 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
QUBO Formulations for Training Machine Learning Models
Aug 05, 2020
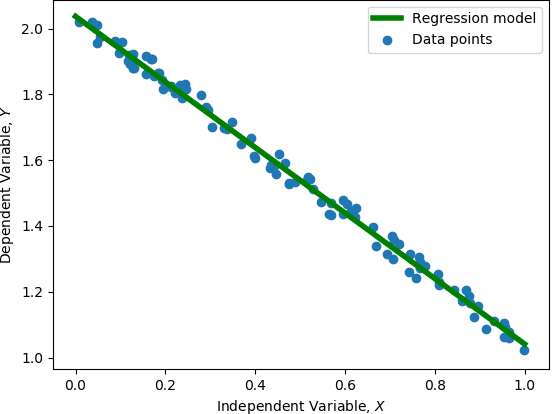
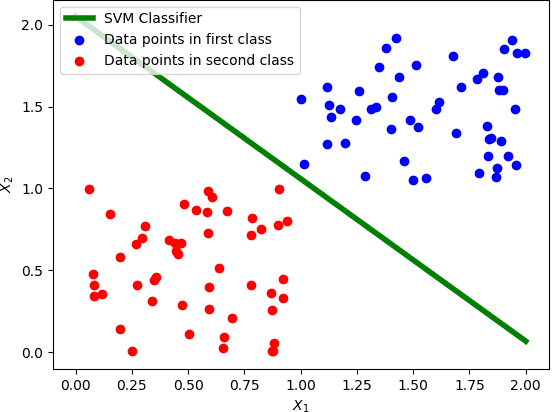
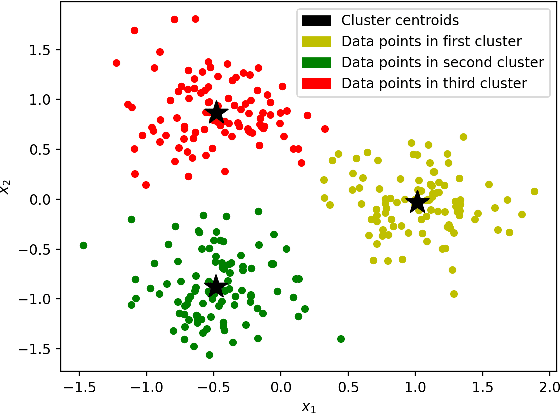
Training machine learning models on classical computers is usually a time and compute intensive process. With Moore's law coming to an end and ever increasing demand for large-scale data analysis using machine learning, we must leverage non-conventional computing paradigms like quantum computing to train machine learning models efficiently. Adiabatic quantum computers like the D-Wave 2000Q can approximately solve NP-hard optimization problems, such as the quadratic unconstrained binary optimization (QUBO), faster than classical computers. Since many machine learning problems are also NP-hard, we believe adiabatic quantum computers might be instrumental in training machine learning models efficiently in the post Moore's law era. In order to solve a problem on adiabatic quantum computers, it must be formulated as a QUBO problem, which is a challenging task in itself. In this paper, we formulate the training problems of three machine learning models---linear regression, support vector machine (SVM) and equal-sized k-means clustering---as QUBO problems so that they can be trained on adiabatic quantum computers efficiently. We also analyze the time and space complexities of our formulations and compare them to the state-of-the-art classical algorithms for training these machine learning models. We show that the time and space complexities of our formulations are better (in the case of SVM and equal-sized k-means clustering) or equivalent (in case of linear regression) to their classical counterparts.
NeuralFusion: Online Depth Fusion in Latent Space
Nov 30, 2020
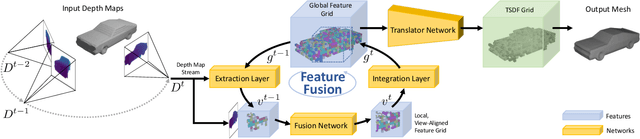
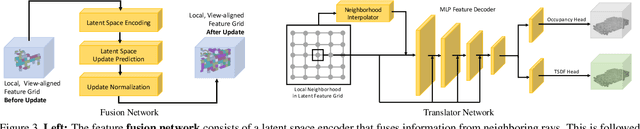
We present a novel online depth map fusion approach that learns depth map aggregation in a latent feature space. While previous fusion methods use an explicit scene representation like signed distance functions (SDFs), we propose a learned feature representation for the fusion. The key idea is a separation between the scene representation used for the fusion and the output scene representation, via an additional translator network. Our neural network architecture consists of two main parts: a depth and feature fusion sub-network, which is followed by a translator sub-network to produce the final surface representation (e.g. TSDF) for visualization or other tasks. Our approach is real-time capable, handles high noise levels, and is particularly able to deal with gross outliers common for photometric stereo-based depth maps. Experiments on real and synthetic data demonstrate improved results compared to the state of the art, especially in challenging scenarios with large amounts of noise and outliers.
