 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DeepGMR: Learning Latent Gaussian Mixture Models for Registration
Aug 20, 2020
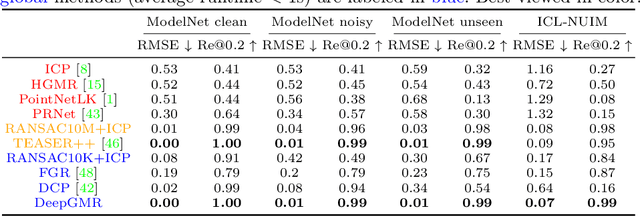
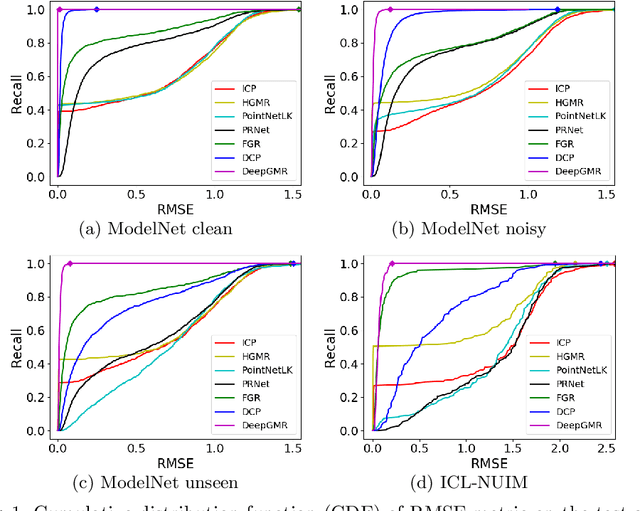
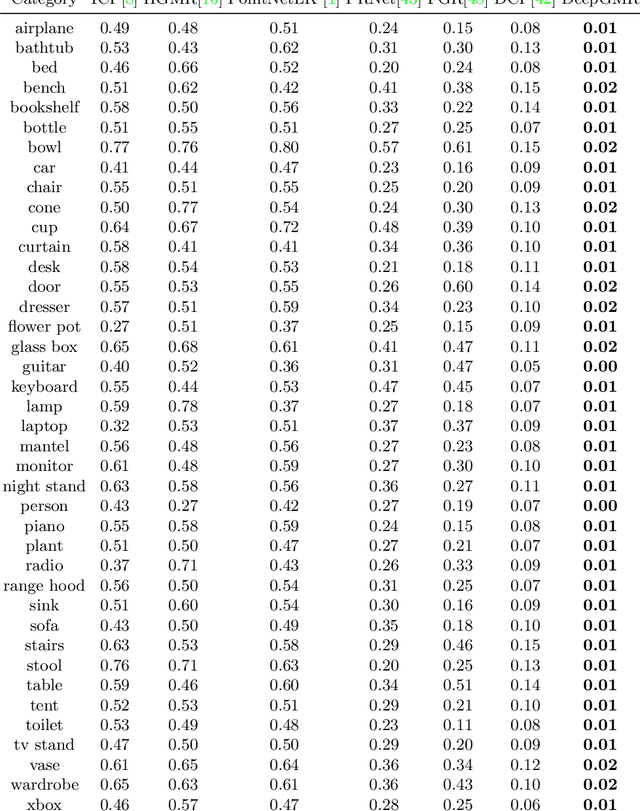
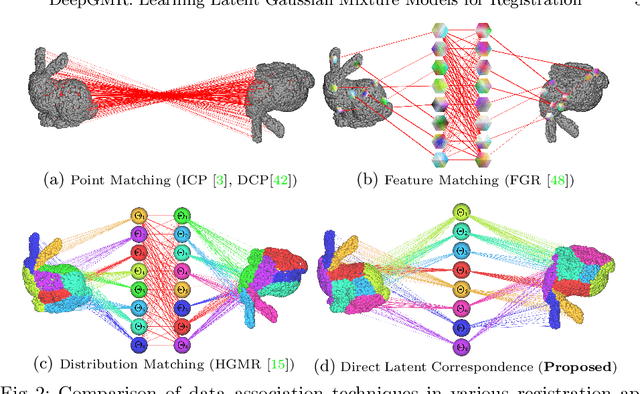
Point cloud registration is a fundamental problem in 3D computer vision, graphics and robotics. For the last few decades, existing registration algorithms have struggled in situations with large transformations, noise, and time constraints. In this paper, we introduce Deep Gaussian Mixture Registration (DeepGMR), the first learning-based registration method that explicitly leverages a probabilistic registration paradigm by formulating registration as the minimization of KL-divergence between two probability distributions modeled as mixtures of Gaussians. We design a neural network that extracts pose-invariant correspondences between raw point clouds and Gaussian Mixture Model (GMM) parameters and two differentiable compute blocks that recover the optimal transformation from matched GMM parameters. This construction allows the network learn an SE(3)-invariant feature space, producing a global registration method that is real-time, generalizable, and robust to noise. Across synthetic and real-world data, our proposed method shows favorable performance when compared with state-of-the-art geometry-based and learning-based registration methods.
