 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving the Efficiency of Grammatical Error Correction with Erroneous Span Detection and Correction
Oct 07, 2020
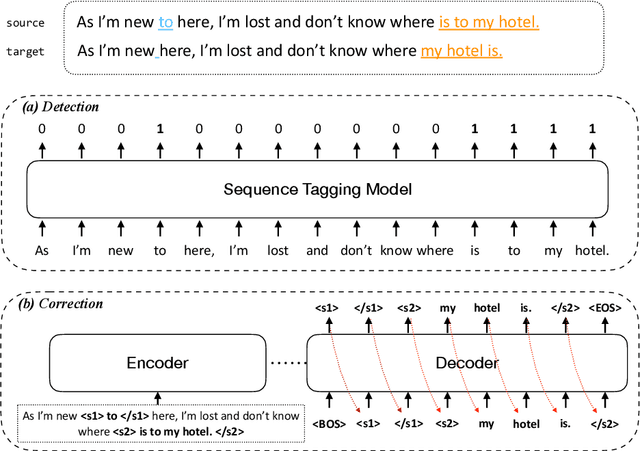
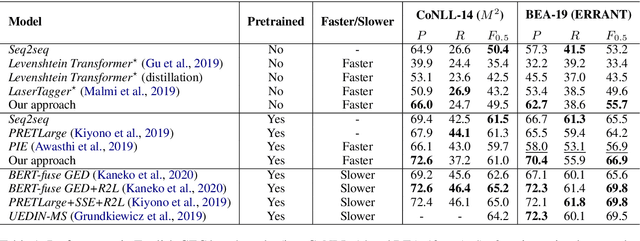

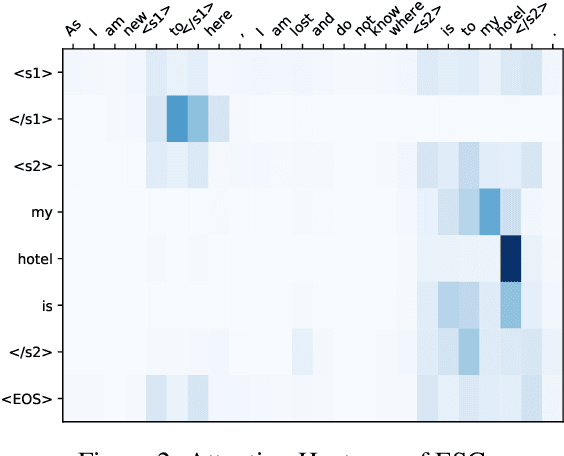
We propose a novel language-independent approach to improve the efficiency for Grammatical Error Correction (GEC) by dividing the task into two subtasks: Erroneous Span Detection (ESD) and Erroneous Span Correction (ESC). ESD identifies grammatically incorrect text spans with an efficient sequence tagging model. Then, ESC leverages a seq2seq model to take the sentence with annotated erroneous spans as input and only outputs the corrected text for these spans. Experiments show our approach performs comparably to conventional seq2seq approaches in both English and Chinese GEC benchmarks with less than 50% time cost for inference.
