 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TP-LSD: Tri-Points Based Line Segment Detector
Sep 11, 2020
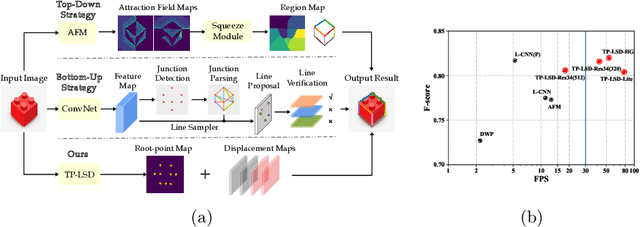
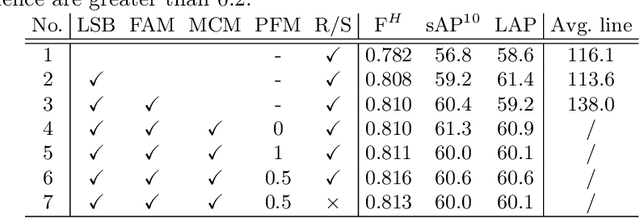

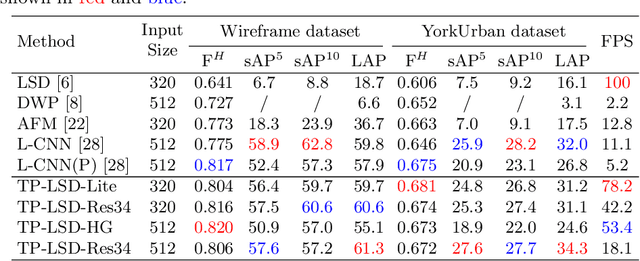
This paper proposes a novel deep convolutional model, Tri-Points Based Line Segment Detector (TP-LSD), to detect line segments in an image at real-time speed. The previous related methods typically use the two-step strategy, relying on either heuristic post-process or extra classifier. To realize one-step detection with a faster and more compact model, we introduce the tri-points representation, converting the line segment detection to the end-to-end prediction of a root-point and two endpoints for each line segment. TP-LSD has two branches: tri-points extraction branch and line segmentation branch. The former predicts the heat map of root-points and the two displacement maps of endpoints. The latter segments the pixels on straight lines out from background. Moreover, the line segmentation map is reused in the first branch as structural prior. We propose an additional novel evaluation metric and evaluate our method on Wireframe and YorkUrban datasets, demonstrating not only the competitive accuracy compared to the most recent methods, but also the real-time run speed up to 78 FPS with the $320\times 320$ input.
* Accepted by ECCV 2020
Fitting very flexible models: Linear regression with large numbers of parameters
Jan 15, 2021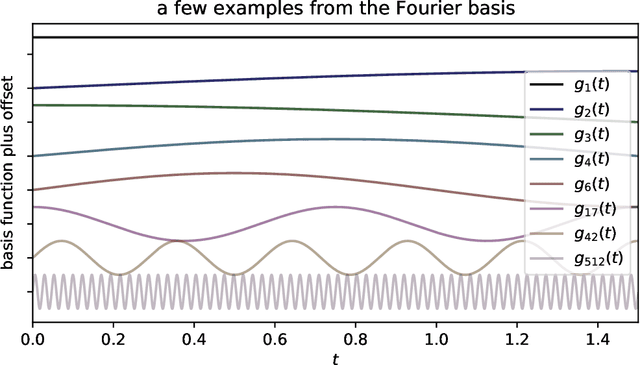
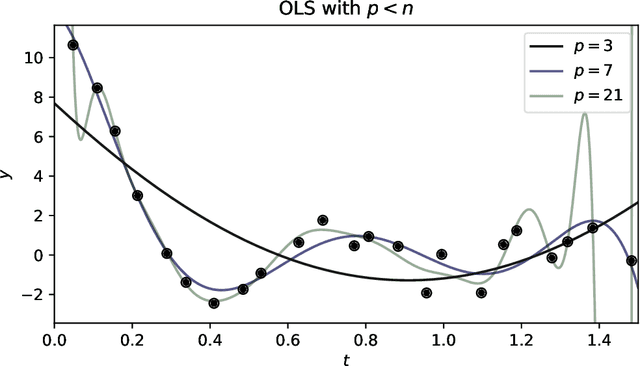
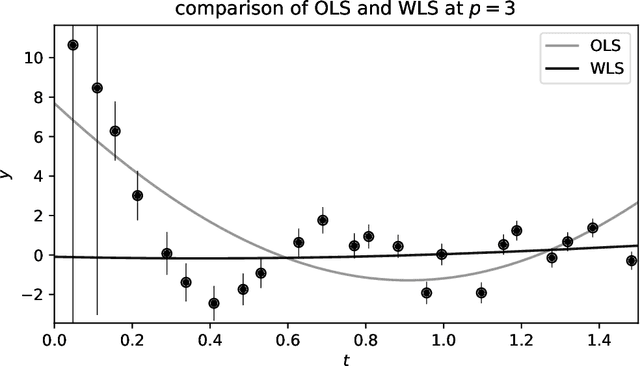
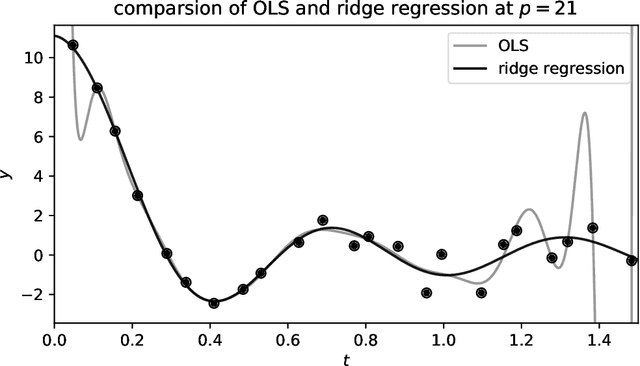
There are many uses for linear fitting; the context here is interpolation and denoising of data, as when you have calibration data and you want to fit a smooth, flexible function to those data. Or you want to fit a flexible function to de-trend a time series or normalize a spectrum. In these contexts, investigators often choose a polynomial basis, or a Fourier basis, or wavelets, or something equally general. They also choose an order, or number of basis functions to fit, and (often) some kind of regularization. We discuss how this basis-function fitting is done, with ordinary least squares and extensions thereof. We emphasize that it is often valuable to choose far more parameters than data points, despite folk rules to the contrary: Suitably regularized models with enormous numbers of parameters generalize well and make good predictions for held-out data; over-fitting is not (mainly) a