 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Social Network Analysis of Hadith Narrators from Sahih Bukhari
Feb 03, 2021
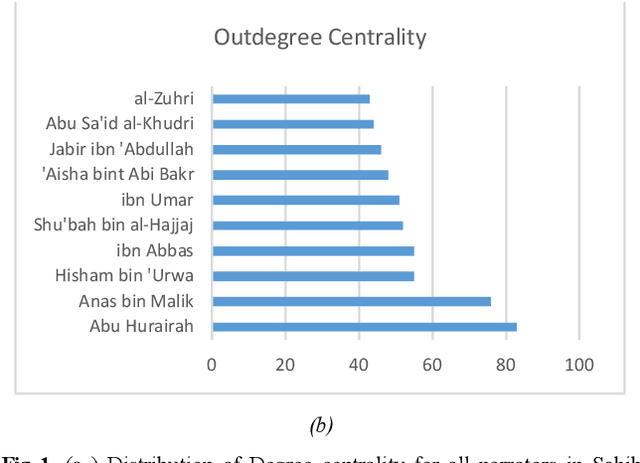
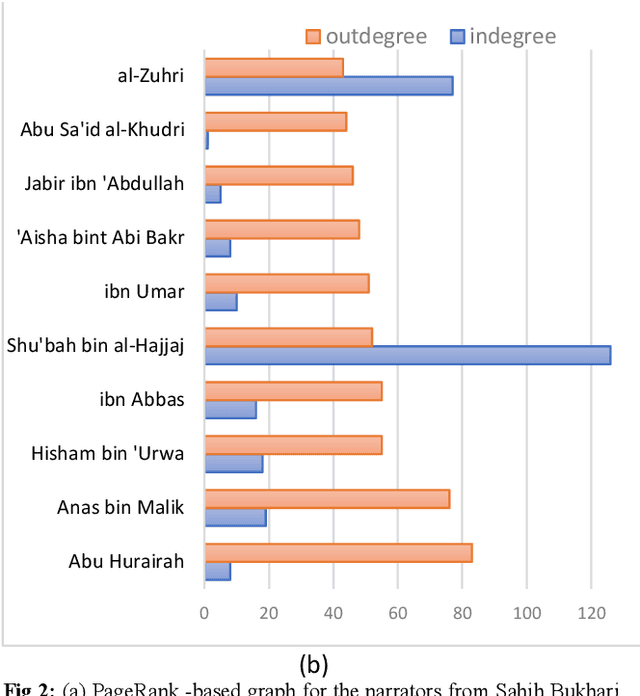
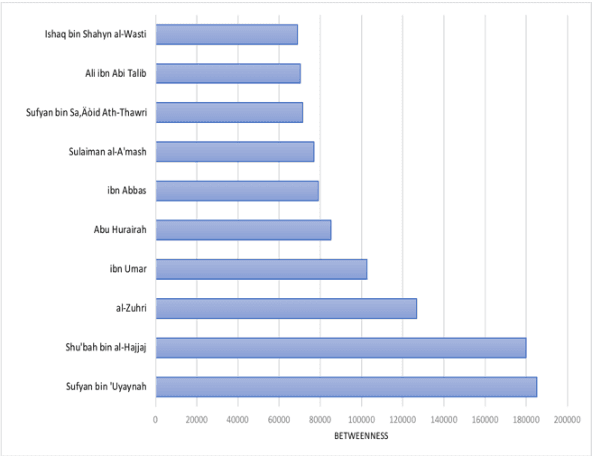

The ahadith, prophetic traditions for the Muslims around the world, are narrations originating from the sayings and the deeds of Prophet Muhammad (pbuh). They are considered one of the fundamental sources of Islamic legislation along with the Quran. The list of persons involved in the narration of each hadith is carefully scrutinized by scholars studying the hadith, with respect to their reputation and authenticity of the hadith. This is due to the its legislative importance in Islamic principles. There were many narrators who contributed to this responsibility of preserving prophetic narrations over the centuries. But to date, no systematic and comprehensive study, based on the social network, has been adapted to understand the contribution of early hadith narrators and the propagation of hadith across generations. In this study, we represented the chain of narrators of the hadith collection from Sahih Bukhari as a social graph. Based on social network analysis (SNA) on this graph, we found that the network of narrators is a scale-free network. We identified a list of influential narrators from the companions as well as the narrators from the second and third-generation who contribute significantly in the propagation of hadith collected in Sahih Bukhari. We discovered sixteen communities from the narrators of Sahih Bukhari. In each of these communities, there are other narrators who contributed significantly to the propagation of prophetic narrations. We also found that most narrators were centered in Makkah and Madinah in the era of companions and, then, gradually the center of hadith narrators shifted towards Kufa, Baghdad and central Asia over a period of time. To the best of our knowledge, this the first comprehensive and systematic study based on SNA, representing the narrators as a social graph to analyze their contribution to the preservation and propagation of hadith.
