 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Action Duration Prediction for Segment-Level Alignment of Weakly-Labeled Videos
Nov 20, 2020
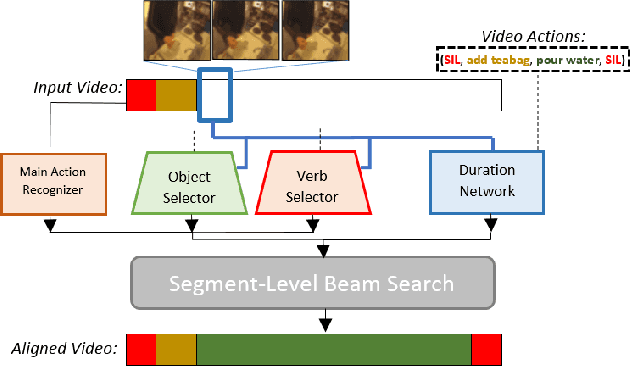
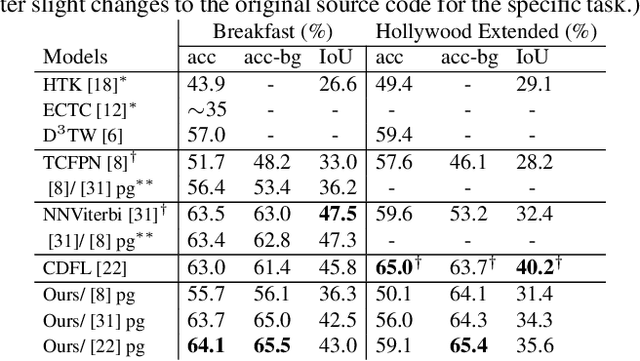
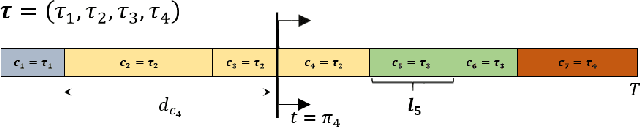
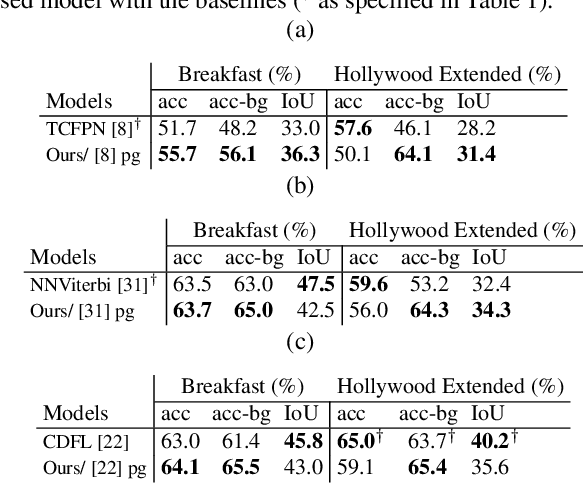
This paper focuses on weakly-supervised action alignment, where only the ordered sequence of video-level actions is available for training. We propose a novel Duration Network, which captures a short temporal window of the video and learns to predict the remaining duration of a given action at any point in time with a level of granularity based on the type of that action. Further, we introduce a Segment-Level Beam Search to obtain the best alignment, that maximizes our posterior probability. Segment-Level Beam Search efficiently aligns actions by considering only a selected set of frames that have more confident predictions. The experimental results show that our alignments for long videos are more robust than existing models. Moreover, the proposed method achieves state of the art results in certain cases on the popular Breakfast and Hollywood Extended datasets.