Initial condition assessment for reaction-diffusion glioma growth models: A translational MRI/histology (in)validation study
Feb 02, 2021
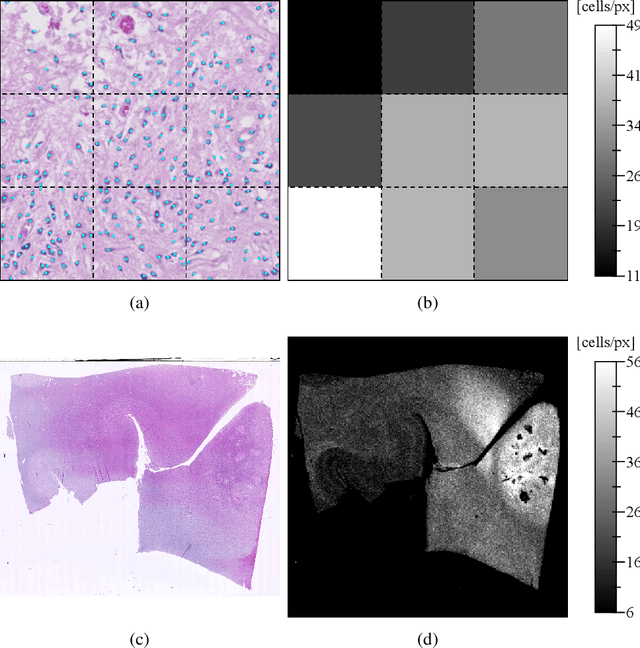

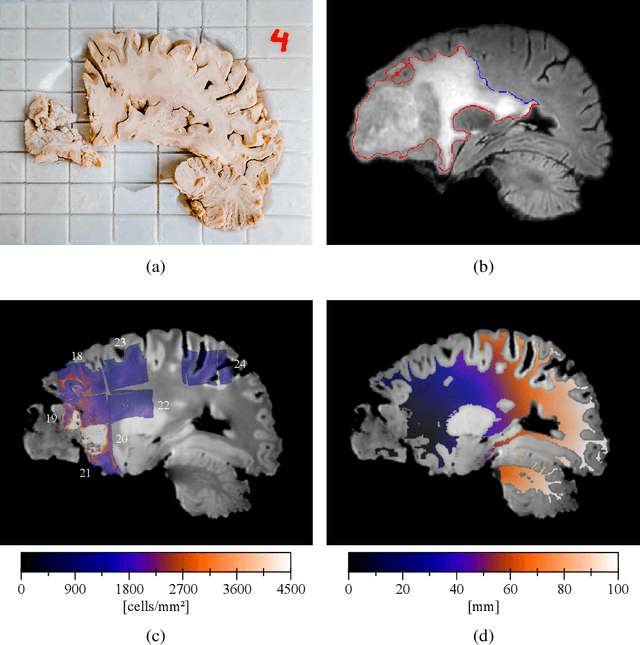
Diffuse gliomas are highly infiltrative tumors whose early diagnosis and follow-up usually rely on magnetic resonance imaging (MRI). However, the limited sensitivity of this technique makes it impossible to directly assess the extent of the glioma cell invasion, leading to sub-optimal treatment planing. Reaction-diffusion growth models have been proposed for decades to extrapolate glioma cell infiltration beyond margins visible on MRI and predict its spatial-temporal evolution. These models nevertheless require an initial condition, that is the tumor cell density values at every location of the brain at diagnosis time. Several works have proposed to relate the tumor cell density function to abnormality outlines visible on MRI but the underlying assumptions have never been verified so far. In this work we propose to verify these assumptions by stereotactic histological analysis of a non-operated brain with glioblastoma using a tailored 3D-printed slicer. Cell density maps are computed from histological slides using a deep learning approach. The density maps are then registered to a postmortem MR image and related to an MR-derived geodesic distance map to the tumor core. The relation between the edema outlines visible on T2 FLAIR MRI and the distance to the core is also investigated. Our results suggest that (i) the previously suggested exponential decrease of the tumor cell density with the distance to the tumor core is not unreasonable but (ii) the edema outlines may in general not correspond to a cell density iso-contour and (iii) the commonly adopted tumor cell density value at these outlines is likely overestimated. These findings highlight the limitations of using conventional MRI to derive glioma cell density maps and point out the need of validating other methods to initialize reaction-diffusion growth models and make them usable in clinical practice.
