 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-stage Speaker Extraction with Utterance and Frame-Level Reference Signals
Nov 19, 2020
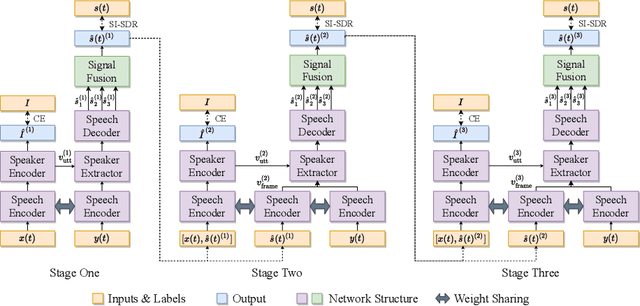
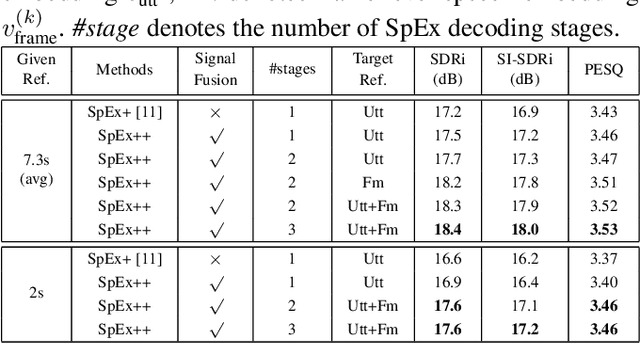
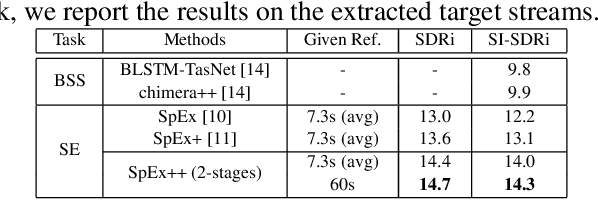
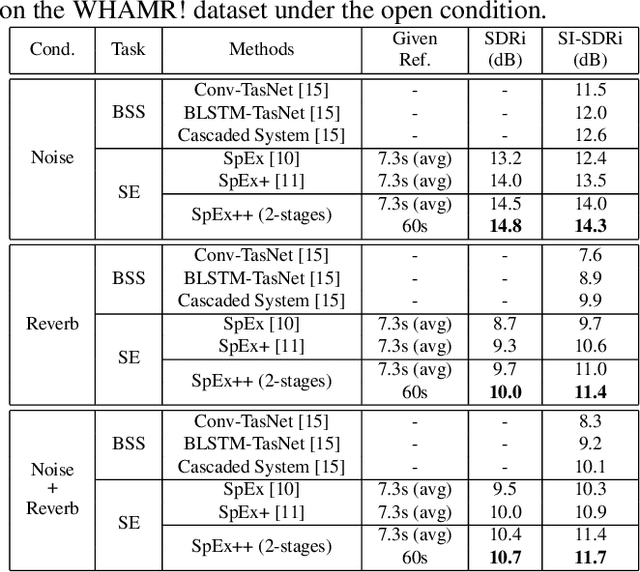
Speaker extraction uses a pre-recorded reference speech as the reference signal for target speaker extraction. In real-world applications, enrolling a speaker with a long speech is not practical. We propose a speaker extraction technique, that performs in multiple stages to take full advantage of short reference speech sample. The extracted speech in early stages is used as the reference speech for late stages. Furthermore, for the first time, we use frame-level sequential speech embedding as the reference for target speaker. This is a departure from the traditional utterance-based speaker embedding reference. In addition, a signal fusion scheme is proposed to combine the decoded signals in multiple scales with automatically learned weights. Experiments on WSJ0-2mix and its noisy versions (WHAM! and WHAMR!) show that SpEx++ consistently outperforms other state-of-the-art baselines.