An Adaptive Multi-Agent Physical Layer Security Framework for Cognitive Cyber-Physical Systems
Jan 07, 2021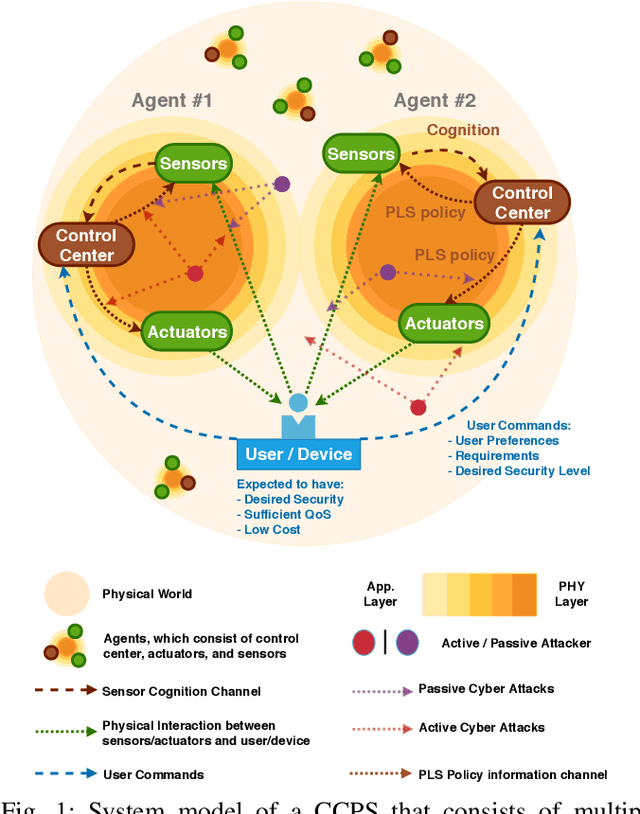
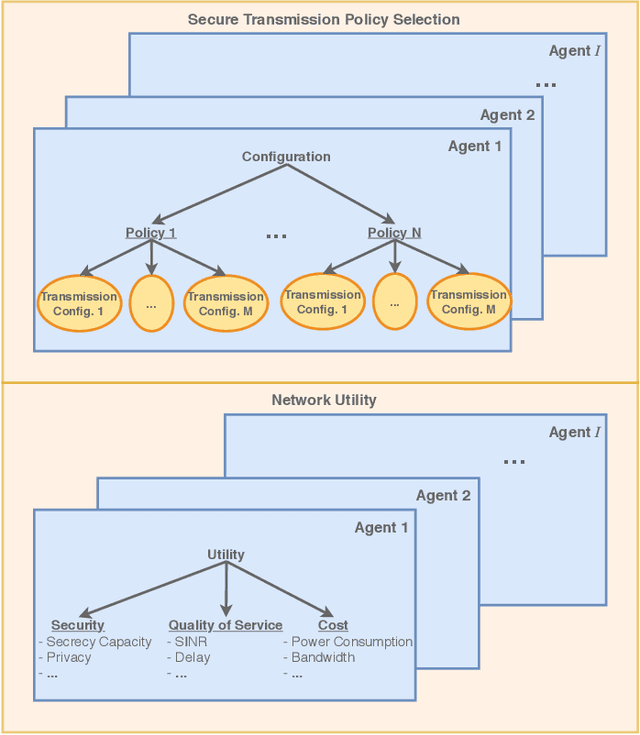
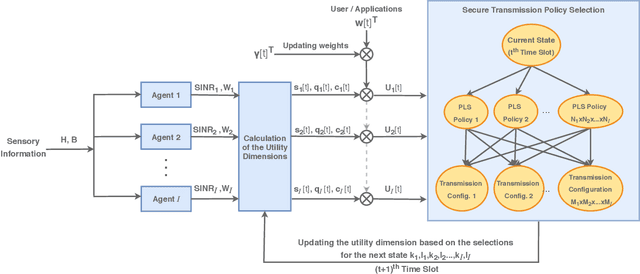
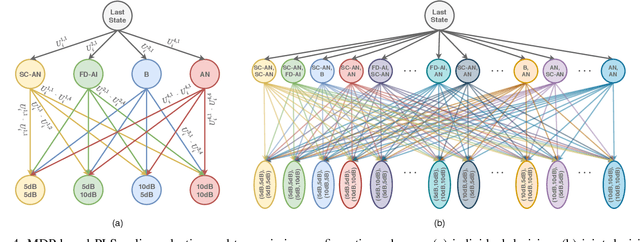
Being capable of sensing and behavioral adaptation in line with their changing environments, cognitive cyber-physical systems (CCPSs) are the new form of applications in future wireless networks. With the advancement of the machine learning algorithms, the transmission scheme providing the best performance can be utilized to sustain a reliable network of CCPS agents equipped with self-decision mechanisms, where the interactions between each agent are modeled in terms of service quality, security, and cost dimensions. In this work, first, we provide network utility as a reliability metric, which is a weighted sum of the individual utility values of the CCPS agents. The individual utilities are calculated by mixing the quality of service (QoS), security, and cost dimensions with the proportions determined by the individualized user requirements. By changing the proportions, the CCPS network can be tuned for different applications of next-generation wireless networks. Then, we propose a secure transmission policy selection (STPS) mechanism that maximizes the network utility by using the Markov-decision process (MDP). In STPS, the CCPS network jointly selects the best performing physical layer security policy and the parameters of the selected secure transmission policy to adapt to the changing environmental effects. The proposed STPS is realized by reinforcement learning (RL), considering its real-time decision mechanism where agents can decide automatically the best utility providing policy in an altering environment.