problem of having too many parameters. It is even possible to take the limit of infinite parameters, at which, if the basis and regularization are chosen correctly, the least-squares fit becomes the mean of a Gaussian process. We recommend cross-validation as a good empirical method for model selection (for example, setting the number of parameters and the form of the regularization), and jackknife resampling as a good empirical method for estimating the uncertainties of the predictions made by the model. We also give advice for building stable computational implementations.
Tensor-Train Networks for Learning Predictive Modeling of Multidimensional Data
Jan 22, 2021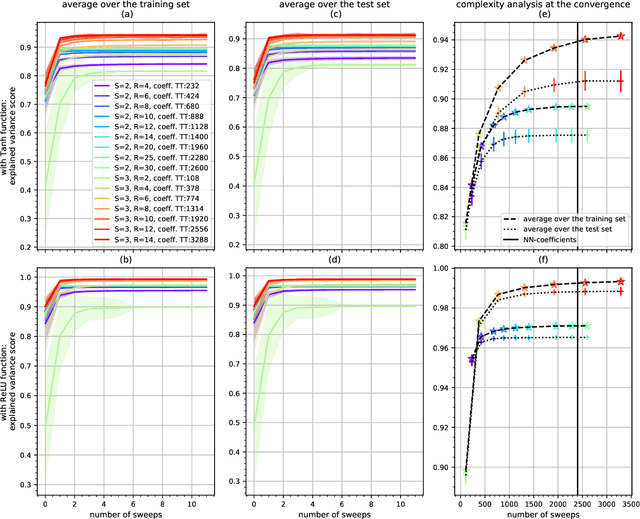
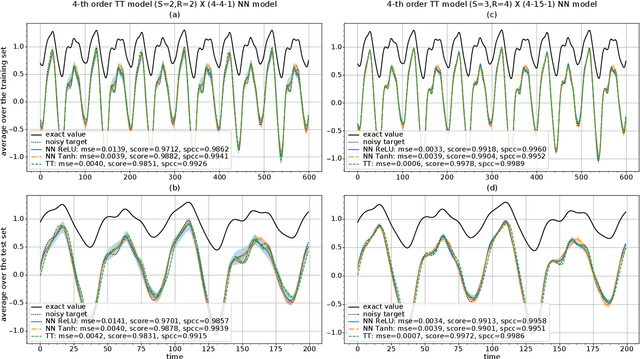
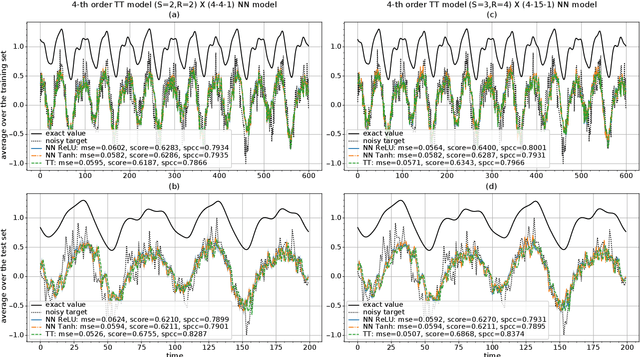
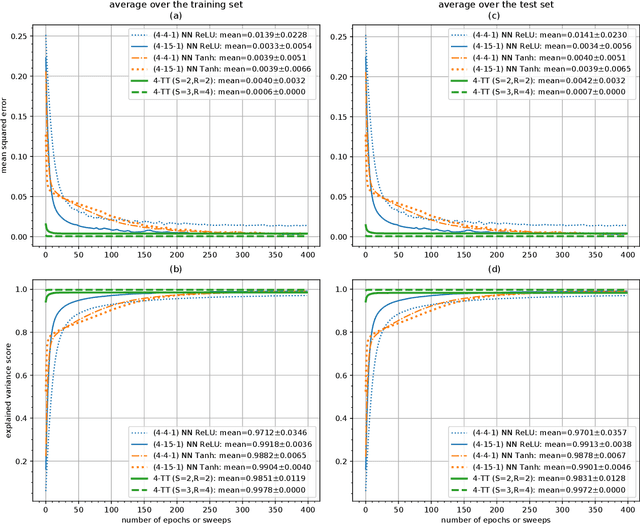
Deep neural networks have attracted the attention of the machine learning community because of their appealing data-driven framework and of their performance in several pattern recognition tasks. On the other hand, there are many open theoretical problems regarding the internal operation of the network, the necessity of certain layers, hyperparameter selection etc. A promising strategy is based on tensor networks, which have been very successful in physical and chemical applications. In general, higher-order tensors are decomposed into sparsely interconnected lower-order tensors. This is a numerically reliable way to avoid the curse of dimensionality and to provide highly compressed representation of a data tensor, besides the good numerical properties that allow to control the desired accuracy of approximation. In order to compare tensor and neural networks, we first consider the identification of the classical Multilayer Perceptron using Tensor-Train. A comparative analysis is also carried out in the context of prediction of the Mackey-Glass noisy chaotic time series and NASDAQ index. We have shown that the weights of a multidimensional regression model can be learned by means of tensor networks with the aim of performing a powerful compact representation retaining the accuracy of neural networks. Furthermore, an algorithm based on alternating least squares has been proposed for approximating the weights in TT-format with a reduction of computational calculus. By means of a direct expression, we have approximated the core estimation as the conventional solution for a general regression model, which allows to extend the applicability of tensor structures to different algorithms.