Temporal Attribute Prediction via Joint Modeling of Multi-Relational Structure Evolution
Mar 09, 2020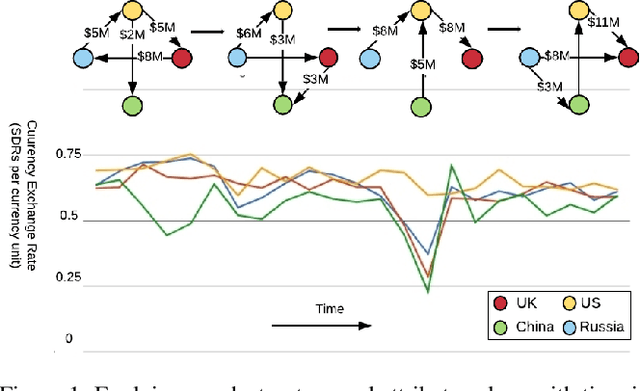
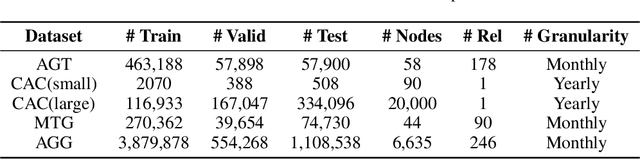
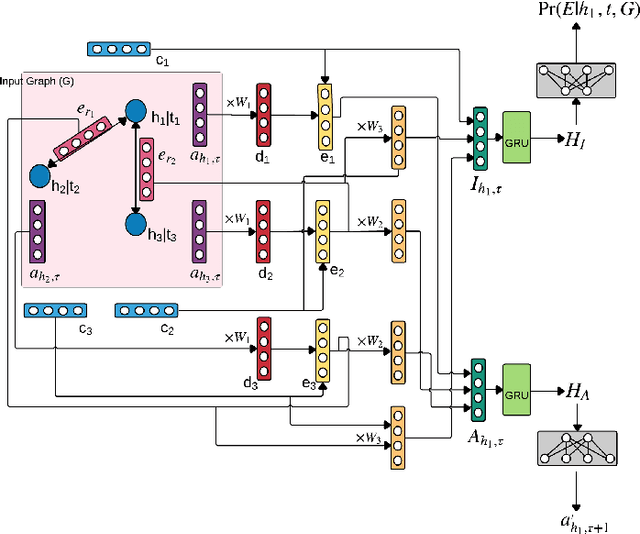
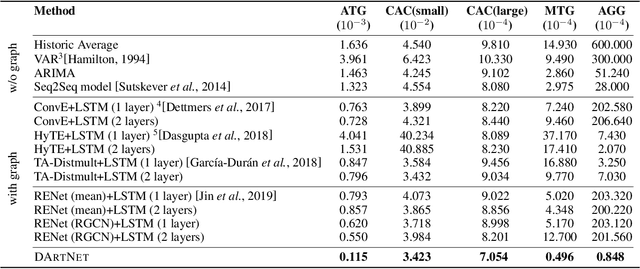
Time series prediction is an important problem in machine learning. Previous methods for time series prediction did not involve additional information. With a lot of dynamic knowledge graphs available, we can use this additional information to predict the time series better. Recently, there has been a focus on the application of deep representation learning on dynamic graphs. These methods predict the structure of the graph by reasoning over the interactions in the graph at previous time steps. In this paper, we propose a new framework to incorporate the information from dynamic knowledge graphs for time series prediction. We show that if the information contained in the graph and the time series data are closely related, then this inter-dependence can be used to predict the time series with improved accuracy. Our framework, DArtNet, learns a static embedding for every node in the graph as well as a dynamic embedding which is dependent on the dynamic attribute value (time-series). Then it captures the information from the neighborhood by taking a relation specific mean and encodes the history information using RNN. We jointly train the model link prediction and attribute prediction. We evaluate our method on five specially curated datasets for this problem and show a consistent improvement in time series prediction results.