Minimal Solutions for Panoramic Stitching Given Gravity Prior
Dec 01, 2020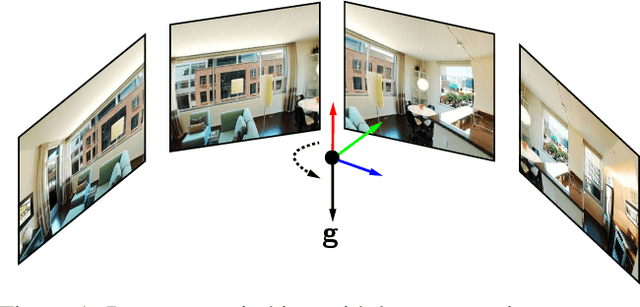
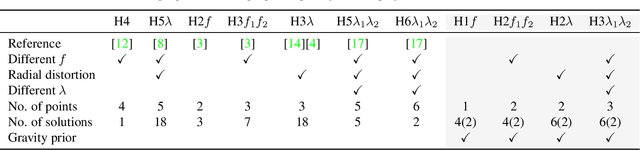

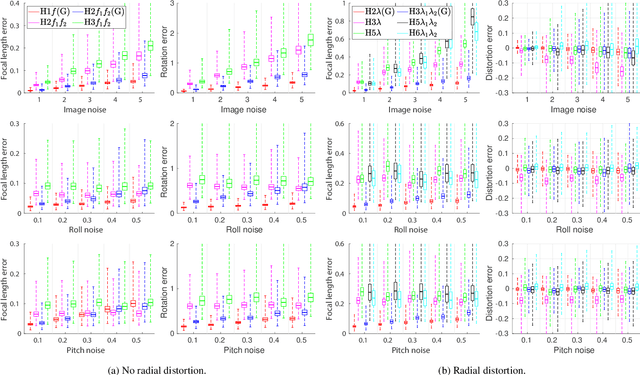
When capturing panoramas, people tend to align their cameras with the vertical axis, i.e., the direction of gravity. Moreover, modern devices, such as smartphones and tablets, are equipped with an IMU (Inertial Measurement Unit) that can measure the gravity vector accurately. Using this prior, the y-axes of the cameras can be aligned or assumed to be already aligned, reducing their relative orientation to 1-DOF (degree of freedom). Exploiting this assumption, we propose new minimal solutions to panoramic image stitching of images taken by cameras with coinciding optical centers, i.e., undergoing pure rotation. We consider four practical camera configurations, assuming unknown fixed or varying focal length with or without radial distortion. The solvers are tested both on synthetic scenes and on more than 500k real image pairs from the Sun360 dataset and from scenes captured by us using two smartphones equipped with IMUs. It is shown, that they outperform the state-of-the-art both in terms of accuracy and processing time.