Differentially Private Online Submodular Maximization
Oct 24, 2020In this work we consider the problem of online submodular maximization under a cardinality constraint with differential privacy (DP). A stream of $T$ submodular functions over a common finite ground set $U$ arrives online, and at each time-step the decision maker must choose at most $k$ elements of $U$ before observing the function. The decision maker obtains a payoff equal to the function evaluated on the chosen set, and aims to learn a sequence of sets that achieves low expected regret. In the full-information setting, we develop an $(\varepsilon,\delta)$-DP algorithm with expected $(1-1/e)$-regret bound of $\mathcal{O}\left( \frac{k^2\log |U|\sqrt{T \log k/\delta}}{\varepsilon} \right)$. This algorithm contains $k$ ordered experts that learn the best marginal increments for each item over the whole time horizon while maintaining privacy of the functions. In the bandit setting, we provide an $(\varepsilon,\delta+ O(e^{-T^{1/3}}))$-DP algorithm with expected $(1-1/e)$-regret bound of $\mathcal{O}\left( \frac{\sqrt{\log k/\delta}}{\varepsilon} (k (|U| \log |U|)^{1/3})^2 T^{2/3} \right)$. Our algorithms contains $k$ ordered experts that learn the best marginal item to select given the items chosen her predecessors, while maintaining privacy of the functions. One challenge for privacy in this setting is that the payoff and feedback of expert $i$ depends on the actions taken by her $i-1$ predecessors. This particular type of information leakage is not covered by post-processing, and new analysis is required. Our techniques for maintaining privacy with feedforward may be of independent interest.
Pixie: A System for Recommending 3+ Billion Items to 200+ Million Users in Real-Time
Nov 21, 2017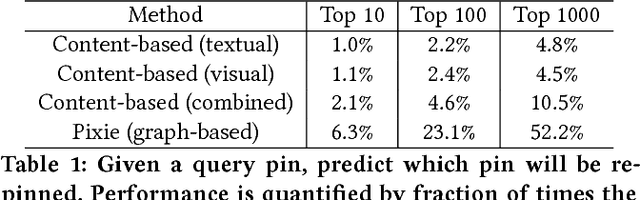
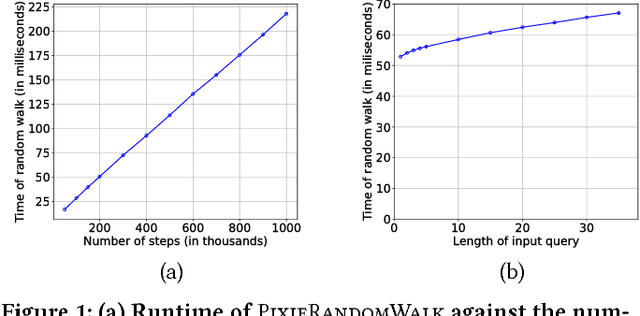

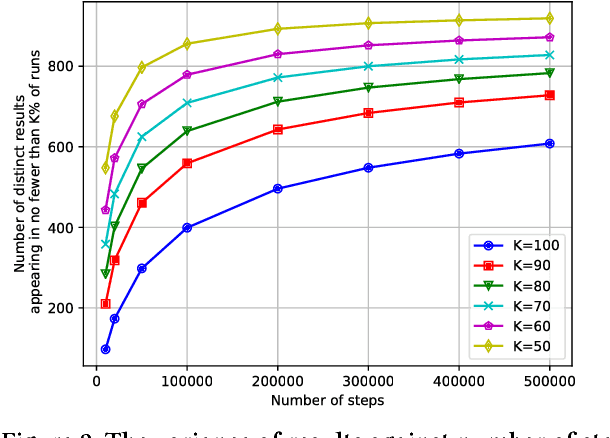
User experience in modern content discovery applications critically depends on high-quality personalized recommendations. However, building systems that provide such recommendations presents a major challenge due to a massive pool of items, a large number of users, and requirements for recommendations to be responsive to user actions and generated on demand in real-time. Here we present Pixie, a scalable graph-based real-time recommender system that we developed and deployed at Pinterest. Given a set of user-specific pins as a query, Pixie selects in real-time from billions of possible pins those that are most related to the query. To generate recommendations, we develop Pixie Random Walk algorithm that utilizes the Pinterest object graph of 3 billion nodes and 17 billion edges. Experiments show that recommendations provided by Pixie lead up to 50% higher user engagement when compared to the previous Hadoop-based production system. Furthermore, we develop a graph pruning strategy at that leads to an additional 58% improvement in recommendations. Last, we discuss system aspects of Pixie, where a single server executes 1,200 recommendation requests per second with 60 millisecond latency. Today, systems backed by Pixie contribute to more than 80% of all user engagement on Pinterest.
