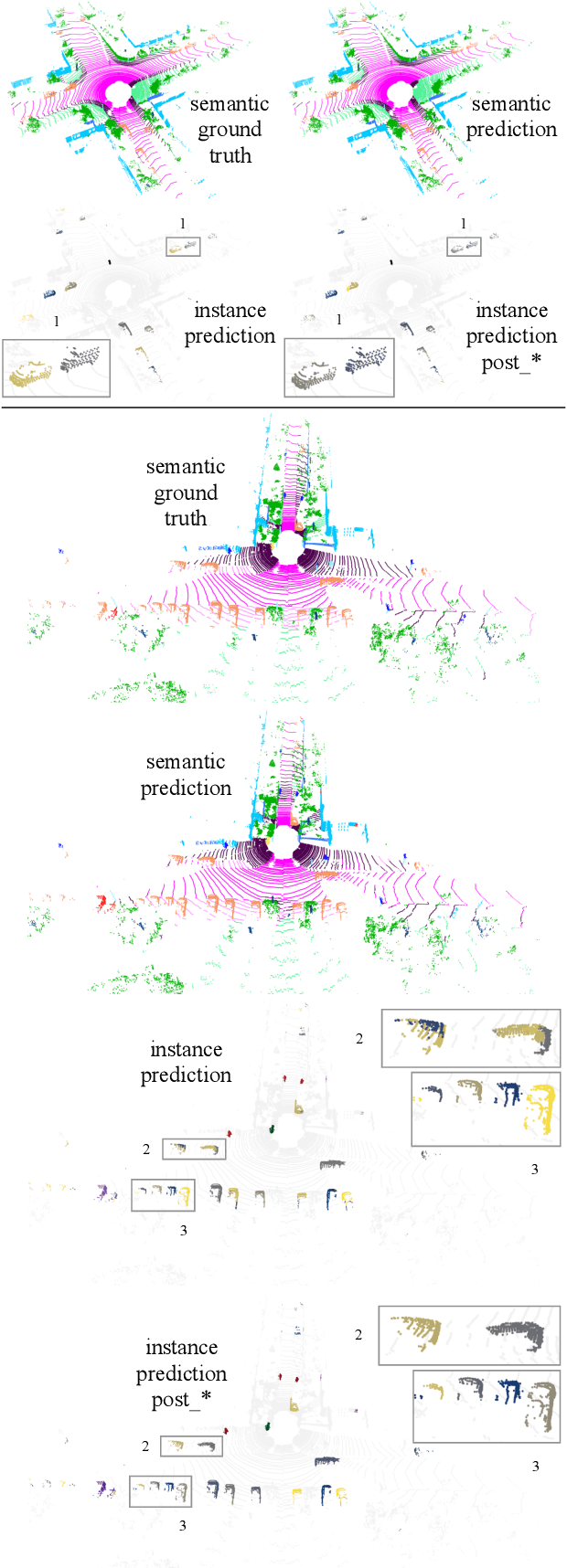
Panoptic segmentation has recently unified semantic and instance segmentation, previously addressed separately, thus taking a step further towards creating more comprehensive and efficient perception systems. In this paper, we present Panoster, a novel proposal-free panoptic segmentation method for point clouds. Unlike previous approaches relying on several steps to group pixels or points into objects, Panoster proposes a simplified framework incorporating a learning-based clustering solution to identify instances. At inference time, this acts as a class-agnostic semantic segmentation, allowing Panoster to be fast, while outperforming prior methods in terms of accuracy. Additionally, we showcase how our approach can be flexibly and effectively applied on diverse existing semantic architectures to deliver panoptic predictions.