Truly shift-invariant convolutional neural networks
Dec 01, 2020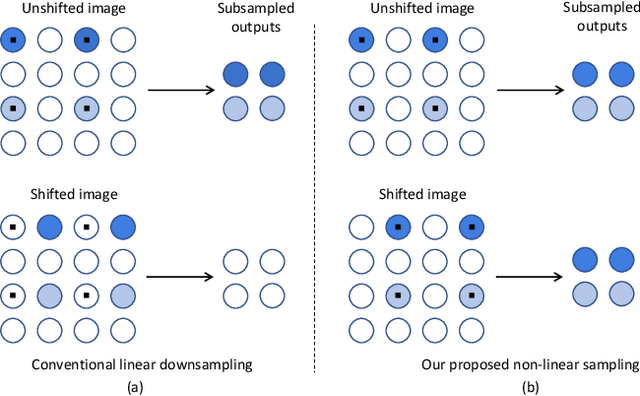
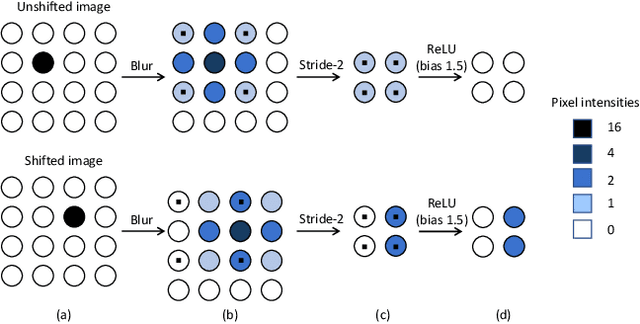
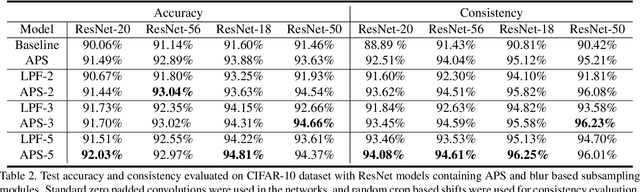
Thanks to the use of convolution and pooling layers, convolutional neural networks were for a long time thought to be shift-invariant. However, recent works have shown that the output of a CNN can change significantly with small shifts in input: a problem caused by the presence of downsampling (stride) layers. The existing solutions rely either on data augmentation or on anti-aliasing, both of which have limitations and neither of which enables perfect shift invariance. Additionally, the gains obtained from these methods do not extend to image patterns not seen during training. To address these challenges, we propose adaptive polyphase sampling (APS), a simple sub-sampling scheme that allows convolutional neural networks to achieve 100% consistency in classification performance under shifts, without any loss in accuracy. With APS the networks exhibit perfect consistency to shifts even before training, making it the first approach that makes convolutional neural networks truly shift invariant.
Sim-to-real for high-resolution optical tactile sensing: From images to 3D contact force distributions
Dec 21, 2020
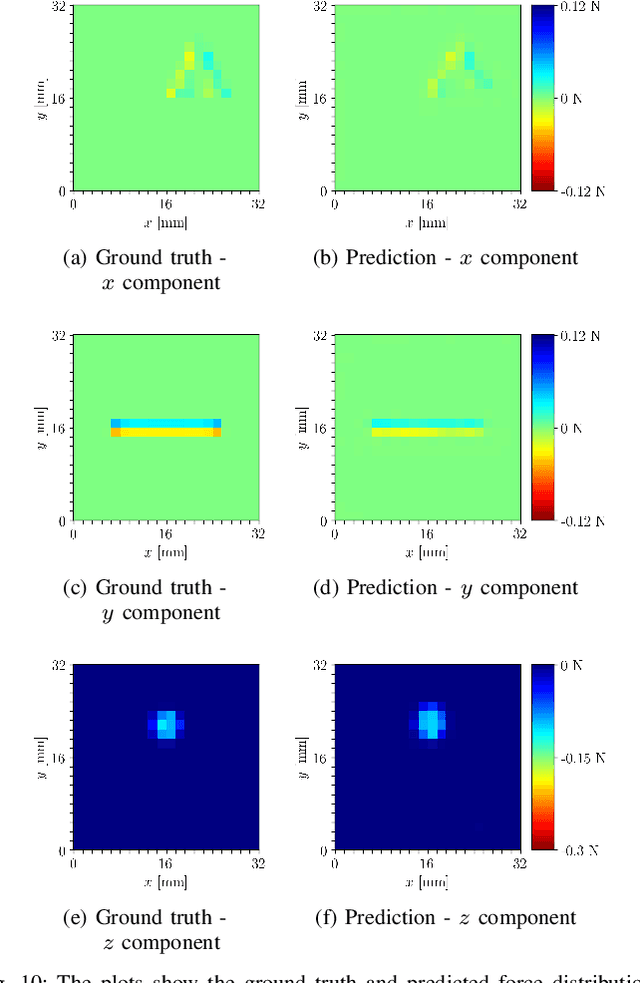


The images captured by vision-based tactile sensors carry information about high-resolution tactile fields, such as the distribution of the contact forces applied to their soft sensing surface. However, extracting the information encoded in the images is challenging and often addressed with learning-based approaches, which generally require a large amount of training data. This article proposes a strategy to generate tactile images in simulation for a vision-based tactile sensor based on an internal camera that tracks the motion of spherical particles within a soft material. The deformation of the material is simulated in a finite element environment under a diverse set of contact conditions, and spherical particles are projected to a simulated image. Features extracted from the images are mapped to the 3D contact force distribution, with the ground truth also obtained via finite-element simulations, with an artificial neural network that is therefore entirely trained on synthetic data avoiding the need for real-world data collection. The resulting model exhibits high accuracy when evaluated on real-world tactile images, is transferable across multiple tactile sensors without further training, and is suitable for efficient real-time inference.