Very Deep VAEs Generalize Autoregressive Models and Can Outperform Them on Images
Nov 20, 2020


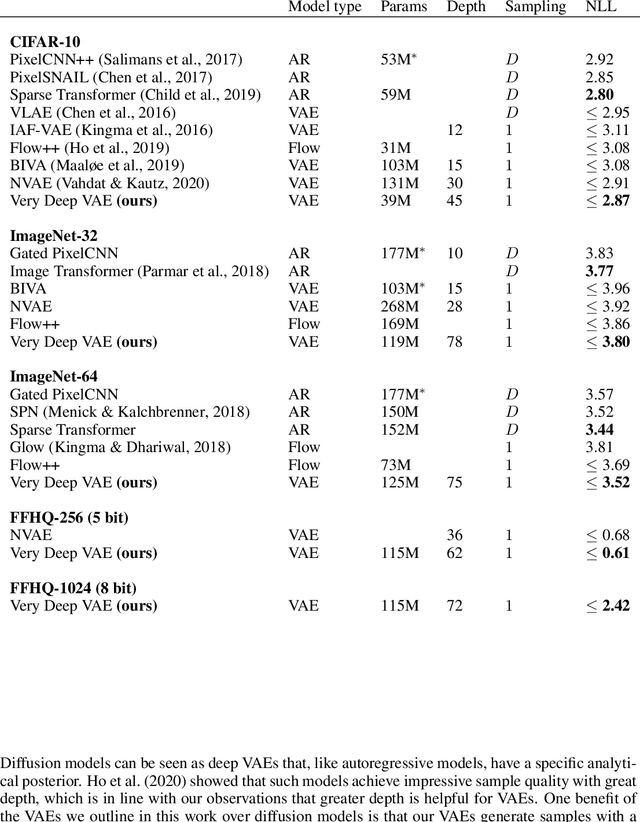
We present a hierarchical VAE that, for the first time, outperforms the PixelCNN in log-likelihood on all natural image benchmarks. We begin by observing that VAEs can actually implement autoregressive models, and other, more efficient generative models, if made sufficiently deep. Despite this, autoregressive models have traditionally outperformed VAEs. We test if insufficient depth explains the performance gap by by scaling a VAE to greater stochastic depth than previously explored and evaluating it on CIFAR-10, ImageNet, and FFHQ. We find that, in comparison to the PixelCNN, these very deep VAEs achieve higher likelihoods, use fewer parameters, generate samples thousands of times faster, and are more easily applied to high-resolution images. We visualize the generative process and show the VAEs learn efficient hierarchical visual representations. We release our source code and models at https://github.com/openai/vdvae.