Distributed Infrastructure Inspection Path Planning subject to Time Constraints
Dec 25, 2016
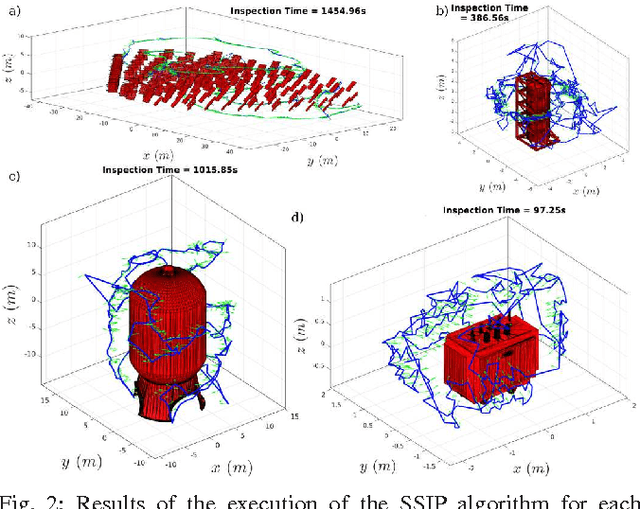
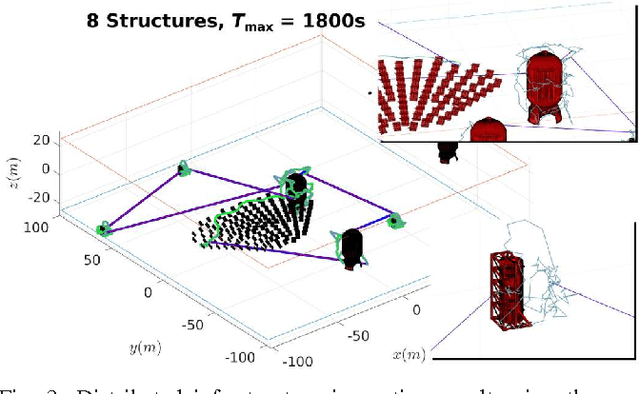
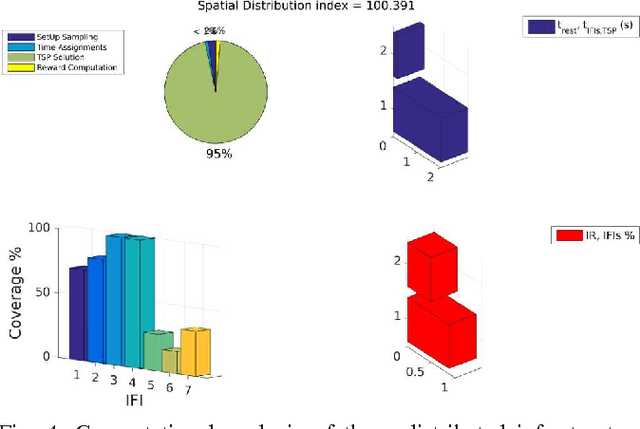
Within this paper, the problem of 3D structural inspection path planning for distributed infrastructure using aerial robots that are subject to time constraints is addressed. The proposed algorithm handles varying spatial properties of the infrastructure facilities, accounts for their different importance and exploration function and computes an overall inspection path of high inspection reward while respecting the robot endurance or mission time constraints as well as the vehicle dynamics and sensor limitations. To achieve its goal, it employs an iterative, 3-step optimization strategy at each iteration of which it first randomly samples a set of possible structures to visit, subsequently solves the derived traveling salesman problem and computes the travel costs, while finally it samples and assigns inspection times to each structure and evaluates the total inspection reward. For the derivation of the inspection paths per each independent facility, it interfaces a path planner dedicated to the 3D coverage of single structures. The resulting algorithm properties, computational performance and path quality are evaluated using simulation studies as well as experimental test-cases employing a multirotor micro aerial vehicle.