Adaptive Histogram-Based Gradient Boosted Trees for Federated Learning
Dec 11, 2020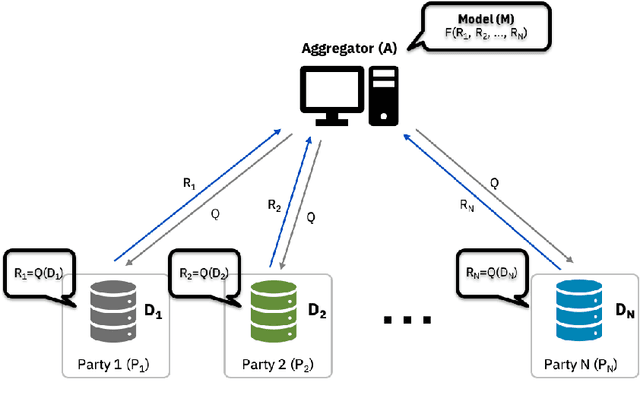
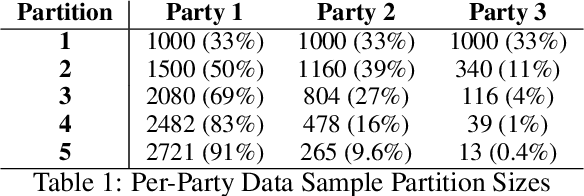


Federated Learning (FL) is an approach to collaboratively train a model across multiple parties without sharing data between parties or an aggregator. It is used both in the consumer domain to protect personal data as well as in enterprise settings, where dealing with data domicile regulation and the pragmatics of data silos are the main drivers. While gradient boosted tree implementations such as XGBoost have been very successful for many use cases, its federated learning adaptations tend to be very slow due to using cryptographic and privacy methods and have not experienced widespread use. We propose the Party-Adaptive XGBoost (PAX) for federated learning, a novel implementation of gradient boosting which utilizes a party adaptive histogram aggregation method, without the need for data encryption. It constructs a surrogate representation of the data distribution for finding splits of the decision tree. Our experimental results demonstrate strong model performance, especially on non-IID distributions, and significantly faster training run-time across different data sets than existing federated implementations. This approach makes the use of gradient boosted trees practical in enterprise federated learning.
