 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Solving non-linear Kolmogorov equations in large dimensions by using deep learning: a numerical comparison of discretization schemes
Dec 28, 2020




Non-linear partial differential Kolmogorov equations are successfully used to describe a wide range of time dependent phenomena, in natural sciences, engineering or even finance. For example, in physical systems, the Allen-Cahn equation describes pattern formation associated to phase transitions. In finance, instead, the Black-Scholes equation describes the evolution of the price of derivative investment instruments. Such modern applications often require to solve these equations in high-dimensional regimes in which classical approaches are ineffective. Recently, an interesting new approach based on deep learning has been introduced by E, Han, and Jentzen [1][2]. The main idea is to construct a deep network which is trained from the samples of discrete stochastic differential equations underlying Kolmogorov's equation. The network is able to approximate, numerically at least, the solutions of the Kolmogorov equation with polynomial complexity in whole spatial domains. In this contribution we study variants of the deep networks by using different discretizations schemes of the stochastic differential equation. We compare the performance of the associated networks, on benchmarked examples, and show that, for some discretization schemes, improvements in the accuracy are possible without affecting the observed computational complexity.
Factorized Gaussian Process Variational Autoencoders
Nov 14, 2020
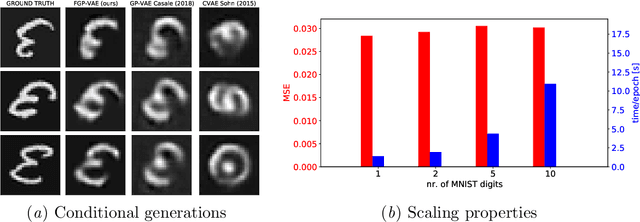


