 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multiple Sclerosis Lesion Activity Segmentation with Attention-Guided Two-Path CNNs
Aug 05, 2020
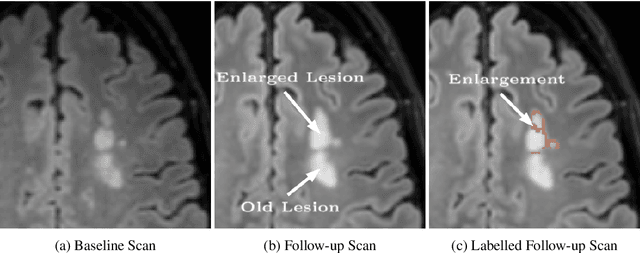
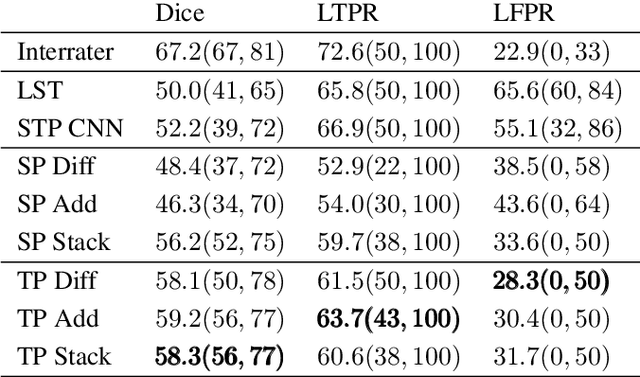
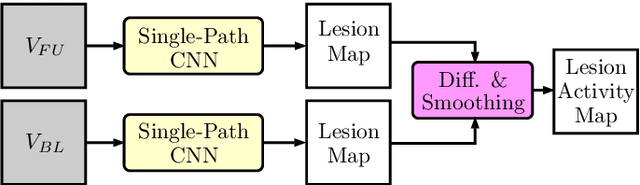
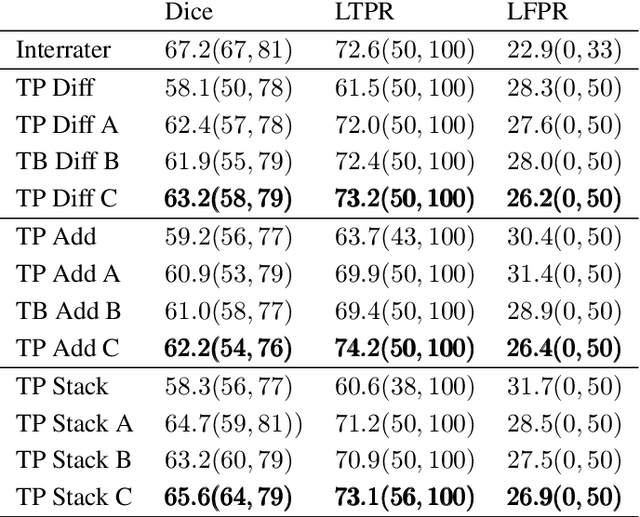
Multiple sclerosis is an inflammatory autoimmune demyelinating disease that is characterized by lesions in the central nervous system. Typically, magnetic resonance imaging (MRI) is used for tracking disease progression. Automatic image processing methods can be used to segment lesions and derive quantitative lesion parameters. So far, methods have focused on lesion segmentation for individual MRI scans. However, for monitoring disease progression, \textit{lesion activity} in terms of new and enlarging lesions between two time points is a crucial biomarker. For this problem, several classic methods have been proposed, e.g., using difference volumes. Despite their success for single-volume lesion segmentation, deep learning approaches are still rare for lesion activity segmentation. In this work, convolutional neural networks (CNNs) are studied for lesion activity segmentation from two time points. For this task, CNNs are designed and evaluated that combine the information from two points in different ways. In particular, two-path architectures with attention-guided interactions are proposed that enable effective information exchange between the two time point's processing paths. It is demonstrated that deep learning-based methods outperform classic approaches and it is shown that attention-guided interactions significantly improve performance. Furthermore, the attention modules produce plausible attention maps that have a masking effect that suppresses old, irrelevant lesions. A lesion-wise false positive rate of 26.4% is achieved at a true positive rate of 74.2%, which is not significantly different from the interrater performance.