Fully Convolutional Network Bootstrapped by Word Encoding and Embedding for Activity Recognition in Smart Homes
Dec 01, 2020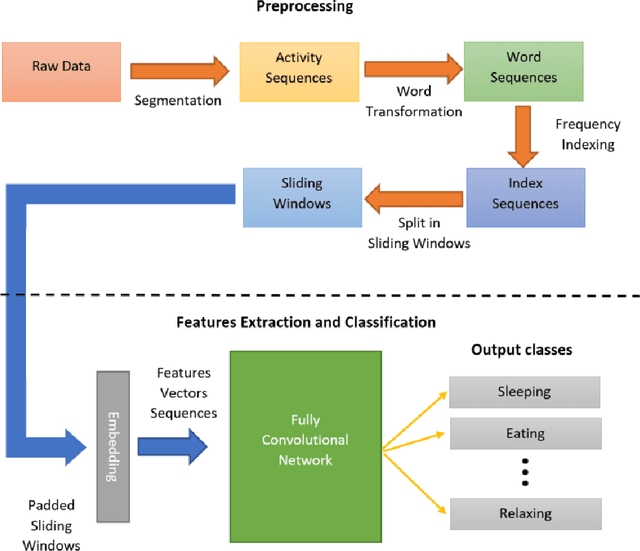
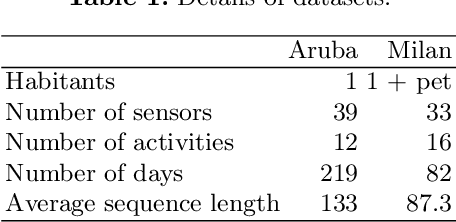
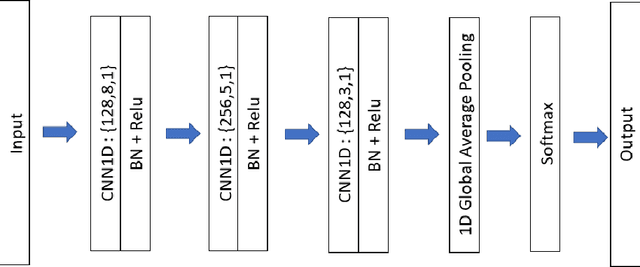
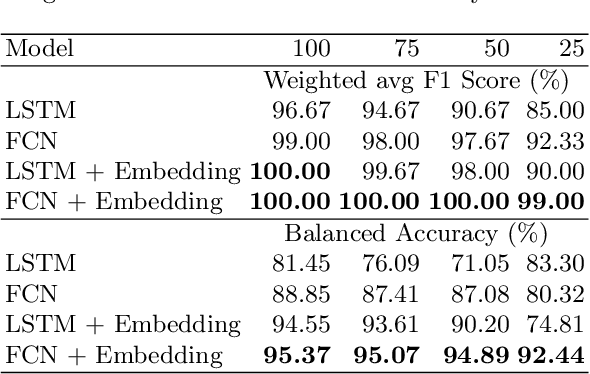
Activity recognition in smart homes is essential when we wish to propose automatic services for the inhabitants. However, it poses challenges in terms of variability of the environment, sensorimotor system, but also user habits. Therefore, endto-end systems fail at automatically extracting key features, without extensive pre-processing. We propose to tackle feature extraction for activity recognition in smart homes by merging methods from the Natural Language Processing (NLP) and the Time Series Classification (TSC) domains. We evaluate the performance of our method on two datasets issued from the Center for Advanced Studies in Adaptive Systems (CASAS). Moreover, we analyze the contributions of the use of NLP encoding Bag-Of-Word with Embedding as well as the ability of the FCN algorithm to automatically extract features and classify. The method we propose shows good performance in offline activity classification. Our analysis also shows that FCN is a suitable algorithm for smart home activity recognition and hightlights the advantages of automatic feature extraction.
Is Reinforcement Learning More Difficult Than Bandits? A Near-optimal Algorithm Escaping the Curse of Horizon
Sep 28, 2020
Episodic reinforcement learning and contextual bandits are two widely studied sequential decision-making problems. Episodic reinforcement learning generalizes contextual bandits and is often perceived to be more difficult due to long planning horizon and unknown state-dependent transitions. The current paper shows that the long planning horizon and the unknown state-dependent transitions (at most) pose little additional difficulty on sample complexity. We consider the episodic reinforcement learning with $S$ states, $A$ actions, planning horizon $H$, total reward bounded by $1$, and the agent plays for $K$ episodes. We propose a new algorithm, \textbf{M}onotonic \textbf{V}alue \textbf{P}ropagation (MVP), which relies on a new Bernstein-type bonus. The new bonus only requires tweaking the \emph{constants} to ensure optimism and thus is significantly simpler than existing bonus constructions. We show MVP enjoys an $O\left(\left(\sqrt{SAK} + S^2A\right) \text{poly}\log \left(SAHK\right)\right)$ regret, approaching the $\Omega\left(\sqrt{SAK}\right)$ lower bound of \emph{contextual bandits}. Notably, this result 1) \emph{exponentially} improves the state-of-the-art polynomial-time algorithms by Dann et al. [2019], Zanette et al. [2019] and Zhang et al. [2020] in terms of the dependency on $H$, and 2) \emph{exponentially} improves the running time in [Wang et al. 2020] and significantly improves the dependency on $S$, $A$ and $K$ in sample complexity.