Householder Dice: A Matrix-Free Algorithm for Simulating Dynamics on Gaussian and Random Orthogonal Ensembles
Jan 19, 2021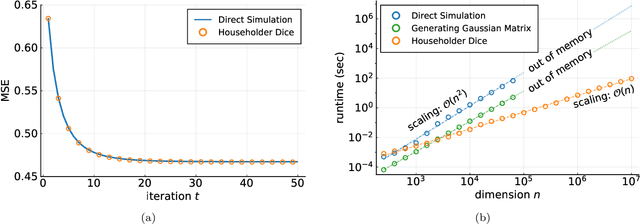
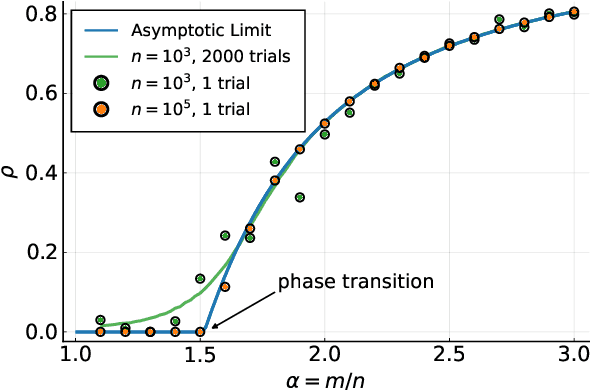
In the study of large random systems, researchers often need to simulate dynamics in the form of iterated matrix-vector multiplications interspersed with nonlinear operations. Examples include message passing algorithms, gradient descent, and matrix iterative methods for extremal eigenvalue calculations. This paper proposes a new algorithm, named Householder Dice (HD), for simulating such dynamics on several random matrix ensembles with translation-invariant properties. Examples include the Gaussian ensemble, the Haar-distributed random orthogonal ensemble, and their complex-valued counterparts. A "direct" approach to the simulation, where one first generates a dense $n \times n$ matrix from the ensemble, requires at least $\mathcal{O}(n^2)$ resource in space and time. The HD algorithm overcomes this $\mathcal{O}(n^2)$ bottleneck by using the principle of deferred decisions: rather than fixing the entire random matrix in advance, it lets the randomness unfold with the dynamics. Key to this matrix-free construction is an adaptive and recursive construction of (random) Householder reflectors. These orthogonal transformations exploit the group symmetry of the matrix ensembles, while simultaneously maintaining the statistical correlations induced by the dynamics. The memory and computation costs of the HD algorithm are $\mathcal{O}(nT)$ and $\mathcal{O}(nT^2)$, respectively, with $T$ being the number of iterations. When $T \ll n$, which is nearly always the case in practice, the HD algorithm leads to significant reductions in runtime and memory footprint. Numerical results demonstrate the promise of the new algorithm as a new computational tool in the study of high-dimensional random systems.
