 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Composite Adversarial Attacks
Dec 10, 2020
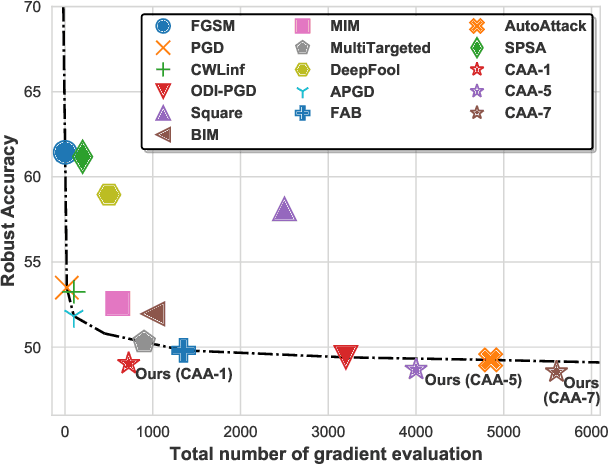

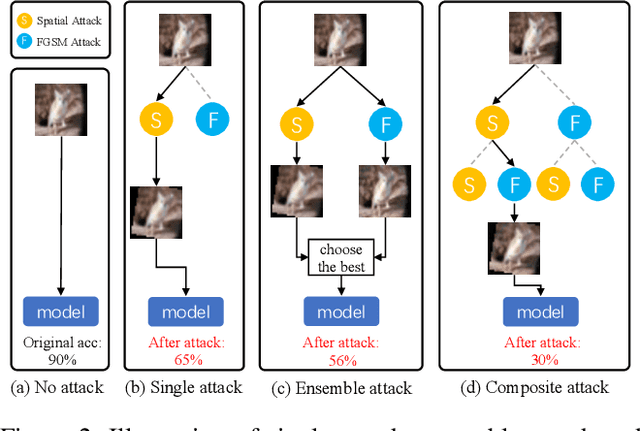
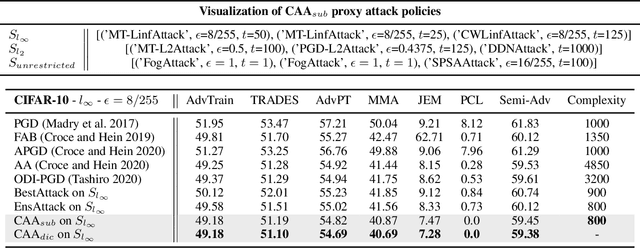
Adversarial attack is a technique for deceiving Machine Learning (ML) models, which provides a way to evaluate the adversarial robustness. In practice, attack algorithms are artificially selected and tuned by human experts to break a ML system. However, manual selection of attackers tends to be sub-optimal, leading to a mistakenly assessment of model security. In this paper, a new procedure called Composite Adversarial Attack (CAA) is proposed for automatically searching the best combination of attack algorithms and their hyper-parameters from a candidate pool of \textbf{32 base attackers}. We design a search space where attack policy is represented as an attacking sequence, i.e., the output of the previous attacker is used as the initialization input for successors. Multi-objective NSGA-II genetic algorithm is adopted for finding the strongest attack policy with minimum complexity. The experimental result shows CAA beats 10 top attackers on 11 diverse defenses with less elapsed time (\textbf{6 $\times$ faster than AutoAttack}), and achieves the new state-of-the-art on $l_{\infty}$, $l_{2}$ and unrestricted adversarial attacks.