Neural Dynamic Mode Decomposition for End-to-End Modeling of Nonlinear Dynamics
Dec 11, 2020

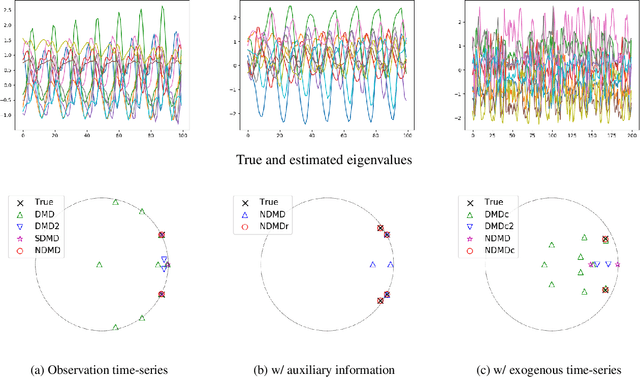
Koopman spectral analysis has attracted attention for understanding nonlinear dynamical systems by which we can analyze nonlinear dynamics with a linear regime by lifting observations using a nonlinear function. For analysis, we need to find an appropriate lift function. Although several methods have been proposed for estimating a lift function based on neural networks, the existing methods train neural networks without spectral analysis. In this paper, we propose neural dynamic mode decomposition, in which neural networks are trained such that the forecast error is minimized when the dynamics is modeled based on spectral decomposition in the lifted space. With our proposed method, the forecast error is backpropagated through the neural networks and the spectral decomposition, enabling end-to-end learning of Koopman spectral analysis. When information is available on the frequencies or the growth rates of the dynamics, the proposed method can exploit it as regularizers for training. We also propose an extension of our approach when observations are influenced by exogenous control time-series. Our experiments demonstrate the effectiveness of our proposed method in terms of eigenvalue estimation and forecast performance.
Hybrid Beamforming for Terahertz Wireless Communications: Challenges, Architectures, and Open Problems
Jan 21, 2021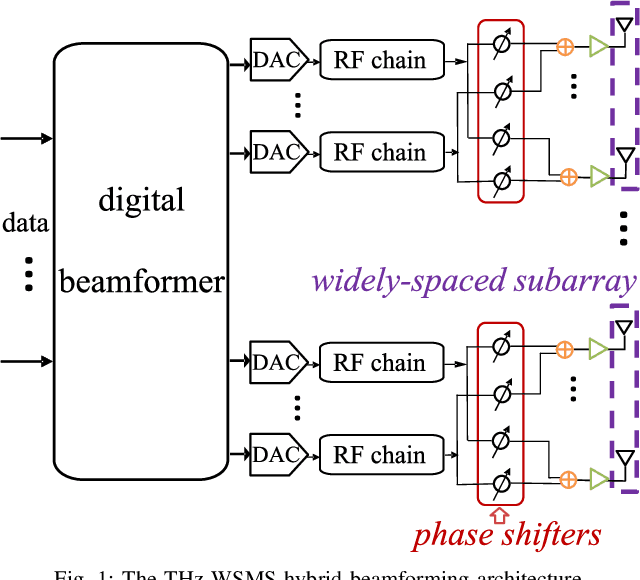
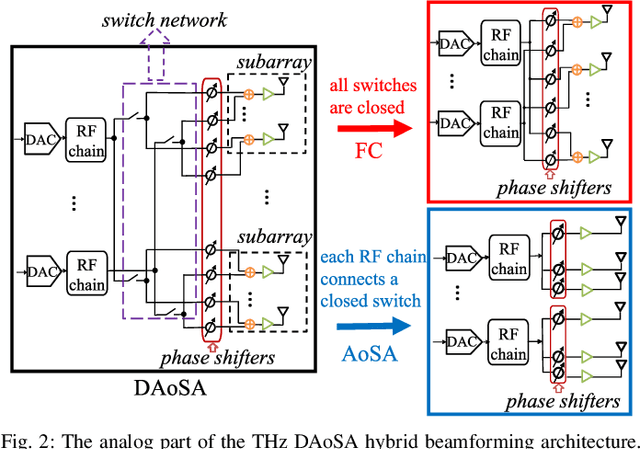
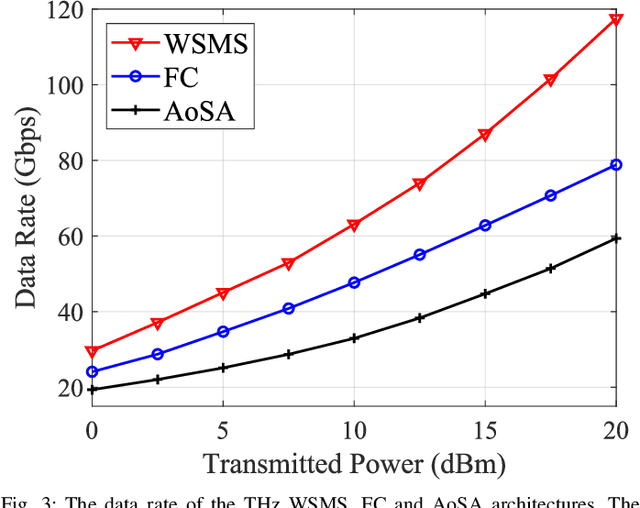
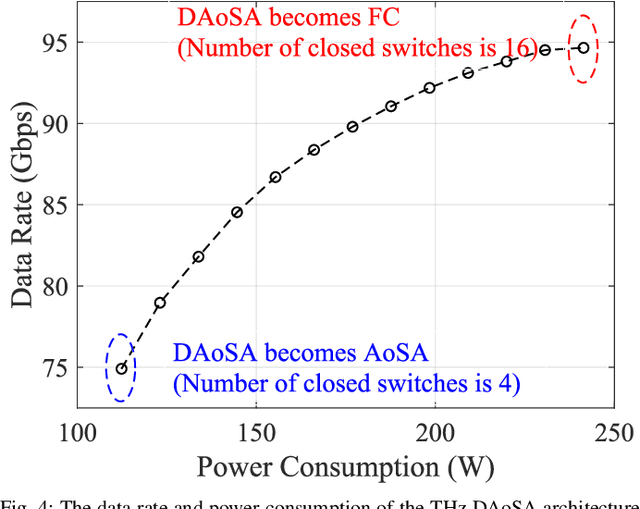