Distributed Gaussian Learning over Time-varying Directed Graphs
Dec 07, 2016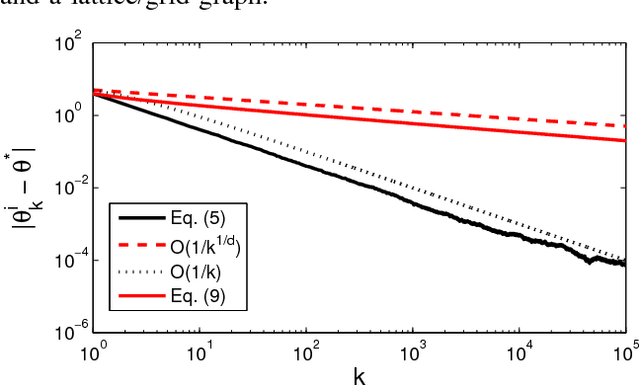
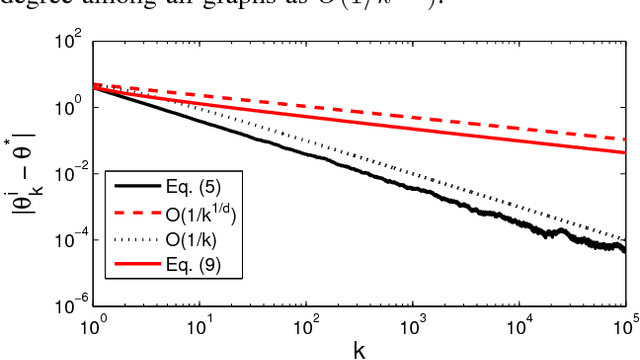
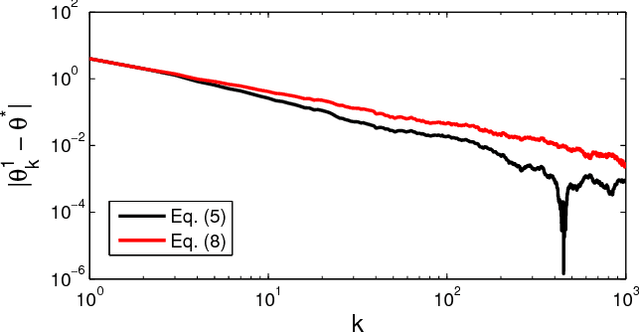
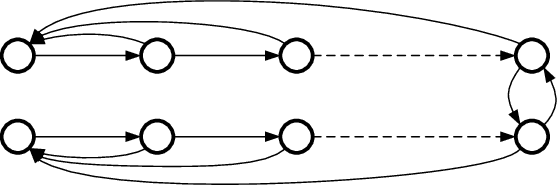
We present a distributed (non-Bayesian) learning algorithm for the problem of parameter estimation with Gaussian noise. The algorithm is expressed as explicit updates on the parameters of the Gaussian beliefs (i.e. means and precision). We show a convergence rate of $O(1/k)$ with the constant term depending on the number of agents and the topology of the network. Moreover, we show almost sure convergence to the optimal solution of the estimation problem for the general case of time-varying directed graphs.
Accelerated Large Batch Optimization of BERT Pretraining in 54 minutes
Jun 24, 2020


BERT has recently attracted a lot of attention in natural language understanding (NLU) and achieved state-of-the-art results in various NLU tasks. However, its success requires large deep neural networks and huge amount of data, which result in long training time and impede development progress. Using stochastic gradient methods with large mini-batch has been advocated as an efficient tool to reduce the training time. Along this line of research, LAMB is a prominent example that reduces the training time of BERT from 3 days to 76 minutes on a TPUv3 Pod. In this paper, we propose an accelerated gradient method called LANS to improve the efficiency of using large mini-batches for training. As the learning rate is theoretically upper bounded by the inverse of the Lipschitz constant of the function, one cannot always reduce the number of optimization iterations by selecting a larger learning rate. In order to use larger mini-batch size without accuracy loss, we develop a new learning rate scheduler that overcomes the difficulty of using large learning rate. Using the proposed LANS method and the learning rate scheme, we scaled up the mini-batch sizes to 96K and 33K in phases 1 and 2 of BERT pretraining, respectively. It takes 54 minutes on 192 AWS EC2 P3dn.24xlarge instances to achieve a target F1 score of 90.5 or higher on SQuAD v1.1, achieving the fastest BERT training time in the cloud.