Investigating the significance of adversarial attacks and their relation to interpretability for radar-based human activity recognition systems
Jan 26, 2021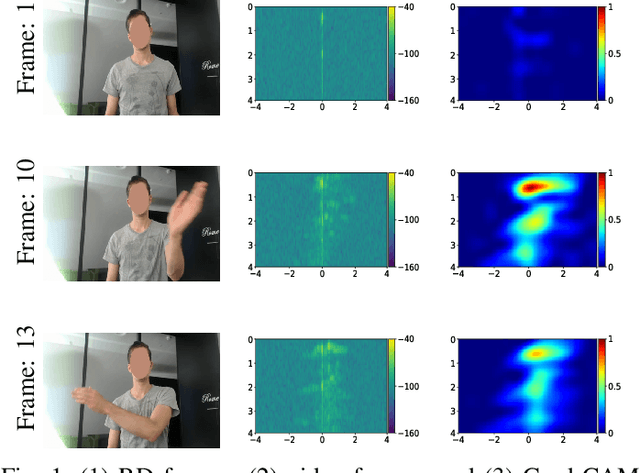
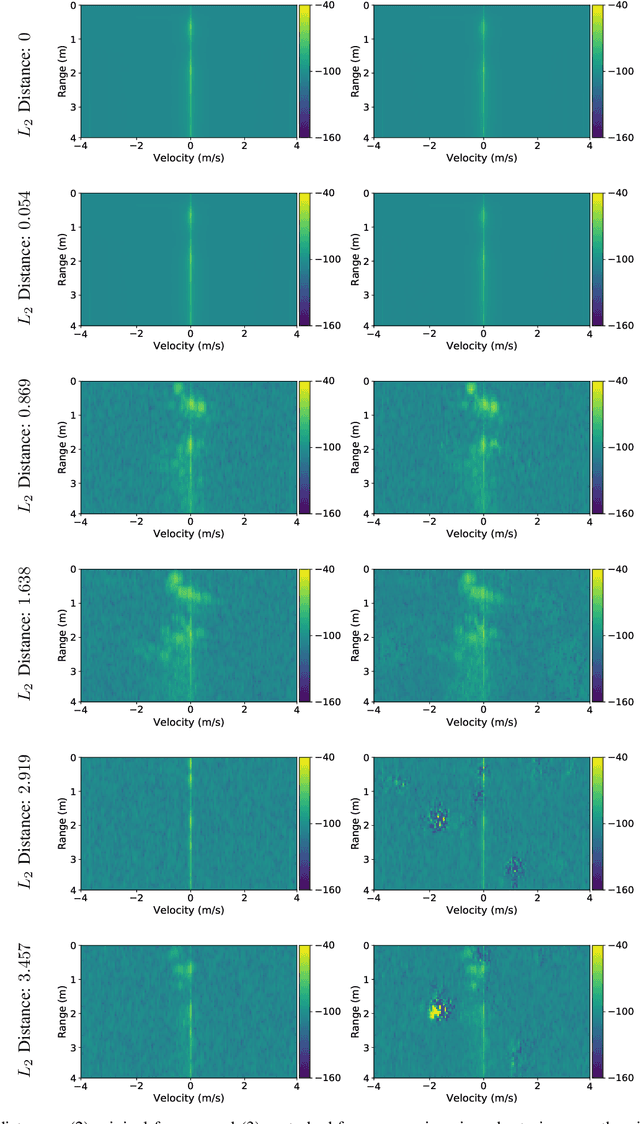
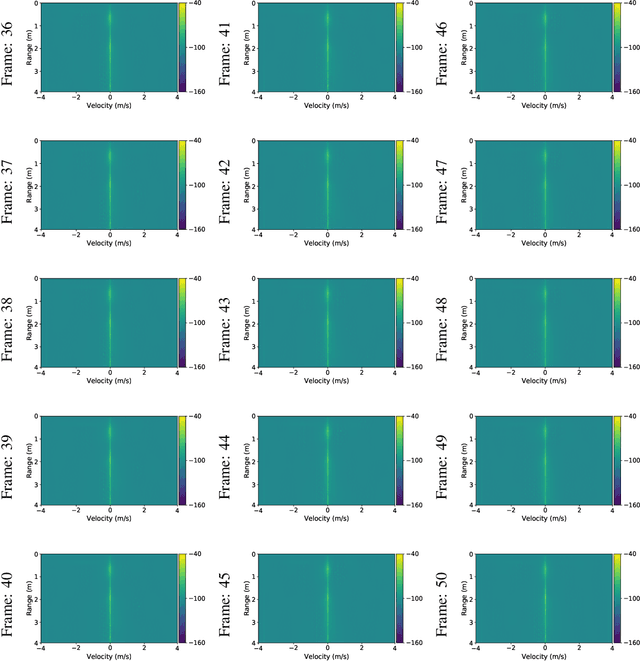
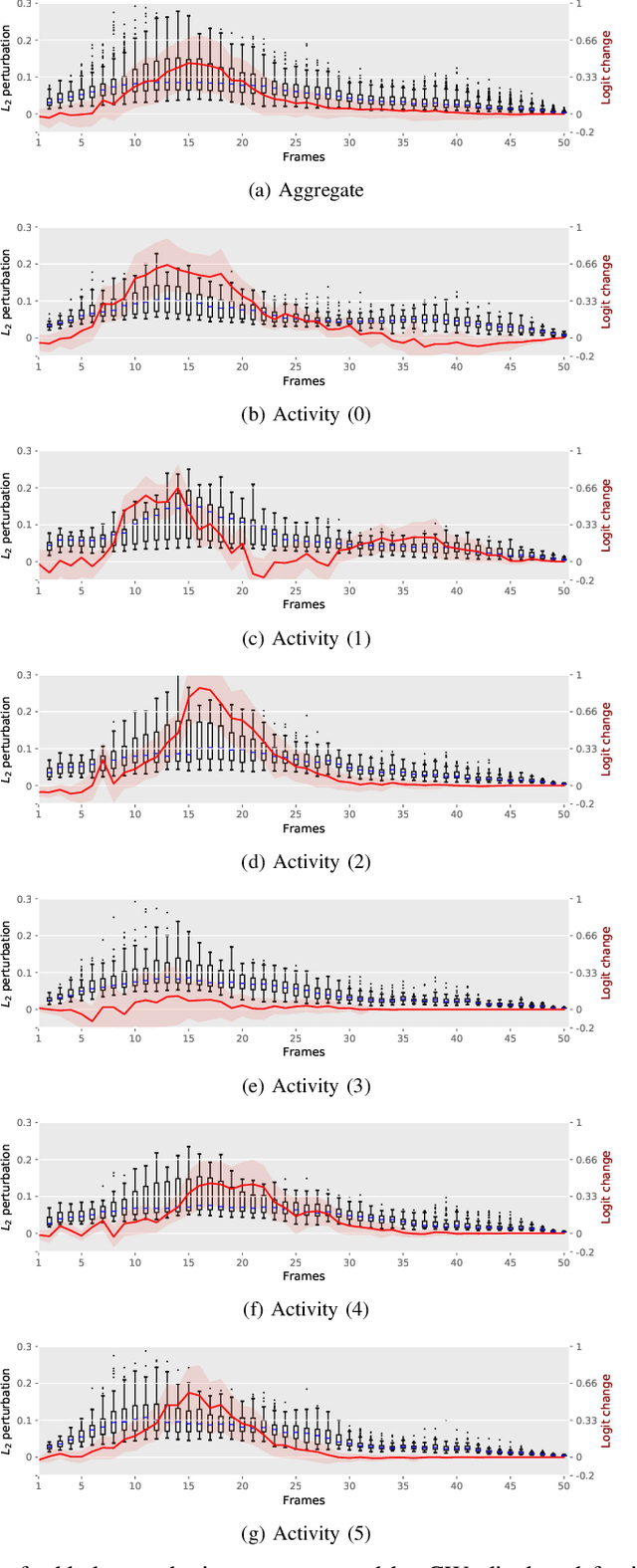
Given their substantial success in addressing a wide range of computer vision challenges, Convolutional Neural Networks (CNNs) are increasingly being used in smart home applications, with many of these applications relying on the automatic recognition of human activities. In this context, low-power radar devices have recently gained in popularity as recording sensors, given that the usage of these devices allows mitigating a number of privacy concerns, a key issue when making use of conventional video cameras. Another concern that is often cited when designing smart home applications is the resilience of these applications against cyberattacks. It is, for instance, well-known that the combination of images and CNNs is vulnerable against adversarial examples, mischievous data points that force machine learning models to generate wrong classifications during testing time. In this paper, we investigate the vulnerability of radar-based CNNs to adversarial attacks, and where these radar-based CNNs have been designed to recognize human gestures. Through experiments with four unique threat models, we show that radar-based CNNs are susceptible to both white- and black-box adversarial attacks. We also expose the existence of an extreme adversarial attack case, where it is possible to change the prediction made by the radar-based CNNs by only perturbing the padding of the inputs, without touching the frames where the action itself occurs. Moreover, we observe that gradient-based attacks exercise perturbation not randomly, but on important features of the input data. We highlight these important features by making use of Grad-CAM, a popular neural network interpretability method, hereby showing the connection between adversarial perturbation and prediction interpretability.