Funnel Libraries for Real-Time Robust Feedback Motion Planning
Apr 29, 2017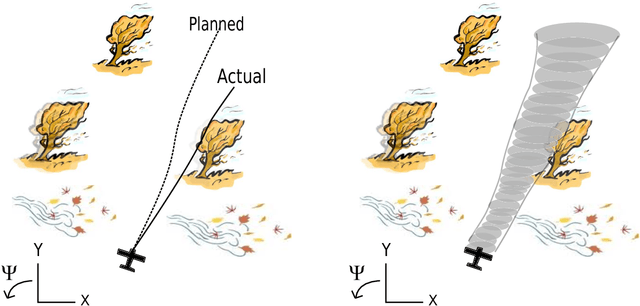
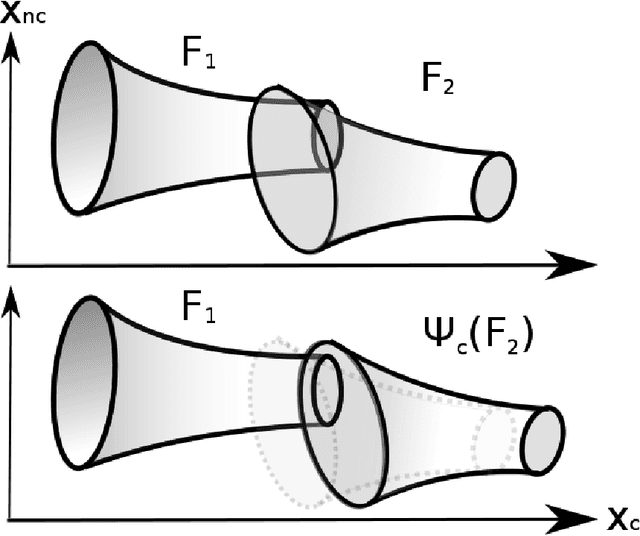
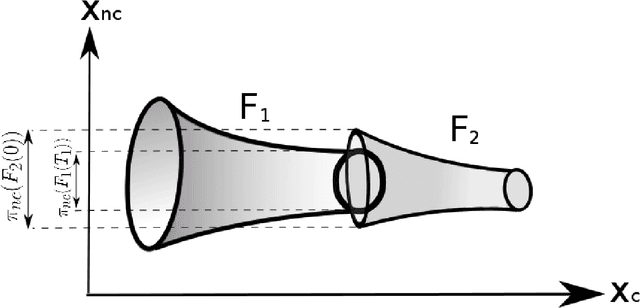
We consider the problem of generating motion plans for a robot that are guaranteed to succeed despite uncertainty in the environment, parametric model uncertainty, and disturbances. Furthermore, we consider scenarios where these plans must be generated in real-time, because constraints such as obstacles in the environment may not be known until they are perceived (with a noisy sensor) at runtime. Our approach is to pre-compute a library of "funnels" along different maneuvers of the system that the state is guaranteed to remain within (despite bounded disturbances) when the feedback controller corresponding to the maneuver is executed. We leverage powerful computational machinery from convex optimization (sums-of-squares programming in particular) to compute these funnels. The resulting funnel library is then used to sequentially compose motion plans at runtime while ensuring the safety of the robot. A major advantage of the work presented here is that by explicitly taking into account the effect of uncertainty, the robot can evaluate motion plans based on how vulnerable they are to disturbances. We demonstrate and validate our method using extensive hardware experiments on a small fixed-wing airplane avoiding obstacles at high speed (~12 mph), along with thorough simulation experiments of ground vehicle and quadrotor models navigating through cluttered environments. To our knowledge, these demonstrations constitute one of the first examples of provably safe and robust control for robotic systems with complex nonlinear dynamics that need to plan in real-time in environments with complex geometric constraints.