Variational autoencoders often assume isotropic Gaussian priors and mean-field posteriors, hence do not exploit structure in scenarios where we may expect similarity or consistency across latent variables. Gaussian process variational autoencoders alleviate this problem through the use of a latent Gaussian process, but lead to a cubic inference time complexity. We propose a more scalable extension of these models by leveraging the independence of the auxiliary features, which is present in many datasets. Our model factorizes the latent kernel across these features in different dimensions, leading to a significant speed-up (in theory and practice), while empirically performing comparably to existing non-scalable approaches. Moreover, our approach allows for additional modeling of global latent information and for more general extrapolation to unseen input combinations.
Self-supervised Temporal Discriminative Learning for Video Representation Learning
Aug 05, 2020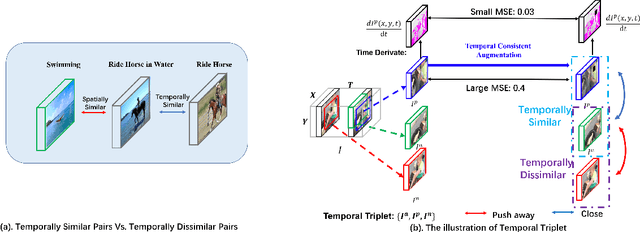
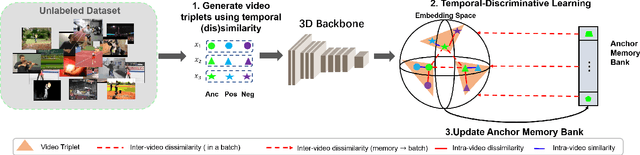
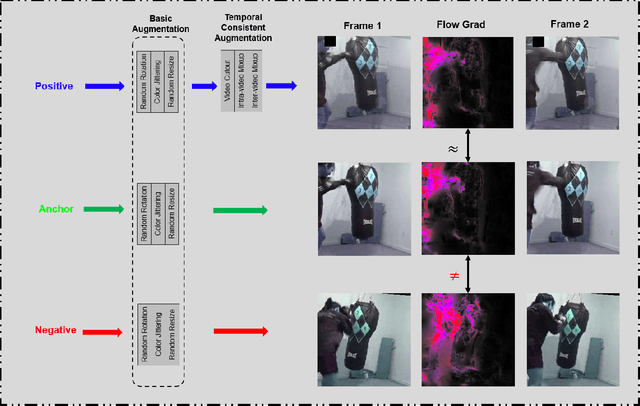
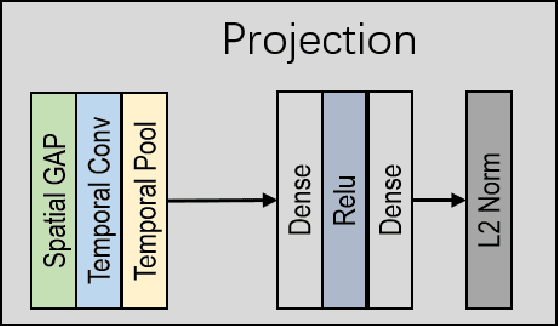
Temporal cues in videos provide important information for recognizing actions accurately. However, temporal-discriminative features can hardly be extracted without using an annotated large-scale video action dataset for training. This paper proposes a novel Video-based Temporal-Discriminative Learning (VTDL) framework in self-supervised manner. Without labelled data for network pretraining, temporal triplet is generated for each anchor video by using segment of the same or different time interval so as to enhance the capacity for temporal feature representation. Measuring temporal information by time derivative, Temporal Consistent Augmentation (TCA) is