Complex-valued Gaussian Process Regression for Time Series Analysis
Dec 07, 2017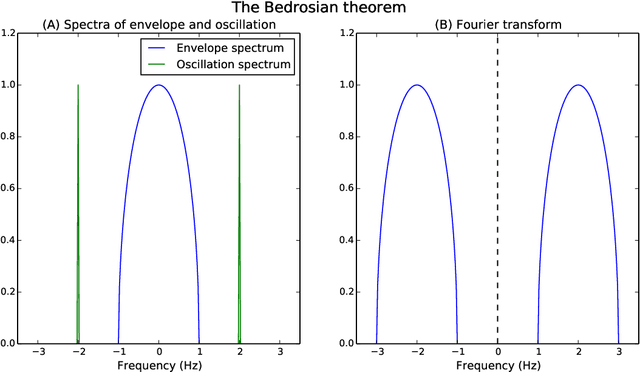
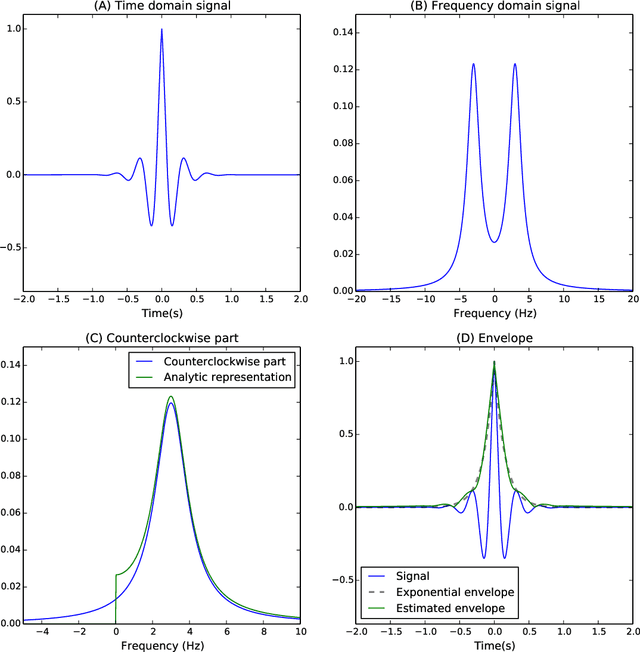
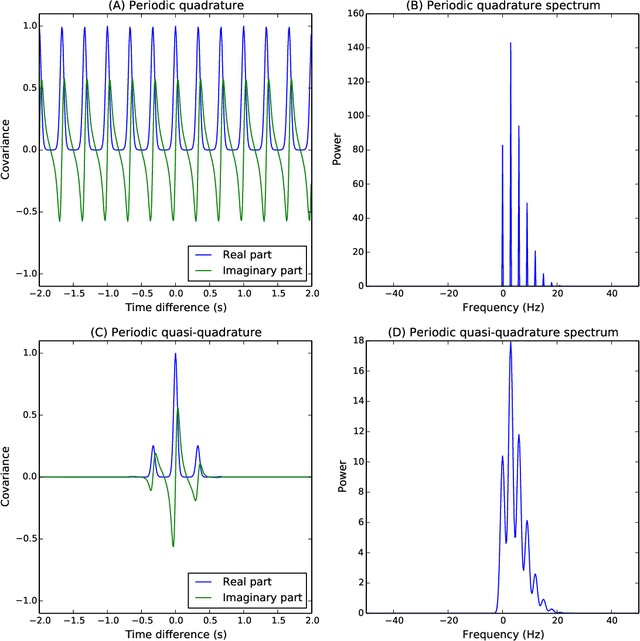
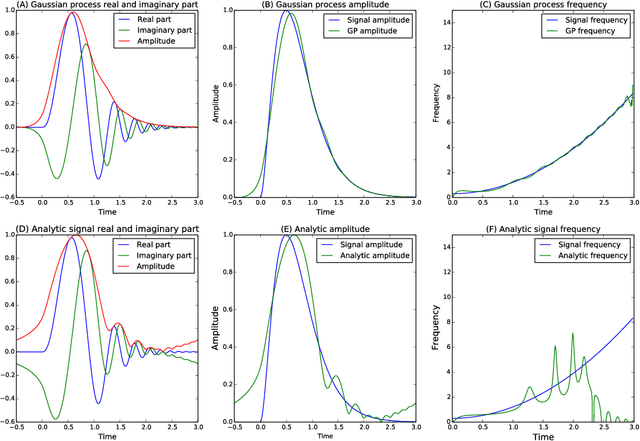
The construction of synthetic complex-valued signals from real-valued observations is an important step in many time series analysis techniques. The most widely used approach is based on the Hilbert transform, which maps the real-valued signal into its quadrature component. In this paper, we define a probabilistic generalization of this approach. We model the observable real-valued signal as the real part of a latent complex-valued Gaussian process. In order to obtain the appropriate statistical relationship between its real and imaginary parts, we define two new classes of complex-valued covariance functions. Through an analysis of simulated chirplets and stochastic oscillations, we show that the resulting Gaussian process complex-valued signal provides a better estimate of the instantaneous amplitude and frequency than the established approaches. Furthermore, the complex-valued Gaussian process regression allows to incorporate prior information about the structure in signal and noise and thereby to tailor the analysis to the features of the signal. As a example, we analyze the non-stationary dynamics of brain oscillations in the alpha band, as measured using magneto-encephalography.