Hardness results for Multimarginal Optimal Transport problems
Dec 10, 2020Multimarginal Optimal Transport (MOT) is the problem of linear programming over joint probability distributions with fixed marginals. A key issue in many applications is the complexity of solving MOT: the linear program has exponential size in the number of marginals k and their support sizes n. A recent line of work has shown that MOT is poly(n,k)-time solvable for certain families of costs that have poly(n,k)-size implicit representations. However, it is unclear what further families of costs this line of algorithmic research can encompass. In order to understand these fundamental limitations, this paper initiates the study of intractability results for MOT. Our main technical contribution is developing a toolkit for proving NP-hardness and inapproximability results for MOT problems. We demonstrate this toolkit by using it to establish the intractability of a number of MOT problems studied in the literature that have resisted previous algorithmic efforts. For instance, we provide evidence that repulsive costs make MOT intractable by showing that several such problems of interest are NP-hard to solve--even approximately.
Neural Network architectures to classify emotions in Indian Classical Music
Feb 01, 2021
Music is often considered as the language of emotions. It has long been known to elicit emotions in human being and thus categorizing music based on the type of emotions they induce in human being is a very intriguing topic of research. When the task comes to classify emotions elicited by Indian Classical Music (ICM), it becomes much more challenging because of the inherent ambiguity associated with ICM. The fact that a single musical performance can evoke a variety of emotional response in the audience is implicit to the nature of ICM renditions. With the rapid advancements in the field of Deep Learning, this Music Emotion Recognition (MER) task is becoming more and more relevant and robust, hence can be applied to one of the most challenging test case i.e. classifying emotions elicited from ICM. In this paper we present a new dataset called JUMusEmoDB which presently has 400 audio clips (30 seconds each) where 200 clips correspond to happy emotions and the remaining 200 clips correspond to sad emotion. For supervised classification purposes, we have used 4 existing deep Convolutional Neural Network (CNN) based architectures (resnet18, mobilenet v2.0, squeezenet v1.0 and vgg16) on corresponding music spectrograms of the 2000 sub-clips (where every clip was segmented into 5 sub-clips of about 5 seconds each) which contain both time as well as frequency domain information. The initial results are quite inspiring, and we look forward to setting the baseline values for the dataset using this architecture. This type of CNN based classification algorithm using a rich corpus of Indian Classical Music is unique even in the global perspective and can be replicated in other modalities of music also. This dataset is still under development and we plan to include more data containing other emotional features as well. We plan to make the dataset publicly available soon.