Terahertz (THz) communications are regarded as a pillar technology for the sixth generation (6G) wireless systems, by offering multi-ten-GHz bandwidth. To overcome the short transmission distance and huge propagation loss, ultra-massive (UM) MIMO systems that employ sub-millimeter wavelength antennas array are proposed to enable an enticingly high array gain. In the UM-MIMO systems, hybrid beamforming stands out for its great potential in promisingly high data rate and reduced power consumption. In this paper, challenges and features of the THz hybrid beamforming design are investigated, in light of the distinctive THz peculiarities. Specifically, we demonstrate that the spatial degree-of-freedom (SDoF) is less than 5, which is caused by the extreme sparsity of the THz channel. The blockage problem caused by the huge reflection and scattering losses, as high as 15 dB or over, is studied. Moreover, we analyze the challenges led by the array containing 1024 or more antennas, including the requirement for intelligent subarray architecture, strict energy efficiency, and propagation characterization based on spherical-wave propagation mechanisms. Owning up to hundreds of GHz bandwidth, beam squint effect could cause over 5~dB array gain loss, when the fractional bandwidth exceeds 10%. Inspired by these facts, three novel THz-specific hybrid beamforming architectures are presented, including widely-spaced multi-subarray, dynamic array-of-subarrays, and true-time-delay-based architectures. We also demonstrate the potential data rate, power consumption, and array gain capabilities for THz communications. As a roadmap of THz hybrid beamforming design, multiple open problems and potential research directions are elaborated.
