 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
mlOSP: Towards a Unified Implementation of Regression Monte Carlo Algorithms
Dec 01, 2020
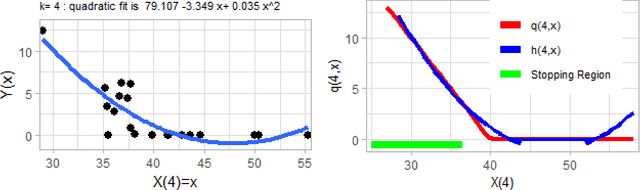
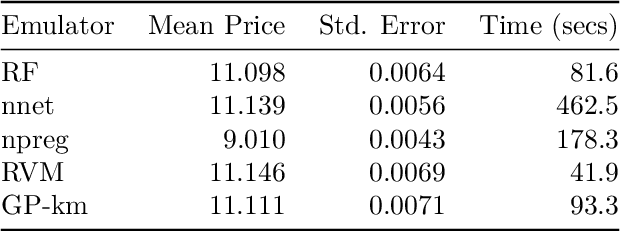
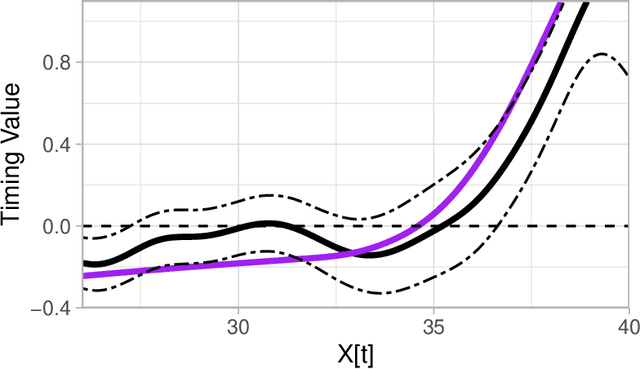
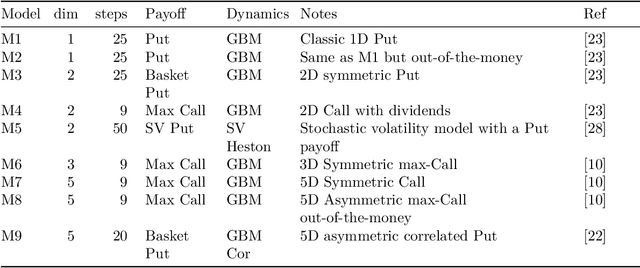
We introduce mlOSP, a computational template for Machine Learning for Optimal Stopping Problems. The template is implemented in the R statistical environment and publicly available via a GitHub repository. mlOSP presents a unified numerical implementation of Regression Monte Carlo (RMC) approaches to optimal stopping, providing a state-of-the-art, open-source, reproducible and transparent platform. Highlighting its modular nature, we present multiple novel variants of RMC algorithms, especially in terms of constructing simulation designs for training the regressors, as well as in terms of machine learning regression modules. At the same time, mlOSP nests most of the existing RMC schemes, allowing for a consistent and verifiable benchmarking of extant algorithms. The article contains extensive R code snippets and figures, and serves the dual role of presenting new RMC features and as a vignette to the underlying software package.
Convolutional Neural Networks at Constrained Time Cost
Dec 04, 2014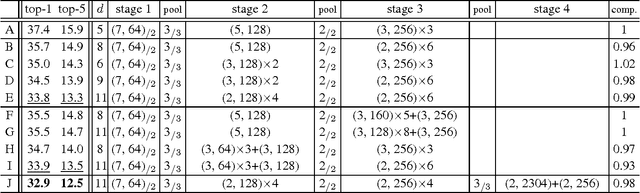
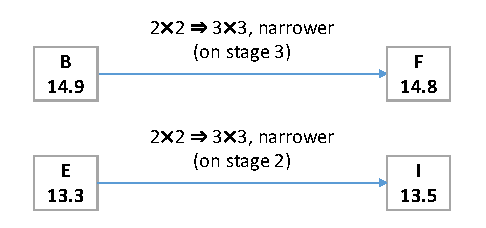


Though recent advanced convolutional neural networks (CNNs) have been improving the image recognition accuracy, the models are getting more complex and time-consuming. For real-world applications in industrial and commercial scenarios, engineers and developers are often faced with the requirement of constrained time budget. In this paper, we investigate the accuracy of CNNs under constrained time cost. Under this constraint, the designs of the network architectures should exhibit as trade-offs among the factors like depth, numbers of filters, filter sizes, etc. With a series of controlled comparisons, we progressively modify a baseline model while preserving its time complexity. This is also helpful for understanding the importance of the factors in network designs. We present an architecture that achieves very competitive accuracy in the ImageNet dataset (11.8% top-5 error, 10-view test), yet is 20% faster than "AlexNet" (16.0% top-5 error, 10-view test).