Learning to Rearrange Deformable Cables, Fabrics, and Bags with Goal-Conditioned Transporter Networks
Dec 18, 2020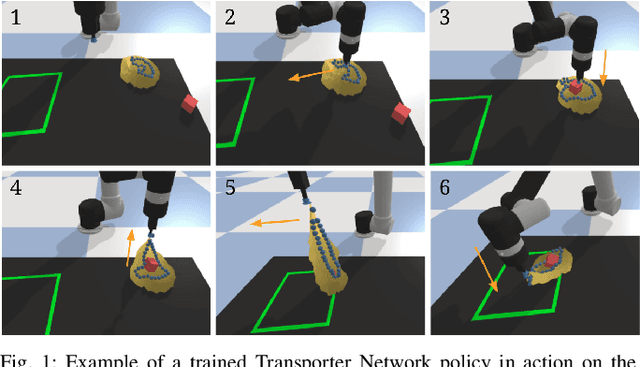
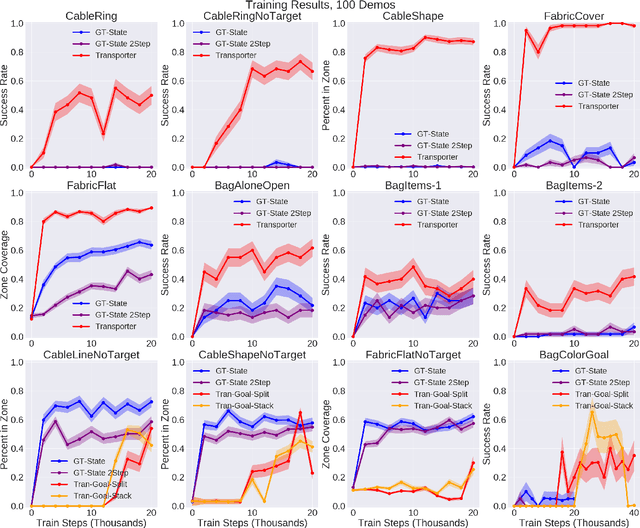
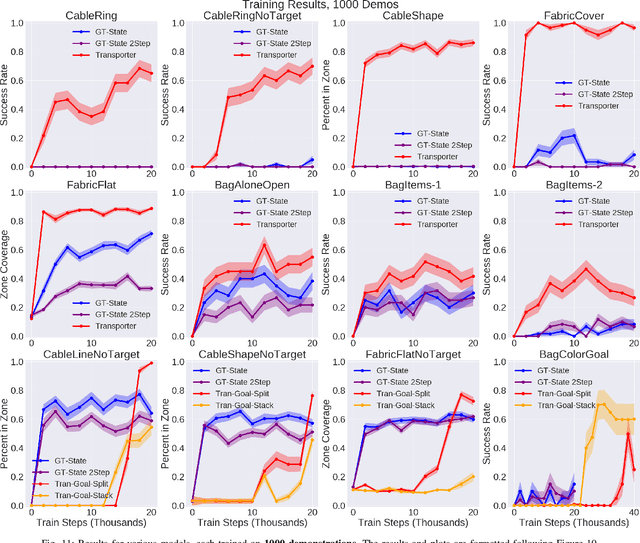
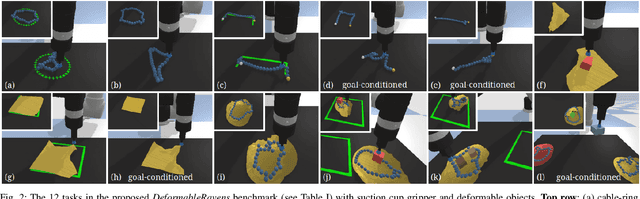
Rearranging and manipulating deformable objects such as cables, fabrics, and bags is a long-standing challenge in robotic manipulation. The complex dynamics and high-dimensional configuration spaces of deformables, compared to rigid objects, make manipulation difficult not only for multi-step planning, but even for goal specification. Goals cannot be as easily specified as rigid object poses, and may involve complex relative spatial relations such as "place the item inside the bag". In this work, we develop a suite of simulated benchmarks with 1D, 2D, and 3D deformable structures, including tasks that involve image-based goal-conditioning and multi-step deformable manipulation. We propose embedding goal-conditioning into Transporter Networks, a recently proposed model architecture for learning robotic manipulation that rearranges deep features to infer displacements that can represent pick and place actions. We demonstrate that goal-conditioned Transporter Networks enable agents to manipulate deformable structures into flexibly specified configurations without test-time visual anchors for target locations. We also significantly extend prior results using Transporter Networks for manipulating deformable objects by testing on tasks with 2D and 3D deformables. Supplementary material is available at https://berkeleyautomation.github.io/bags/.