Learning To Find Shortest Collision-Free Paths From Images
Nov 30, 2020
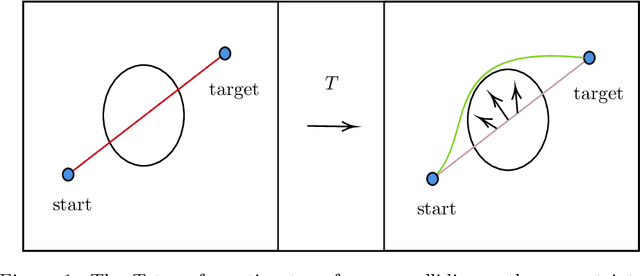


Motion planning is a fundamental problem in robotics and machine perception. Sampling-based planners find accurate solutions by exhaustively exploring the space, but are inefficient and tend to produce jerky motions. Optimization and learning-based planners are more efficient and produce smooth trajectories. However, a significant hurdle that these approaches face is constructing a differentiable cost function that simultaneously minimizes path length and avoids collisions. These two objectives are conflicting by nature -- path length is continuous and well-behaved, but collisions are discrete non-differentiable events. Reconciling these terms has been a significant challenge in optimization-based motion planning. The main contribution of this paper is a novel cost function that guarantees collision-free shortest paths are found at its minimum. We show that our approach works seamlessly with RGBD input and predicts high-quality paths in 2D, 3D, and 6 DoF robotic manipulator settings. Our method also reduces training and inference time compared to existing approaches, in some cases by orders of magnitude.
Leveraging Multiple Environments for Learning and Decision Making: a Dismantling Use Case
Sep 18, 2020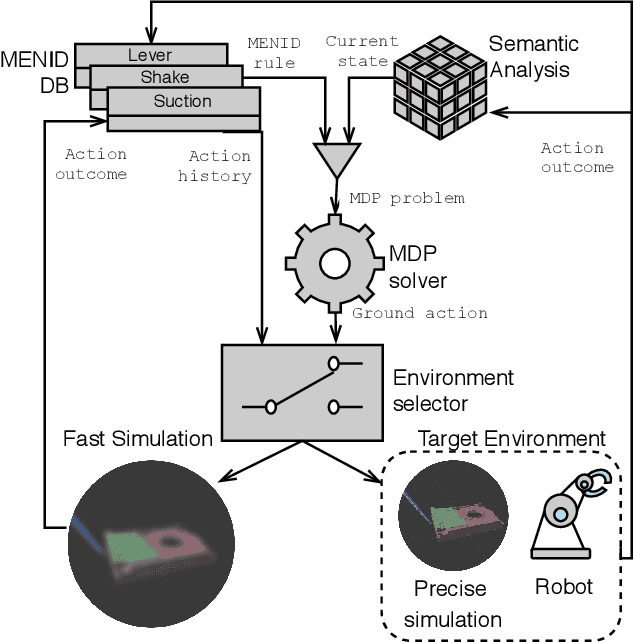
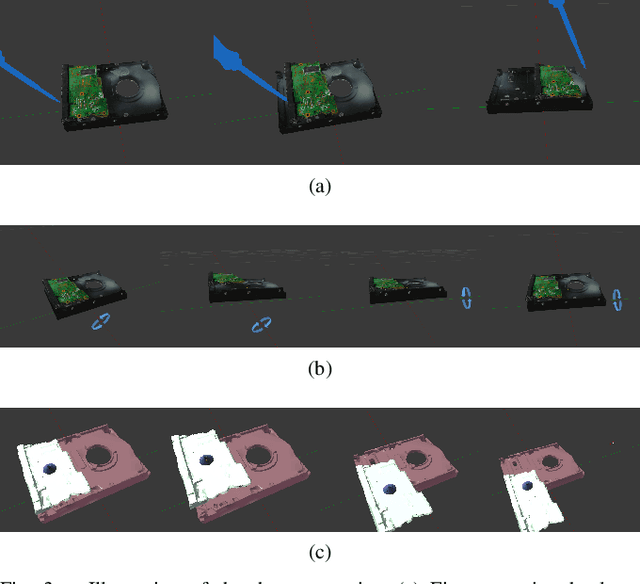
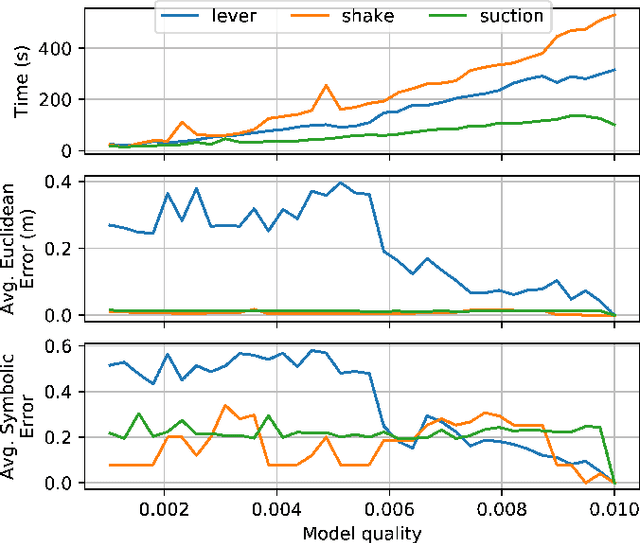
Learning is usually performed by observing real robot executions. Physics-based simulators are a good alternative for providing highly valuable information while avoiding costly and potentially destructive robot executions. We present a novel approach for learning the probabilities of symbolic robot action outcomes. This is done leveraging different environments, such as physics-based simulators, in execution time. To this end, we propose MENID (Multiple Environment Noise Indeterministic Deictic) rules, a novel representation