Weakly Supervised Temporal Action Localization with Segment-Level Labels
Jul 03, 2020
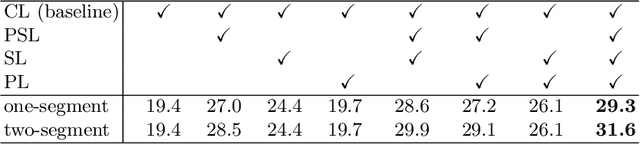
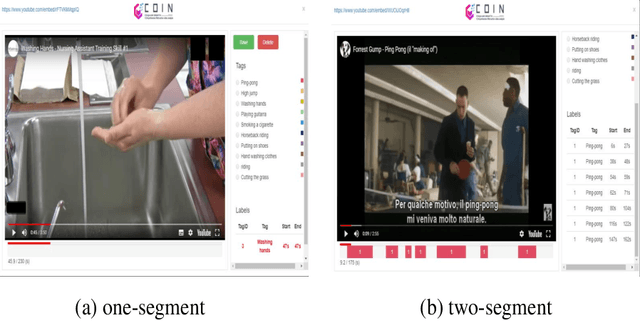
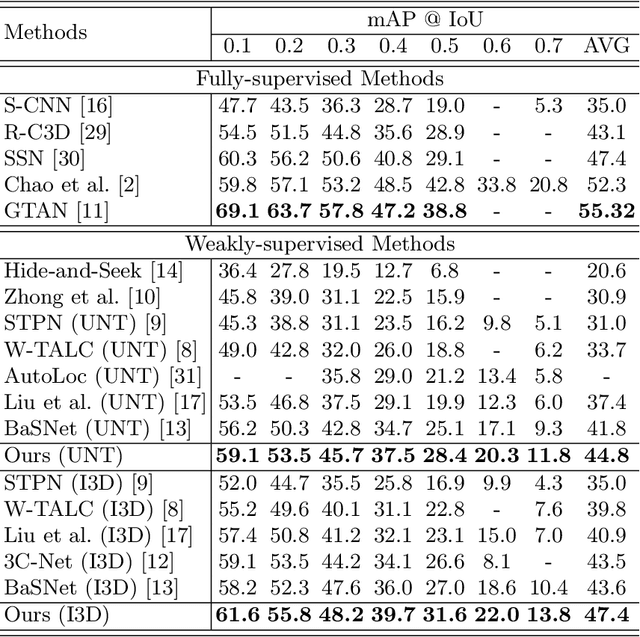
Temporal action localization presents a trade-off between test performance and annotation-time cost. Fully supervised methods achieve good performance with time-consuming boundary annotations. Weakly supervised methods with cheaper video-level category label annotations result in worse performance. In this paper, we introduce a new segment-level supervision setting: segments are labeled when annotators observe actions happening here. We incorporate this segment-level supervision along with a novel localization module in the training. Specifically, we devise a partial segment loss regarded as a loss sampling to learn integral action parts from labeled segments. Since the labeled segments are only parts of actions, the model tends to overfit along with the training process. To tackle this problem, we first obtain a similarity matrix from discriminative features guided by a sphere loss. Then, a propagation loss is devised based on the matrix to act as a regularization term, allowing implicit unlabeled segments propagation during training. Experiments validate that our method can outperform the video-level supervision methods with almost same the annotation time.