Primal-dual Learning for the Model-free Risk-constrained Linear Quadratic Regulator
Dec 02, 2020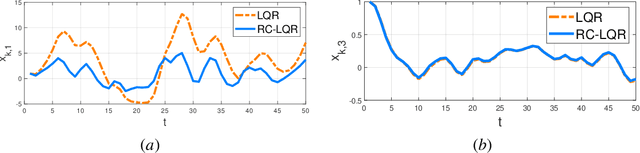
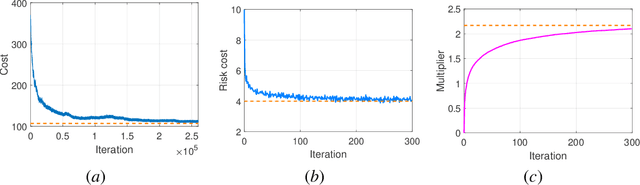
Risk-aware control, though with promise to tackle unexpected events, requires a known exact dynamical model. In this work, we propose a model-free framework to learn a risk-aware controller with a focus on the linear system. We formulate it as a discrete-time infinite-horizon LQR problem with a state predictive variance constraint. To solve it, we parameterize the policy with a feedback gain pair and leverage primal-dual methods to optimize it by solely using data. We first study the optimization landscape of the Lagrangian function and establish the strong duality in spite of its non-convex nature. Alongside, we find that the Lagrangian function enjoys an important local gradient dominance property, which is then exploited to develop a convergent random search algorithm to learn the dual function. Furthermore, we propose a primal-dual algorithm with global convergence to learn the optimal policy-multiplier pair. Finally, we validate our results via simulations.
Globally-scalable Automated Target Recognition (GATR)
Sep 10, 2020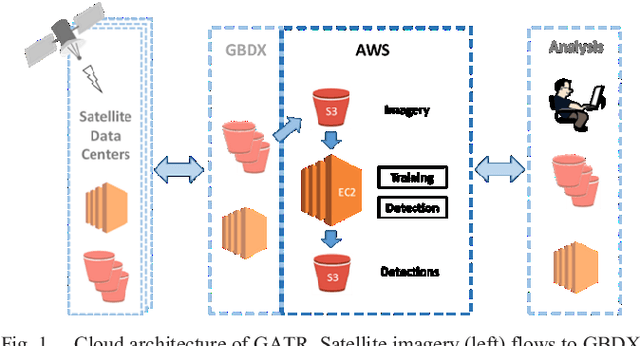
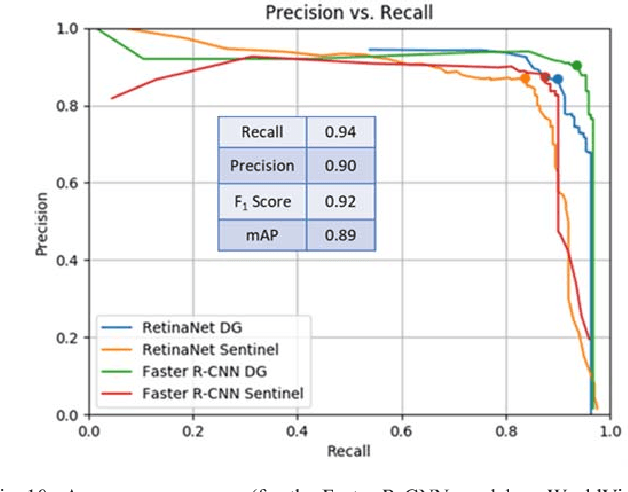
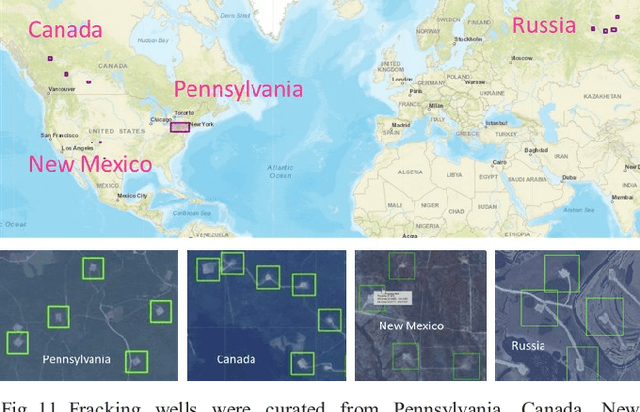
GATR (Globally-scalable Automated Target Recognition) is a Lockheed Martin software system for real-time object detection and classification in satellite imagery on a worldwide basis. GATR uses GPU-accelerated deep learning software to quickly search large geographic regions. On a single GPU it processes imagery at a rate of over 16 square km/sec (or more than 10 Mpixels/sec), and it requires only two hours to search the entire state of Pennsylvania for gas fracking wells. The search time scales linearly with the geographic area, and the processing rate scales linearly with the number of GPUs. GATR has a modular, cloud-based architecture that uses the Maxar GBDX platform and provides an ATR analytic as a service. Applications include broad area search, watch