A Hybrid Learner for Simultaneous Localization and Mapping
Jan 04, 2021
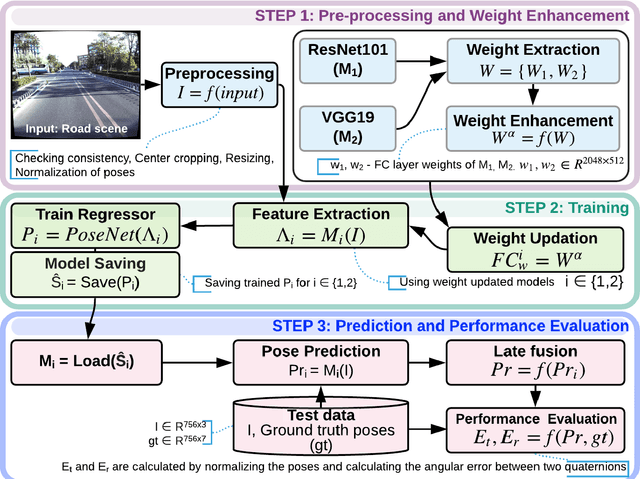
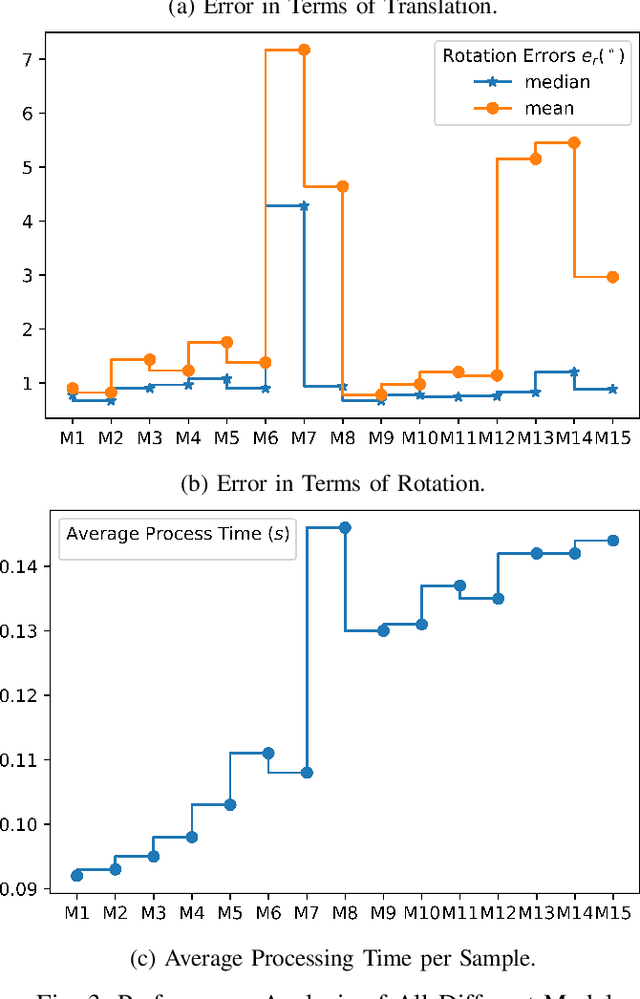
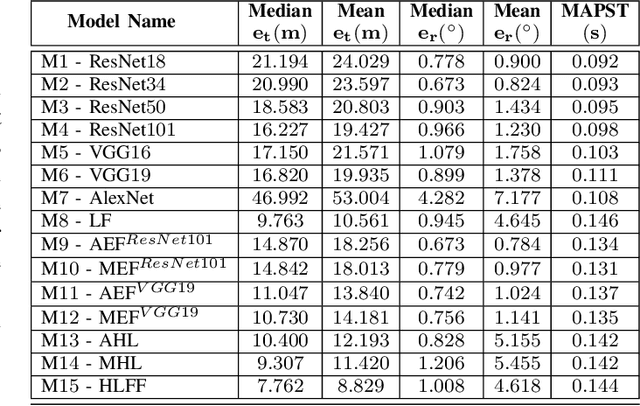
Simultaneous localization and mapping (SLAM) is used to predict the dynamic motion path of a moving platform based on the location coordinates and the precise mapping of the physical environment. SLAM has great potential in augmented reality (AR), autonomous vehicles, viz. self-driving cars, drones, Autonomous navigation robots (ANR). This work introduces a hybrid learning model that explores beyond feature fusion and conducts a multimodal weight sewing strategy towards improving the performance of a baseline SLAM algorithm. It carries out weight enhancement of the front end feature extractor of the SLAM via mutation of different deep networks' top layers. At the same time, the trajectory predictions from independently trained models are amalgamated to refine the location detail. Thus, the integration of the aforesaid early and late fusion techniques under a hybrid learning framework minimizes the translation and rotation errors of the SLAM model. This study exploits some well-known deep learning (DL) architectures, including ResNet18, ResNet34, ResNet50, ResNet101, VGG16, VGG19, and AlexNet for experimental analysis. An extensive experimental analysis proves that hybrid learner (HL) achieves significantly better results than the unimodal approaches and multimodal approaches with early or late fusion strategies. Hence, it is found that the Apolloscape dataset taken in this work has never been used in the literature under SLAM with fusion techniques, which makes this work unique and insightful.