Kinetics-Informed Neural Networks
Nov 30, 2020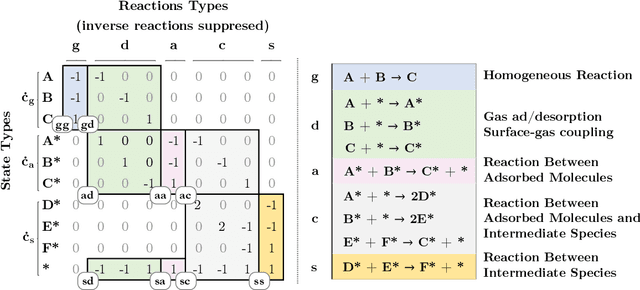
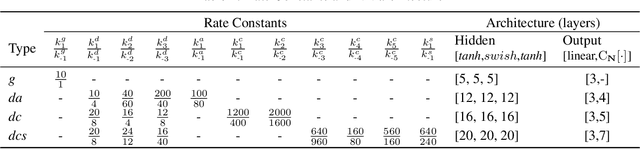
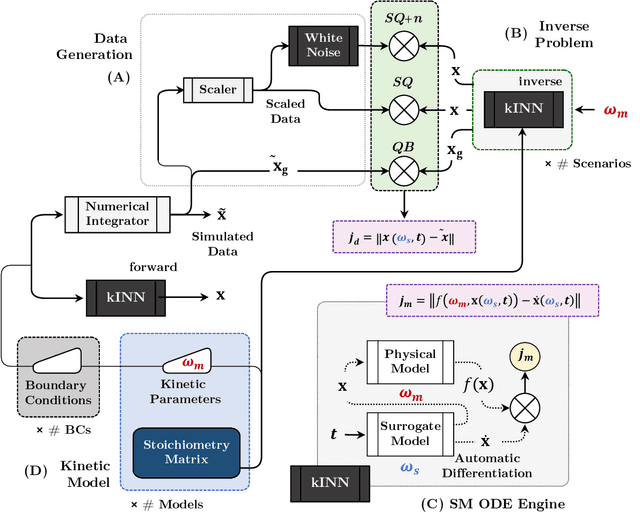
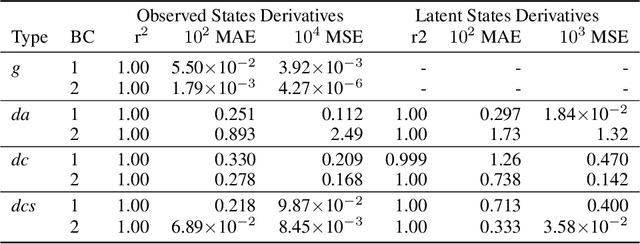
Chemical kinetics consists of the phenomenological framework for the disentanglement of reaction mechanisms, optimization of reaction performance and the rational design of chemical processes. Here, we utilize feed-forward artificial neural networks as basis functions for the construction of surrogate models to solve ordinary differential equations (ODEs) that describe microkinetic models (MKMs). We present an algebraic framework for the mathematical description and classification of reaction networks, types of elementary reaction, and chemical species. Under this framework, we demonstrate that the simultaneous training of neural nets and kinetic model parameters in a regularized multiobjective optimization setting leads to the solution of the inverse problem through the estimation of kinetic parameters from synthetic experimental data. We probe the limits at which kinetic parameters can be retrieved as a function of knowledge about the chemical system states over time, and assess the robustness of the methodology with respect to statistical noise. This surrogate approach to inverse kinetic ODEs can assist in the elucidation of reaction mechanisms based on transient data.