Extracting full-field subpixel structural displacements from videos via deep learning
Aug 31, 2020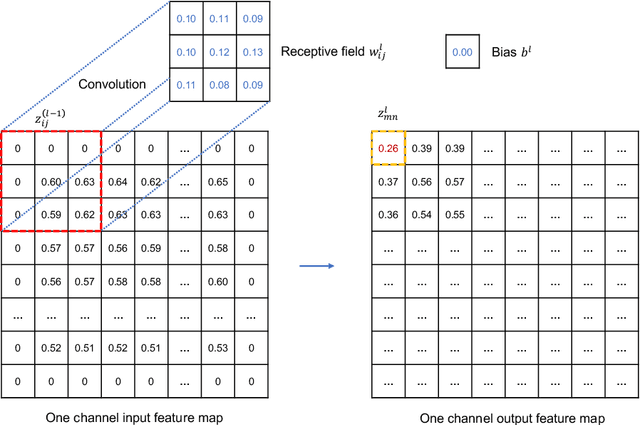
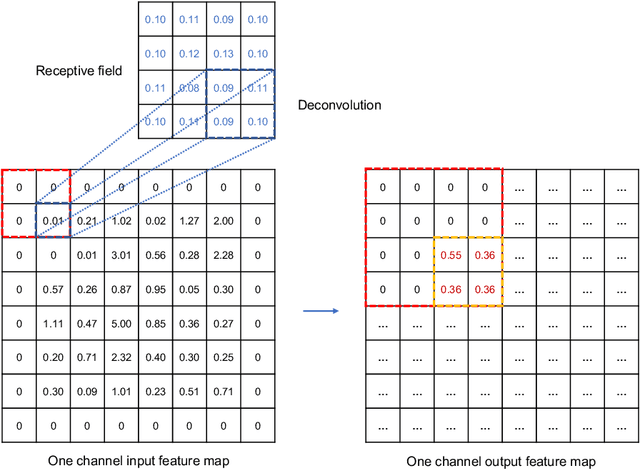
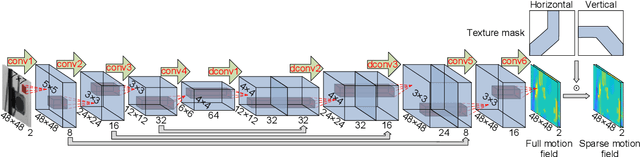
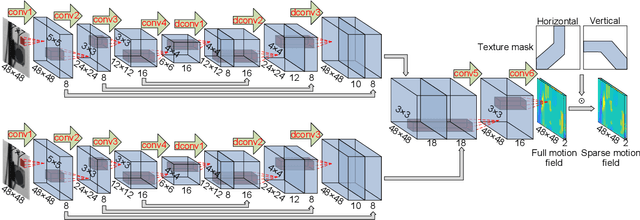
This paper develops a deep learning framework based on convolutional neural networks (CNNs) that enable real-time extraction of full-field subpixel structural displacements from videos. In particular, two new CNN architectures are designed and trained on a dataset generated by the phase-based motion extraction method from a single lab-recorded high-speed video of a dynamic structure. As displacement is only reliable in the regions with sufficient texture contrast, the sparsity of motion field induced by the texture mask is considered via the network architecture design and loss function definition. Results show that, with the supervision of full and sparse motion field, the trained network is capable of identifying the pixels with sufficient texture contrast as well as their subpixel motions. The performance of the trained networks is tested on various videos of other structures to extract the full-field motion (e.g., displacement time histories), which indicates that the trained networks have generalizability to accurately extract full-field subtle displacements for pixels with sufficient texture contrast.
Social Network Analysis of Hadith Narrators from Sahih Bukhari
Feb 03, 2021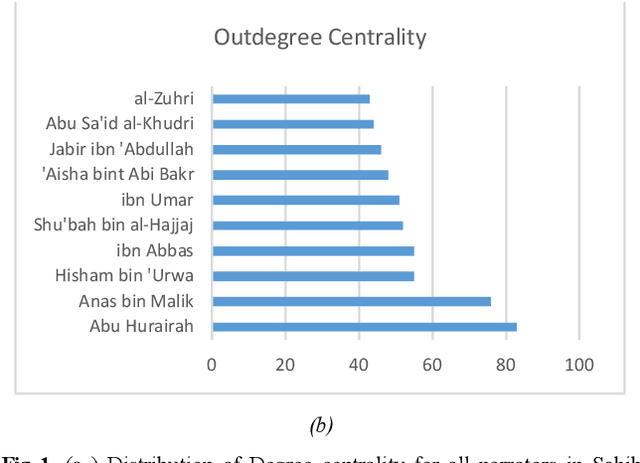
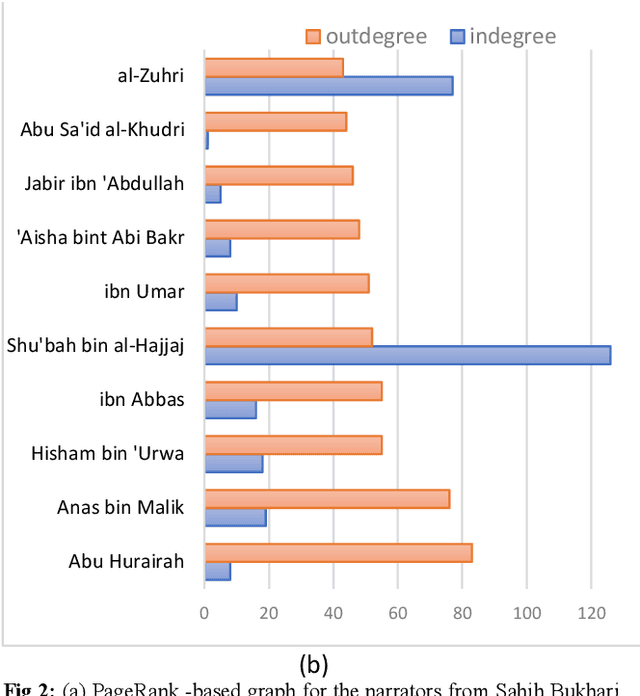
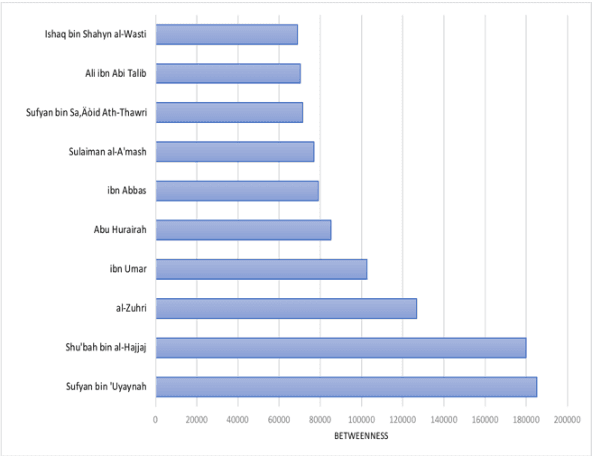