Learning Dense Representations of Phrases at Scale
Dec 23, 2020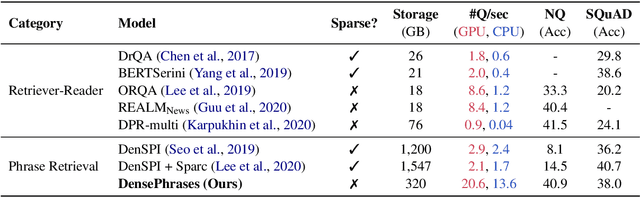
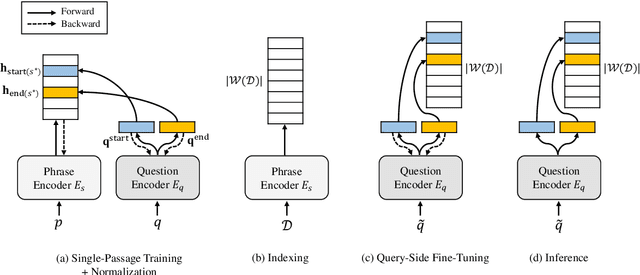
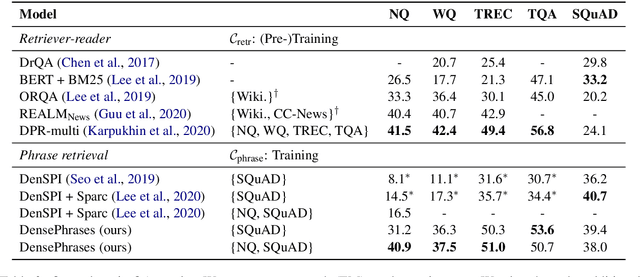
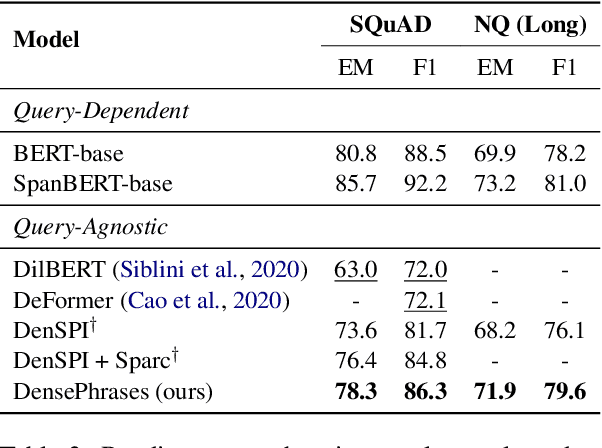
Open-domain question answering can be reformulated as a phrase retrieval problem, without the need for processing documents on-demand during inference (Seo et al., 2019). However, current phrase retrieval models heavily depend on their sparse representations while still underperforming retriever-reader approaches. In this work, we show for the first time that we can learn dense phrase representations alone that achieve much stronger performance in open-domain QA. Our approach includes (1) learning query-agnostic phrase representations via question generation and distillation; (2) novel negative-sampling methods for global normalization; (3) query-side fine-tuning for transfer learning. On five popular QA datasets, our model DensePhrases improves previous phrase retrieval models by 15%-25% absolute accuracy and matches the performance of state-of-the-art retriever-reader models. Our model is easy to parallelize due to pure dense representations and processes more than 10 questions per second on CPUs. Finally, we directly use our pre-indexed dense phrase representations for two slot filling tasks, showing the promise of utilizing DensePhrases as a dense knowledge base for downstream tasks.