Dosimetric impact of physician style variations in contouring CTV for post-operative prostate cancer: A deep learning based simulation study
Feb 01, 2021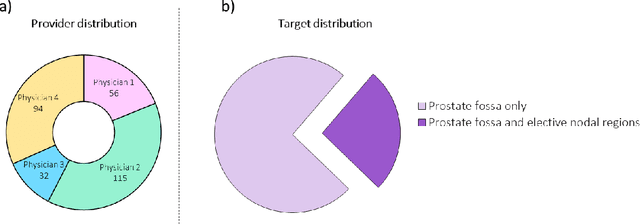
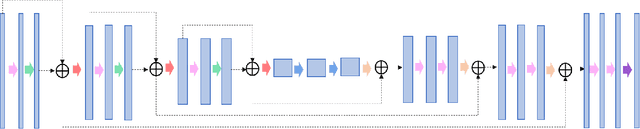
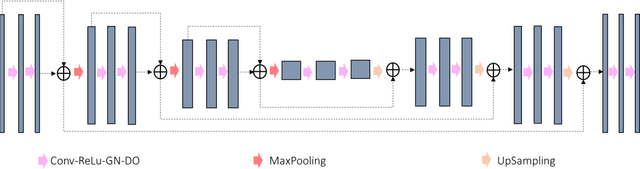
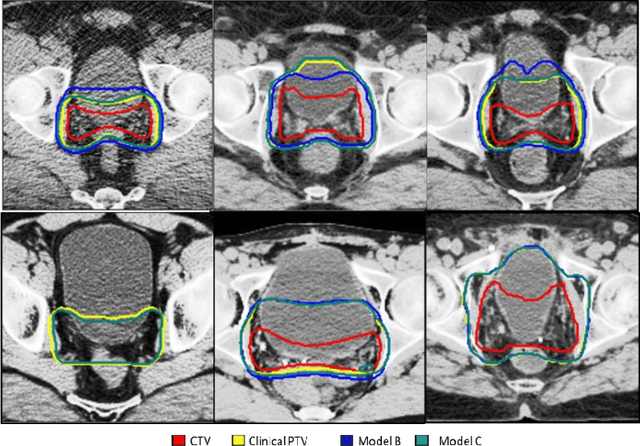
In tumor segmentation, inter-observer variation is acknowledged to be a significant problem. This is even more significant in clinical target volume (CTV) segmentation, specifically, in post-operative settings, where a gross tumor does not exist. In this scenario, CTV is not an anatomically established structure but rather one determined by the physician based on the clinical guideline used, the preferred trade off between tumor control and toxicity, their experience, training background etc... This results in high inter-observer variability between physicians. Inter-observer variability has been considered an issue, however its dosimetric consequence is still unclear, due to the absence of multiple physician CTV contours for each patient and the significant amount of time required for dose planning. In this study, we analyze the impact that these physician stylistic variations have on organs-at-risk (OAR) dose by simulating the clinical workflow using deep learning. For a given patient previously treated by one physician, we use DL-based tools to simulate how other physicians would contour the CTV and how the corresponding dose distributions should look like for this patient. To simulate multiple physician styles, we use a previously developed in-house CTV segmentation model that can produce physician style-aware segmentations. The corresponding dose distribution is predicted using another in-house deep learning tool, which, averaging across all structures, is capable of predicting dose within 3% of the prescription dose on the test data. For every test patient, four different physician-style CTVs are considered and four different dose distributions are analyzed. OAR dose metrics are compared, showing that even though physician style variations results in organs getting different doses, all the important dose metrics except Maximum Dose point are within the clinically acceptable limit.