The ahadith, prophetic traditions for the Muslims around the world, are narrations originating from the sayings and the deeds of Prophet Muhammad (pbuh). They are considered one of the fundamental sources of Islamic legislation along with the Quran. The list of persons involved in the narration of each hadith is carefully scrutinized by scholars studying the hadith, with respect to their reputation and authenticity of the hadith. This is due to the its legislative importance in Islamic principles. There were many narrators who contributed to this responsibility of preserving prophetic narrations over the centuries. But to date, no systematic and comprehensive study, based on the social network, has been adapted to understand the contribution of early hadith narrators and the propagation of hadith across generations. In this study, we represented the chain of narrators of the hadith collection from Sahih Bukhari as a social graph. Based on social network analysis (SNA) on this graph, we found that the network of narrators is a scale-free network. We identified a list of influential narrators from the companions as well as the narrators from the second and third-generation who contribute significantly in the propagation of hadith collected in Sahih Bukhari. We discovered sixteen communities from the narrators of Sahih Bukhari. In each of these communities, there are other narrators who contributed significantly to the propagation of prophetic narrations. We also found that most narrators were centered in Makkah and Madinah in the era of companions and, then, gradually the center of hadith narrators shifted towards Kufa, Baghdad and central Asia over a period of time. To the best of our knowledge, this the first comprehensive and systematic study based on SNA, representing the narrators as a social graph to analyze their contribution to the preservation and propagation of hadith.