Large-Scale Generative Data-Free Distillation
Dec 10, 2020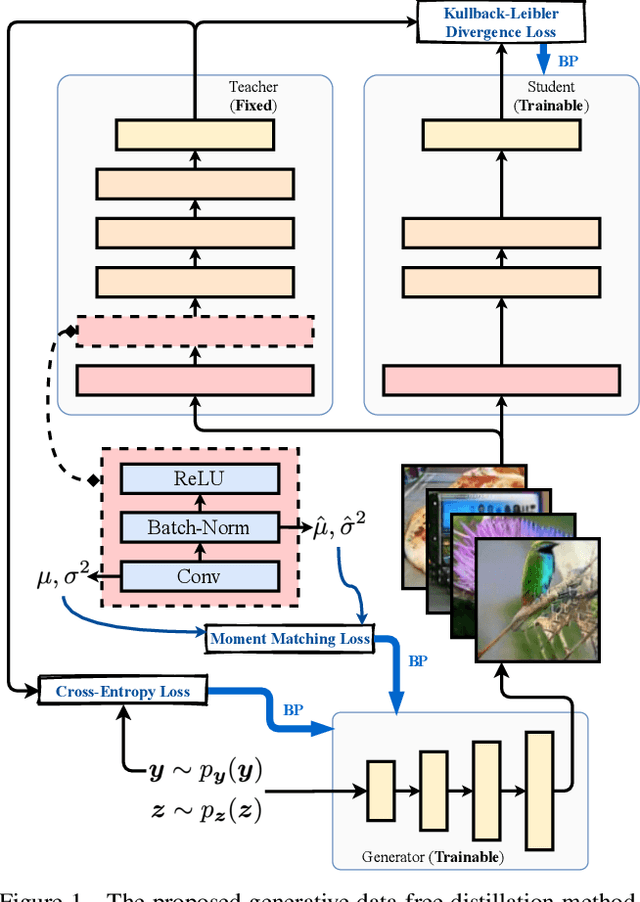
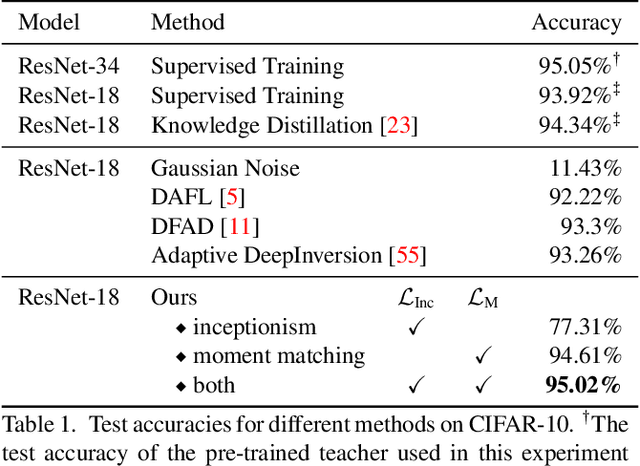

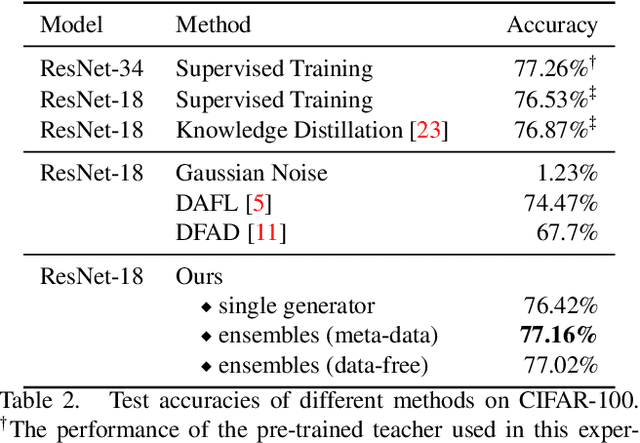
Knowledge distillation is one of the most popular and effective techniques for knowledge transfer, model compression and semi-supervised learning. Most existing distillation approaches require the access to original or augmented training samples. But this can be problematic in practice due to privacy, proprietary and availability concerns. Recent work has put forward some methods to tackle this problem, but they are either highly time-consuming or unable to scale to large datasets. To this end, we propose a new method to train a generative image model by leveraging the intrinsic normalization layers' statistics of the trained teacher network. This enables us to build an ensemble of generators without training data that can efficiently produce substitute inputs for subsequent distillation. The proposed method pushes forward the data-free distillation performance on CIFAR-10 and CIFAR-100 to 95.02% and 77.02% respectively. Furthermore, we are able to scale it to ImageNet dataset, which to the best of our knowledge, has never been done using generative models in a data-free setting.