Information contraction in noisy binary neural networks and its implications
Feb 01, 2021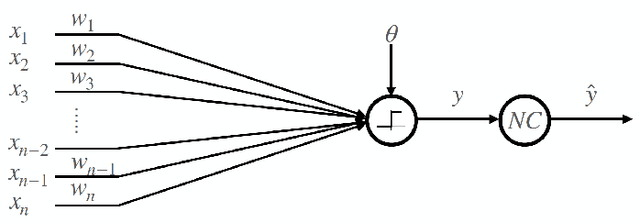
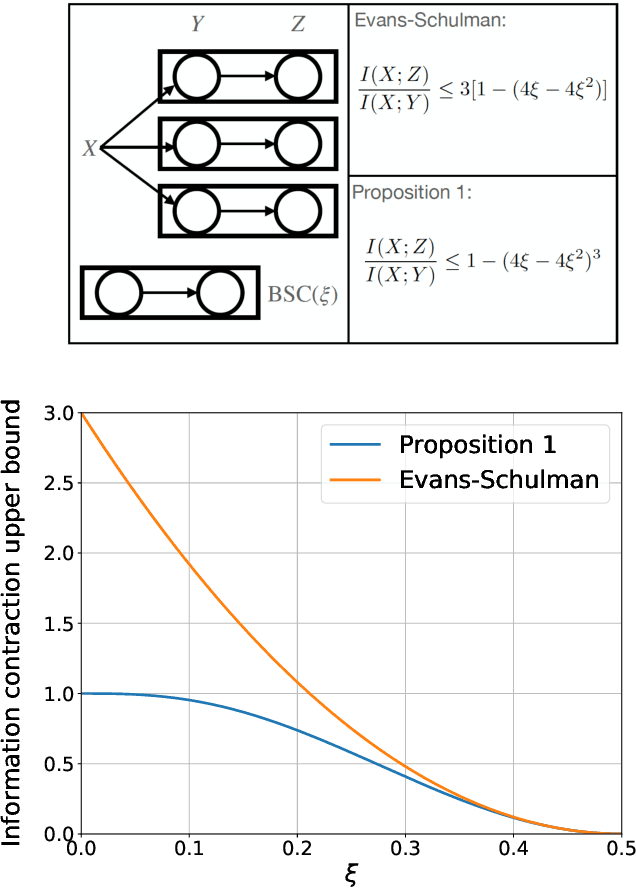
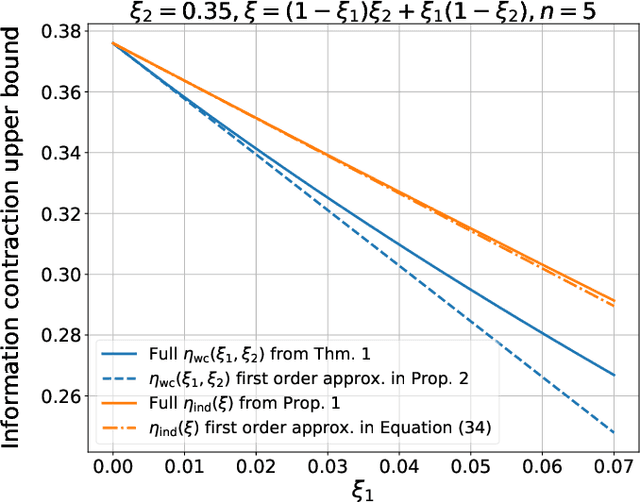
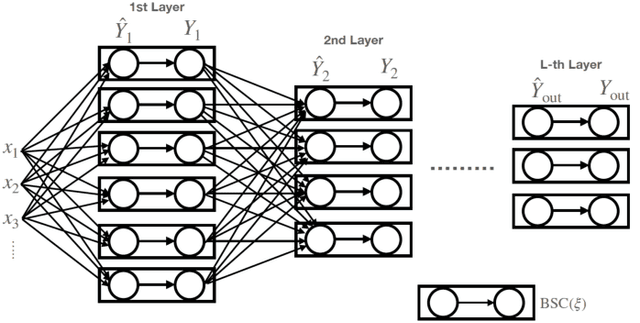
Neural networks have gained importance as the machine learning models that achieve state-of-the-art performance on large-scale image classification, object detection and natural language processing tasks. In this paper, we consider noisy binary neural networks, where each neuron has a non-zero probability of producing an incorrect output. These noisy models may arise from biological, physical and electronic contexts and constitute an important class of models that are relevant to the physical world. Intuitively, the number of neurons in such systems has to grow to compensate for the noise while maintaining the same level of expressive power and computation reliability. Our key finding is a lower bound for the required number of neurons in noisy neural networks, which is first of its kind. To prove this lower bound, we take an information theoretic approach and obtain a novel strong data processing inequality (SDPI), which not only generalizes the Evans-Schulman results for binary symmetric channels to general channels, but also improves the tightness drastically when applied to estimate end-to-end information contraction in networks. Our SDPI can be applied to various information processing systems, including neural networks and cellular automata. Applying the SDPI in noisy binary neural networks, we obtain our key lower bound and investigate its implications on network depth-width trade-offs, our results suggest a depth-width trade-off for noisy neural networks that is very different from the established understanding regarding noiseless neural networks. Furthermore, we apply the SDPI to study fault-tolerant cellular automata and obtain bounds on the error correction overheads and the relaxation time. This paper offers new understanding of noisy information processing systems through the lens of information theory.