C-Watcher: A Framework for Early Detection of High-Risk Neighborhoods Ahead of COVID-19 Outbreak
Jan 27, 2021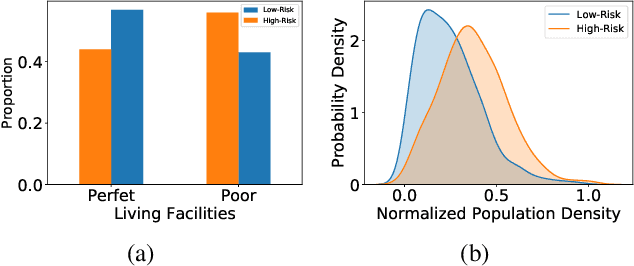
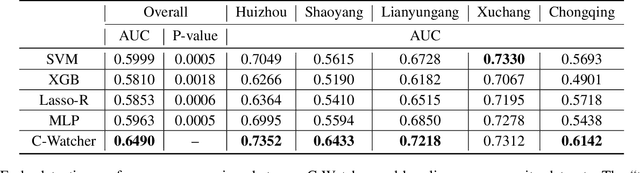
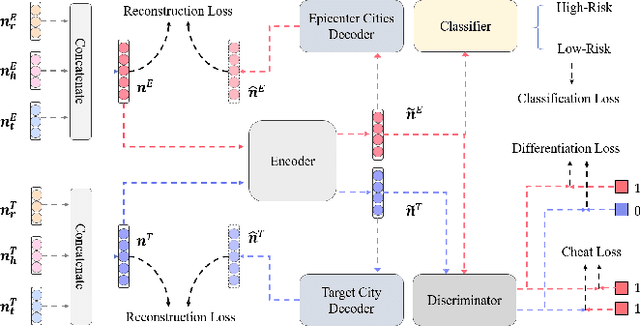
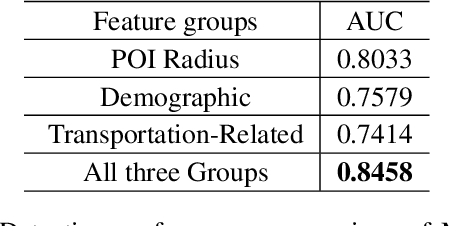
The novel coronavirus disease (COVID-19) has crushed daily routines and is still rampaging through the world. Existing solution for nonpharmaceutical interventions usually needs to timely and precisely select a subset of residential urban areas for containment or even quarantine, where the spatial distribution of confirmed cases has been considered as a key criterion for the subset selection. While such containment measure has successfully stopped or slowed down the spread of COVID-19 in some countries, it is criticized for being inefficient or ineffective, as the statistics of confirmed cases are usually time-delayed and coarse-grained. To tackle the issues, we propose C-Watcher, a novel data-driven framework that aims at screening every neighborhood in a target city and predicting infection risks, prior to the spread of COVID-19 from epicenters to the city. In terms of design, C-Watcher collects large-scale long-term human mobility data from Baidu Maps, then characterizes every residential neighborhood in the city using a set of features based on urban mobility patterns. Furthermore, to transfer the firsthand knowledge (witted in epicenters) to the target city before local outbreaks, we adopt a novel adversarial encoder framework to learn "city-invariant" representations from the mobility-related features for precise early detection of high-risk neighborhoods, even before any confirmed cases known, in the target city. We carried out extensive experiments on C-Watcher using the real-data records in the early stage of COVID-19 outbreaks, where the results demonstrate the efficiency and effectiveness of C-Watcher for early detection of high-risk neighborhoods from a large number of cities.
Learning from Incremental Directional Corrections
Nov 30, 2020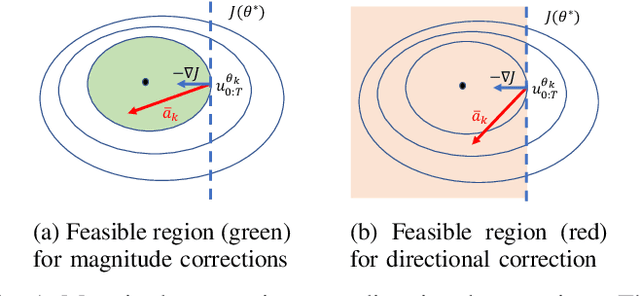
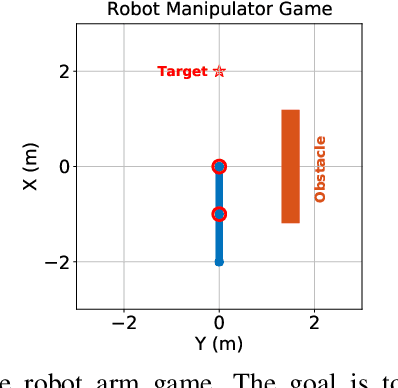
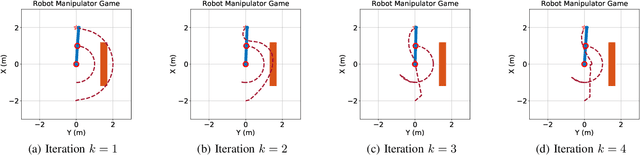
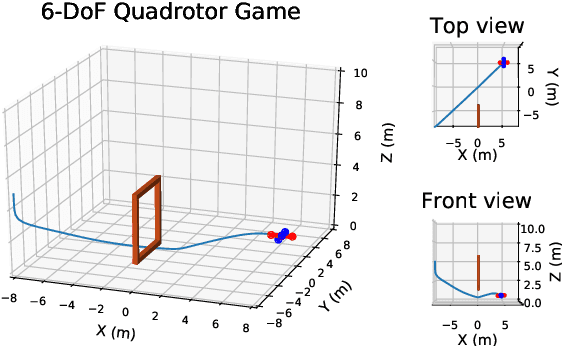