designed to ensure that the time derivative (in any order) of the augmented positive is invariant except for a scaling constant. Finally, temporal-discriminative features are learnt by minimizing the distance between each anchor and its augmented positive, while the distance between each anchor and its augmented negative as well as other videos saved in the memory bank is maximized to enrich the representation diversity. In the downstream action recognition task, the proposed method significantly outperforms existing related works. Surprisingly, the proposed self-supervised approach is better than fully-supervised methods on UCF101 and HMDB51 when a small-scale video dataset (with only thousands of videos) is used for pre-training. The code has been made publicly available on https://github.com/FingerRec/Self-Supervised-Temporal-Discriminative-Representation-Learning-for-Video-Action-Recognition.
Early Classification for Agricultural Monitoring from Satellite Time Series
Aug 27, 2019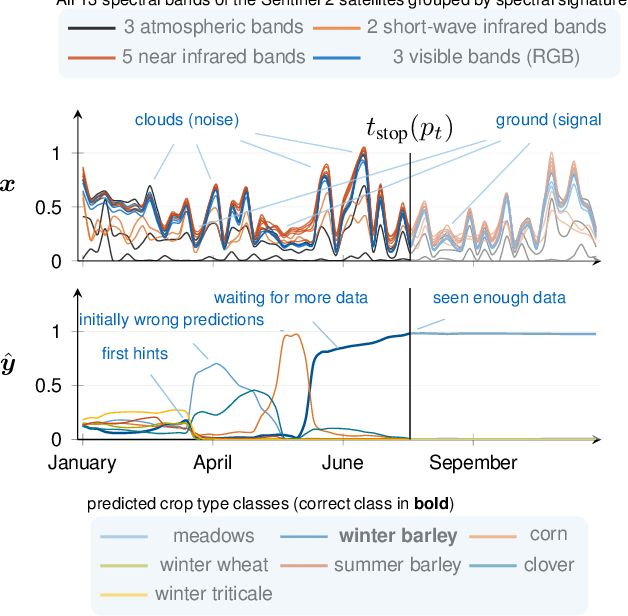
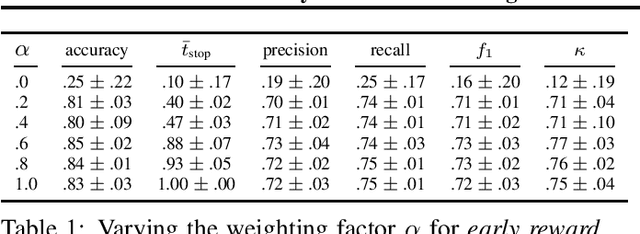
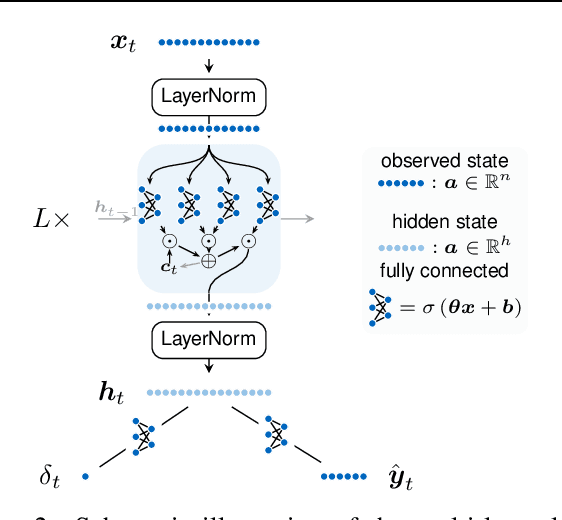
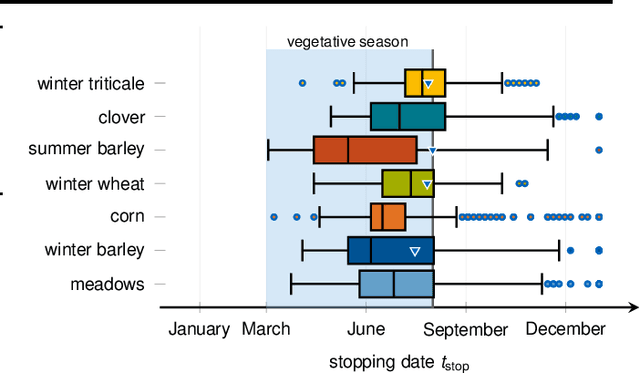
In this work, we introduce a recently developed early classification mechanism to satellite-based agricultural monitoring. It augments existing classification models by an additional stopping probability based on the previously seen information. This mechanism is end-to-end trainable and derives its stopping decision solely from the observed satellite data. We show results on field parcels in central Europe where sufficient ground truth data is available for an empiric evaluation of the results with local phenological information obtained from authorities. We