able to cope with the inherent uncertainties present in robotic tasks. MENID rules explicitly represent each possible outcomes of an action, keep memory of the source of the experience, and maintain the probability of success of each outcome. We also introduce an algorithm to distribute actions among environments, based on previous experiences and expected gain. Before using physics-based simulations, we propose a methodology for evaluating different simulation settings and determining the least time-consuming model that could be used while still producing coherent results. We demonstrate the validity of the approach in a dismantling use case, using a simulation with reduced quality as simulated system, and a simulation with full resolution where we add noise to the trajectories and some physical parameters as a representation of the real system.
A3D: Adaptive 3D Networks for Video Action Recognition
Nov 24, 2020
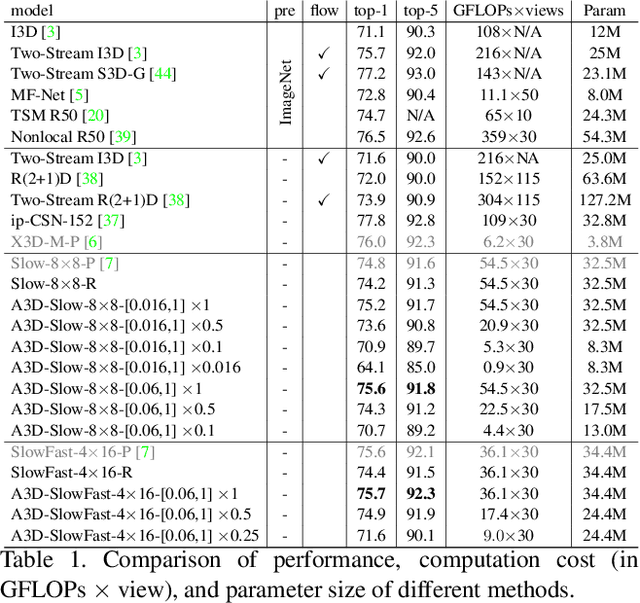
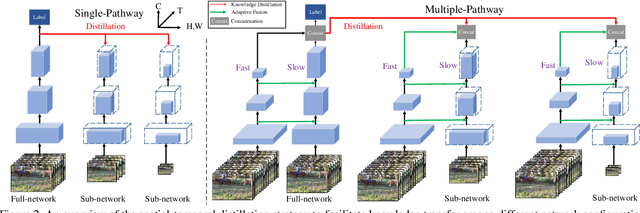

This paper presents A3D, an adaptive 3D network that can infer at a wide range of computational constraints with one-time training. Instead of training multiple models in a grid-search manner, it generates good configurations by trading off between network width and spatio-temporal resolution. Furthermore, the computation cost can be adapted after the model is deployed to meet variable constraints, for example, on edge devices. Even under the same computational constraints, the performance of our adaptive networks can be significantly boosted over the baseline counterparts by the mutual training along three dimensions. When a multiple pathway framework, e.g. SlowFast, is adopted, our adaptive method encourages a better trade-off between pathways than manual designs. Extensive experiments on the Kinetics dataset show the effectiveness of the proposed framework. The performance gain is also verified to transfer well between datasets and tasks. Code will be made available.