Commission Fee is not Enough: A Hierarchical Reinforced Framework for Portfolio Management
Dec 23, 2020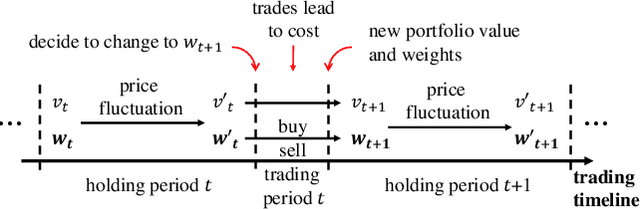
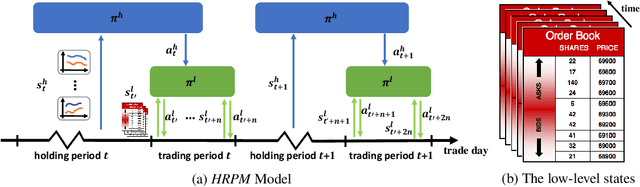
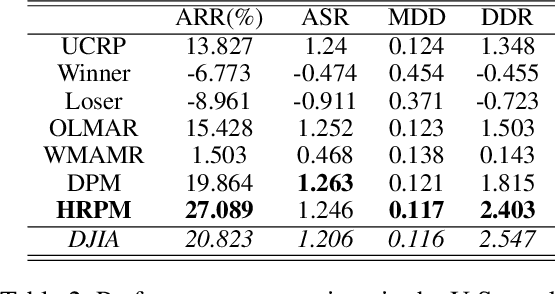
Portfolio management via reinforcement learning is at the forefront of fintech research, which explores how to optimally reallocate a fund into different financial assets over the long term by trial-and-error. Existing methods are impractical since they usually assume each reallocation can be finished immediately and thus ignoring the price slippage as part of the trading cost. To address these issues, we propose a hierarchical reinforced stock trading system for portfolio management (HRPM). Concretely, we decompose the trading process into a hierarchy of portfolio management over trade execution and train the corresponding policies. The high-level policy gives portfolio weights at a lower frequency to maximize the long term profit and invokes the low-level policy to sell or buy the corresponding shares within a short time window at a higher frequency to minimize the trading cost. We train two levels of policies via pre-training scheme and iterative training scheme for data efficiency. Extensive experimental results in the U.S. market and the China market demonstrate that HRPM achieves significant improvement against many state-of-the-art approaches.
Beyond I.I.D.: Three Levels of Generalization for Question Answering on Knowledge Bases
Dec 13, 2020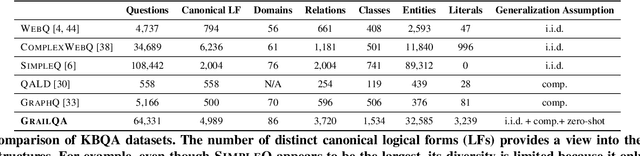
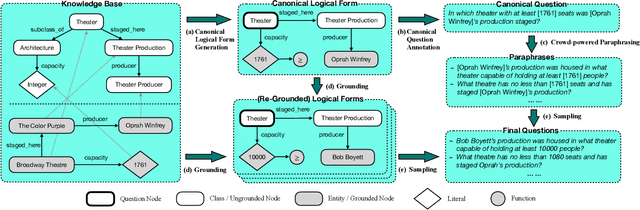

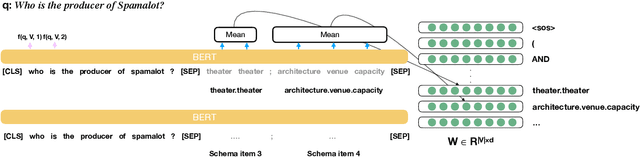
Existing studies on question answering on knowledge bases (KBQA) mainly operate with the standard i.i.d assumption, i.e., training distribution over questions is the same as the test distribution. However, i.i.d may be neither reasonably achievable nor desirable on large-scale KBs because 1) true user distribution is hard to capture and 2) randomly sample training examples from the enormous space would be highly data-inefficient. Instead, we suggest that KBQA models should have three levels of built-in generalization: i.i.d, compositional, and zero-shot. To facilitate the development of KBQA models with stronger generalization, we construct and release a new large-scale, high-quality dataset with 64,331 questions, GrailQA, and provide evaluation settings for all three levels of generalization. In addition, we propose a novel BERT-based KBQA model. The combination of our dataset and model enables us to thoroughly examine and demonstrate, for the first time, the key role of pre-trained contextual embeddings like BERT in the generalization of KBQA.