observe that the recurrent neural network outfitted with this early classification mechanism was able to distinguish the many of the crop types before the end of the vegetative period. Further, we associated these stopping times with evaluated ground truth information and saw that the times of classification were related to characteristic events of the observed plants' phenology.
Forecasting the Olympic medal distribution during a pandemic: a socio-economic machine learning model
Dec 08, 2020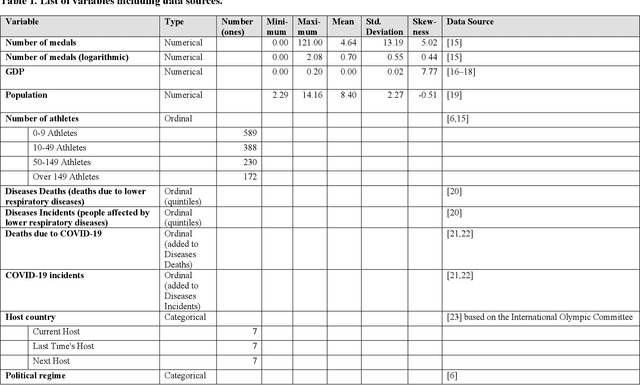
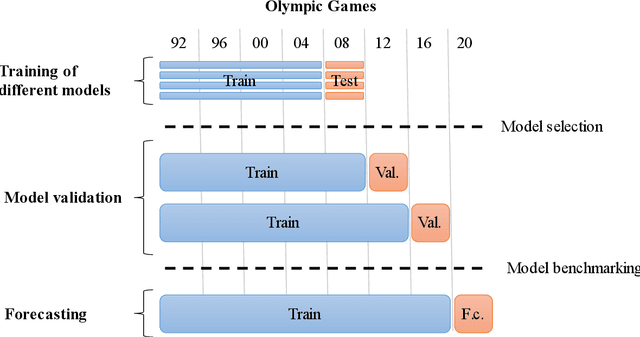
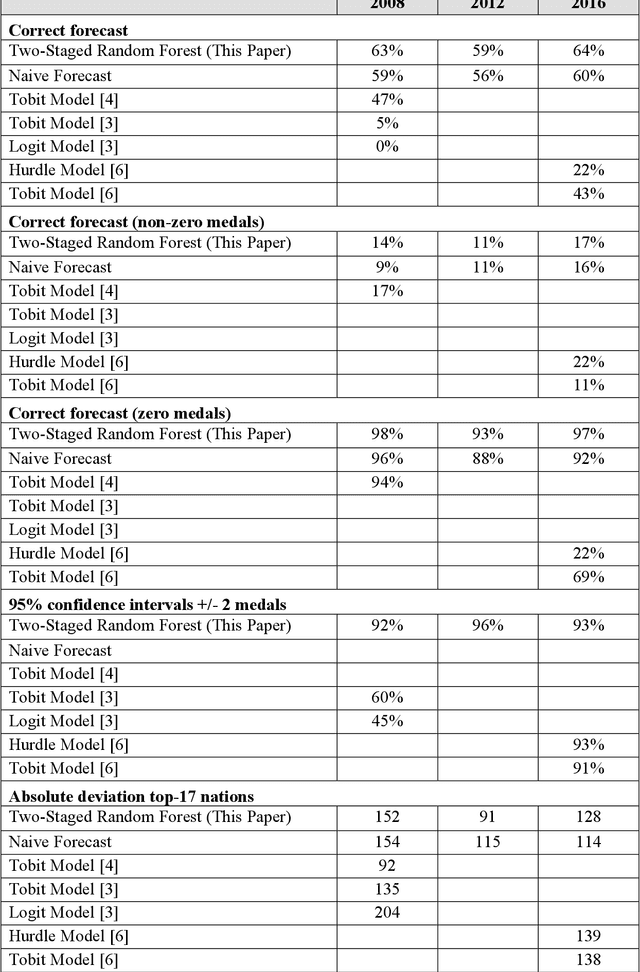
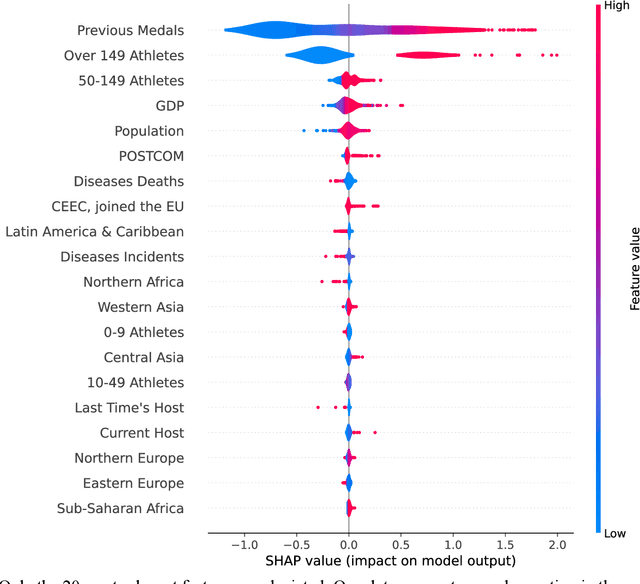
Forecasting the number of Olympic medals for each nation is highly relevant for different stakeholders: Ex ante, sports betting companies can determine the odds while sponsors and media companies can allocate their resources to promising teams. Ex post, sports politicians and managers can benchmark the performance of their teams and evaluate the drivers of success. To significantly increase the Olympic medal forecasting accuracy, we apply machine learning, more specifically a two-staged Random Forest, thus outperforming more traditional na\"ive forecast for three previous Olympics held between 2008 and 2016 for the first time. Regarding the Tokyo 2020 Games in 2021, our model suggests that the United States will lead the Olympic medal table, winning 120 medals, followed by China (87) and Great Britain (74). Intriguingly, we predict that the current COVID-19 pandemic will not significantly alter the medal count as all countries suffer from the pandemic to some extent (data inherent) and limited historical data points on comparable diseases (model inherent).