Decentralized Safe Reactive Planning under TWTL Specifications
Jul 23, 2020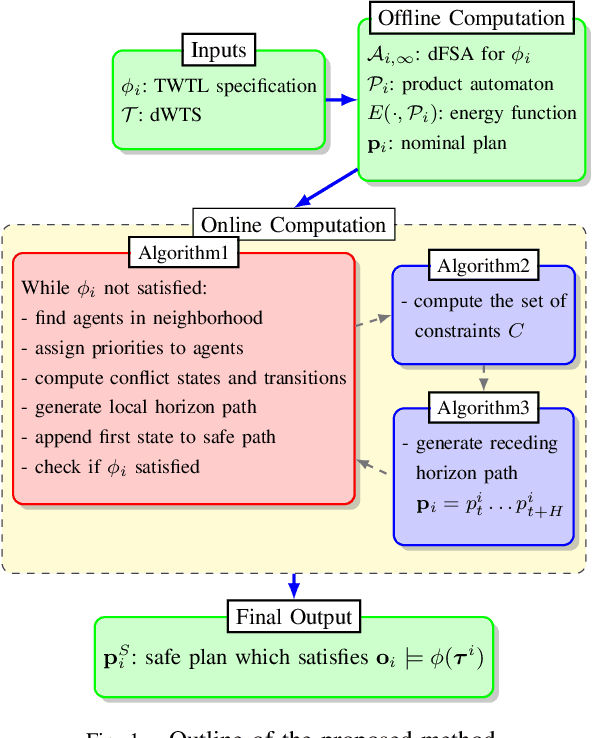
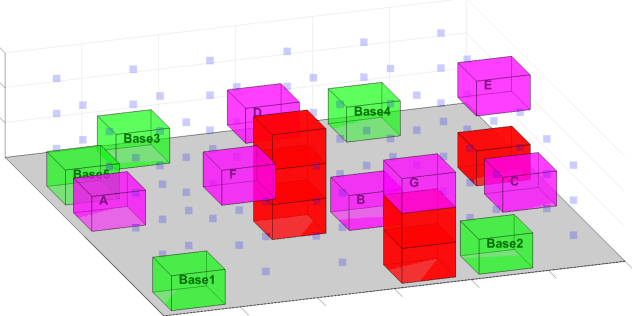


We investigate a multi-agent planning problem, where each agent aims to achieve an individual task while avoiding collisions with others. We assume that each agent's task is expressed as a Time-Window Temporal Logic (TWTL) specification defined over a 3D environment. We propose a decentralized receding horizon algorithm for online planning of trajectories. We show that when the environment is sufficiently connected, the resulting agent trajectories are always safe (collision-free) and lead to the satisfaction of the TWTL specifications or their finite temporal relaxations. Accordingly, deadlocks are always avoided and each agent is guaranteed to safely achieve its task with a finite time-delay in the worst case. Performance of the proposed algorithm is demonstrated via numerical simulations and experiments with quadrotors.
Recurrence of Optimum for Training Weight and Activation Quantized Networks
Dec 10, 2020


Deep neural networks (DNNs) are quantized for efficient inference on resource-constrained platforms. However, training deep learning models with low-precision weights and activations involves a demanding optimization task, which calls for minimizing a stage-wise loss function subject to a discrete set-constraint. While numerous training methods have been proposed, existing studies for full quantization of DNNs are mostly empirical. From a theoretical point of view, we study practical techniques for overcoming the combinatorial nature of network quantization. Specifically, we investigate a simple yet powerful projected gradient-like algorithm for quantizing two-linear-layer networks, which proceeds by repeatedly moving one step at float weights in the negation of a heuristic \emph{fake} gradient of the loss function (so-called coarse gradient) evaluated at quantized weights. For the first time, we prove that under mild conditions, the sequence of quantized weights recurrently visits the global optimum of the discrete minimization problem for training fully quantized network. We also show numerical evidence of the recurrence phenomenon of weight evolution in training quantized deep networks.