Improving the Robustness of Trading Strategy Backtesting with Boltzmann Machines and Generative Adversarial Networks
Jul 09, 2020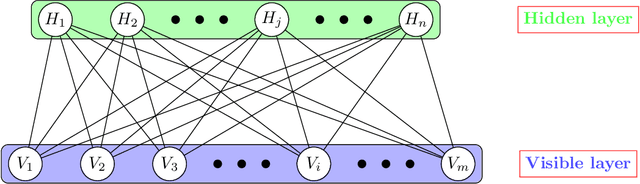
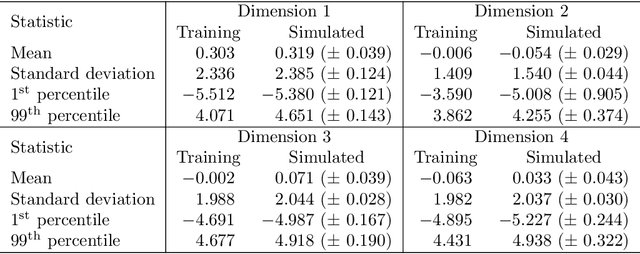
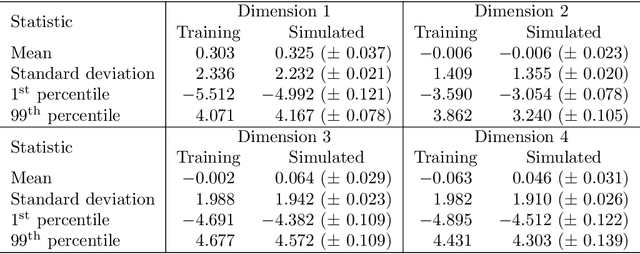
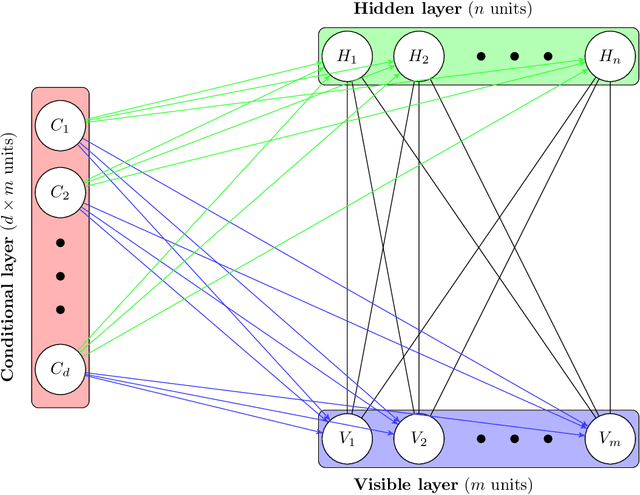
This article explores the use of machine learning models to build a market generator. The underlying idea is to simulate artificial multi-dimensional financial time series, whose statistical properties are the same as those observed in the financial markets. In particular, these synthetic data must preserve the probability distribution of asset returns, the stochastic dependence between the different assets and the autocorrelation across time. The article proposes then a new approach for estimating the probability distribution of backtest statistics. The final objective is to develop a framework for improving the risk management of quantitative investment strategies, in particular in the space of smart beta, factor investing and alternative risk premia.
A high fidelity synthetic face framework for computer vision
Jul 16, 2020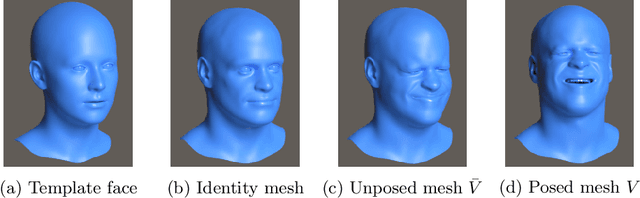

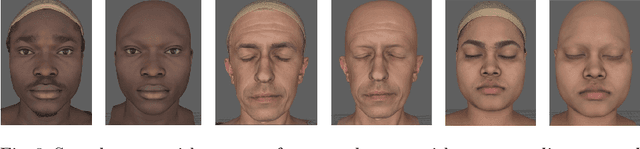

Analysis of faces is one of the core applications of computer vision, with tasks ranging from landmark alignment, head pose estimation, expression recognition, and face recognition among others. However, building reliable methods requires time-consuming data collection and often even more time-consuming manual annotation, which can be unreliable. In our work we propose synthesizing such facial data, including ground truth annotations that would be almost impossible to acquire through manual annotation at the consistency and scale possible through use of synthetic data. We use a parametric face model together with hand crafted assets which enable us to generate training data with unprecedented quality and diversity (varying shape, texture, expression, pose, lighting, and hair).