Linear State-Space Model with Time-Varying Dynamics
Oct 03, 2014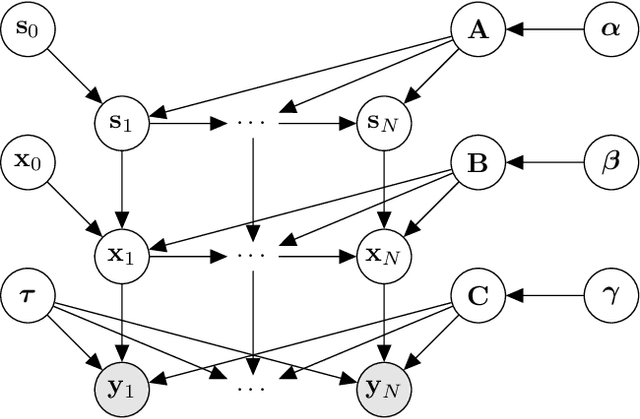
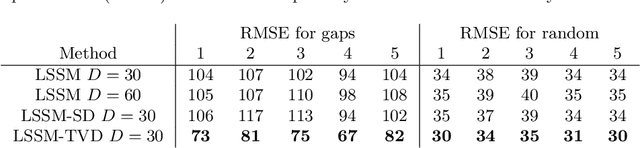
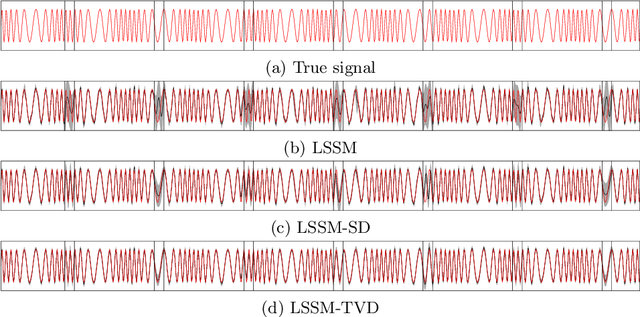

This paper introduces a linear state-space model with time-varying dynamics. The time dependency is obtained by forming the state dynamics matrix as a time-varying linear combination of a set of matrices. The time dependency of the weights in the linear combination is modelled by another linear Gaussian dynamical model allowing the model to learn how the dynamics of the process changes. Previous approaches have used switching models which have a small set of possible state dynamics matrices and the model selects one of those matrices at each time, thus jumping between them. Our model forms the dynamics as a linear combination and the changes can be smooth and more continuous. The model is motivated by physical processes which are described by linear partial differential equations whose parameters vary in time. An example of such a process could be a temperature field whose evolution is driven by a varying wind direction. The posterior inference is performed using variational Bayesian approximation. The experiments on stochastic advection-diffusion processes and real-world weather processes show that the model with time-varying dynamics can outperform previously introduced approaches.
* The final publication is available at Springer via http://dx.doi.org/10.1007/978-3-662-44851-9_22
Structural Forecasting for Tropical Cyclone Intensity Prediction: Providing Insight with Deep Learning
Oct 15, 2020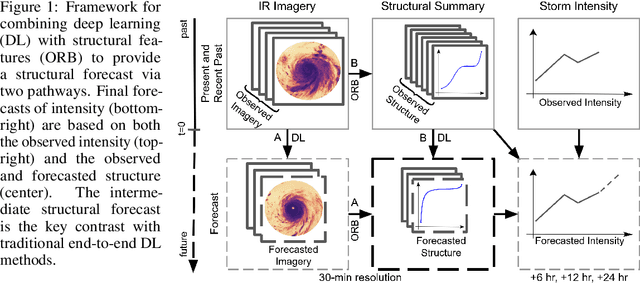
Tropical cyclone (TC) intensity forecasts are ultimately issued by human forecasters. The human in-the-loop pipeline requires that any forecasting guidance must be easily digestible by TC experts if it is to be adopted at operational centers like the National Hurricane Center. Our proposed framework leverages deep learning to provide forecasters with something neither end-to-end prediction models nor traditional intensity guidance does: a powerful tool for monitoring high-dimensional time series of key physically relevant predictors and the means to understand how the predictors relate to one another and to short-term intensity changes.