Overfitting for Fun and Profit: Instance-Adaptive Data Compression
Jan 21, 2021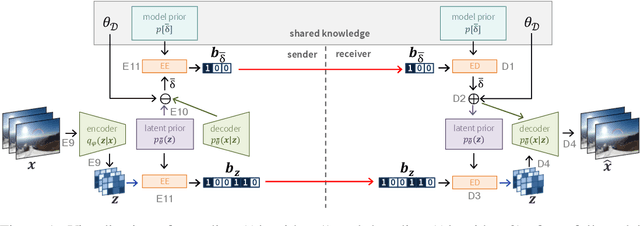

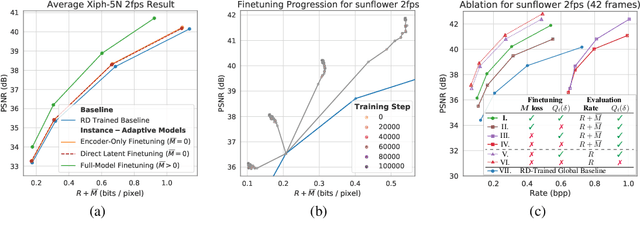
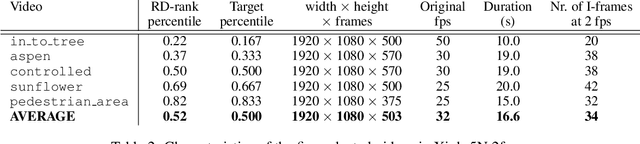
Neural data compression has been shown to outperform classical methods in terms of $RD$ performance, with results still improving rapidly. At a high level, neural compression is based on an autoencoder that tries to reconstruct the input instance from a (quantized) latent representation, coupled with a prior that is used to losslessly compress these latents. Due to limitations on model capacity and imperfect optimization and generalization, such models will suboptimally compress test data in general. However, one of the great strengths of learned compression is that if the test-time data distribution is known and relatively low-entropy (e.g. a camera watching a static scene, a dash cam in an autonomous car, etc.), the model can easily be finetuned or adapted to this distribution, leading to improved $RD$ performance. In this paper we take this concept to the extreme, adapting the full model to a single video, and sending model updates (quantized and compressed using a parameter-space prior) along with the latent representation. Unlike previous work, we finetune not only the encoder/latents but the entire model, and - during finetuning - take into account both the effect of model quantization and the additional costs incurred by sending the model updates. We evaluate an image compression model on I-frames (sampled at 2 fps) from videos of the Xiph dataset, and demonstrate that full-model adaptation improves $RD$ performance by ~1 dB, with respect to encoder-only finetuning.
Two-Phase Learning for Overcoming Noisy Labels
Dec 08, 2020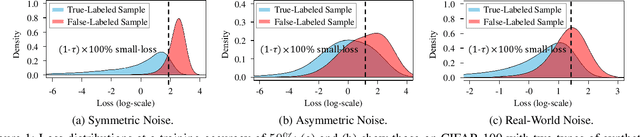
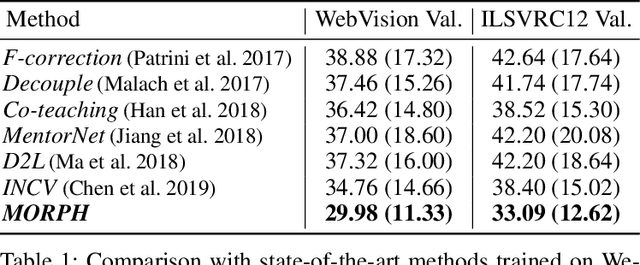
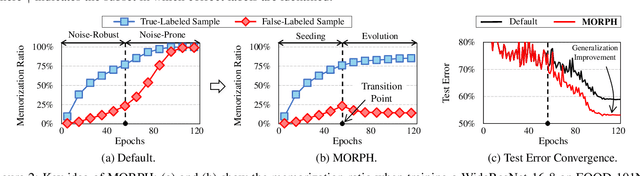
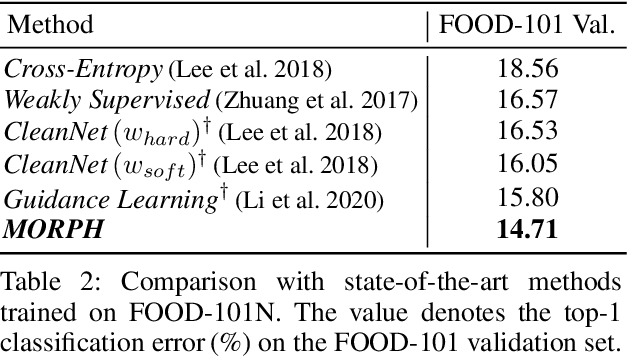
To counter the challenge associated with noise labels, the learning strategy of deep neural networks must be differentiated over the learning period during the training process. Therefore, we propose a novel two-phase learning method, MORPH, which automatically transitions its learning phase at the point when the network begins to rapidly memorize false-labeled samples. In the first phase, MORPH starts to update the network for all the training samples before the transition point. Without any supervision, the learning phase is converted to the next phase on the basis of the estimated best transition point. Subsequently, MORPH resumes the training of the network only for a maximal safe set, which maintains the collection of almost certainly true-labeled samples at each epoch. Owing to its two-phase learning, MORPH realizes noise-free training for any type of label noise for practical use. Moreover, extensive experiments using six datasets verify that MORPH significantly outperforms five state-of-the art methods in terms of test error and training time.