Computer Vision based Animal Collision Avoidance Framework for Autonomous Vehicles
Dec 20, 2020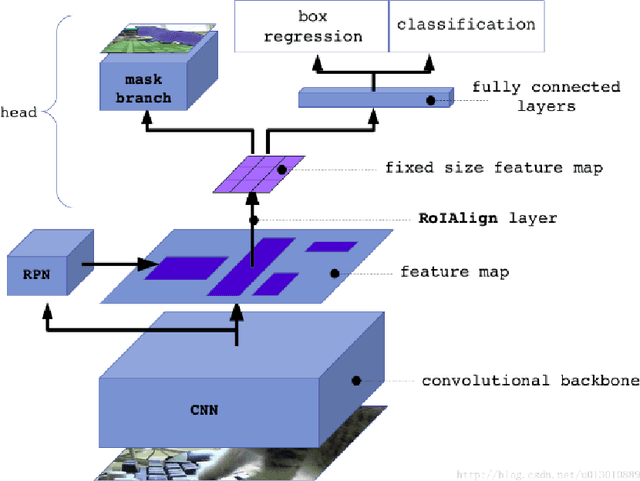
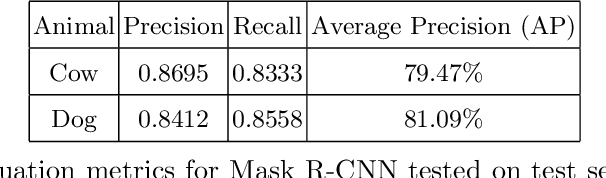
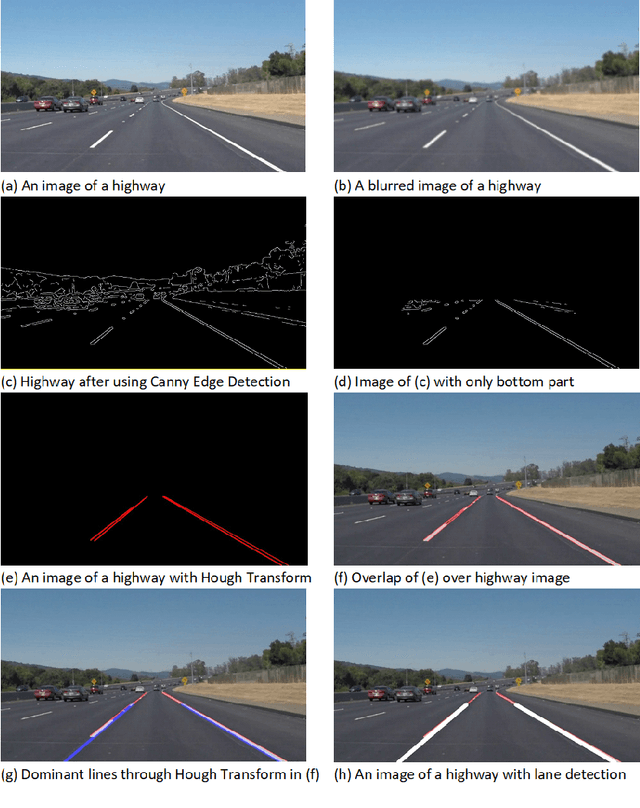
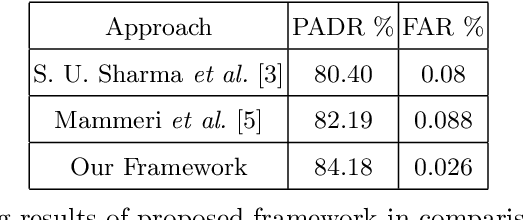
Animals have been a common sighting on roads in India which leads to several accidents between them and vehicles every year. This makes it vital to develop a support system for driverless vehicles that assists in preventing these forms of accidents. In this paper, we propose a neoteric framework for avoiding vehicle-to-animal collisions by developing an efficient approach for the detection of animals on highways using deep learning and computer vision techniques on dashcam video. Our approach leverages the Mask R-CNN model for detecting and identifying various commonly found animals. Then, we perform lane detection to deduce whether a detected animal is on the vehicle's lane or not and track its location and direction of movement using a centroid based object tracking algorithm. This approach ensures that the framework is effective at determining whether an animal is obstructing the path or not of an autonomous vehicle in addition to predicting its movement and giving feedback accordingly. This system was tested under various lighting and weather conditions and was observed to perform relatively well, which leads the way for prominent driverless vehicle's support systems for avoiding vehicular collisions with animals on Indian roads in real-time.