Cycloidal Trajectory Realization on Staircase with Optimal Trajectory Tracking Control based on Neural Network Temporal Quantized Lagrange Dynamics (NNTQLD)
Dec 02, 2020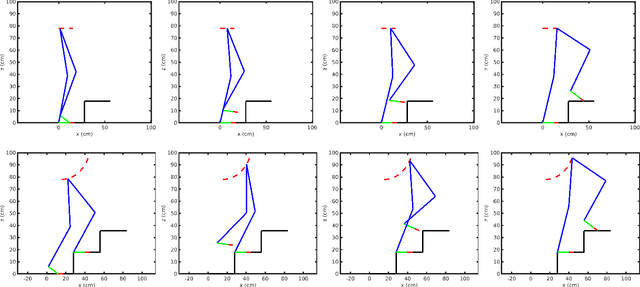
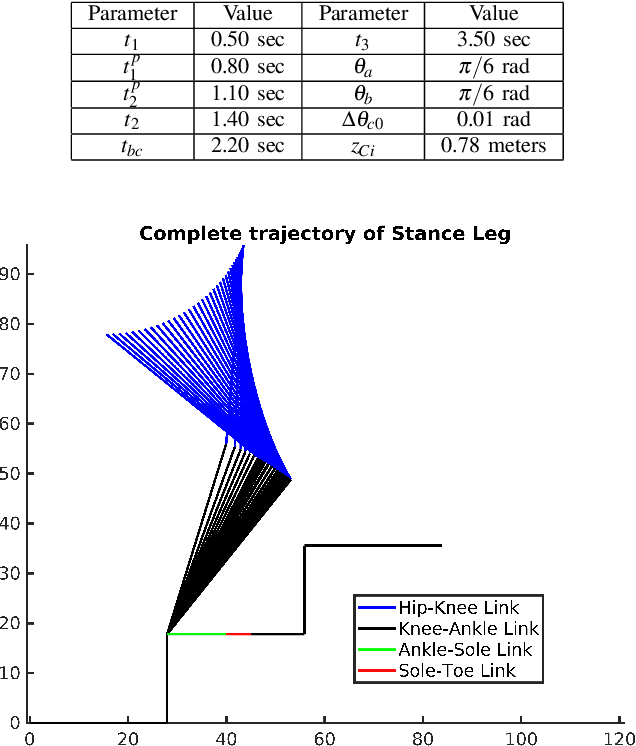
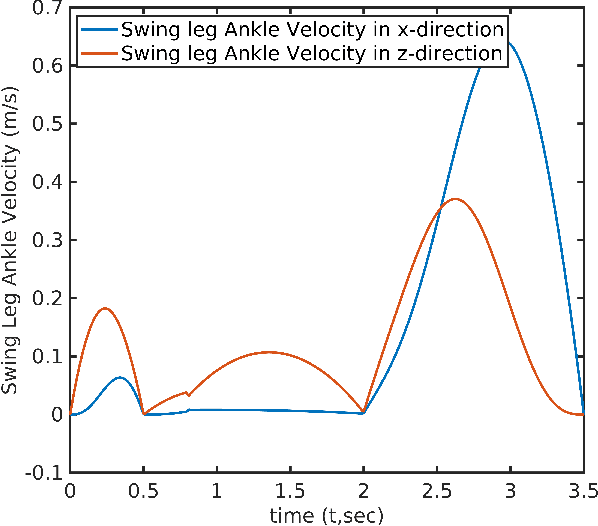
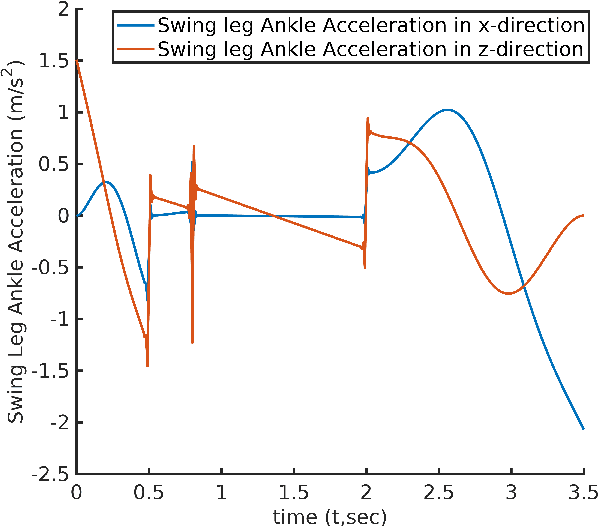
In this paper, a novel optimal technique for joint angles trajectory tracking control of a biped robot with toe foot is proposed. For the task of climbing stairs by a 9 link biped model, a cycloid trajectory for swing phase is proposed in such a way that the cycloid variables depend on the staircase dimensions. Zero Moment Point(ZMP) criteria is taken for satisfying stability constraint. This paper mainly can be divided into 4 steps: 1) Planning stable cycloid trajectory for initial step and subsequent step for climbing upstairs. 2) Inverse Kinematics using unsupervised artificial neural network with knot shifting procedure for jerk minimization. 3) Modeling Dynamics for Toe foot biped model using Lagrange Dynamics along with contact modeling using spring damper system , and finally 4) Real time joint angle trajectory tracking optimization using Temporal Quantized Lagrange Dynamics which takes inverse kinematics output from neural network as its inputs. Generated patterns have been simulated in MATLAB.