Real-Time Area Coverage and Target Localization using Receding-Horizon Ergodic Exploration
Aug 28, 2017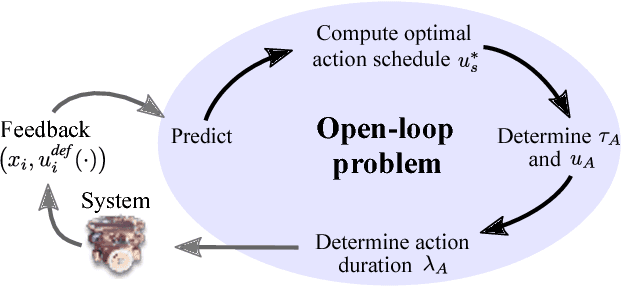
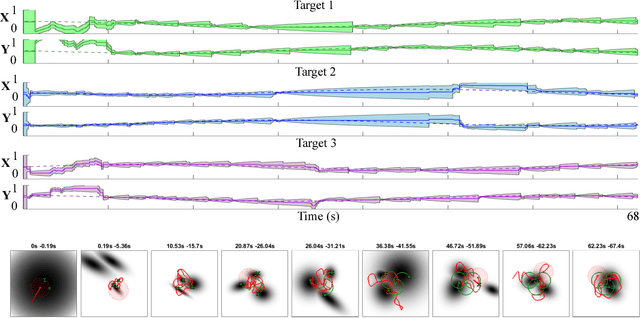
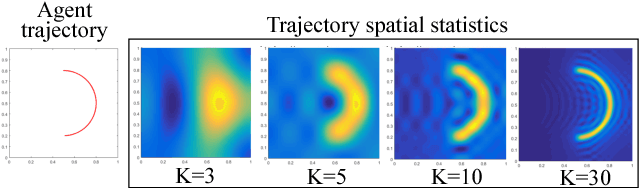
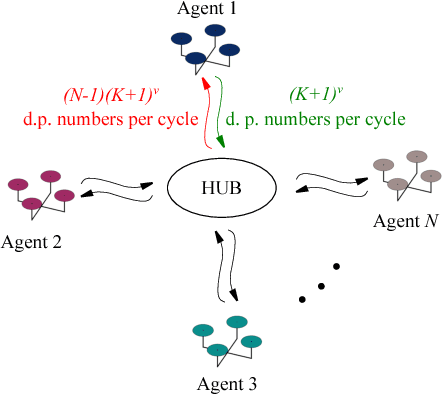
Although a number of solutions exist for the problems of coverage, search and target localization---commonly addressed separately---whether there exists a unified strategy that addresses these objectives in a coherent manner without being application-specific remains a largely open research question. In this paper, we develop a receding-horizon ergodic control approach, based on hybrid systems theory, that has the potential to fill this gap. The nonlinear model predictive control algorithm plans real-time motions that optimally improve ergodicity with respect to a distribution defined by the expected information density across the sensing domain. We establish a theoretical framework for global stability guarantees with respect to a distribution. Moreover, the approach is distributable across multiple agents, so that each agent can independently compute its own control while sharing statistics of its coverage across a communication network. We demonstrate the method in both simulation and in experiment in the context of target localization, illustrating that the algorithm is independent of the number of targets being tracked and can be run in real-time on computationally limited hardware platforms.