boxes for monitoring ports and airfields, and site characterization. ATR is performed by deep learning models including RetinaNet and Faster R-CNN. Results are presented for the detection of aircraft and fracking wells and show that the recalls exceed 90% even in geographic regions never seen before. GATR is extensible to new targets, such as cars and ships, and it also handles radar and infrared imagery.
* 7 pages, 18 figures, 2019 IEEE Applied Imagery Pattern Recognition Workshop (AIPR)
Learning interaction kernels in stochastic systems of interacting particles from multiple trajectories
Jul 30, 2020
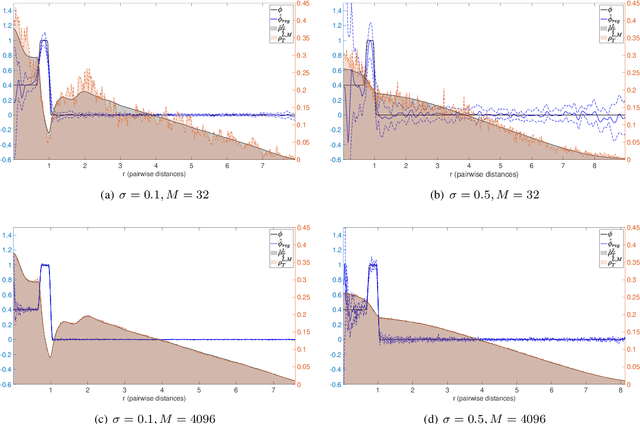

We consider stochastic systems of interacting particles or agents, with dynamics determined by an interaction kernel which only depends on pairwise distances. We study the problem of inferring this interaction kernel from observations of the positions of the particles, in either continuous or discrete time, along multiple independent trajectories. We introduce a nonparametric inference approach to this inverse problem, based on a regularized maximum likelihood estimator constrained to suitable hypothesis spaces adaptive to data. We show that a coercivity condition enables us to control the condition number of this problem and prove the consistency of our estimator, and that in fact it converges at a near-optimal learning rate, equal to the min-max rate of $1$-dimensional non-parametric regression. In particular, this rate is independent of the dimension of the state space, which is typically very high. We also analyze the discretization errors in the case of discrete-time observations, showing that it is of order $1/2$ in terms of the time gaps between observations. This term, when large, dominates the sampling error and the approximation error, preventing convergence of the estimator. Finally, we exhibit an efficient parallel algorithm to construct the estimator from data, and we demonstrate the effectiveness of our algorithm with numerical tests on prototype systems including stochastic opinion dynamics and a Lennard-Jones model.