Dynamic Bicycle Dispatching of Dockless Public Bicycle-sharing Systems using Multi-objective Reinforcement Learning
Jan 19, 2021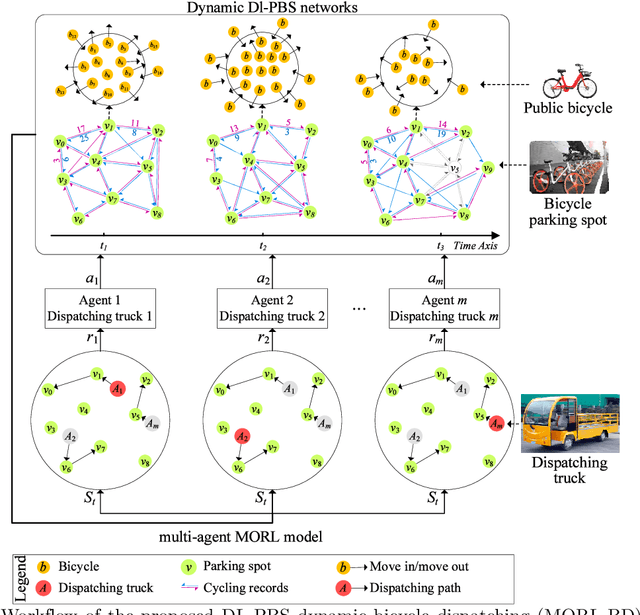
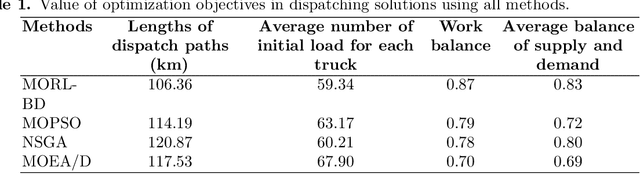

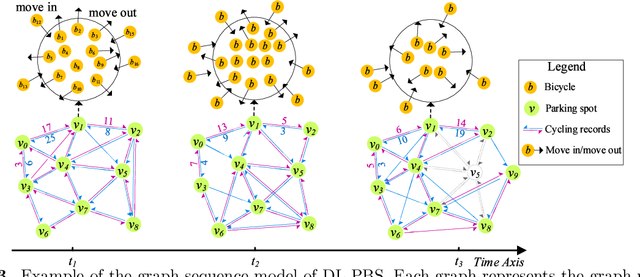
As a new generation of Public Bicycle-sharing Systems (PBS), the dockless PBS (DL-PBS) is an important application of cyber-physical systems and intelligent transportation. How to use AI to provide efficient bicycle dispatching solutions based on dynamic bicycle rental demand is an essential issue for DL-PBS. In this paper, we propose a dynamic bicycle dispatching algorithm based on multi-objective reinforcement learning (MORL-BD) to provide the optimal bicycle dispatching solution for DL-PBS. We model the DL-PBS system from the perspective of CPS and use deep learning to predict the layout of bicycle parking spots and the dynamic demand of bicycle dispatching. We define the multi-route bicycle dispatching problem as a multi-objective optimization problem by considering the optimization objectives of dispatching costs, dispatch truck's initial load, workload balance among the trucks, and the dynamic balance of bicycle supply and demand. On this basis, the collaborative multi-route bicycle dispatching problem among multiple dispatch trucks is modeled as a multi-agent MORL model. All dispatch paths between parking spots are defined as state spaces, and the reciprocal of dispatching costs is defined as a reward. Each dispatch truck is equipped with an agent to learn the optimal dispatch path in the dynamic DL-PBS network. We create an elite list to store the Pareto optimal solutions of bicycle dispatch paths found in each action, and finally, get the Pareto frontier. Experimental results on the actual DL-PBS systems show that compared with existing methods, MORL-BD can find a higher quality Pareto frontier with less execution time.