Certifying Incremental Quadratic Constraints for Neural Networks
Dec 10, 2020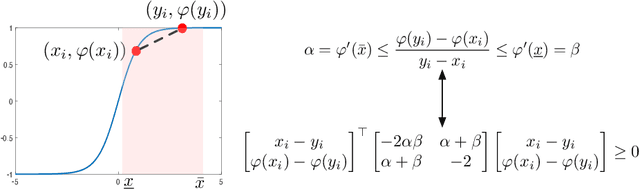
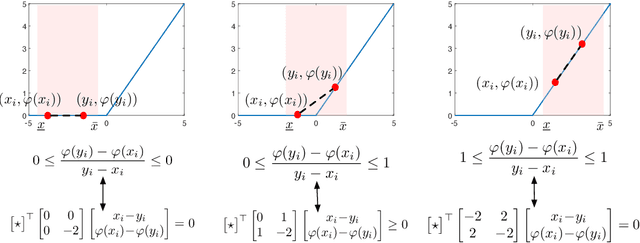
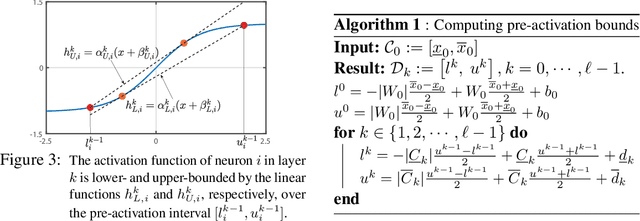
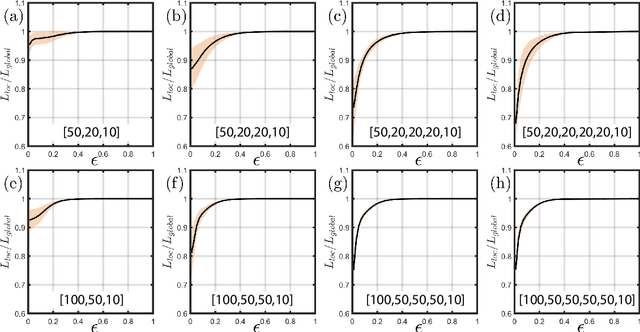
Abstracting neural networks with constraints they impose on their inputs and outputs can be very useful in the analysis of neural network classifiers and to derive optimization-based algorithms for certification of stability and robustness of feedback systems involving neural networks. In this paper, we propose a convex program, in the form of a Linear Matrix Inequality (LMI), to certify incremental quadratic constraints on the map of neural networks over a region of interest. These certificates can capture several useful properties such as (local) Lipschitz continuity, one-sided Lipschitz continuity, invertibility, and contraction. We illustrate the utility of our approach in two different settings. First, we develop a semidefinite program to compute guaranteed and sharp upper bounds on the local Lipschitz constant of neural networks and illustrate the results on random networks as well as networks trained on MNIST. Second, we consider a linear time-invariant system in feedback with an approximate model predictive controller parameterized by a neural network. We then turn the stability analysis into a semidefinite feasibility program and estimate an ellipsoidal invariant set for the closed-loop system.
Scalable Graph Networks for Particle Simulations
Oct 14, 2020Learning system dynamics directly from observations is a promising direction in machine learning due to its potential to significantly enhance our ability to understand physical systems. However, the dynamics of many real-world systems are challenging to learn due to the presence of nonlinear potentials and a number of interactions that scales quadratically with the number of particles $N$, as in the case of the N-body problem. In this work, we introduce an approach that transforms a fully-connected interaction graph into a hierarchical one which reduces the number of edges to $O(N)$. This results in linear time and space complexity while the pre-computation of the hierarchical graph requires $O(N\log (N))$ time and $O(N)$ space. Using our approach, we are able to train models on much larger particle counts, even on a single GPU. We evaluate how the phase space position accuracy and energy conservation depend on the number of simulated particles. Our approach retains high accuracy and efficiency even on large-scale gravitational N-body simulations which are impossible to run on a single machine if a fully-connected graph is used. Similar results are also observed when simulating Coulomb interactions. Furthermore, we make several important observations regarding the performance of this new hierarchical model, including: i) its accuracy tends to improve with the number of particles in the simulation and ii) its generalisation to unseen particle counts is also much better than for models that use all $O(N^2)$ interactions.