Neural Model-based Optimization with Right-Censored Observations
Sep 29, 2020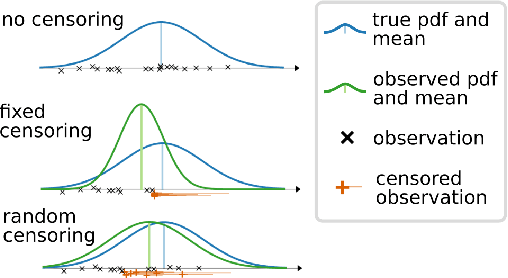
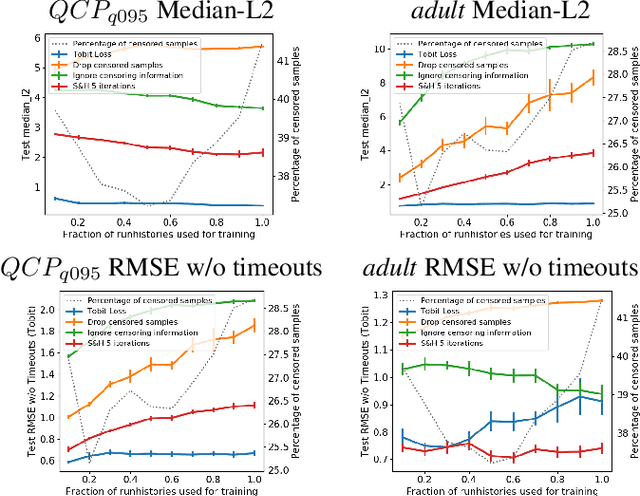

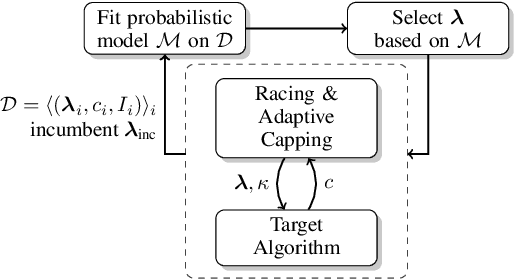
In many fields of study, we only observe lower bounds on the true response value of some experiments. When fitting a regression model to predict the distribution of the outcomes, we cannot simply drop these right-censored observations, but need to properly model them. In this work, we focus on the concept of censored data in the light of model-based optimization where prematurely terminating evaluations (and thus generating right-censored data) is a key factor for efficiency, e.g., when searching for an algorithm configuration that minimizes runtime of the algorithm at hand. Neural networks (NNs) have been demonstrated to work well at the core of model-based optimization procedures and here we extend them to handle these censored observations. We propose (i)~a loss function based on the Tobit model to incorporate censored samples into training and (ii) use an ensemble of networks to model the posterior distribution. To nevertheless be efficient in terms of optimization-overhead, we propose to use Thompson sampling s.t. we only need to train a single NN in each iteration. Our experiments show that our trained regression models achieve a better predictive quality than several baselines and that our approach achieves new state-of-the-art performance for model-based optimization on two optimization problems: minimizing the solution time of a SAT solver and the time-to-accuracy of neural networks.
Integration of IRS in Indoor VLC Systems: Challenges, Potential and Promising Solutions
Jan 15, 2021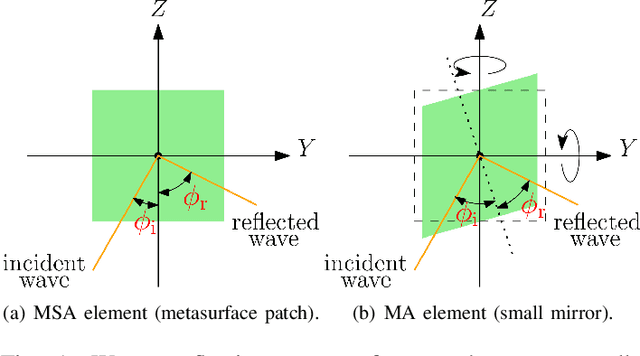
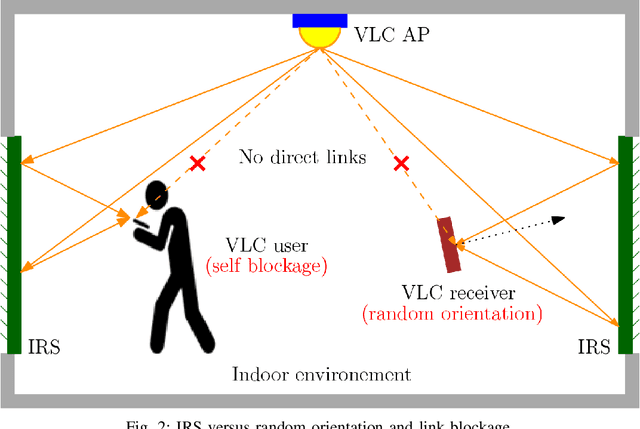
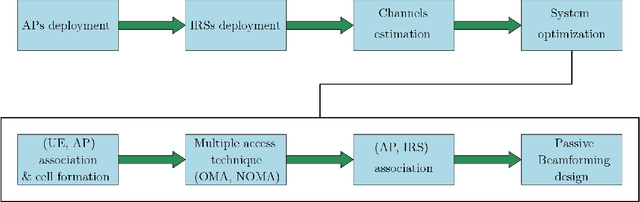
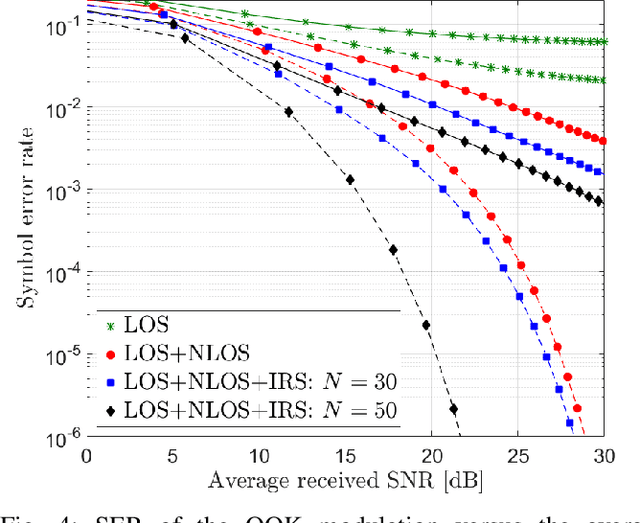
Visible light communication (VLC) is an optical wireless communication technology that is considered a promising solution for high-speed indoor connectivity. Unlike the case in conventional radio-frequency wireless systems, the VLC channel is not isotropic, meaning that the device orientation affects the channel gain significantly. In addition, due to the use of optical frequency bands, the presence of different obstacles (e.g., walls, human bodies, furniture) may easily block the VLC links. One solution to overcome these issues is the integration of the