HDR Denoising and Deblurring by Learning Spatio-temporal Distortion Models
Dec 22, 2020
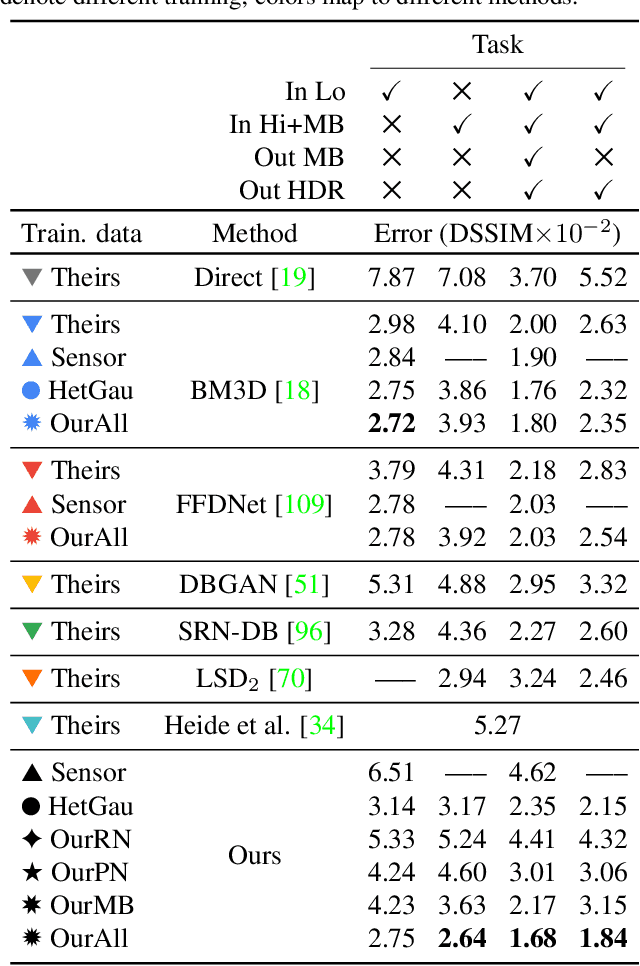
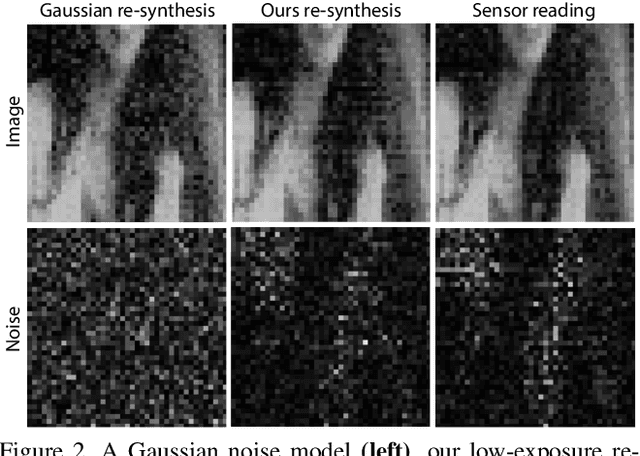
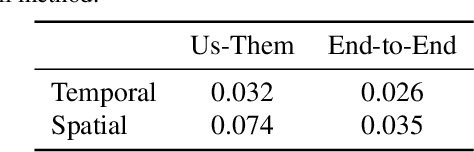
We seek to reconstruct sharp and noise-free high-dynamic range (HDR) video from a dual-exposure sensor that records different low-dynamic range (LDR) information in different pixel columns: Odd columns provide low-exposure, sharp, but noisy information; even columns complement this with less noisy, high-exposure, but motion-blurred data. Previous LDR work learns to deblur and denoise (DISTORTED->CLEAN) supervised by pairs of CLEAN and DISTORTED images. Regrettably, capturing DISTORTED sensor readings is time-consuming; as well, there is a lack of CLEAN HDR videos. We suggest a method to overcome those two limitations. First, we learn a different function instead: CLEAN->DISTORTED, which generates samples containing correlated pixel noise, and row and column noise, as well as motion blur from a low number of CLEAN sensor readings. Second, as there is not enough CLEAN HDR video available, we devise a method to learn from LDR video in-stead. Our approach compares favorably to several strong baselines, and can boost existing methods when they are re-trained on our data. Combined with spatial and temporal super-resolution, it enables applications such as re-lighting with low noise or blur.