Preference-based performance measures for Time-Domain Global Similarity method
Nov 08, 2017
For Time-Domain Global Similarity (TDGS) method, which transforms the data cleaning problem into a binary classification problem about the physical similarity between channels, directly adopting common performance measures could only guarantee the performance for physical similarity. Nevertheless, practical data cleaning tasks have preferences for the correctness of original data sequences. To obtain the general expressions of performance measures based on the preferences of tasks, the mapping relations between performance of TDGS method about physical similarity and correctness of data sequences are investigated by probability theory in this paper. Performance measures for TDGS method in several common data cleaning tasks are set. Cases when these preference-based performance measures could be simplified are introduced.
Robustness to Missing Features using Hierarchical Clustering with Split Neural Networks
Nov 19, 2020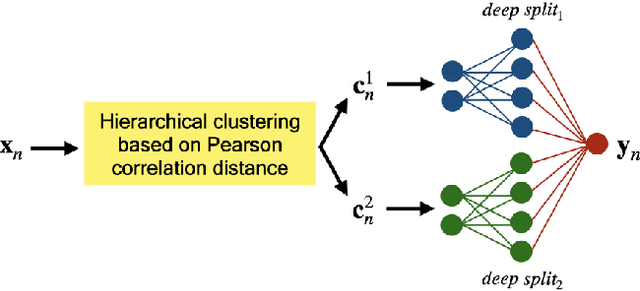
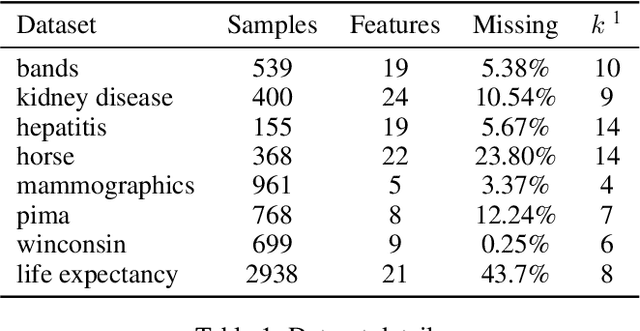
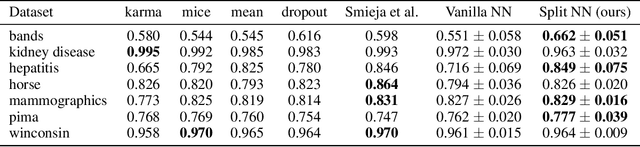
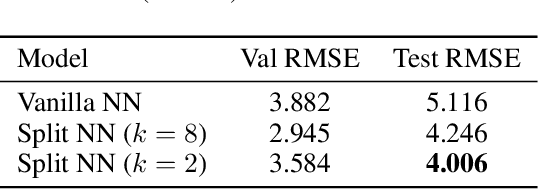
The problem of missing data has been persistent for a long time and poses a major obstacle in machine learning and statistical data analysis. Past works in this field have tried using various data imputation techniques to fill in the missing data, or training neural networks (NNs) with the missing data. In this work, we propose a simple yet effective approach that clusters similar input features together using hierarchical clustering and then trains proportionately split neural networks with a joint loss. We evaluate this approach on a series of benchmark datasets and show promising improvements even with simple imputation techniques. We attribute this to learning through clusters of similar features in our model architecture. The source code is available at https://github.com/usarawgi911/Robustness-to-Missing-Features
Quantum Mathematics in Artificial Intelligence
Feb 01, 2021
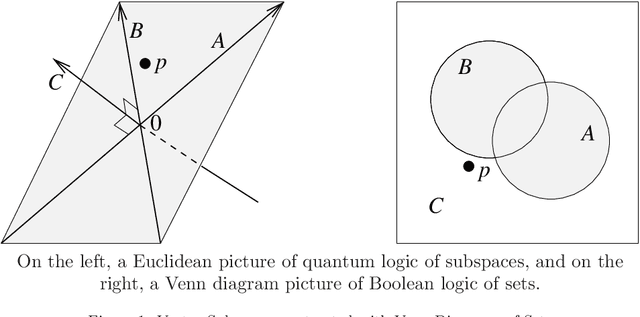
In the decade since 2010, successes in artificial intelligence have been at the forefront of computer science and technology, and vector space models have solidified a position at the forefront of artificial intelligence. At the same time, quantum computers have become much more powerful, and announcements of major advances are frequently in the news. The mathematical techniques underlying both these