Auto-calibration Method Using Stop Signs for Urban Autonomous Driving Applications
Oct 14, 2020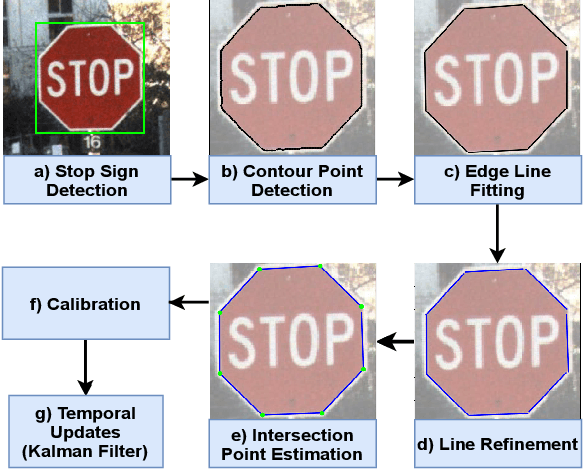
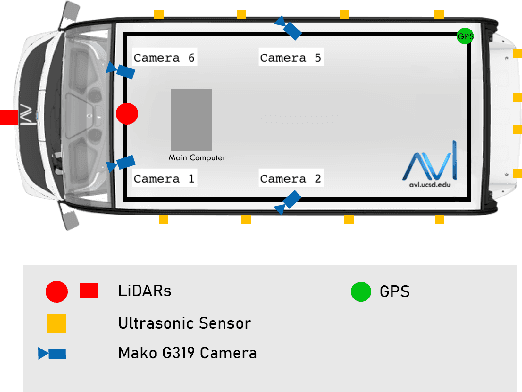
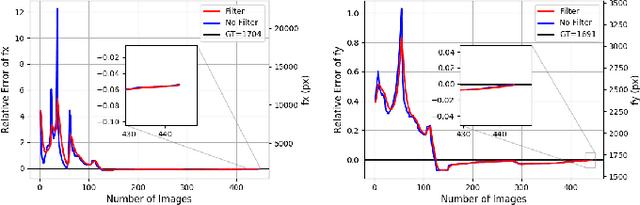
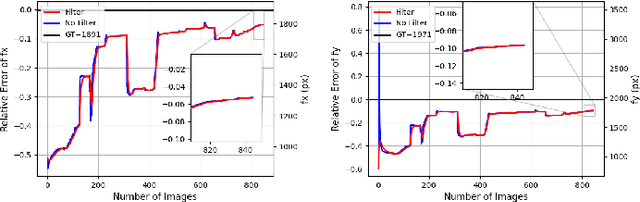
For use of cameras on an intelligent vehicle, driving over a major bump could challenge the calibration. It is then of interest to do dynamic calibration. What structures can be used for calibration? How about using traffic signs that you recognize? In this paper an approach is presented for dynamic camera calibration based on recognition of stop signs. The detection is performed based on convolutional neural networks (CNNs). A recognized sign is modeled as a polygon and matched to a model. Parameters are tracked over time. Experimental results show clear convergence and improved performance for the calibration.