Deep learning and high harmonic generation
Jan 04, 2021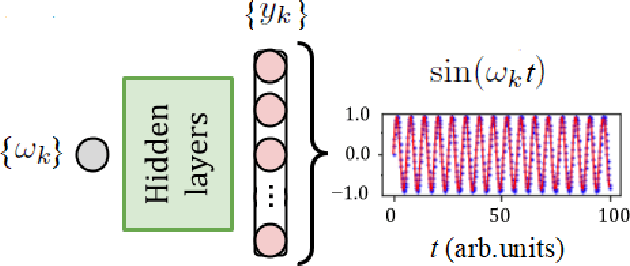
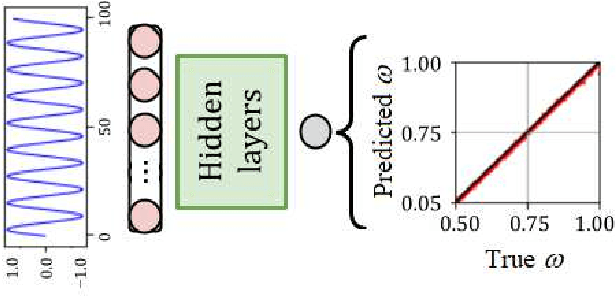
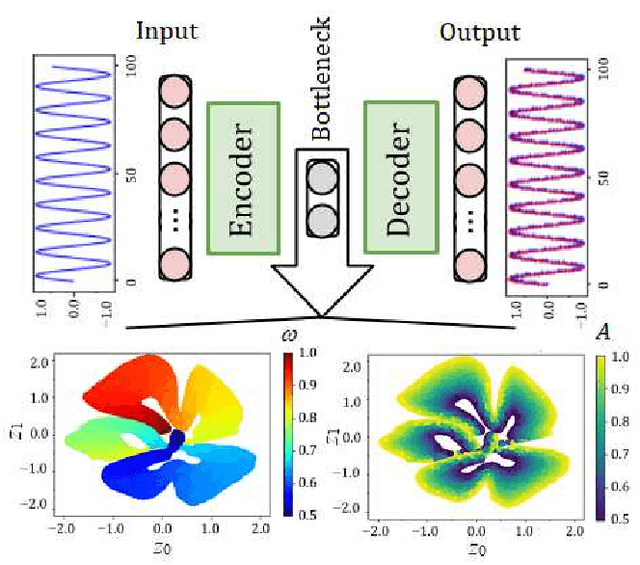
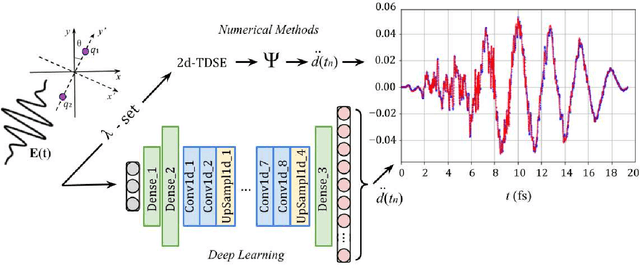
Using machine learning, we explore the utility of various deep neural networks (NN) when applied to high harmonic generation (HHG) scenarios. First, we train the NNs to predict the time-dependent dipole and spectra of HHG emission from reduced-dimensionality models of di- and triatomic systems based of on sets of randomly generated parameters (laser pulse intensity, internuclear distance, and molecular orientation). These networks, once trained, are useful tools to rapidly generate the HHG spectra of our systems. Similarly, we have trained the NNs to solve the inverse problem - to determine the molecular parameters based on HHG spectra or dipole acceleration data. These types of networks could then be used as spectroscopic tools to invert HHG spectra in order to recover the underlying physical parameters of a system. Next, we demonstrate that transfer learning can be applied to our networks to expand the range of applicability of the networks with only a small number of new test cases added to our training sets. Finally, we demonstrate NNs that can be used to classify molecules by type: di- or triatomic, symmetric or asymmetric, wherein we can even rely on fairly simple fully connected neural networks. With outlooks toward training with experimental data, these NN topologies offer a novel set of spectroscopic tools that could be incorporated into HHG experiments.