areas have more in common than is sometimes realized. Vector spaces took a position at the axiomatic heart of quantum mechanics in the 1930s, and this adoption was a key motivation for the derivation of logic and probability from the linear geometry of vector spaces. Quantum interactions between particles are modelled using the tensor product, which is also used to express objects and operations in artificial neural networks. This paper describes some of these common mathematical areas, including examples of how they are used in artificial intelligence (AI), particularly in automated reasoning and natural language processing (NLP). Techniques discussed include vector spaces, scalar products, subspaces and implication, orthogonal projection and negation, dual vectors, density matrices, positive operators, and tensor products. Application areas include information retrieval, categorization and implication, modelling word-senses and disambiguation, inference in knowledge bases, and semantic composition. Some of these approaches can potentially be implemented on quantum hardware. Many of the practical steps in this implementation are in early stages, and some are already realized. Explaining some of the common mathematical tools can help researchers in both AI and quantum computing further exploit these overlaps, recognizing and exploring new directions along the way.
Design of Experiments for Verifying Biomolecular Networks
Nov 25, 2020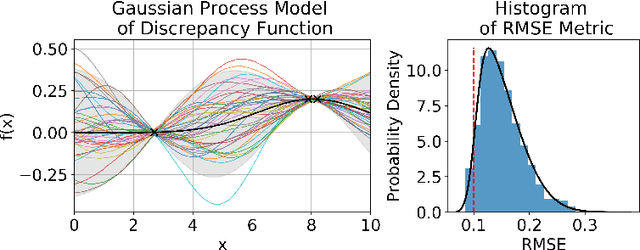
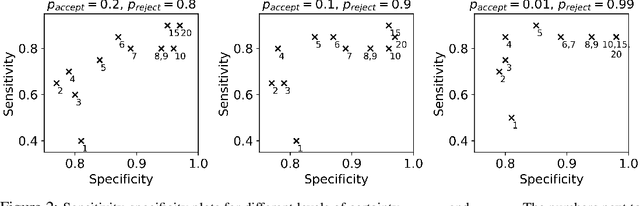
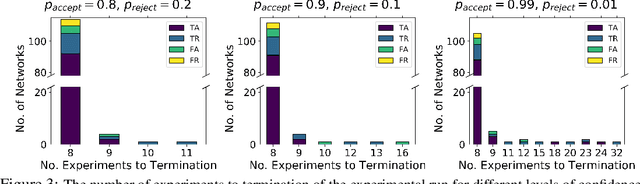
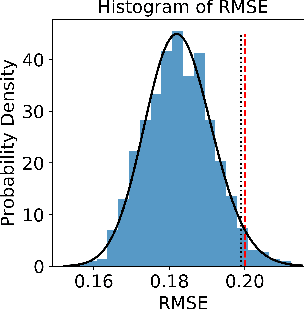
There is a growing trend in molecular and synthetic biology of using mechanistic (non machine learning) models to design biomolecular networks. Once designed, these networks need to be validated by experimental results to ensure the theoretical network correctly models the true system. However, these experiments can be expensive and time consuming. We propose a design of experiments approach for validating these networks efficiently. Gaussian processes are used to construct a probabilistic model of the discrepancy between experimental results and the designed response, then a Bayesian optimization strategy used to select the next sample points. We compare different design criteria and develop a stopping criterion based on a metric that quantifies this discrepancy over the whole surface, and its uncertainty. We test our strategy on simulated data from computer models of biochemical processes.