Optimizing Reachability Sets in Temporal Graphs by Delaying
Apr 13, 2020


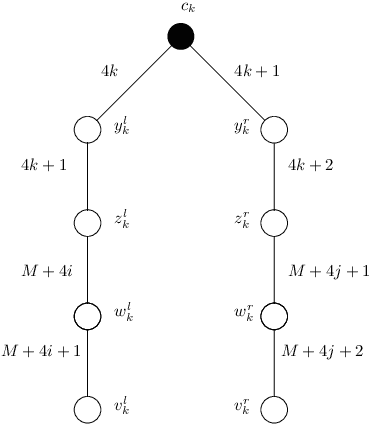
A temporal graph is a dynamic graph where every edge is assigned a set of integer time labels that indicate at which discrete time step the edge is available. In this paper, we study how changes of the time labels, corresponding to delays on the availability of the edges, affect the reachability sets from given sources. The questions about reachability sets are motivated by numerous applications of temporal graphs in network epidemiology, which aim to minimise the spread of infection, and scheduling problems in supply networks in manufacturing with the opposite objectives of maximising coverage and productivity. We introduce control mechanisms for reachability sets that are based on two natural operations of delaying time events which significantly affecting the chains of these events. The first operation, termed merging, is global and batches together consecutive time labels in the whole network simultaneously. This corresponds to postponing all events until a particular time. The second, imposes independent delays on the time labels of every edge of the graph.cWe provide a thorough investigation of the computational complexity of different objectives related to reachability sets when these operations are used. For the merging operation, i.e. global lockdown effect, we prove NP-hardness results for several minimization and maximization reachability objectives, even for very simple graph structures. For the second operation, independent delays, we prove that the minimization problems are NP-hard when the number of allowed delays is bounded. We complement this with a polynomial-time algorithm for minimising the reachability set in case of unbounded delays.
Spot The Bot: A Robust and Efficient Framework for the Evaluation of Conversational Dialogue Systems
Oct 05, 2020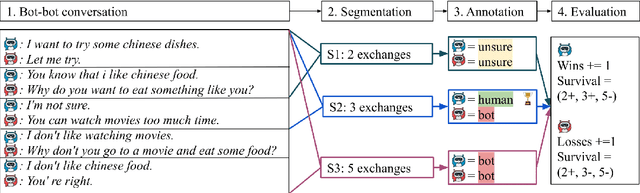
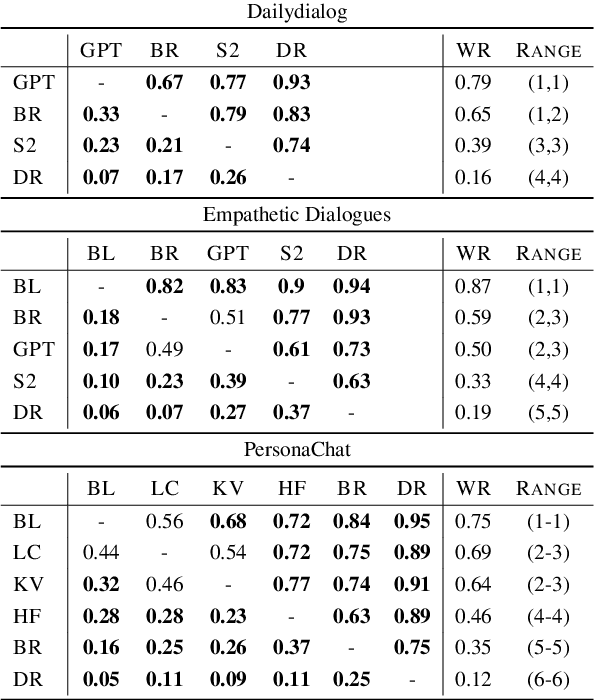
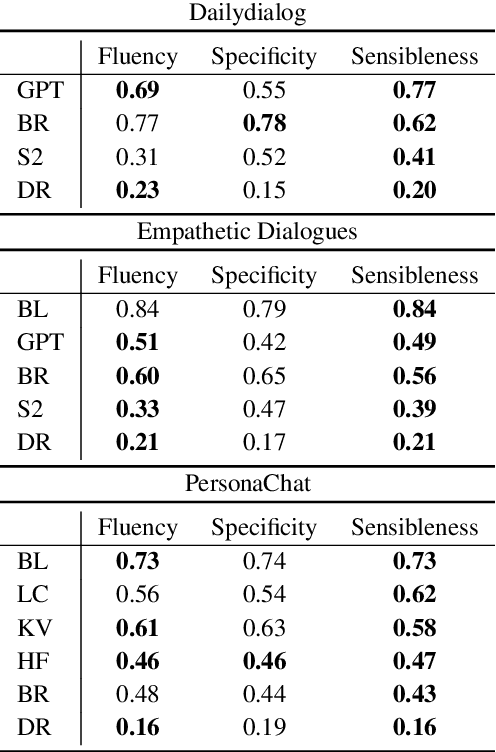
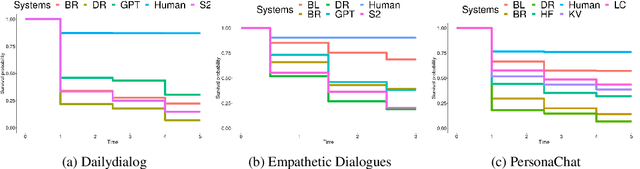