Cyber Threat Intelligence for Secure Smart City
Jul 26, 2020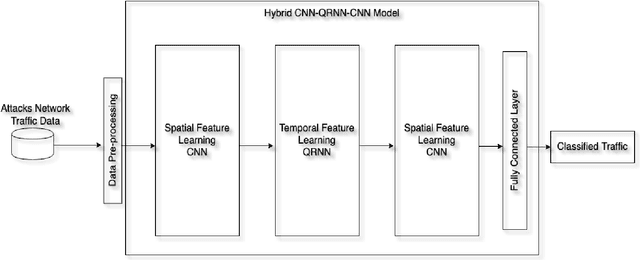
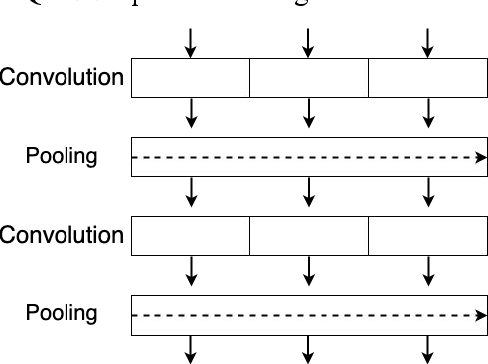

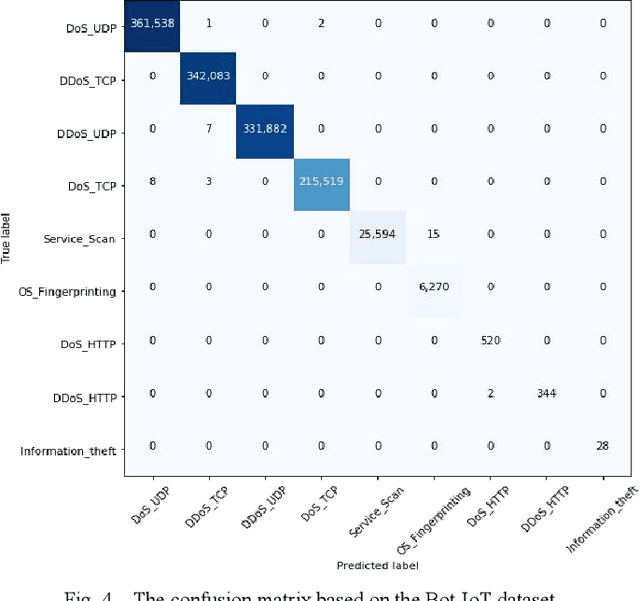
Smart city improved the quality of life for the citizens by implementing information communication technology (ICT) such as the internet of things (IoT). Nevertheless, the smart city is a critical environment that needs to secure it is network and data from intrusions and attacks. This work proposes a hybrid deep learning (DL) model for cyber threat intelligence (CTI) to improve threats classification performance based on convolutional neural network (CNN) and quasi-recurrent neural network (QRNN). We use QRNN to provide a real-time threat classification model. The evaluation results of the proposed model compared to the state-of-the-art models show that the proposed model outperformed the other models. Therefore, it will help in classifying the smart city threats in a reasonable time.
A Review of Network Inference Techniques for Neural Activation Time Series
Jun 20, 2018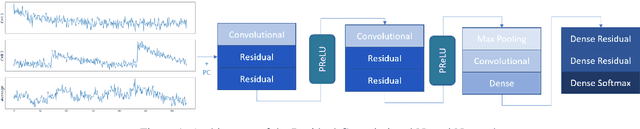
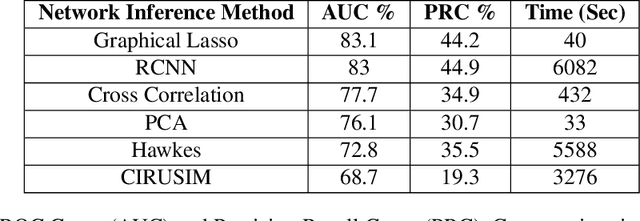

Studying neural connectivity is considered one of the most promising and challenging areas of modern neuroscience. The underpinnings of cognition are hidden in the way neurons interact with each other. However, our experimental methods of studying real neural connections at a microscopic level are still arduous and costly. An efficient alternative is to infer connectivity based on the neuronal activations using computational methods. A reliable method for network inference, would not only facilitate research of neural circuits without the need of laborious experiments but also reveal insights on the underlying mechanisms of the brain. In this work, we perform a review of methods for neural circuit inference given the activation time series of the neural population. Approaching it from machine learning perspective, we divide the methodologies into unsupervised and supervised learning. The methods are based on correlation metrics, probabilistic point processes, and neural networks. Furthermore, we add a data mining methodology inspired by influence estimation in social networks as a new supervised learning approach. For comparison, we use the small version of the Chalearn Connectomics competition, that is accompanied with ground truth connections between neurons. The experiments indicate that unsupervised learning methods perform better, however, supervised methods could surpass them given enough data and resources.