An IoT Real-Time Biometric Authentication System Based on ECG Fiducial Extracted Features Using Discrete Cosine Transform
Aug 28, 2017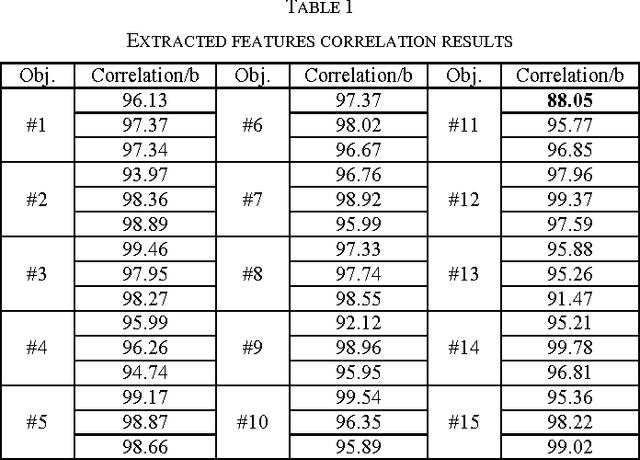
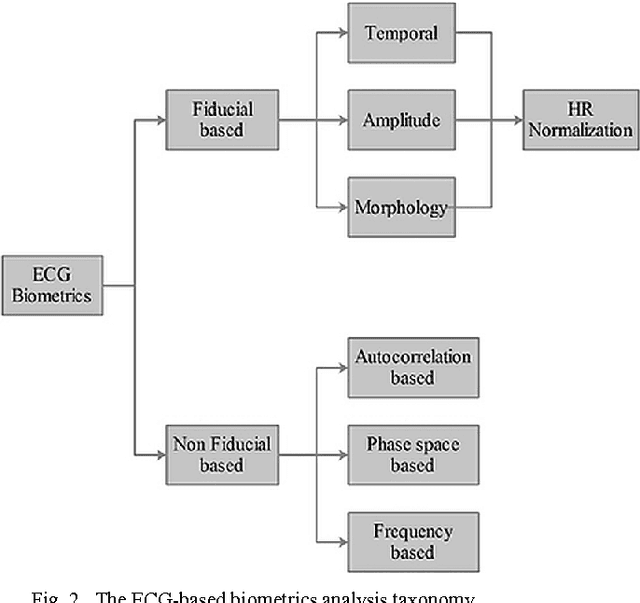
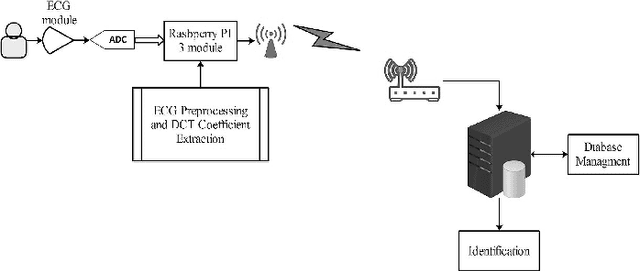
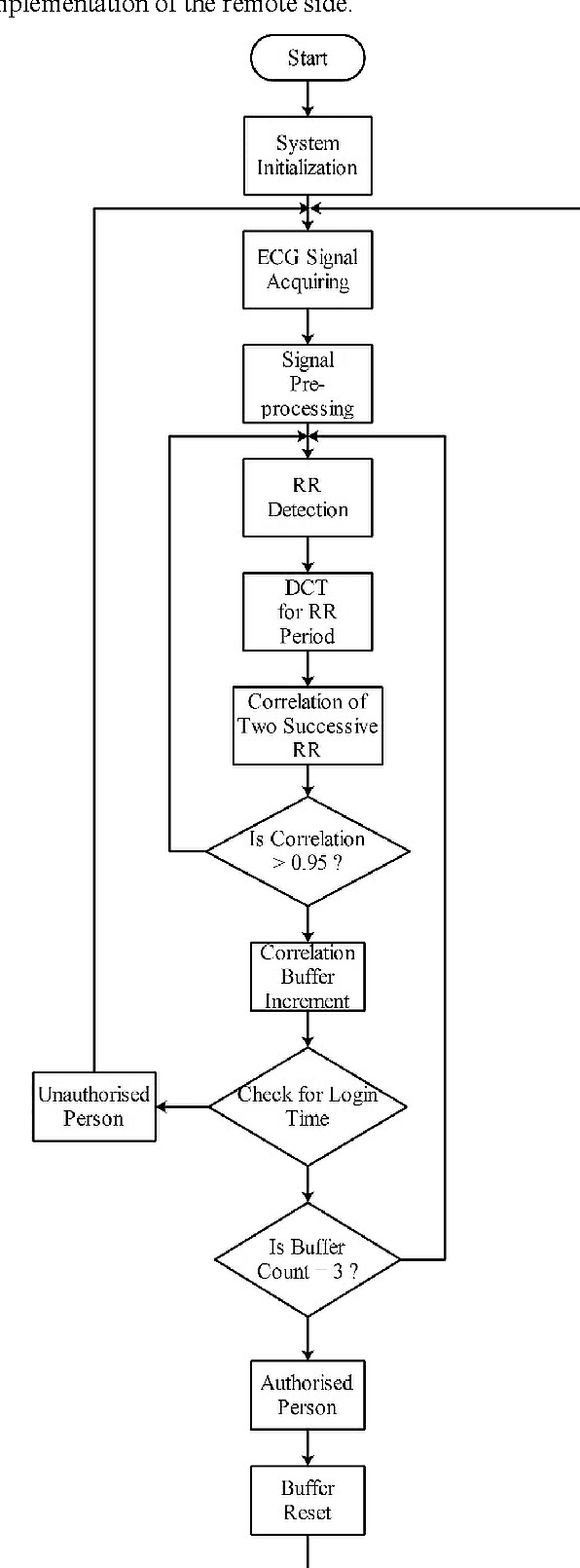
The conventional authentication technologies, like RFID tags and authentication cards/badges, suffer from different weaknesses, therefore a prompt replacement to use biometric method of authentication should be applied instead. Biometrics, such as fingerprints, voices, and ECG signals, are unique human characters that can be used for authentication processing. In this work, we present an IoT real-time authentication system based on using extracted ECG features to identify the unknown persons. The Discrete Cosine Transform (DCT) is used as an ECG feature extraction, where it has better characteristics for real-time system implementations. There are a substantial number of researches with a high accuracy of authentication, but most of them ignore the real-time capability of authenticating individuals. With the accuracy rate of 97.78% at around 1.21 seconds of processing time, the proposed system is more suitable for use in many applications that require fast and reliable authentication processing demands.