intelligent reflective surface (IRS), which is a new and revolutionizing technology that has the potential to significantly improve the performance of wireless networks. IRS is capable of smartly reconfiguring the wireless propagation environment with the use of massive low-cost passive reflecting elements integrated on a planar surface. In this paper, a framework for integrating IRS in indoor VLC systems is presented. We give an overview of IRS, including its advantages, different types and main applications in VLC systems, where we demonstrate the potential of IRS in overcoming the effects of random device orientation and links blockages. We discuss key factors pertaining to the design and integration of IRS in VLC systems, namely, the deployment of IRSs, the channel state information acquisition, the optimization of IRS configuration and the real-time IRS control. We also lay out a number of promising research directions that center around the integration of IRS in indoor VLC systems.
On Target Segmentation for Direct Speech Translation
Sep 10, 2020
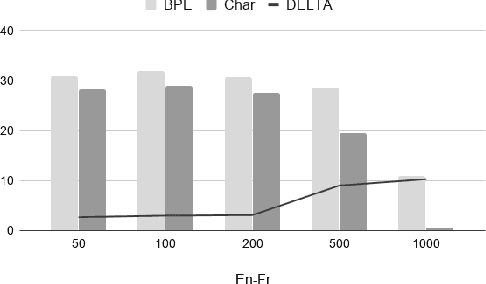
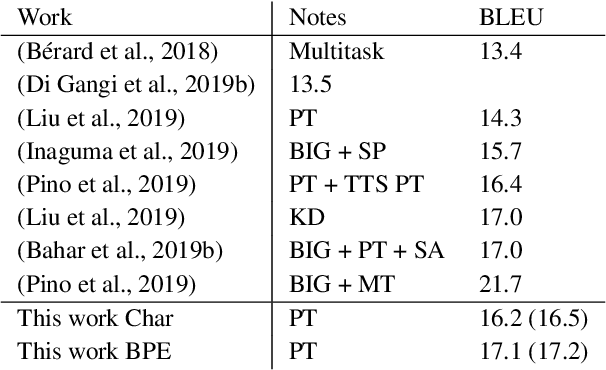
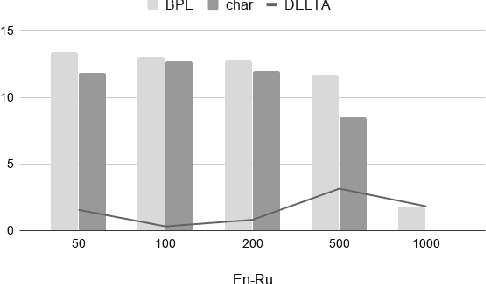
Recent studies on direct speech translation show continuous improvements by means of data augmentation techniques and bigger deep learning models. While these methods are helping to close the gap between this new approach and the more traditional cascaded one, there are many incongruities among different studies that make it difficult to assess the state of the art. Surprisingly, one point of discussion is the segmentation of the target text. Character-level segmentation has been initially proposed to obtain an open vocabulary, but it results on long sequences and long training time. Then, subword-level segmentation became the state of the art in neural machine translation as it produces shorter sequences that reduce the training time, while being superior to word-level models. As such, recent works on speech translation started using target subwords despite the initial use of characters and some recent claims of better results at the character level. In this work, we perform an extensive comparison of the two methods on three benchmarks covering 8 language directions and multilingual training. Subword-level segmentation compares favorably in all settings, outperforming its character-level counterpart in a range of 1 to 3 BLEU points.