This paper proposes a technique which enables a robot to learn a control objective function incrementally from human user's corrections. The human's corrections can be as simple as directional corrections -- corrections that indicate the direction of a control change without indicating its magnitude -- applied at some time instances during the robot's motion. We only assume that each of the human's corrections, regardless of its magnitude, points in a direction that improves the robot's current motion relative to an implicit objective function. The proposed method uses the direction of a correction to update the estimate of the objective function based on a cutting plane technique. We establish the theoretical results to show that this process of incremental correction and update guarantees convergence of the learned objective function to the implicit one. The method is validated by both simulations and two human-robot games, where human players teach a 2-link robot arm and a 6-DoF quadrotor system for motion planning in environments with obstacles.
Multi-stage Speaker Extraction with Utterance and Frame-Level Reference Signals
Nov 19, 2020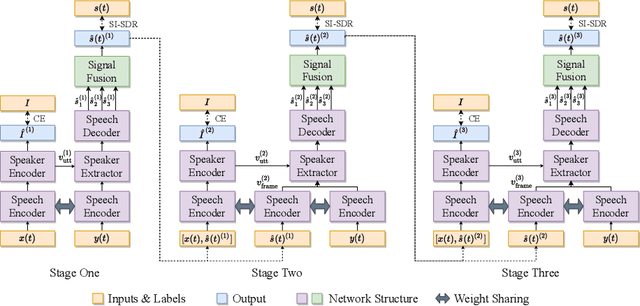
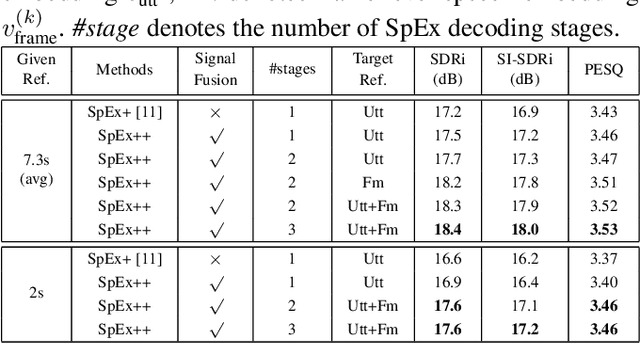
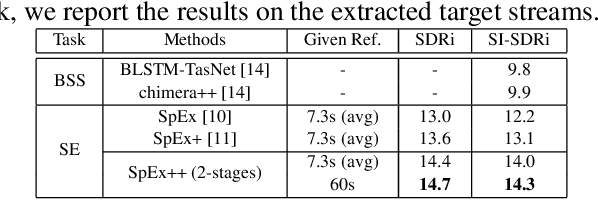
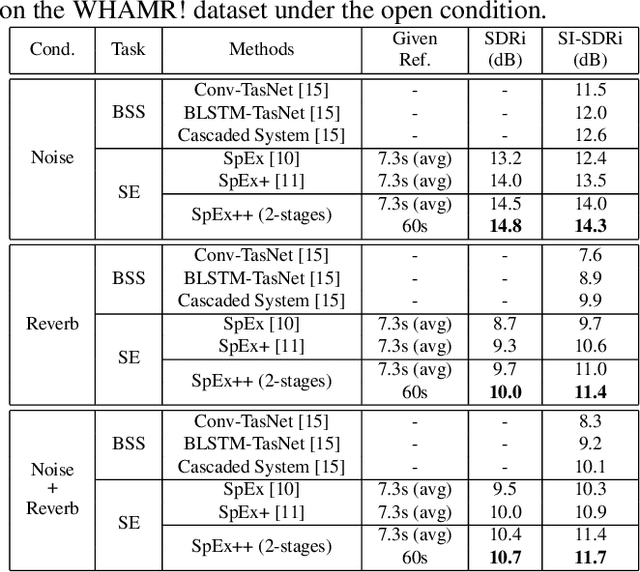
Speaker extraction uses a pre-recorded reference speech as the reference signal for target speaker extraction. In real-world applications, enrolling a speaker with a long speech is not practical. We propose a speaker extraction technique, that performs in multiple stages to take full advantage of short reference speech sample. The extracted speech in early stages is used as the reference speech for late stages. Furthermore, for the first time, we use frame-level sequential speech embedding as the reference for target speaker. This is a departure from the traditional utterance-based speaker embedding reference. In addition, a signal fusion scheme is proposed to combine the decoded signals in multiple scales with automatically learned weights. Experiments on WSJ0-2mix and its noisy versions (WHAM! and WHAMR!) show that SpEx++ consistently outperforms other state-of-the-art baselines.