A General Machine Learning Framework for Survival Analysis
Jun 27, 2020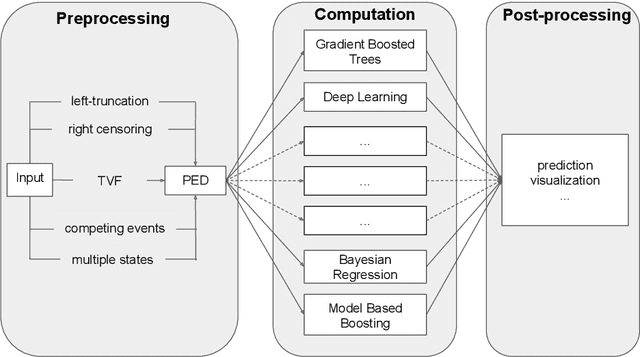

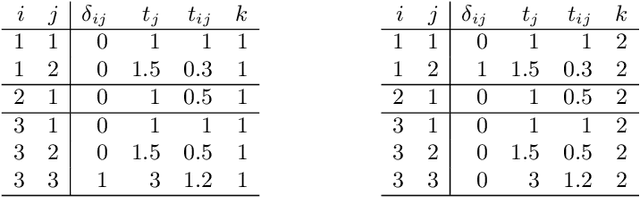
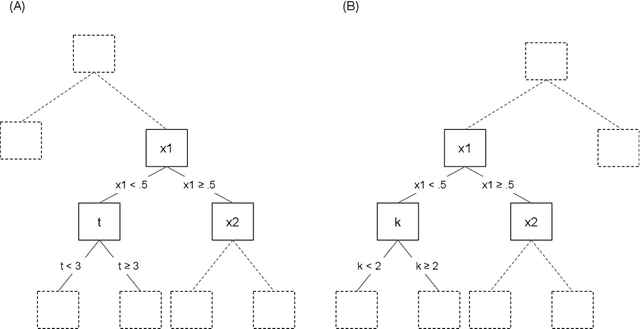
The modeling of time-to-event data, also known as survival analysis, requires specialized methods that can deal with censoring and truncation, time-varying features and effects, and that extend to settings with multiple competing events. However, many machine learning methods for survival analysis only consider the standard setting with right-censored data and proportional hazards assumption. The methods that do provide extensions usually address at most a subset of these challenges and often require specialized software that can not be integrated into standard machine learning workflows directly. In this work, we present a very general machine learning framework for time-to-event analysis that uses a data augmentation strategy to reduce complex survival tasks to standard Poisson regression tasks. This reformulation is based on well developed statistical theory. With the proposed approach, any algorithm that can optimize a Poisson (log-)likelihood, such as gradient boosted trees, deep neural networks, model-based boosting and many more can be used in the context of time-to-event analysis. The proposed technique does not require any assumptions with respect to the distribution of event times or the functional shapes of feature and interaction effects. Based on the proposed framework we develop new methods that are competitive with specialized state of the art approaches in terms of accuracy, and versatility, but with comparatively small investments of programming effort or requirements for specialized methodological know-how.
Approximate Solutions to a Class of Reachability Games
Nov 01, 2020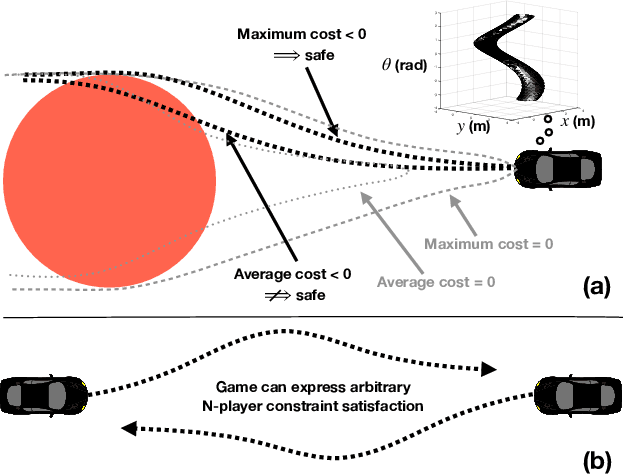
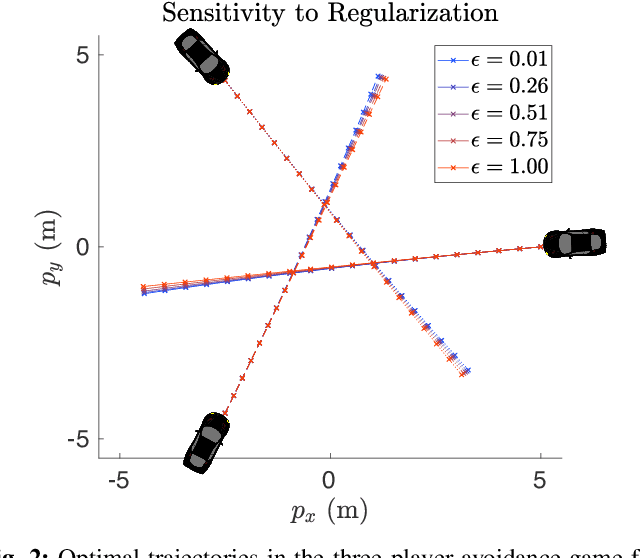
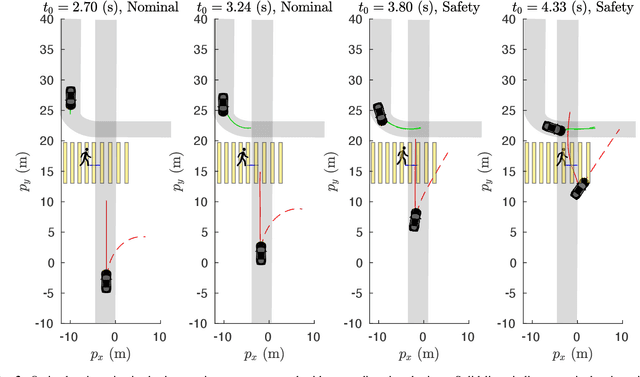
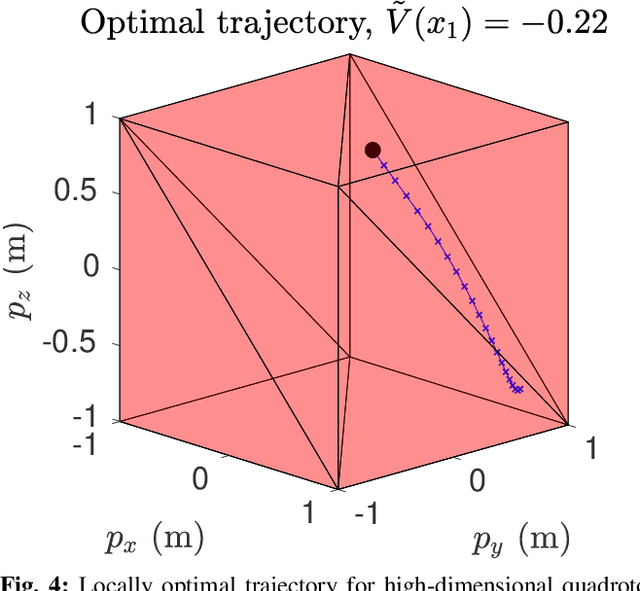
In this paper, we present a method for finding approximate Nash equilibria in a broad class of reachability games. These games are often used to formulate both collision avoidance and goal satisfaction. Our method is computationally efficient, running in real-time for scenarios involving multiple players and more than ten state dimensions. The proposed approach forms a family of increasingly exact approximations to the original game. Our results characterize the quality of these approximations and show operation in a receding horizon, minimally-invasive control context. Additionally, as a special case, our method reduces to local optimization in the single-player (optimal control) setting, for which a wide variety of efficient algorithms exist.