Inverse Optimal Control from Demonstration Segments
Oct 28, 2020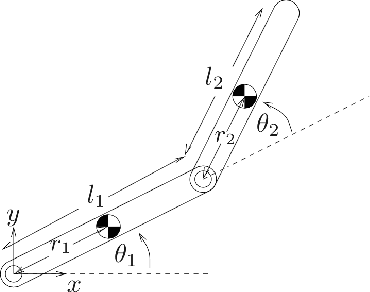
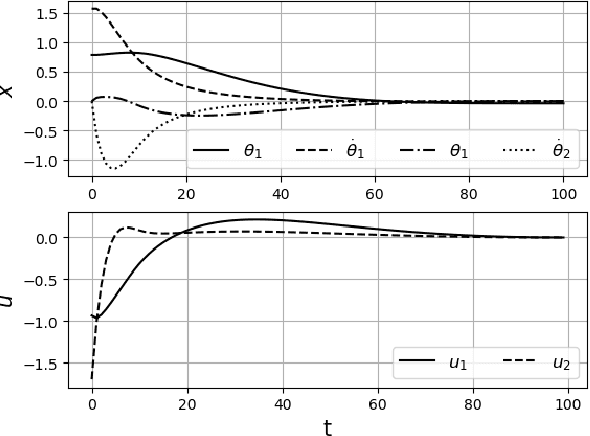
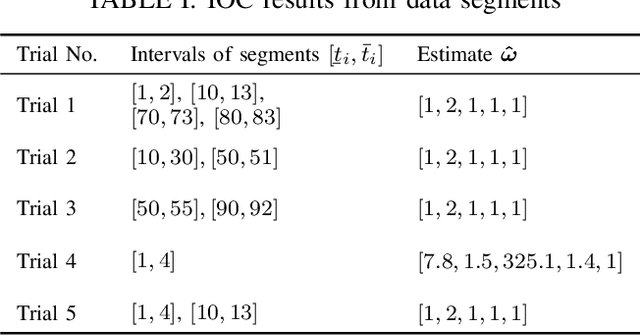
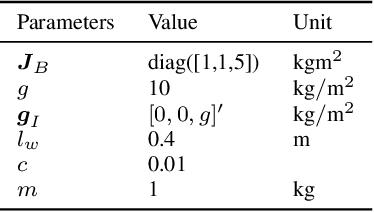
This paper develops an inverse optimal control method to learn an objective function from segments of demonstrations. Here, each segment is part of an optimal trajectory within any time interval of the horizon. The unknown objective function is parameterized as a weighted sum of given features with unknown weights. The proposed method shows that each trajectory segment can be transformed into a linear constraint to the unknown weights, and then all available segments are incrementally incorporated to solve for the unknown weights. Effectiveness of the proposed method is shown on a simulated 2-link robot arm and a 6-DoF maneuvering quadrotor system, in each of which only segment data of the systems' trajectories are available.
EvaLDA: Efficient Evasion Attacks Towards Latent Dirichlet Allocation
Dec 09, 2020

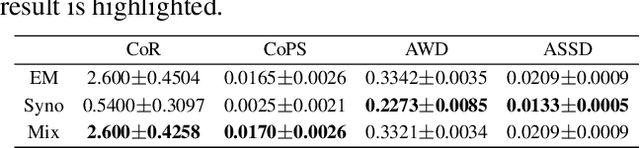

As one of the most powerful topic models, Latent Dirichlet Allocation (LDA) has been used in a vast range of tasks, including document understanding, information retrieval and peer-reviewer assignment. Despite its tremendous popularity, the security of LDA has rarely been studied. This poses severe risks to security-critical tasks such as sentiment analysis and peer-reviewer assignment that are based on LDA. In this paper, we are interested in knowing whether LDA models are vulnerable to adversarial perturbations of benign document examples during inference time. We formalize the evasion attack to LDA models as an optimization problem and prove it to be NP-hard. We then propose a novel and efficient algorithm, EvaLDA to solve it. We show the effectiveness of EvaLDA via extensive empirical evaluations. For instance, in the NIPS dataset, EvaLDA can averagely promote the rank of a target topic from 10 to around 7 by only replacing 1% of the words with similar words in a victim document. Our work provides significant insights into the power and limitations of evasion attacks to LDA models.