Knowledge-Driven Machine Learning: Concept, Model and Case Study on Channel Estimation
Dec 21, 2020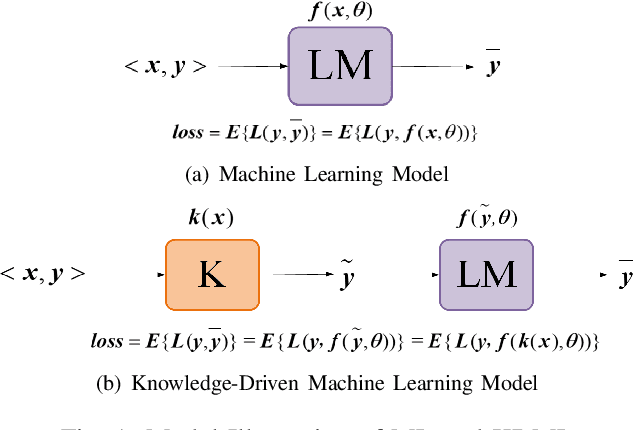
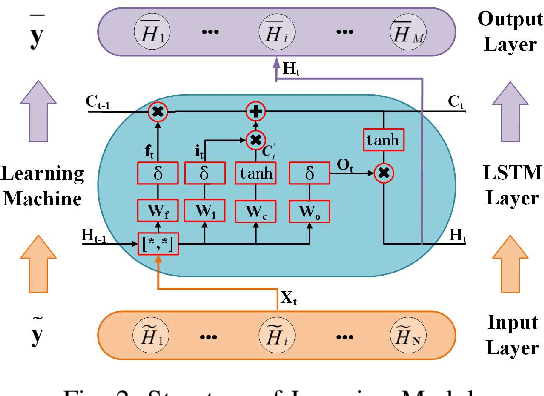
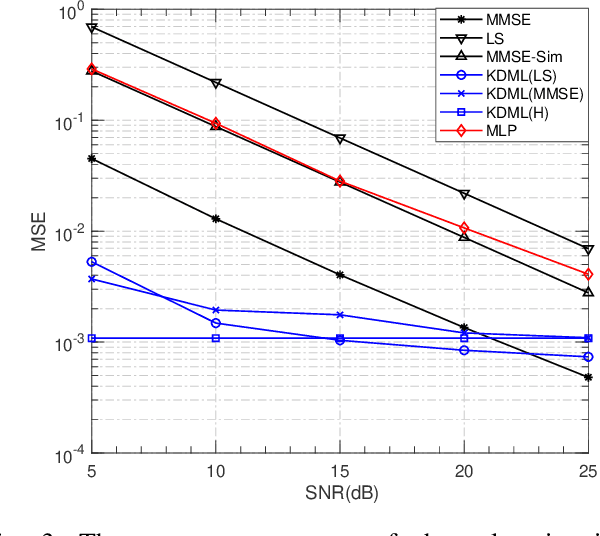
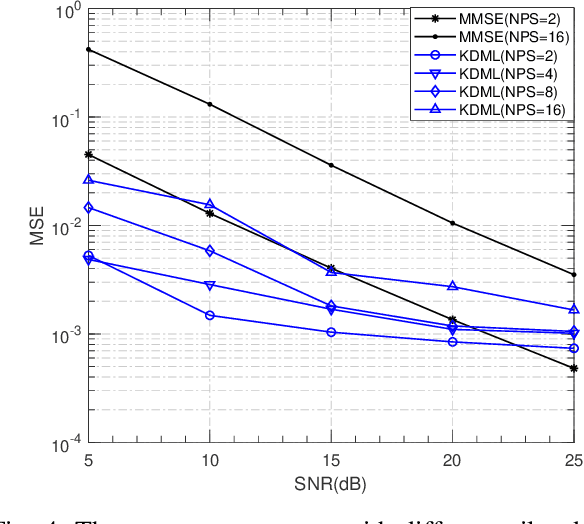
The power of big data and machine learning has been drastically demonstrated in many fields during the past twenty years which somehow leads to the vague even false understanding that the huge amount of precious human knowledge accumulated to date no longer seems to matter. In this paper, we are pioneering to propose the knowledge-driven machine learning(KDML) model to exhibit that knowledge can play an important role in machine learning tasks. KDML takes advantage of domain knowledge to processes the input data by space transforming without any training which enable the space of input and the output data of the neural networks to be identical, so that we can simplify the machine learning network structure and reduce training costs significantly. Channel estimation problems considering the time selective and frequency selective fading in wireless communications are taken as a case study, where we choose least square(LS) and minimum meansquare error(MMSE) as knowledge module and Long Short Term Memory(LSTM) as learning module. The performance obtained by KDML channel estimator obviously outperforms that of knowledge processing or conventional machine learning, respectively. Our work sheds light on the new area of machine learning and knowledge processing.