Tensor-Generative Adversarial Network with Two-dimensional Sparse Coding: Application to Real-time Indoor Localization
Nov 07, 2017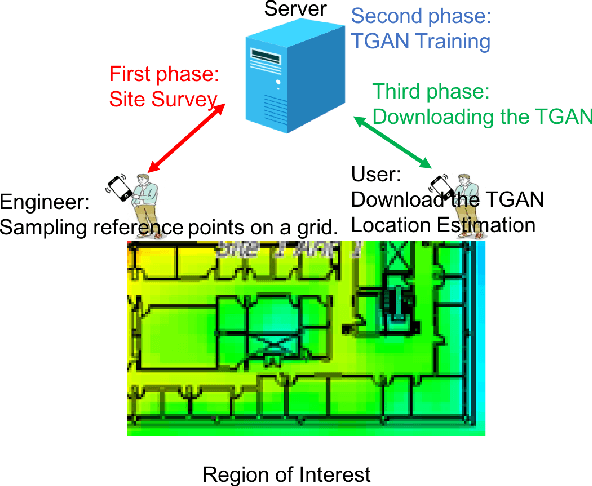
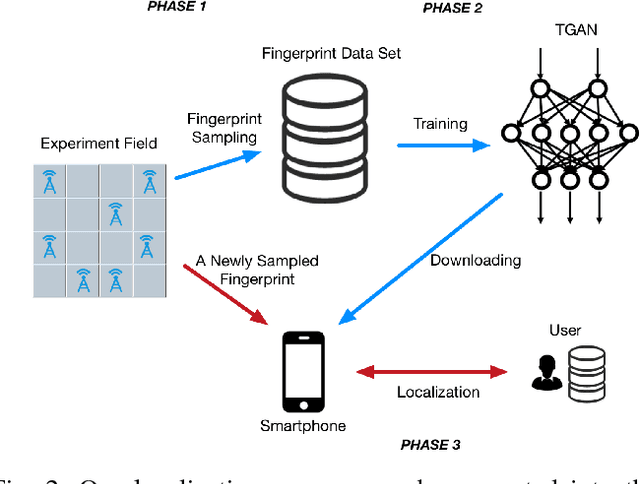
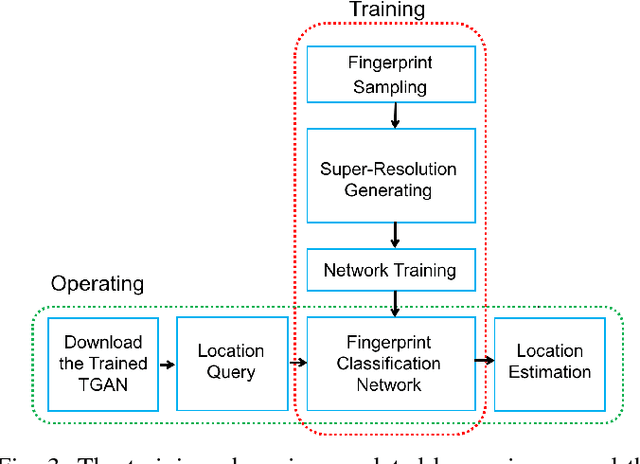
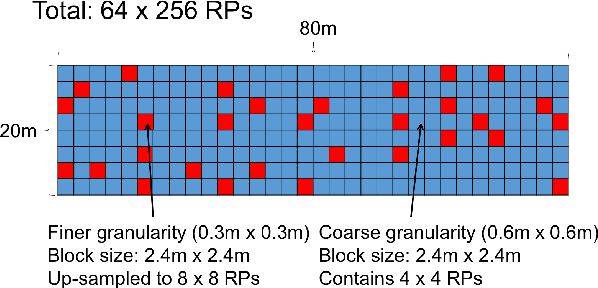
Localization technology is important for the development of indoor location-based services (LBS). Global Positioning System (GPS) becomes invalid in indoor environments due to the non-line-of-sight issue, so it is urgent to develop a real-time high-accuracy localization approach for smartphones. However, accurate localization is challenging due to issues such as real-time response requirements, limited fingerprint samples and mobile device storage. To address these problems, we propose a novel deep learning architecture: Tensor-Generative Adversarial Network (TGAN). We first introduce a transform-based 3D tensor to model fingerprint samples. Instead of those passive methods that construct a fingerprint database as a prior, our model applies artificial neural network with deep learning to train network classifiers and then gives out estimations. Then we propose a novel tensor-based super-resolution scheme using the generative adversarial network (GAN) that adopts sparse coding as the generator network and a residual learning network as the discriminator. Further, we analyze the performance of tensor-GAN and implement a trace-based localization experiment, which achieves better performance. Compared to existing methods for smartphones indoor positioning, that are energy-consuming and high demands on devices, TGAN can give out an improved solution in localization accuracy, response time and implementation complexity.