Certifying Incremental Quadratic Constraints for Neural Networks
Dec 10, 2020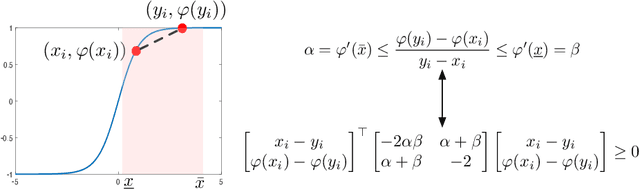
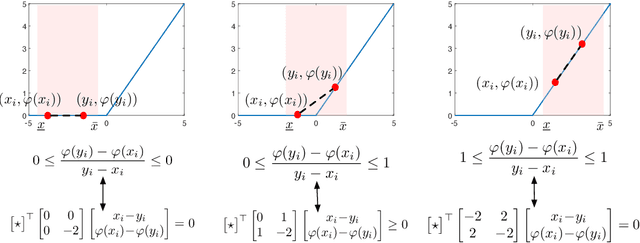
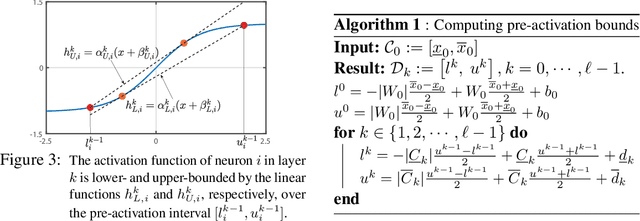
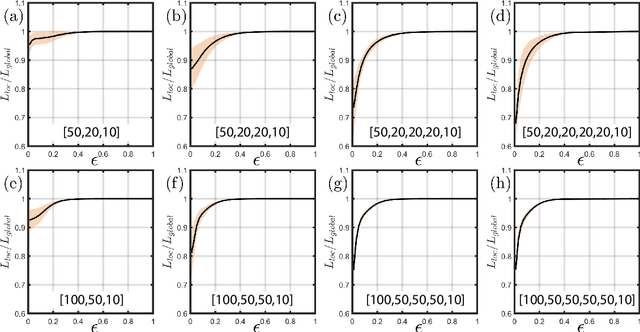
Abstracting neural networks with constraints they impose on their inputs and outputs can be very useful in the analysis of neural network classifiers and to derive optimization-based algorithms for certification of stability and robustness of feedback systems involving neural networks. In this paper, we propose a convex program, in the form of a Linear Matrix Inequality (LMI), to certify incremental quadratic constraints on the map of neural networks over a region of interest. These certificates can capture several useful properties such as (local) Lipschitz continuity, one-sided Lipschitz continuity, invertibility, and contraction. We illustrate the utility of our approach in two different settings. First, we develop a semidefinite program to compute guaranteed and sharp upper bounds on the local Lipschitz constant of neural networks and illustrate the results on random networks as well as networks trained on MNIST. Second, we consider a linear time-invariant system in feedback with an approximate model predictive controller parameterized by a neural network. We then turn the stability analysis into a semidefinite feasibility program and estimate an ellipsoidal invariant set for the closed-loop system.
Show and Speak: Directly Synthesize Spoken Description of Images
Oct 23, 2020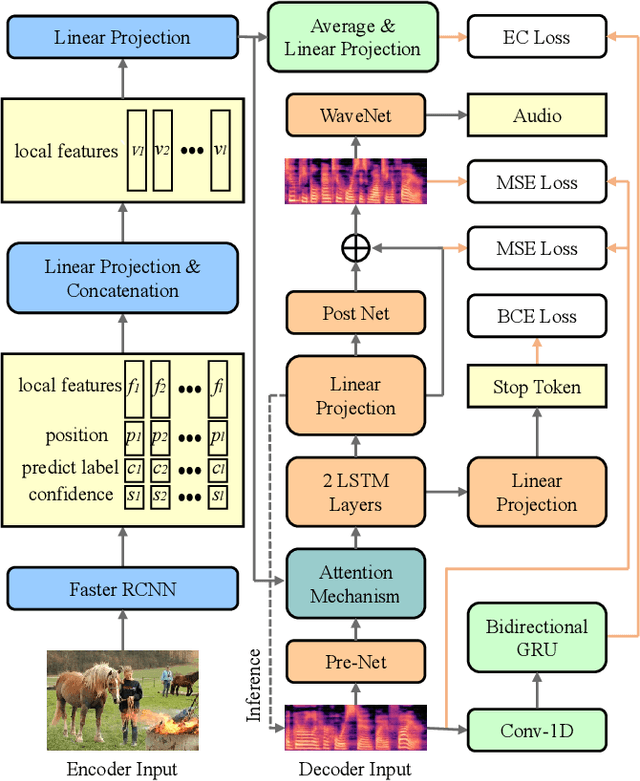

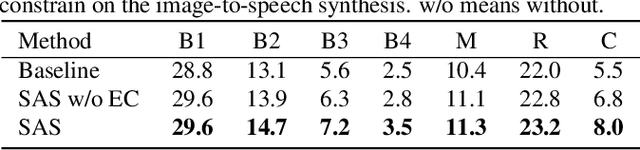

This paper proposes a new model, referred to as the show and speak (SAS) model that, for the first time, is able to directly synthesize spoken descriptions of images, bypassing the need for any text or phonemes. The basic structure of SAS is an encoder-decoder architecture that takes an image as input and predicts the spectrogram of speech that describes this image. The final speech audio is obtained from the predicted spectrogram via WaveNet. Extensive experiments on the public benchmark database Flickr8k demonstrate that the proposed SAS is able to synthesize natural spoken descriptions for images, indicating that synthesizing spoken descriptions for images while bypassing text and phonemes is feasible.