Controllable Neural Prosody Synthesis
Aug 07, 2020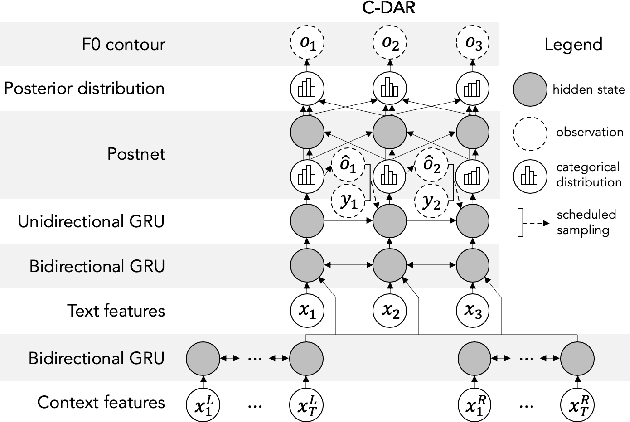

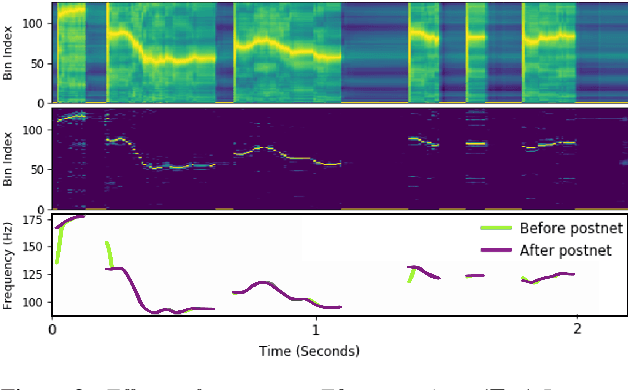
Speech synthesis has recently seen significant improvements in fidelity, driven by the advent of neural vocoders and neural prosody generators. However, these systems lack intuitive user controls over prosody, making them unable to rectify prosody errors (e.g., misplaced emphases and contextually inappropriate emotions) or generate prosodies with diverse speaker excitement levels and emotions. We address these limitations with a user-controllable, context-aware neural prosody generator. Given a real or synthesized speech recording, our model allows a user to input prosody constraints for certain time frames and generates the remaining time frames from input text and contextual prosody. We also propose a pitch-shifting neural vocoder to modify input speech to match the synthesized prosody. Through objective and subjective evaluations we show that we can successfully incorporate user control into our prosody generation model without sacrificing the overall naturalness of the synthesized speech.