How can I choose an explainer? An Application-grounded Evaluation of Post-hoc Explanations
Jan 22, 2021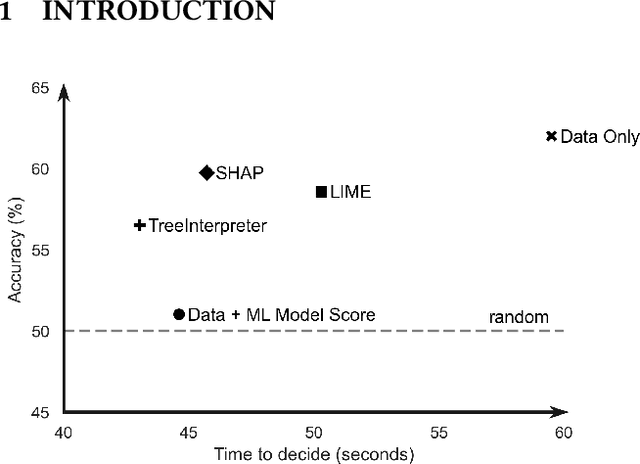
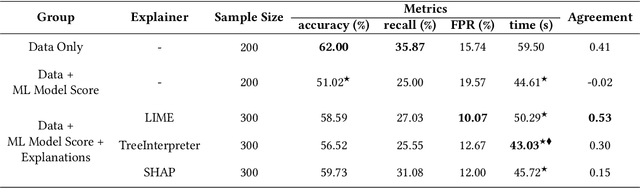
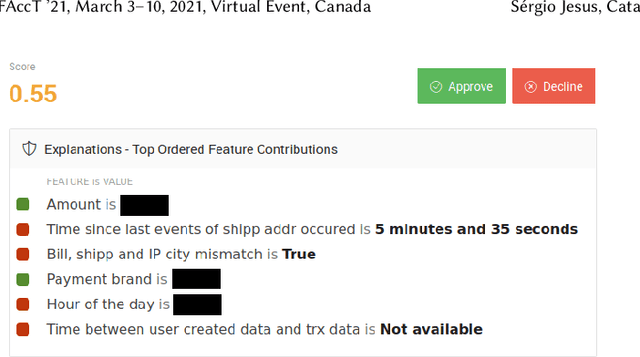
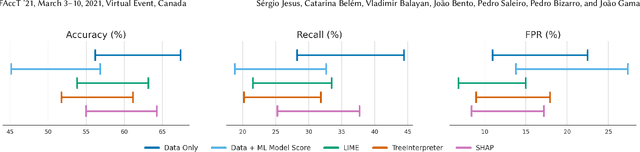
There have been several research works proposing new Explainable AI (XAI) methods designed to generate model explanations having specific properties, or desiderata, such as fidelity, robustness, or human-interpretability. However, explanations are seldom evaluated based on their true practical impact on decision-making tasks. Without that assessment, explanations might be chosen that, in fact, hurt the overall performance of the combined system of ML model + end-users. This study aims to bridge this gap by proposing XAI Test, an application-grounded evaluation methodology tailored to isolate the impact of providing the end-user with different levels of information. We conducted an experiment following XAI Test to evaluate three popular post-hoc explanation methods -- LIME, SHAP, and TreeInterpreter -- on a real-world fraud detection task, with real data, a deployed ML model, and fraud analysts. During the experiment, we gradually increased the information provided to the fraud analysts in three stages: Data Only, i.e., just transaction data without access to model score nor explanations, Data + ML Model Score, and Data + ML Model Score + Explanations. Using strong statistical analysis, we show that, in general, these popular explainers have a worse impact than desired. Some of the conclusion highlights include: i) showing Data Only results in the highest decision accuracy and the slowest decision time among all variants tested, ii) all the explainers improve accuracy over the Data + ML Model Score variant but still result in lower accuracy when compared with Data Only; iii) LIME was the least preferred by users, probably due to its substantially lower variability of explanations from case to case.