A3D: Adaptive 3D Networks for Video Action Recognition
Nov 24, 2020
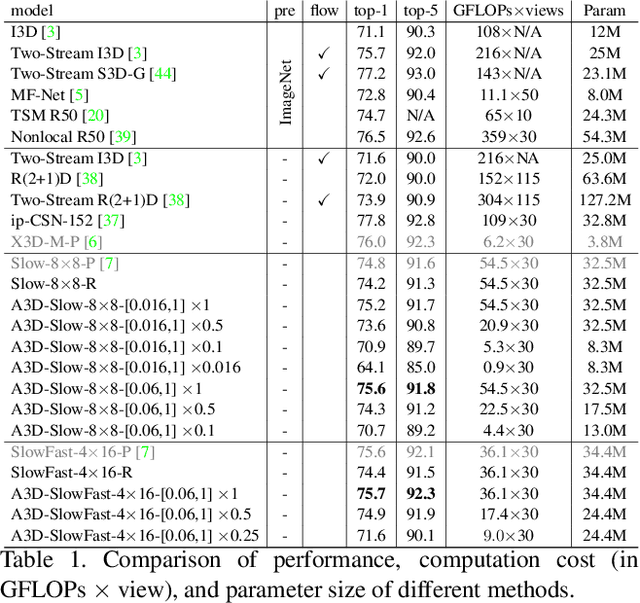
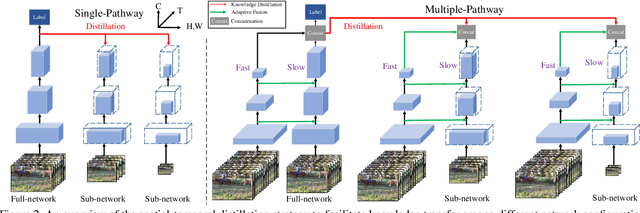

This paper presents A3D, an adaptive 3D network that can infer at a wide range of computational constraints with one-time training. Instead of training multiple models in a grid-search manner, it generates good configurations by trading off between network width and spatio-temporal resolution. Furthermore, the computation cost can be adapted after the model is deployed to meet variable constraints, for example, on edge devices. Even under the same computational constraints, the performance of our adaptive networks can be significantly boosted over the baseline counterparts by the mutual training along three dimensions. When a multiple pathway framework, e.g. SlowFast, is adopted, our adaptive method encourages a better trade-off between pathways than manual designs. Extensive experiments on the Kinetics dataset show the effectiveness of the proposed framework. The performance gain is also verified to transfer well between datasets and tasks. Code will be made available.
SAR Image Despeckling Based on Convolutional Denoising Autoencoder
Nov 30, 2020
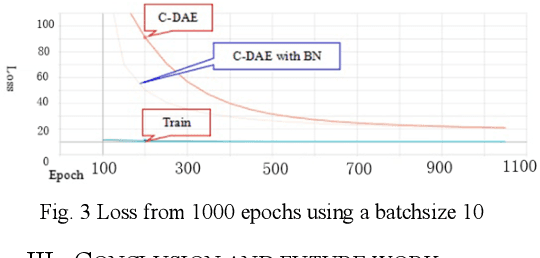
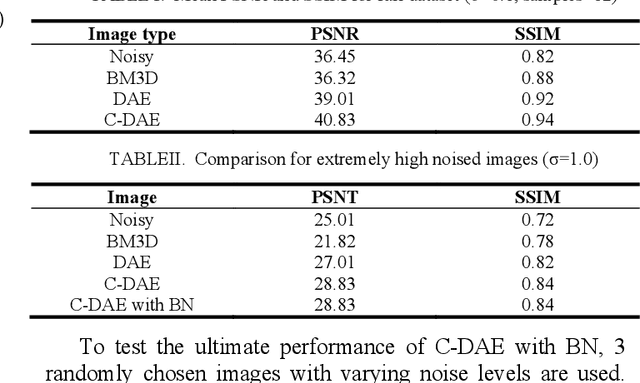
In Synthetic Aperture Radar (SAR) imaging, despeckling is very important for image analysis,whereas speckle is known as a kind of multiplicative noise caused by the coherent imaging system. During the past three decades, various algorithms have been proposed to denoise the SAR image. Generally, the BM3D is considered as the state of art technique to despeckle the speckle noise with excellent performance. More recently, deep learning make a success in image denoising and achieved a improvement over conventional method where large train dataset is required. Unlike most of the images SAR image despeckling approach, the proposed approach learns the speckle from corrupted images directly. In this paper, the limited scale of dataset make a efficient exploration by using convolutioal denoising autoencoder (C-DAE) to reconstruct the speckle-free SAR images. Batch normalization strategy is integrated with C- DAE to speed up the train time. Moreover, we compute image quality in standard metrics, PSNR and SSIM. It is revealed that our approach perform well than some others.