Scalable Graph Networks for Particle Simulations
Oct 14, 2020Learning system dynamics directly from observations is a promising direction in machine learning due to its potential to significantly enhance our ability to understand physical systems. However, the dynamics of many real-world systems are challenging to learn due to the presence of nonlinear potentials and a number of interactions that scales quadratically with the number of particles $N$, as in the case of the N-body problem. In this work, we introduce an approach that transforms a fully-connected interaction graph into a hierarchical one which reduces the number of edges to $O(N)$. This results in linear time and space complexity while the pre-computation of the hierarchical graph requires $O(N\log (N))$ time and $O(N)$ space. Using our approach, we are able to train models on much larger particle counts, even on a single GPU. We evaluate how the phase space position accuracy and energy conservation depend on the number of simulated particles. Our approach retains high accuracy and efficiency even on large-scale gravitational N-body simulations which are impossible to run on a single machine if a fully-connected graph is used. Similar results are also observed when simulating Coulomb interactions. Furthermore, we make several important observations regarding the performance of this new hierarchical model, including: i) its accuracy tends to improve with the number of particles in the simulation and ii) its generalisation to unseen particle counts is also much better than for models that use all $O(N^2)$ interactions.
Improving the Robustness of Trading Strategy Backtesting with Boltzmann Machines and Generative Adversarial Networks
Jul 09, 2020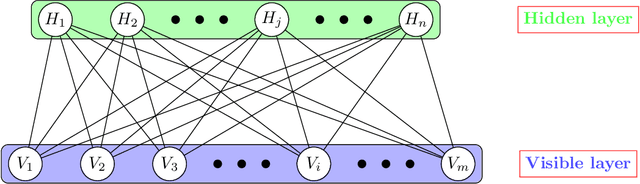
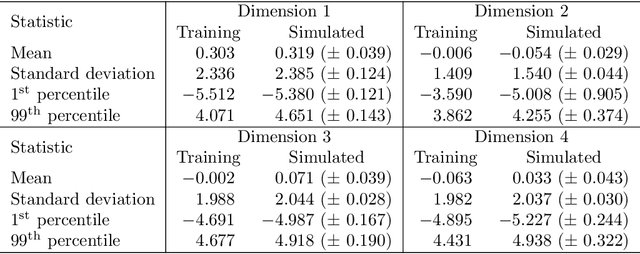
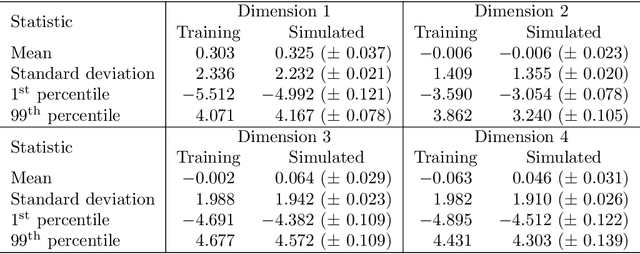
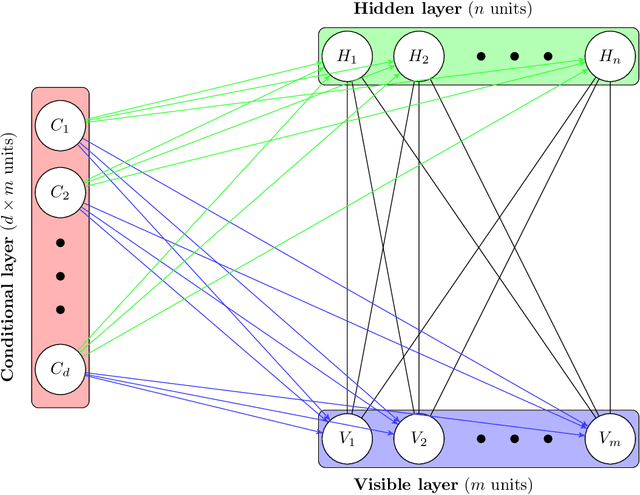