Gaussian Process Bandit Optimization of the Thermodynamic Variational Objective
Oct 31, 2020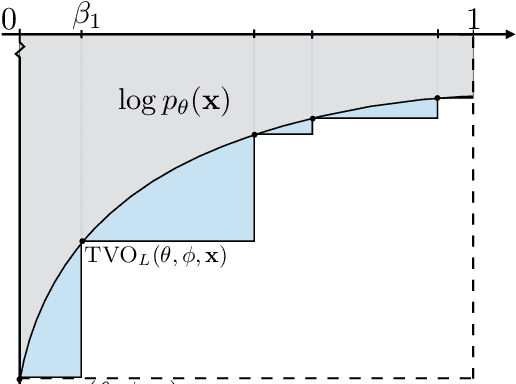

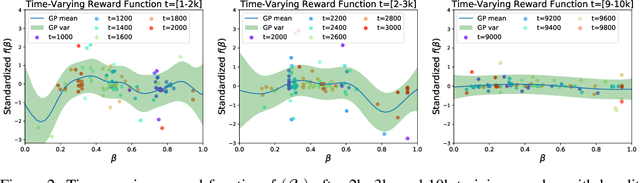

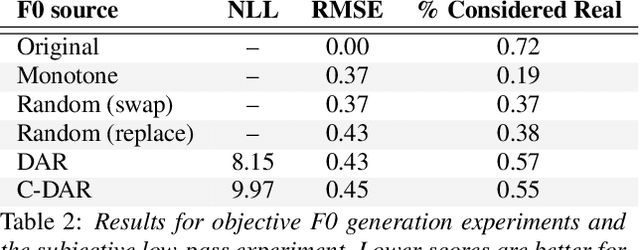
Achieving the full promise of the Thermodynamic Variational Objective (TVO), a recently proposed variational lower bound on the log evidence involving a one-dimensional Riemann integral approximation, requires choosing a "schedule" of sorted discretization points. This paper introduces a bespoke Gaussian process bandit optimization method for automatically choosing these points. Our approach not only automates their one-time selection, but also dynamically adapts their positions over the course of optimization, leading to improved model learning and inference. We provide theoretical guarantees that our bandit optimization converges to the regret-minimizing choice of integration points. Empirical validation of our algorithm is provided in terms of improved learning and inference in Variational Autoencoders and Sigmoid Belief Networks.
An algorithm for real-time restructuring of a ranging-based localization network
Apr 25, 2018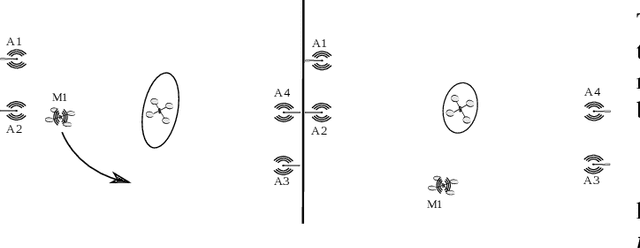
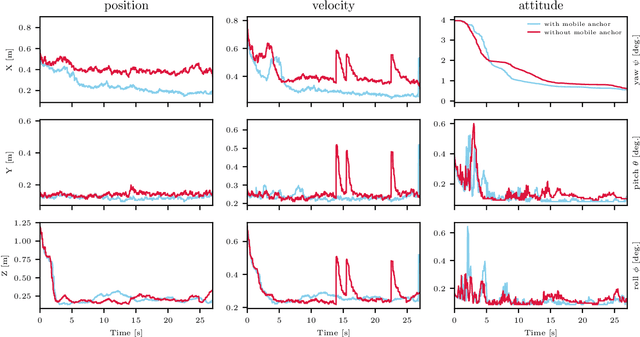
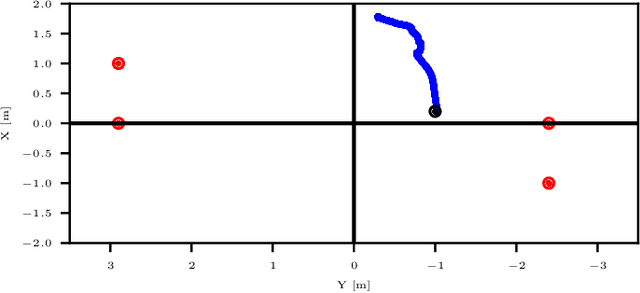

This paper presents a method to improve the localization accuracy of robots operating in a range-based localization network. The method is favorable especially when the robots operate in harsh environments where the access to a robust and reliable localization system is limited. A state estimator is used for a six degree of freedom object using inertial sensors as well as an Ultra-wideband (UWB) range measurement sensor. The estimator is incorporated into an adaptive algorithm, improving the localization quality of an agent by using a mobile UWB ranging sensor, where the mobile anchor moves to improve localization quality. The algorithm reconstructs localization network in real-time to minimize the determinant of the covariance matrix in the sense of least square error. Finally, the proposed algorithm is experimentally validated in a network consisting of one mobile and four fixed anchors.