Real-time 3D scene description using Spheres, Cones and Cylinders
Mar 12, 2016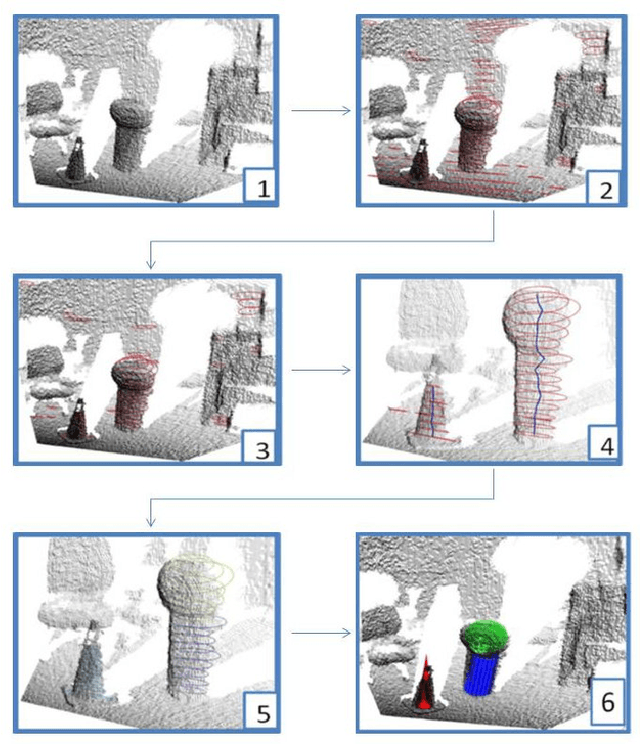
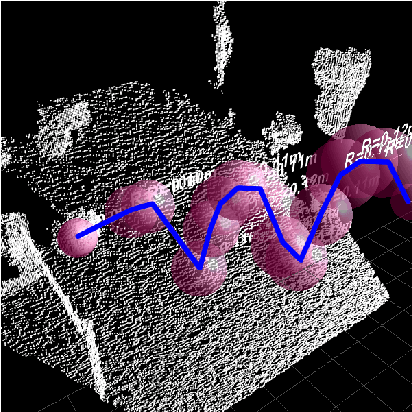

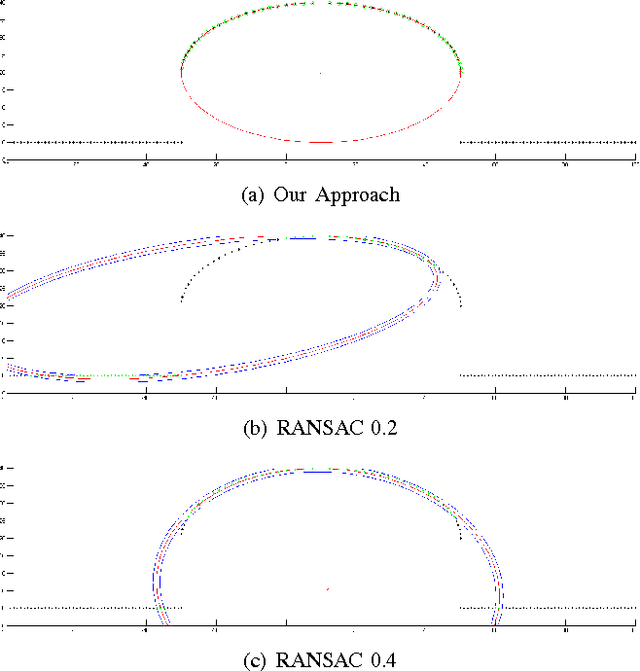
The paper describes a novel real-time algorithm for finding 3D geometric primitives (cylinders, cones and spheres) from 3D range data. In its core, it performs a fast model fitting with a model update in constant time (O(1)) for each new data point added to the model. We use a three stage approach.The first step inspects 1.5D sub spaces, to find ellipses. The next stage uses these ellipses as input by examining their neighborhood structure to form sets of candidates for the 3D geometric primitives. Finally, candidate ellipses are fitted to the geometric primitives. The complexity for point processing is O(n); additional time of lower order is needed for working on significantly smaller amount of mid-level objects. This allows the approach to process 30 frames per second on Kinect depth data, which suggests this approach as a pre-processing step for 3D real-time higher level tasks in robotics, like tracking or feature based mapping.