An Efficient Algorithm for Cooperative Semi-Bandits
Oct 05, 2020We consider the problem of asynchronous online combinatorial optimization on a network of communicating agents. At each time step, some of the agents are stochastically activated, requested to make a prediction, and the system pays the corresponding loss. Then, neighbors of active agents receive semi-bandit feedback and exchange some succinct local information. The goal is to minimize the network regret, defined as the difference between the cumulative loss of the predictions of active agents and that of the best action in hindsight, selected from a combinatorial decision set. The main challenge in such a context is to control the computational complexity of the resulting algorithm while retaining minimax optimal regret guarantees. We introduce Coop-FTPL, a cooperative version of the well-known Follow The Perturbed Leader algorithm, that implements a new loss estimation procedure generalizing the Geometric Resampling of Neu and Bart\'ok [2013] to our setting. Assuming that the elements of the decision set are $k$-dimensional binary vectors with at most $m$ non-zero entries and $\alpha_1$ is the independence number of the network, we show that the expected regret of our algorithm after $T$ time steps is of order $Q\sqrt{mkT\log(k) (k\alpha_1/Q+m)}$, where $Q$ is the total activation probability mass. Furthermore, we prove that this is only $\sqrt{k\log k}$-away from the best achievable rate and that \coopftpl{} has a state-of-the-art $T^{3/2}$ worst-case computational complexity.
Solving high-dimensional parameter inference: marginal posterior densities & Moment Networks
Nov 11, 2020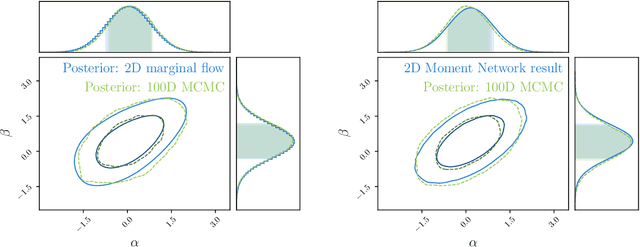
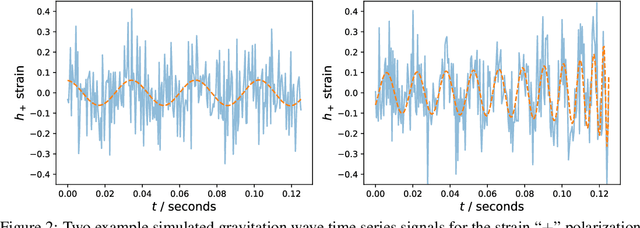
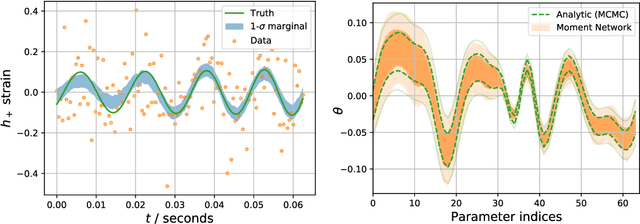
High-dimensional probability density estimation for inference suffers from the "curse of dimensionality". For many physical inference problems, the full posterior distribution is unwieldy and seldom used in practice. Instead, we propose direct estimation of lower-dimensional marginal distributions, bypassing high-dimensional density estimation or high-dimensional Markov chain Monte Carlo (MCMC) sampling. By evaluating the two-dimensional marginal posteriors we can unveil the full-dimensional parameter covariance structure. We additionally propose constructing a simple hierarchy of fast neural regression models, called Moment Networks, that compute increasing moments of any desired lower-dimensional marginal posterior density; these reproduce exact results from analytic posteriors and those obtained from Masked Autoregressive Flows. We demonstrate marginal posterior density estimation using high-dimensional LIGO-like gravitational wave time series and describe applications for problems of fundamental cosmology.