Online Active Proposal Set Generation for Weakly Supervised Object Detection
Jan 20, 2021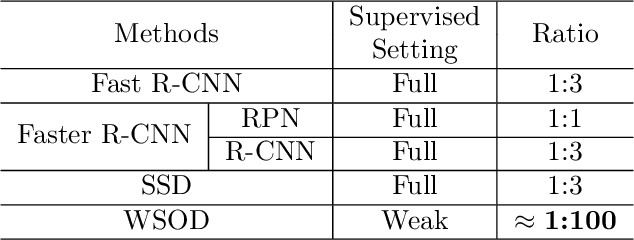

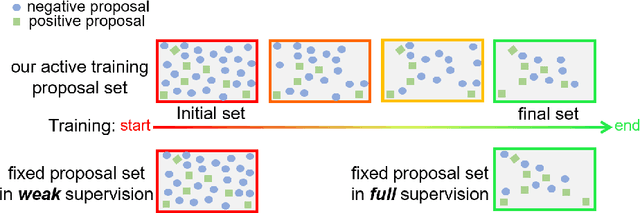
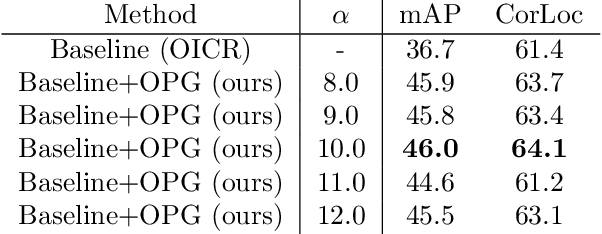
To reduce the manpower consumption on box-level annotations, many weakly supervised object detection methods which only require image-level annotations, have been proposed recently. The training process in these methods is formulated into two steps. They firstly train a neural network under weak supervision to generate pseudo ground truths (PGTs). Then, these PGTs are used to train another network under full supervision. Compared with fully supervised methods, the training process in weakly supervised methods becomes more complex and time-consuming. Furthermore, overwhelming negative proposals are involved at the first step. This is neglected by most methods, which makes the training network biased towards to negative proposals and thus degrades the quality of the PGTs, limiting the training network performance at the second step. Online proposal sampling is an intuitive solution to these issues. However, lacking of adequate labeling, a simple online proposal sampling may make the training network stuck into local minima. To solve this problem, we propose an Online Active Proposal Set Generation (OPG) algorithm. Our OPG algorithm consists of two parts: Dynamic Proposal Constraint (DPC) and Proposal Partition (PP). DPC is proposed to dynamically determine different proposal sampling strategy according to the current training state. PP is used to score each proposal, part proposals into different sets and generate an active proposal set for the network optimization. Through experiments, our proposed OPG shows consistent and significant improvement on both datasets PASCAL VOC 2007 and 2012, yielding comparable performance to the state-of-the-art results.
Monocular Depth Estimation for Soft Visuotactile Sensors
Jan 05, 2021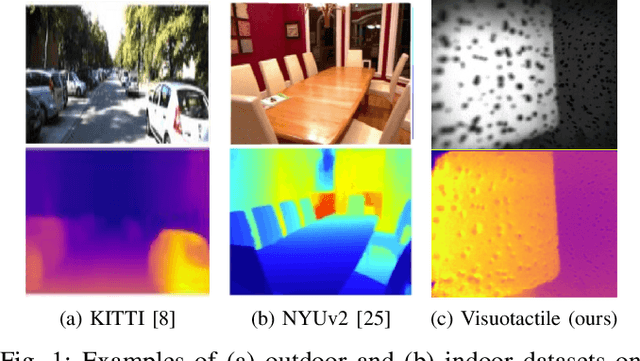
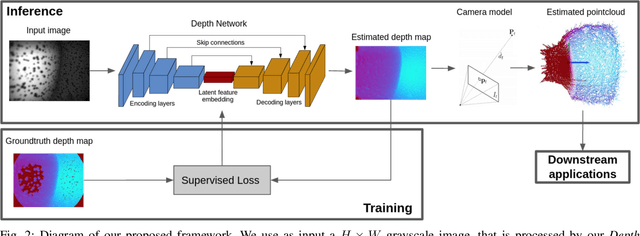


Fluid-filled soft visuotactile sensors such as the Soft-bubbles alleviate key challenges for robust manipulation, as they enable reliable grasps along with the ability to obtain high-resolution sensory feedback on contact geometry and forces. Although they are simple in construction, their utility has been limited due to size constraints introduced by enclosed custom IR/depth imaging sensors to directly measure surface deformations. Towards mitigating this limitation, we investigate the application of state-of-the-art monocular depth estimation to infer dense internal (tactile) depth maps directly from the internal single small IR imaging sensor. Through real-world experiments, we show that deep networks typically used for long-range depth estimation (1-100m) can be effectively trained for precise predictions at a much shorter range (1-100mm) inside a mostly textureless deformable fluid-filled sensor. We propose a simple supervised learning process to train an object-agnostic network requiring less than 10 random poses in contact for less than 10 seconds for a small set of diverse objects (mug, wine glass, box, and fingers in our experiments). We show that our approach is sample-efficient, accurate, and generalizes across different objects and sensor configurations unseen at training time. Finally, we discuss the implications of our approach for the design of soft visuotactile sensors and grippers.