The lack of time-efficient and reliable evaluation methods hamper the development of conversational dialogue systems (chatbots). Evaluations requiring humans to converse with chatbots are time and cost-intensive, put high cognitive demands on the human judges, and yield low-quality results. In this work, we introduce \emph{Spot The Bot}, a cost-efficient and robust evaluation framework that replaces human-bot conversations with conversations between bots. Human judges then only annotate for each entity in a conversation whether they think it is human or not (assuming there are humans participants in these conversations). These annotations then allow us to rank chatbots regarding their ability to mimic the conversational behavior of humans. Since we expect that all bots are eventually recognized as such, we incorporate a metric that measures which chatbot can uphold human-like behavior the longest, i.e., \emph{Survival Analysis}. This metric has the ability to correlate a bot's performance to certain of its characteristics (e.g., \ fluency or sensibleness), yielding interpretable results. The comparably low cost of our framework allows for frequent evaluations of chatbots during their evaluation cycle. We empirically validate our claims by applying \emph{Spot The Bot} to three domains, evaluating several state-of-the-art chatbots, and drawing comparisons to related work. The framework is released as a ready-to-use tool.
Multi-view Human Pose and Shape Estimation Using Learnable Volumetric Aggregation
Nov 26, 2020
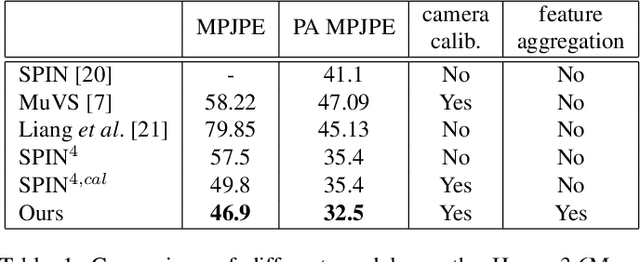
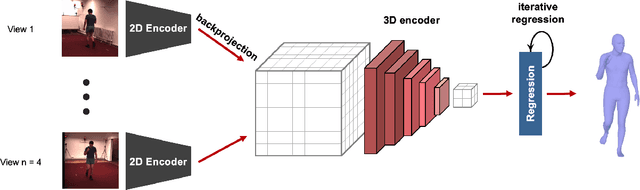
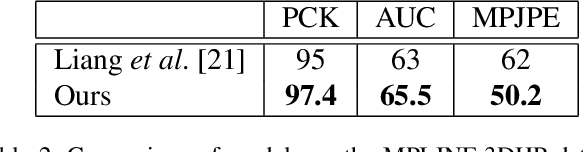
Human pose and shape estimation from RGB images is a highly sought after alternative to marker-based motion capture, which is laborious, requires expensive equipment, and constrains capture to laboratory environments. Monocular vision-based algorithms, however, still suffer from rotational ambiguities and are not ready for translation in healthcare applications, where high accuracy is paramount. While fusion of data from multiple viewpoints could overcome these challenges, current algorithms require further improvement to obtain clinically acceptable accuracies. In this paper, we propose a learnable volumetric aggregation approach to reconstruct 3D human body pose and shape from calibrated multi-view images. We use a parametric representation of the human body, which makes our approach directly applicable to medical applications. Compared to previous approaches, our framework shows higher accuracy and greater promise for real-time prediction, given its cost efficiency.