This article explores the use of machine learning models to build a market generator. The underlying idea is to simulate artificial multi-dimensional financial time series, whose statistical properties are the same as those observed in the financial markets. In particular, these synthetic data must preserve the probability distribution of asset returns, the stochastic dependence between the different assets and the autocorrelation across time. The article proposes then a new approach for estimating the probability distribution of backtest statistics. The final objective is to develop a framework for improving the risk management of quantitative investment strategies, in particular in the space of smart beta, factor investing and alternative risk premia.
A Stochastic Path-Integrated Differential EstimatoR Expectation Maximization Algorithm
Nov 30, 2020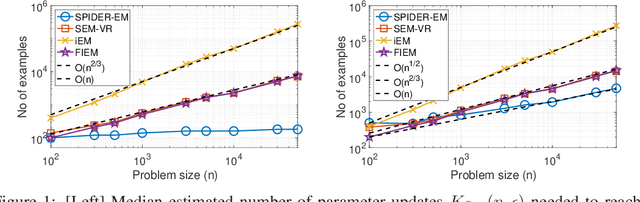

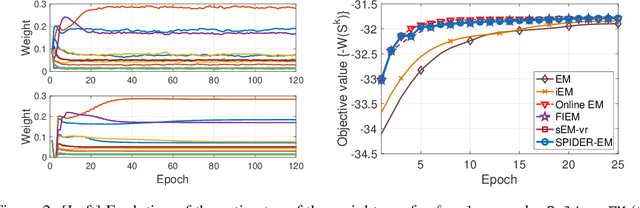
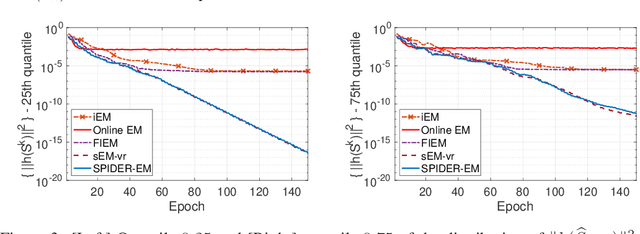
The Expectation Maximization (EM) algorithm is of key importance for inference in latent variable models including mixture of regressors and experts, missing observations. This paper introduces a novel EM algorithm, called \texttt{SPIDER-EM}, for inference from a training set of size $n$, $n \gg 1$. At the core of our algorithm is an estimator of the full conditional expectation in the {\sf E}-step, adapted from the stochastic path-integrated differential estimator ({\tt SPIDER}) technique. We derive finite-time complexity bounds for smooth non-convex likelihood: we show that for convergence to an $\epsilon$-approximate stationary point, the complexity scales as $K_{\operatorname{Opt}} (n,\epsilon )={\cal O}(\epsilon^{-1})$ and $K_{\operatorname{CE}}( n,\epsilon ) = n+ \sqrt{n} {\cal O}(\epsilon^{-1} )$, where $K_{\operatorname{Opt}}( n,\epsilon )$ and $K_{\operatorname{CE}}(n, \epsilon )$ are respectively the number of {\sf M}-steps and the number of per-sample conditional expectations evaluations. This improves over the state-of-the-art algorithms. Numerical results support our findings.