Learned Block-based Hybrid Image Compression
Jan 18, 2021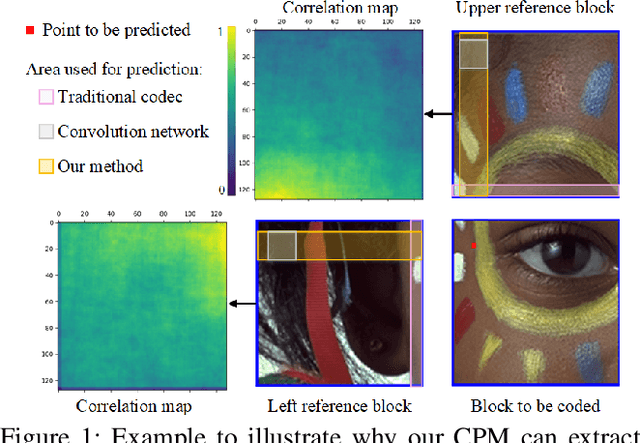
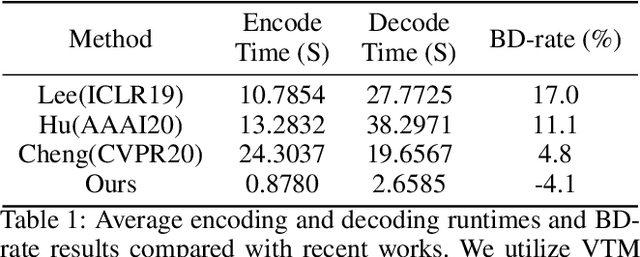
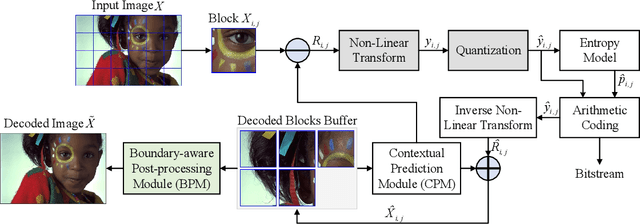
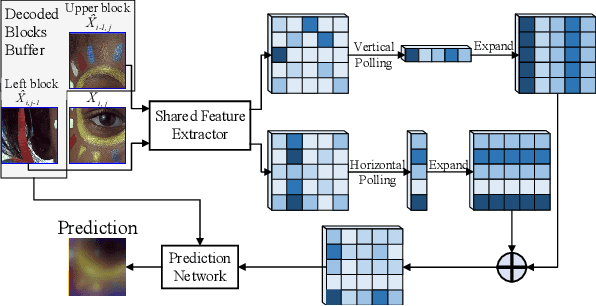
Recent works on learned image compression perform encoding and decoding processes in a full-resolution manner, resulting in two problems when deployed for practical applications. First, parallel acceleration of the autoregressive entropy model cannot be achieved due to serial decoding. Second, full-resolution inference often causes the out-of-memory(OOM) problem with limited GPU resources, especially for high-resolution images. Block partition is a good design choice to handle the above issues, but it brings about new challenges in reducing the redundancy between blocks and eliminating block effects. To tackle the above challenges, this paper provides a learned block-based hybrid image compression (LBHIC) framework. Specifically, we introduce explicit intra prediction into a learned image compression framework to utilize the relation among adjacent blocks. Superior to context modeling by linear weighting of neighbor pixels in traditional codecs, we propose a contextual prediction module (CPM) to better capture long-range correlations by utilizing the strip pooling to extract the most relevant information in neighboring latent space, thus achieving effective information prediction. Moreover, to alleviate blocking artifacts, we further propose a boundary-aware postprocessing module (BPM) with the edge importance taken into account. Extensive experiments demonstrate that the proposed LBHIC codec outperforms the VVC, with a bit-rate conservation of 4.1%, and reduces the decoding time by approximately 86.7% compared with that of state-of-the-art learned image compression methods.