Computer Vision based Animal Collision Avoidance Framework for Autonomous Vehicles
Dec 20, 2020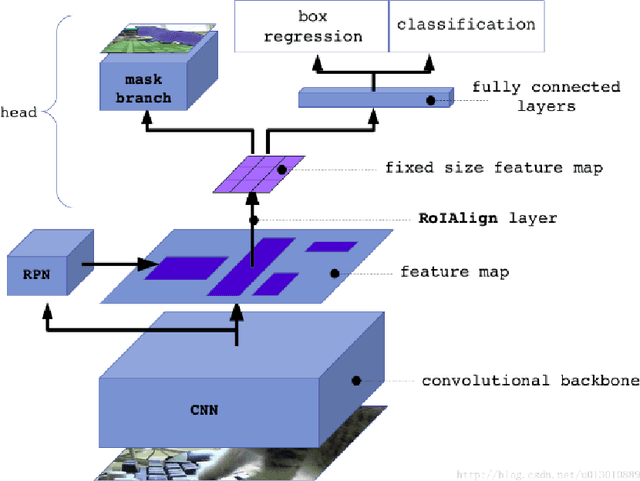
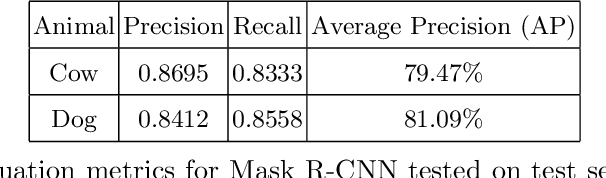
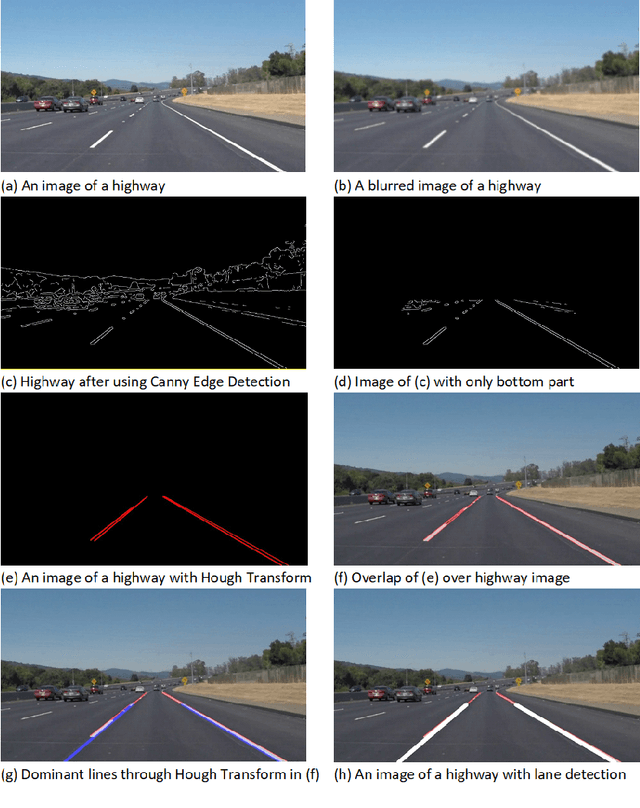
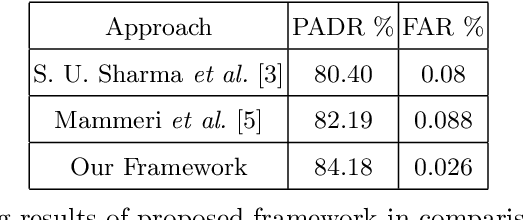
Animals have been a common sighting on roads in India which leads to several accidents between them and vehicles every year. This makes it vital to develop a support system for driverless vehicles that assists in preventing these forms of accidents. In this paper, we propose a neoteric framework for avoiding vehicle-to-animal collisions by developing an efficient approach for the detection of animals on highways using deep learning and computer vision techniques on dashcam video. Our approach leverages the Mask R-CNN model for detecting and identifying various commonly found animals. Then, we perform lane detection to deduce whether a detected animal is on the vehicle's lane or not and track its location and direction of movement using a centroid based object tracking algorithm. This approach ensures that the framework is effective at determining whether an animal is obstructing the path or not of an autonomous vehicle in addition to predicting its movement and giving feedback accordingly. This system was tested under various lighting and weather conditions and was observed to perform relatively well, which leads the way for prominent driverless vehicle's support systems for avoiding vehicular collisions with animals on Indian roads in real-time.